《Linux 性能优化实战》IO —— 小记随笔
基础篇:Linux 文件系统是怎么工作的?
同 CPU、内存一样,磁盘和文件系统的管理,也是操作系统最核心的功能。
- 磁盘为系统提供了最基本的持久化存储。
- 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
索引节点和目录项
在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。
Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
存储模型
索引节点和目录项纪录了文件的元数据,以及文件间的目录关系,那么具体来说,文件数据到底是怎么存储的呢?
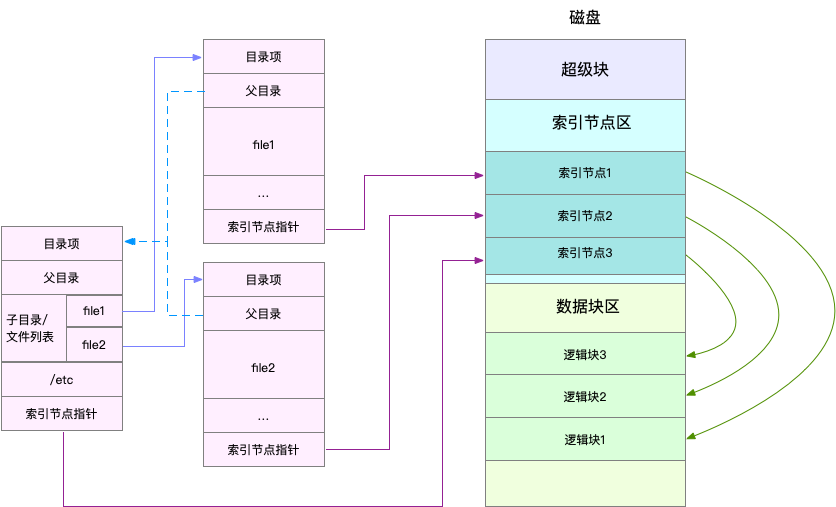
磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
-
目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的 Buffer 和 Cache 原理中,我曾经提到过,为了协调慢速磁盘与快速 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中。
那么,你应该想到,这些索引节点自然也会缓存到内存中,加速文件的访问。 -
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
** 超级块,存储整个文件系统的状态。
** 索引节点区,用来存储索引节点。
** 数据块区,则用来存储文件数据。
虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过,为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
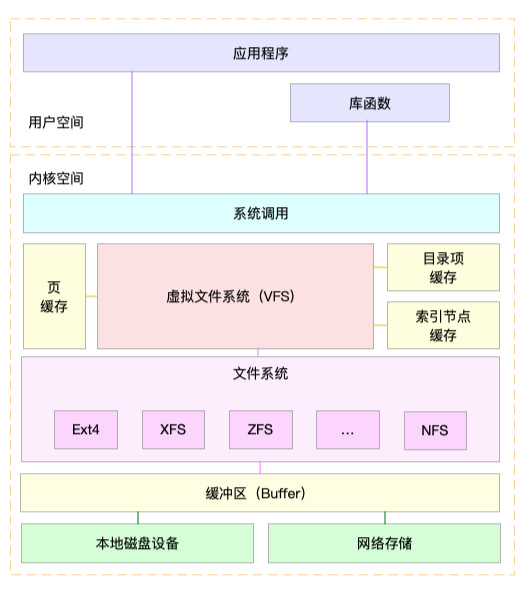
Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
- 第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
- 第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
- 第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
文件系统 I/O
文件读写方式的各种差异,导致 I/O 的分类多种多样
第一种,根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O
- 缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
- 非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
这里所说的“缓冲”,是指标准库内部实现的缓存
无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
第二,根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
第三,根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
第四,根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
举个例子,在操作文件时,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。
性能观测
容量
用 df 命令,就能查看文件系统的磁盘空间使用情况。
$ df /dev/sda1
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 30308240 3167020 27124836 11% /
$ df -h /dev/sda1
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 29G 3.1G 26G 11% /
明明你碰到了空间不足的问题,可是用 df 查看磁盘空间后,却发现剩余空间还有很多。这是怎么回事呢?不知道你还记不记得,刚才我强调的一个细节。除了文件数据,索引节点也占用磁盘空间。你可以给 df 命令加上 -i 参数,查看索引节点的使用情况,如下所示:
$ df -i /dev/sda1
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 3870720 157460 3713260 5% /
索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
缓存
可以用 free 或 vmstat,来观察页缓存的大小
$ cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 748316 kB
SwapCached: 0 kB
SReclaimable: 179508 kB
文件系统中的目录项和索引节点缓存,又该如何观察呢?
实际上,内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了 Slab 的整体大小,具体到每一种 Slab 缓存,还要查看 /proc/slabinfo 这个文件。
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0
...
ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0
shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0
proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0
inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0
dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0
dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
在实际性能分析中,我们更常使用 slabtop ,来找到占用内存最多的缓存类型。
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
Active / Total Objects (% used) : 277970 / 358914 (77.4%)
Active / Total Slabs (% used) : 12414 / 12414 (100.0%)
Active / Total Caches (% used) : 83 / 135 (61.5%)
Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%)
Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
69804 23094 0% 0.19K 3324 21 13296K dentry
16380 15854 0% 0.59K 1260 13 10080K inode_cache
58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache
485 413 0% 5.69K 97 5 3104K task_struct
1472 1397 0% 2.00K 92 16 2944K kmalloc-2048
基础篇:Linux 磁盘I/O是怎么工作的
磁盘
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
机械磁盘和固态磁盘还分别有一个最小的读写单位。
- 机械磁盘的最小读写单位是扇区,一般大小为 512 字节。
- 而固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等。
在上一节中,我也提到过,如果每次都读写 512 字节这么小的单位的话,效率很低。所以,文件系统会把连续的扇区或页,组成逻辑块,然后以逻辑块作为最小单元来管理数据。常见的逻辑块的大小是 4KB,也就是说,连续 8 个扇区,或者单独的一个页,都可以组成一个逻辑块。
另一个比较常用的架构,是把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列,也就是 RAID(Redundant Array of Independent Disks),从而可以提高数据访问的性能,并且增强数据存储的可靠性。RAID0 有最优的读写性能,但不提供数据冗余的功能。而其他级别的 RAID,在提供数据冗余的基础上,对读写性能也有一定程度的优化。
最后一种架构,是把这些磁盘组合成一个网络存储集群,再通过 NFS、SMB、iSCSI 等网络存储协议,暴露给服务器使用。
其实在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层
跟我们上一节讲到的虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 。
- 第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
其中,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。事实上,Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。这里我也分别介绍一下。
- 第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
- 第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
- 第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
- 最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
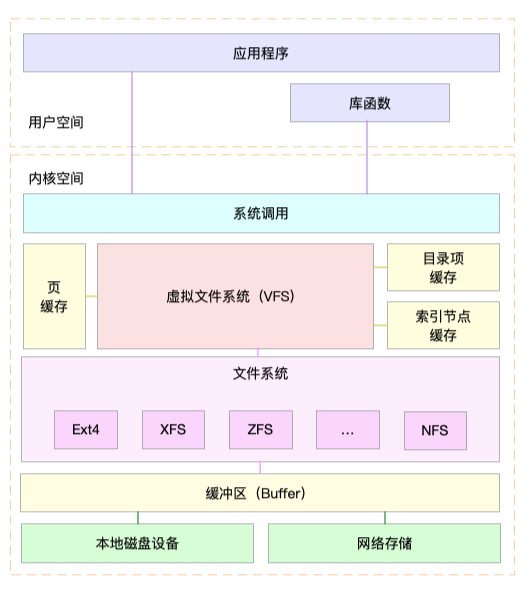
I/O 栈
我们可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。
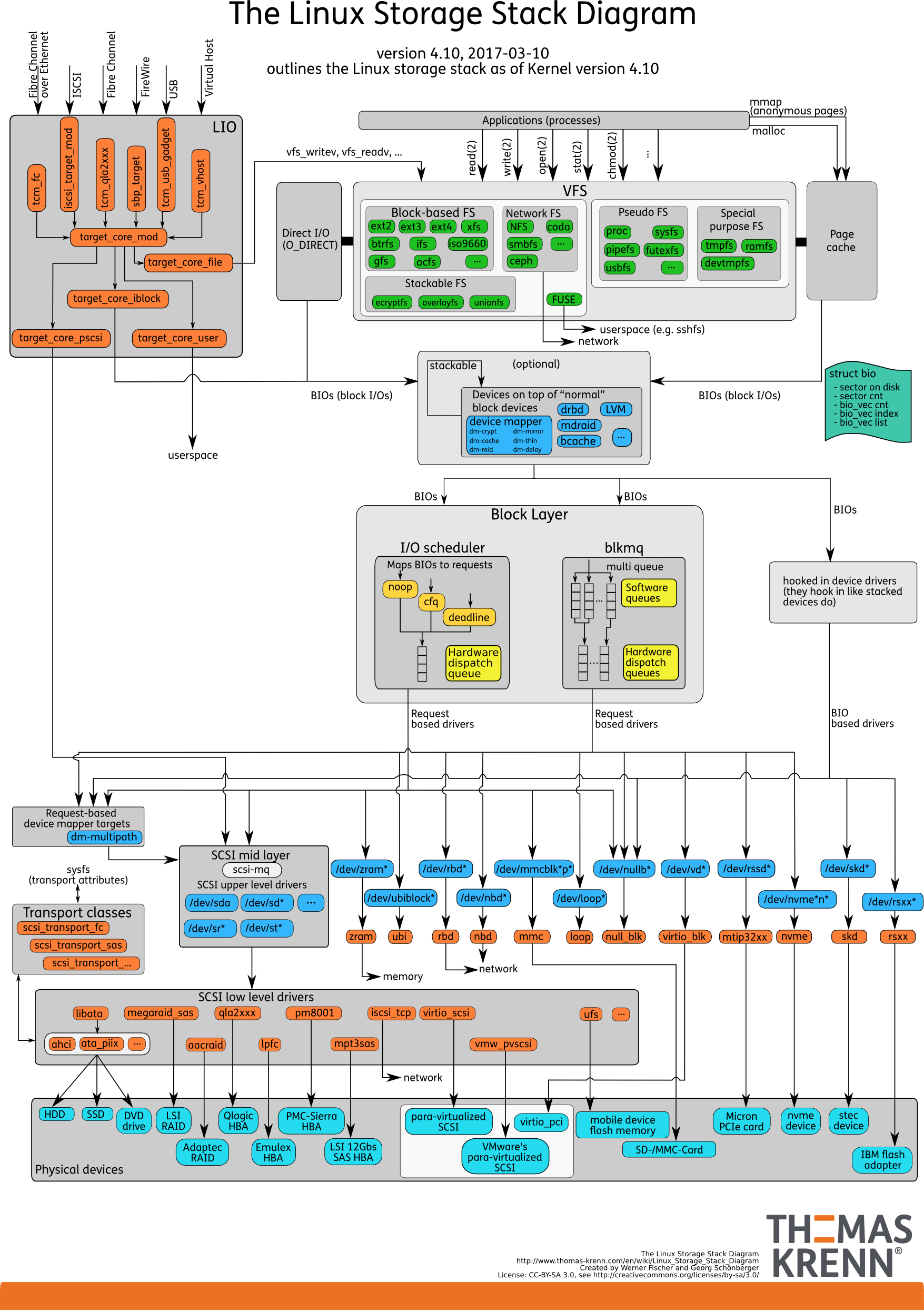
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率。
磁盘性能指标
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
这里要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
我推荐用性能测试工具 fio ,来测试磁盘的 IOPS、吞吐量以及响应时间等核心指标。
磁盘 I/O 观测
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
# -d -x表示显示所有磁盘I/O的指标
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00

- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
进程 I/O 观测
要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
pidstat 是我们的老朋友了,这里我就不再啰嗦它的功能了。给它加上 -d 参数,你就可以看到进程的 I/O 情况,
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop。它是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
从这个输出,你可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。
剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
案例篇:如何找出狂打日志的“内鬼”?
一般可以先用 top 命令查询 cpu + mem 情况,再看 iostat 看是否跟磁盘有关
# 按1切换到每个CPU的使用情况
$ top
top - 14:43:43 up 1 day, 1:39, 2 users, load average: 2.48, 1.09, 0.63
Tasks: 130 total, 2 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 6.0 sy, 0.0 ni, 0.7 id, 92.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 92.3 id, 7.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169308 total, 747684 free, 741336 used, 6680288 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7113124 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18940 root 20 0 656108 355740 5236 R 6.3 4.4 0:12.56 python
1312 root 20 0 236532 24116 9648 S 0.3 0.3 9:29.80 python3
观察 top 的输出,你会发现,CPU0 的使用率非常高,它的系统 CPU 使用率(sys%)为 6%,而 iowait 超过了 90%。这说明 CPU0 上,可能正在运行 I/O 密集型的进程。
python 进程的 CPU 使用率已经达到了 6%,而其余进程的 CPU 使用率都比较低,不超过 0.3%。看起来 python 是个可疑进程。
最后再看内存的使用情况,总内存 8G,剩余内存只有 730 MB,而 Buffer/Cache 占用内存高达 6GB 之多,这说明内存主要被缓存占用。虽然大部分缓存可回收,我们还是得了解下缓存的去处,确认缓存使用都是合理的
# -d表示显示I/O性能指标,-x表示显示扩展统计(即所有I/O指标)
$ iostat -x -d 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20
观察 iostat 的最后一列,你会看到,磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接近 I/O 饱和。
再看前面的各个指标,每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。此时,sda 磁盘已经遇到了严重的性能瓶颈。
可以用 pidstat 或者 iotop ,观察进程的 I/O 情况。这里,我就用 pidstat 来看一下。
$ pidstat -d 1
15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:36 0 18940 0.00 45816.00 0.00 96 python
15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-8
15:08:37 0 18940 0.00 46000.00 0.00 96 python
15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2
从 pidstat 的输出,你可以发现,只有 python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大。很明显,正是 python 进程导致了 I/O 瓶颈。
有两个进程 (kworker 和 jbd2 )的延迟,居然比 python 进程还大很多。这其中,kworker 是一个内核线程,而 jbd2 是 ext4 文件系统中,用来保证数据完整性的内核线程。他们都是保证文件系统基本功能的内核线程,所以具体细节暂时就不用管了,我们只需要明白,它们延迟的根源还是大量 I/O。
知道了进程的 PID 号,具体要怎么查看写的情况呢?其实,我在系统调用的案例中讲过,读写文件必须通过系统调用完成。观察系统调用情况,就可以知道进程正在写的文件。想起 strace 了吗,它正是我们分析系统调用时最常用的工具。
$ strace -p 18940
strace: Process 18940 attached
...
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000
write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844
) = 314572844
munmap(0x7f0f682e8000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f0f7aee9000, 314576896) = 0
close(3) = 0
stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0
从 write() 系统调用上,我们可以看到,进程向文件描述符编号为 3 的文件中,写入了 300MB 的数据。看来,它应该是我们要找的文件。不过,write() 调用中只能看到文件的描述符编号,文件名和路径还是未知的。
再观察后面的 stat() 调用,你可以看到,它正在获取 /tmp/logtest.txt.1 的状态。 这种“点 + 数字格式”的文件,在日志回滚中非常常见。我们可以猜测,这是第一个日志回滚文件,而正在写的日志文件路径,则是 /tmp/logtest.txt。
这只是我们的猜测,自然还需要验证。这里,我再给你介绍一个新的工具 lsof。它专门用来查看进程打开文件列表,不过,这里的“文件”不只有普通文件,还包括了目录、块设备、动态库、网络套接字等。
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
看最后一行,这说明,这个进程打开了文件 /tmp/logtest.txt,并且它的文件描述符是 3 号,而 3 后面的 w ,表示以写的方式打开。
案例篇:为什么我的磁盘I/O延迟很高?
跟上一个案例比较类似,我们可以先用 top 来观察 CPU 和内存的使用情况,然后再用 iostat 来观察磁盘的 I/O 情况。
$ top
top - 14:27:02 up 10:30, 1 user, load average: 1.82, 1.26, 0.76
Tasks: 129 total, 1 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu0 : 3.5 us, 2.1 sy, 0.0 ni, 0.0 id, 94.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.4 us, 0.7 sy, 0.0 ni, 70.4 id, 26.5 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169300 total, 3323248 free, 436748 used, 4409304 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7412556 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12280 root 20 0 103304 28824 7276 S 14.0 0.4 0:08.77 python
16 root 20 0 0 0 0 S 0.3 0.0 0:09.22 ksoftirqd/1
1549 root 20 0 236712 24480 9864 S 0.3 0.3 3:31.38 python3
观察 top 的输出可以发现,两个 CPU 的 iowait 都非常高。特别是 CPU0, iowait 已经高达 94 %,而剩余内存还有 3GB,看起来也是充足的。再往下看,进程部分有一个 python 进程的 CPU 使用率稍微有点高,达到了 14%。虽然 14% 并不能成为性能瓶颈,不过有点嫌疑——可能跟 iowait 的升高有关。
运行下面的 iostat 命令
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 71.00 0.00 32912.00 0.00 0.00 0.00 0.00 0.00 18118.31 241.89 0.00 463.55 13.86 98.40
明白了指标含义,再来具体观察 iostat 的输出。你可以发现,磁盘 sda 的 I/O 使用率已经达到 98% ,接近饱和了。而且,写请求的响应时间高达 18 秒,每秒的写数据为 32 MB,显然写磁盘碰到了瓶颈。
这些 I/O 请求到底是哪些进程导致的呢?我想,你已经还记得上一节我们用到的 pidstat。
$ pidstat -d 1
14:39:14 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
14:39:15 0 12280 0.00 335716.00 0.00 0 python
我们再次看到了 PID 号为 12280 的结果。这说明,正是案例应用引发 I/O 的性能瓶颈。
先用 strace 确认它是不是在写文件,再用 lsof 找出文件描述符对应的文件即可。
$ strace -p 12280
strace: Process 12280 attached
select(0, NULL, NULL, NULL, {tv_sec=0, tv_usec=567708}) = 0 (Timeout)
stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0
stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0
从 strace 中,你可以看到大量的 stat 系统调用,并且大都为 python 的文件,但是,请注意,这里并没有任何 write 系统调用。
这里我给你介绍一个新工具, filetop。它是 bcc 软件包的一部分,基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,主要跟踪内核中文件的读写情况,并输出线程 ID(TID)、读写大小、读写类型以及文件名称。
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install bcc-tools libbcc-examples linux-headers-$(uname -r)
# 切换到工具目录
$ cd /usr/share/bcc/tools
# -C 选项表示输出新内容时不清空屏幕
$ ./filetop -C
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 0 1 0 2832 R 669.txt
514 python 0 1 0 2490 R 667.txt
514 python 0 1 0 2685 R 671.txt
514 python 0 1 0 2392 R 670.txt
514 python 0 1 0 2050 R 672.txt
...
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 2 0 5957 0 R 651.txt
514 python 2 0 5371 0 R 112.txt
514 python 2 0 4785 0 R 861.txt
514 python 2 0 4736 0 R 213.txt
514 python 2 0 4443 0 R 45.txt
你会看到,filetop 输出了 8 列内容,分别是线程 ID、线程命令行、读写次数、读写的大小(单位 KB)、文件类型以及读写的文件名称。
线程号为 514 的线程,属于哪个进程呢?我们可以用 ps 命令查看。先在终端一中,按下 Ctrl+C ,停止 filetop ;然后,运行下面的 ps 命令。这个输出的第二列内容,就是我们想知道的进程号:
$ ps -efT | grep 514
root 12280 514 14626 33 14:47 pts/0 00:00:05 /usr/local/bin/python /app.py
我们看到,这个线程正是案例应用 12280 的线程。终于可以先松一口气,不过还没完,filetop 只给出了文件名称,却没有文件路径,还得继续找啊。我再介绍一个好用的工具,opensnoop 。它同属于 bcc 软件包,可以动态跟踪内核中的 open 系统调用。这样,我们就可以找出这些 txt 文件的路径。
$ opensnoop
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/650.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/651.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/652.txt
案例篇:一个SQL查询要15秒,这是怎么回事?
我们在终端一执行 top 命令,分析系统的 CPU 使用情况:
$ top
top - 12:02:15 up 6 days, 8:05, 1 user, load average: 0.66, 0.72, 0.59
Tasks: 137 total, 1 running, 81 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 1.3 sy, 0.0 ni, 35.9 id, 62.1 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.7 sy, 0.0 ni, 84.7 id, 14.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169300 total, 7238472 free, 546132 used, 384696 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7316952 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27458 999 20 0 833852 57968 13176 S 1.7 0.7 0:12.40 mysqld
27617 root 20 0 24348 9216 4692 S 1.0 0.1 0:04.40 python
1549 root 20 0 236716 24568 9864 S 0.3 0.3 51:46.57 python3
22421 root 20 0 0 0 0 I 0.3 0.0 0:01.16 kworker/u
观察 top 的输出,我们发现,两个 CPU 的 iowait 都比较高,特别是 CPU0,iowait 已经超过 60%。而具体到各个进程, CPU 使用率并不高,最高的也只有 1.7%。
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
...
sda 273.00 0.00 32568.00 0.00 0.00 0.00 0.00 0.00 7.90 0.00 1.16 119.30 0.00 3.56 97.20
而 I/O 使用率高达 97% ,接近饱和,这说明,磁盘 sda 的读取确实碰到了性能瓶颈。
那要怎么知道,这些 I/O 请求到底是哪些进程导致的呢?当然可以找我们的老朋友, pidstat。接下来,在终端一中,按下 Ctrl+C 停止 iostat 命令,然后运行下面的 pidstat 命令,观察进程的 I/O 情况:
# -d选项表示展示进程的I/O情况
$ pidstat -d 1
12:04:11 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:04:12 999 27458 32640.00 0.00 0.00 0 mysqld
12:04:12 0 27617 4.00 4.00 0.00 3 python
12:04:12 0 27864 0.00 4.00 0.00 0 systemd-journal
从 pidstat 的输出可以看到,PID 为 27458 的 mysqld 进程正在进行大量的读,而且读取速度是 32 MB/s,跟刚才 iostat 的发现一致。两个结果一对比,我们自然就找到了磁盘 I/O 瓶颈的根源,即 mysqld 进程。
要分析进程的数据读取,当然还要靠上一节用到过的 strace+ lsof 组合。为了不漏掉这些线程的数据读取情况,你要记得在执行 stace 命令时,加上 -f 参数:
$ strace -f -p 27458
[pid 28014] read(38, "934EiwT363aak7VtqF1mHGa4LL4Dhbks"..., 131072) = 131072
[pid 28014] read(38, "hSs7KBDepBqA6m4ce6i6iUfFTeG9Ot9z"..., 20480) = 20480
[pid 28014] read(38, "NRhRjCSsLLBjTfdqiBRLvN9K6FRfqqLm"..., 131072) = 131072
[pid 28014] read(38, "AKgsik4BilLb7y6OkwQUjjqGeCTQTaRl"..., 24576) = 24576
[pid 28014] read(38, "hFMHx7FzUSqfFI22fQxWCpSnDmRjamaW"..., 131072) = 131072
[pid 28014] read(38, "ajUzLmKqivcDJSkiw7QWf2ETLgvQIpfC"..., 20480) = 20480
$ lsof -p 27458
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
...
mysqld 27458 999 38u REG 8,1 512440000 2601895 /var/lib/mysql/test/products.MYD
这次我们得到了 lsof 的输出。从输出中可以看到, mysqld 进程确实打开了大量文件,而根据文件描述符(FD)的编号,我们知道,描述符为 38 的是一个路径为 /var/lib/mysql/test/products.MYD 的文件。这里注意, 38 后面的 u 表示, mysqld 以读写的方式访问文件。
解决方案
- 加索引
mysql> CREATE INDEX products_index ON products (productName(64));
Query OK, 10000 rows affected (14.45 sec)
Records: 10000 Duplicates: 0 Warnings: 0
- 停止 DataService 应用,因为这个会一直把 /proc/sys/vm/drop_caches 改成 1。这个会导致MySQL 的文件缓存失效。
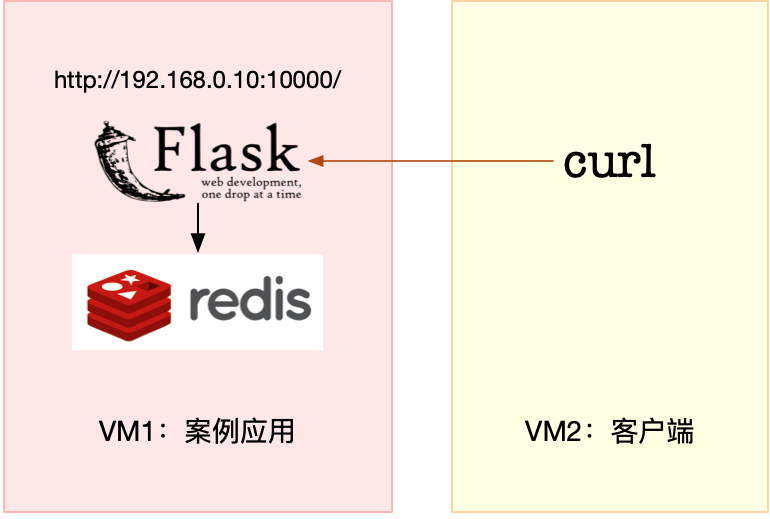
案例篇:Redis响应严重延迟,如何解决?
$ top
top - 12:46:18 up 11 days, 8:49, 1 user, load average: 1.36, 1.36, 1.04
Tasks: 137 total, 1 running, 79 sleeping, 0 stopped, 0 zombie
%Cpu0 : 6.0 us, 2.7 sy, 0.0 ni, 5.7 id, 84.7 wa, 0.0 hi, 1.0 si, 0.0 st
%Cpu1 : 1.0 us, 3.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
KiB Mem : 8169300 total, 7342244 free, 432912 used, 394144 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7478748 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9181 root 20 0 193004 27304 8716 S 8.6 0.3 0:07.15 python
9085 systemd+ 20 0 28352 9760 1860 D 5.0 0.1 0:04.34 redis-server
368 root 20 0 0 0 0 D 1.0 0.0 0:33.88 jbd2/sda1-8
149 root 0 -20 0 0 0 I 0.3 0.0 0:10.63 kworker/0:1H
1549 root 20 0 236716 24576 9864 S 0.3 0.3 91:37.30 python3
观察 top 的输出可以发现,CPU0 的 iowait 比较高,已经达到了 84%;而各个进程的 CPU 使用率都不太高,最高的 python 和 redis-server ,也分别只有 8% 和 5%。再看内存,总内存 8GB,剩余内存还有 7GB 多,显然内存也没啥问题。
还在第一个终端中,先按下 Ctrl+C,停止 top 命令;然后,执行下面的 iostat 命令,查看有没有 I/O 性能问题:
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
...
sda 0.00 492.00 0.00 2672.00 0.00 176.00 0.00 26.35 0.00 1.76 0.00 0.00 5.43 0.00 0.00
观察 iostat 的输出,我们发现,磁盘 sda 每秒的写数据(wkB/s)为 2.5MB,I/O 使用率(%util)是 0。看来,虽然有些 I/O 操作,但并没导致磁盘的 I/O 瓶颈。
要知道 I/O 请求来自哪些进程,还是要靠我们的老朋友 pidstat。在终端一中运行下面的 pidstat 命令,观察进程的 I/O 情况:
$ pidstat -d 1
12:49:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:49:36 0 368 0.00 16.00 0.00 86 jbd2/sda1-8
12:49:36 100 9085 0.00 636.00 0.00 1 redis-server
从 pidstat 的输出,我们看到,I/O 最多的进程是 PID 为 9085 的 redis-server,并且它也刚好是在写磁盘。这说明,确实是 redis-server 在进行磁盘写。
当然,光找到读写磁盘的进程还不够,我们还要再用 strace+lsof 组合,看看 redis-server 到底在写什么。
# -f表示跟踪子进程和子线程,-T表示显示系统调用的时长,-tt表示显示跟踪时间
$ strace -f -T -tt -p 9085
[pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055>
[pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071>
[pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063>
[pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173>
[pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032>
[pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044>
[pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043>
[pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141>
[pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049>
[pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043>
[pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034>
[pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288>
[pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057>
[pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040>
[pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052>
[pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060>
[pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415>
[pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250>
从系统调用来看, epoll_pwait、read、write、fdatasync 这些系统调用都比较频繁。那么,刚才观察到的写磁盘,应该就是 write 或者 fdatasync 导致的了。
$ lsof -p 9085
redis-ser 9085 systemd-network 3r FIFO 0,12 0t0 15447970 pipe
redis-ser 9085 systemd-network 4w FIFO 0,12 0t0 15447970 pipe
redis-ser 9085 systemd-network 5u a_inode 0,13 0 10179 [eventpoll]
redis-ser 9085 systemd-network 6u sock 0,9 0t0 15447972 protocol: TCP
redis-ser 9085 systemd-network 7w REG 8,1 8830146 2838532 /data/appendonly.aof
redis-ser 9085 systemd-network 8u sock 0,9 0t0 15448709 protocol: TCP
结合磁盘写的现象,我们知道,只有 7 号普通文件才会产生磁盘写,而它操作的文件路径是 /data/appendonly.aof,相应的系统调用包括 write 和 fdatasync。
如果你对 Redis 的持久化配置比较熟,看到这个文件路径以及 fdatasync 的系统调用,你应该能想到,这对应着正是 Redis 持久化配置中的 appendonly 和 appendfsync 选项。很可能是因为它们的配置不合理,导致磁盘写比较多。
继续在终端一中,运行下面的命令,查询 appendonly 和 appendfsync 的配置:
$ docker exec -it redis redis-cli config get 'append*'
1) "appendfsync"
2) "always"
3) "appendonly"
4) "yes"
这里做一下简单介绍。
Redis 提供了两种数据持久化的方式,分别是快照和追加文件。
快照方式,会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中。为了避免阻塞主进程,Redis 还会 fork 出一个子进程,来负责快照的保存。这种方式的性能好,无论是备份还是恢复,都比追加文件好很多。
不过,它的缺点也很明显。在数据量大时,fork 子进程需要用到比较大的内存,保存数据也很耗时。所以,你需要设置一个比较长的时间间隔来应对,比如至少 5 分钟。这样,如果发生故障,你丢失的就是几分钟的数据。
追加文件,则是用在文件末尾追加记录的方式,对 Redis 写入的数据,依次进行持久化,所以它的持久化也更安全。
此外,它还提供了一个用 appendfsync 选项设置 fsync 的策略,确保写入的数据都落到磁盘中,具体选项包括 always、everysec、no 等。
- always 表示,每个操作都会执行一次 fsync,是最为安全的方式;
- everysec 表示,每秒钟调用一次 fsync ,这样可以保证即使是最坏情况下,也只丢失 1 秒的数据;
- 而 no 表示交给操作系统来处理。
我们可以给 lsof 命令加上 -i 选项,找出 TCP socket 对应的 TCP 连接信息。不过,由于 Redis 和 Python 应用都在容器中运行,我们需要进入容器的网络命名空间内部,才能看到完整的 TCP 连接。
下面的命令用到的 nsenter 工具,可以进入容器命名空间。如果你的系统没有安装,请运行下面命令安装 nsenter:docker run --rm -v /usr/local/bin:/target jpetazzo/nsenter
# 由于这两个容器共享同一个网络命名空间,所以我们只需要进入app的网络命名空间即可
$ PID=$(docker inspect --format {{.State.Pid}} app)
# -i表示显示网络套接字信息
$ nsenter --target $PID --net -- lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 9085 systemd-network 6u IPv4 15447972 0t0 TCP localhost:6379 (LISTEN)
redis-ser 9085 systemd-network 8u IPv4 15448709 0t0 TCP localhost:6379->localhost:32996 (ESTABLISHED)
python 9181 root 3u IPv4 15448677 0t0 TCP *:http (LISTEN)
python 9181 root 5u IPv4 15449632 0t0 TCP localhost:32996->localhost:6379 (ESTABLISHED)
这次我们可以看到,redis-server 的 8 号文件描述符,对应 TCP 连接 localhost:6379->localhost:32996。其中, localhost:6379 是 redis-server 自己的监听端口,自然 localhost:32996 就是 redis 的客户端。再观察最后一行,localhost:32996 对应的,正是我们的 Python 应用程序(进程号为 9181)。
解决方案
第一个问题,Redis 配置的 appendfsync 是 always,这就导致 Redis 每次的写操作,都会触发 fdatasync 系统调用。今天的案例,没必要用这么高频的同步写,使用默认的 1s 时间间隔,就足够了。
第二个问题,Python 应用在查询接口中会调用 Redis 的 SADD 命令,这很可能是不合理使用缓存导致的。改代码
套路篇:如何迅速分析出系统I/O的瓶颈在哪里?
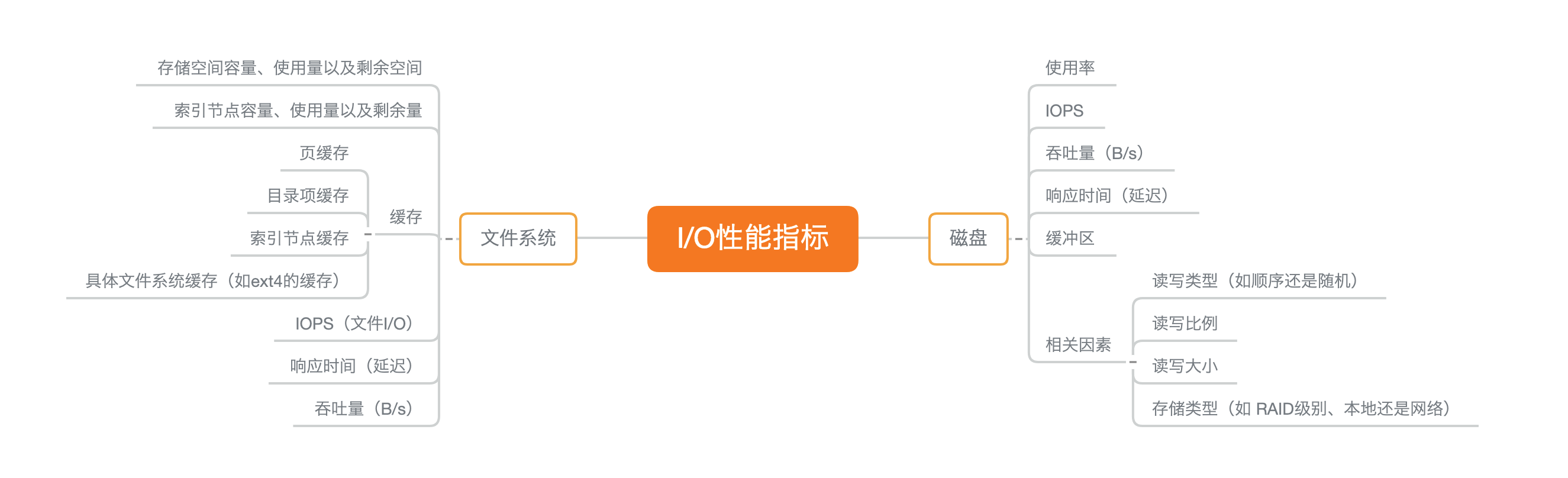
性能指标
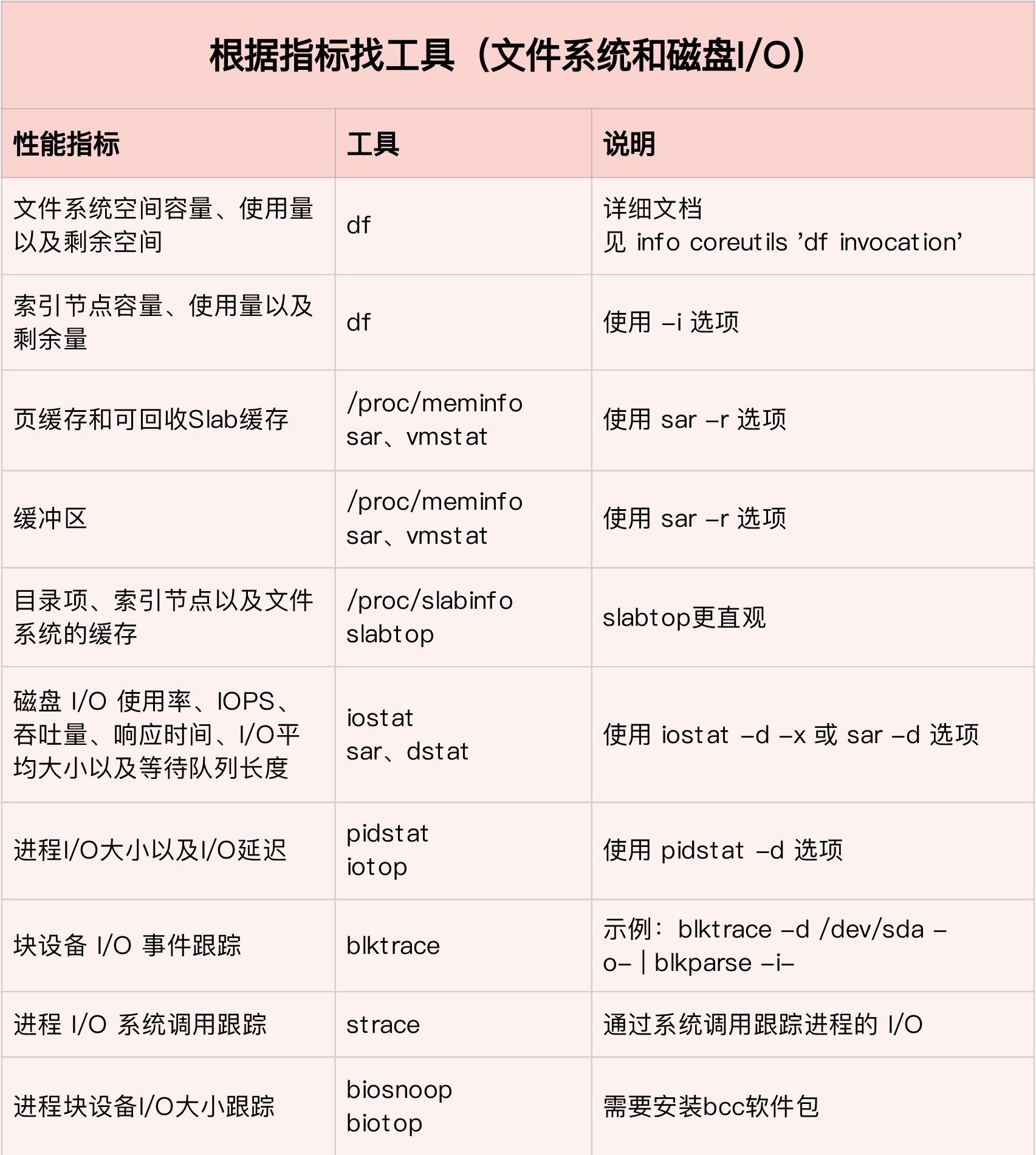
性能工具
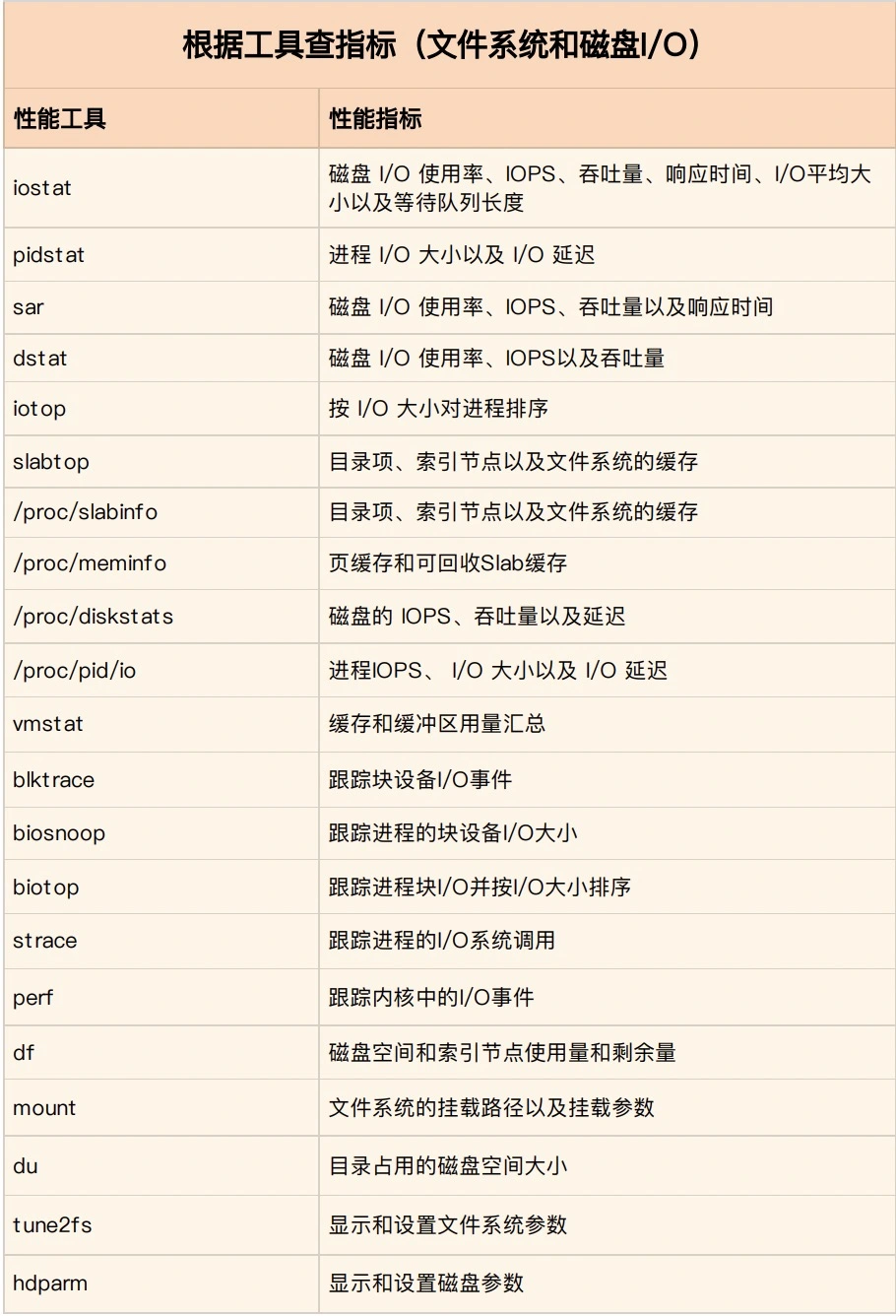
如何迅速分析 I/O 的性能瓶颈
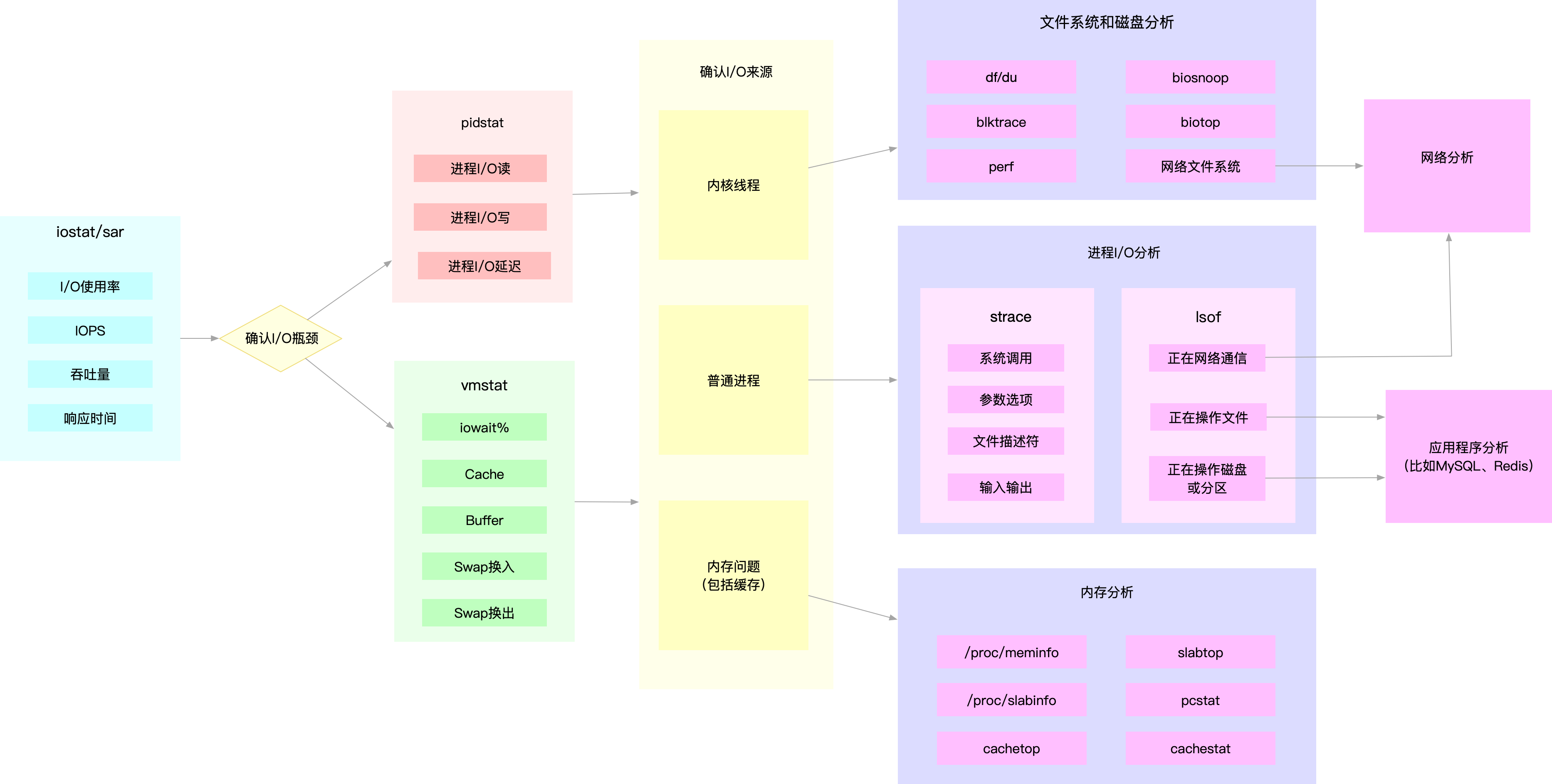
为了缩小排查范围,我通常会先运行那几个支持指标较多的工具,如 iostat、vmstat、pidstat 等。然后再根据观察到的现象,结合系统和应用程序的原理,寻找下一步的分析方向。
套路篇:磁盘 I/O 性能优化的几个思路
I/O 基准测试
为了更客观合理地评估优化效果,我们首先应该对磁盘和文件系统进行基准测试,得到文件系统或者磁盘 I/O 的极限性能。
fio(Flexible I/O Tester)正是最常用的文件系统和磁盘 I/O 性能基准测试工具。它提供了大量的可定制化选项,可以用来测试,裸盘或者文件系统在各种场景下的 I/O 性能,包括了不同块大小、不同 I/O 引擎以及是否使用缓存等场景。
# Ubuntu
apt-get install -y fio
# CentOS
yum install -y fio
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
在这其中,有几个参数需要你重点关注一下。
- direct,表示是否跳过系统缓存。上面示例中,我设置的 1 ,就表示跳过系统缓存。
- iodepth,表示使用异步 I/O(asynchronous I/O,简称 AIO)时,同时发出的 I/O 请求上限。在上面的示例中,我设置的是 64。
- rw,表示 I/O 模式。我的示例中, read/write 分别表示顺序读 / 写,而 randread/randwrite 则分别表示随机读 / 写。
- ioengine,表示 I/O 引擎,它支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。上面示例中,我设置的 libaio 表示使用异步 I/O。
- bs,表示 I/O 的大小。示例中,我设置成了 4K(这也是默认值)。
- filename,表示文件路径,当然,它可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。示例中,我把它设置成了磁盘 /dev/sdb。不过注意,用磁盘路径测试写,会破坏这个磁盘中的文件系统,所以在使用前,你一定要事先做好数据备份。
下面就是我使用 fio 测试顺序读的一个报告示例。
read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=16.7MiB/s,w=0KiB/s][r=4280,w=0 IOPS][eta 00m:00s]
read: (groupid=0, jobs=1): err= 0: pid=17966: Sun Dec 30 08:31:48 2018
read: IOPS=4257, BW=16.6MiB/s (17.4MB/s)(1024MiB/61568msec)
slat (usec): min=2, max=2566, avg= 4.29, stdev=21.76
clat (usec): min=228, max=407360, avg=15024.30, stdev=20524.39
lat (usec): min=243, max=407363, avg=15029.12, stdev=20524.26
clat percentiles (usec):
| 1.00th=[ 498], 5.00th=[ 1020], 10.00th=[ 1319], 20.00th=[ 1713],
| 30.00th=[ 1991], 40.00th=[ 2212], 50.00th=[ 2540], 60.00th=[ 2933],
| 70.00th=[ 5407], 80.00th=[ 44303], 90.00th=[ 45351], 95.00th=[ 45876],
| 99.00th=[ 46924], 99.50th=[ 46924], 99.90th=[ 48497], 99.95th=[ 49021],
| 99.99th=[404751]
bw ( KiB/s): min= 8208, max=18832, per=99.85%, avg=17005.35, stdev=998.94, samples=123
iops : min= 2052, max= 4708, avg=4251.30, stdev=249.74, samples=123
lat (usec) : 250=0.01%, 500=1.03%, 750=1.69%, 1000=2.07%
lat (msec) : 2=25.64%, 4=37.58%, 10=2.08%, 20=0.02%, 50=29.86%
lat (msec) : 100=0.01%, 500=0.02%
cpu : usr=1.02%, sys=2.97%, ctx=33312, majf=0, minf=75
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwt: total=262144,0,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=16.6MiB/s (17.4MB/s), 16.6MiB/s-16.6MiB/s (17.4MB/s-17.4MB/s), io=1024MiB (1074MB), run=61568-61568msec
Disk stats (read/write):
sdb: ios=261897/0, merge=0/0, ticks=3912108/0, in_queue=3474336, util=90.09%
这个报告中,需要我们重点关注的是, slat、clat、lat ,以及 bw 和 iops 这几行。
先来看刚刚提到的前三个参数。事实上,slat、clat、lat 都是指 I/O 延迟(latency)。不同之处在于:
- slat ,是指从 I/O 提交到实际执行 I/O 的时长(Submission latency);
- clat ,是指从 I/O 提交到 I/O 完成的时长(Completion latency);
- 而 lat ,指的是从 fio 创建 I/O 到 I/O 完成的总时长。
这里需要注意的是,对同步 I/O 来说,由于 I/O 提交和 I/O 完成是一个动作,所以 slat 实际上就是 I/O 完成的时间,而 clat 是 0。而从示例可以看到,使用异步 I/O(libaio)时,lat 近似等于 slat + clat 之和。
再来看 bw ,它代表吞吐量。在我上面的示例中,你可以看到,平均吞吐量大约是 16 MB(17005 KiB/1024)。
最后的 iops ,其实就是每秒 I/O 的次数,上面示例中的平均 IOPS 为 4250。
幸运的是,fio 支持 I/O 的重放。借助前面提到过的 blktrace,再配合上 fio,就可以实现对应用程序 I/O 模式的基准测试。你需要先用 blktrace ,记录磁盘设备的 I/O 访问情况;然后使用 fio ,重放 blktrace 的记录。
# 使用blktrace跟踪磁盘I/O,注意指定应用程序正在操作的磁盘
$ blktrace /dev/sdb
# 查看blktrace记录的结果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 将结果转化为二进制文件
$ blkparse sdb -d sdb.bin
# 使用fio重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin
I/O 性能优化
应用程序优化
第一,可以用追加写代替随机写,减少寻址开销,加快 I/O 写的速度。
第二,可以借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数。
第三,可以在应用程序内部构建自己的缓存,或者用 Redis 这类外部缓存系统。这样,一方面,能在应用程序内部,控制缓存的数据和生命周期;另一方面,也能降低其他应用程序使用缓存对自身的影响。
第四,在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存的拷贝次数。
第五,在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用 fsync() 取代 O_SYNC。
第六,在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐你使用 cgroups 的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量。
最后,在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。ionice 支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
文件系统优化
第一,你可以根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用 xfs 文件系统。相比于 ext4 ,xfs 支持更大的磁盘分区和更大的文件数量,如 xfs 支持大于 16TB 的磁盘。但是 xfs 文件系统的缺点在于无法收缩,而 ext4 则可以。
第二,在选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载选项(如 noatime)等等。比如, 使用 tune2fs 这个工具,可以调整文件系统的特性(tune2fs 也常用来查看文件系统超级块的内容)。 而通过 /etc/fstab ,或者 mount 命令行参数,我们可以调整文件系统的日志模式和挂载选项等。
第三,可以优化文件系统的缓存。比如,你可以优化 pdflush 脏页的刷新频率(比如设置 dirty_expire_centisecs 和 dirty_writeback_centisecs)以及脏页的限额(比如调整 dirty_background_ratio 和 dirty_ratio 等)。再如,你还可以优化内核回收目录项缓存和索引节点缓存的倾向,即调整 vfs_cache_pressure(/proc/sys/vm/vfs_cache_pressure,默认值 100),数值越大,就表示越容易回收。
最后,在不需要持久化时,你还可以用内存文件系统 tmpfs,以获得更好的 I/O 性能 。tmpfs 把数据直接保存在内存中,而不是磁盘中。比如 /dev/shm/ ,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化
第一,最简单有效的优化方法,就是换用性能更好的磁盘,比如用 SSD 替代 HDD。
第二,我们可以使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
第三,针对磁盘和应用程序 I/O 模式的特征,我们可以选择最适合的 I/O 调度算法。比方说,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法。而数据库应用,我更推荐使用 deadline 算法。
第四,我们可以对应用程序的数据,进行磁盘级别的隔离。比如,我们可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
第五,在顺序读比较多的场景中,我们可以增大磁盘的预读数据,比如,你可以通过下面两种方法,调整 /dev/sdb 的预读大小。
- 调整内核选项 /sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。
- 使用 blockdev 工具设置,比如 blockdev --setra 8192 /dev/sdb,注意这里的单位是 512B(0.5KB),所以它的数值总是 read_ahead_kb 的两倍。
第六,我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
最后,要注意,磁盘本身出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时,你还需要确认,磁盘本身是不是出现了硬件错误。比如,你可以查看 dmesg 中是否有硬件 I/O 故障的日志。 还可以使用 badblocks、smartctl 等工具,检测磁盘的硬件问题,或用 e2fsck 等来检测文件系统的错误。如果发现问题,你可以使用 fsck 等工具来修复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号