《Tony Bai. Go语言第一课》——小记随笔
入口函数与包初始化
main.main 函数:Go 应用的入口函数
Go 语言中有一个特殊的函数:main 包中的 main 函数,也就是 main.main,它是所有 Go 可执行程序的用户层执行逻辑的入口函数。Go 程序在用户层面的执行逻辑,会在这个函数内按照它的调用顺序展开。
package main
func main() {
// 用户层执行逻辑
... ...
}
init 函数:Go 包的初始化函数
func init() {
// 包初始化逻辑
... ...
}
如果 main 包依赖的包中定义了 init 函数,或者是 main 包自身定义了 init 函数,那么 Go 程序在这个包初始化的时候,就会自动调用它的 init 函数,因此这些 init 函数的执行就都会发生在 main 函数之前。
Go 包可以拥有不止一个 init 函数,每个组成 Go 包的 Go 源文件中,也可以定义多个 init 函数。
在初始化 Go 包时,Go 会按照一定的次序,逐一、顺序地调用这个包的 init 函数。一般来说,先传递给 Go 编译器的源文件中的 init 函数,会先被执行;而同一个源文件中的多个 init 函数,会按声明顺序依次执行。
Go 包的初始化次序
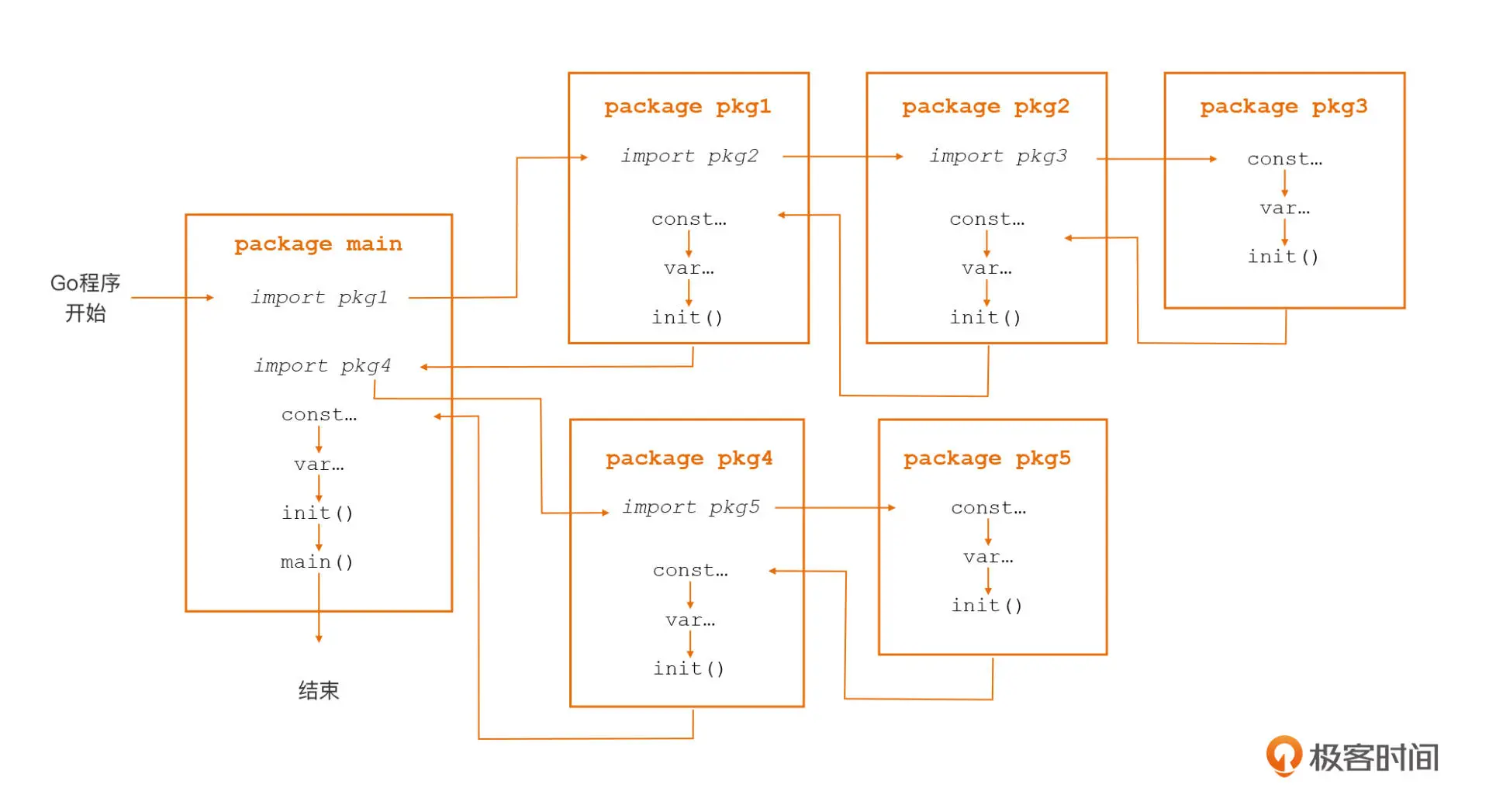
- 依赖包按“深度优先”的次序进行初始化;
- 每个包内按以“常量 -> 变量 -> init 函数”的顺序进行初始化;
- 包内的多个 init 函数按出现次序进行自动调用。
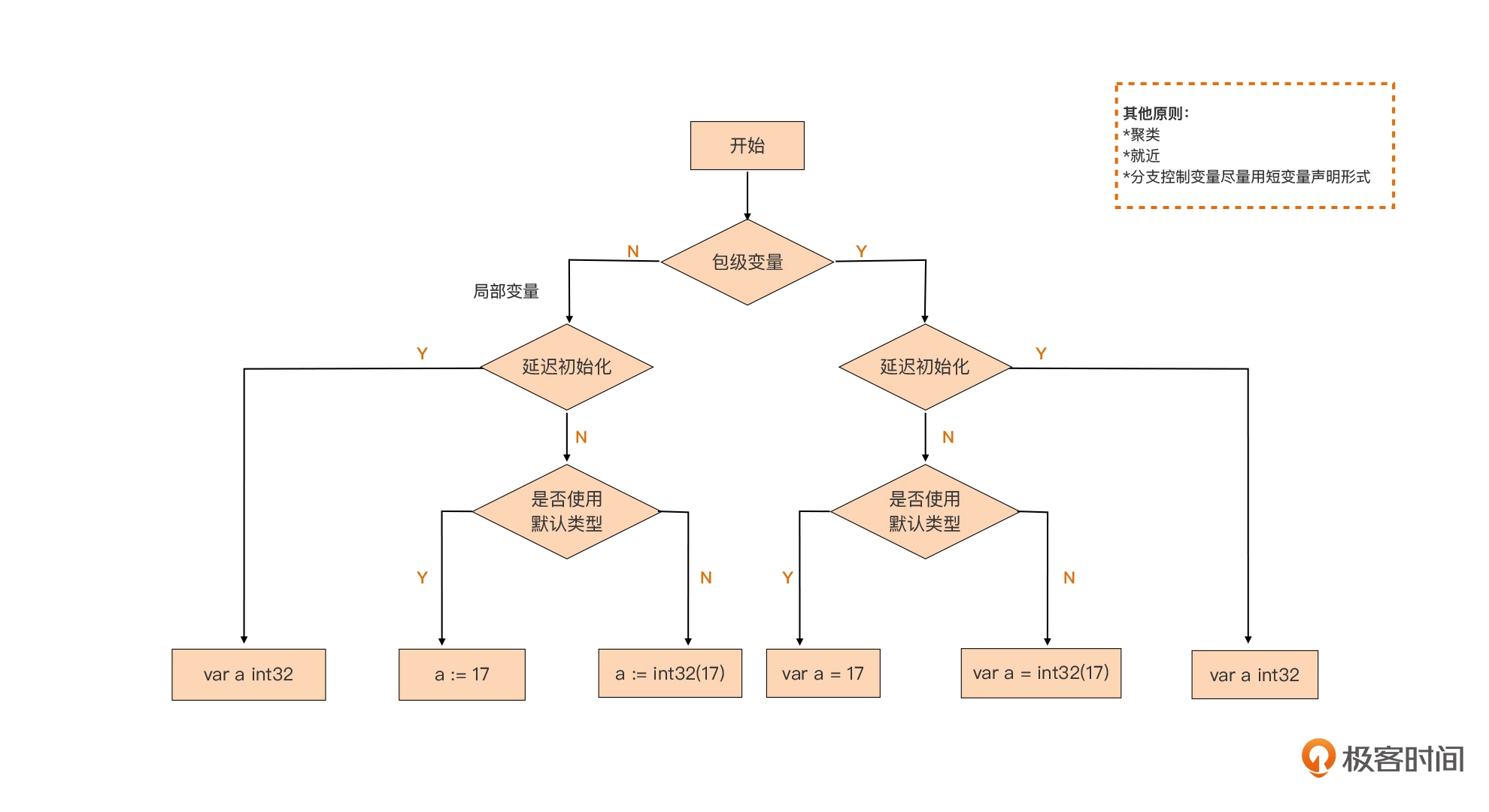
变量声明:静态语言有别于动态语言的重要特征
基本数据类型:为什么Go要原生支持字符串类型?
原生支持字符串有什么好处?
- 第一点:string 类型的数据是不可变的,提高了字符串的并发安全性和存储利用率。
- 第二点:没有结尾’\0’,而且获取长度的时间复杂度是常数时间,消除了获取字符串长度的开销。
- 第三点:原生支持“所见即所得”的原始字符串,大大降低构造多行字符串时的心智负担。
var s string = ` ,_---~~~~~----._
_,,_,*^____ _____*g*\"*,--,
/ __/ /' ^. / \ ^@q f
[ @f | @)) | | @)) l 0 _/
\/ \~____ / __ \_____/ \
| _l__l_ I
} [______] I
] | | | |
] ~ ~ |
| |
| |`
fmt.Println(s)
字符串变量 s 被赋值了一个由一对反引号包裹的 Gopher 图案。这个 Gopher 图案由诸多 ASCII 字符组成,其中就包括了转义字符。这个时候,如果我们通过 Println 函数输出这个字符串,得到的图案和上面的图案并无二致。
- 第四点:对非 ASCII 字符提供原生支持,消除了源码在不同环境下显示乱码的可能。
Go 语言源文件默认采用的是 Unicode 字符集,Unicode 字符集是目前市面上最流行的字符集,它囊括了几乎所有主流非 ASCII 字符(包括中文字符)
Go 字符串的组成
Go 语言在看待 Go 字符串组成这个问题上,有两种视角。
一种是字节视角,也就是和所有其它支持字符串的主流语言一样,Go 语言中的字符串值也是一个可空的字节序列,字节序列中的字节个数称为该字符串的长度。一个个的字节只是孤立数据,不表意。
var s = "中国人"
fmt.Printf("the length of s = %d\n", len(s)) // 9
for i := 0; i < len(s); i++ {
fmt.Printf("0x%x ", s[i]) // 0xe4 0xb8 0xad 0xe5 0x9b 0xbd 0xe4 0xba 0xba
}
fmt.Printf("\n")
如果要表意,我们就需要从字符串的另外一个视角来看,也就是字符串是由一个可空的字符序列构成。这个时候我们再看下面代码:
var s = "中国人"
fmt.Println("the character count in s is", utf8.RuneCountInString(s)) // 3
for _, c := range s {
fmt.Printf("0x%x ", c) // 0x4e2d 0x56fd 0x4eba
}
fmt.Printf("\n")
在这段代码中,我们输出了字符串中的字符数量,也输出了这个字符串中的每个字符。前面说过,Go 采用的是 Unicode 字符集,每个字符都是一个 Unicode 字符,那么这里输出的 0x4e2d、0x56fd 和 0x4eba 就应该是某种 Unicode 字符的表示了。没错,以 0x4e2d 为例,它是汉字“中”在 Unicode 字符集表中的码点(Code Point)。
rune 类型与字符字面值
// $GOROOT/src/builtin.go
type rune = int32
由于一个 Unicode 码点唯一对应一个 Unicode 字符。所以我们可以说,一个 rune 实例就是一个 Unicode 字符,一个 Go 字符串也可以被视为 rune 实例的集合。我们可以通过字符字面值来初始化一个 rune 变量。
在 Go 中,字符字面值有多种表示法,最常见的是通过单引号括起的字符字面值,比如:
'a' // ASCII字符
'中' // Unicode字符集中的中文字符
'\n' // 换行字符
'\'' // 单引号字符
我们还可以使用 Unicode 专用的转义字符\u 或\U 作为前缀,来表示一个 Unicode 字符,比如:
'\u4e2d' // 字符:中
'\U00004e2d' // 字符:中
'\u0027' // 单引号字符
\u 后面接四个十六进制数。如果是用四个十六进制数无法表示的 Unicode 字符,我们可以使用\U,\U 后面可以接八个十六进制数来表示一个 Unicode 字符。
,由于表示码点的 rune 本质上就是一个整型数,所以我们还可用整型值来直接作为字符字面值给 rune 变量赋值,比如下面代码:
'\x27' // 使用十六进制表示的单引号字符
'\047' // 使用八进制表示的单引号字符
Go 字符串类型的内部表示
// $GOROOT/src/reflect/value.go
// StringHeader是一个string的运行时表示
type StringHeader struct {
Data uintptr
Len int
}
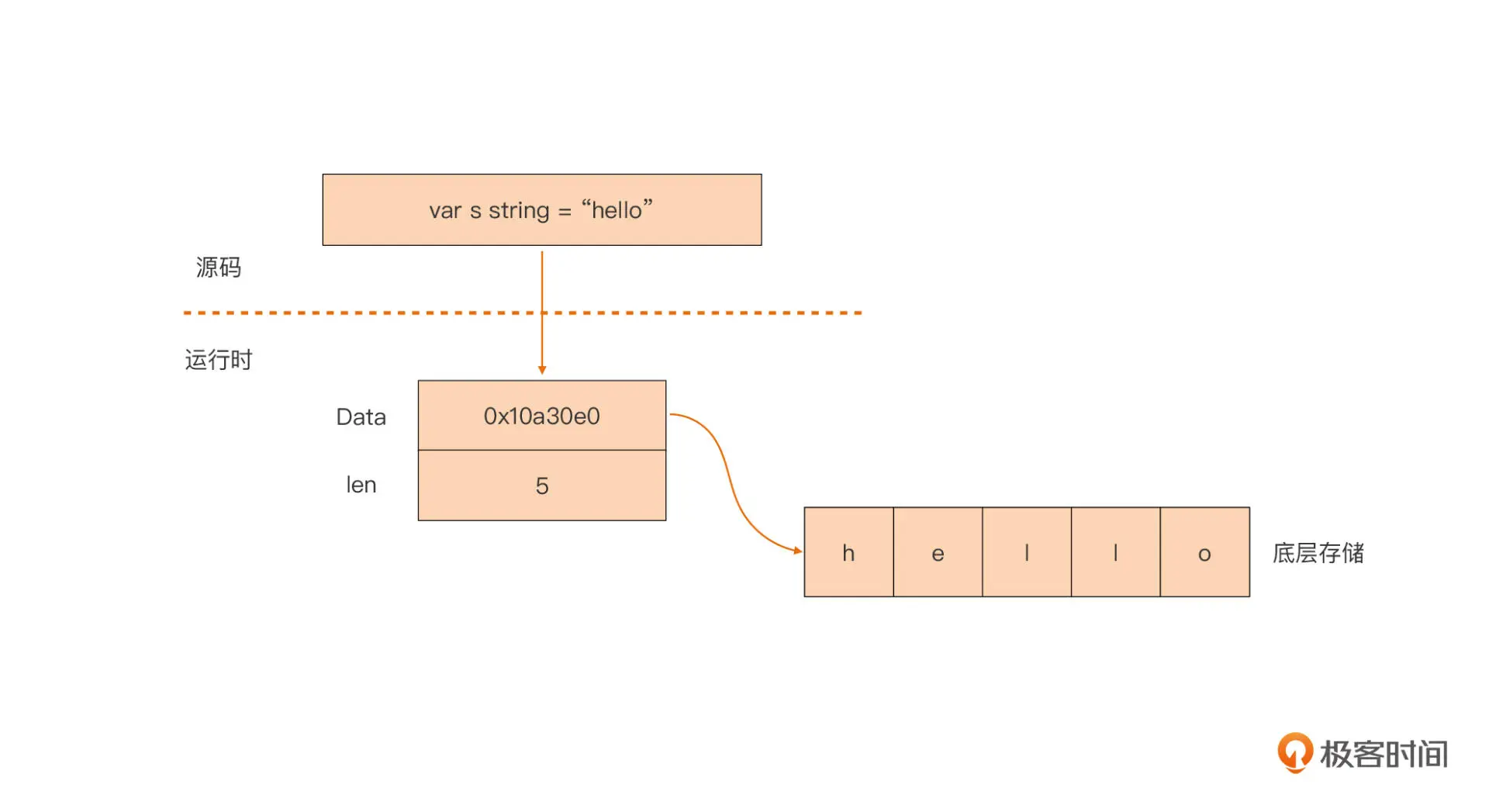
string 类型其实是一个“描述符”,它本身并不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成的。我也
Go 字符串类型的常见操作
第一个操作:下标操作。
var s = "中国人"
fmt.Printf("0x%x\n", s[0]) // 0xe4:字符“中” utf-8编码的第一个字节
我们可以看到,通过下标操作,我们获取的是字符串中特定下标上的字节,而不是字符。
第二个操作:字符迭代。
常规 for 迭代与 for range 迭代。你要注意,通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
var s = "中国人"
for i := 0; i < len(s); i++ {
fmt.Printf("index: %d, value: 0x%x\n", i, s[i])
}
运行这段代码,我们会看到,经过常规 for 迭代后,我们获取到的是字符串里字符的 UTF-8 编码中的一个字节.
var s = "中国人"
for i, v := range s {
fmt.Printf("index: %d, value: 0x%x\n", i, v)
}
通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值。
而通过 Go 提供的内置函数 len,我们只能获取字符串内容的长度(字节个数)。当然了,获取字符串中字符个数更专业的方法,是调用标准库 UTF-8 包中的 RuneCountInString 函数,这点你可以自己试一下。
第三个操作:字符串连接。
s := "Rob Pike, "
s = s + "Robert Griesemer, "
s += " Ken Thompson"
fmt.Println(s) // Rob Pike, Robert Griesemer, Ken Thompson
虽然通过 +/+= 进行字符串连接的开发体验是最好的,但连接性能就未必是最快的了。除了这个方法外,Go 还提供了 strings.Builder、strings.Join、fmt.Sprintf 等函数来进行字符串连接操作
第四个操作:字符串比较。
Go 采用字典序的比较策略,分别从每个字符串的起始处,开始逐个字节地对两个字符串类型变量进行比较。
第五个操作:字符串转换。
Go 支持字符串与字节切片、字符串与 rune 切片的双向转换,并且这种转换无需调用任何函数,只需使用显式类型转换就可以了
var s string = "中国人"
// string -> []rune
rs := []rune(s)
fmt.Printf("%x\n", rs) // [4e2d 56fd 4eba]
// string -> []byte
bs := []byte(s)
fmt.Printf("%x\n", bs) // e4b8ade59bbde4baba
// []rune -> string
s1 := string(rs)
fmt.Println(s1) // 中国人
// []byte -> string
s2 := string(bs)
fmt.Println(s2) // 中国人
这样的转型看似简单,但无论是 string 转切片,还是切片转 string,这类转型背后也是有着一定开销的。这些开销的根源就在于 string 是不可变的,运行时要为转换后的类型分配新内存。
同构复合类型:从定长数组到变长切片
数组有哪些基本特性?
var arr [N]T
我们可以识别出 Go 的数组类型包含两个重要属性:元素的类型和数组长度(元素的个数)
数组类型不仅是逻辑上的连续序列,而且在实际内存分配时也占据着一整块内存。
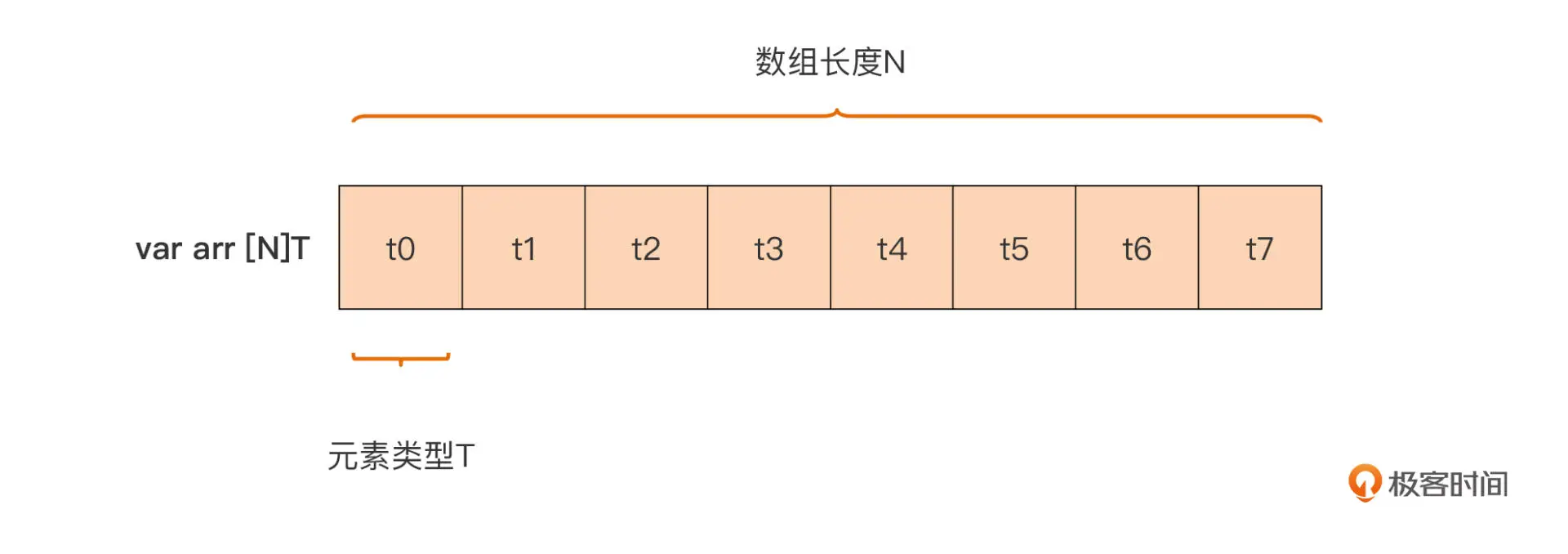
Go 提供了预定义函数 len 可以用于获取一个数组类型变量的长度,通过 unsafe 包提供的 Sizeof 函数,我们可以获得一个数组变量的总大小,如下面代码:
var arr = [6]int{1, 2, 3, 4, 5, 6}
fmt.Println("数组长度:", len(arr)) // 6
fmt.Println("数组大小:", unsafe.Sizeof(arr)) // 48
切片是怎么一回事?
数组作为最基本同构类型在 Go 语言中被保留了下来,但数组在使用上确有两点不足:固定的元素个数,以及传值机制下导致的开销较大。
var nums = []int{1, 2, 3, 4, 5, 6}
Go 切片在运行时其实是一个三元组结构,它在 Go 运行时中的表示如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
- array: 是指向底层数组的指针;
- len: 是切片的长度,即切片中当前元素的个数;
- cap: 是底层数组的长度,也是切片的最大容量,cap 值永远大于等于 len 值。
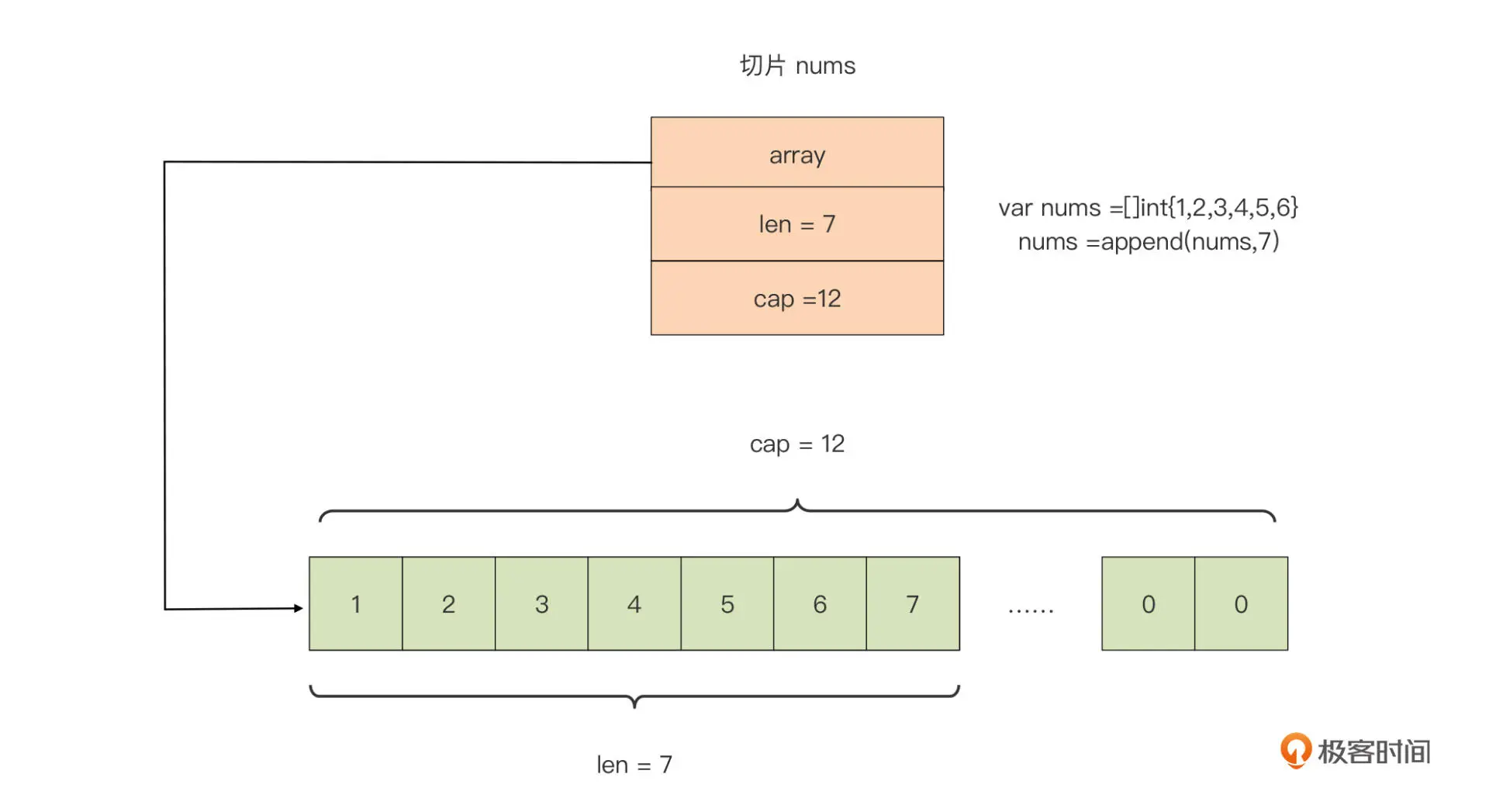
Go 编译器会自动为每个新创建的切片,建立一个底层数组,默认底层数组的长度与切片初始元素个数相同。我们还可以用以下几种方法创建切片,并指定它底层数组的长度。
- 方法一:通过 make 函数来创建切片,并指定底层数组的长度。
sl := make([]byte, 6, 10) // 其中10为cap值,即底层数组长度,6为切片的初始长度
- 方法二:采用 array[low : high : max]语法基于一个已存在的数组创建切片。这种方式被称为数组的切片化
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
sl := arr[3:7:9]
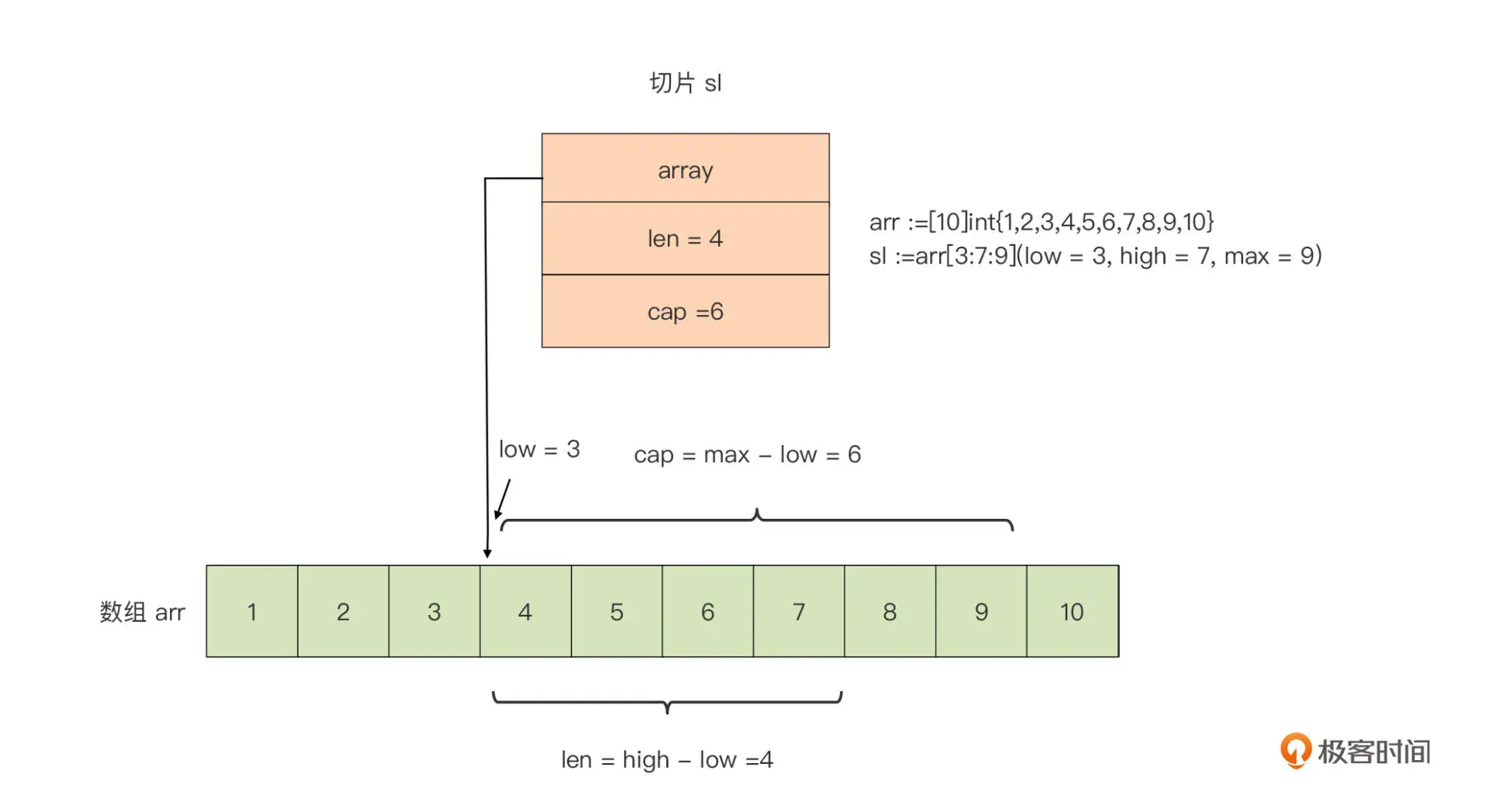
对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,如果我们将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14:
sl[0] += 10
fmt.Println("arr[3] =", arr[3]) // 14
- 方法三:基于切片创建切片。
切片的动态扩容
append 会根据切片的需要,在当前底层数组容量无法满足的情况下,动态分配新的数组,新数组长度会按一定规律扩展。在上面这段代码中,针对元素是 int 型的数组,新数组的容量是当前数组的 2 倍。新数组建立后,append 会把旧数组中的数据拷贝到新数组中,之后新数组便成为了切片的底层数组,旧数组会被垃圾回收掉。
比如基于一个已有数组建立的切片,一旦追加的数据操作触碰到切片的容量上限(实质上也是数组容量的上界),切片就会和原数组解除“绑定”,后续对切片的任何修改都不会反映到原数组中了
复合数据类型:原生map类型的实现机制是怎样的?
Go 语言中要求,key 的类型必须支持“==”和“!=”两种比较操作符。
因此在这里,你一定要注意:函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的。
map 的内部实现
运行时实现了 map 类型操作的所有功能,包括查找、插入、删除等。在编译阶段,Go 编译器会将 Go 语法层面的 map 操作,重写成运行时对应的函数调用。大致的对应关系是这样的:
// 创建map类型变量实例
m := make(map[keyType]valType, capacityhint) → m := runtime.makemap(maptype, capacityhint, m)
// 插入新键值对或给键重新赋值
m["key"] = "value" → v := runtime.mapassign(maptype, m, "key") v是用于后续存储value的空间的地址
// 获取某键的值
v := m["key"] → v := runtime.mapaccess1(maptype, m, "key")
v, ok := m["key"] → v, ok := runtime.mapaccess2(maptype, m, "key")
// 删除某键
delete(m, "key") → runtime.mapdelete(maptype, m, “key”)
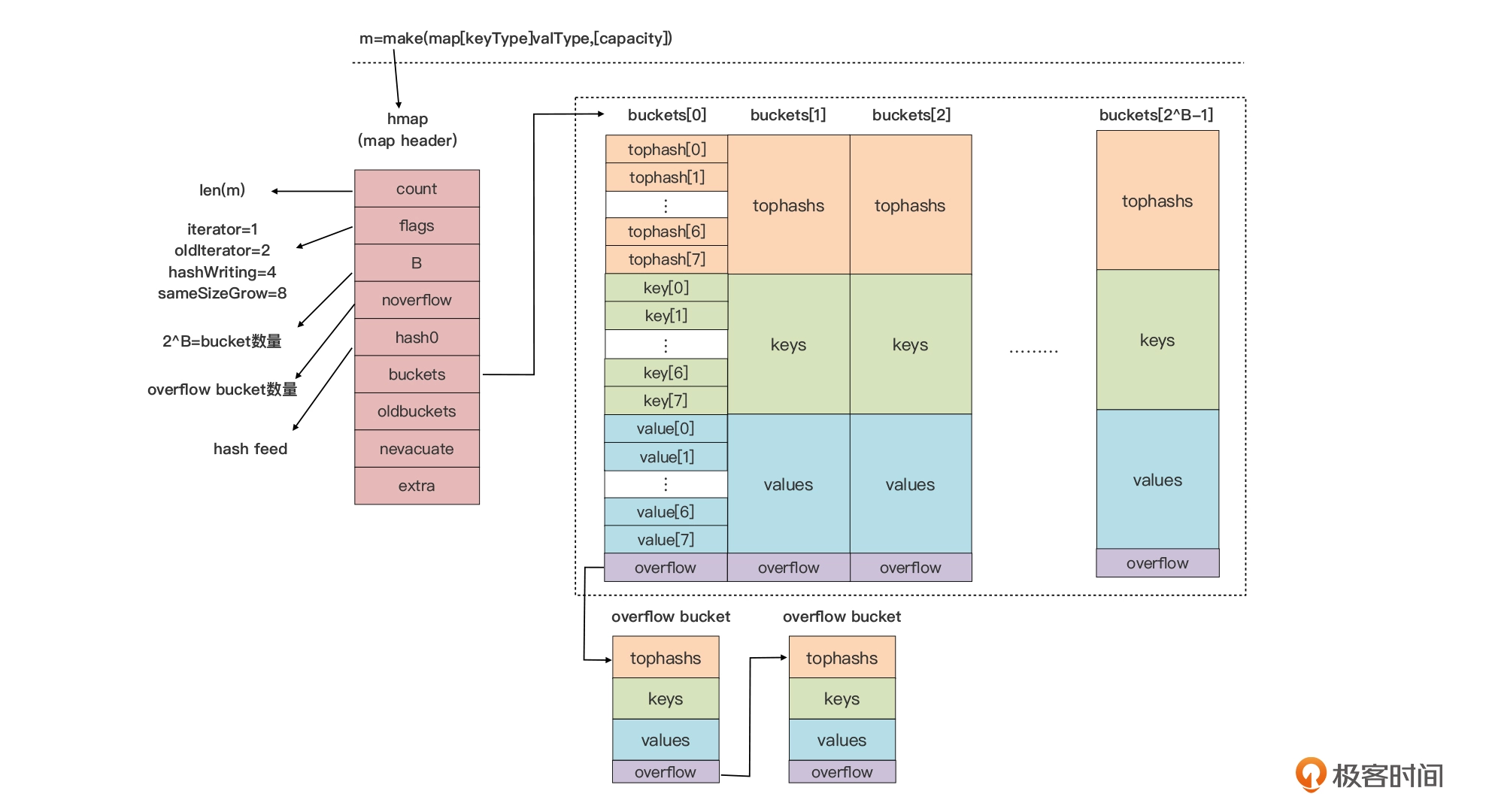
初始状态
与语法层面 map 类型变量(m)一一对应的是 *runtime.hmap 的实例,即 runtime.hmap 类型的指针,也就是我们前面在讲解 map 类型变量传递开销时提到的 map 类型的描述符。hmap 类型是 map 类型的头部结构(header),它存储了后续 map 类型操作所需的所有信息
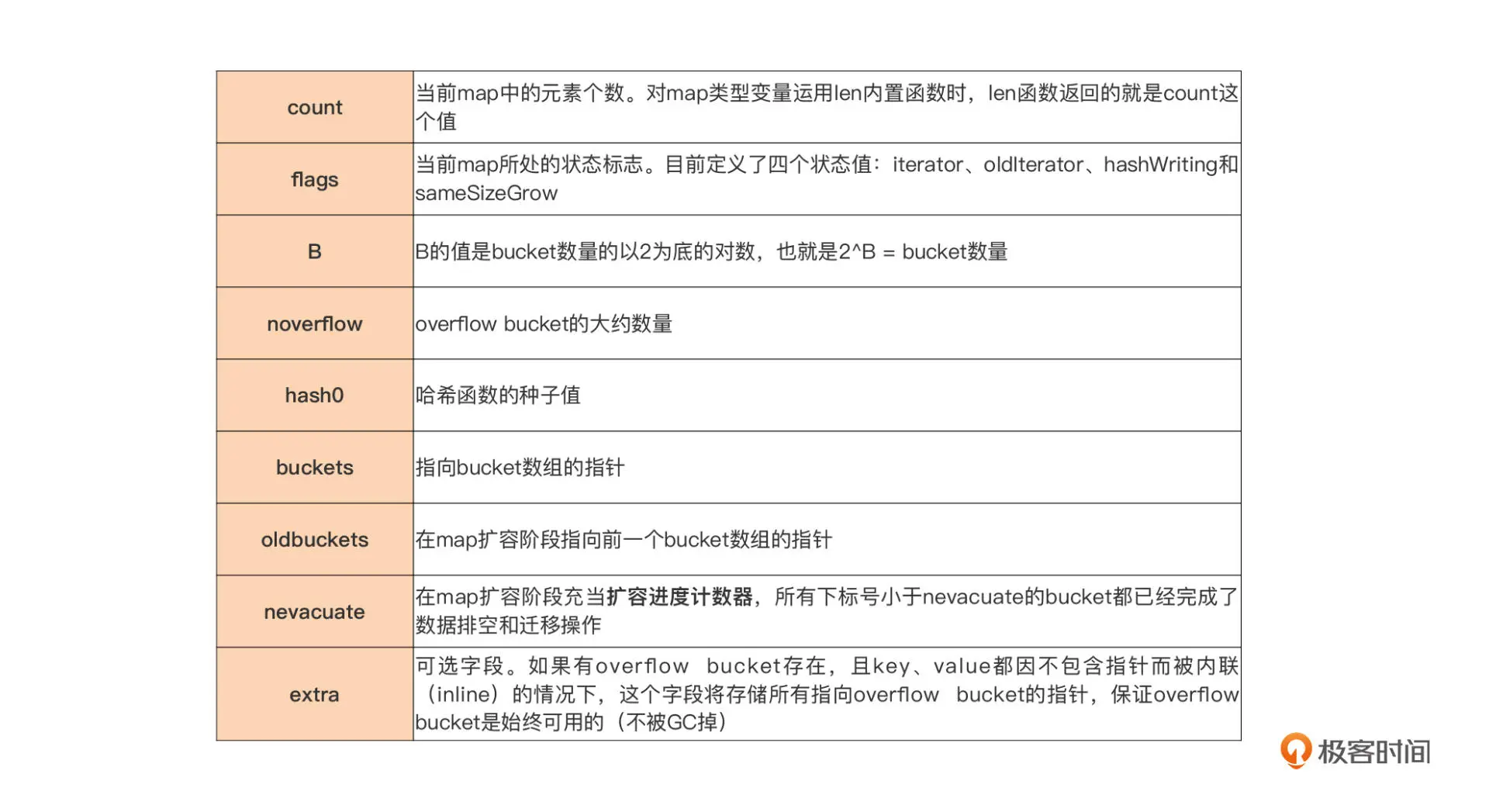
真正用来存储键值对数据的是桶,也就是 bucket,每个 bucket 中存储的是 Hash 值低 bit 位数值相同的元素,默认的元素个数为 BUCKETSIZE
当某个 bucket(比如 buckets[0]) 的 8 个空槽 slot)都填满了,且 map 尚未达到扩容的条件的情况下,运行时会建立 overflow bucket,并将这个 overflow bucket 挂在上面 bucket(如 buckets[0])末尾的 overflow 指针上,这样两个 buckets 形成了一个链表结构,直到下一次 map 扩容之前,这个结构都会一直存在。
- tophash 区域
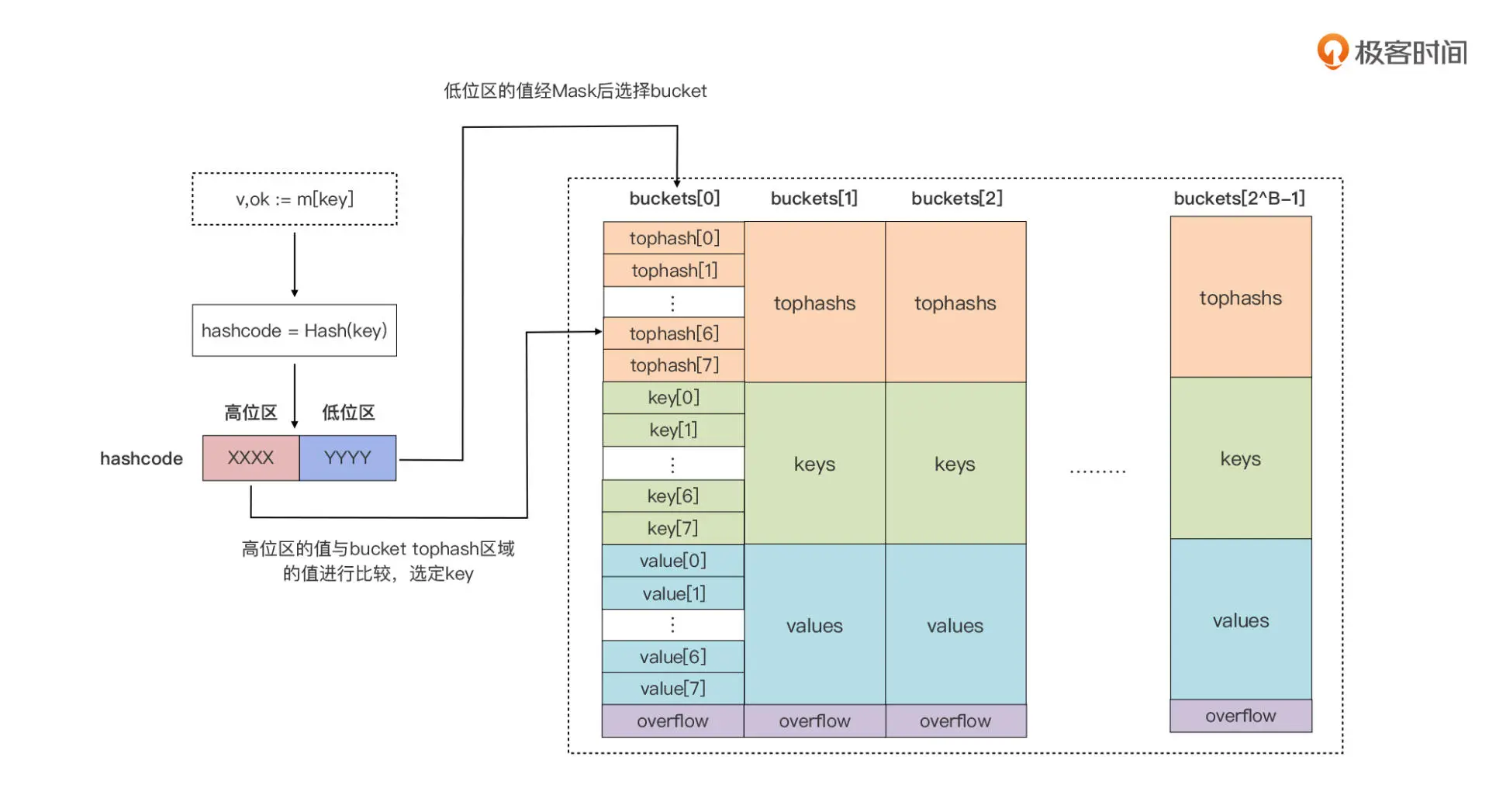
当我们向 map 插入一条数据,或者是从 map 按 key 查询数据的时候,运行时都会使用哈希函数对 key 做哈希运算,并获得一个哈希值(hashcode)。这个 hashcode 非常关键,运行时会把 hashcode“一分为二”来看待,其中低位区的值用于选定 bucket,高位区的值用于在某个 bucket 中确定 key 的位置。
因此,每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。
- key 存储区域
我们看 tophash 区域下面是一块连续的内存区域,存储的是这个 bucket 承载的所有 key 数据。运行时在分配 bucket 的时候需要知道 key 的 Size。那么运行时是如何知道 key 的 size 的呢?
当我们声明一个 map 类型变量,比如 var m map[string]int 时,Go 运行时就会为这个变量对应的特定 map 类型,生成一个 runtime.maptype 实例。如果这个实例已经存在,就会直接复用。maptype 实例的结构是这样的:
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}
我们可以看到,这个实例包含了我们需要的 map 类型中的所有"元信息"。我们前面提到过,编译器会把语法层面的 map 操作重写成运行时对应的函数调用,这些运行时函数都有一个共同的特点,那就是第一个参数都是 maptype 指针类型的参数。
Go 运行时就是利用 maptype 参数中的信息确定 key 的类型和大小的。map 所用的 hash 函数也存放在 maptype.key.alg.hash(key, hmap.hash0) 中。同时 maptype 的存在也让 Go 中所有 map 类型都共享一套运行时 map 操作函数,而不是像 C++ 那样为每种 map 类型创建一套 map 操作函数,这样就节省了对最终二进制文件空间的占用。
- value 存储区域
这个区域存储的是 key 对应的 value。和 key 一样,这个区域的创建也是得到了 maptype 中信息的帮助。Go 运行时采用了把 key 和 value 分开存储的方式,而不是采用一个 kv 接着一个 kv 的 kv 紧邻方式存储,这带来的其实是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。
我们以 map[int8]int64 为例,看看下面的存储空间利用率对比图:

你会看到,当前 Go 运行时使用的方案内存利用效率很高,而 kv 紧邻存储的方案在 map[int8]int64 这样的例子中内存浪费十分严重,它的内存利用率是 72/128=56.25%,有近一半的空间都浪费掉了。
另外,还有一点我要跟你强调一下,如果 key 或 value 的数据长度大于一定数值,那么运行时不会在 bucket 中直接存储数据,而是会存储 key 或 value 数据的指针。目前 Go 运行时定义的最大 key 和 value 的长度是这样的:
// $GOROOT/src/runtime/map.go
const (
maxKeySize = 128
maxElemSize = 128
)
map 扩容
Go 运行时的 map 实现中引入了一个 LoadFactor(负载因子),当 count > LoadFactor * 2^B 或 overflow bucket 过多时,运行时会自动对 map 进行扩容。目前 Go 最新 1.17 版本 LoadFactor 设置为 6.5
这两方面原因导致的扩容,在运行时的操作其实是不一样的。
-
如果是因为 overflow bucket 过多导致的“扩容”,实际上运行时会新建一个和现有规模一样的 bucket 数组,然后在 assign 和 delete 时做排空和迁移。
-
如果是因为当前数据数量超出 LoadFactor 指定水位而进行的扩容,那么运行时会建立一个两倍于现有规模的 bucket 数组,但真正的排空和迁移工作也是在 assign 和 delete 时逐步进行的
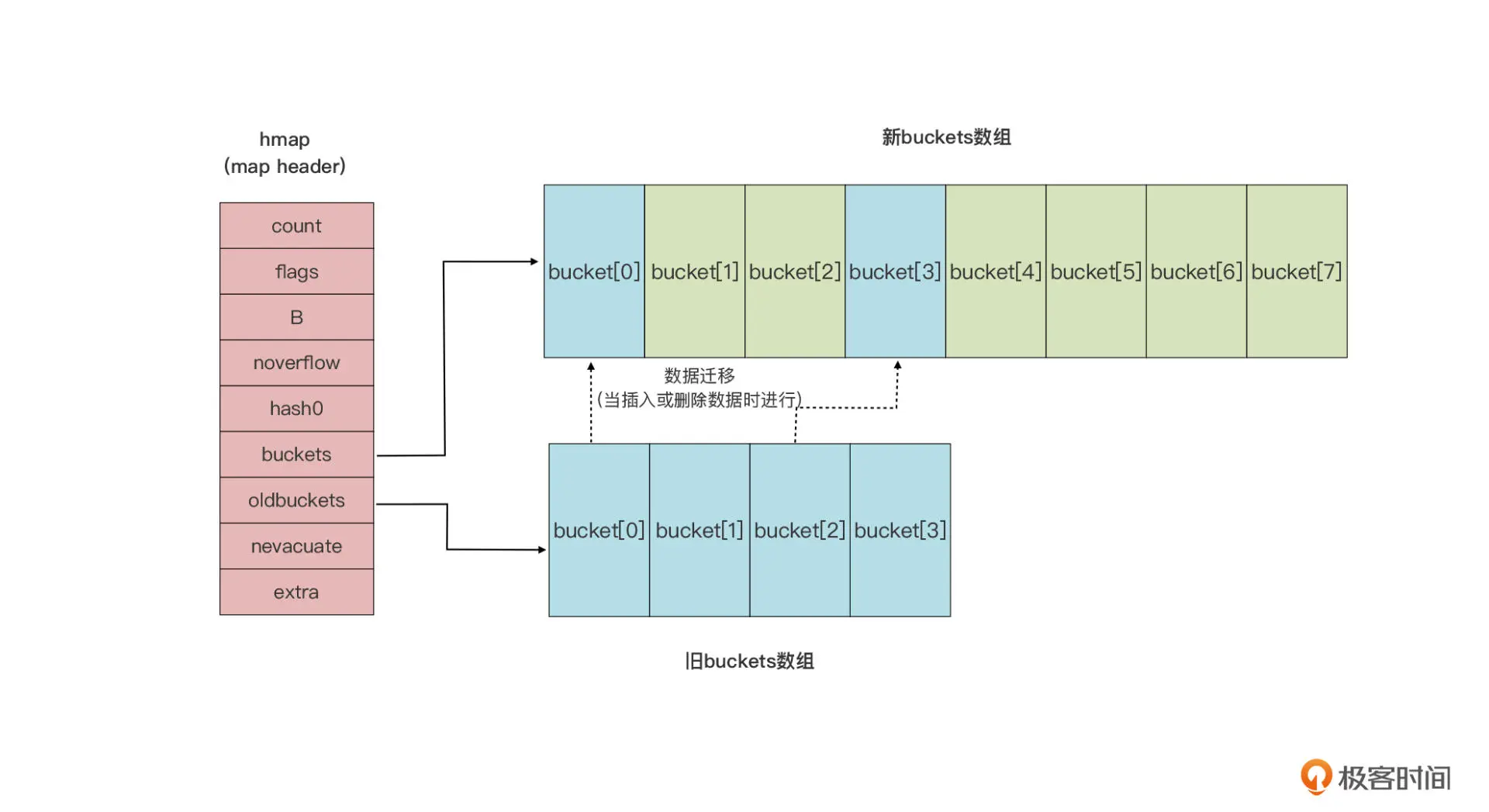
原 bucket 数组会挂在 hmap 的 oldbuckets 指针下面,直到原 buckets 数组中所有数据都迁移到新数组后,原 buckets 数组才会被释放。
map 与并发
接着我们来看一下 map 和并发。从上面的实现原理来看,充当 map 描述符角色的 hmap 实例自身是有状态的(hmap.flags),而且对状态的读写是没有并发保护的。所以说 map 实例不是并发写安全的,也不支持并发读写。
不过,如果我们仅仅是进行并发读,map 是没有问题的。而且,Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型,可以在并发读写的场景下替换掉 map。
考虑到 map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的。下面这段代码就展示了 Go 编译器识别出获取 map 中 value 地址的语句后,给出的编译错误:
符合数据类型:结构体
内存布局
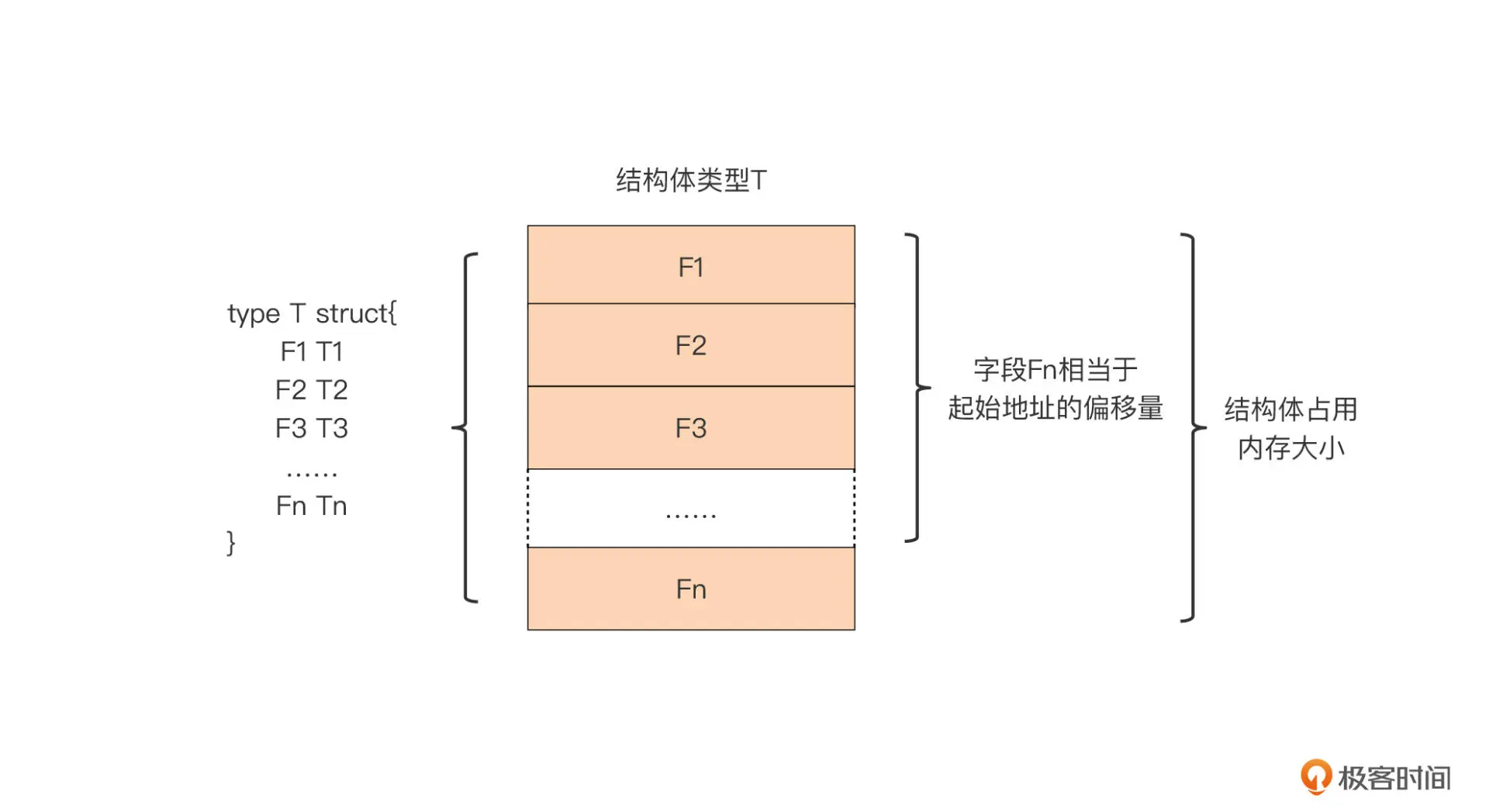
结构体类型 T 在内存中布局是非常紧凑的,Go 为它分配的内存都用来存储字段了,没有被 Go 编译器插入的额外字段。我们可以借助标准库 unsafe 包提供的函数,获得结构体类型变量占用的内存大小,以及它每个字段在内存中相对于结构体变量起始地址的偏移量:
var t T
unsafe.Sizeof(t) // 结构体类型变量占用的内存大小
unsafe.Offsetof(t.Fn) // 字段Fn在内存中相对于变量t起始地址的偏移量
不过,上面这张示意图是比较理想的状态,真实的情况可能就没那么好了:
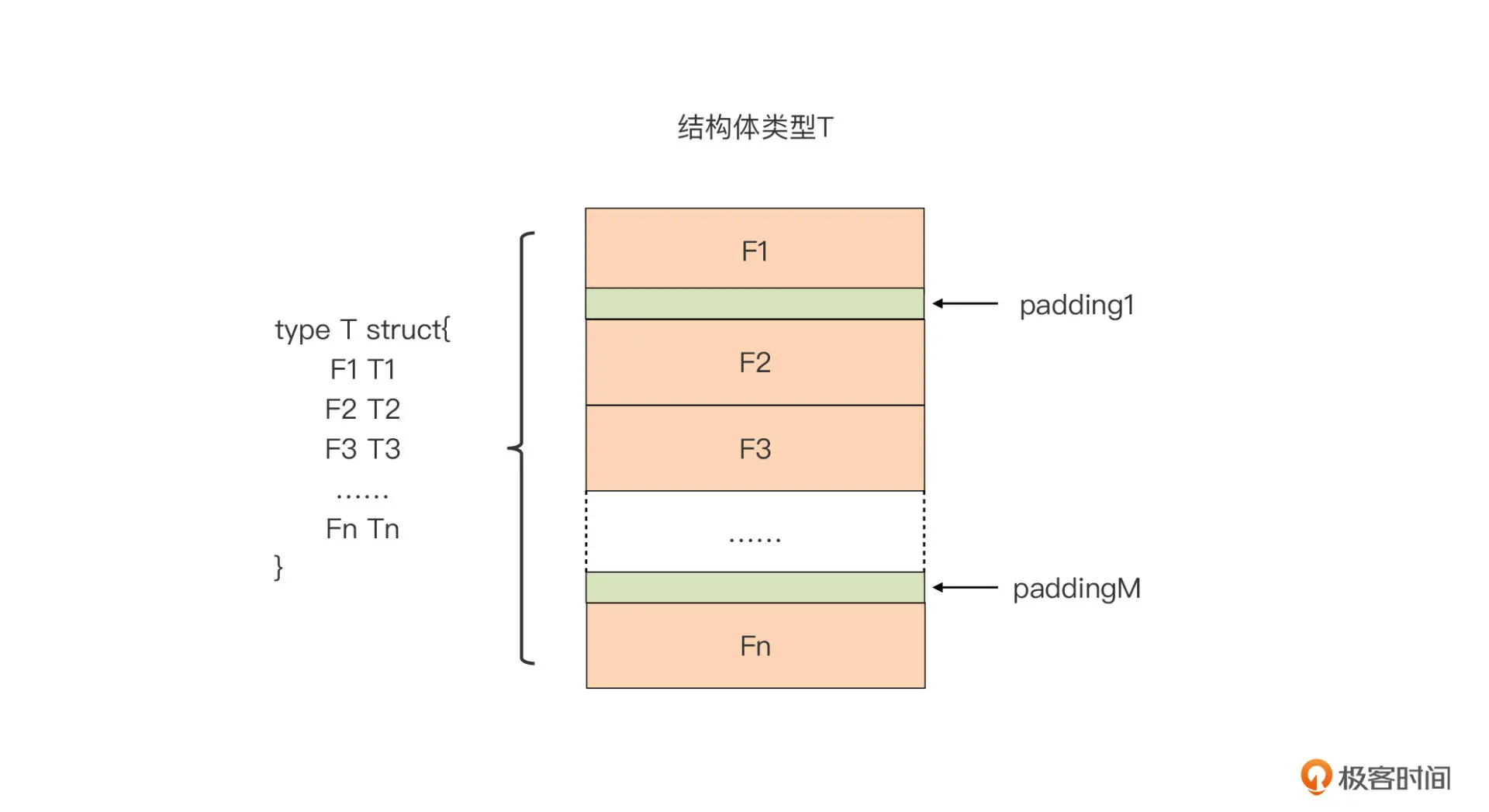
在真实情况下,虽然 Go 编译器没有在结构体变量占用的内存空间中插入额外字段,但结构体字段实际上可能并不是紧密相连的,中间可能存在“缝隙”。这些“缝隙”同样是结构体变量占用的内存空间的一部分,它们是 Go 编译器插入的“填充物(Padding)”。
Go 编译器为什么要在结构体的字段间插入“填充物”呢?这其实是内存对齐的要求。所谓内存对齐,指的就是各种内存对象的内存地址不是随意确定的,必须满足特定要求。
对于各种基本数据类型来说,它的变量的内存地址值必须是其类型本身大小的整数倍,比如,一个 int64 类型的变量的内存地址,应该能被 int64 类型自身的大小,也就是 8 整除;一个 uint16 类型的变量的内存地址,应该能被 uint16 类型自身的大小,也就是 2 整除。
对于结构体而言,它的变量的内存地址,只要是它最长字段长度与系统对齐系数两者之间较小的那个的整数倍就可以了。但对于结构体类型来说,我们还要让它每个字段的内存地址都严格满足内存对齐要求。
一个结构体类型 T 的对齐系数 demo
type T struct {
b byte
i int64
u uint16
}
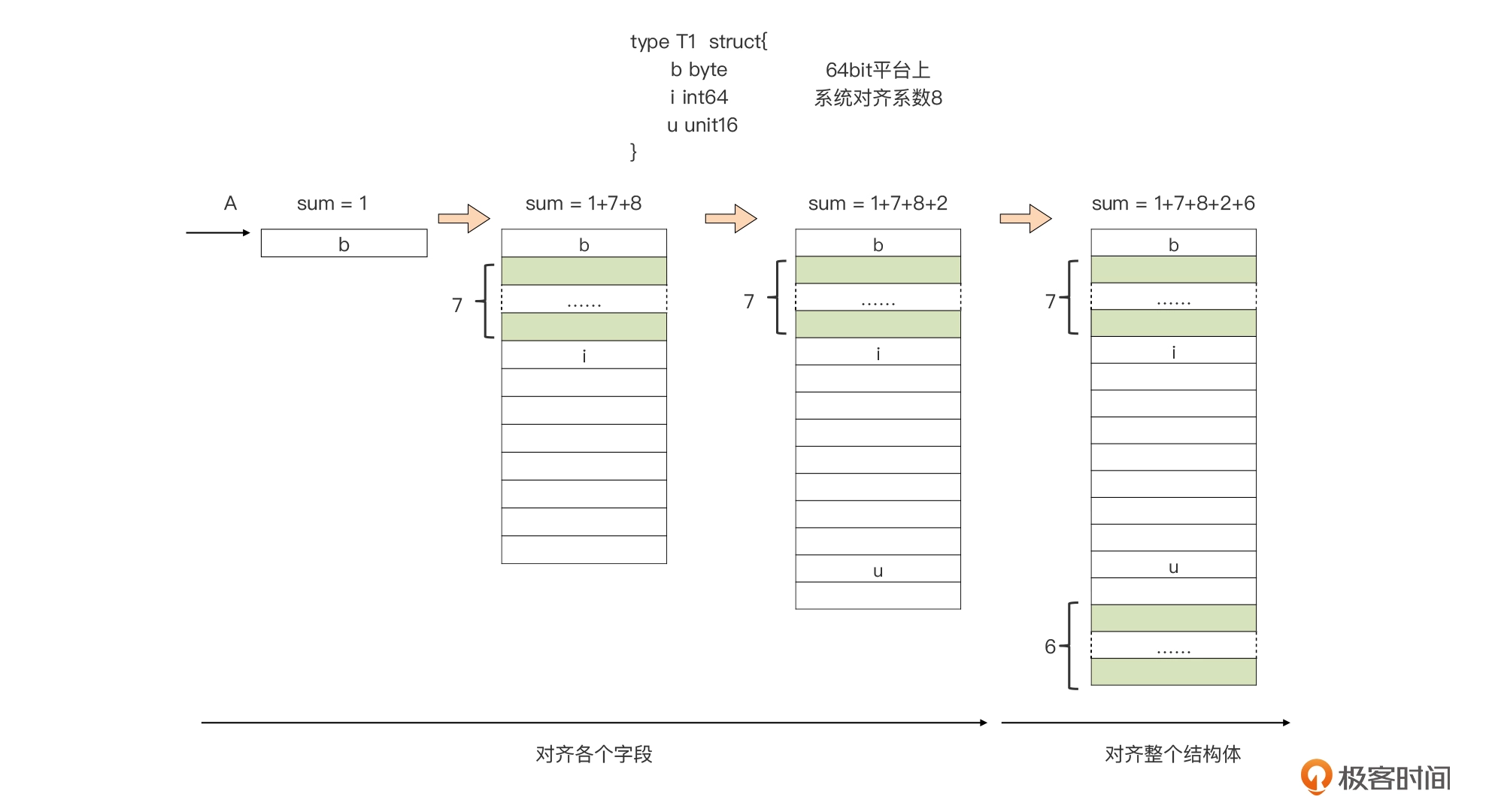
- 第一个阶段是对齐结构体的各个字段
我们看第一个字段 b 是长度 1 个字节的 byte 类型变量,这样字段 b 放在任意地址上都可以被 1 整除,所以我们说它是天生对齐的。
按照内存对齐要求,它应该被放在可以被 8 整除的地址上。但是,如果把 i 紧邻 b 进行分配,当 i 的地址可以被 8 整除时,b 的地址就无法被 8 整除。这个时候,我们需要在 b 与 i 之间做一些填充,使得 i 的地址可以被 8 整除时,b 的地址也始终可以被 8 整除,于是我们在 i 与 b 之间填充了 7 个字节,此时此刻 sum=1+7+8;
再下来,我们看第三个字段 u,它是一个长度为 2 个字节的 uint16 类型变量,按照内存对其要求,它应该被放在可以被 2 整除的地址上。有了对其的 i 作为基础,我们现在知道将 u 与 i 相邻而放,是可以满足其地址的对齐要求的。i 之后的那个字节的地址肯定可以被 8 整除,也一定可以被 2 整除。于是我们把 u 直接放在 i 的后面,中间不需要填充,此时此刻,sum=1+7+8+2。
- 我们开始第二个阶段,也就是对齐整个结构体。
结构体的内存地址为 min(结构体最长字段的长度,系统内存对齐系数)的整数倍,那么这里结构体 T 最长字段为 i,它的长度为 8,而 64bit 系统上的系统内存对齐系数一般为 8,两者相同,我们取 8 就可以了。那么整个结构体的对齐系数就是 8。
为什么上面的示意图还要在结构体的尾部填充了 6 个字节呢?如果考虑我们分配的是一个元素为 T 类型的数组,比如下面这行代码,我们虽然可以保证 T[0]这个元素地址可以被 8 整除,但能保证 T[1]的地址也可以被 8 整除吗?
var array [10]T
我们知道,数组是元素连续存储的一种类型,元素 T[1]的地址为 T[0]地址 +T 的大小 (18),显然无法被 8 整除,这将导致 T[1]及后续元素的地址都无法对齐,这显然不能满足内存对齐的要求。
问题的根源在哪里呢?问题就在于 T 的当前大小为 18,这是一个不能被 8 整除的数值,如果 T 的大小可以被 8 整除,那问题就解决了。于是我们才有了最后一个步骤,我们从 18 开始向后找到第一个可以被 8 整除的数字,也就是将 18 圆整到 8 的倍数上,我们得到 24,我们将 24 作为类型 T 最终的大小就可以了。
为什么会出现内存对齐的要求呢?这是出于对处理器存取数据效率的考虑。在早期的一些处理器中,比如 Sun 公司的 Sparc 处理器仅支持内存对齐的地址,如果它遇到没有对齐的内存地址,会引发段错误,导致程序崩溃。我们常见的 x86-64 架构处理器虽然处理未对齐的内存地址不会出现段错误,但数据的存取性能也会受到影响。
控制结构:Go的for循环,仅此一种
for 语句的常见“坑”与避坑方法
问题一:循环变量的重用
func main() {
var m = []int{1, 2, 3, 4, 5}
for i, v := range m {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}()
}
time.Sleep(time.Second * 10)
}
我们实际运行输出一下:
4 5
4 5
4 5
4 5
4 5
事实上,这些循环变量在 for range 语句中仅会被声明一次,且在每次迭代中都会被重用。
那么如何修改代码,可以让实际输出和我们最初的预期输出一致呢?我们可以为闭包函数增加参数,并且在创建 Goroutine 时将参数与 i、v 的当时值进行绑定,看下面的修正代码:
func main() {
var m = []int{1, 2, 3, 4, 5}
for i, v := range m {
go func(i, v int) {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}(i, v)
}
time.Sleep(time.Second * 10)
}
问题二:参与循环的是 range 表达式的副本
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
fmt.Println("original a =", a)
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("after for range loop, r =", r)
fmt.Println("after for range loop, a =", a)
}
实际运行该程序的输出结果却是:
original a = [1 2 3 4 5]
after for range loop, r = [1 2 3 4 5]
after for range loop, a = [1 12 13 4 5]
为什么会是这种情况呢?原因就是参与 for range 循环的是 range 表达式的副本。也就是说,在上面这个例子中,真正参与循环的是 a 的副本,而不是真正的 a。
那么应该如何解决这个问题,让输出结果符合我们前面的预期呢?我们前面说过,在 Go 中,大多数应用数组的场景我们都可以用切片替代
切片在 Go 内部表示为一个结构体,由(array, len, cap)组成,其中 array 是指向切片对应的底层数组的指针,len 是切片当前长度,cap 为切片的最大容量。所以,当进行 range 表达式复制时,我们实际上复制的是一个切片,也就是表示切片的结构体。表示切片副本的结构体中的 array,依旧指向原切片对应的底层数组,所以我们对切片副本的修改也都会反映到底层数组 a 上去。而 v 再从切片副本结构体中 array 指向的底层数组中,获取数组元素,也就得到了被修改后的元素值。
问题三:遍历 map 中元素的随机性
如果我们在循环的过程中,对 map 进行了修改,那么这样修改的结果是否会影响后续迭代呢?这个结果和我们遍历 map 一样,具有随机性。
所以遍历过程做修改的话最好是用一个新的 map 存储修改后的结果。
函数:怎么让函数更简洁健壮?
健壮性的“三不要”原则
- 原则一:不要相信任何外部输入的参数。
- 原则二:不要忽略任何一个错误。
- 原则三:不要假定异常不会发生。
认识 Go 语言中的异常:panic
发生 panic 不处理会直接退出进程
func bar() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recover the panic:", e)
}
}()
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
使用 defer 简化函数实现
defer 是 Go 语言提供的一种延迟调用机制,defer 的运作离不开函数。怎么理解呢?这句话至少有以下两点含义:
- 在 Go 中,只有在函数(和方法)内部才能使用 defer;
- defer 关键字后面只能接函数(或方法),这些函数被称为 deferred 函数。

无论是执行到函数体尾部返回,还是在某个错误处理分支显式 return,又或是出现 panic,已经存储到 deferred 函数栈中的函数,都会被调度执行。所以说,deferred 函数是一个可以在任何情况下为函数进行收尾工作的好“伙伴”。
defer 使用的几个注意事项
对于自定义的函数或方法,defer 可以给与无条件的支持,但是对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃。
而且,Go 语言中除了自定义函数 / 方法,还有 Go 语言内置的 / 预定义的函数,这里我给出了 Go 语言内置函数的完全列表:
Functions:
append cap close complex copy delete imag len
make new panic print println real recover
append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等内置函数则可以直接被 defer 设置为 deferred 函数。
不过,对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求,以 append 为例是这样的:
defer func() {
_ = append(sl, 11)
}()
第二点:注意 defer 关键字后面表达式的求值时机
defer 关键字后面的表达式,是在将 deferred 函数注册到 deferred 函数栈的时候进行求值的。
func foo1() {
for i := 0; i <= 3; i++ {
defer fmt.Println(i)
}
}
//压栈内容
//fmt.Println(0)
//fmt.Println(1)
//fmt.Println(2)
//fmt.Println(3)
func foo2() {
for i := 0; i <= 3; i++ {
defer func(n int) {
fmt.Println(n)
}(i)
}
}
//压栈内容
//func(0)
//func(1)
//func(2)
//func(3)
func foo3() {
for i := 0; i <= 3; i++ {
defer func() {
fmt.Println(i)
}()
}
}
//压栈内容
//func()
//func()
//func()
//func()
//输出
//4
//4
//4
//4
func main() {
fmt.Println("foo1 result:")
foo1()
fmt.Println("\nfoo2 result:")
foo2()
fmt.Println("\nfoo3 result:")
foo3()
}
第三点:知晓 defer 带来的性能损耗
从 Go 1.13 版本开始,Go 核心团队对 defer 性能进行了多次优化,到现在的 Go 1.17 版本,defer 的开销已经足够小了。我们看看使用 Go 1.17 版本运行上述基准测试的结果:
$go test -bench . defer_test.go
goos: darwin
goarch: amd64
BenchmarkFooWithDefer-8 194593353 6.183 ns/op
BenchmarkFooWithoutDefer-8 284272650 4.259 ns/op
PASS
ok command-line-arguments 3.472s
我们看到,带有 defer 的函数执行开销,仅是不带有 defer 的函数的执行开销的 1.45 倍左右,已经达到了几乎可以忽略不计的程度,我们可以放心使用。
方法:理解“方法”的本质
认识 Go 方法

Go 语言对 receiver 参数的基类型也有约束,那就是 receiver 参数的基类型本身不能为指针类型或接口类型。
type MyInt *int
func (r MyInt) String() string { // r的基类型为MyInt,编译器报错:invalid receiver type MyInt (MyInt is a pointer type)
return fmt.Sprintf("%d", *(*int)(r))
}
type MyReader io.Reader
func (r MyReader) Read(p []byte) (int, error) { // r的基类型为MyReader,编译器报错:invalid receiver type MyReader (MyReader is an interface type)
return r.Read(p)
}
Go 对方法声明的位置也是有约束的,Go 要求,方法声明要与 receiver 参数的基类型声明放在同一个包内。基于这个约束,我们还可以得到两个推论。
- 第一个推论:我们不能为原生类型(诸如 int、float64、map 等)添加方法。
- 第二个推论:不能跨越 Go 包为其他包的类型声明新方法。比如,下面的代码试图跨越包边界,为 Go 标准库中的 http.Server 类型添加新方法 Foo,这样做,Go 编译器同样会报错:
方法的本质是什么?
type T struct {
a int
}
func (t T) Get() int {
return t.a
}
func (t *T) Set(a int) int {
t.a = a
return t.a
}
你大约会知道,C++ 中的对象在调用方法时,编译器会自动传入指向对象自身的 this 指针作为方法的第一个参数。而 Go 方法中的原理也是相似的,只不过我们是将 receiver 参数以第一个参数的身份并入到方法的参数列表中。按照这个原理,我们示例中的类型 T 和 *T 的方法,就可以分别等价转换为下面的普通函数:
// 类型T的方法Get的等价函数
func Get(t T) int {
return t.a
}
// 类型*T的方法Set的等价函数
func Set(t *T, a int) int {
t.a = a
return t.a
}
这种等价转换后的函数的类型就是方法的类型。只不过在 Go 语言中,这种等价转换是由 Go 编译器在编译和生成代码时自动完成的。Go 语言规范中还提供了方法表达式(Method Expression)的概念,可以让我们更充分地理解上面的等价转换,我们来看一下。
var t T
t.Get()
(&t).Set(1)
我们可以用另一种方式,把上面的方法调用做一个等价替换:
var t T
T.Get(t)
(*T).Set(&t, 1)
这种直接以类型名 T 调用方法的表达方式,被称为 Method Expression。通过 Method Expression 这种形式,类型 T 只能调用 T 的方法集合(Method Set)中的方法,同理类型 *T 也只能调用 *T 的方法集合中的方法。
巧解难题
package main
import (
"fmt"
"time"
)
type field struct {
name string
}
func (p *field) print() {
fmt.Println(p.name)
}
func main() {
data1 := []*field{{"one"}, {"two"}, {"three"}}
for _, v := range data1 {
go v.print()
}
data2 := []field{{"four"}, {"five"}, {"six"}}
for _, v := range data2 {
go v.print()
}
time.Sleep(3 * time.Second)
}
这段代码在我的多核 macOS 上的运行结果是这样
one
two
three
six
six
six
为什么对 data2 迭代输出的结果是三个“six”,而不是 four、five、six?
首先,我们根据 Go 方法的本质,也就是一个以方法的 receiver 参数作为第一个参数的普通函数,对这个程序做个等价变换。这里我们利用 Method Expression 方式,等价变换后的源码如下:
type field struct {
name string
}
func (p *field) print() {
fmt.Println(p.name)
}
func main() {
data1 := []*field{{"one"}, {"two"}, {"three"}}
for _, v := range data1 {
go (*field).print(v)
}
data2 := []field{{"four"}, {"five"}, {"six"}}
for _, v := range data2 {
go (*field).print(&v)
}
time.Sleep(3 * time.Second)
}
可以明显得出结论,v 是复用的,所以取地址,其实拿的都是同一个地址,如果 go 协程在 main 协程跑到 sleep 之后执行,那就都是6。
改动可以将 field 类型 print 方法的 receiver 类型由 *field 改为 field 就可以了,这样子就会利用函数形参值传递的方式进行 cp,可以解决这个问题。
方法:方法集合与如何选择receiver类型?
receiver 参数类型对 Go 方法的影响
func (t T) M1() <=> F1(t T)
func (t *T) M2() <=> F2(t *T)
-
首先,当 receiver 参数的类型为 T 时:当我们选择以 T 作为 receiver 参数类型时,M1 方法等价转换为 F1(t T)。我们知道,Go 函数的参数采用的是值拷贝传递,也就是说,F1 函数体中的 t 是 T 类型实例的一个副本。这样,我们在 F1 函数的实现中对参数 t 做任何修改,都只会影响副本,而不会影响到原 T 类型实例。
-
第二,当 receiver 参数的类型为 *T 时:当我们选择以 *T 作为 receiver 参数类型时,M2 方法等价转换为 F2(t *T)。同上面分析,我们传递给 F2 函数的 t 是 T 类型实例的地址,这样 F2 函数体中对参数 t 做的任何修改,都会反映到原 T 类型实例上。
选择 receiver 参数类型原则
- 原则一
如果 Go 方法要把对 receiver 参数代表的类型实例的修改,反映到原类型实例上,那么我们应该选择 *T 作为 receiver 参数的类型。
PS:无论是 T 类型实例,还是 *T 类型实例,都既可以调用 receiver 为 T 类型的方法,也可以调用 receiver 为 *T 类型的方法。
- 原则二
一般情况下,我们通常会为 receiver 参数选择 T 类型,因为这样可以缩窄外部修改类型实例内部状态的“接触面”,也就是尽量少暴露可以修改类型内部状态的方法。
考虑到 Go 方法调用时,receiver 参数是以值拷贝的形式传入方法中的。那么,如果 receiver 参数类型的 size 较大,以值拷贝形式传入就会导致较大的性能开销,这时我们选择 *T 作为 receiver 类型可能更好些。
- 原则三
这个原则的选择依据就是 T 类型是否需要实现某个接口,也就是是否存在将 T 类型的变量赋值给某接口类型变量的情况。
如果 T 类型需要实现某个接口,那我们就要使用 T 作为 receiver 参数的类型,来满足接口类型方法集合中的所有方法。如果 T 不需要实现某一接口,但 T 需要实现该接口,那么根据方法集合概念,T 的方法集合是包含 T 的方法集合的,这样我们在确定 Go 方法的 receiver 的类型时,参考原则一和原则二就可以了。
方法集合
type Interface interface {
M1()
M2()
}
type T struct{}
func (t T) M1() {}
func (t *T) M2() {}
func main() {
var t T
var pt *T
var i Interface
i = pt
i = t // cannot use t (type T) as type Interface in assignment: T does not implement Interface (M2 method has pointer receiver)
}
Go 中任何一个类型都有属于自己的方法集合,或者说方法集合是 Go 类型的一个“属性”。但不是所有类型都有自己的方法呀,比如 int 类型就没有。所以,对于没有定义方法的 Go 类型,我们称其拥有空方法集合。
Go 语言规定,*T 类型的方法集合包含所有以 *T 为 receiver 参数类型的方法,以及所有以 T 为 receiver 参数类型的方法。
接口:为什么nil接口不等于nil?
接口的静态特性与动态特性
接口的静态特性体现在接口类型变量具有静态类型,比如 var err error 中变量 err 的静态类型为 error。拥有静态类型,那就意味着编译器会在编译阶段对所有接口类型变量的赋值操作进行类型检查,编译器会检查右值的类型是否实现了该接口方法集合中的所有方法。如果不满足,就会报错
var err error = 1 // cannot use 1 (type int) as type error in assignment: int does not implement error (missing Error method)
接口的动态特性,就体现在接口类型变量在运行时还存储了右值的真实类型信息,这个右值的真实类型被称为接口类型变量的动态类型。
var err error
err = errors.New("error1")
fmt.Printf("%T\n", err) // *errors.errorString
nil error 值 != nil
type MyError struct {
error
}
var ErrBad = MyError{
error: errors.New("bad things happened"),
}
func bad() bool {
return false
}
func returnsError() error {
var p *MyError = nil
if bad() {
p = &ErrBad
}
return p
}
func main() {
err := returnsError()
if err != nil {
fmt.Printf("error occur: %+v\n", err)
return
}
fmt.Println("ok")
}
真实的运行结果是什么样的呢?我们来看一下:
error occur: <nil>
我们看到,示例程序并未如我们前面预期的那样输出 ok。程序显然是进入了错误处理分支,输出了 err 的值。那这里就有一个问题了:明明 returnsError 函数返回的 p 值为 nil,为什么却满足了 if err != nil 的条件进入错误处理分支呢?
接口类型变量的内部表示
// $GOROOT/src/runtime/runtime2.go
type iface struct {
tab *itab
data unsafe.Pointer
}
type eface struct {
_type *_type
data unsafe.Pointer
}
我们看到,在运行时层面,接口类型变量有两种内部表示:iface 和 eface,这两种表示分别用于不同的接口类型变量:
- eface 用于表示没有方法的空接口(empty interface)类型变量,也就是 interface{}类型的变量;
- iface 用于表示其余拥有方法的接口 interface 类型变量。
这两个结构的共同点是它们都有两个指针字段,并且第二个指针字段的功能相同,都是指向当前赋值给该接口类型变量的动态类型变量的值。
就在于 eface 表示的空接口类型并没有方法列表,因此它的第一个指针字段指向一个_type 类型结构,这个结构为该接口类型变量的动态类型的信息,它的定义是这样的:
// $GOROOT/src/runtime/type.go
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
而 iface 除了要存储动态类型信息之外,还要存储接口本身的信息(接口的类型信息、方法列表信息等)以及动态类型所实现的方法的信息,因此 iface 的第一个字段指向一个 itab 类型结构。itab 结构的定义如下:
// $GOROOT/src/runtime/runtime2.go
type itab struct {
inter *interfacetype
_type *_type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
这里我们也可以看到,itab 结构中的第一个字段 inter 指向的 interfacetype 结构,存储着这个接口类型自身的信息。你看一下下面这段代码表示的 interfacetype 类型定义, 这个 interfacetype 结构由类型信息(typ)、包路径名(pkgpath)和接口方法集合切片(mhdr)组成。
// $GOROOT/src/runtime/type.go
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
itab 结构中的字段_type 则存储着这个接口类型变量的动态类型的信息,字段 fun 则是动态类型已实现的接口方法的调用地址数组。
eface demo
type T struct {
n int
s string
}
func main() {
var t = T {
n: 17,
s: "hello, interface",
}
var ei interface{} = t // Go运行时使用eface结构表示ei
}
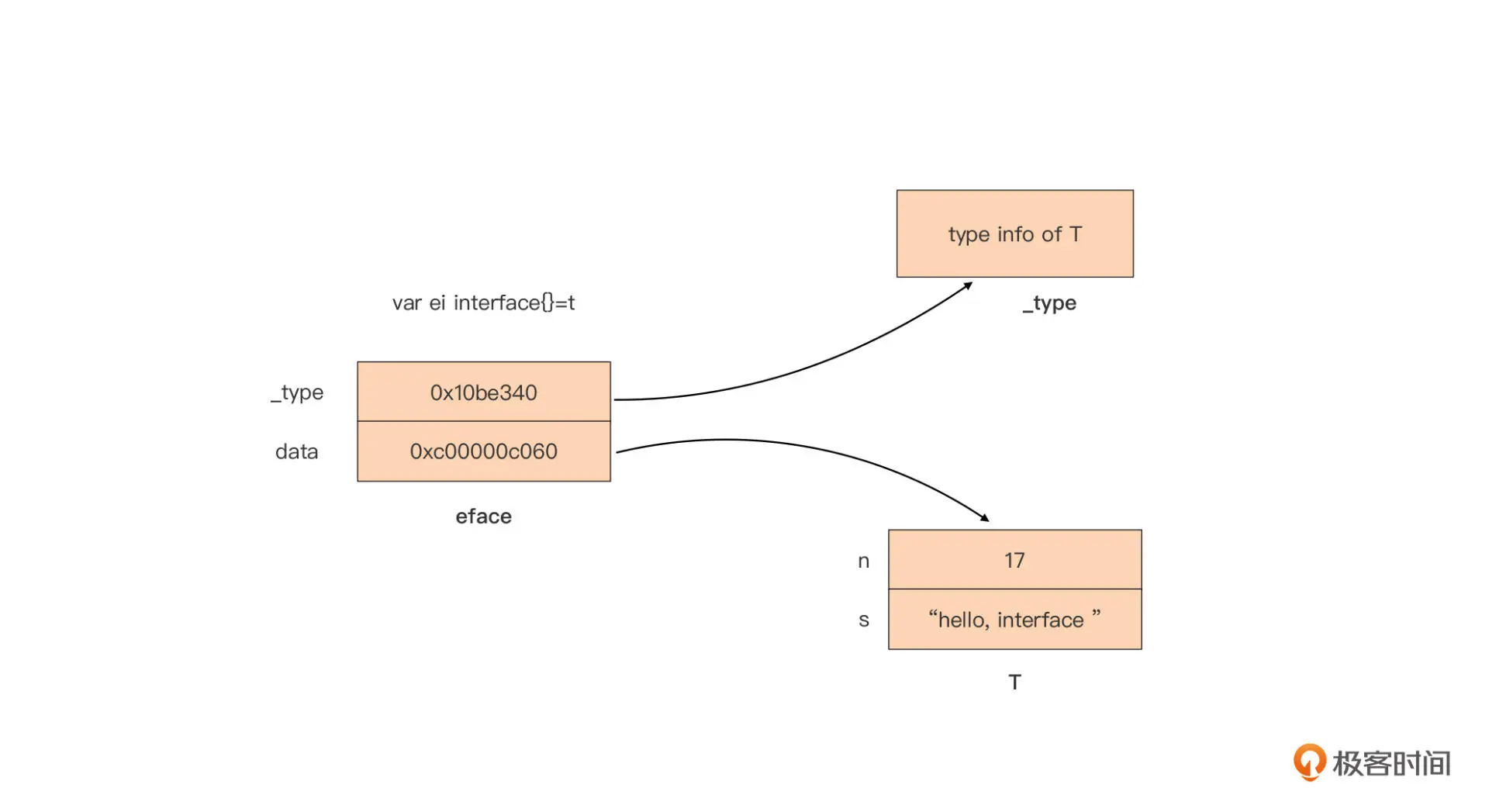
我们看到空接口类型的表示较为简单,图中上半部分 _type 字段指向它的动态类型 T 的类型信息,下半部分的 data 则是指向一个 T 类型的实例值。
iface demo
type T struct {
n int
s string
}
func (T) M1() {}
func (T) M2() {}
type NonEmptyInterface interface {
M1()
M2()
}
func main() {
var t = T{
n: 18,
s: "hello, interface",
}
var i NonEmptyInterface = t
}
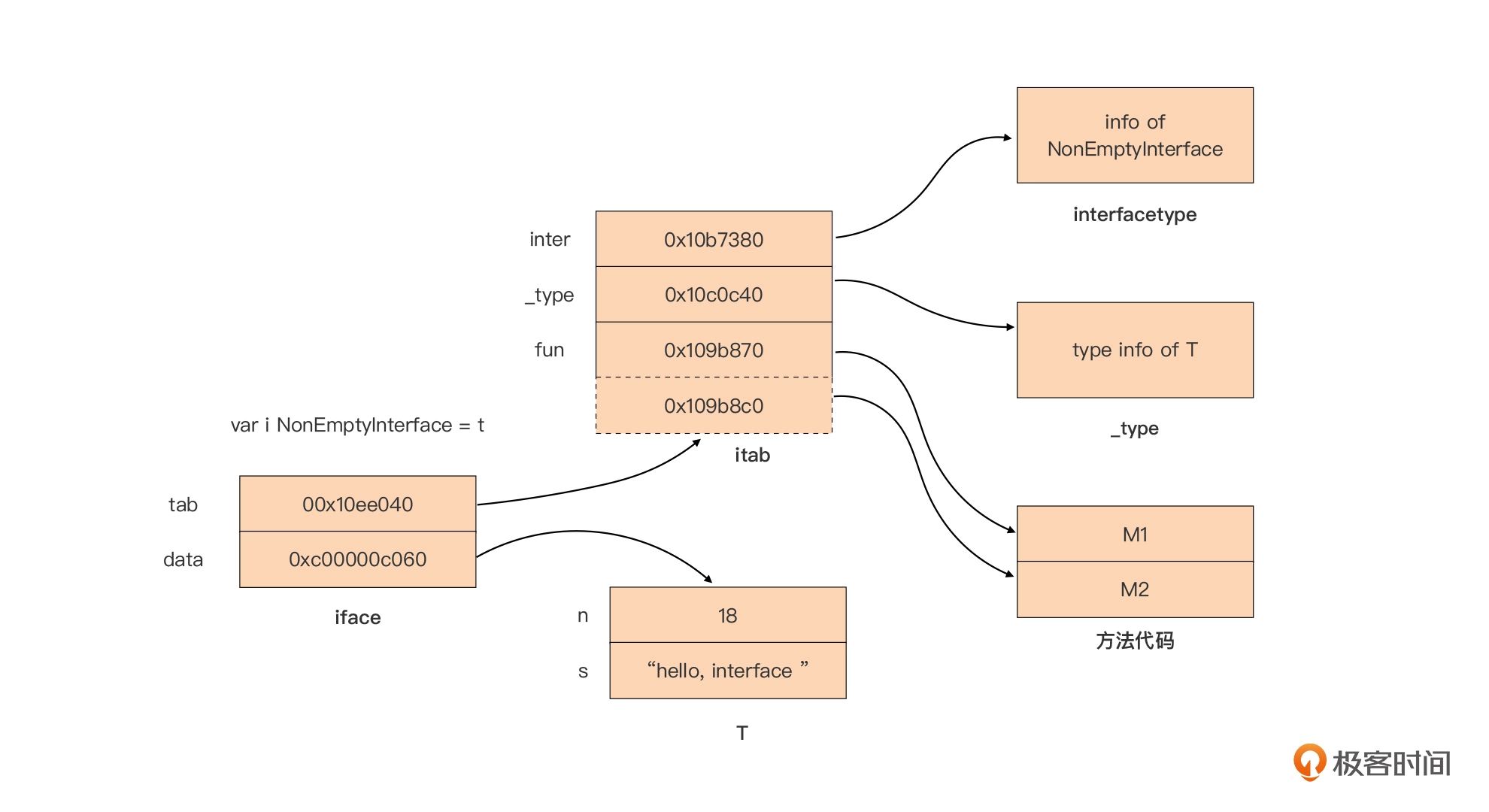
而且,虽然 eface 和 iface 的第一个字段有所差别,但 tab 和 _type 可以统一看作是动态类型的类型信息。Go 语言中每种类型都会有唯一的 _type 信息,无论是内置原生类型,还是自定义类型都有。Go 运行时会为程序内的全部类型建立只读的共享 _type 信息表,因此拥有相同动态类型的同类接口类型变量的 _type/tab 信息是相同的。而接口类型变量的 data 部分则是指向一个动态分配的内存空间,这个内存空间存储的是赋值给接口类型变量的动态类型变量的值。未显式初始化的接口类型变量的值为nil,也就是这个变量的 _type/tab 和 data 都为 nil。
也就是说,我们判断两个接口类型变量是否相等,只需判断 _type/tab 以及 data 是否都相等即可。两个接口变量的 _type/tab 不同时,即两个接口变量的动态类型不相同时,两个接口类型变量一定不等。
当两个接口变量的 _type/tab 相同时,对 data 的相等判断要有区分。当接口变量的动态类型为指针类型时 (*T),Go 不会再额外分配内存存储指针值,而会将动态类型的指针值直接存入 data 字段中,这样 data 值的相等性决定了两个接口类型变量是否相等;
当接口变量的动态类型为非指针类型 (T) 时,我们判断的将不是 data 指针的值是否相等,而是判断 data 指针指向的内存空间所存储的数据值是否相等,若相等,则两个接口类型变量相等。
- 第一种:nil 接口变量
无论是空接口类型还是非空接口类型变量,一旦变量值为 nil,那么它们内部表示均为(0x0,0x0),也就是类型信息、数据值信息均为空。因此上面的变量 i 和 err 等值判断为 true。
- 第二种:空接口类型变量
对于空接口类型变量,只有 _type 和 data 所指数据内容一致的情况下,两个空接口类型变量之间才能划等号。
- 第三种:非空接口类型变量
和空接口类型变量一样,只有 tab 和 data 指的数据内容一致的情况下,两个非空接口类型变量之间才能划等号。
- 第四种:空接口类型变量与非空接口类型变量的等值比较
空接口类型变量和非空接口类型变量内部表示的结构有所不同(第一个字段:_type vs. tab),两者似乎一定不能相等。但 Go 在进行等值比较时,类型比较使用的是 eface 的 _type 和 iface 的 tab._type,因此就像我们在这个例子中看到的那样,当 eif 和 err 都被赋值为 T(5)时,两者之间是划等号的。
接口类型的装箱(boxing)原理
在 Go 语言中,将任意类型赋值给一个接口类型变量也是装箱操作。有了前面对接口类型变量内部表示的学习,我们知道接口类型的装箱实际就是创建一个 eface 或 iface 的过程。接下来我们就来简要描述一下这个过程,也就是接口类型的装箱原理。
经过装箱后,箱内的数据,也就是存放在新分配的内存空间中的数据与原变量便无瓜葛了
func main() {
var n int = 61
var ei interface{} = n
n = 62 // n的值已经改变
fmt.Println("data in box:", ei) // 输出仍是61
}
不过,装箱是一个有性能损耗的操作,因此 Go 也在不断对装箱操作进行优化,包括对常见类型如整型、字符串、切片等提供系列快速转换函数:
// $GOROOT/src/runtime/iface.go
func convT16(val any) unsafe.Pointer // val must be uint16-like
func convT32(val any) unsafe.Pointer // val must be uint32-like
func convT64(val any) unsafe.Pointer // val must be uint64-like
func convTstring(val any) unsafe.Pointer // val must be a string
func convTslice(val any) unsafe.Pointer // val must be a slice
这些函数去除了 typedmemmove 操作,增加了零值快速返回等特性。同时 Go 建立了 staticuint64s 区域,对 255 以内的小整数值进行装箱操作时不再分配新内存,而是利用 staticuint64s 区域的内存空间,下面是 staticuint64s 的定义:
// $GOROOT/src/runtime/iface.go
// staticuint64s is used to avoid allocating in convTx for small integer values.
var staticuint64s = [...]uint64{
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07,
0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f,
... ...
}
接口:Go中最强大的魔法
一切皆组合
构建 Go 应用程序的静态骨架结构有两种主要的组合方式,如下图所示:

垂直组合
在实现层面,Go 语言通过类型嵌入(Type Embedding)实现垂直组合,
第一种:通过嵌入接口构建接口
// $GOROOT/src/io/io.go
type ReadWriter interface {
Reader
Writer
}
第二种:通过嵌入接口构建结构体类型
type MyReader struct {
io.Reader // underlying reader
N int64 // max bytes remaining
}
在结构体中嵌入接口,可以用于快速构建满足某一个接口的结构体类型,来满足某单元测试的需要,之后我们只需要实现少数需要的接口方法就可以了。尤其是将这样的结构体类型变量传递赋值给大接口的时候,就更能体现嵌入接口类型的优势了。
第三种:通过嵌入结构体类型构建新结构体类型
在结构体中嵌入接口类型名和在结构体中嵌入其他结构体,都是“委派模式(delegate)”的一种应用。对新结构体类型的方法调用,可能会被“委派”给该结构体内部嵌入的结构体的实例,通过这种方式构建的新结构体类型就“继承”了被嵌入的结构体的方法的实现。
现在我们可以知道,包括嵌入接口类型在内的各种垂直组合更多用于类型定义层面,本质上它是一种类型组合,也是一种类型之间的耦合方式。
水平组合
通过接口进行水平组合的基本模式就是:使用接受接口类型参数的函数或方法。
基本模式
func YourFuncName(param YourInterfaceType)
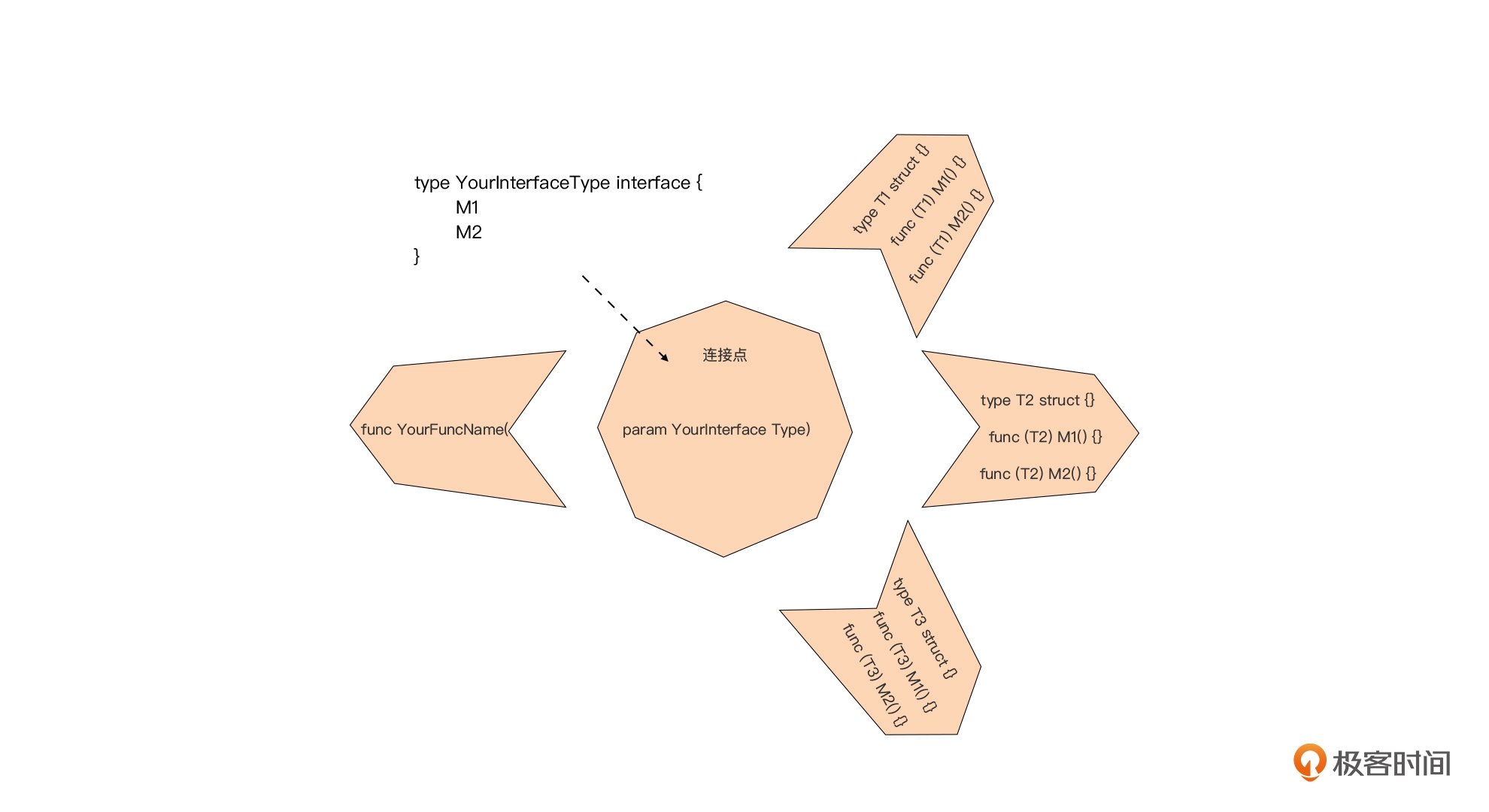
我们看到,函数 / 方法参数中的接口类型作为“关节(连接点)”,支持将位于多个包中的多个类型与 YourFuncName 函数连接到一起,共同实现某一新特性。
同时,接口类型和它的实现者之间隐式的关系却在不经意间满足了:依赖抽象(DIP)、里氏替换原则(LSP)、接口隔离(ISP)等代码设计原则,这在其他语言中是需要很“刻意”地设计谋划的,但对 Go 接口来看,这一切却是自然而然的。
创建模式
Go 社区流传一个经验法则:“接受接口,返回结构体(Accept interfaces, return structs)”,这其实就是一种把接口作为“关节”的应用模式。我这里把它叫做创建模式,是因为这个经验法则多用于创建某一结构体类型的实例。
// $GOROOT/src/sync/cond.go
type Cond struct {
... ...
L Locker
}
func NewCond(l Locker) *Cond {
return &Cond{L: l}
}
// $GOROOT/src/log/log.go
type Logger struct {
mu sync.Mutex
prefix string
flag int
out io.Writer
buf []byte
}
func New(out io.Writer, prefix string, flag int) *Logger {
return &Logger{out: out, prefix: prefix, flag: flag}
}
// $GOROOT/src/log/log.go
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
func NewWriterSize(w io.Writer, size int) *Writer {
// Is it already a Writer?
b, ok := w.(*Writer)
if ok && len(b.buf) >= size {
return b
}
if size <= 0 {
size = defaultBufSize
}
return &Writer{
buf: make([]byte, size),
wr: w,
}
}
创建模式在 sync、log、bufio 包中都有应用。以上面 log 包的 New 函数为例,这个函数用于实例化一个 log.Logger 实例,它接受一个 io.Writer 接口类型的参数,返回 *log.Logger。从 New 的实现上来看,传入的 out 参数被作为初值赋值给了 log.Logger 结构体字段 out。
创建模式通过接口,在 NewXXX 函数所在包与接口的实现者所在包之间建立了一个连接。大多数包含接口类型字段的结构体的实例化,都可以使用创建模式实现。这个模式比较容易理解,我们就不再深入了。
包装器模式
func YourWrapperFunc(param YourInterfaceType) YourInterfaceType
通过这个函数,我们可以实现对输入参数的类型的包装,并在不改变被包装类型(输入参数类型)的定义的情况下,返回具备新功能特性的、实现相同接口类型的新类型。这种接口应用模式我们叫它包装器模式,也叫装饰器模式。包装器多用于对输入数据的过滤、变换等操作。
// $GOROOT/src/io/io.go
func LimitReader(r Reader, n int64) Reader { return &LimitedReader{r, n} }
type LimitedReader struct {
R Reader // underlying reader
N int64 // max bytes remaining
}
func (l *LimitedReader) Read(p []byte) (n int, err error) {
// ... ...
}
使用实例
func main() {
r := strings.NewReader("hello, gopher!\n")
lr := io.LimitReader(r, 4)
if _, err := io.Copy(os.Stdout, lr); err != nil {
log.Fatal(err)
}
}
适配器模式
适配器模式的核心是适配器函数类型(Adapter Function Type)。适配器函数类型是一个辅助水平组合实现的“工具”类型。这里我要再强调一下,它是一个类型。它可以将一个满足特定函数签名的普通函数,显式转换成自身类型的实例,转换后的实例同时也是某个接口类型的实现者。
func greetings(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome!")
}
func main() {
http.ListenAndServe(":8080", http.HandlerFunc(greetings))
}
我们可以看到,这个例子通过 http.HandlerFunc 这个适配器函数类型,将普通函数 greetings 快速转化为满足 http.Handler 接口的类型。而 http.HandleFunc 这个适配器函数类型的定义是这样的:
// $GOROOT/src/net/http/server.go
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
经过 HandlerFunc 的适配转化后,我们就可以将它的实例用作实参,传递给接收 http.Handler 接口的 http.ListenAndServe 函数,从而实现基于接口的组合。
中间件(Middleware)
最后,我们来介绍下中间件这个应用模式。中间件(Middleware)这个词的含义可大可小。在 Go Web 编程中,“中间件”常常指的是一个实现了 http.Handler 接口的 http.HandlerFunc 类型实例。实质上,这里的中间件就是包装模式和适配器模式结合的产物。
func validateAuth(s string) error {
if s != "123456" {
return fmt.Errorf("%s", "bad auth token")
}
return nil
}
func greetings(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome!")
}
func logHandler(h http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
t := time.Now()
log.Printf("[%s] %q %v\n", r.Method, r.URL.String(), t)
h.ServeHTTP(w, r)
})
}
func authHandler(h http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
err := validateAuth(r.Header.Get("auth"))
if err != nil {
http.Error(w, "bad auth param", http.StatusUnauthorized)
return
}
h.ServeHTTP(w, r)
})
}
func main() {
http.ListenAndServe(":8080", logHandler(authHandler(http.HandlerFunc(greetings))))
}
我们看到,所谓中间件(如:logHandler、authHandler)本质就是一个包装函数(支持链式调用),但它的内部利用了适配器函数类型(http.HandlerFunc),将一个普通函数(比如例子中的几个匿名函数)转型为实现了 http.Handler 的类型的实例
运行这个示例,并用 curl 工具命令对其进行测试,我们可以得到下面结果:
$curl http://localhost:8080
bad auth param
$curl -H "auth:123456" localhost:8080/
Welcome!
并发:Go的并发方案实现方案是怎样的?
Go 的并发方案:goroutine
Go 并没有使用操作系统线程作为承载分解后的代码片段(模块)的基本执行单元,而是实现了 goroutine 这一由 Go 运行时(runtime)负责调度的、轻量的用户级线程,为并发程序设计提供原生支持。
相比传统操作系统线程来说,goroutine 的优势主要是:
- 资源占用小,每个 goroutine 的初始栈大小仅为 2k;
- 由 Go 运行时而不是操作系统调度,goroutine 上下文切换在用户层完成,开销更小;
- 在语言层面而不是通过标准库提供。goroutine 由go关键字创建,一退出就会被回收或销毁,开发体验更佳;
- 语言内置 channel 作为 goroutine 间通信原语,为并发设计提供了强大支撑。
Go 语言是面向并发而生的,所以,在程序的结构设计阶段,Go 的惯例是优先考虑并发设计。这样做的目的更多是考虑随着外界环境的变化,通过并发设计的 Go 应用可以更好地、更自然地适应规模化(scale)。
goroutine 的基本用法
go fmt.Println("I am a goroutine")
var c = make(chan int)
go func(a, b int) {
c <- a + b
}(3,4)
// $GOROOT/src/net/http/server.go
c := srv.newConn(rw)
go c.serve(connCtx)
我们看到,通过 go 关键字,我们可以基于已有的具名函数 / 方法创建 goroutine,也可以基于匿名函数 / 闭包创建 goroutine。
那我们怎么退出 goroutine 呢?goroutine 的使用代价很低,Go 官方也推荐你多多使用 goroutine。而且,多数情况下,我们不需要考虑对 goroutine 的退出进行控制:goroutine 的执行函数的返回,就意味着 goroutine 退出。
如果 main goroutine 退出了,那么也意味着整个应用程序的退出。此外,你还要注意的是,goroutine 执行的函数或方法即便有返回值,Go 也会忽略这些返回值。所以,如果你要获取 goroutine 执行后的返回值,你需要另行考虑其他方法,比如通过 goroutine 间的通信来实现。
goroutine 间的通信
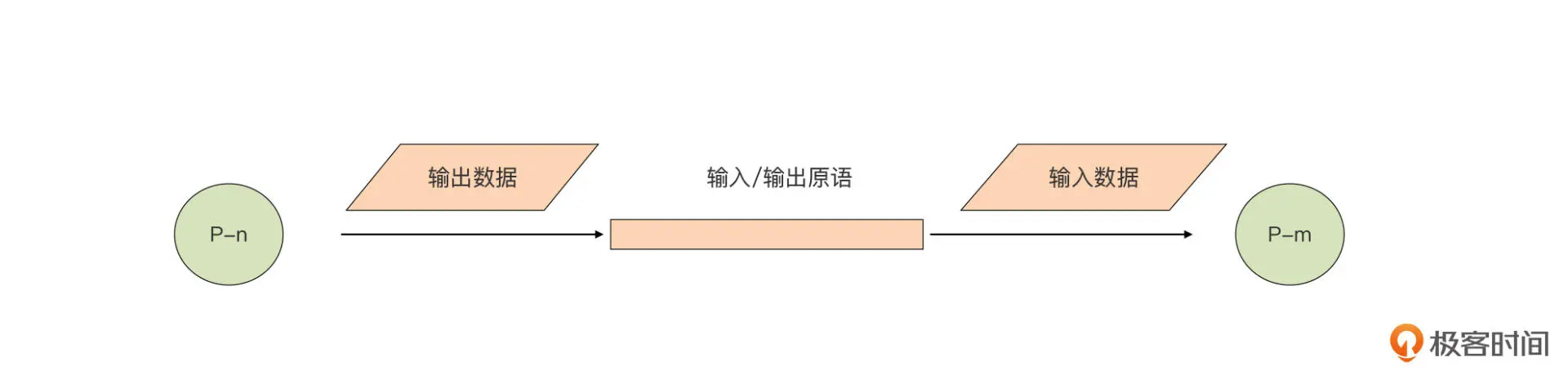
注意了,这里的 P 并不一定与操作系统的进程或线程划等号。在 Go 中,与“Process”对应的是 goroutine。为了实现 CSP 并发模型中的输入和输出原语,Go 还引入了 goroutine(P)之间的通信原语 channel。goroutine 可以从 channel 获取输入数据,再将处理后得到的结果数据通过 channel 输出。通过 channel 将 goroutine(P)组合连接在一起,让设计和编写大型并发系统变得更加简单和清晰,我们再也不用为那些传统共享内存并发模型中的问题而伤脑筋了。
func spawn(f func() error) <-chan error {
c := make(chan error)
go func() {
c <- f()
}()
return c
}
func main() {
c := spawn(func() error {
time.Sleep(2 * time.Second)
return errors.New("timeout")
})
fmt.Println(<-c)
}
毫无疑问,从程序的整体结构来看,Go 始终推荐以 CSP 并发模型风格构建并发程序,尤其是在复杂的业务层面,这能提升程序的逻辑清晰度,大大降低并发设计的复杂性,并让程序更具可读性和可维护性。
不过,对于局部情况,比如涉及性能敏感的区域或需要保护的结构体数据时,我们可以使用更为高效的低级同步原语(如 mutex),保证 goroutine 对数据的同步访问。
并发:聊聊Goroutine调度器的原理
Goroutine 调度器
Go 程序是用户层程序,它本身就是整体运行在一个或多个操作系统线程上的。所以这个答案就出来了:Goroutine 们要竞争的“CPU”资源就是操作系统线程。这样,Goroutine 调度器的任务也就明确了:将 Goroutine 按照一定算法放到不同的操作系统线程中去执行。
Goroutine 调度器模型与演化过程
Go1.1
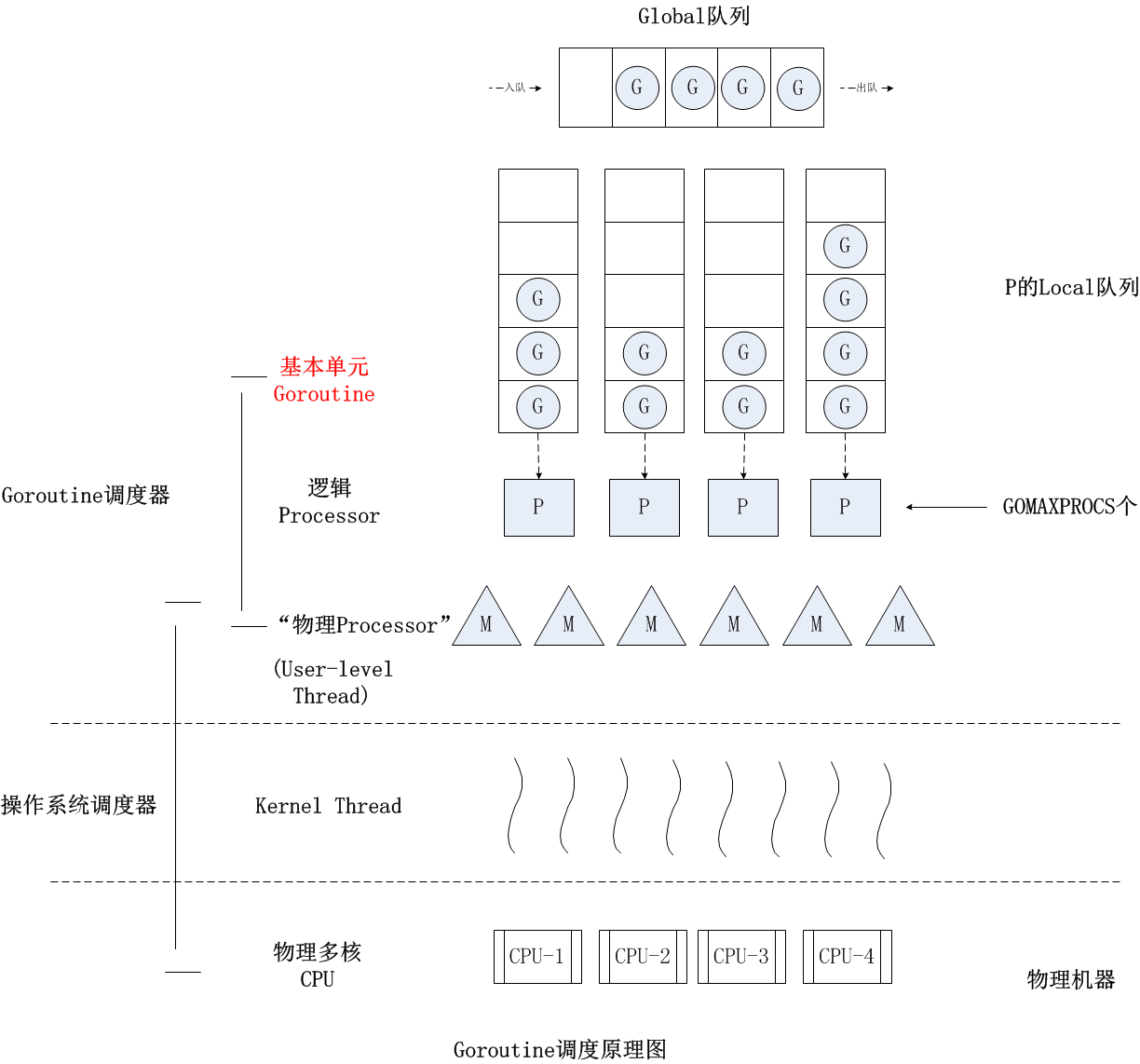
在 Go 1.1 版本中实现了 G-P-M 调度模型和work stealing 算法,这个模型一直沿用至今。
G-P-M 模型的实现算是Go调度器的一大进步,但调度器仍然有一个令人头疼的问题,那就是不支持抢占式调度,这导致一旦某个 G 中出现死循环的代码逻辑,那么 G 将永久占用分配给它的 P 和 M,而位于同一个 P 中的其他 G 将得不到调度,出现“饿死”的情况。
GO1.2
Go 1.2 中实现了基于协作的“抢占式”调度。这个抢占式调度的原理就是,Go 编译器在每个函数或方法的入口处加上了一段额外的代码 (runtime.morestack_noctxt),让运行时有机会在这段代码中检查是否需要执行抢占调度。
这种解决方案只能说局部解决了“饿死”问题,只在有函数调用的地方才能插入“抢占”代码(埋点),对于没有函数调用而是纯算法循环计算的 G,Go 调度器依然无法抢占。比如,死循环等并没有给编译器插入抢占代码的机会,这就会导致 GC 在等待所有 Goroutine 停止时的等待时间过长,从而导致 GC 延迟,内存占用瞬间冲高;甚至在一些特殊情况下,导致在 STW(stop the world)时死锁。
Go 1.14
为了解决这些问题,Go 在 1.14 版本中接受了奥斯汀·克莱门茨(Austin Clements)的提案,增加了对非协作的抢占式调度的支持,这种抢占式调度是基于系统信号的,也就是通过向线程发送信号的方式来抢占正在运行的 Goroutine。
除了这些大的迭代外,Goroutine 的调度器还有一些小的优化改动,比如通过文件 I/O poller 减少 M 的阻塞等。
Go 运行时已经实现了 netpoller,这使得即便 G 发起网络 I/O 操作,也不会导致 M 被阻塞(仅阻塞 G),也就不会导致大量线程(M)被创建出来。
GO 1.9
但是对于文件 I/O 操作来说,一旦阻塞,那么线程(M)将进入挂起状态,等待 I/O 返回后被唤醒。这种情况下 P 将与挂起的 M 分离,再选择一个处于空闲状态(idle)的 M。如果此时没有空闲的 M,就会新创建一个 M(线程),所以,这种情况下,大量 I/O 操作仍然会导致大量线程被创建。
为了解决这个问题,Go 开发团队的伊恩·兰斯·泰勒(Ian Lance Taylor)在 Go 1.9 中增加了一个针对文件 I/O 的 Poller的功能,这个功能可以像 netpoller 那样,在 G 操作那些支持监听(pollable)的文件描述符时,仅会阻塞 G,而不会阻塞 M。不过这个功能依然不能对常规文件有效,常规文件是不支持监听的(pollable)。但对于 Go 调度器而言,这也算是一个不小的进步了。
深入 G-P-M 模型
G、P 和 M
-
G: 代表 Goroutine,存储了 Goroutine 的执行栈信息、Goroutine 状态以及 Goroutine 的任务函数等,而且 G 对象是可以重用的;
-
P: 代表逻辑 processor,P 的数量决定了系统内最大可并行的 G 的数量,P 的最大作用还是其拥有的各种 G 对象队列、链表、一些缓存和状态;
-
M: M 代表着真正的执行计算资源。在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
G 被抢占调度
前面说过,除非极端的无限循环,否则只要 G 调用函数,Go 运行时就有了抢占 G 的机会。Go 程序启动时,运行时会去启动一个名为 sysmon 的 M(一般称为监控线程),这个 M 的特殊之处在于它不需要绑定 P 就可以运行(以 g0 这个 G 的形式),这个 M 在整个 Go 程序的运行过程中至关重要,你可以看下我对 sysmon 被创建的部分代码以及 sysmon 的执行逻辑摘录:
//$GOROOT/src/runtime/proc.go
// The main goroutine.
func main() {
... ...
systemstack(func() {
newm(sysmon, nil)
})
.... ...
}
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
// If a heap span goes unused for 5 minutes after a garbage collection,
// we hand it back to the operating system.
scavengelimit := int64(5 * 60 * 1e9)
... ...
if .... {
... ...
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
... ...
}
}
我们看到,sysmon 每 20us~10ms 启动一次,sysmon 主要完成了这些工作:
- 释放闲置超过 5 分钟的 span 内存;
- 如果超过 2 分钟没有垃圾回收,强制执行;
- 将长时间未处理的 netpoll 结果添加到任务队列;
- 向长时间运行的 G 任务发出抢占调度;
- 收回因 syscall 长时间阻塞的 P;
我们看到 sysmon 将“向长时间运行的 G 任务发出抢占调度”,这个事情由函数 retake 实施:
// $GOROOT/src/runtime/proc.go
// forcePreemptNS is the time slice given to a G before it is
// preempted.
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
... ...
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
if pd.schedwhen+forcePreemptNS > now {
continue
}
preemptone(_p_)
... ...
}
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true //设置被抢占标志
// Every call in a go routine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
gp.stackguard0 = stackPreempt
return true
}
从上面的代码中,我们可以看出,如果一个 G 任务运行 10ms,sysmon 就会认为它的运行时间太久而发出抢占式调度的请求。一旦 G 的抢占标志位被设为 true,那么等到这个 G 下一次调用函数或方法时,运行时就可以将 G 抢占并移出运行状态,放入队列中,等待下一次被调度。
不过,除了这个常规调度之外,还有两个特殊情况下 G 的调度方法。
第一种:channel 阻塞或网络 I/O 情况下的调度。
如果 G 被阻塞在某个 channel 操作或网络 I/O 操作上时,G 会被放置到某个等待(wait)队列中,而 M 会尝试运行 P 的下一个可运行的 G。如果这个时候 P 没有可运行的 G 供 M 运行,那么 M 将解绑 P,并进入挂起状态。当 I/O 操作完成或 channel 操作完成,在等待队列中的 G 会被唤醒,标记为可运行(runnable),并被放入到某 P 的队列中,绑定一个 M 后继续执行。
第二种:系统调用阻塞情况下的调度。
如果 G 被阻塞在某个系统调用(system call)上,那么不光 G 会阻塞,执行这个 G 的 M 也会解绑 P,与 G 一起进入挂起状态。如果此时有空闲的 M,那么 P 就会和它绑定,并继续执行其他 G;如果没有空闲的 M,但仍然有其他 G 要去执行,那么 Go 运行时就会创建一个新 M(线程)。
当系统调用返回后,阻塞在这个系统调用上的 G 会尝试获取一个可用的 P,如果没有可用的 P,那么 G 会被标记为 runnable,之前的那个挂起的 M 将再次进入挂起状态。
并发:小channel中蕴含大智慧
channel
创建 channel
为 channel 类型变量赋初值的唯一方法就是使用 make 这个 Go 预定义的函数
ch1 := make(chan int)
ch2 := make(chan int, 5)
第一行我们通过 make(chan T)创建的、元素类型为 T 的 channel 类型,是无缓冲 channel,而第二行中通过带有 capacity 参数的make(chan T, capacity)创建的元素类型为 T、缓冲区长度为 capacity 的 channel 类型,是带缓冲 channel。
发送与接收
ch1 <- 13 // 将整型字面值13发送到无缓冲channel类型变量ch1中
n := <- ch1 // 从无缓冲channel类型变量ch1中接收一个整型值存储到整型变量n中
ch2 <- 17 // 将整型字面值17发送到带缓冲channel类型变量ch2中
m := <- ch2 // 从带缓冲channel类型变量ch2中接收一个整型值存储到整型变量m中
对无缓冲 channel 类型的发送与接收操作,一定要放在两个不同的 Goroutine 中进行,否则会导致 deadlock。
func main() {
ch1 := make(chan int)
go func() {
ch1 <- 13 // 将发送操作放入一个新goroutine中执行
}()
n := <-ch1
println(n)
}
使用操作符<-,我们还可以声明只发送 channel 类型(send-only)和只接收 channel 类型(recv-only)
ch1 := make(chan<- int, 1) // 只发送channel类型
ch2 := make(<-chan int, 1) // 只接收channel类型
<-ch1 // invalid operation: <-ch1 (receive from send-only type chan<- int)
ch2 <- 13 // invalid operation: ch2 <- 13 (send to receive-only type <-chan int)
试图从一个只发送 channel 类型变量中接收数据,或者向一个只接收 channel 类型发送数据,都会导致编译错误。通常只发送 channel 类型和只接收 channel 类型,会被用作函数的参数类型或返回值,用于限制对 channel 内的操作,或者是明确可对 channel 进行的操作的类型
关闭 channel
n := <- ch // 当ch被关闭后,n将被赋值为ch元素类型的零值
m, ok := <-ch // 当ch被关闭后,m将被赋值为ch元素类型的零值, ok值为false
for v := range ch { // 当ch被关闭后,for range循环结束
... ...
}
从前面 produce 的示例程序中,我们也可以看到,channel 是在 produce 函数中被关闭的,这也是 channel 的一个使用惯例,那就是发送端负责关闭 channel。
select
当涉及同时对多个 channel 进行操作时,我们会结合 Go 为 CSP 并发模型提供的另外一个原语 select,一起使用
select {
case x := <-ch1: // 从channel ch1接收数据
... ...
case y, ok := <-ch2: // 从channel ch2接收数据,并根据ok值判断ch2是否已经关闭
... ...
case ch3 <- z: // 将z值发送到channel ch3中:
... ...
default: // 当上面case中的channel通信均无法实施时,执行该默认分支
}
无缓冲 channel 的惯用法
第一种用法:用作信号传递
1对1
type signal struct{}
func worker() {
println("worker is working...")
time.Sleep(1 * time.Second)
}
func spawn(f func()) <-chan signal {
c := make(chan signal)
go func() {
println("worker start to work...")
f()
c <- signal{}
}()
return c
}
func main() {
println("start a worker...")
c := spawn(worker)
<-c
fmt.Println("worker work done!")
}
1对多
func worker(i int) {
fmt.Printf("worker %d: is working...\n", i)
time.Sleep(1 * time.Second)
fmt.Printf("worker %d: works done\n", i)
}
type signal struct{}
func spawnGroup(f func(i int), num int, groupSignal <-chan signal) <-chan signal {
c := make(chan signal)
var wg sync.WaitGroup
for i := 0; i < num; i++ {
wg.Add(1)
go func(i int) {
<-groupSignal
fmt.Printf("worker %d: start to work...\n", i)
f(i)
wg.Done()
}(i + 1)
}
go func() {
wg.Wait()
c <- signal{}
}()
return c
}
func main() {
fmt.Println("start a group of workers...")
groupSignal := make(chan signal)
c := spawnGroup(worker, 5, groupSignal)
time.Sleep(5 * time.Second)
fmt.Println("the group of workers start to work...")
close(groupSignal)
<-c
fmt.Println("the group of workers work done!")
}
这个例子中,main goroutine 创建了一组 5 个 worker goroutine,这些 Goroutine 启动后会阻塞在名为 groupSignal 的无缓冲 channel 上。main goroutine 通过close(groupSignal)向所有 worker goroutine 广播“开始工作”的信号,收到 groupSignal 后,所有 worker goroutine 会“同时”开始工作,就像起跑线上的运动员听到了裁判员发出的起跑信号枪声。
第二种用法:用于替代锁机制
首先我们看一个传统的、基于“共享内存”+“互斥锁”的 Goroutine 安全的计数器的实现:
type counter struct {
sync.Mutex
i int
}
var cter counter
func Increase() int {
cter.Lock()
defer cter.Unlock()
cter.i++
return cter.i
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
v := Increase()
fmt.Printf("goroutine-%d: current counter value is %d\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
type counter struct {
c chan int
i int
}
func NewCounter() *counter {
cter := &counter{
c: make(chan int),
}
go func() {
for {
cter.i++
cter.c <- cter.i
}
}()
return cter
}
func (cter *counter) Increase() int {
return <-cter.c
}
func main() {
cter := NewCounter()
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
v := cter.Increase()
fmt.Printf("goroutine-%d: current counter value is %d\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
在这个实现中,我们将计数器操作全部交给一个独立的 Goroutine 去处理,并通过无缓冲 channel 的同步阻塞特性,实现了计数器的控制。这样其他 Goroutine 通过 Increase 函数试图增加计数器值的动作,实质上就转化为了一次无缓冲 channel 的接收动作。
带缓冲 channel 的惯用法
第一种用法:用作消息队列
Go 支持 channel 的初衷是将它作为 Goroutine 间的通信手段,它并不是专门用于消息队列场景的。如果你的项目需要专业消息队列的功能特性,比如支持优先级、支持权重、支持离线持久化等,那么 channel 就不合适了,可以使用第三方的专业的消息队列实现。
第二种用法:用作计数信号量(counting semaphore)
Go 并发设计的一个惯用法,就是将带缓冲 channel 用作计数信号量(counting semaphore)。带缓冲 channel 中的当前数据个数代表的是,当前同时处于活动状态(处理业务)的 Goroutine 的数量,而带缓冲 channel 的容量(capacity),就代表了允许同时处于活动状态的 Goroutine 的最大数量。向带缓冲 channel 的一个发送操作表示获取一个信号量,而从 channel 的一个接收操作则表示释放一个信号量。
var active = make(chan struct{}, 3)
var jobs = make(chan int, 10)
func main() {
go func() {
for i := 0; i < 8; i++ {
jobs <- (i + 1)
}
close(jobs)
}()
var wg sync.WaitGroup
for j := range jobs {
wg.Add(1)
go func(j int) {
active <- struct{}{}
log.Printf("handle job: %d\n", j)
time.Sleep(2 * time.Second)
<-active
wg.Done()
}(j)
}
wg.Wait()
}
为了达成这一目标,我们看到这个示例使用了一个容量(capacity)为 3 的带缓冲 channel: active 作为计数信号量,这意味着允许同时处于活动状态的最大 Goroutine 数量为 3。
len(channel) 的应用
针对 channel ch 的类型不同,len(ch) 有如下两种语义:
- 当 ch 为无缓冲 channel 时,len(ch) 总是返回 0;
- 当 ch 为带缓冲 channel 时,len(ch) 返回当前 channel ch 中尚未被读取的元素个数。
channel 原语用于多个 Goroutine 间的通信,一旦多个 Goroutine 共同对 channel 进行收发操作,len(channel) 就会在多个 Goroutine 间形成“竞态”。单纯地依靠 len(channel) 来判断 channel 中元素状态,是不能保证在后续对 channel 的收发时 channel 状态是不变的。
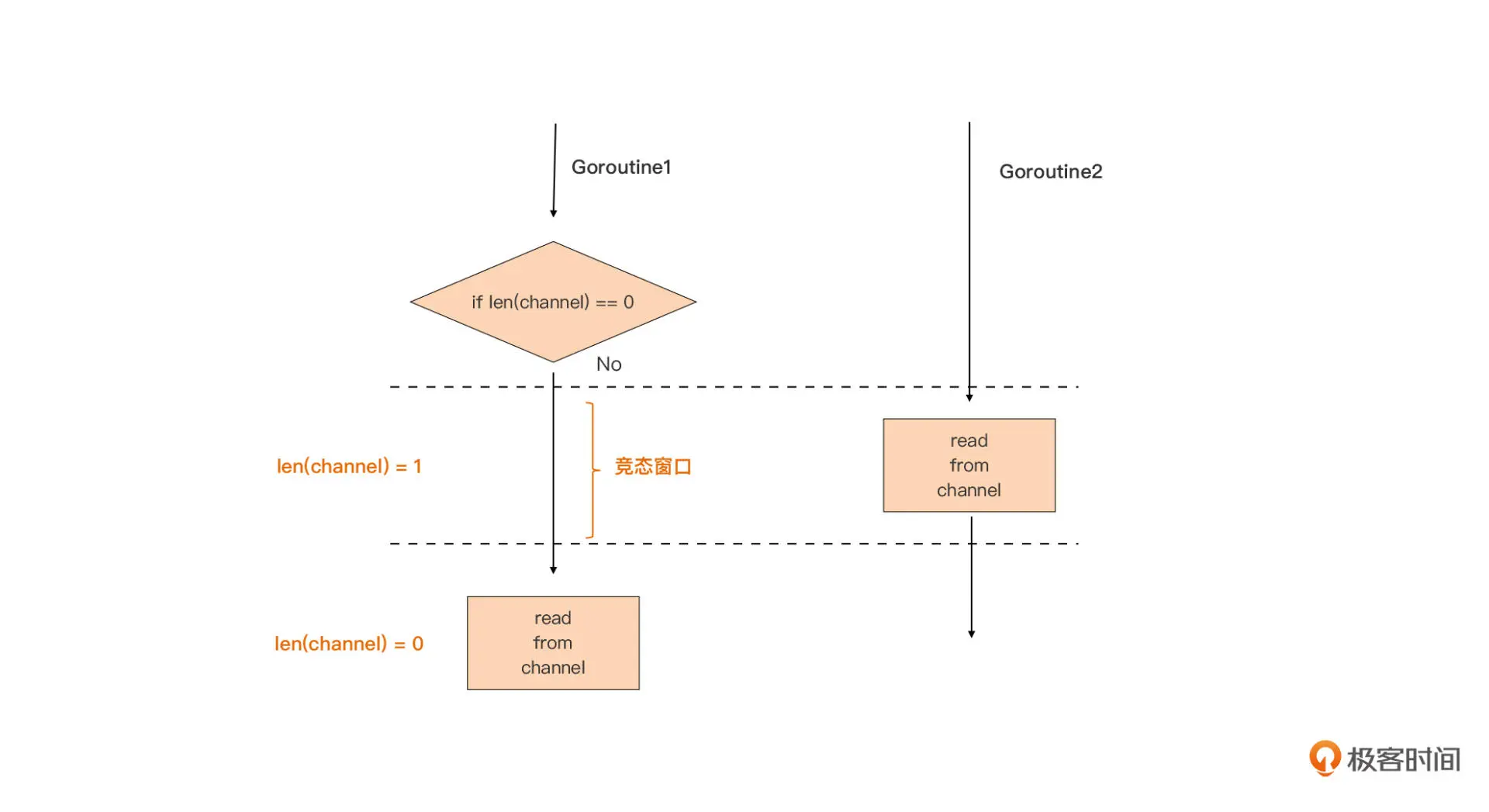
从上图可以看到,Goroutine1 使用 len(channel) 判空后,就会尝试从 channel 中接收数据。但在它真正从 channel 读数据之前,另外一个 Goroutine2 已经将数据读了出去,所以,Goroutine1 后面的读取就会阻塞在 channel 上,导致后面逻辑的失效。因此,为了不阻塞在 channel 上,常见的方法是将“判空与读取”放在一个“事务”中,将“判满与写入”放在一个“事务”中,而这类“事务”我们可以通过 select 实现。我们来看下面示例:
func producer(c chan<- int) {
var i int = 1
for {
time.Sleep(2 * time.Second)
ok := trySend(c, i)
if ok {
fmt.Printf("[producer]: send [%d] to channel\n", i)
i++
continue
}
fmt.Printf("[producer]: try send [%d], but channel is full\n", i)
}
}
func tryRecv(c <-chan int) (int, bool) {
select {
case i := <-c:
return i, true
default:
return 0, false
}
}
func trySend(c chan<- int, i int) bool {
select {
case c <- i:
return true
default:
return false
}
}
func consumer(c <-chan int) {
for {
i, ok := tryRecv(c)
if !ok {
fmt.Println("[consumer]: try to recv from channel, but the channel is empty")
time.Sleep(1 * time.Second)
continue
}
fmt.Printf("[consumer]: recv [%d] from channel\n", i)
if i >= 3 {
fmt.Println("[consumer]: exit")
return
}
}
}
func main() {
var wg sync.WaitGroup
c := make(chan int, 3)
wg.Add(2)
go func() {
producer(c)
wg.Done()
}()
go func() {
consumer(c)
wg.Done()
}()
wg.Wait()
}
这种方法适用于大多数场合,但是这种方法有一个“问题”,那就是它改变了 channel 的状态,会让 channel 接收了一个元素或发送一个元素到 channel。
有些时候我们不想这么做,我们想在不改变 channel 状态的前提下,单纯地侦测 channel 的状态,而又不会因 channel 满或空阻塞在 channel 上。但很遗憾,目前没有一种方法可以在实现这样的功能的同时,适用于所有场合。
但是在特定的场景下,我们可以用 len(channel) 来实现。比如下面这两种场景:
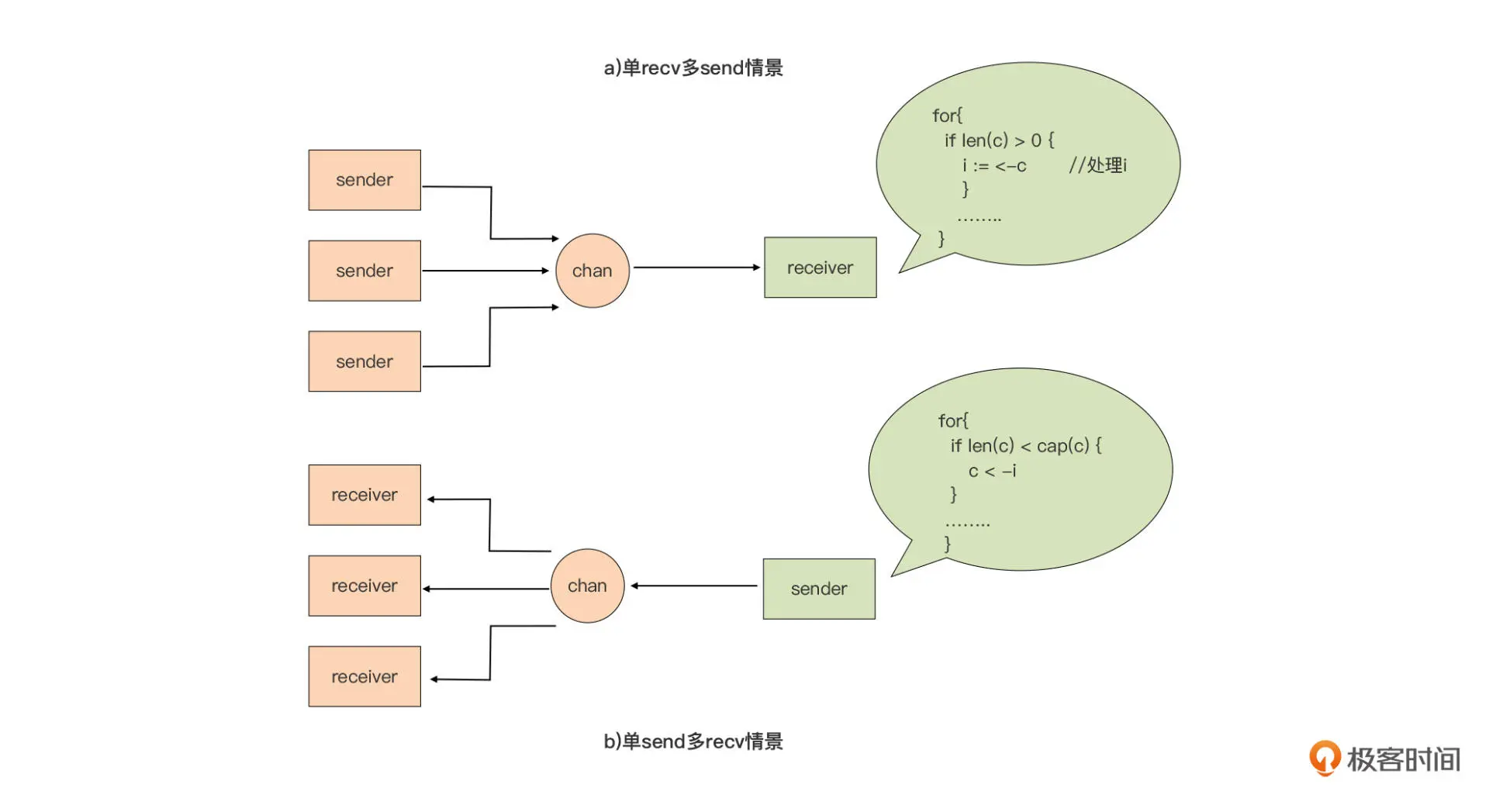
上图中的情景 (a) 是一个“多发送单接收”的场景,也就是有多个发送者,但有且只有一个接收者。在这样的场景下,我们可以在接收 goroutine 中使用 len(channel)是否大于0来判断是否 channel 中有数据需要接收。而情景 (b) 呢,是一个“多接收单发送”的场景,也就是有多个接收者,但有且只有一个发送者。在这样的场景下,我们可以在发送 Goroutine 中使用 len(channel)是否小于 cap(channel)来判断是否可以执行向 channel 的发送操作。
nil channel 的妙用
如果一个 channel 类型变量的值为 nil,我们称它为 nil channel。nil channel 有一个特性,那就是对 nil channel 的读写都会发生阻塞。比如下面示例代码:
func main() {
var c chan int
<-c //阻塞
}
或者:
func main() {
var c chan int
c<-1 //阻塞
}
不过,nil channel 的这个特性可不是一无是处,有些时候应用 nil channel 的这个特性可以得到事半功倍的效果。我们来看一个例子:
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() {
time.Sleep(time.Second * 5)
ch1 <- 5
close(ch1)
}()
go func() {
time.Sleep(time.Second * 7)
ch2 <- 7
close(ch2)
}()
var ok1, ok2 bool
for {
select {
case x := <-ch1:
ok1 = true
fmt.Println(x)
case x := <-ch2:
ok2 = true
fmt.Println(x)
}
if ok1 && ok2 {
break
}
}
fmt.Println("program end")
}
5
0
0
0
... ... //循环输出0
7
program end
我们原本期望上面这个在依次输出 5 和 7 两个数字后退出,但实际运行的输出结果却是在输出 5 之后,程序输出了许多的 0 值,之后才输出 7 并退出。这是怎么回事呢?我们简单分析一下这段代码的运行过程:
- 前 5s,select 一直处于阻塞状态;
- 第 5s,ch1 返回一个 5 后被 close,select 语句的 case x := <-ch1 这个分支被选出执行,程序输出 5,并回到 for 循环并重新 select;
- 由于 ch1 被关闭,从一个已关闭的 channel 接收数据将永远不会被阻塞,于是新一轮 select 又把 case x := <-ch1这个分支选出并执行。由于 ch1 处于关闭状态,从这个 channel 获取数据,我们会得到这个 channel 对应类型的零值,这里就是 0。于是程序再次输出 0;程序按这个逻辑循环执行,一直输出 0 值;
- 2s 后,ch2 被写入了一个数值 7。这样在某一轮 select 的过程中,分支 case x := <-ch2被选中得以执行,程序输出 7 之后满足退出条件,于是程序终止。
那我们可以怎么改进一下这个程序,让它能按照我们的预期输出呢?是时候让 nil channel 登场了!用 nil channel 改进后的示例代码是这样的:
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() {
time.Sleep(time.Second * 5)
ch1 <- 5
close(ch1)
}()
go func() {
time.Sleep(time.Second * 7)
ch2 <- 7
close(ch2)
}()
for {
select {
case x, ok := <-ch1:
if !ok {
ch1 = nil
} else {
fmt.Println(x)
}
case x, ok := <-ch2:
if !ok {
ch2 = nil
} else {
fmt.Println(x)
}
}
if ch1 == nil && ch2 == nil {
break
}
}
fmt.Println("program end")
}
这里,改进后的示例程序的最关键的一个变化,就是在判断 ch1 或 ch2 被关闭后,显式地将 ch1 或 ch2 置为 nil。而我们前面已经知道了,对一个 nil channel 执行获取操作,这个操作将阻塞。于是,这里已经被置为 nil 的 c1 或 c2 的分支,将再也不会被 select 选中执行。
与 select 结合使用的一些惯用法
第一种用法:利用 default 分支避免阻塞
select 语句的 default 分支的语义,就是在其他非 default 分支因通信未就绪,而无法被选择的时候执行的,这就给 default 分支赋予了一种“避免阻塞”的特性。其实在前面的“len(channel) 的应用”小节的例子中,我们就已经用到了“利用 default 分支”实现的 trySend 和 tryRecv 两个函数:
func tryRecv(c <-chan int) (int, bool) {
select {
case i := <-c:
return i, true
default: // channel为空
return 0, false
}
}
func trySend(c chan<- int, i int) bool {
select {
case c <- i:
return true
default: // channel满了
return false
}
}
而且,无论是无缓冲 channel 还是带缓冲 channel,这两个函数都能适用,并且不会阻塞在空 channel 或元素个数已经达到容量的 channel 上。
第二种用法:实现超时机制
带超时机制的 select,是 Go 中常见的一种 select 和 channel 的组合用法。通过超时事件,我们既可以避免长期陷入某种操作的等待中,也可以做一些异常处理工作。比如,下面示例代码实现了一次具有 30s 超时的 select:
func worker() {
select {
case <-c:
// ... do some stuff
case <-time.After(30 *time.Second):
return
}
}
不过,在应用带有超时机制的 select 时,我们要特别注意 timer 使用后的释放,尤其在大量创建 timer 的时候。
Go 语言标准库提供的 timer 实际上是由 Go 运行时自行维护的,而不是操作系统级的定时器资源,它的使用代价要比操作系统级的低许多。但即便如此,作为 time.Timer 的使用者,我们也要尽量减少在使用 Timer 时给 Go 运行时和 Go 垃圾回收带来的压力,要及时调用 timer 的 Stop 方法回收 Timer 资源。
第三种用法:实现心跳机制
结合 time 包的 Ticker,我们可以实现带有心跳机制的 select。这种机制让我们可以在监听 channel 的同时,执行一些周期性的任务,比如下面这段代码:
func worker() {
heartbeat := time.NewTicker(30 * time.Second)
defer heartbeat.Stop()
for {
select {
case <-c:
// ... do some stuff
case <- heartbeat.C:
//... do heartbeat stuff
}
}
}
这里我们使用 time.NewTicker,创建了一个 Ticker 类型实例 heartbeat。这个实例包含一个 channel 类型的字段 C,这个字段会按一定时间间隔持续产生事件,就像“心跳”一样。这样 for 循环在 channel c 无数据接收时,会每隔特定时间完成一次迭代,然后回到 for 循环进行下一次迭代。
和 timer 一样,我们在使用完 ticker 之后,也不要忘记调用它的 Stop 方法,避免心跳事件在 ticker 的 channel(上面示例中的 heartbeat.C)中持续产生。
并发:如何使用共享变量?
sync 包低级同步原语可以用在哪?
-
首先是需要高性能的临界区(critical section)同步机制场景。
-
第二种就是在不想转移结构体对象所有权,但又要保证结构体内部状态数据的同步访问的场景。
基于 channel 的并发设计,有一个特点:在 Goroutine 间通过 channel 转移数据对象的所有权。所以,只有拥有数据对象所有权(从 channel 接收到该数据)的 Goroutine 才可以对该数据对象进行状态变更。如果你的设计中没有转移结构体对象所有权,但又要保证结构体内部状态数据在多个 Goroutine 之间同步访问,那么你可以使用 sync 包提供的低级同步原语来实现,比如最常用的 sync.Mutex。
sync 包中同步原语使用的注意事项
在使用 sync 包中的类型的时候,我们推荐通过闭包方式,或者是传递类型实例(或包裹该类型的类型实例)的地址(指针)的方式进行。这就是使用 sync 包时最值得我们注意的事项。
互斥锁(Mutex)还是读写锁(RWMutex)?
var mu sync.Mutex
mu.Lock() // 加锁
doSomething()
mu.Unlock() // 解锁
var rwmu sync.RWMutex
rwmu.RLock() //加读锁
readSomething()
rwmu.RUnlock() //解读锁
rwmu.Lock() //加写锁
changeSomething()
rwmu.Unlock() //解写锁
- 并发量较小的情况下,Mutex 性能最好;随着并发量增大,Mutex 的竞争激烈,导致加锁和解锁性能下降;
- RWMutex 的读锁性能并没有随着并发量的增大,而发生较大变化,性能始终恒定在 40ns 左右;
- 在并发量较大的情况下,RWMutex 的写锁性能和 Mutex、RWMutex 读锁相比,是最差的,并且随着并发量增大,RWMutex 写锁性能有继续下降趋势。
读写锁适合应用在具有一定并发量且读多写少的场合。在大量并发读的情况下,多个 Goroutine 可以同时持有读锁,从而减少在锁竞争中等待的时间。
条件变量
sync.Cond 是传统的条件变量原语概念在 Go 语言中的实现。我们可以把一个条件变量理解为一个容器,这个容器中存放着一个或一组等待着某个条件成立的 Goroutine。
当条件成立后,这些处于等待状态的 Goroutine 将得到通知,并被唤醒继续进行后续的工作。这与百米飞人大战赛场上,各位运动员等待裁判员的发令枪声的情形十分类似。
条件变量是同步原语的一种,如果没有条件变量,开发人员可能需要在 Goroutine 中通过连续轮询的方式,检查某条件是否为真,这种连续轮询非常消耗资源,因为 Goroutine 在这个过程中是处于活动状态的,但它的工作又没有进展。
type signal struct{}
var ready bool
func worker(i int) {
fmt.Printf("worker %d: is working...\n", i)
time.Sleep(1 * time.Second)
fmt.Printf("worker %d: works done\n", i)
}
func spawnGroup(f func(i int), num int, mu *sync.Mutex) <-chan signal {
c := make(chan signal)
var wg sync.WaitGroup
for i := 0; i < num; i++ {
wg.Add(1)
go func(i int) {
for {
mu.Lock()
if !ready {
mu.Unlock()
time.Sleep(100 * time.Millisecond)
continue
}
mu.Unlock()
fmt.Printf("worker %d: start to work...\n", i)
f(i)
wg.Done()
return
}
}(i + 1)
}
go func() {
wg.Wait()
c <- signal(struct{}{})
}()
return c
}
func main() {
fmt.Println("start a group of workers...")
mu := &sync.Mutex{}
c := spawnGroup(worker, 5, mu)
time.Sleep(5 * time.Second) // 模拟ready前的准备工作
fmt.Println("the group of workers start to work...")
mu.Lock()
ready = true
mu.Unlock()
<-c
fmt.Println("the group of workers work done!")
}
就像前面提到的,轮询的方式开销大,轮询间隔设置的不同,条件检查的及时性也会受到影响。sync.Cond 为 Goroutine 在这个场景下提供了另一种可选的、资源消耗更小、使用体验更佳的同步方式。使用条件变量原语,我们可以在实现相同目标的同时,避免对条件的轮询。我们用 sync.Cond 对上面的例子进行改造,改造后的代码如下:
type signal struct{}
var ready bool
func worker(i int) {
fmt.Printf("worker %d: is working...\n", i)
time.Sleep(1 * time.Second)
fmt.Printf("worker %d: works done\n", i)
}
func spawnGroup(f func(i int), num int, groupSignal *sync.Cond) <-chan signal {
c := make(chan signal)
var wg sync.WaitGroup
for i := 0; i < num; i++ {
wg.Add(1)
go func(i int) {
groupSignal.L.Lock()
for !ready {
groupSignal.Wait()
}
groupSignal.L.Unlock()
fmt.Printf("worker %d: start to work...\n", i)
f(i)
wg.Done()
}(i + 1)
}
go func() {
wg.Wait()
c <- signal(struct{}{})
}()
return c
}
func main() {
fmt.Println("start a group of workers...")
groupSignal := sync.NewCond(&sync.Mutex{})
c := spawnGroup(worker, 5, groupSignal)
time.Sleep(5 * time.Second) // 模拟ready前的准备工作
fmt.Println("the group of workers start to work...")
groupSignal.L.Lock()
ready = true
groupSignal.Broadcast()
groupSignal.L.Unlock()
<-c
fmt.Println("the group of workers work done!")
}
我们看到,sync.Cond 实例的初始化,需要一个满足实现了 sync.Locker 接口的类型实例,通常我们使用 sync.Mutex。
条件变量需要这个互斥锁来同步临界区,保护用作条件的数据。加锁后,各个等待条件成立的 Goroutine 判断条件是否成立,如果不成立,则调用 sync.Cond 的 Wait 方法进入等待状态。Wait 方法在 Goroutine 挂起前会进行 Unlock 操作。
当 main goroutine 将 ready 置为 true,并调用 sync.Cond 的 Broadcast 方法后,各个阻塞的 Goroutine 将被唤醒,并从 Wait 方法中返回。Wait 方法返回前,Wait 方法会再次加锁让 Goroutine 进入临界区。接下来 Goroutine 会再次对条件数据进行判定,如果条件成立,就会解锁并进入下一个工作阶段;如果条件依旧不成立,那么会再次进入循环体,并调用 Wait 方法挂起等待。
和 sync.Mutex 、sync.RWMutex等相比,sync.Cond 应用的场景更为有限,只有在需要“等待某个条件成立”的场景下,Cond 才有用武之地。
原子操作(atomic operations)
我们以 atomic.SwapInt64 函数在 x86_64 平台上的实现为例,看看这个函数的实现方法:
// $GOROOT/src/sync/atomic/doc.go
func SwapInt64(addr *int64, new int64) (old int64)
// $GOROOT/src/sync/atomic/asm.s
TEXT ·SwapInt64(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Xchg64(SB)
// $GOROOT/src/runtime/internal/atomic/asm_amd64.s
TEXT runtime∕internal∕atomic·Xchg64(SB), NOSPLIT, $0-24
MOVQ ptr+0(FP), BX
MOVQ new+8(FP), AX
XCHGQ AX, 0(BX)
MOVQ AX, ret+16(FP)
RET
从函数 SwapInt64 的实现中,我们可以看到:它基本就是对 x86_64 CPU 实现的原子操作指令 XCHGQ 的直接封装。
atomic 包提供了两大类原子操作接口,一类是针对整型变量的,包括有符号整型、无符号整型以及对应的指针类型;另外一类是针对自定义类型的。因此,第一类原子操作接口的存在让 atomic 包天然适合去实现某一个共享整型变量的并发同步。
var n1 int64
func addSyncByAtomic(delta int64) int64 {
return atomic.AddInt64(&n1, delta)
}
func readSyncByAtomic() int64 {
return atomic.LoadInt64(&n1)
}
var n2 int64
var rwmu sync.RWMutex
func addSyncByRWMutex(delta int64) {
rwmu.Lock()
n2 += delta
rwmu.Unlock()
}
func readSyncByRWMutex() int64 {
var n int64
rwmu.RLock()
n = n2
rwmu.RUnlock()
return n
}
func BenchmarkAddSyncByAtomic(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
addSyncByAtomic(1)
}
})
}
func BenchmarkReadSyncByAtomic(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
readSyncByAtomic()
}
})
}
func BenchmarkAddSyncByRWMutex(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
addSyncByRWMutex(1)
}
})
}
func BenchmarkReadSyncByRWMutex(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
readSyncByRWMutex()
}
})
}
- 读写锁的性能随着并发量增大的情况,与前面讲解的 sync.RWMutex 一致;
- 利用原子操作的无锁并发写的性能,随着并发量增大几乎保持恒定;
- 利用原子操作的无锁并发读的性能,随着并发量增大有持续提升的趋势,并且性能是读锁的约 200 倍。
通过这些结论,我们大致可以看到 atomic 原子操作的特性:随着并发量提升,使用 atomic 实现的共享变量的并发读写性能表现更为稳定,尤其是原子读操作,和 sync 包中的读写锁原语比起来,atomic 表现出了更好的伸缩性和高性能。
由此,我们也可以看出 atomic 包更适合一些对性能十分敏感、并发量较大且读多写少的场合。不过,atomic 原子操作可用来同步的范围有比较大限制,只能同步一个整型变量或自定义类型变量。如果我们要对一个复杂的临界区数据进行同步,那么首选的依旧是 sync 包中的原语。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号