《趣谈网络协议》云中网络——小记随笔
云中网络:自己拿地成本高,购买公寓更灵活
从物理机到虚拟机
我们常把物理机比喻为自己拿地盖房子,而虚拟机则相当于购买公寓,更加灵活方面,随时可买可卖。 那这个软件为什么能做到这些事儿呢?
它用的是软件模拟硬件的方式。刚才说了,数据中心里面用的 qemu-kvm。从名字上来讲,emu 就是 Emulator(模拟器)的意思,主要会模拟 CPU、内存、网络、硬盘,使得虚拟机感觉自己在使用独立的设备,但是真正使用的时候,当然还是使用物理的设备。
例如,多个虚拟机轮流使用物理 CPU,内存也是使用虚拟内存映射的方式,最终映射到物理内存上。硬盘在一块大的文件系统上创建一个 N 个 G 的文件,作为虚拟机的硬盘。
简单比喻,虚拟化软件就像一个“骗子”,向上“骗”虚拟机里面的应用,让它们感觉独享资源,其实自己啥都没有,全部向下从物理机里面弄。
虚拟网卡的原理
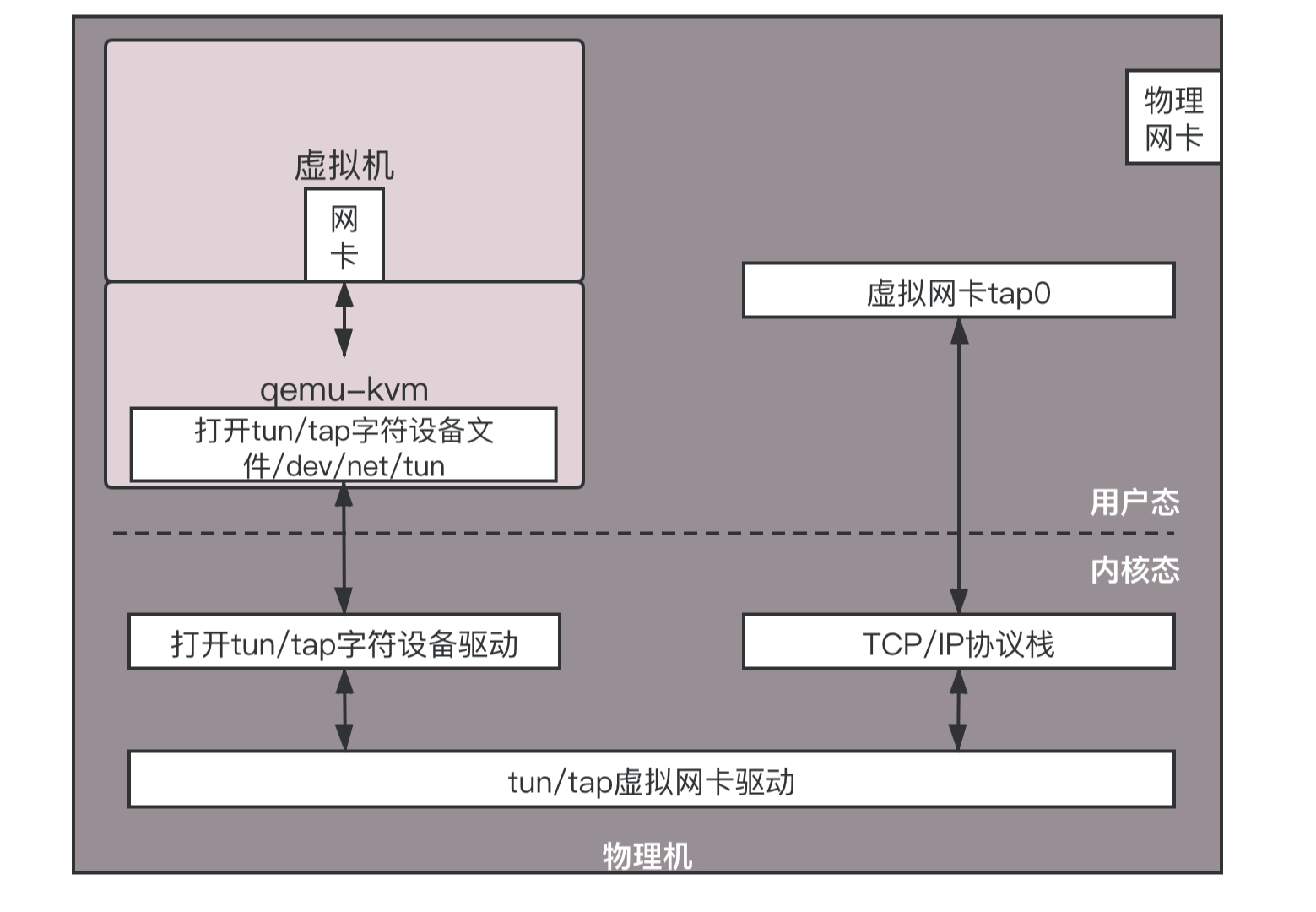
虚拟机要有一张网卡。对于 qemu-kvm 来说,这是通过 Linux 上的一种 TUN/TAP 技术来实现的。
虚拟机是物理机上跑着的一个软件。这个软件可以像其他应用打开文件一样,打开一个称为 TUN/TAP 的 Char Dev(字符设备文件)。打开了这个字符设备文件之后,在物理机上就能看到一张虚拟 TAP 网卡。
虚拟化软件作为“骗子”,会将打开的这个文件,在虚拟机里面虚拟出一张网卡,让虚拟机里面的应用觉得它们真有一张网卡。于是,所有的网络包都往这里发。
当然,网络包会到虚拟化软件这里。它会将网络包转换成为文件流,写入字符设备,就像写一个文件一样。内核中 TUN/TAP 字符设备驱动会收到这个写入的文件流,交给 TUN/TAP 的虚拟网卡驱动。这个驱动将文件流再次转成网络包,交给 TCP/IP 协议栈,最终从虚拟 TAP 网卡发出来,成为标准的网络包。
虚拟网卡连接到云中
我们就这样有了虚拟 TAP 网卡。接下来就要看,这个卡怎么接入庞大的数据中心网络中。在接入之前,我们先来看,云计算中的网络都需要注意哪些点。
- 共享:尽管每个虚拟机都会有一个或者多个虚拟网卡,但是物理机上可能只有有限的网卡。那这么多虚拟网卡如何共享同一个出口?
- 隔离:分两个方面,一个是安全隔离,两个虚拟机可能属于两个用户,那怎么保证一个用户的数据不被另一个用户窃听?一个是流量隔离,两个虚拟机,如果有一个疯狂下片,会不会导致另外一个上不了网?
- 互通:分两个方面,一个是如果同一台机器上的两个虚拟机,属于同一个用户的话,这两个如何相互通信?另一个是如果不同物理机上的两个虚拟机,属于同一个用户的话,这两个如何相互通信?
- 灵活:虚拟机和物理不同,会经常创建、删除,从一个机器漂移到另一台机器,有的互通、有的不通等等,灵活性比物理网络要好得多,需要能够灵活配置。
共享与互通问题
在物理机上,应该有一个虚拟的交换机,在 Linux 上有一个命令叫作 brctl,可以创建虚拟的网桥 brctl addbr br0。创建出来以后,将两个虚拟机的虚拟网卡,都连接到虚拟网桥 brctl addif br0 tap0 上,这样将两个虚拟机配置相同的子网网段,两台虚拟机就能够相互通信了。
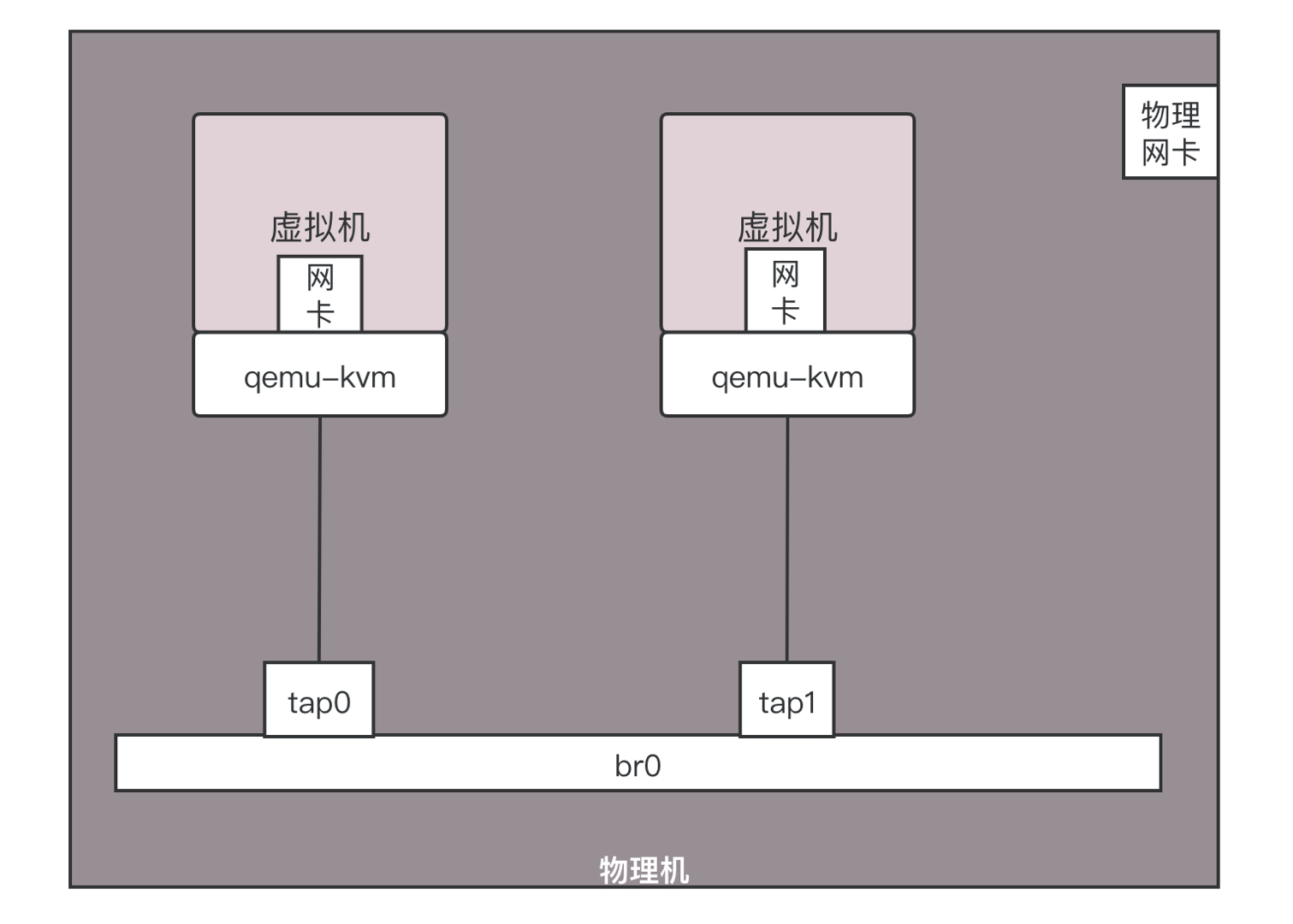
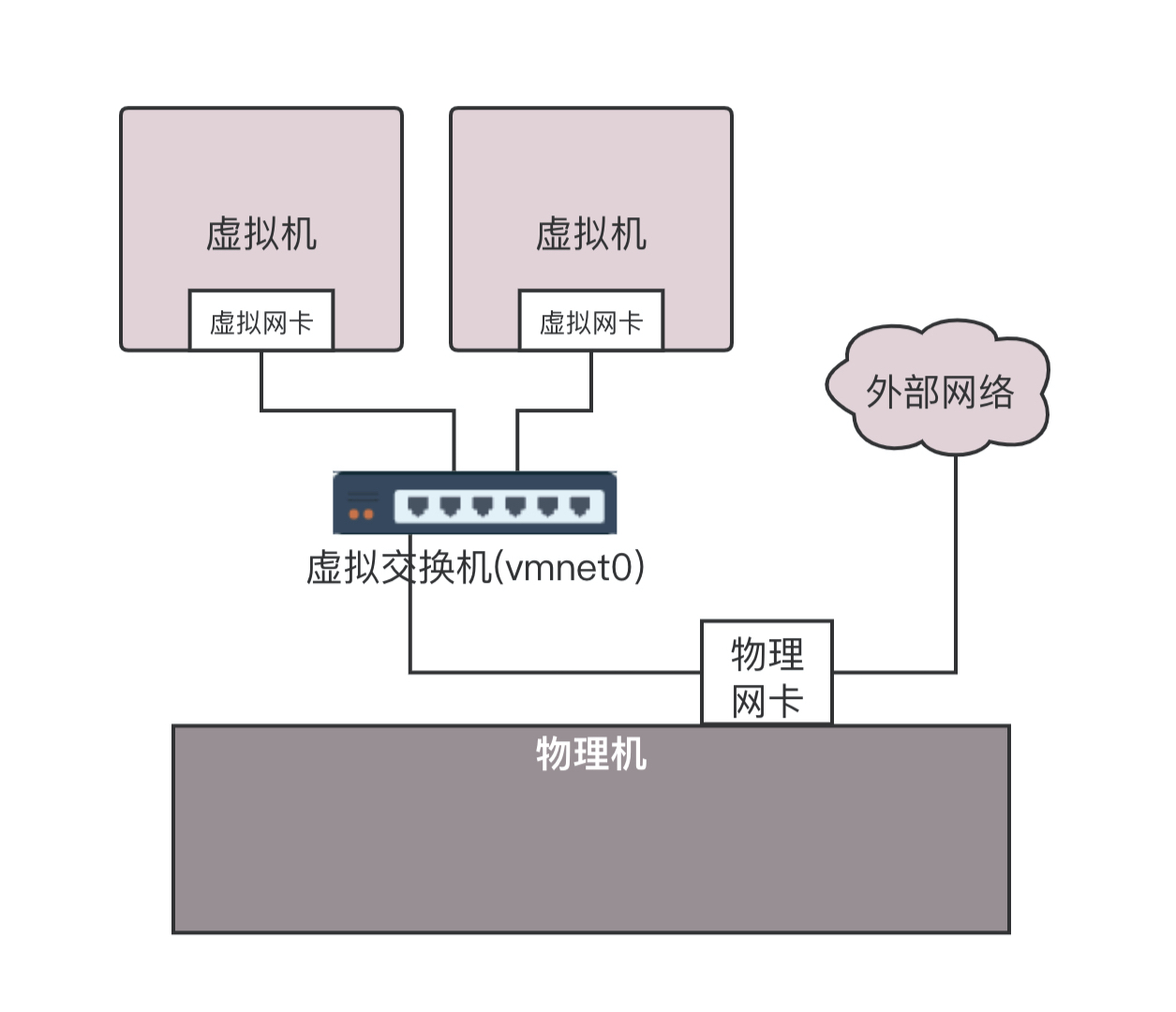
那这些虚拟机如何连接外网呢?在桌面虚拟化软件上面,我们能看到以下选项。
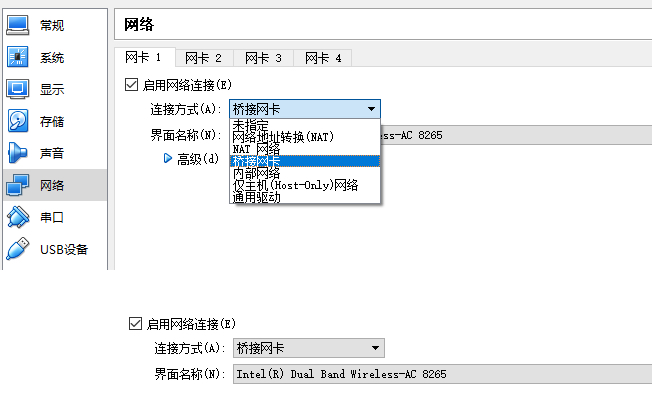
host-only 的网络对应的,其实就是上面两个虚拟机连到一个 br0 虚拟网桥上,而且不考虑访问外部的场景,只要虚拟机之间能够相互访问就可以了。
桥接模式
一种方式称为桥接。如果在桌面虚拟化软件上选择桥接网络,则在你的笔记本电脑上,就会形成下面的结构。
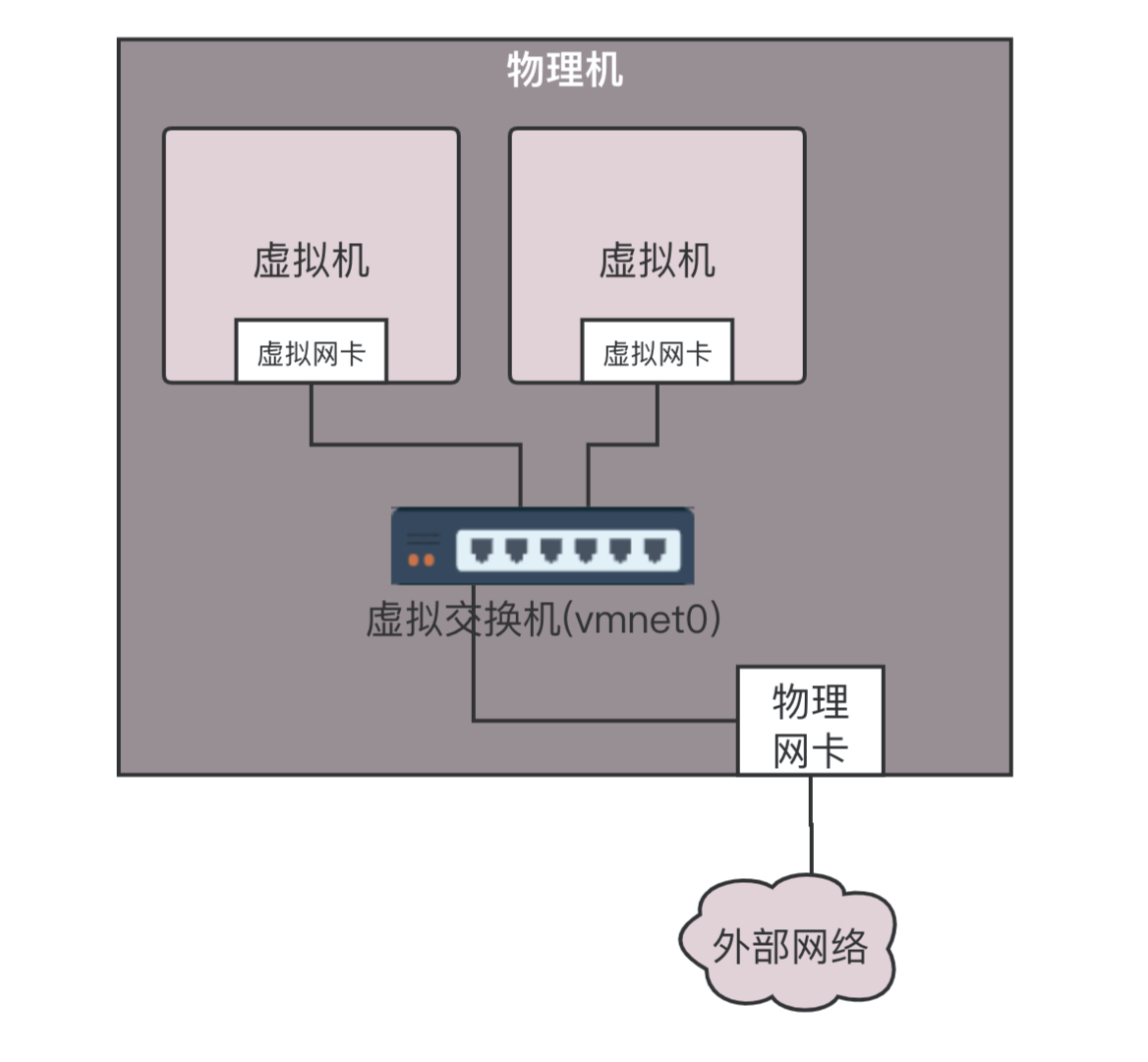
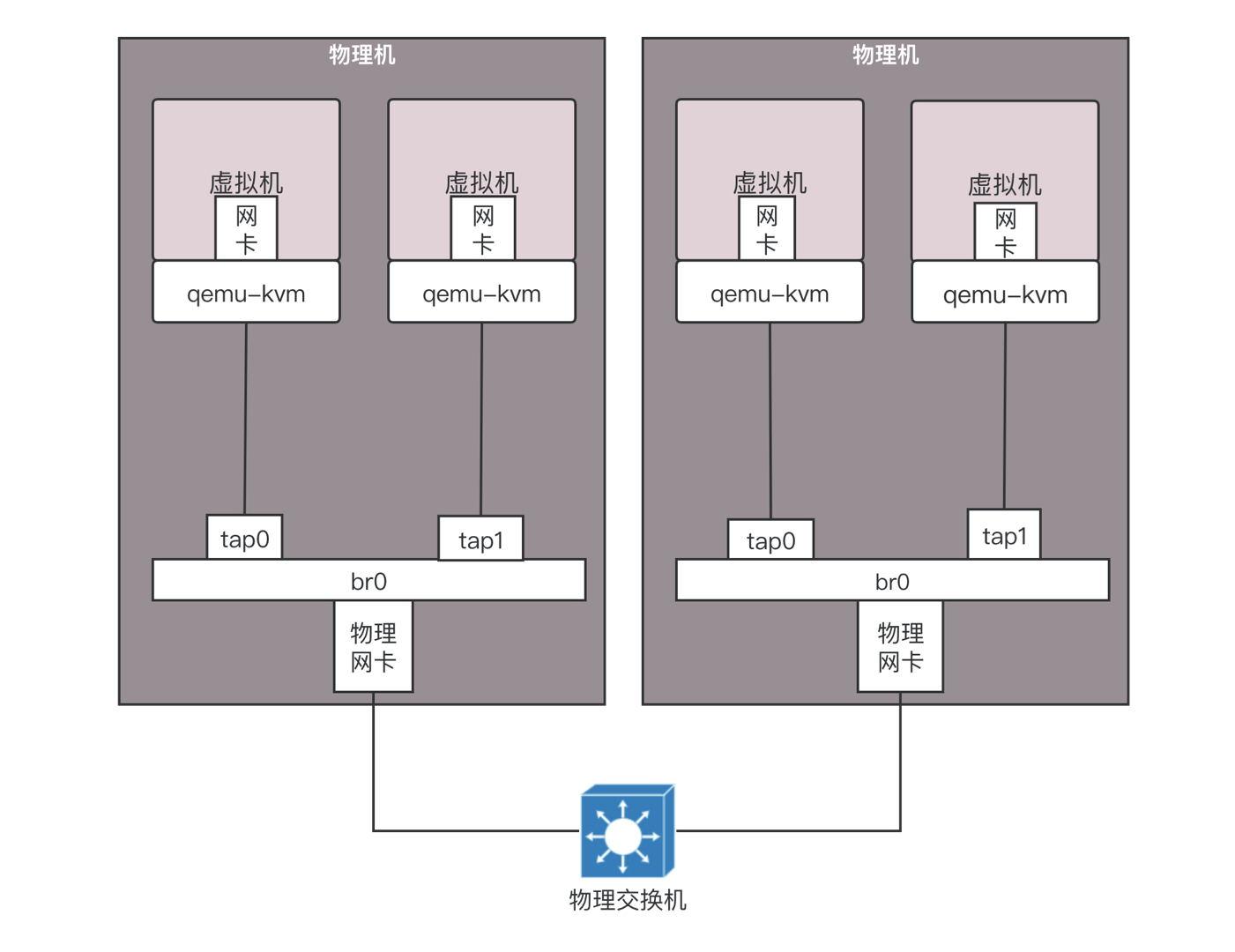
每个虚拟机都会有虚拟网卡,在你的笔记本电脑上,会发现多了几个网卡,其实是虚拟交换机。这个虚拟交换机将虚拟机连接在一起。在桥接模式下,物理网卡也连接到这个虚拟交换机上
如果使用桥接网络,当你登录虚拟机里看 IP 地址的时候会发现,你的虚拟机的地址和你的笔记本电脑的,以及你旁边的同事的电脑的网段是一个网段。这是为什么呢?这其实相当于将物理机和虚拟机放在同一个网桥上,相当于这个网桥上有三台机器,是一个网段的,全部打平了。
在数据中心里面,采取的也是类似的技术,只不过都是 Linux,在每台机器上都创建网桥 br0,虚拟机的网卡都连到 br0 上,物理网卡也连到 br0 上,所有的 br0 都通过物理网卡出来连接到物理交换机上。
同样我们换一个角度看待这个拓扑图。同样是将网络打平,虚拟机会和你的物理网络具有相同的网段。
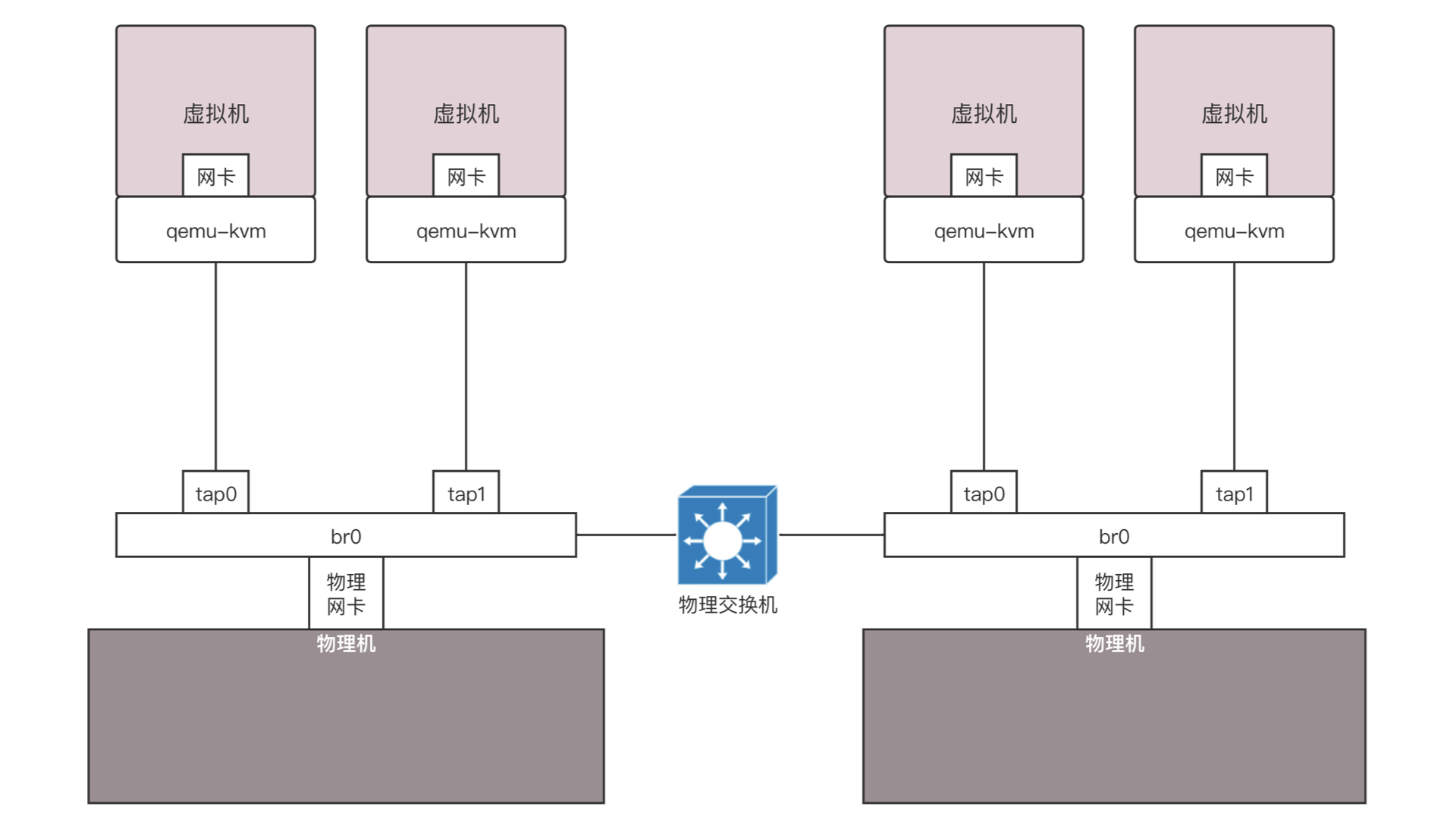
在这种方式下,不但解决了同一台机器的互通问题,也解决了跨物理机的互通问题,因为都在一个二层网络里面,彼此用相同的网段访问就可以了。但是当规模很大的时候,会存在问题。
你还记得吗?在一个二层网络里面,最大的问题是广播。一个数据中心的物理机已经很多了,广播已经非常严重,需要通过 VLAN 进行划分。如果使用了虚拟机,假设一台物理机里面创建 10 台虚拟机,全部在一个二层网络里面,那广播就会很严重,所以除非是你的桌面虚拟机或者数据中心规模非常小,才可以使用这种相对简单的方式。
Nat 模式
如果在桌面虚拟化软件中使用 NAT 模式,在你的笔记本电脑上会出现如下的网络结构。
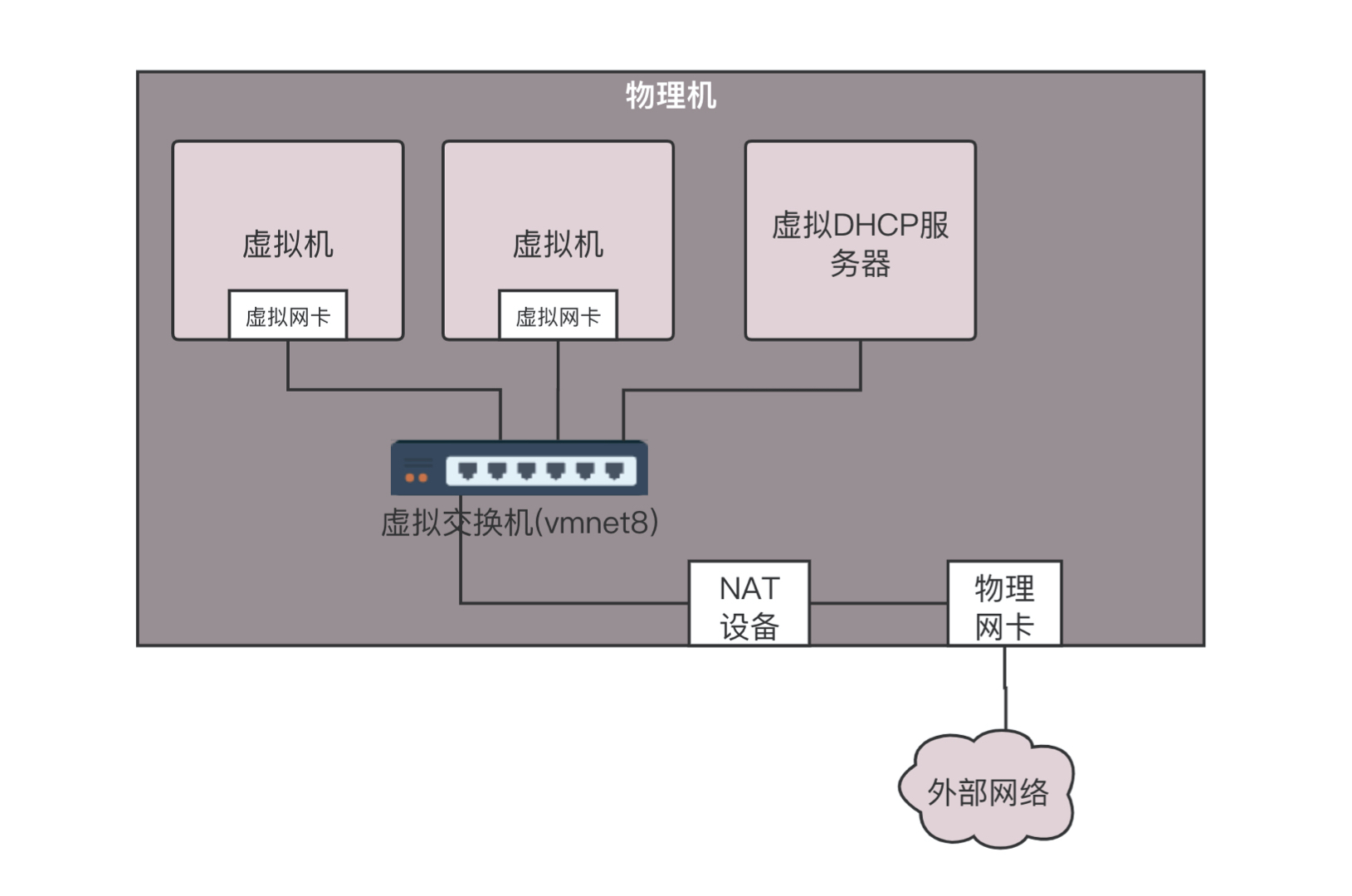
在这种方式下,你登录到虚拟机里面查看 IP 地址,会发现虚拟机的网络是虚拟机的,物理机的网络是物理机的,两个不相同。虚拟机要想访问物理机的时候,需要将地址 NAT 成为物理机的地址。
除此之外,它还会在你的笔记本电脑里内置一个 DHCP 服务器,为笔记本电脑上的虚拟机动态分配 IP 地址。因为虚拟机的网络自成体系,需要进行 IP 管理。为什么桥接方式不需要呢?因为桥接将网络打平了,虚拟机的 IP 地址应该由物理网络的 DHCP 服务器分配。
在数据中心里面,也是使用类似的方式。这种方式更像是真的将你宿舍里面的情况,搬到一台物理机上来。
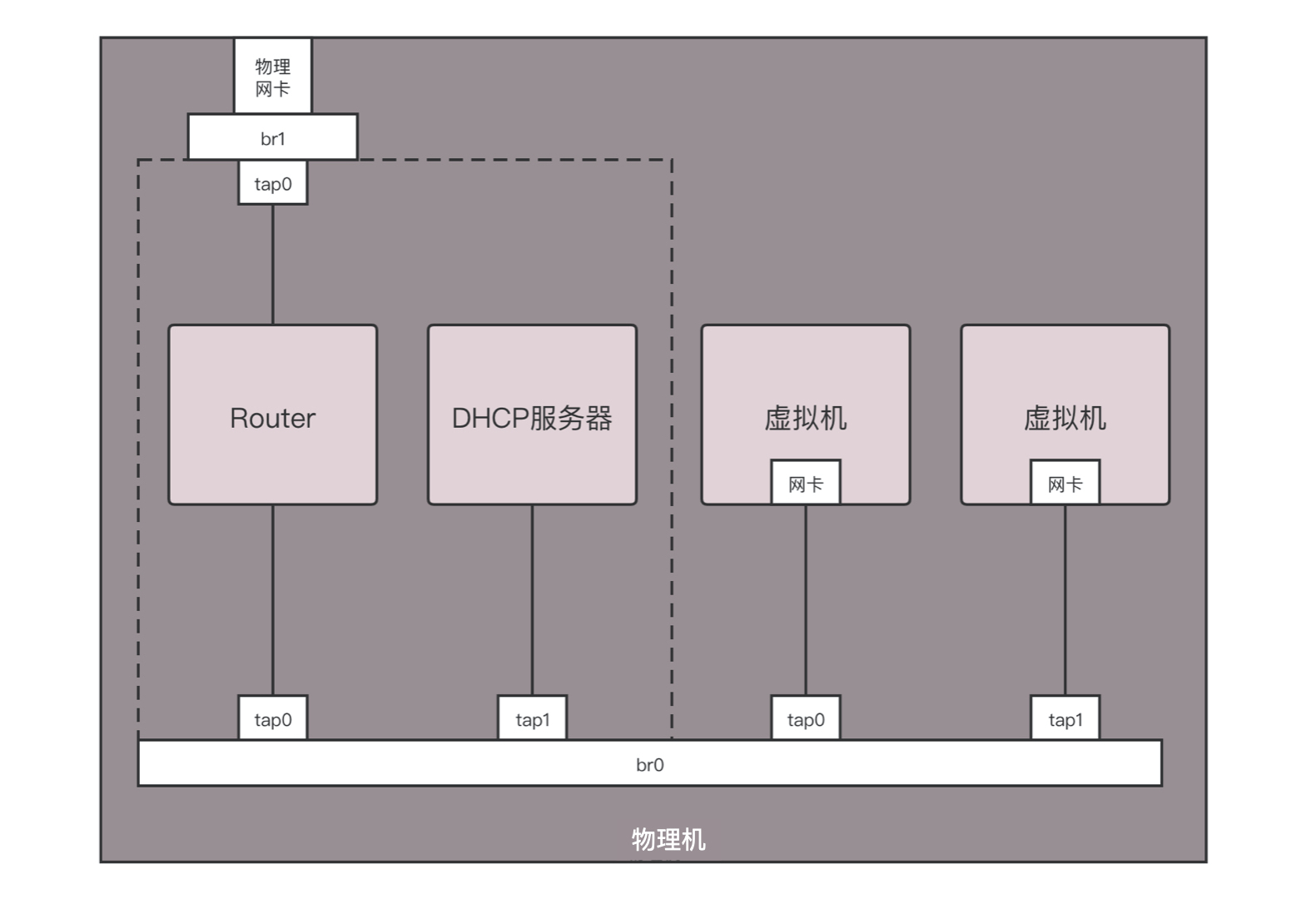
所有电脑都通过内网网口连接到一个网桥 br0 上,虚拟机要想访问互联网,需要通过 br0 连到路由器上,然后通过路由器将请求 NAT 成为物理网络的地址,转发到物理网络。
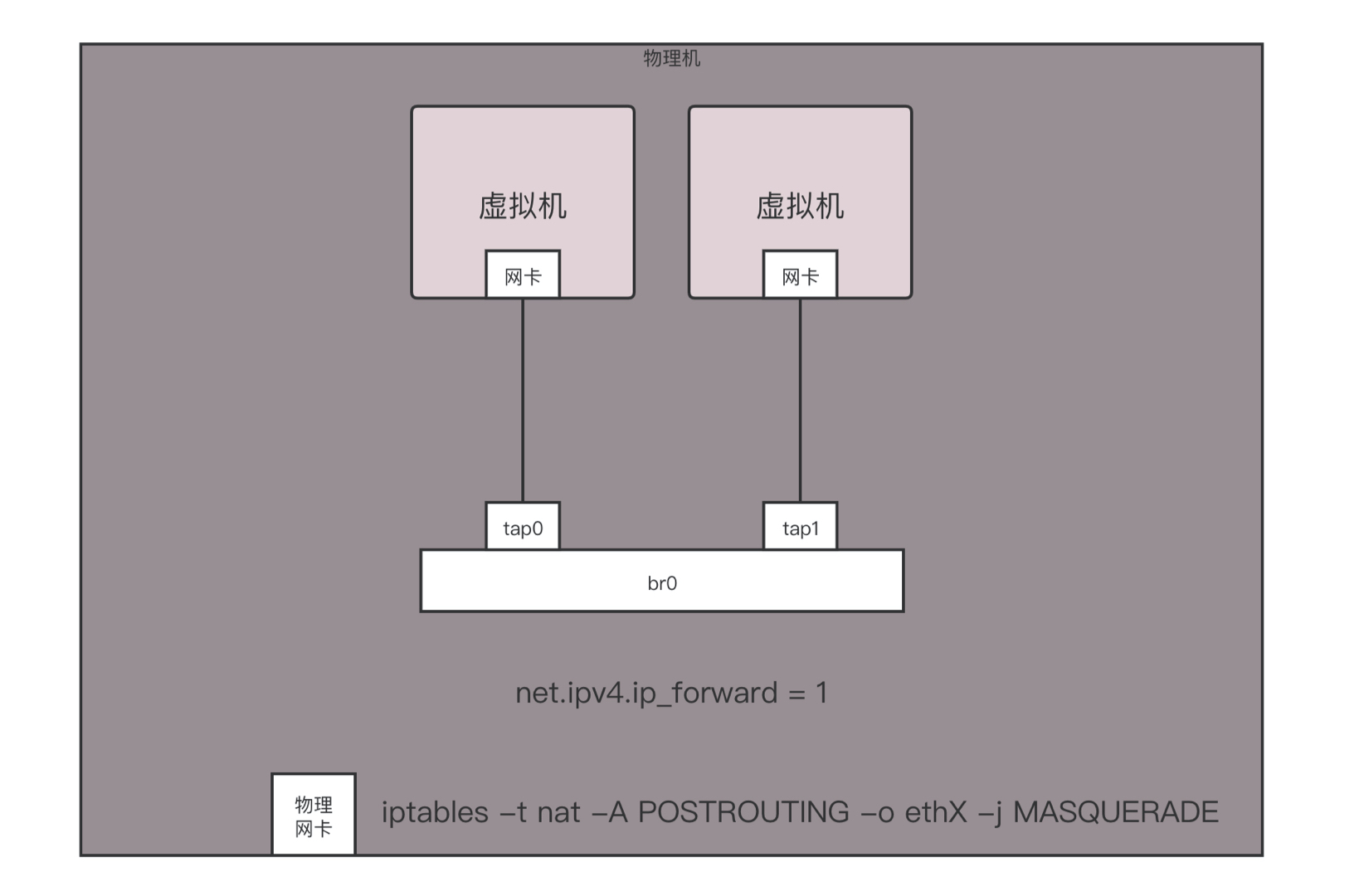
如果是你自己登录到物理机上做个简单配置,你可以简化一下。例如将虚拟机所在网络的网关的地址直接配置到 br0 上,不用 DHCP Server,手动配置每台虚拟机的 IP 地址,通过命令 iptables -t nat -A POSTROUTING -o ethX -j MASQUERADE,直接在物理网卡 ethX 上进行 NAT,所有从这个网卡出去的包都 NAT 成这个网卡的地址。通过设置 net.ipv4.ip_forward = 1,开启物理机的转发功能,直接做路由器,而不用单独的路由器,这样虚拟机就能直接上网了。
隔离问题
如果一台机器上的两个虚拟机不属于同一个用户,怎么办呢?好在 brctl 创建的网桥也是支持 VLAN 功能的,可以设置两个虚拟机的 tag,这样在这个虚拟网桥上,两个虚拟机是不互通的。但是如何跨物理机互通,并且实现 VLAN 的隔离呢?由于 brctl 创建的网桥上面的 tag 是没办法在网桥之外的范围内起作用的,因此我们需要寻找其他的方式。
有一个命令 vconfig,可以基于物理网卡 eth0 创建带 VLAN 的虚拟网卡,所有从这个虚拟网卡出去的包,都带这个 VLAN,如果这样,跨物理机的互通和隔离就可以通过这个网卡来实现。
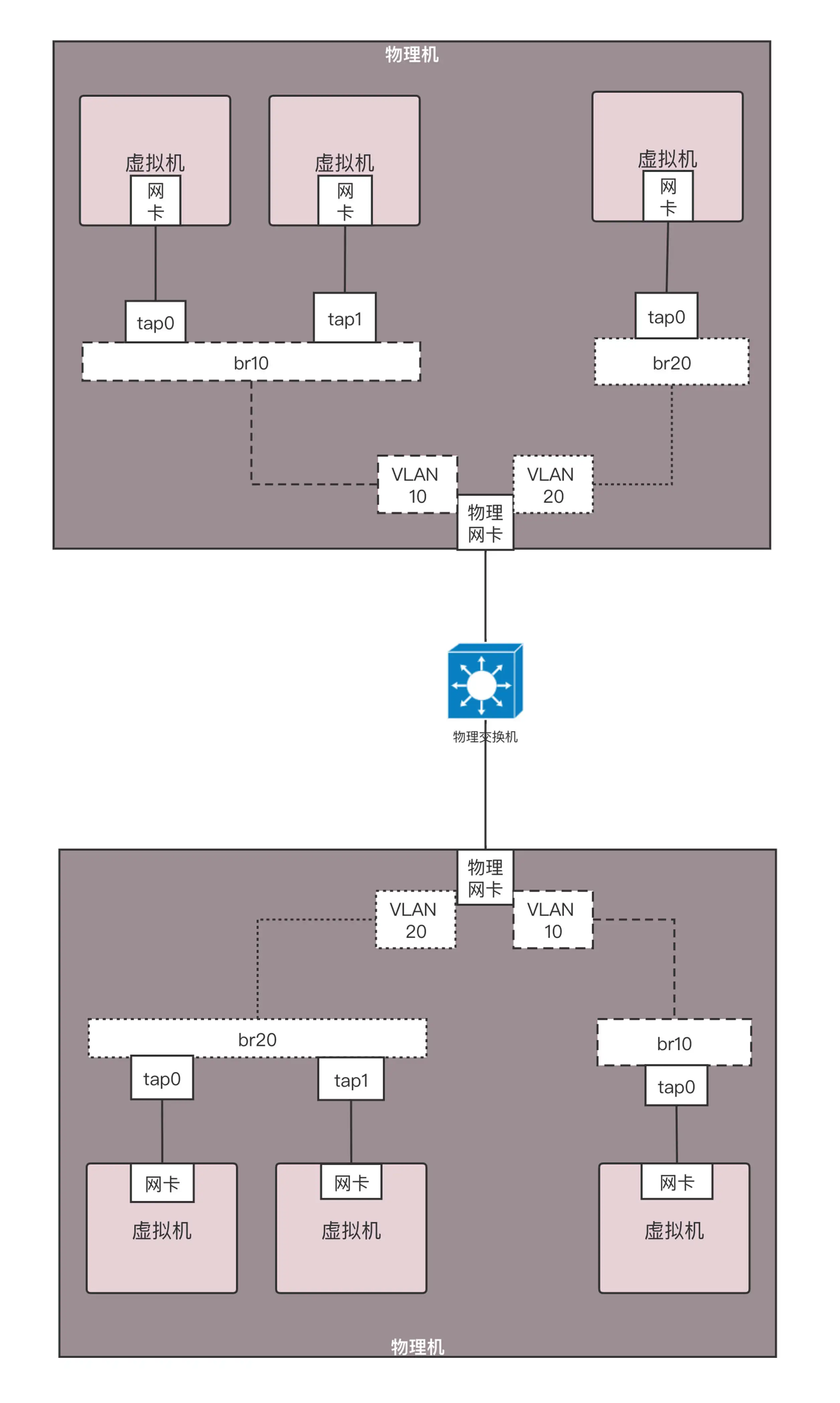
首先为每个用户分配不同的 VLAN,例如有一个用户 VLAN 10,一个用户 VLAN 20。在一台物理机上,基于物理网卡,为每个用户用 vconfig 创建一个带 VLAN 的网卡。不同的用户使用不同的虚拟网桥,带 VLAN 的虚拟网卡也连接到虚拟网桥上
这样是否能保证两个用户的隔离性呢?不同的用户由于网桥不通,不能相互通信,一旦出了网桥,由于 VLAN 不同,也不会将包转发到另一个网桥上。另外,出了物理机,也是带着 VLAN ID 的。只要物理交换机也是支持 VLAN 的,到达另一台物理机的时候,VLAN ID 依然在,它只会将包转发给相同 VLAN 的网卡和网桥,所以跨物理机,不同的 VLAN 也不会相互通信。
使用 brctl 创建出来的网桥功能是简单的,基于 VLAN 的虚拟网卡也能实现简单的隔离。但是这都不是大规模云平台能够满足的,一个是 VLAN 的隔离,数目太少。前面我们学过,VLAN ID 只有 4096 个,明显不够用。另外一点是这个配置不够灵活。谁和谁通,谁和谁不通,流量的隔离也没有实现,还有大量改进的空间。
软件定义网络:共享基础设施的小区物业管理办法
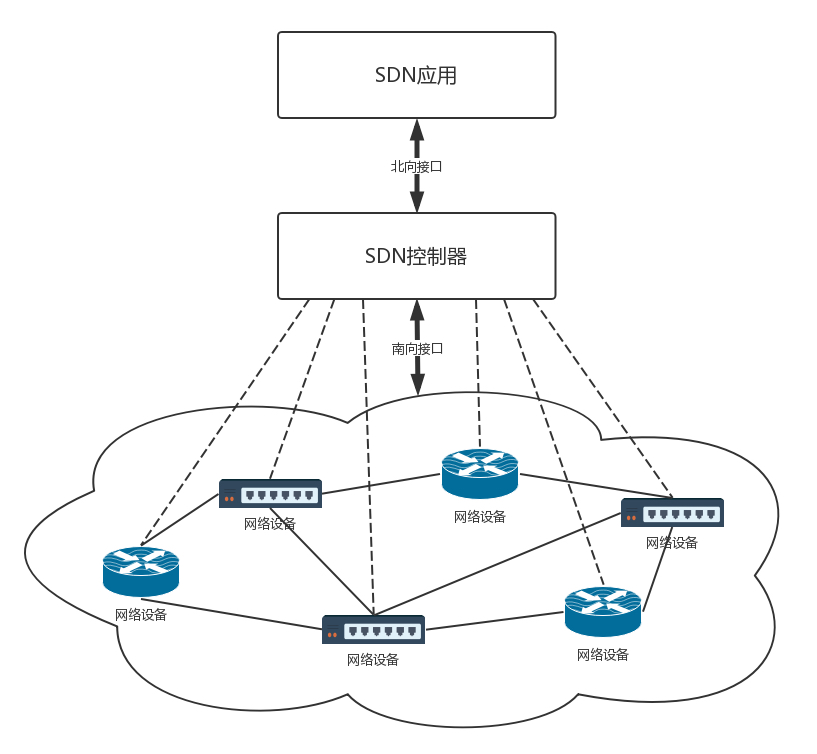
软件定义网络(SDN)
软件定义网络(SDN)。它主要有以下三个特点。
-
控制与转发分离:转发平面就是一个个虚拟或者物理的网络设备,就像小区里面的一条条路。控制平面就是统一的控制中心,就像小区物业的监控室。它们原来是一起的,物业管理员要从监控室出来,到路上去管理设备,现在是分离的,路就是走人的,控制都在监控室。
-
控制平面与转发平面之间的开放接口:控制器向上提供接口,被应用层调用,就像总控室提供按钮,让物业管理员使用。控制器向下调用接口,来控制网络设备,就像总控室会远程控制电梯的速度。这里经常使用两个名词,前面这个接口称为北向接口,后面这个接口称为南向接口,上北下南嘛。
-
逻辑上的集中控制:逻辑上集中的控制平面可以控制多个转发面设备,也就是控制整个物理网络,因而可以获得全局的网络状态视图,并根据该全局网络状态视图实现对网络的优化控制,就像物业管理员在监控室能够看到整个小区的情况,并根据情况优化出入方案。
OpenFlow 和 OpenvSwitch
SDN 有很多种实现方式,我们来看一种开源的实现方式。OpenFlow 是 SDN 控制器和网络设备之间互通的南向接口协议,OpenvSwitch 用于创建软件的虚拟交换机。OpenvSwitch 是支持 OpenFlow 协议的,当然也有一些硬件交换机也支持 OpenFlow 协议。它们都可以被统一的 SDN 控制器管理,从而实现物理机和虚拟机的网络连通。
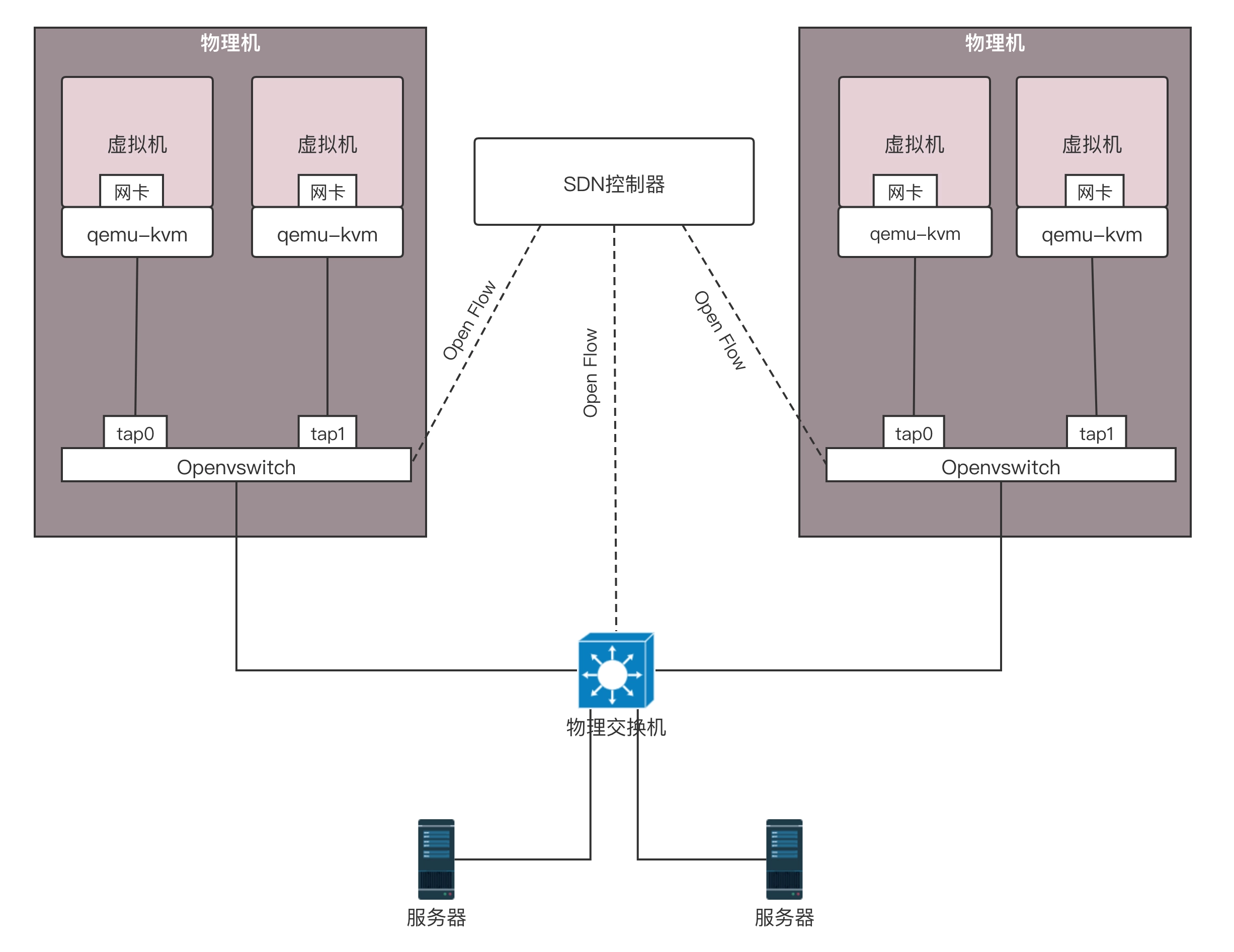
SDN 控制器是如何通过 OpenFlow 协议控制网络的呢?
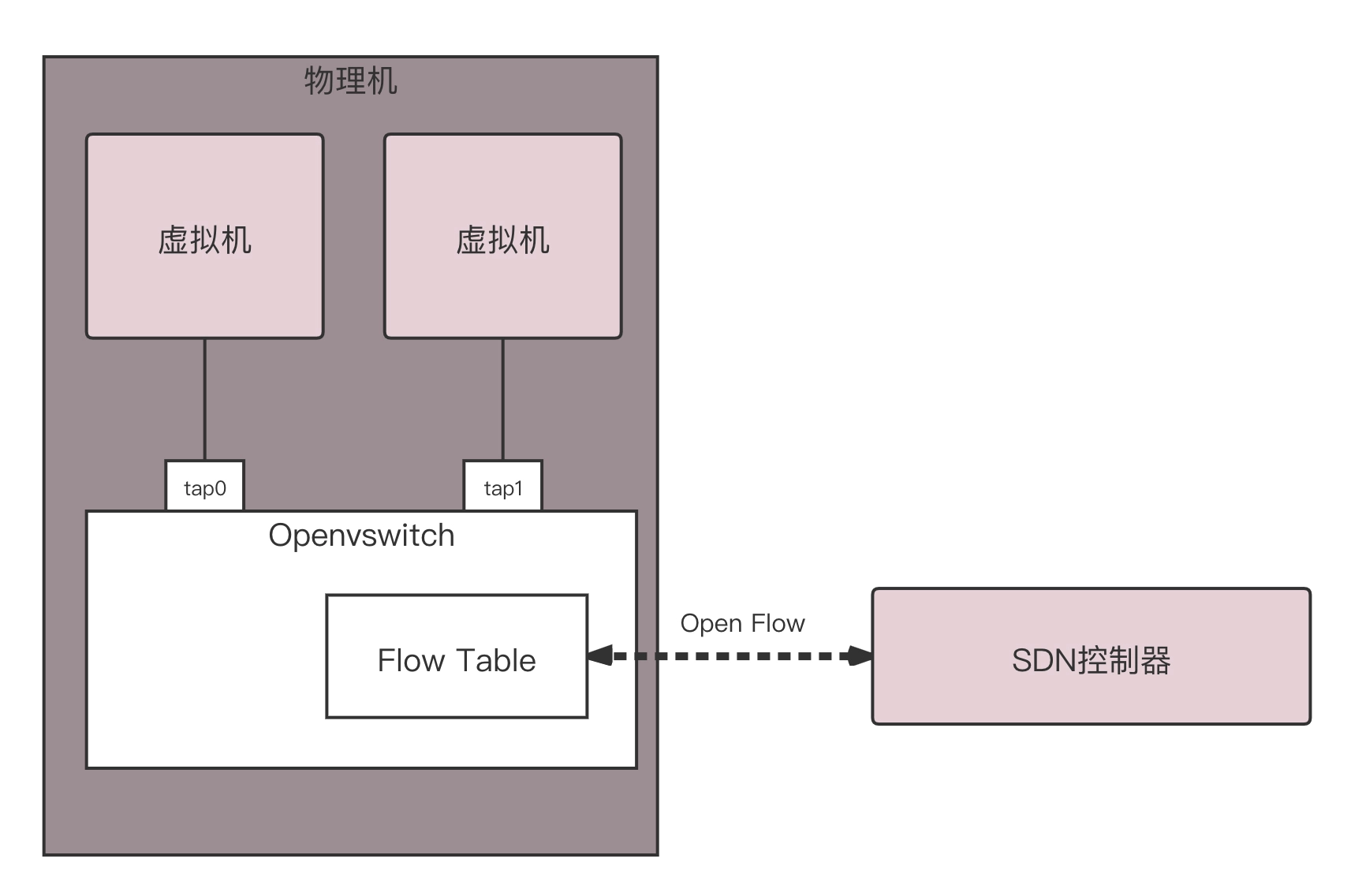
在 OpenvSwitch 里面,有一个流表规则,任何通过这个交换机的包,都会经过这些规则进行处理,从而接收、转发、放弃。那流表长啥样呢?其实就是一个个表格,每个表格好多行,每行都是一条规则。每条规则都有优先级,先看高优先级的规则,再看低优先级的规则。
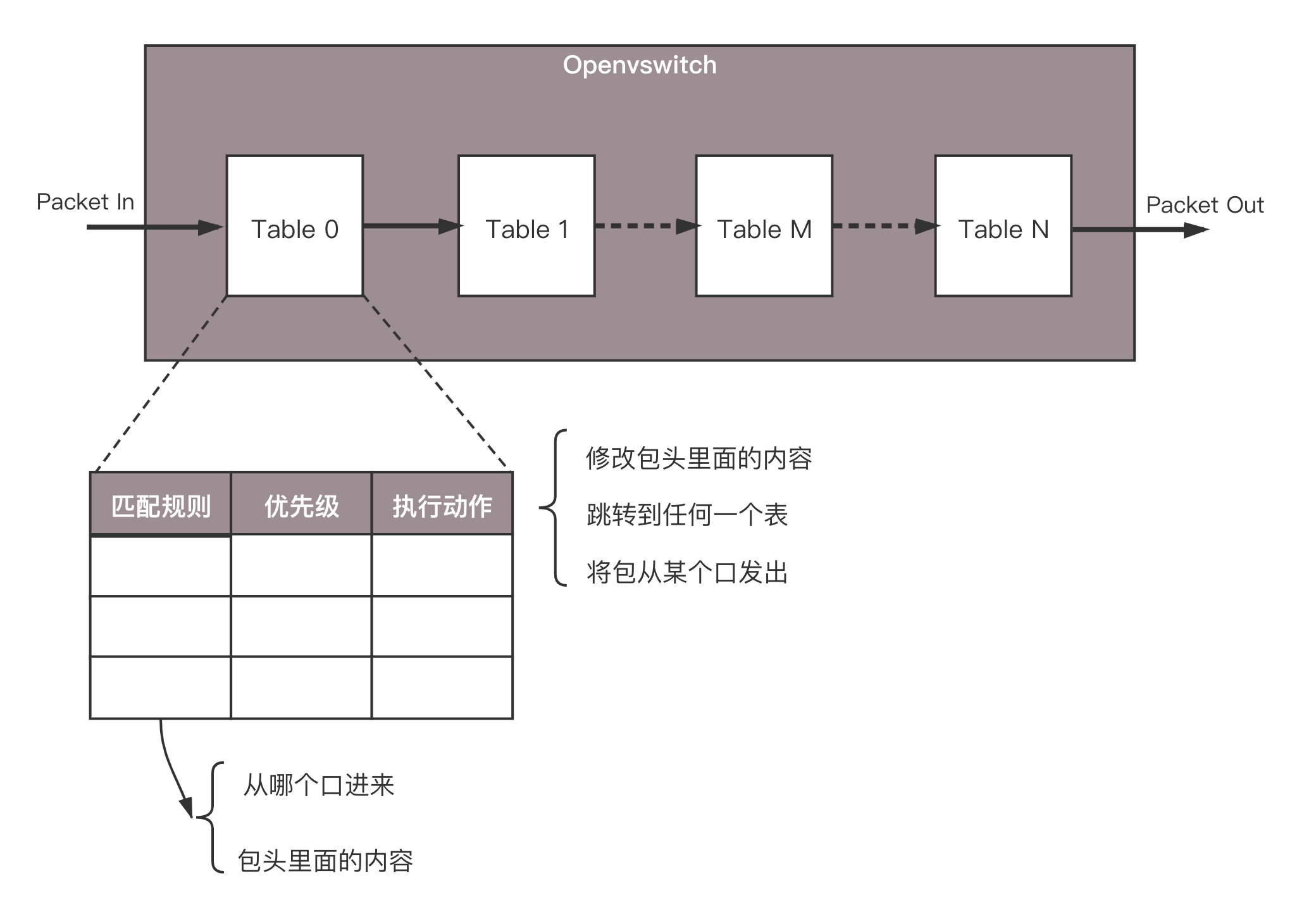
通过这些表格,可以对收到的网络包随意处理。
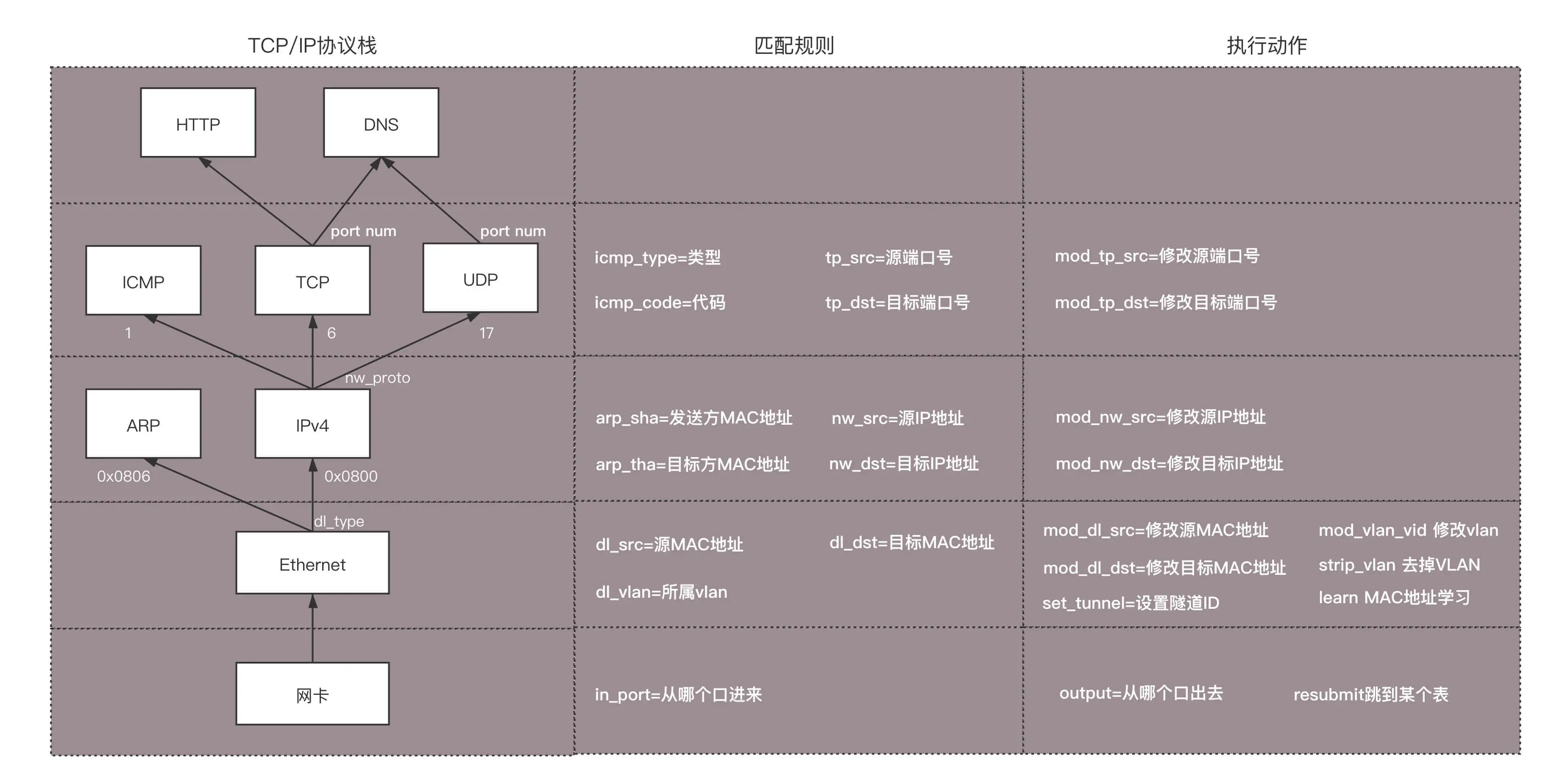
具体都能做什么处理呢?通过上面的表格可以看出,简直是想怎么处理怎么处理,可以覆盖 TCP/IP 协议栈的四层。
对于物理层:
- 匹配规则包括从哪个口进来;
- 执行动作包括从哪个口出去。
对于 MAC 层:
- 匹配规则包括:源 MAC 地址是多少?(dl_src),目标 MAC 是多少?(dl_dst),所属 vlan 是多少?(dl_vlan);
- 执行动作包括:修改源 MAC(mod_dl_src),修改目标 MAC(mod_dl_dst),修改 VLAN(mod_vlan_vid),删除 VLAN(strip_vlan),MAC 地址学习(learn)。
对于网络层:
- 匹配规则包括:源 IP 地址是多少?(nw_src),目标 IP 是多少?(nw_dst)。
- 执行动作包括:修改源 IP 地址(mod_nw_src),修改目标 IP 地址(mod_nw_dst)。
对于传输层:
- 匹配规则包括:源端口是多少?(tp_src),目标端口是多少?(tp_dst)。
- 执行动作包括:修改源端口(mod_tp_src),修改目标端口(mod_tp_dst)
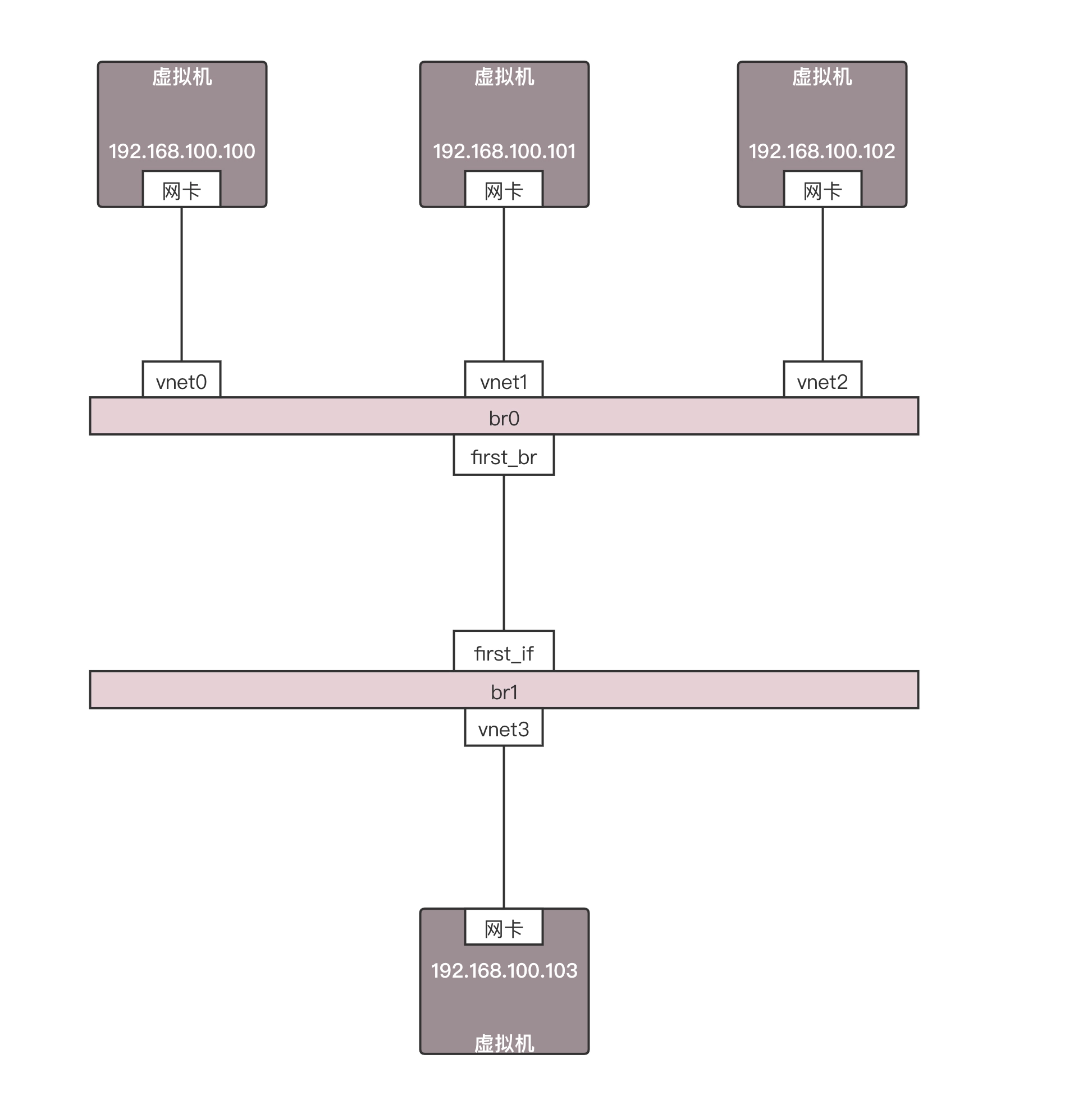
实验一:用 OpenvSwitch 实现 VLAN 的功能
在 OpenvSwitch 中端口 port 分两种,分别叫做 access port 和 trunk port。
第一类是 access port:
- 这个端口可以配置一个 tag,其实就是一个 VLAN ID,从这个端口进来的包都会被打上这个 tag;
- 如果网络包本身带有某个 VLAN ID 并且等于这个 tag,则这个包就会从这个 port 发出去;
- 从 access port 发出的包就会把 VLAN ID 去掉。
第二类是 trunk port:
- 这个 port 是不配置任何 tag 的,配置叫 trunks 的参数;
- 如果 trunks 为空,则所有的 VLAN 都 trunk,也就意味着对于所有的 VLAN 的包,无论本身带什么 VLAN ID,我还是让他携带着这个 VLAN ID,如果没有设置 VLAN,就属于 VLAN 0,全部允许通过;
- 如果 trunks 不为空,则仅仅允许带着这些 VLAN ID 的包通过。
我们通过以下命令创建如下的环境:
ovs-vsctl add-port br0 first_br
ovs-vsctl add-port br0 second_br
ovs-vsctl add-port br0 third_br
ovs-vsctl set Port vnet0 tag=101
ovs-vsctl set Port vnet1 tag=102
ovs-vsctl set Port vnet2 tag=103
ovs-vsctl set Port first_br tag=103
ovs-vsctl clear Port second_br tag
ovs-vsctl set Port third_br trunks=101,102
另外要配置禁止 MAC 地址学习。
ovs-vsctl set bridge br0 flood-vlans=101,102,103
这样就形成了如下的拓扑图,有三个虚拟机,有三个网卡,都连到一个叫 br0 的网桥上,并且他们被都打了不同的 VLAN tag。
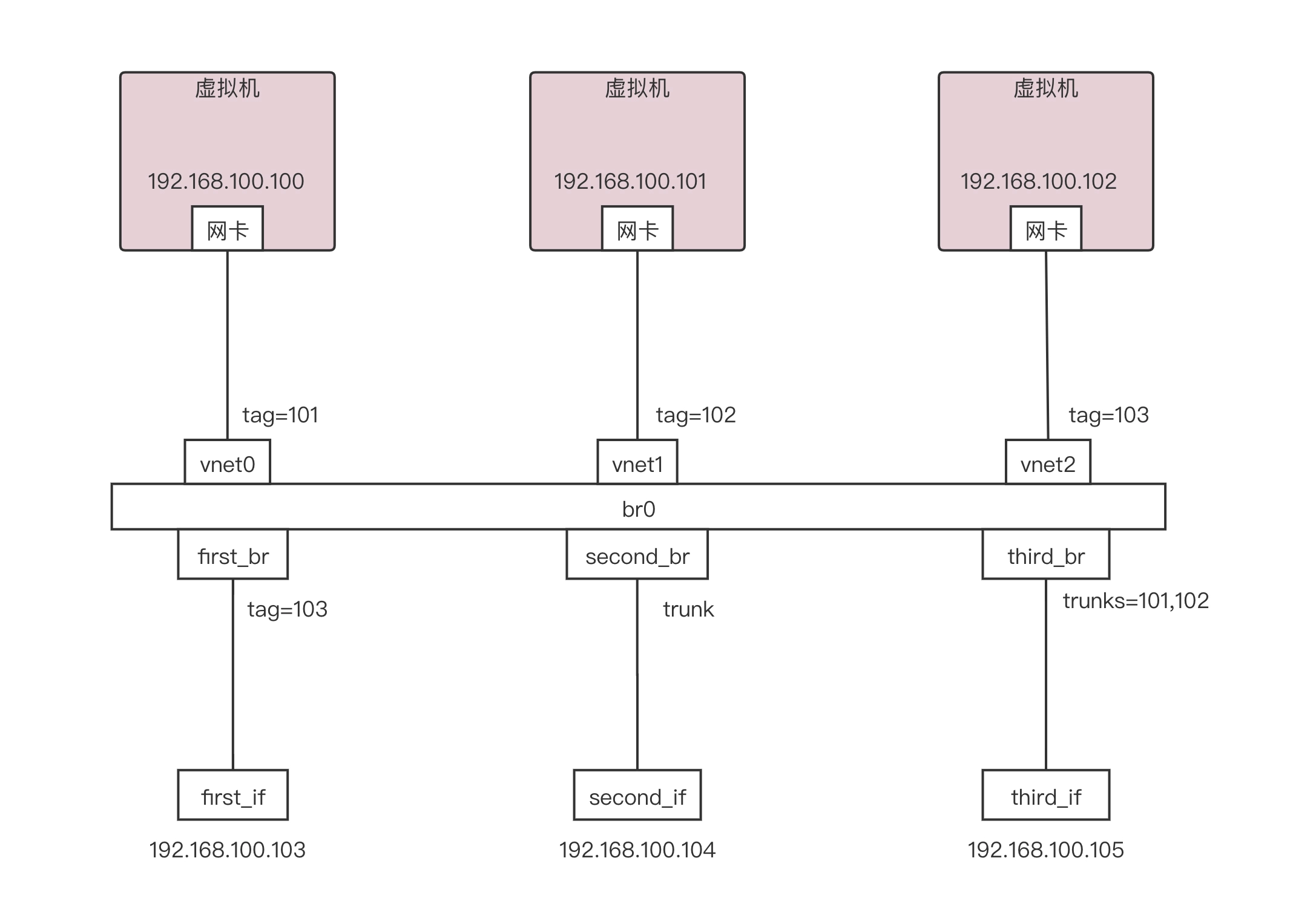
从 192.168.100.102 来 ping 192.168.100.103
-
由于 192.168.100.102 和 first_br 都配置了 tag103,也就是说他们都属于同一个 VLAN 103 的,因而这个 first_if 是能够收到包的。但是 first_if 会拒绝丢弃包,因为从 first_br 出来的包头是没有带 VLAN ID 的。
-
由于 second_br 是 trunk port,所有的 VLAN 都会放行,因而 second_if 也是能收到包的,并且根据 trunk port 的规则,出来的包的包头里面是带有 VLAN ID 的。
-
由于 third_br 仅仅配置了允许 VLAN 101 和 102 通过,不允许 103 通过,因而 third_if 他是收不到包的。
从 192.168.100.100 来 ping 192.168.100.105
-
因为 second_br 是配置了 trunk 的,是全部放行的,所以说 second_if 是可以收到包的。
-
那 third_br 是配置了可以放行 VLAN 101 和 102,所以说 third_if 是可以收到包的。当然 ping 不通,因为从 third_br 出来的包是带 VLAN 的,而 third_if 他本身不属于某个 VLAN,所以说他 ping 不通,但是能够收到包
-
first_br 是属于 VLAN 103 的,因而 first_if 是收不到包的。
192.168.100.101 来 ping 192.168.100.104
-
因为 192.168.100.101 是属于 VLAN 102 的, 因而 second_if 和 third_if 都因为配置了 trunk,是都可以收到包的。
-
first_br 是属于 VLAN 103 的,他不属于 VLAN 102,所以 first_if 是收不到包的。
-
second_br 能够收到包,并且包头里面是带 VLAN ID 102 的。third_if 也能收到包,并且包头里面也是带 VLAN ID 102 的。
实验二:用 OpenvSwitch 模拟网卡绑定,连接交换机
在前面,我们还说过,为了高可用,可以使用网卡绑定,连接到交换机,OpenvSwitch 也可以模拟这一点。
在 OpenvSwitch 里面,有个 bond_mode,可以设置为以下三个值:
- active-backup:一个连接是 active,其他的是 backup,只有当 active 失效的时候,backup 才顶上;
- balance-slb:流量按照源 MAC 和 output VLAN 进行负载均衡;
- balance-tcp:必须在支持 LACP 协议的情况下才可以,可根据 L2、L3、L4 进行负载均衡(L2、L3、L4 指的是网络协议 2、3、4 层)
我们搭建一个测试环境。这个测试环境是两台虚拟机连接到 br0 上,另外两台虚拟机连接到 br1 上,br0 和 br1 之间通过两条通路进行 bond(绑定)。形成如下的拓扑图。
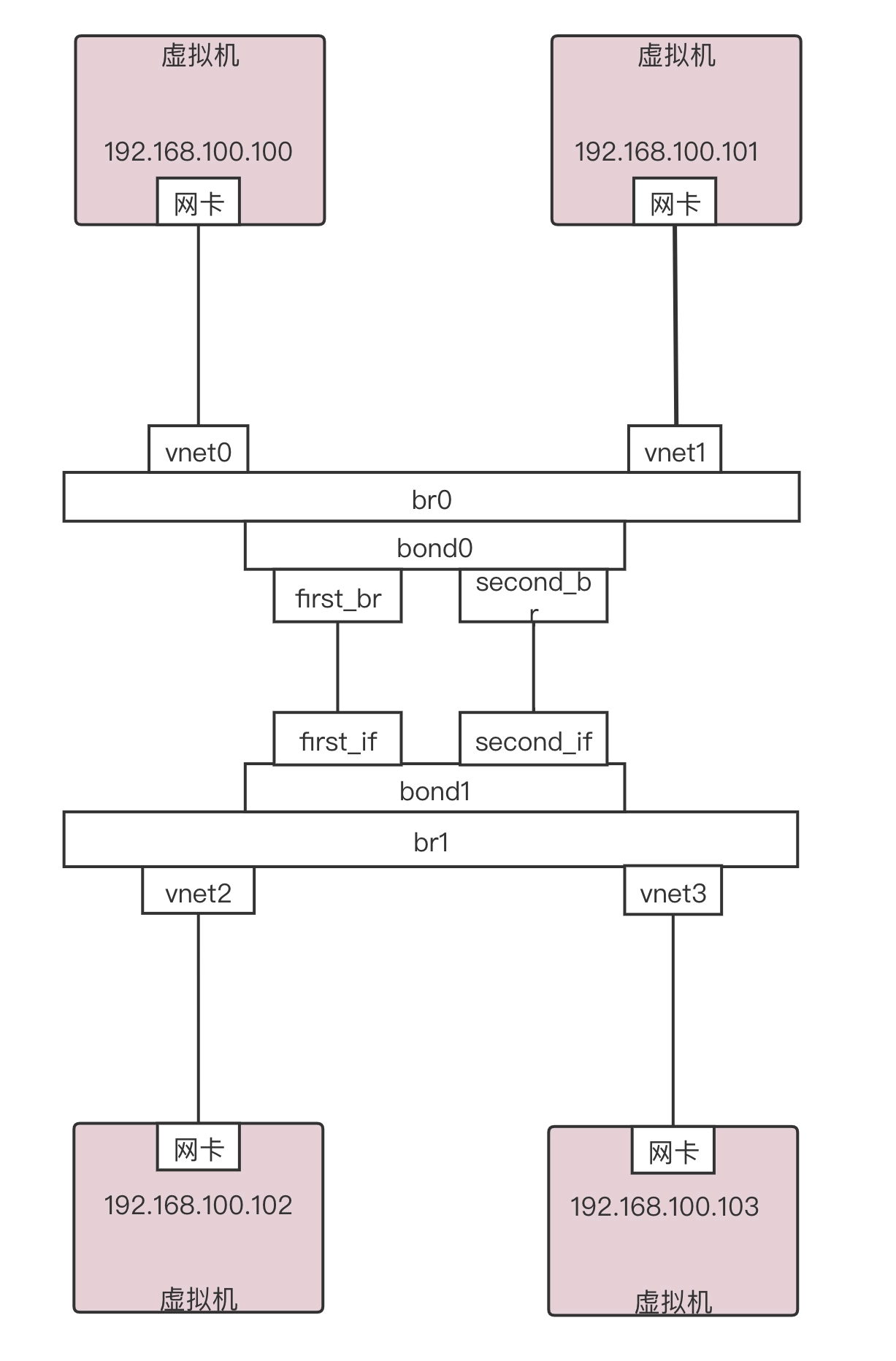
我们使用下面的命令,建立 bond 连接。
ovs-vsctl add-bond br0 bond0 first_br second_br
ovs-vsctl add-bond br1 bond1 first_if second_if
ovs-vsctl set Port bond0 lacp=active
ovs-vsctl set Port bond1 lacp=active
默认情况下 bond_mode 是 active-backup 模式,一开始 active 的是左面这条路,也即 first_br 和 first_if 这条路。
这个时候如果我们从 192.168.100.100 来 ping 192.168.100.102,以及从 192.168.100.101 来 ping 192.168.100.103 的时候,我从 tcpdump 可以看到所有的包都是从 first_if 这条路通过。接下来,如果我们把 first_if 这个网卡设成 down 的模式,则包的走向就会改变,你会发现 second_if 这条路开始有流量了,对于 192.168.100.100 和 192.168.100.101 从应用层来讲,感觉似乎没有收到影响。
如果我们通过以下命令,把 bond_mode 改为 balance-slb。然后我们同时在 192.168.100.100 来 ping 192.168.100.102,同时也在 192.168.100.101 来 ping 192.168.100.103,我们通过 tcpdump 会发现,包已经被分流了。
ovs-vsctl set Port bond0 bond_mode=balance-slb
ovs-vsctl set Port bond1 bond_mode=balance-slb
OpenvSwitch 架构图
OpenvSwitch 包含很多的模块,在用户态有两个重要的进程,也有两个重要的命令行工具。
-
第一个进程是 OVSDB 进程。ovs-vsctl 命令行会和这个进程通信,去创建虚拟交换机,创建端口,将端口添加到虚拟交换机上,OVSDB 会将这些拓扑信息保存在一个本地的文件中。
-
第二个进程是 vswitchd 进程。ovs-ofctl 命令行会和这个进程通信,去下发流表规则,规则里面会规定如何对网络包进行处理,vswitchd 会将流表放在用户态 Flow Table 中。
在内核态,OpenvSwitch 有内核模块 OpenvSwitch.ko,对应图中的 Datapath 部分。他会在网卡上注册一个函数,每当有网络包到达网卡的时候,这个函数就会被调用。
在内核的这个函数里面,会拿到网络包,将各个层次的重要信息拿出来,例如:
- 在物理层,会拿到 in_port,即包是从哪个网口进来的。;
- 在 MAC 层,会拿到源和目的 MAC 地址;
- 在 IP 层,会拿到源和目的 IP 地址;
- 在传输层,会拿到源和目的端口号。
在内核中,还有一个内核态 Flow Table。接下来内核态模块在这个内核态的流表中匹配规则,如果匹配上了,就执行相应的操作,比如修改包,或者转发,或者放弃。如果内核没有匹配上,这个时候就需要进入用户态,用户态和内核态之间通过 Linux 的一个机制叫 Netlink,来进行相互通信。
内核通过 upcall,告知用户态进程 vswitchd,在用户态的 Flow Table 里面去匹配规则,这里面的规则是全量的流表规则,而内核态的 Flow Table 只是为了做快速处理,保留了部分规则,内核里面的规则过一段时间就会过期
当在用户态匹配到了流表规则之后,就在用户态执行操作,同时将这个匹配成功的流表通过 reinject 下发到内核,从而接下来的包都能在内核找到这个规则,来进行转发。
这里调用 openflow 协议的,是本地的命令行工具。当然你也可以是远程的 SDN 控制器来进行控制,一个重要的 SDN 控制器是 OpenDaylight。
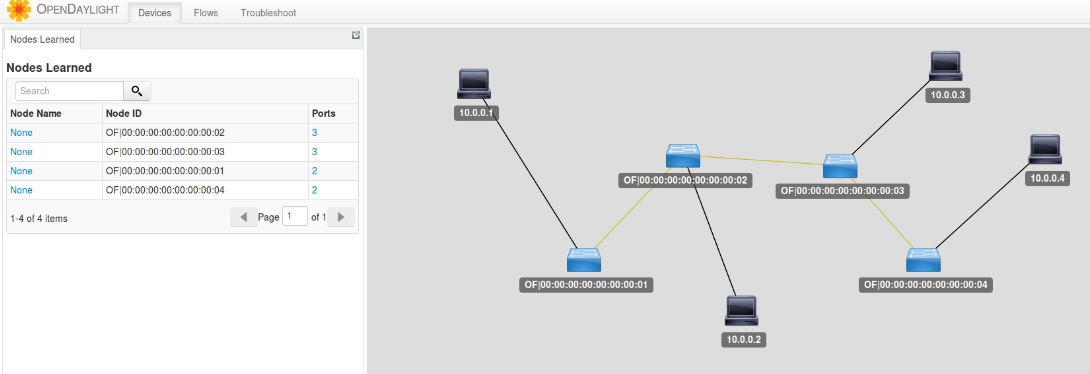
我们可以通过在 OpenDaylight 里,将两个交换机之间配置通,也可以配置不通,还可以配置一个虚拟 IP 地址为 VIP,在不同的机器之间实现负载均衡等等,所有的策略都可以灵活配置。
如何在云计算中使用 OpenvSwitch?
没有 openvSwitch 时候用户隔离问题
在没有 OpenvSwitch 的时候,如果一个新的用户要使用一个新的 VLAN,就需要创建一个属于新的 VLAN 的虚拟网卡,并且为这个租户创建一个单独的虚拟网桥,这样用户越来越多的时候,虚拟网卡和虚拟网桥会越来越多,管理就越来越复杂。
另一个问题是虚拟机的 VLAN 和物理环境的 VLAN 是透传的,也即从一开始规划的时候,这两个就需要匹配起来,将物理环境和虚拟环境强绑定,这样本来就不灵活。
OpenvSwitch 解决方案
由于 OpenvSwitch 本身就是支持 VLAN 的,这样所有的虚拟机都可以放在一个网桥 br0 上,通过不同的用户配置不同的 tag,就能够实现隔离。
另外,还可以创建一个虚拟交换机 br1,将物理网络和虚拟网络进行隔离。物理网络有物理网络的 VLAN 规划。
虚拟机在一台物理机上,所有的 VLAN 都可以从 1 开始,由于一台物理机上的虚拟机肯定不会超过 4096 个,所以 VLAN 在一台物理机上如果从 1 开始,肯定够用了。
如果物理机之间的通信和隔离还是通过 VLAN 的话,需要将虚拟机的 VLAN 和物理环境的 VLAN 对应起来,但为了灵活性,不一定一致,这样可以实现分别管理物理机的网络和虚拟机的网络。好在 OpenvSwitch 可以对包的内容进行修改。例如通过匹配 dl_vlan,然后执行 mod_vlan_vid 来改变进进出出物理机的网络包。
尽管租户多了,物理环境的 VLAN 还是不够用,但是有了 OpenvSwitch 的映射,将物理和虚拟解耦,从而可以让物理环境使用其他技术,而不影响虚拟机环境,这个我们后面再讲。
云中的网络安全:虽然不是土豪,也需要基本安全和保障
对于公有云上的虚拟机,我的建议是仅仅开放需要的端口,而将其他的端口一概关闭。这个时候,你只要通过安全措施守护好这个唯一的入口就可以了。采用的方式常常是用 ACL(Access Control List,访问控制列表)来控制 IP 和端口。
设置好了这些规则,只有指定的 IP 段能够访问指定的开放接口,就算有个有漏洞的后台进程在那里,也会被屏蔽,黑客进不来。在云平台上,这些规则的集合常称为安全组。那安全组怎么实现呢?
iptables
首先拿下 MAC 头看看,是不是我的。如果是,则拿下 IP 头来。得到目标 IP 之后呢,就开始进行路由判断。
- 在路由判断之前,这个节点我们称为 PREROUTING
- 如果发现 IP 是我的,包就应该是我的,就发给上面的传输层,这个节点叫作 INPUT
- 如果发现 IP 不是我的,就需要转发出去,这个节点称为 FORWARD。
- 如果是我的,上层处理完毕后,一般会返回一个处理结果,这个处理结果会发出去,这个节点称为 OUTPUT
- 无论是 FORWARD 还是 OUTPUT,都是路由判断之后发生的,最后一个节点是 POSTROUTING。
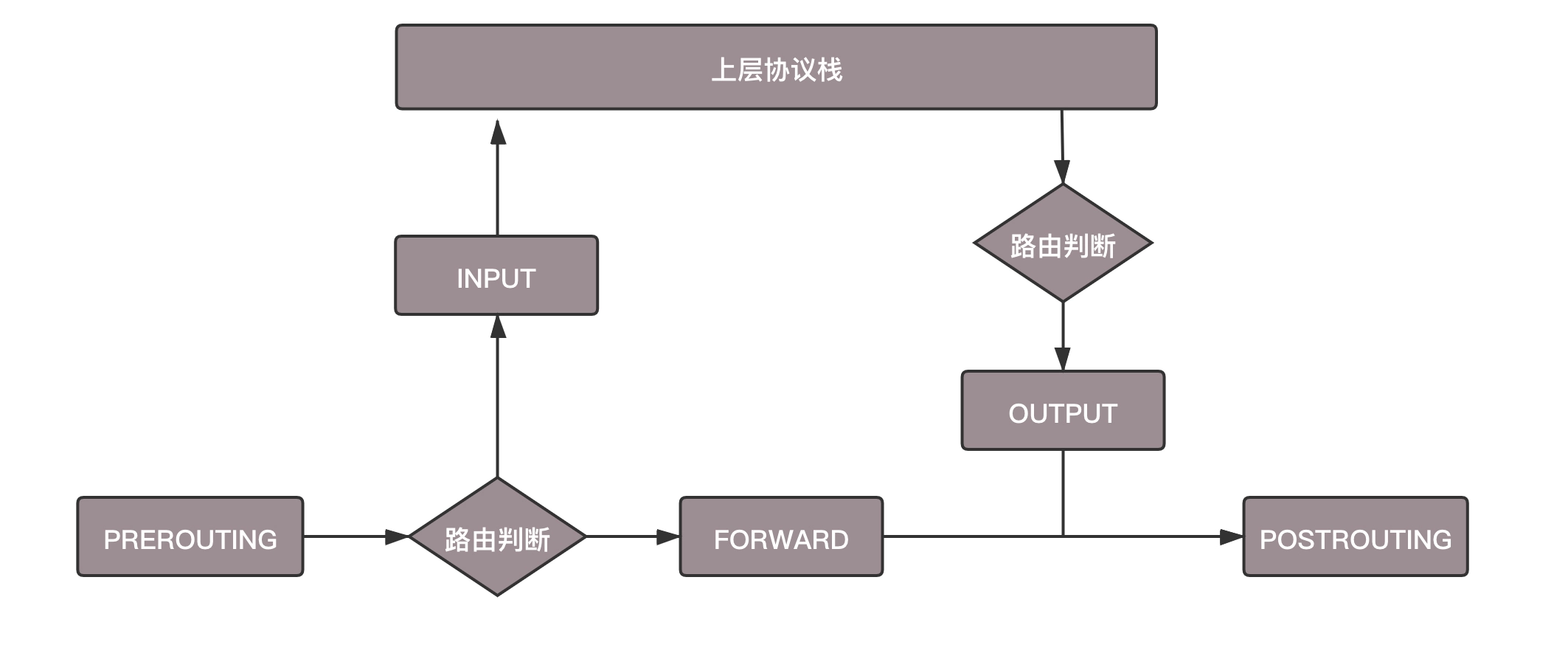
在 Linux 内核中,有一个框架叫 Netfilter。它可以在这些节点插入 hook 函数。这些函数可以截获数据包,对数据包进行干预。例如做一定的修改,然后决策是否接着交给 TCP/IP 协议栈处理;或者可以交回给协议栈,那就是 ACCEPT;或者过滤掉,不再传输,就是 DROP;还有就是 QUEUE,发送给某个用户态进程处理。
一个著名的实现,就是内核模块 ip_tables。它在这五个节点上埋下函数,从而可以根据规则进行包的处理。按功能可分为四大类:连接跟踪(conntrack)、数据包的过滤(filter)、网络地址转换(nat)和数据包的修改(mangle)。其中连接跟踪是基础功能,被其他功能所依赖。其他三个可以实现包的过滤、修改和网络地址转换。
在用户态,还有一个你肯定知道的客户端程序 iptables,用命令行来干预内核的规则。内核的功能对应 iptables 的命令行来讲,就是表和链的概念。
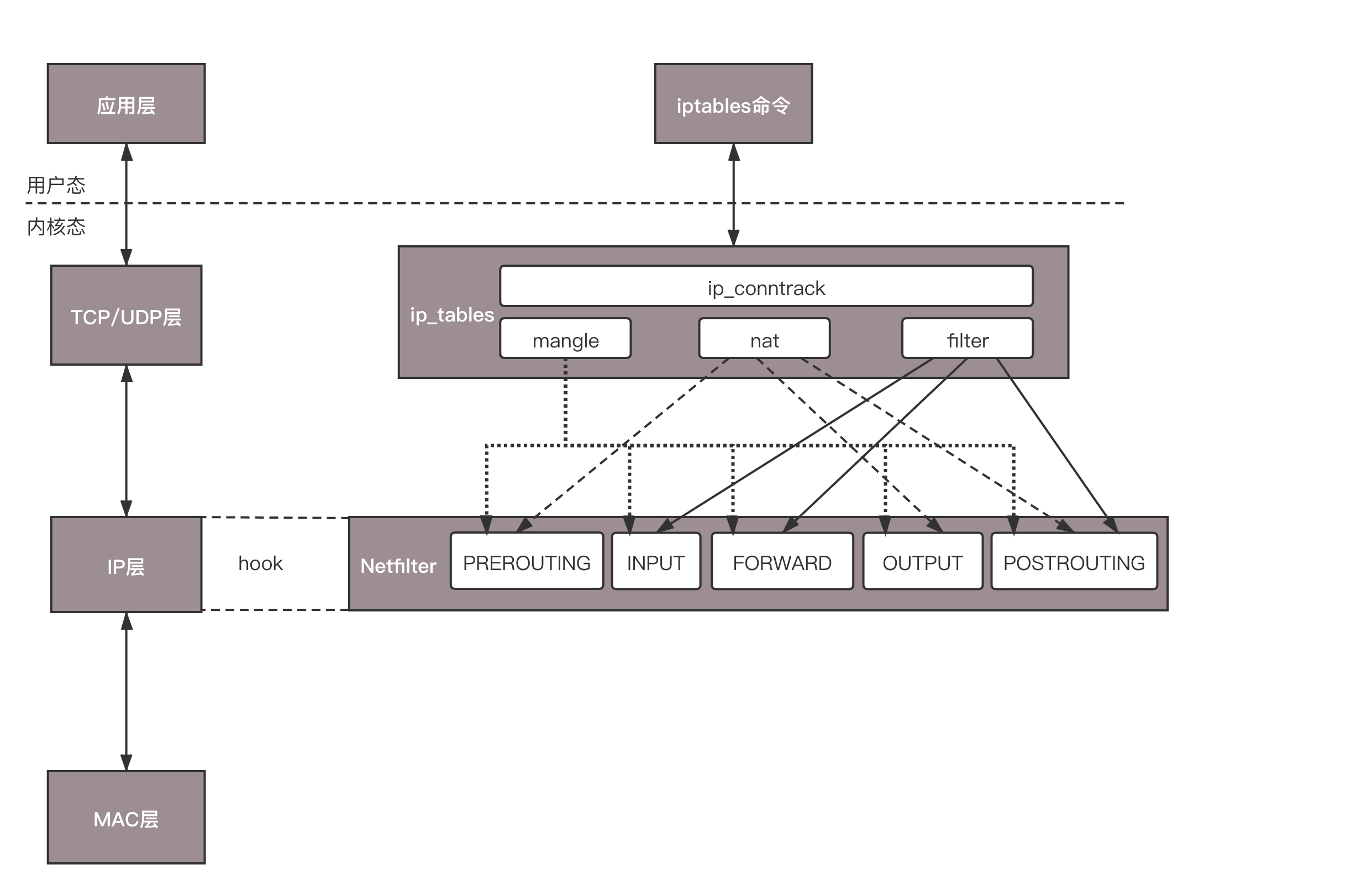
iptables 的表分为四种:raw-->mangle-->nat-->filter。这四个优先级依次降低,raw 不常用,所以主要功能都在其他三种表里实现。每个表可以设置多个链。
filter 表处理过滤功能,主要包含三个链:
- INPUT 链:过滤所有目标地址是本机的数据包;
- FORWARD 链:过滤所有路过本机的数据包;
- OUTPUT 链:过滤所有由本机产生的数据包。
nat 表主要是处理网络地址转换,可以进行 Snat(改变数据包的源地址)、Dnat(改变数据包的目标地址),包含三个链:
- PREROUTING 链:可以在数据包到达防火墙时改变目标地址;
- OUTPUT 链:可以改变本地产生的数据包的目标地址;
- POSTROUTING 链:在数据包离开防火墙时改变数据包的源地址。
mangle 表主要是修改数据包,包含:
- PREROUTING 链;
- INPUT 链;
- FORWARD 链;
- OUTPUT 链;
- POSTROUTING 链。
将 iptables 的表和链加入到上面的过程图中,就形成了下面的图和过程。
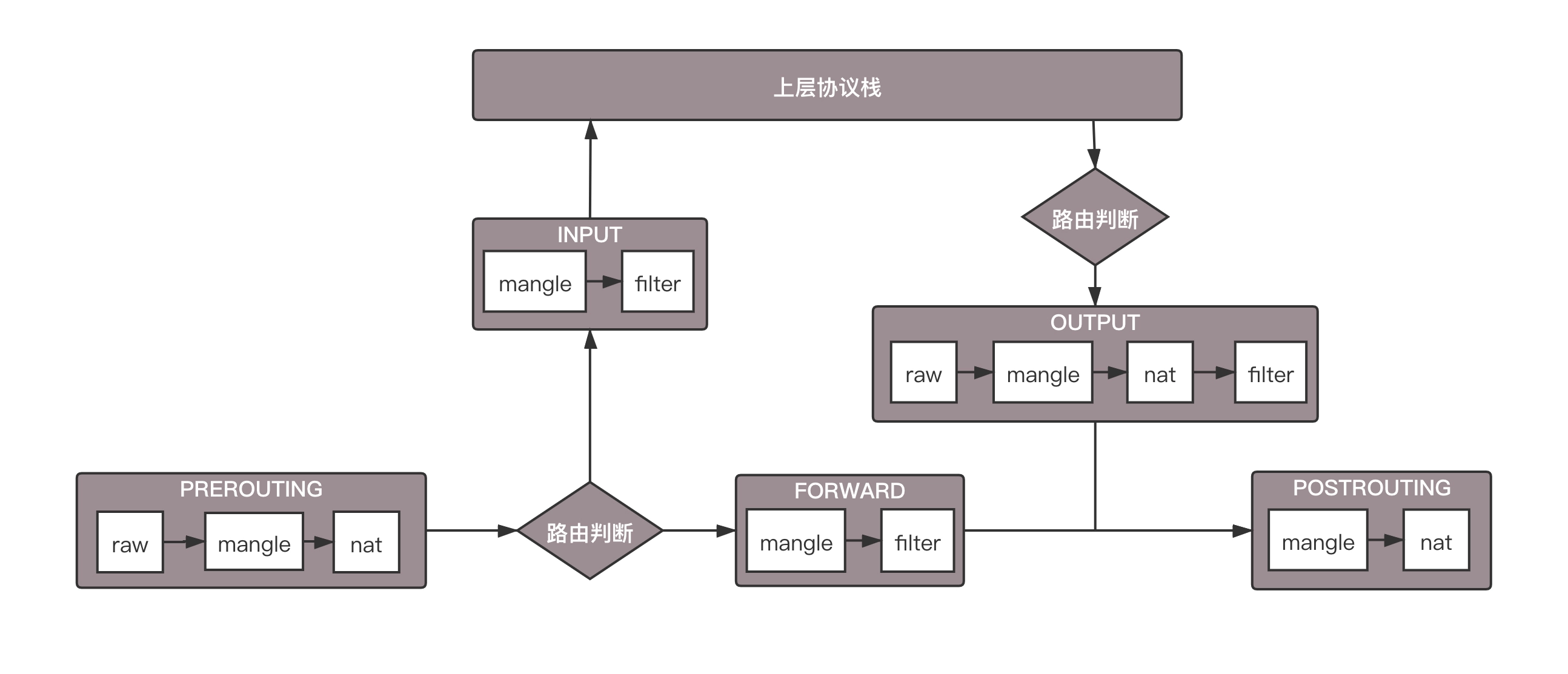
- 数据包进入的时候,先进 mangle 表的 PREROUTING 链。在这里可以根据需要,改变数据包头内容之后,进入 nat 表的 PREROUTING 链,在这里可以根据需要做 Dnat,也就是目标地址转换。
- 进入路由判断,要判断是进入本地的还是转发的。
- 如果是进入本地的,就进入 INPUT 链,之后按条件过滤限制进入。
- 之后进入本机,再进入 OUTPUT 链,按条件过滤限制出去,离开本地。
- 如果是转发就进入 FORWARD 链,根据条件过滤限制转发。
- 之后进入 POSTROUTING 链,这里可以做 Snat,离开网络接口。
使用 iptables 进行控制
有了 iptables 命令,我们就可以在云中实现一定的安全策略。例如我们可以处理前面的偷窥事件。首先我们将所有的门都关闭。
iptables -t filter -A INPUT -s 0.0.0.0/0.0.0.0 -d X.X.X.X -j DROP
-s 表示源 IP 地址段,-d 表示目标地址段,DROP 表示丢弃,也即无论从哪里来的,要想访问我这台机器,全部拒绝,谁也黑不进来。但是你发现坏了,ssh 也进不来了,都不能远程运维了,可以打开一下。
iptables -I INPUT -s 0.0.0.0/0.0.0.0 -d X.X.X.X -p tcp --dport 22 -j ACCEPT
如果这台机器是提供的是 web 服务,80 端口也应该打开,当然一旦打开,这个 80 端口就需要很好的防护,但是从规则角度还是要打开。
iptables -A INPUT -s 0.0.0.0/0.0.0.0 -d X.X.X.X -p tcp --dport 80 -j ACCEPT
如何在云平台实现 iptables 管理
这些规则都可以在虚拟机里,自己安装 iptables 自己配置。但是如果虚拟机数目非常多,都要配置,对于用户来讲就太麻烦了,能不能让云平台把这部分工作做掉呢?
当然可以了。在云平台上,一般允许一个或者多个虚拟机属于某个安全组,而属于不同安全组的虚拟机之间的访问以及外网访问虚拟机,都需要通过安全组进行过滤。
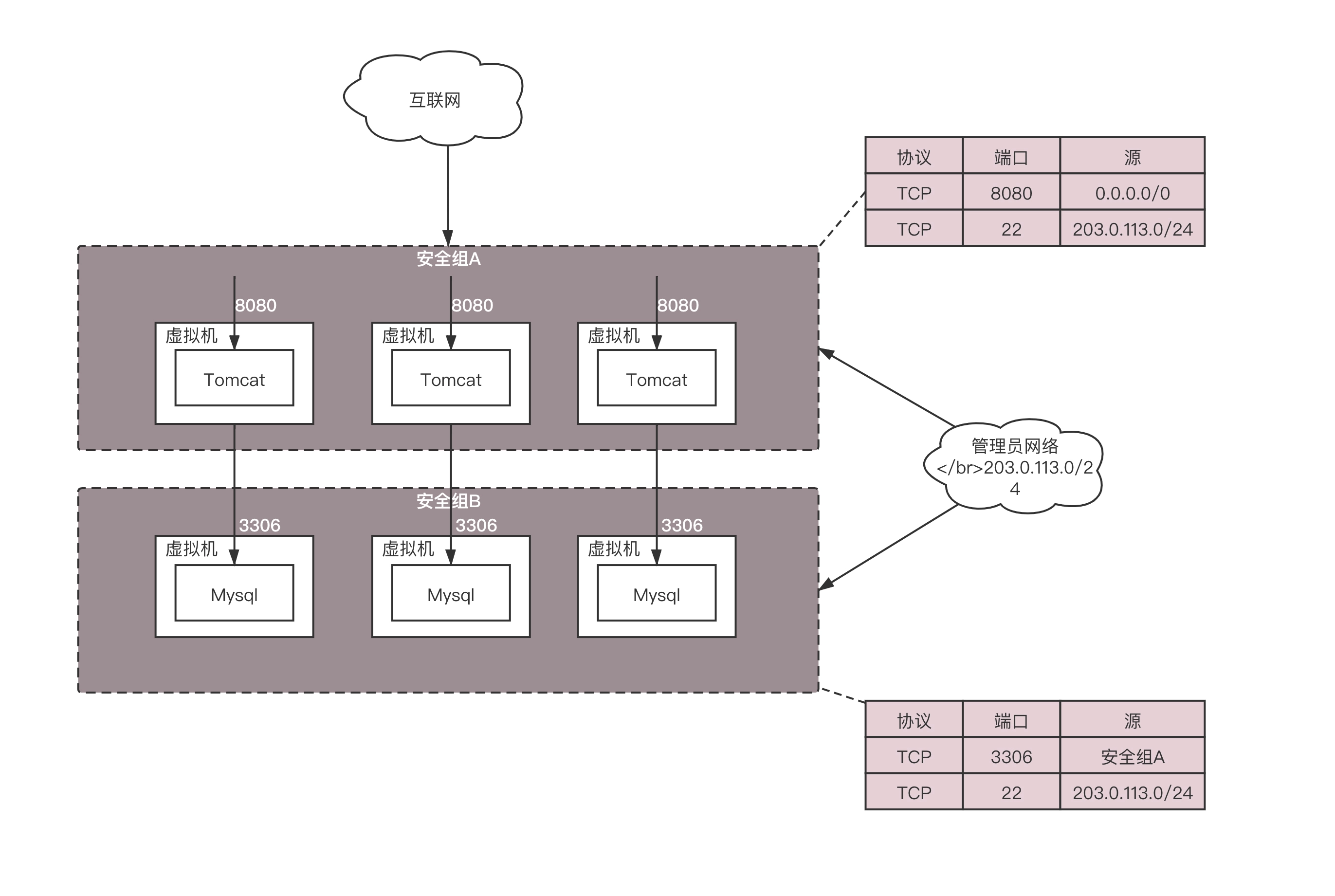
这些安全组规则都可以自动下发到每个在安全组里面的虚拟机上,从而控制一大批虚拟机的安全策略。这种批量下发是怎么做到的呢?
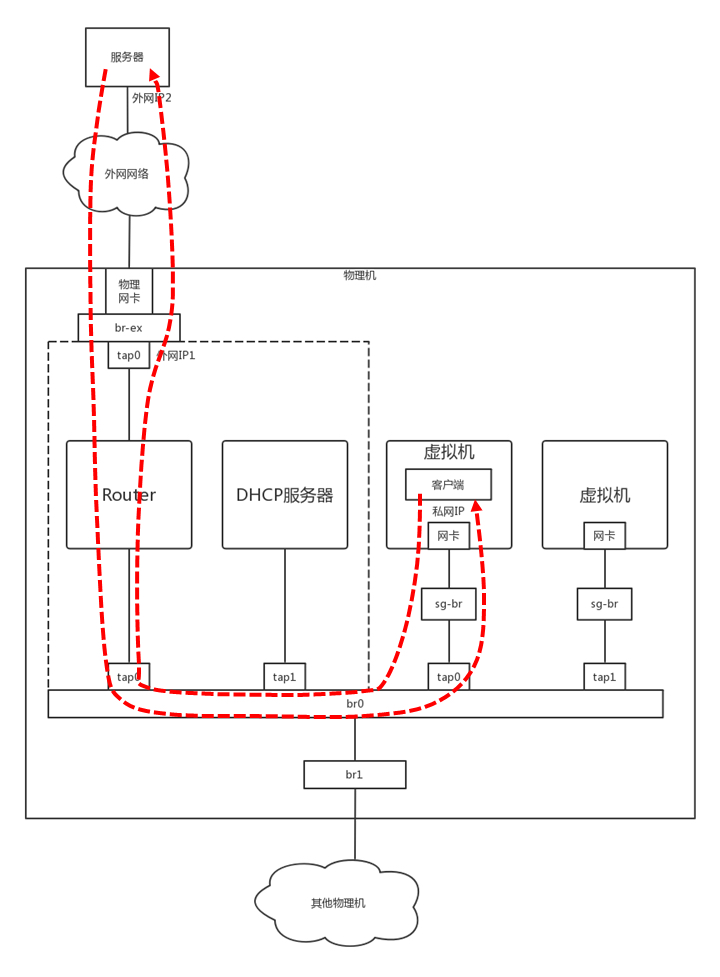
两个 VM 都通过 tap 网卡连接到一个网桥上,但是网桥是二层的,两个 VM 之间是可以随意互通的,因而需要有一个地方统一配置这些 iptables 规则。
可以多加一个网桥,在这个网桥上配置 iptables 规则,将在用户在界面上配置的规则,放到这个网桥上。然后在每台机器上跑一个 Agent,将用户配置的安全组变成 iptables 规则,配置在这个网桥上。
如何使用 iptables 进行 Nat
前面的章节我们说过,在设计云平台的时候,我们想让虚拟机之间的网络和物理网络进行隔离,但是虚拟机毕竟还是要通过物理网和外界通信的,因而需要在出物理网的时候,做一次网络地址转换,也即 nat,这个就可以用 iptables 来做。我们学过,IP 头里面包含源 IP 地址和目标 IP 地址,这两种 IP 地址都可以转换成其他地址。转换源 IP 地址的,我们称为 Snat;转换目标 IP 地址的,我们称为 Dnat。
你有没有思考过这个问题,TCP 的访问都是一去一回的,而你在你家里连接 WiFi 的 IP 地址是一个私网 IP,192.168.1.x。当你通过你们家的路由器访问 163 网站之后,网站的返回结果如何能够到达你的笔记本电脑呢?肯定不能通过 192.168.1.x,这是个私网 IP,不具有公网上的定位能力,而且用这个网段的人很多,茫茫人海,怎么能够找到你呢?
所以当你从你家里访问 163 网站的时候,在你路由器的出口,会做 Snat 的,运营商的出口也可能做 Snat,将你的私网 IP 地址,最终转换为公网 IP 地址,然后 163 网站就可以通过这个公网 IP 地址返回结果,然后再 nat 回来,直到到达你的笔记本电脑。
云平台里面的虚拟机也是这样子的,它只有私网 IP 地址,到达外网网口要做一次 Snat,转换成为机房网 IP,然后出数据中心的时候,再转换为公网 IP。
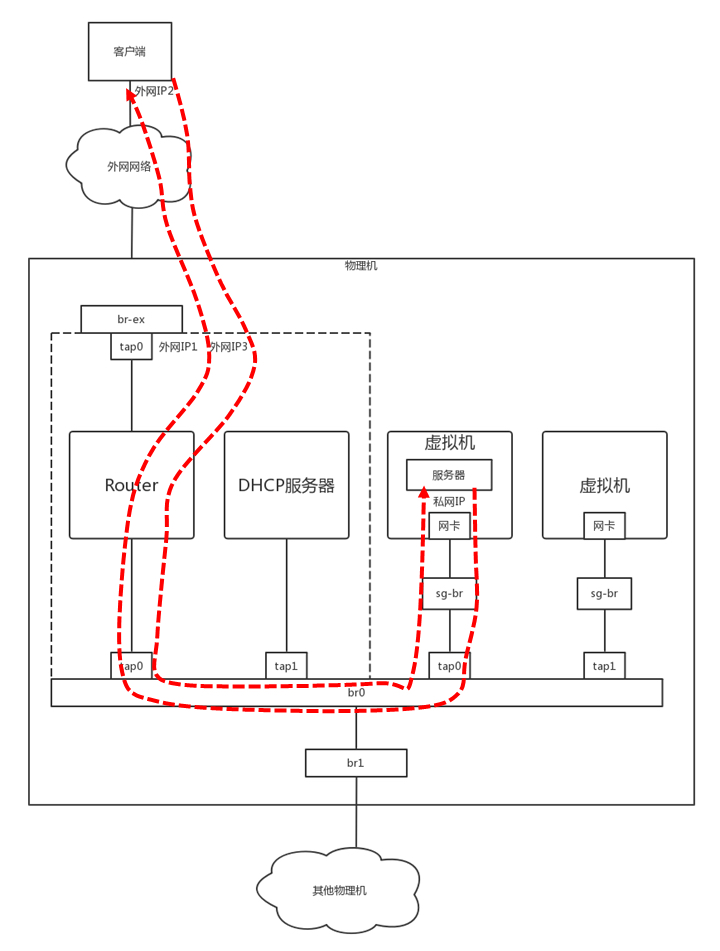
这里有一个问题是,在外网网口上做 Snat 的时候,是全部转换成一个机房网 IP 呢,还是每个虚拟机都对应一个机房网 IP,最终对应一个公网 IP 呢?前面也说过了,公网 IP 非常贵,虚拟机也很多,当然不能每个都有单独的机房网和公网 IP 了,因此这种 Snat 是一种特殊的 Snat,MASQUERADE(地址伪装)。
这种方式下,所有的虚拟机共享一个机房网和公网的 IP 地址,所有从外网网口出去的,都转换成为这个 IP 地址。那又一个问题来了,都变成一个公网 IP 了,当 163 网站返回结果的时候,给谁呢,再 nat 成为哪个私网的 IP 呢?
这就是 Netfilter 的连接跟踪(conntrack)功能了。对于 TCP 协议来讲,肯定是上来先建立一个连接,可以用“源 / 目的 IP+ 源 / 目的端口”唯一标识一条连接,这个连接会放在 conntrack 表里面。当时是这台机器去请求 163 网站的,虽然源地址已经 Snat 成公网 IP 地址了,但是 conntrack 表里面还是有这个连接的记录的。当 163 网站返回数据的时候,会找到记录,从而找到正确的私网 IP 地址。
这是虚拟机做客户端的情况,如果虚拟机做服务器呢?也就是说,如果虚拟机里面部署的就是 163 网站呢?
这个时候就需要给这个网站配置固定的物理网的 IP 地址和公网 IP 地址了。这时候就需要详细配置 Snat 规则和 Dnat 规则了。
当外部访问进来的时候,外网网口会通过 Dnat 规则将公网 IP 地址转换为私网 IP 地址,到达虚拟机,虚拟机里面是 163 网站,返回结果,外网网口会通过 Snat 规则,将私网 IP 地址转换为那个分配给它的固定的公网 IP 地址。
类似的规则如下:
- 源地址转换 (Snat):iptables -t nat -A -s 私网 IP -j Snat --to-source 外网 IP
- 目的地址转换 (Dnat):iptables -t nat -A -PREROUTING -d 外网 IP -j Dnat --to-destination 私网 IP
云中的网络QoS:邻居疯狂下电影,我该怎么办?
你租房子的时候,有没有碰到这样的情况:本来合租共享 WiFi,一个人狂下小电影,从而你网都上不去,是不是很懊恼?在云平台上,也有这种现象,好在有一种流量控制的技术,可以实现 QoS(Quality of Service),从而保障大多数用户的服务质量。
对于控制一台机器的网络的 QoS,分两个方向,一个是入方向,一个是出方向。
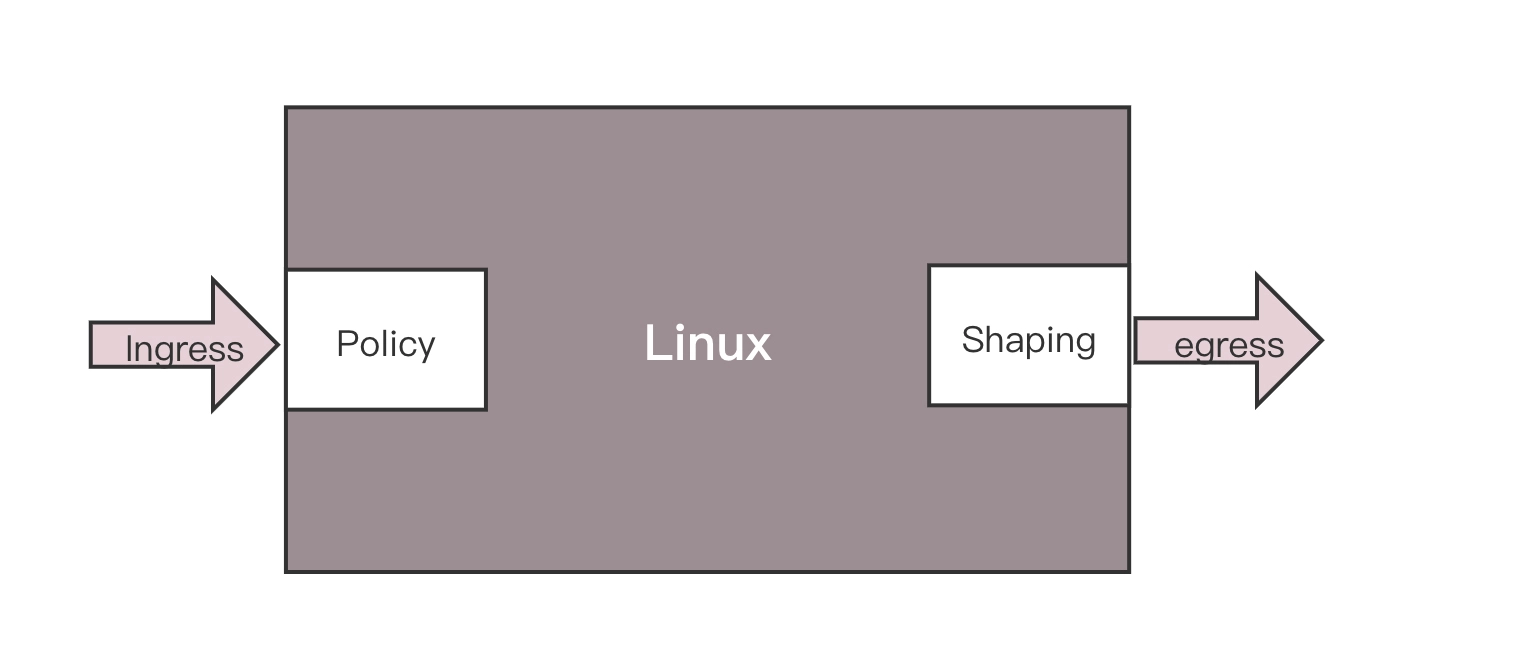
其实我们能控制的只有出方向,通过 Shaping,将出的流量控制成自己想要的模样。而进入的方向是无法控制的,只能通过 Policy 将包丢弃。
控制网络的 QoS 有哪些方式?
在 Linux 下,可以通过 TC 控制网络的 QoS,主要就是通过队列的方式。
无类别排队规则
优先级队列
第一大类称为无类别排队规则(Classless Queuing Disciplines)。还记得我们讲ip addr的时候讲过的 pfifo_fast,这是一种不把网络包分类的技术。
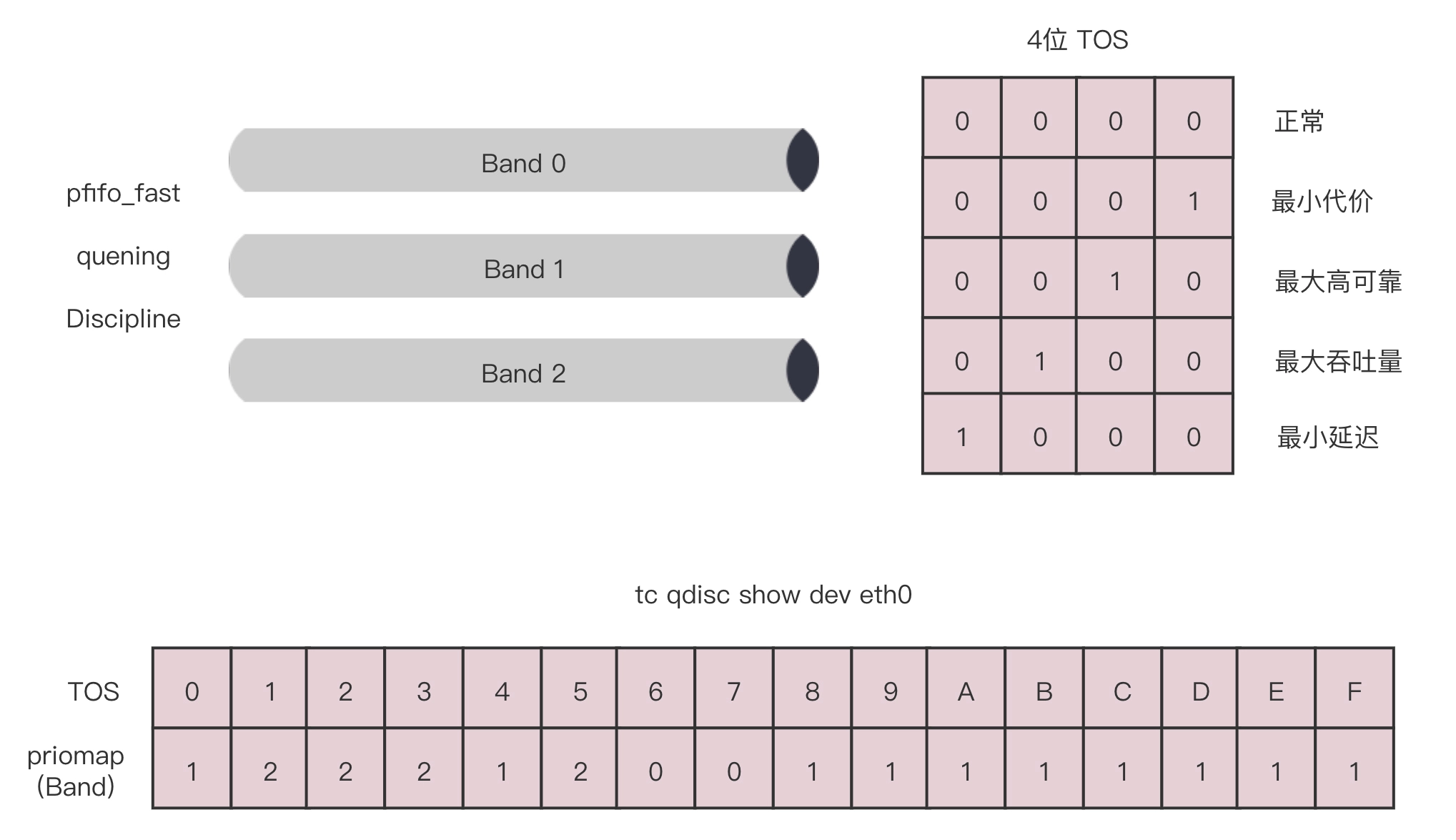
pfifo_fast 分为三个先入先出的队列,称为三个 Band。根据网络包里面 TOS,看这个包到底应该进入哪个队列。TOS 总共四位,每一位表示的意思不同,总共十六种类型。
通过命令行 tc qdisc show dev eth0,可以输出结果 priomap,也是十六个数字。在 0 到 2 之间,和 TOS 的十六种类型对应起来,表示不同的 TOS 对应的不同的队列。其中 Band 0 优先级最高,发送完毕后才轮到 Band 1 发送,最后才是 Band 2。
随机公平队列
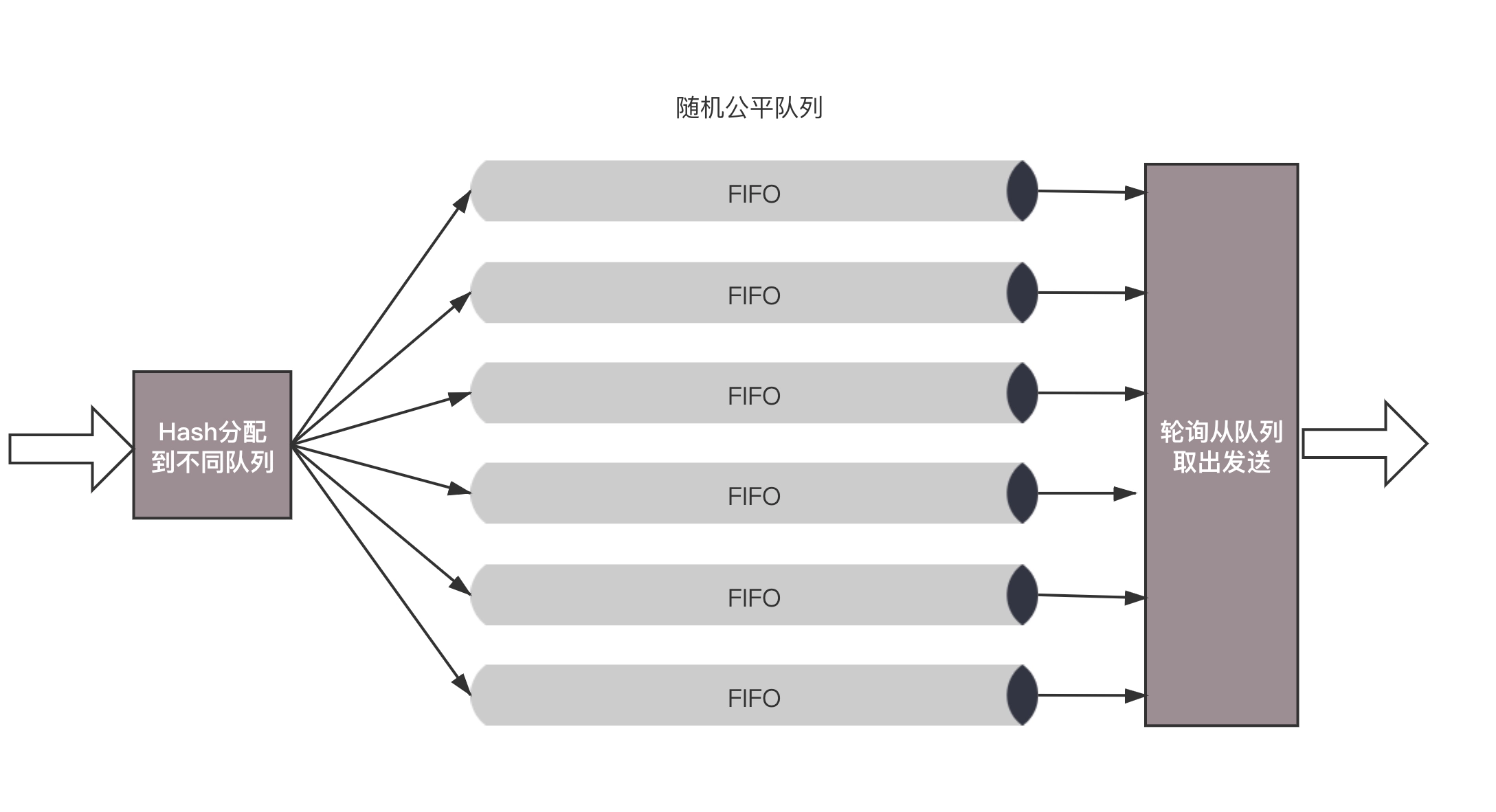
会建立很多的 FIFO 的队列,TCP Session 会计算 hash 值,通过 hash 值分配到某个队列。在队列的另一端,网络包会通过轮询策略从各个队列中取出发送。这样不会有一个 Session 占据所有的流量。
令牌桶
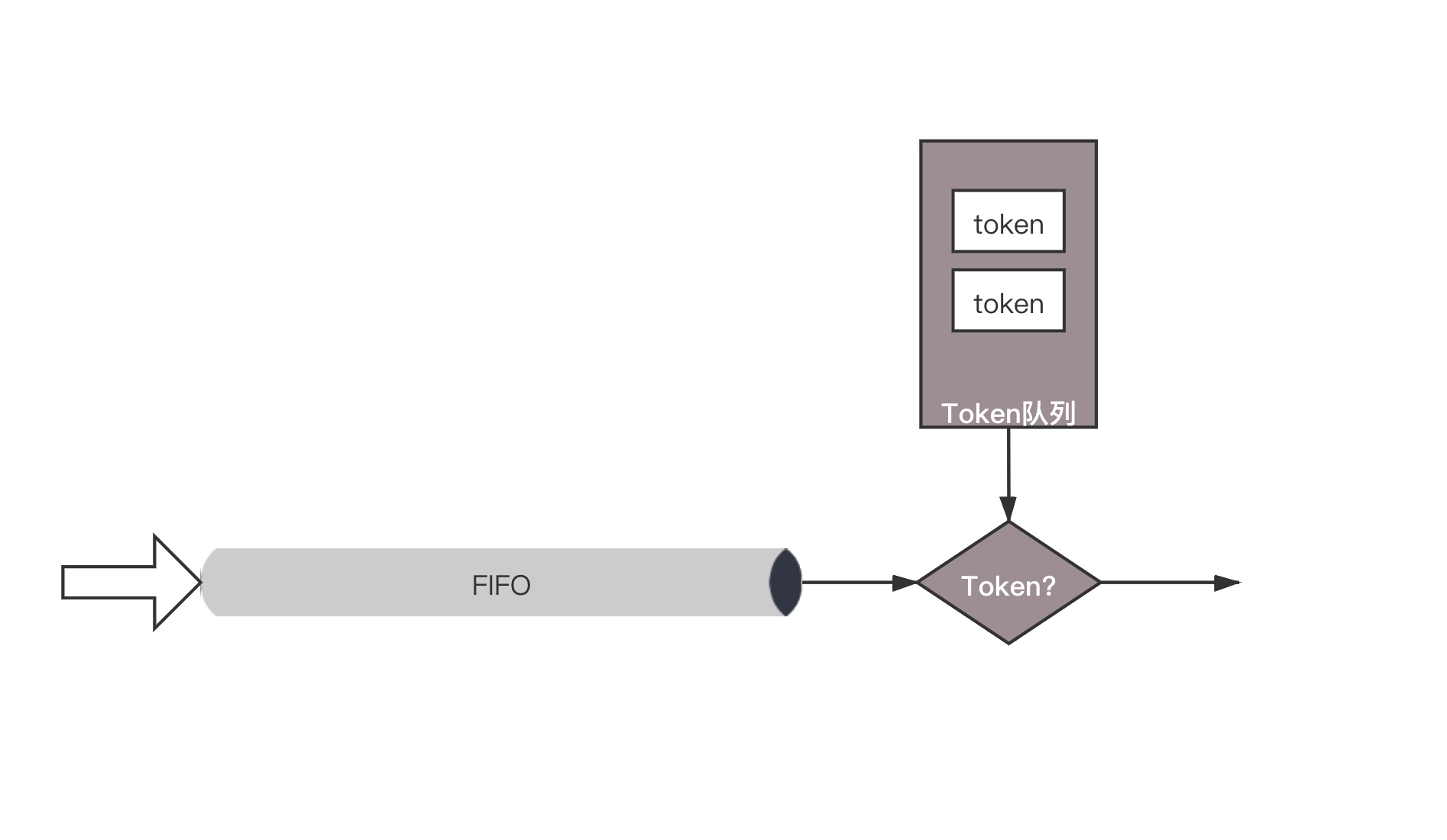
所有的网络包排成队列进行发送,但不是到了队头就能发送,而是需要拿到令牌才能发送。令牌根据设定的速度生成,所以即便队列很长,也是按照一定的速度进行发送的。
当没有包在队列中的时候,令牌还是以既定的速度生成,但是不是无限累积的,而是放满了桶为止。设置桶的大小为了避免下面的情况:当长时间没有网络包发送的时候,积累了大量的令牌,突然来了大量的网络包,每个都能得到令牌,造成瞬间流量大增。
基于类别的队列规则
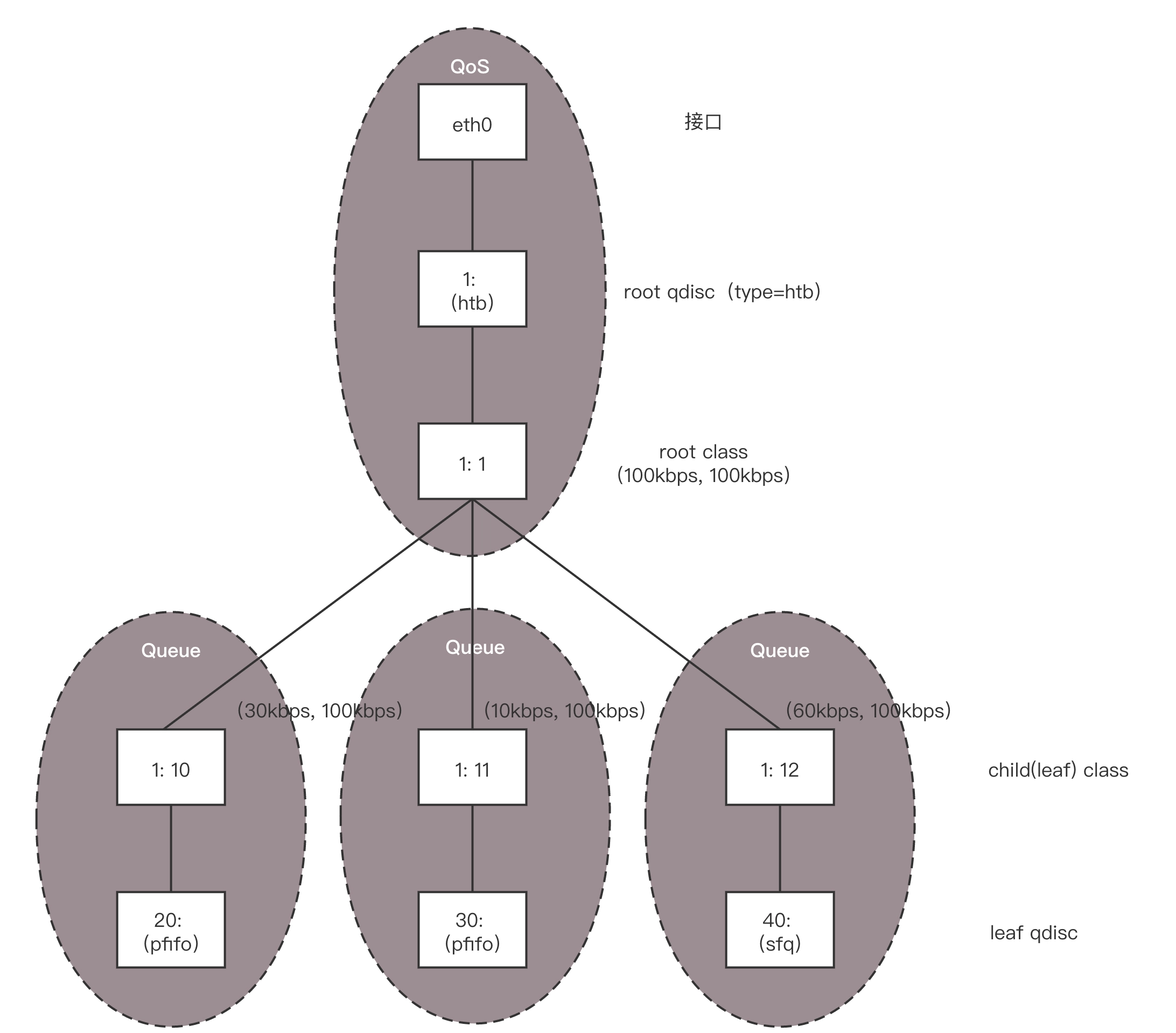
另外一大类是基于类别的队列规则(Classful Queuing Disciplines),其中典型的为分层令牌桶规则(HTB, Hierarchical Token Bucket)。
HTB 往往是一棵树,接下来我举个具体的例子,通过 TC 如何构建一棵 HTB 树来带你理解。
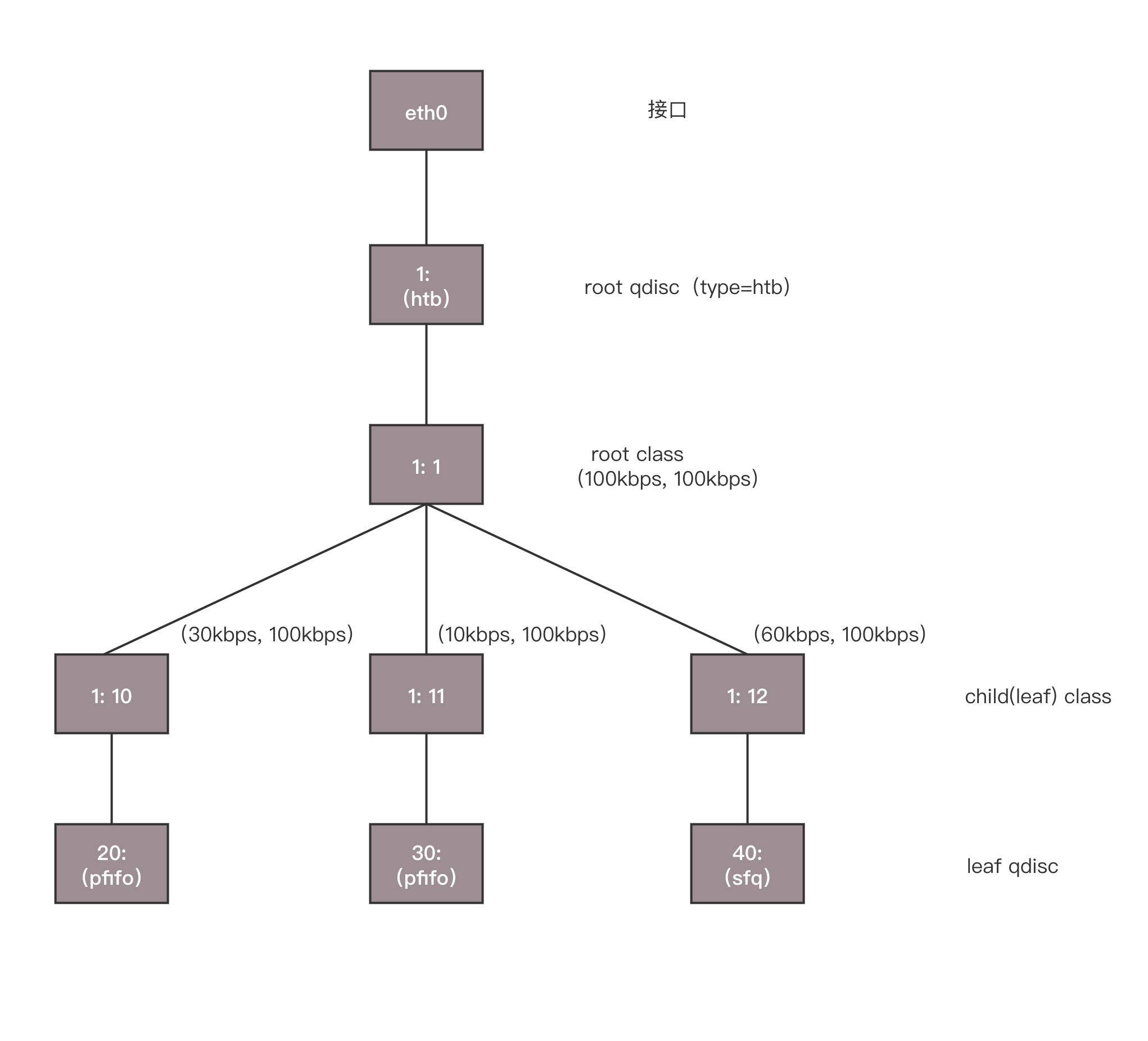
使用 TC 可以为某个网卡 eth0 创建一个 HTB 的队列规则,需要付给它一个句柄为(1:)。
这是整棵树的根节点,接下来会有分支。例如图中有三个分支,句柄分别为(:10)、(:11)、(:12)。最后的参数 default 12,表示默认发送给 1:12,也即发送给第三个分支。
tc qdisc add dev eth0 root handle 1: htb default 12
对于这个网卡,需要规定发送的速度。一般有两个速度可以配置,一个是 rate,表示一般情况下的速度;一个是 ceil,表示最高情况下的速度。对于根节点来讲,这两个速度是一样的,于是创建一个 root class,速度为(rate=100kbps,ceil=100kbps)。
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
接下来要创建分支,也即创建几个子 class。每个子 class 统一有两个速度。三个分支分别为(rate=30kbps,ceil=100kbps)、(rate=10kbps,ceil=100kbps)、(rate=60kbps,ceil=100kbps)。
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
你会发现三个 rate 加起来,是整个网卡允许的最大速度。
HTB 有个很好的特性,同一个 root class 下的子类可以相互借流量,如果不直接在队列规则下面创建一个 root class,而是直接创建三个 class,它们之间是不能相互借流量的。借流量的策略,可以使得当前不使用这个分支的流量的时候,可以借给另一个分支,从而不浪费带宽,使带宽发挥最大的作用。
最后,创建叶子队列规则,分别为 fifo 和 sfq。
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5
tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5
tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10
基于这个队列规则,我们还可以通过 TC 设定发送规则:从 1.2.3.4 来的,发送给 port 80 的包,从第一个分支 1:10 走;其他从 1.2.3.4 发送来的包从第二个分支 1:11 走;其他的走默认分支。
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 flowid 1:11
如何控制 QoS?
我们讲过,使用 OpenvSwitch 将云中的网卡连通在一起,那如何控制 QoS 呢?就像我们上面说的一样,OpenvSwitch 支持两种:
- 对于进入的流量,可以设置策略 Ingress policy;
ovs-vsctl set Interface tap0 ingress_policing_rate=100000
ovs-vsctl set Interface tap0 ingress_policing_burst=10000
- 对于发出的流量,可以设置 QoS 规则 Egress shaping,支持 HTB。
我们构建一个拓扑图,来看看 OpenvSwitch 的 QoS 是如何工作的。
首先,在 port 上可以创建 QoS 规则,一个 QoS 规则可以有多个队列 Queue。
ovs-vsctl set port first_br qos=@newqos -- --id=@newqos create qos type=linux-htb other-config:max-rate=10000000 queues=0=@q0,1=@q1,2=@q2 -- --id=@q0 create queue other-config:min-rate=3000000 other-config:max-rate=10000000 -- --id=@q1 create queue other-config:min-rate=1000000 other-config:max-rate=10000000 -- --id=@q2 create queue other-config:min-rate=6000000 other-config:max-rate=10000000
上面的命令创建了一个 QoS 规则,对应三个 Queue。min-rate 就是上面的 rate,max-rate 就是上面的 ceil。通过交换机的网络包,要通过流表规则,匹配后进入不同的队列。然后我们就可以添加流表规则 Flow(first_br 是 br0 上的 port 5)。
ovs-ofctl add-flow br0 "in_port=6 nw_src=192.168.100.100 actions=enqueue:5:0"
ovs-ofctl add-flow br0 "in_port=7 nw_src=192.168.100.101 actions=enqueue:5:1"
ovs-ofctl add-flow br0 "in_port=8 nw_src=192.168.100.102 actions=enqueue:5:2"
接下来,我们单独测试从 192.168.100.100,192.168.100.101,192.168.100.102 到 192.168.100.103 的带宽的时候,每个都是能够打满带宽的。如果三个一起测试,一起狂发网络包,会发现是按照 3:1:6 的比例进行的,正是根据配置的队列的带宽比例分配的。
如果 192.168.100.100 和 192.168.100.101 一起测试,发现带宽占用比例为 3:1,但是占满了总的流量,也即没有发包的 192.168.100.102 有 60% 的带宽被借用了。如果 192.168.100.100 和 192.168.100.102 一起测试,发现带宽占用比例为 1:2。如果 192.168.100.101 和 192.168.100.102 一起测试,发现带宽占用比例为 1:6。
云中网络的隔离GRE、VXLAN:虽然住一个小区,也要保护隐私
底层的物理网络设备组成的网络我们称为 Underlay 网络,而用于虚拟机和云中的这些技术组成的网络称为 Overlay 网络,这是一种基于物理网络的虚拟化网络实现。这一节我们重点讲两个 Overlay 的网络技术。
GRE
第一个技术是 GRE,全称 Generic Routing Encapsulation,它是一种 IP-over-IP 的隧道技术。它将 IP 包封装在 GRE 包里,外面加上 IP 头,在隧道的一端封装数据包,并在通路上进行传输,到另外一端的时候解封装。你可以认为 Tunnel 是一个虚拟的、点对点的连接。
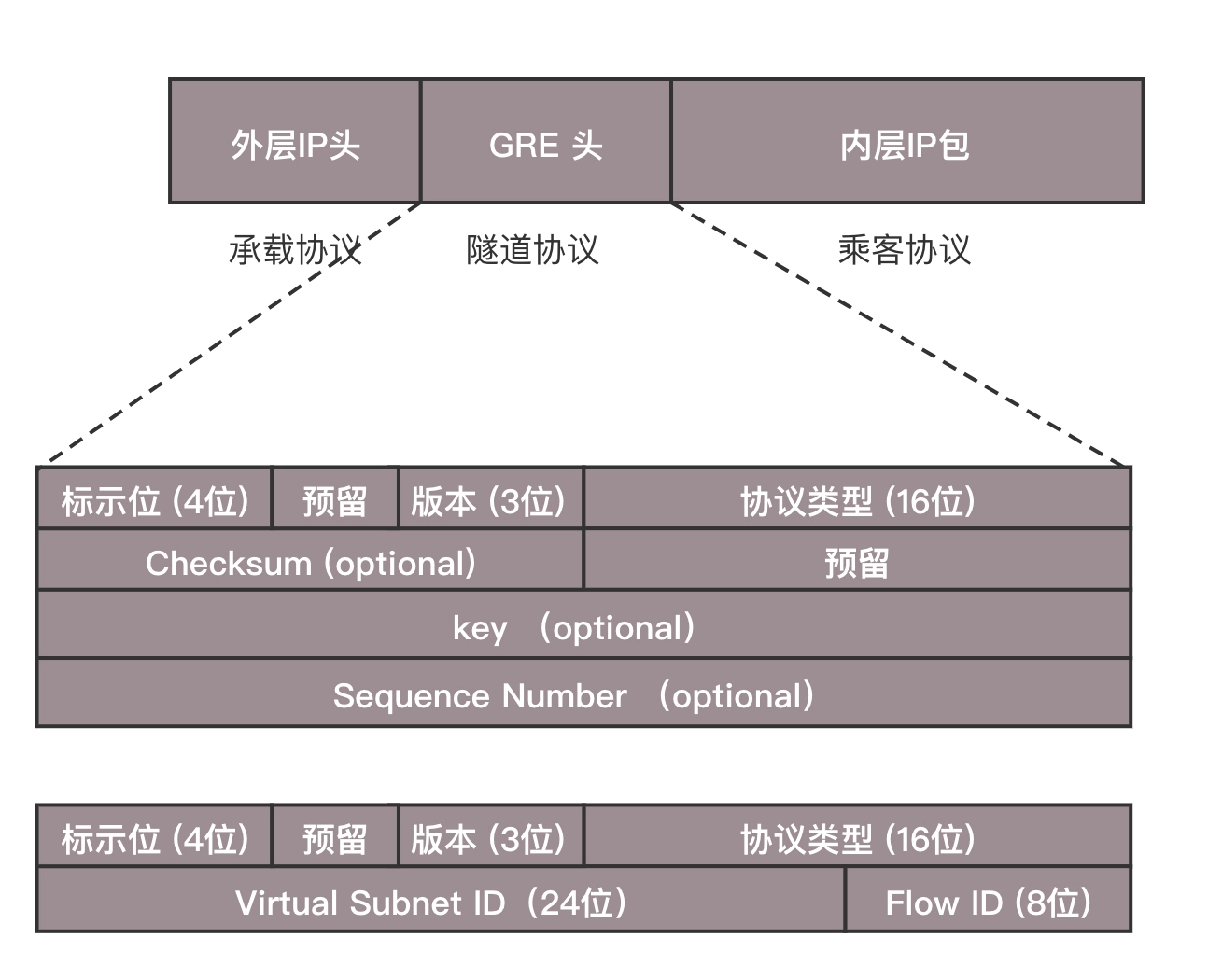
从这个图中可以看到,在 GRE 头中,前 32 位是一定会有的,后面的都是可选的。在前 4 位标识位里面,有标识后面到底有没有可选项?这里面有个很重要的 key 字段,是一个 32 位的字段,里面存放的往往就是用于区分用户的 Tunnel ID。32 位,够任何云平台喝一壶的了!
下面的格式类型专门用于网络虚拟化的 GRE 包头格式,称为 NVGRE,也给网络 ID 号 24 位,也完全够用了。
除此之外,GRE 还需要有一个地方来封装和解封装 GRE 的包,这个地方往往是路由器或者有路由功能的 Linux 机器。
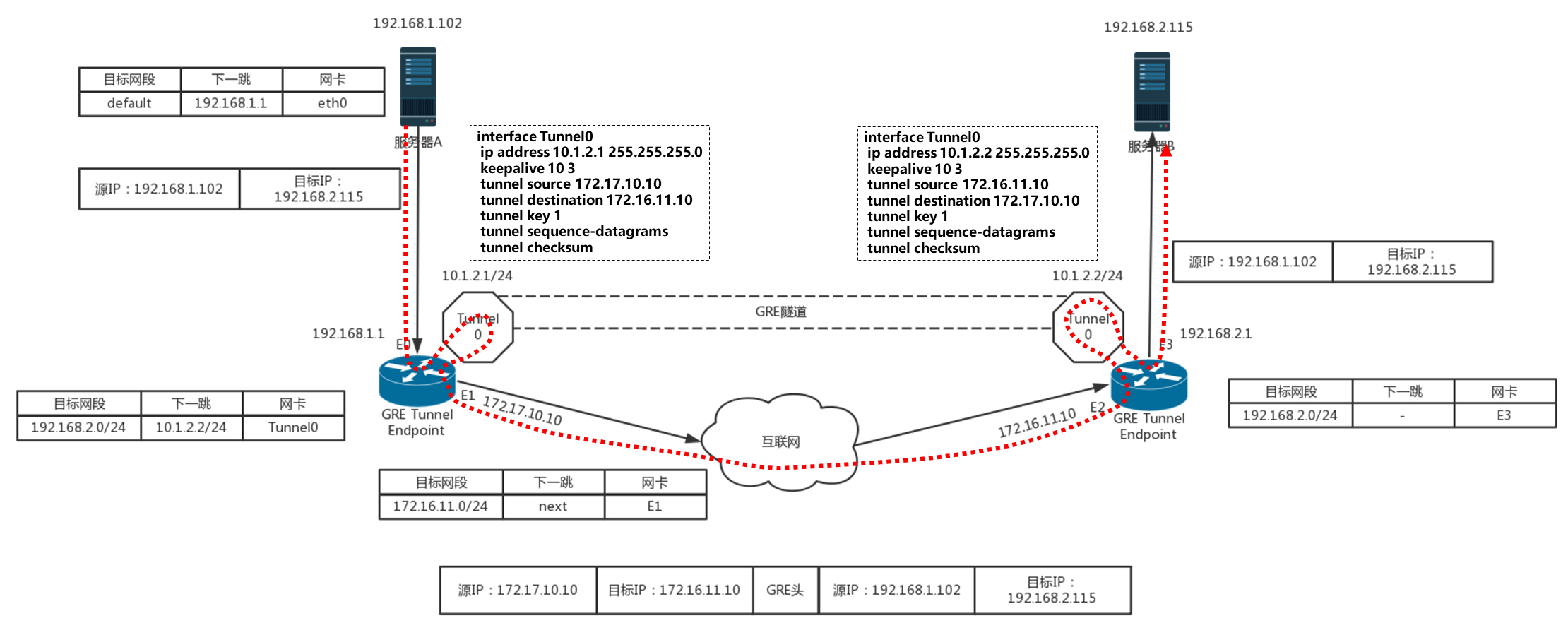
使用 GRE 隧道,传输的过程就像下面这张图。这里面有两个网段、两个路由器,中间要通过 GRE 隧道进行通信。当隧道建立之后,会多出两个 Tunnel 端口,用于封包、解封包。
-
主机 A 在左边的网络,IP 地址为 192.168.1.102,它想要访问主机 B,主机 B 在右边的网络,IP 地址为 192.168.2.115。于是发送一个包,源地址为 192.168.1.102,目标地址为 192.168.2.115。因为要跨网段访问,于是根据默认的 default 路由表规则,要发给默认的网关 192.168.1.1,也即左边的路由器。
-
根据路由表,从左边的路由器,去 192.168.2.0/24 这个网段,应该走一条 GRE 的隧道,从隧道一端的网卡 Tunnel0 进入隧道。
-
在 Tunnel 隧道的端点进行包的封装,在内部的 IP 头之外加上 GRE 头。对于 NVGRE 来讲,是在 MAC 头之外加上 GRE 头,然后加上外部的 IP 地址,也即路由器的外网 IP 地址。源 IP 地址为 172.17.10.10,目标 IP 地址为 172.16.11.10,然后从 E1 的物理网卡发送到公共网络里。
-
在公共网络里面,沿着路由器一跳一跳地走,全部都按照外部的公网 IP 地址进行。
-
当网络包到达对端路由器的时候,也要到达对端的 Tunnel0,然后开始解封装,将外层的 IP 头取下来,然后根据里面的网络包,根据路由表,从 E3 口转发出去到达服务器 B。
从 GRE 的原理可以看出,GRE 通过隧道的方式,很好地解决了 VLAN ID 不足的问题。但是,GRE 技术本身还是存在一些不足之处。
首先是 Tunnel 的数量问题。GRE 是一种点对点隧道,如果有三个网络,就需要在每两个网络之间建立一个隧道。如果网络数目增多,这样隧道的数目会呈指数性增长。
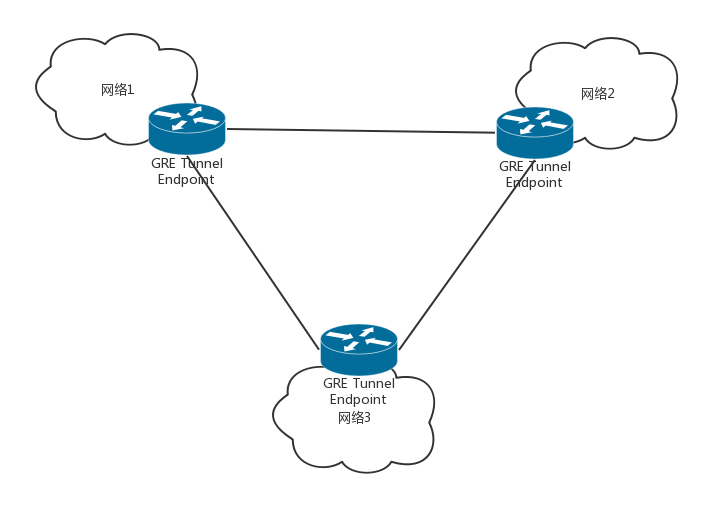
其次,GRE 不支持组播,因此一个网络中的一个虚机发出一个广播帧后,GRE 会将其广播到所有与该节点有隧道连接的节点。
另外一个问题是目前还是有很多防火墙和三层网络设备无法解析 GRE,因此它们无法对 GRE 封装包做合适地过滤和负载均衡。
VXLAN
第二种 Overlay 的技术称为 VXLAN。和三层外面再套三层的 GRE 不同,VXLAN 则是从二层外面就套了一个 VXLAN 的头,这里面包含的 VXLAN ID 为 24 位,也够用了。在 VXLAN 头外面还封装了 UDP、IP,以及外层的 MAC 头。
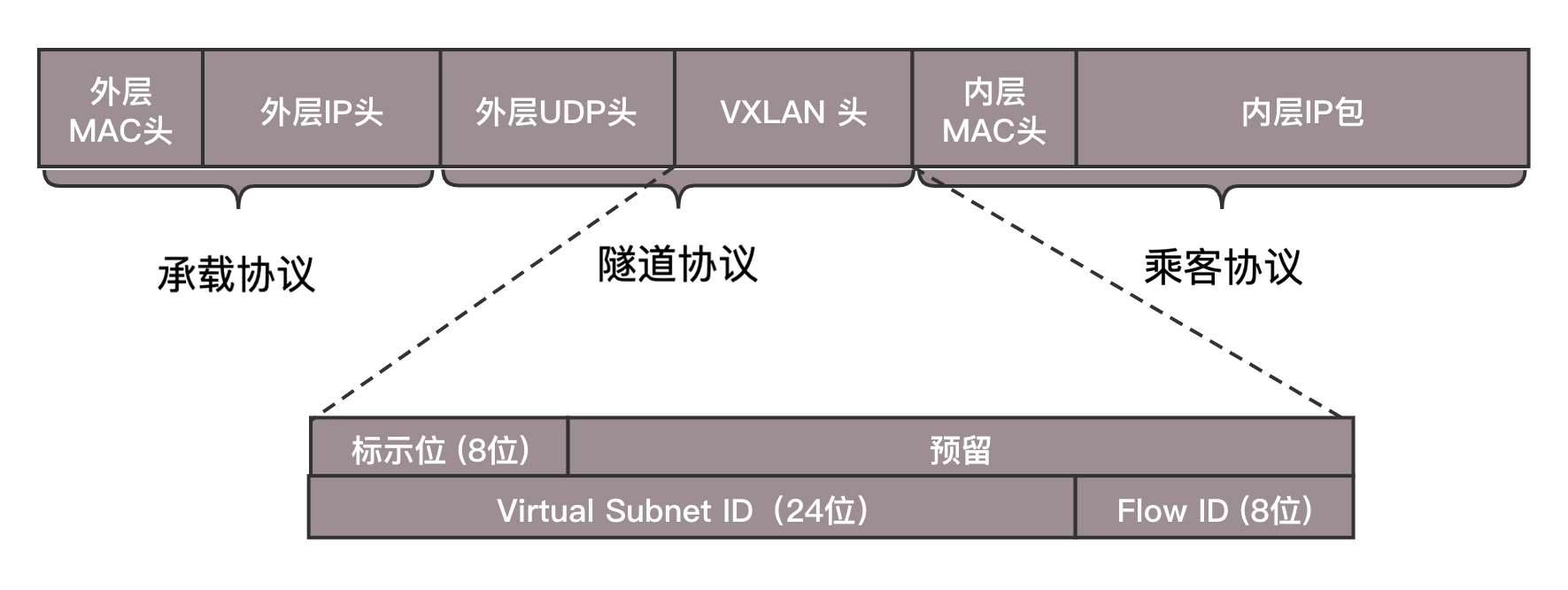
VXLAN 作为扩展性协议,也需要一个地方对 VXLAN 的包进行封装和解封装,实现这个功能的点称为 VTEP(VXLAN Tunnel Endpoint)。
VTEP 相当于虚拟机网络的管家。每台物理机上都可以有一个 VTEP。每个虚拟机启动的时候,都需要向这个 VTEP 管家注册,每个 VTEP 都知道自己上面注册了多少个虚拟机。当虚拟机要跨 VTEP 进行通信的时候,需要通过 VTEP 代理进行,由 VTEP 进行包的封装和解封装。
和 GRE 端到端的隧道不同,VXLAN 不是点对点的,而是支持通过组播的来定位目标机器的,而非一定是这一端发出,另一端接收。
当一个 VTEP 启动的时候,它们都需要通过 IGMP 协议。加入一个组播组,就像加入一个邮件列表,或者加入一个微信群一样,所有发到这个邮件列表里面的邮件,或者发送到微信群里面的消息,大家都能收到。而当每个物理机上的虚拟机启动之后,VTEP 就知道,有一个新的 VM 上线了,它归我管。
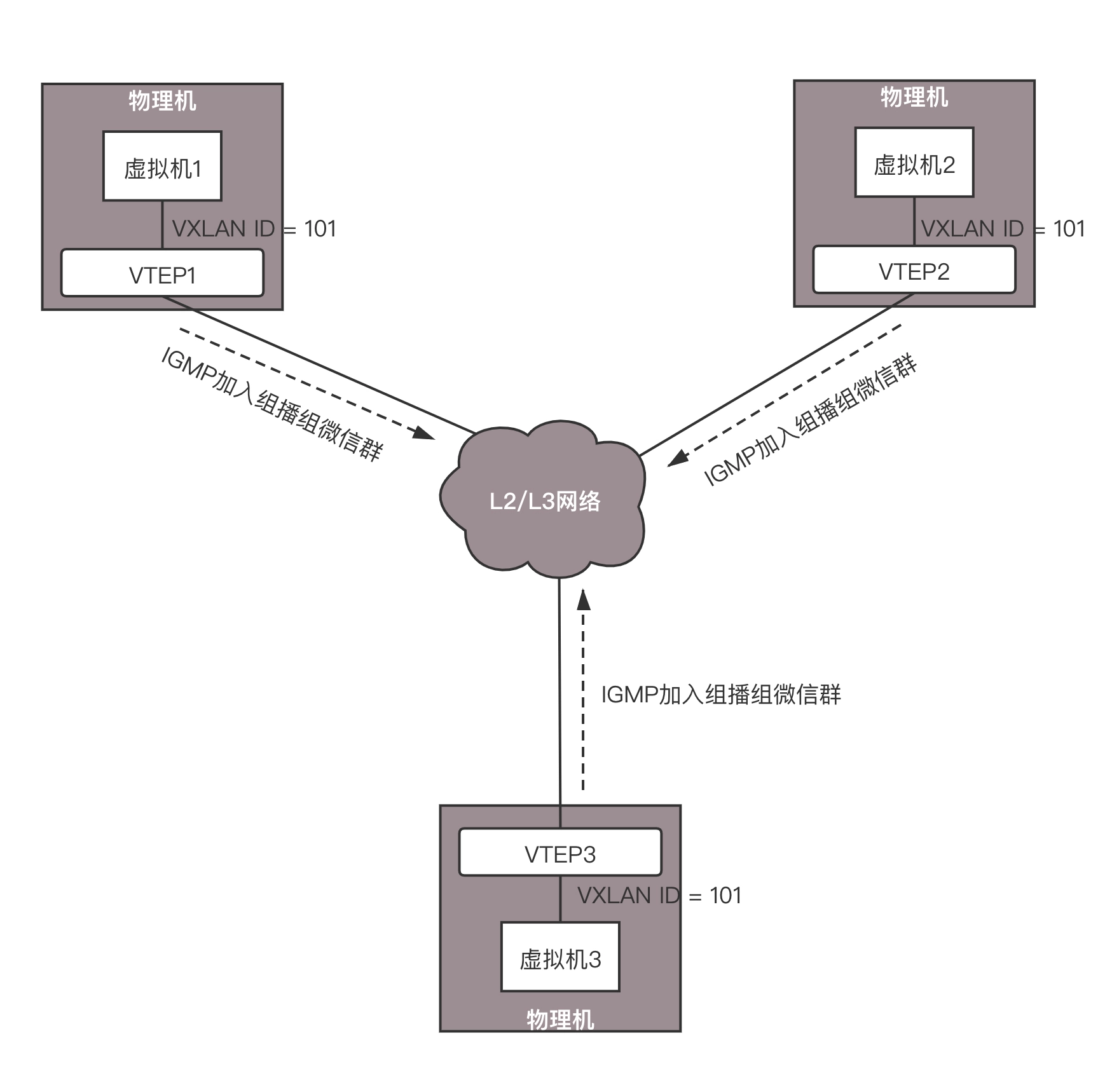
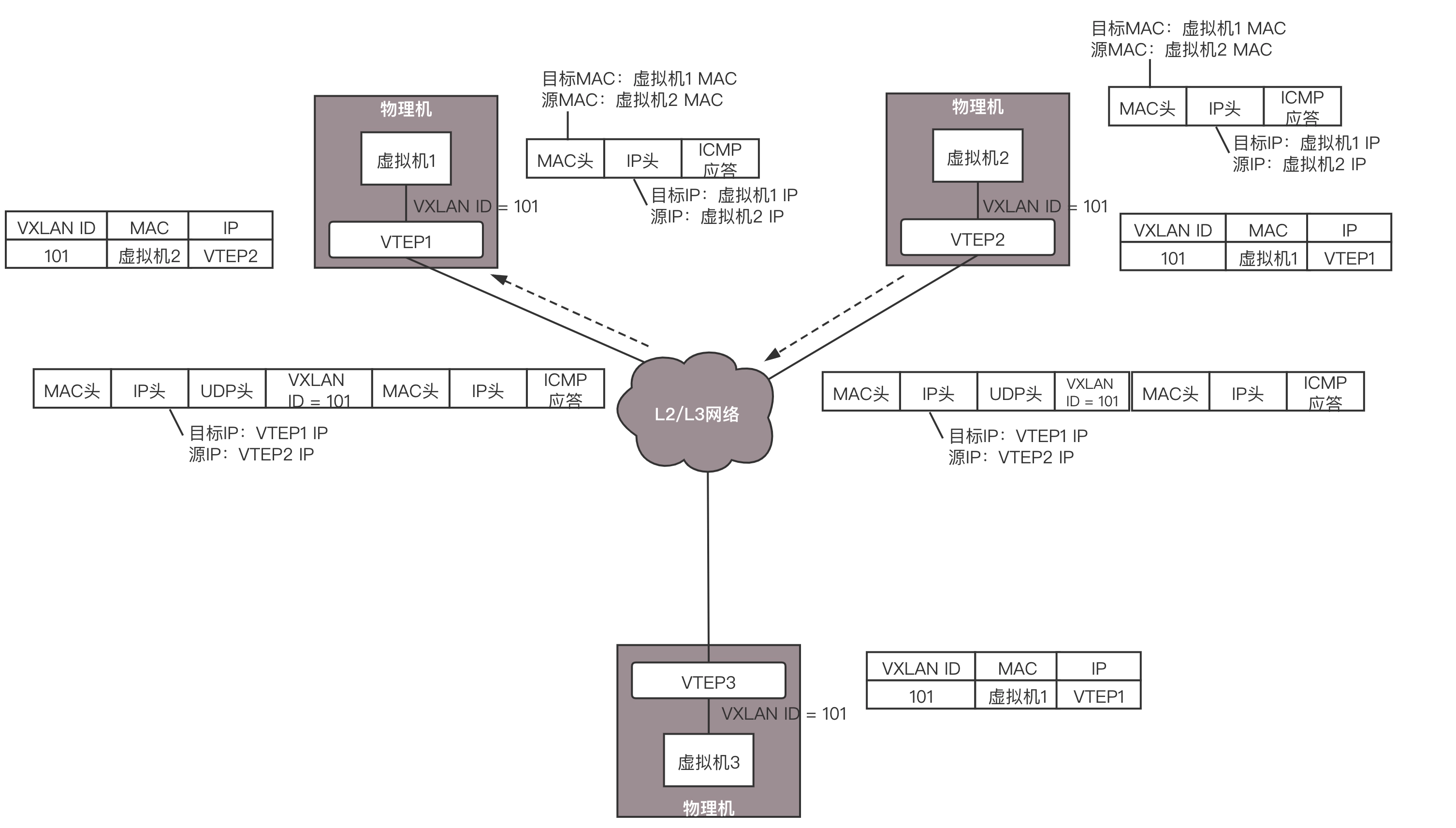
如图,虚拟机 1、2、3 属于云中同一个用户的虚拟机,因而需要分配相同的 VXLAN ID=101。在云的界面上,就可以知道它们的 IP 地址,于是可以在虚拟机 1 上 ping 虚拟机 2。
虚拟机 1 发现,它不知道虚拟机 2 的 MAC 地址,因而包没办法发出去,于是要发送 ARP 广播。
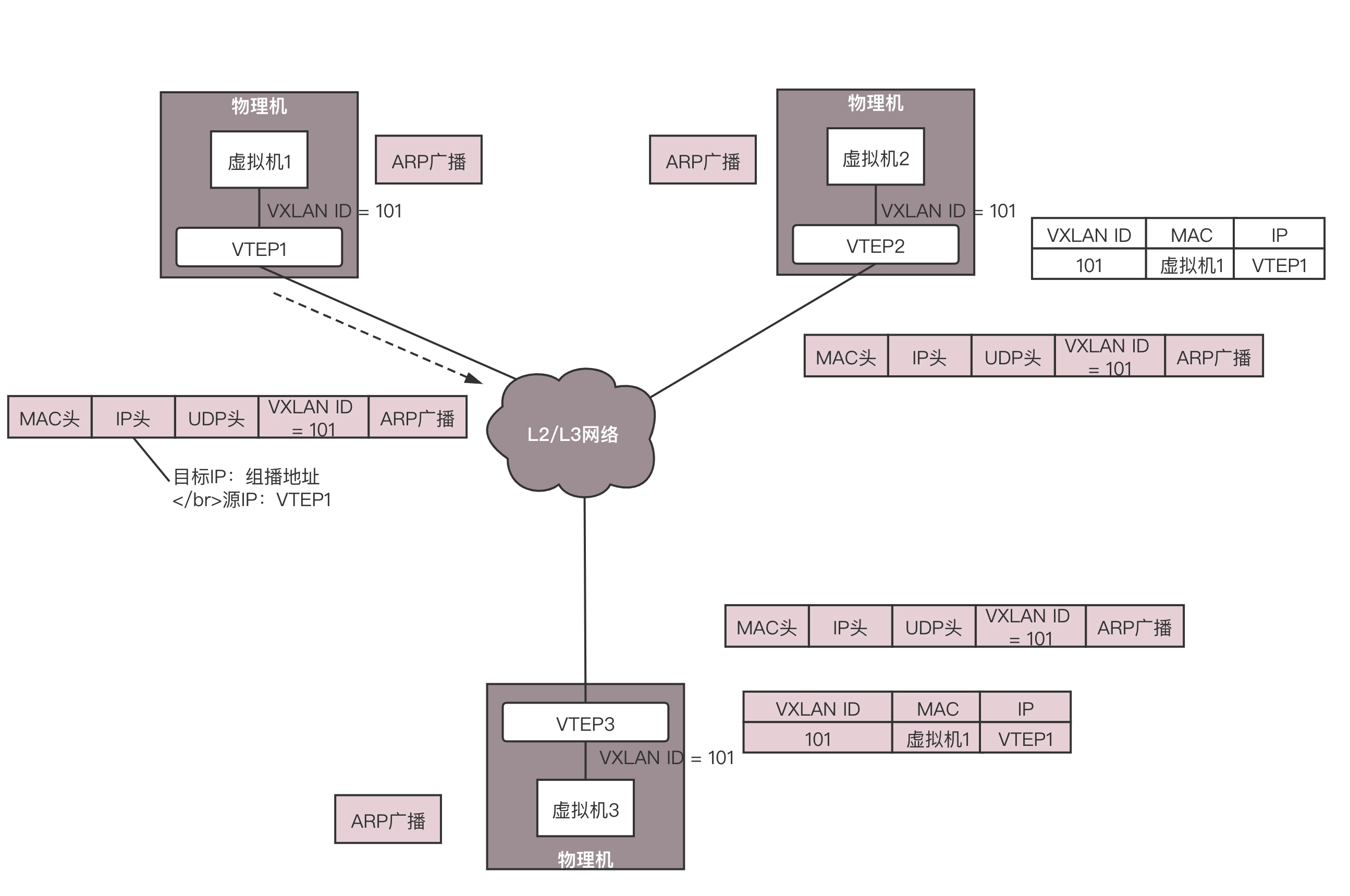
ARP 请求到达 VTEP1 的时候,VTEP1 知道,我这里有一台虚拟机,要访问一台不归我管的虚拟机,需要知道 MAC 地址,可是我不知道啊,这该咋办呢?
VTEP1 想,我不是加入了一个微信群么?可以在里面 @all 一下,问问虚拟机 2 归谁管。于是 VTEP1 将 ARP 请求封装在 VXLAN 里面,组播出去。
当然在群里面,VTEP2 和 VTEP3 都收到了消息,因而都会解开 VXLAN 包看,里面是一个 ARP。
VTEP3 在本地广播了半天,没人回,都说虚拟机 2 不归自己管。
VTEP2 在本地广播,虚拟机 2 回了,说虚拟机 2 归我管,MAC 地址是这个。通过这次通信,VTEP2 也学到了,虚拟机 1 归 VTEP1 管,以后要找虚拟机 1,去找 VTEP1 就可以了。
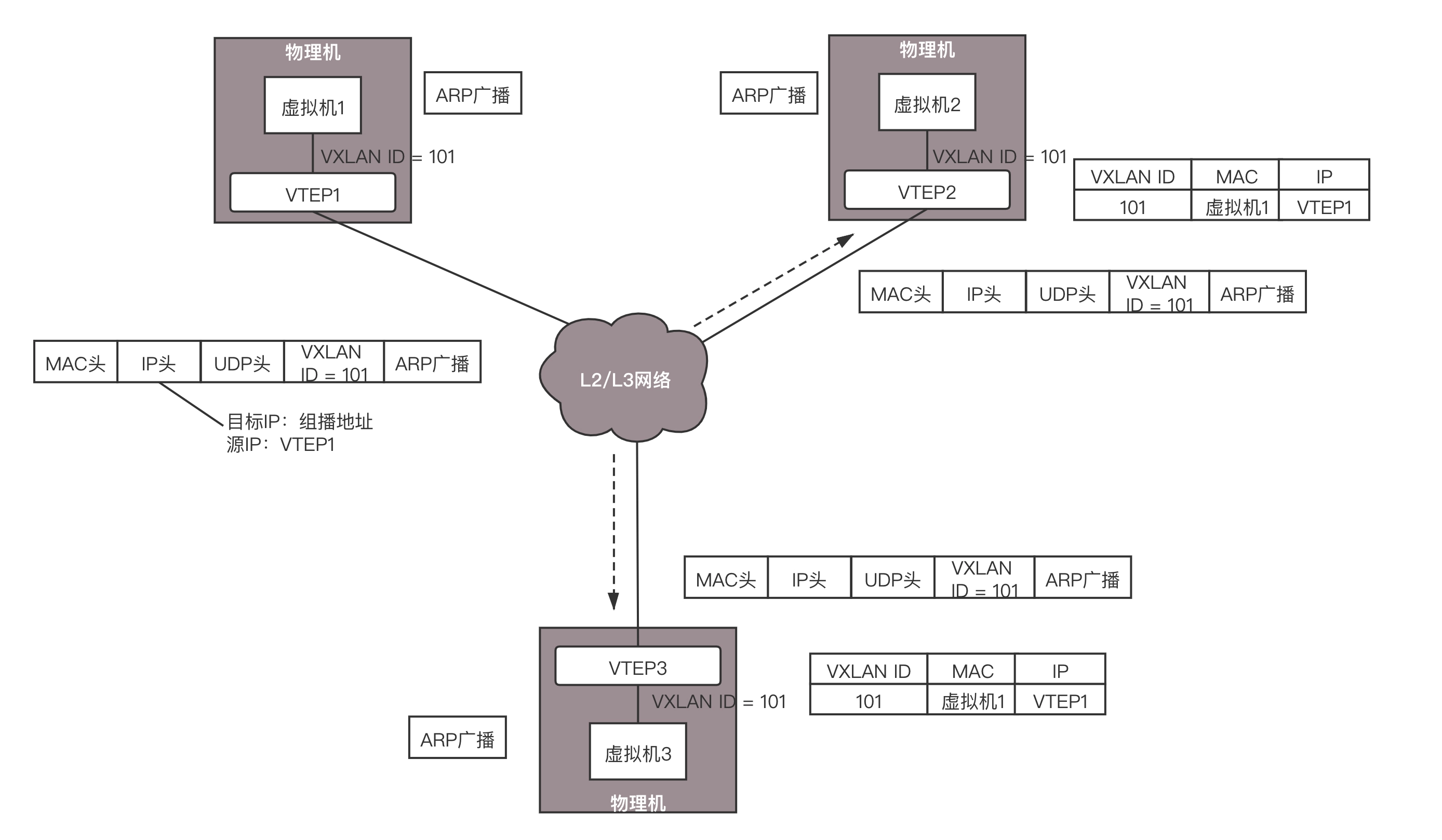
VTEP2 将 ARP 的回复封装在 VXLAN 里面,这次不用组播了,直接发回给 VTEP1。
VTEP1 解开 VXLAN 的包,发现是 ARP 的回复,于是发给虚拟机 1。通过这次通信,VTEP1 也学到了,虚拟机 2 归 VTEP2 管,以后找虚拟机 2,去找 VTEP2 就可以了。
虚拟机 1 的 ARP 得到了回复,知道了虚拟机 2 的 MAC 地址,于是就可以发送包了。
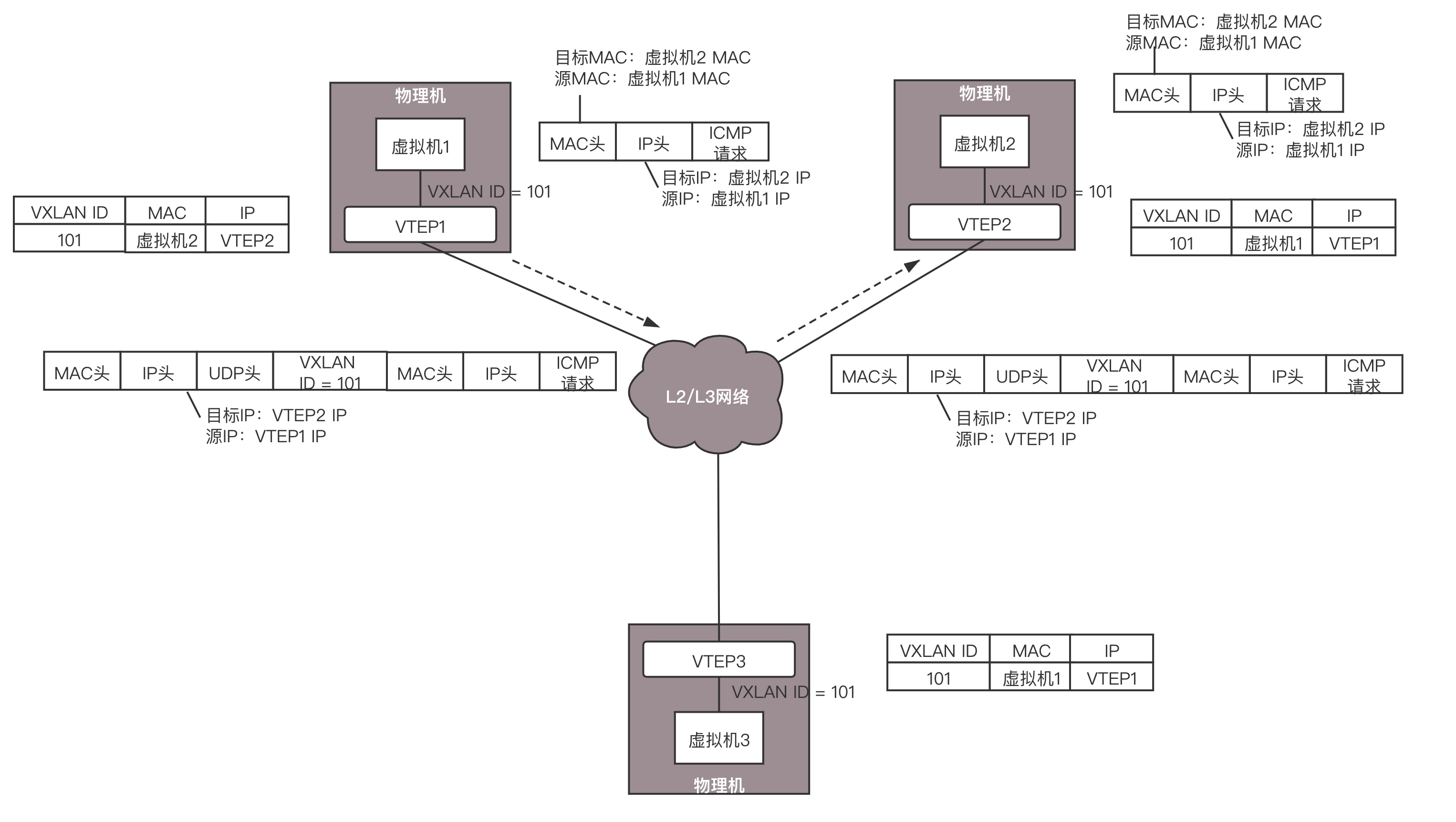
虚拟机 1 发给虚拟机 2 的包到达 VTEP1,它当然记得刚才学的东西,要找虚拟机 2,就去 VTEP2,于是将包封装在 VXLAN 里面,外层加上 VTEP1 和 VTEP2 的 IP 地址,发送出去。
网络包到达 VTEP2 之后,VTEP2 解开 VXLAN 封装,将包转发给虚拟机 2。
虚拟机 2 回复的包,到达 VTEP2 的时候,它当然也记得刚才学的东西,要找虚拟机 1,就去 VTEP1,于是将包封装在 VXLAN 里面,外层加上 VTEP1 和 VTEP2 的 IP 地址,也发送出去。
网络包到达 VTEP1 之后,VTEP1 解开 VXLAN 封装,将包转发给虚拟机 1。
如何在云平台上融入 VXLAN
有了 GRE 和 VXLAN 技术,我们就可以解决云计算中 VLAN 的限制了。那如何将这个技术融入云平台呢?
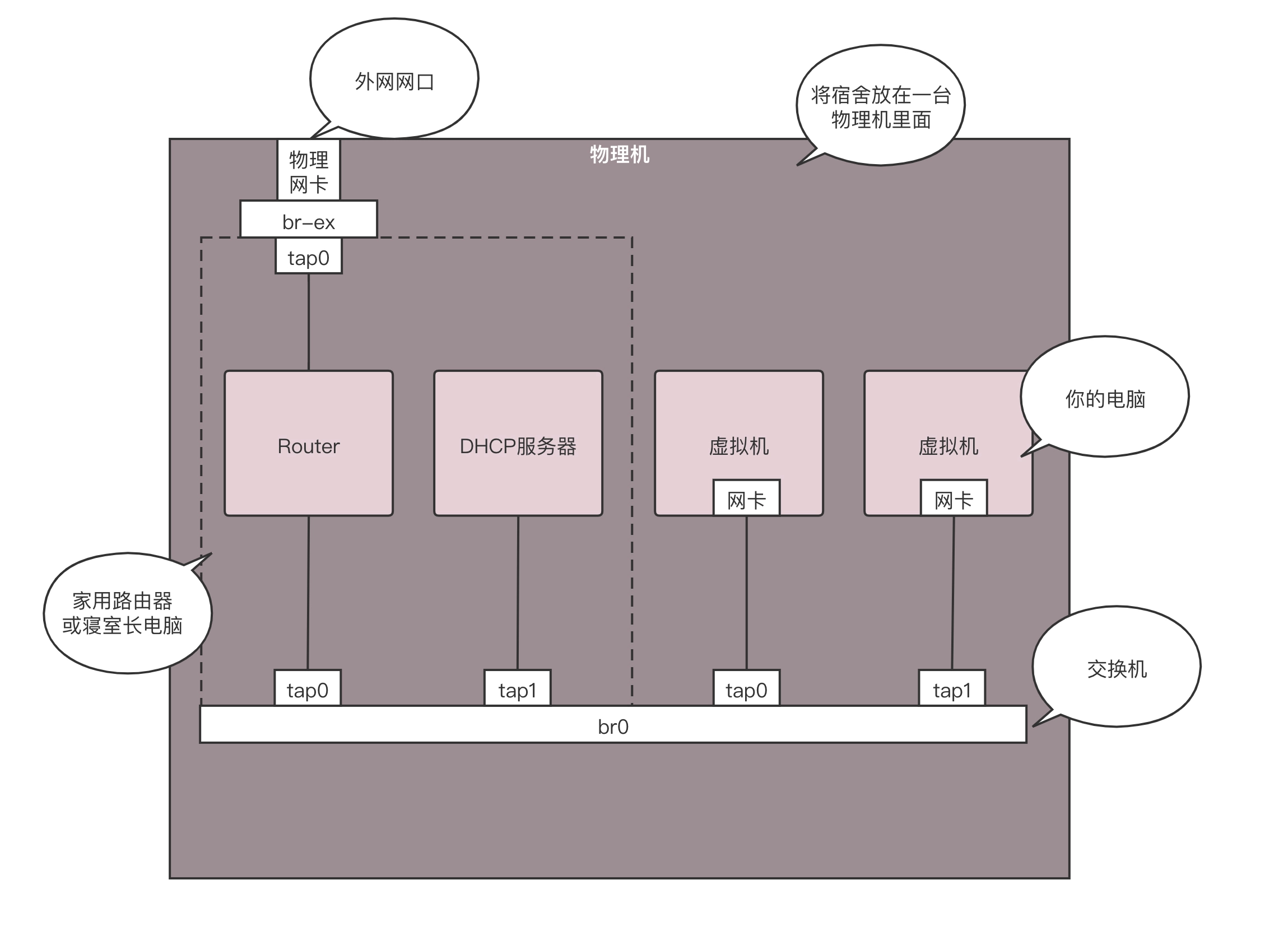
虚拟机是你的电脑,路由器和 DHCP Server 相当于家用路由器或者寝室长的电脑,外网网口访问互联网,所有的电脑都通过内网网口连接到一个交换机 br0 上,虚拟机要想访问互联网,需要通过 br0 连到路由器上,然后通过路由器将请求 NAT 后转发到公网。
接下来的事情就惨了,你们宿舍闹矛盾了,你们要分成三个宿舍住,对应上面的图,你们寝室长,也即路由器单独在一台物理机上,其他的室友也即 VM 分别在两台物理机上。这下把一个完整的 br0 一刀三断,每个宿舍都是单独的一段。

可是只有你的寝室长有公网口可以上网,于是你偷偷在三个宿舍中间打了一个隧道,用网线通过隧道将三个宿舍的两个 br0 连接起来,让其他室友的电脑和你寝室长的电脑,看起来还是连到同一个 br0 上,其实中间是通过你隧道中的网线做了转发。
为什么要多一个 br1 这个虚拟交换机呢?主要通过 br1 这一层将虚拟机之间的互联和物理机机之间的互联分成两层来设计,中间隧道可以有各种挖法,GRE、VXLAN 都可以。
使用了 OpenvSwitch 之后,br0 可以使用 OpenvSwitch 的 Tunnel 功能和 Flow 功能。
OpenvSwitch 支持三类隧道:GRE、VXLAN、IPsec_GRE。在使用 OpenvSwitch 的时候,虚拟交换机就相当于 GRE 和 VXLAN 封装的端点。
我们模拟创建一个如下的网络拓扑结构,来看隧道应该如何工作。
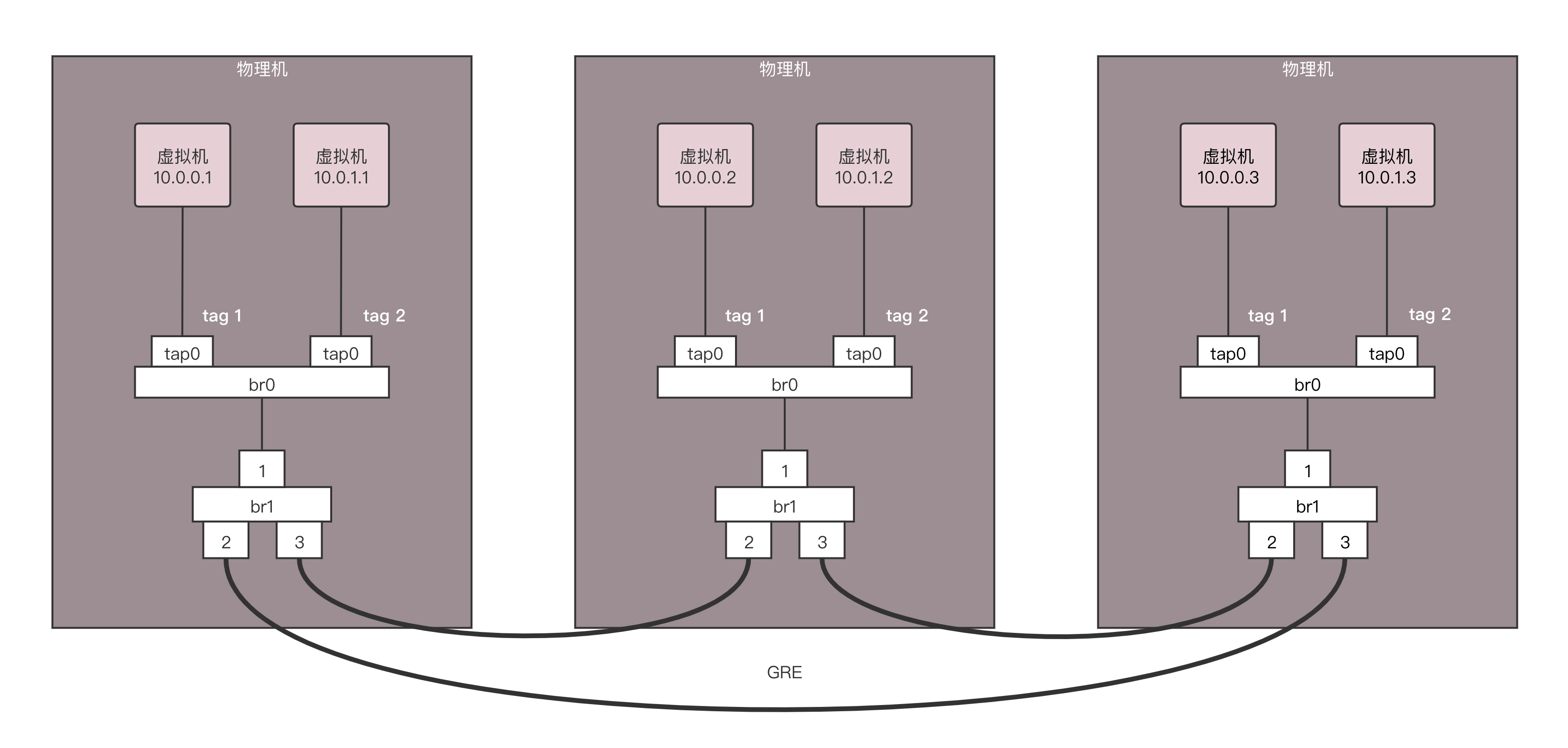
三台物理机,每台上都有两台虚拟机,分别属于两个不同的用户,因而 VLAN tag 都得打地不一样,这样才不能相互通信。但是不同物理机上的相同用户,是可以通过隧道相互通信的,因而通过 GRE 隧道可以连接到一起。
接下来,所有的 Flow Table 规则都设置在 br1 上,每个 br1 都有三个网卡,其中网卡 1 是对内的,网卡 2 和 3 是对外的。
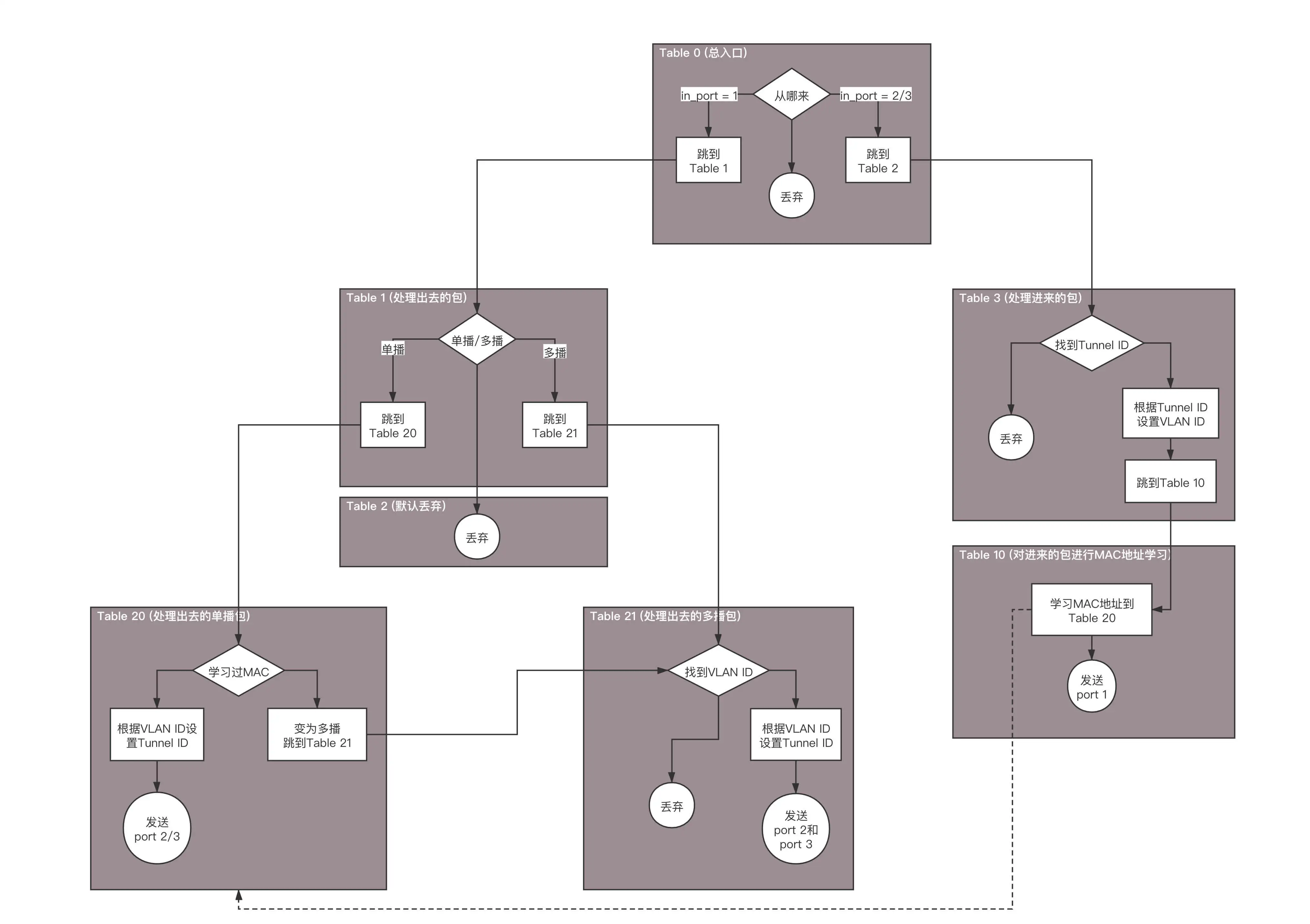
- Table 0 是所有流量的入口,所有进入 br1 的流量,分为两种流量,一个是进入物理机的流量,一个是从物理机发出的流量。
从 port 1 进来的,都是发出去的流量,全部由 Table 1 处理。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=1 actions=resubmit(,1)"
从 port 2、3 进来的,都是进入物理机的流量,全部由 Table 3 处理。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=2 actions=resubmit(,3)"
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=3 actions=resubmit(,3)"
如果都没匹配上,就默认丢弃。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 actions=drop"
- Table 1 用于处理所有出去的网络包,分为两种情况,一种是单播,一种是多播。
对于单播,由 Table 20 处理。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=1 dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)"
对于多播,由 Table 21 处理。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=1 dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,21)"
- Table 2 是紧接着 Table1 的,如果既不是单播,也不是多播,就默认丢弃。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=2 actions=drop"
- Table 3 用于处理所有进来的网络包,需要将隧道 Tunnel ID 转换为 VLAN ID。
如果匹配不上 Tunnel ID,就默认丢弃。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=3 actions=drop"
如果匹配上了 Tunnel ID,就转换为相应的 VLAN ID,然后跳到 Table 10。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=3 tun_id=0x1 actions=mod_vlan_vid:1,resubmit(,10)"
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=3 tun_id=0x2 actions=mod_vlan_vid:2,resubmit(,10)"
- 对于进来的包,Table 10 会进行 MAC 地址学习。这是一个二层交换机应该做的事情,学习完了之后,再从 port 1 发出去。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=10 actions=learn(table=20,priority=1,hard_timeout=300,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:1"
Table 10 是用来学习 MAC 地址的,学习的结果放在 Table 20 里面。Table20 被称为 MAC learning table。
NXM_OF_VLAN_TCI 是 VLAN tag。在 MAC learning table 中,每一个 entry 都仅仅是针对某一个 VLAN 来说的,不同 VLAN 的 learning table 是分开的。在学习结果的 entry 中,会标出这个 entry 是针对哪个 VLAN 的。
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[]表示,当前包里面的 MAC Source Address 会被放在学习结果的 entry 里的 dl_dst 里。这是因为每个交换机都是通过进入的网络包来学习的。某个 MAC 从某个 port 进来,交换机就应该记住,以后发往这个 MAC 的包都要从这个 port 出去,因而源 MAC 地址就被放在了目标 MAC 地址里面,因为这是为了发送才这么做的。
load:0->NXM_OF_VLAN_TCI[]是说,在 Table20 中,将包从物理机发送出去的时候,VLAN tag 设为 0,所以学习完了之后,Table 20 中会有 actions=strip_vlan。
load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[]的意思是,在 Table 20 中,将包从物理机发出去的时候,设置 Tunnel ID,进来的时候是多少,发送的时候就是多少,所以学习完了之后,Table 20 中会有 set_tunnel。
output:NXM_OF_IN_PORT[]是发送给哪个 port。例如是从 port 2 进来的,那学习完了之后,Table 20 中会有 output:2。
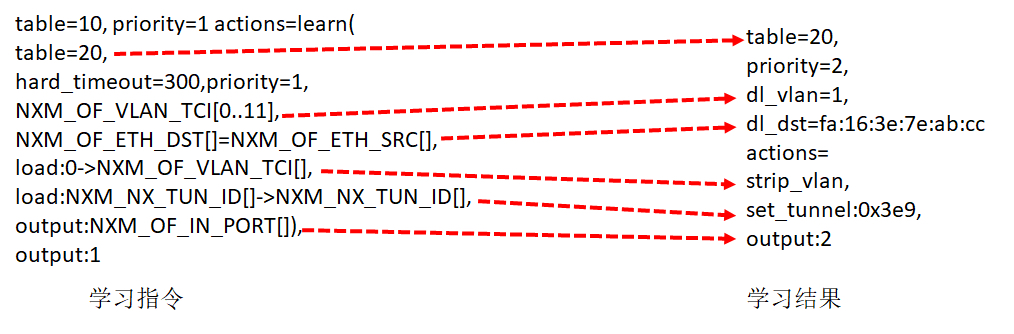
所以如图所示,通过左边的 MAC 地址学习规则,学习到的结果就像右边的一样,这个结果会被放在 Table 20 里面。
- Table 20 是 MAC Address Learning Table。如果不为空,就按照规则处理;如果为空,就说明没有进行过 MAC 地址学习,只好进行广播了,因而要交给 Table 21 处理。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=20 actions=resubmit(,21)"
- Table 21 用于处理多播的包。
如果匹配不上 VLAN ID,就默认丢弃。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=21 actions=drop"
如果匹配上了 VLAN ID,就将 VLAN ID 转换为 Tunnel ID,从两个网卡 port 2 和 port 3 都发出去,进行多播。
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1table=21dl_vlan=1 actions=strip_vlan,set_tunnel:0x1,output:2,output:3"
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1table=21dl_vlan=2 actions=strip_vlan,set_tunnel:0x2,output:2,output:3"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号