《趣谈 Linux 操作系统》系统初始化——小记随笔
x86 架构
作为 Linux 操作系统,何尝不是这样。如果下面的硬件环境千差万别,就会很难集中精力做出让用户易用的产品。毕竟天天适配不同的平台,就已经够头大了。x86 架构就是这样一个开放的平台。今天我们就来解析一下它。
计算机的工作模式是什么样的?
CPU 和内存是完成计算任务的核心组件,所以这里我们重点介绍一下 CPU 和内存是如何配合工作的。
CPU 其实也不是单纯的一块,它包括三个部分,运算单元、数据单元和控制单元。
- 运算单元只管算,例如做加法、做位移等等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。
- 运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了数据单元。数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快,可以暂时存放数据和运算结果。
- 有了放数据的地方,也有了算的地方,还需要有个指挥到底做什么运算的地方,这就是控制单元。控制单元是一个统一的指挥中心,它可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。

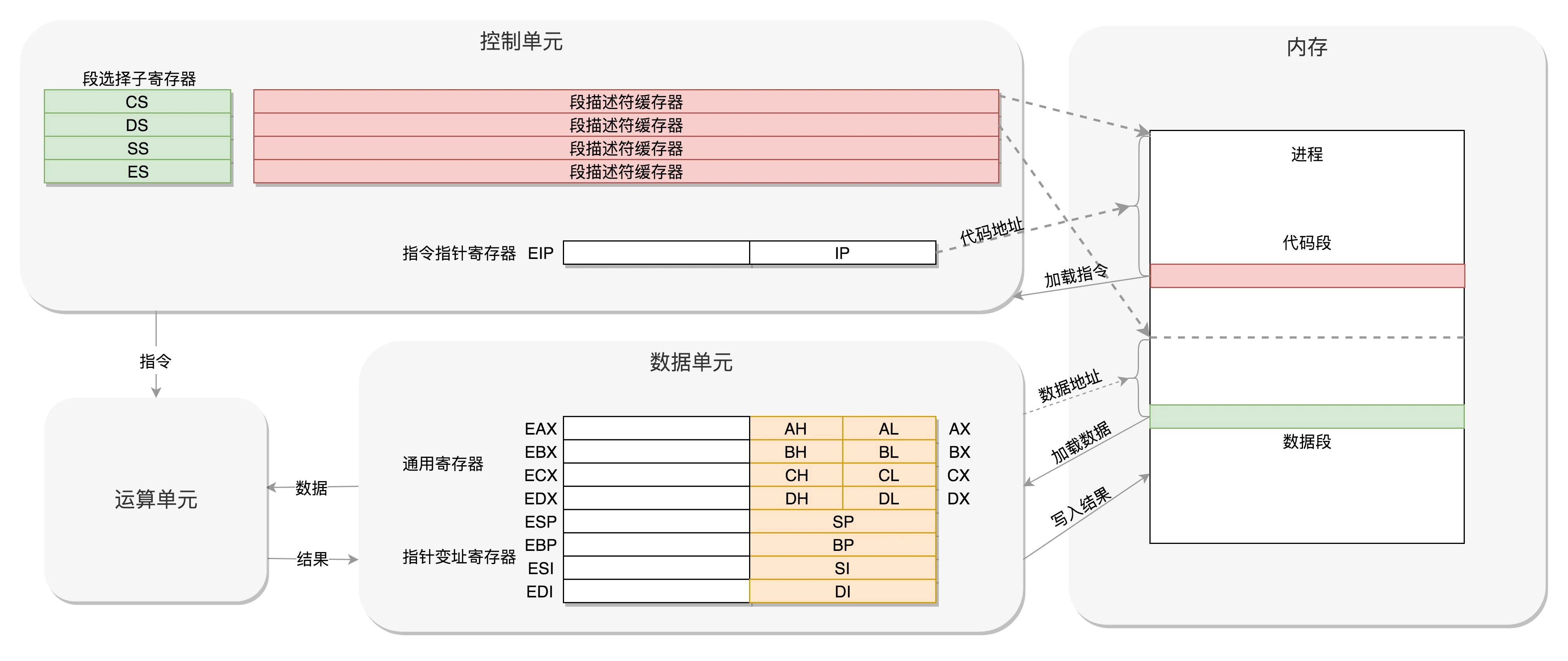
每个进程都有一个程序放在硬盘上,是二进制的,再里面就是一行行的指令,会操作一些数据。
进程一旦运行,比如图中两个进程 A 和 B,会有独立的内存空间,互相隔离,程序会分别加载到进程 A 和进程 B 的内存空间里面,形成各自的代码段。当然真实情况肯定比我说的要复杂的多,进程的内存虽然隔离但不连续,除了简单的区分代码段和数据段,还会分得更细。
程序运行的过程中要操作的数据和产生的计算结果,都会放在数据段里面。
CPU 的控制单元里面,有一个指令指针寄存器,它里面存放的是下一条指令在内存中的地址。控制单元会不停地将代码段的指令拿进来,先放入指令寄存器。
当前的指令分两部分,一部分是做什么操作,例如是加法还是位移;一部分是操作哪些数据。要执行这条指令,就要把第一部分交给运算单元,第二部分交给数据单元。
数据单元根据数据的地址,从数据段里读到数据寄存器里,就可以参与运算了。运算单元做完运算,产生的结果会暂存在数据单元的数据寄存器里。最终,会有指令将数据写回内存中的数据段。
CPU 里有两个寄存器,专门保存当前处理进程的代码段的起始地址,以及数据段的起始地址。这里面写的都是进程 A,那当前执行的就是进程 A 的指令,等切换成进程 B,就会执行 B 的指令了,这个过程叫作进程切换(Process Switch)。
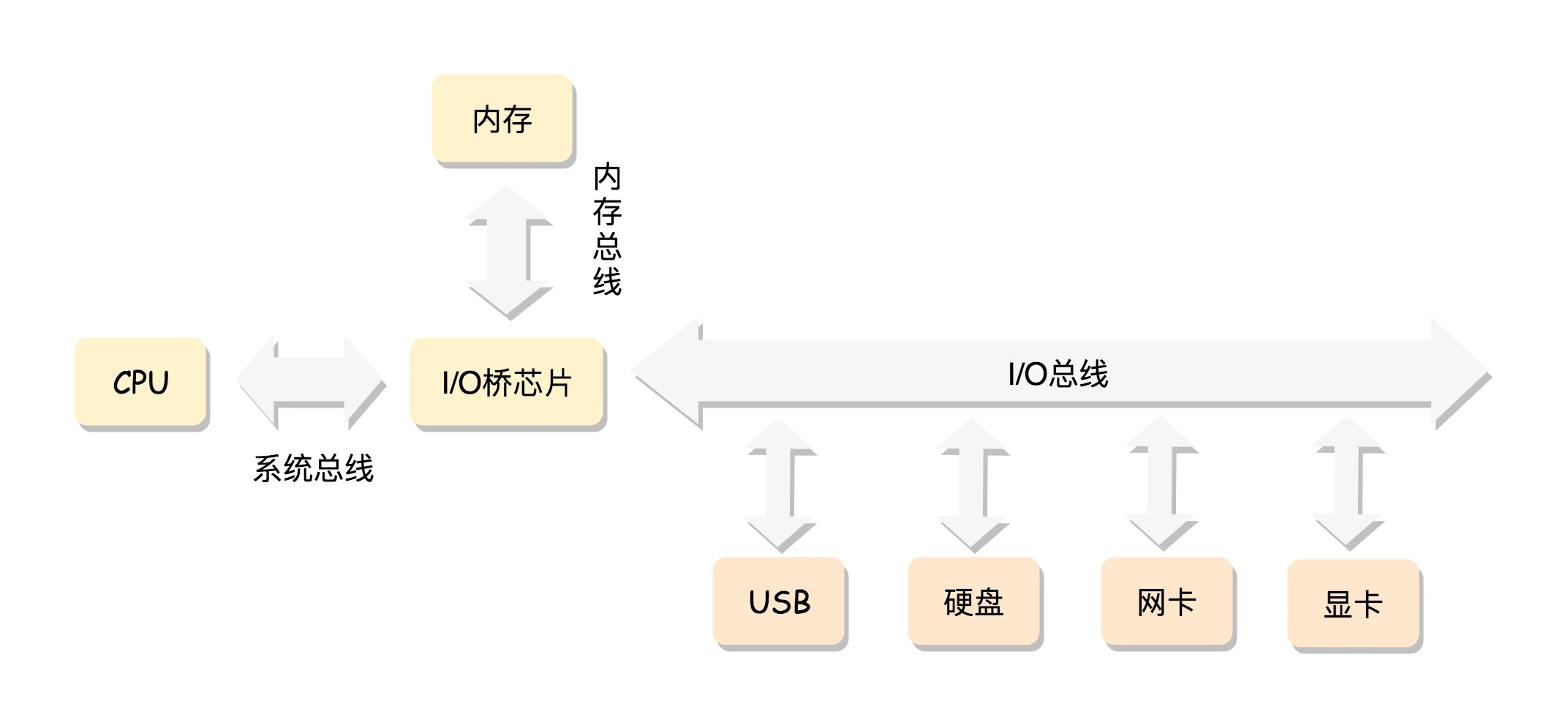
CPU 和内存来来回回传数据,靠的都是总线。其实总线上主要有两类数据,一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(Address Bus);另一类是真正的数据,这类总线叫数据总线(Data Bus)。
所以说,总线其实有点像连接 CPU 和内存这两个设备的高速公路,说总线到底是多少位,就类似说高速公路有几个车道。但是这两种总线的位数意义是不同的。
地址总线的位数,决定了能访问的地址范围到底有多广。例如只有两位,那 CPU 就只能认 00,01,10,11 四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
而数据总线的位数,决定了一次能拿多少个数据进来。例如只有两位,那 CPU 一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快。
从 8086 的原理说起
x86 中最经典的一款处理器,8086 处理器。
数据单元
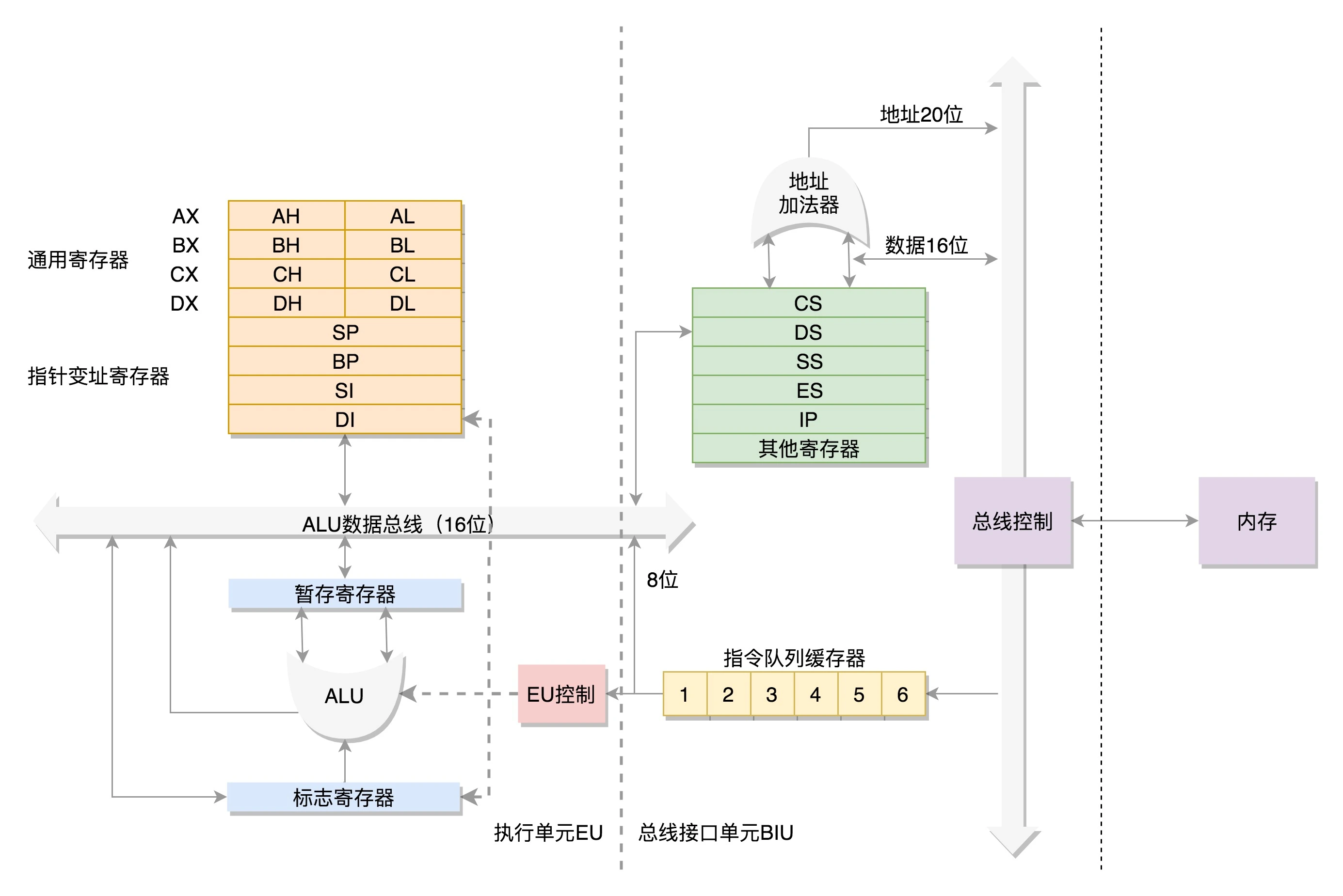
为了暂存数据,8086 处理器内部有 8 个 16 位的通用寄存器,也就是刚才说的 CPU 内部的数据单元,分别是 AX、BX、CX、DX、SP、BP、SI、DI。这些寄存器主要用于在计算过程中暂存数据。
这些寄存器比较灵活,其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
控制单元
IP 寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置。
如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16 位的段寄存器,分别是 CS、DS、SS、ES。
- CS 就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;
- DS 是数据段的寄存器,通过它可以找到数据在内存中的位置。
- SS 是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则,push 就是入栈,pop 就是出栈。
数据如何从内存加载到寄存器
如果运算中需要加载内存中的数据,需要通过 DS 找到内存中的数据,加载到通用寄存器中,应该如何加载呢?对于一个段,有一个起始的地址,而段内的具体位置,我们称为偏移量(Offset)
在 CS 和 DS 中都存放着一个段的起始地址。代码段的偏移量在 IP 寄存器中,数据段的偏移量会放在通用寄存器中。
这时候问题来了,CS 和 DS 都是 16 位的,也就是说,起始地址都是 16 位的,IP 寄存器和通用寄存器都是 16 位的,偏移量也是 16 位的,但是 8086 的地址总线地址是 20 位。怎么凑够这 20 位呢?方法就是“起始地址 *16+ 偏移量”,也就是把 CS 和 DS 中的值左移 4 位,变成 20 位的,加上 16 位的偏移量,这样就可以得到最终 20 位的数据地址。
从这个计算方式可以算出,无论真正的内存多么大,对于只有 20 位地址总线的 8086 来讲,能够区分出的地址也就 2^20=1M
那一个段最大能有多大呢?因为偏移量只能是 16 位的,所以一个段最大的大小是 2^16=64k。
再来说 32 位处理器
在 32 位处理器中,有 32 根地址总线,可以访问 2^32=4G 的内存。使用原来的模式肯定不行了,但是又不能完全抛弃原来的模式,因为这个架构是开放的。
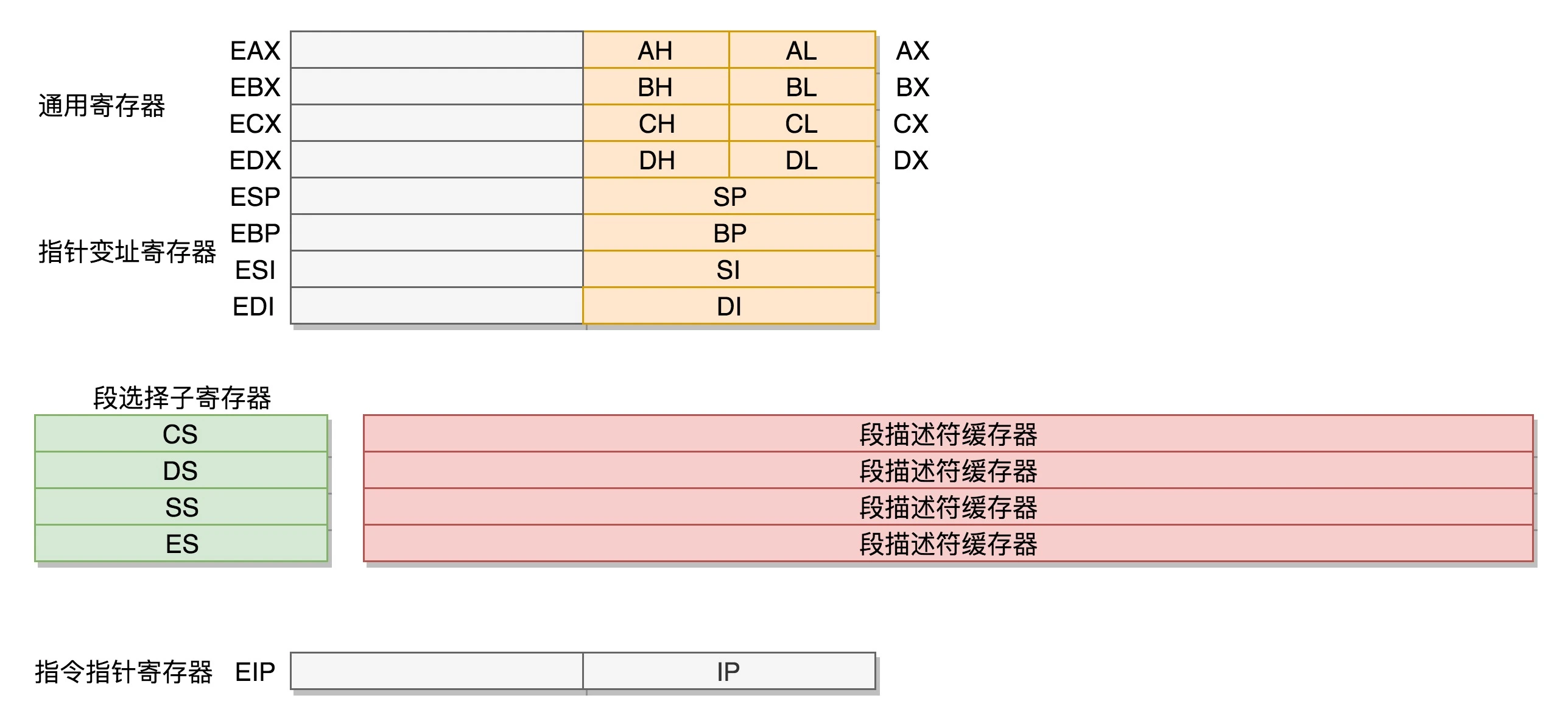
首先,通用寄存器有扩展,可以将 8 个 16 位的扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式。你可能会问,为什么高 16 位不分成两个 8 位使用呢?因为这样就不兼容了呀!
而改动比较大,有点不兼容的就是段寄存器(Segment Register)。因为原来的模式其实有点不伦不类,因为它没有把 16 位当成一个段的起始地址,也没有按 8 位或者 16 位扩展的形式,而是根据当时的硬件,弄了一个不上不下的 20 位的地址。这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。
如果新的段寄存器都改成 32 位的,明明 4G 的内存全部都能访问到,还左移不左移四位呢?
那我们索性就重新定义一把吧。CS、SS、DS、ES 仍然是 16 位的,但是不再是段的起始地址。段的起始地址放在内存的某个地方。这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor)。这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。
这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。这样段起始地址就会很灵活了。当然为了快速拿到段起始地址,段寄存器会从内存中拿到 CPU 的描述符高速缓存器中。
这样就不兼容了,咋办呢?好在后面这种模式灵活度非常高,可以保持将来一直兼容下去。前面的模式出现的时候,没想到自己能够成为一个标准,所以设计就没这么灵活。因而到了 32 位的系统架构下,我们将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern)。
当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的。也就是说,哪怕你买了 32 位的 CPU,也支持在原来的模式下运行,只不过快了一点而已。当需要更多内存的时候,你可以遵循一定的规则,进行一系列的操作,然后切换到保护模式,就能够用到 32 位 CPU 更强大的能力。
总结
从BIOS到bootloader:创业伊始,有活儿老板自己上
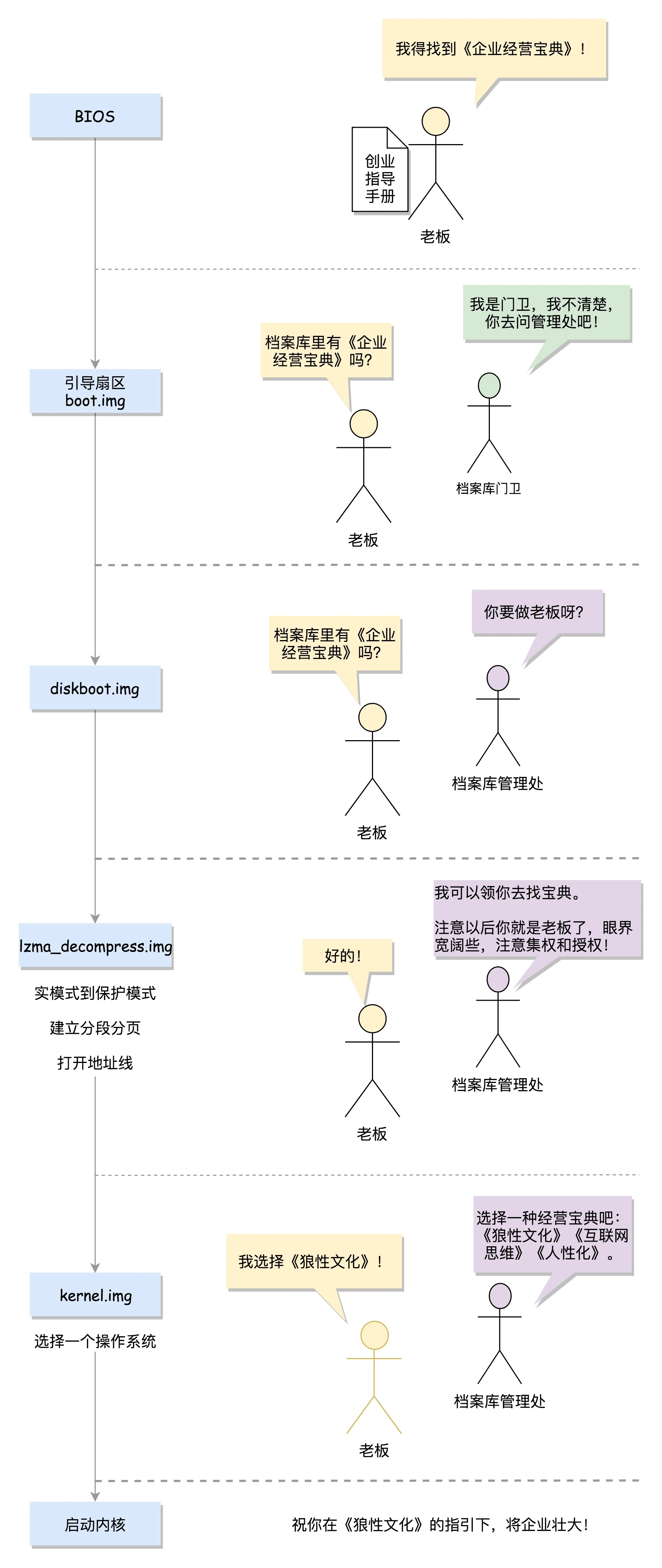
BIOS 时期
当你轻轻按下计算机的启动按钮时,你的主板就加上电了。
在主板上,有一个东西叫 ROM(Read Only Memory,只读存储器)。这和咱们平常说的内存 RAM(Random Access Memory,随机存取存储器)不同。
咱们平时买的内存条是可读可写的,这样才能保存计算结果。而 ROM 是只读的,上面早就固化了一些初始化的程序,也就是 BIOS(Basic Input and Output System,基本输入输出系统)。
创业初期,你的办公室肯定很小。假如现在你有 1M 的内存地址空间。这个空间非常有限,你需要好好利用才行。
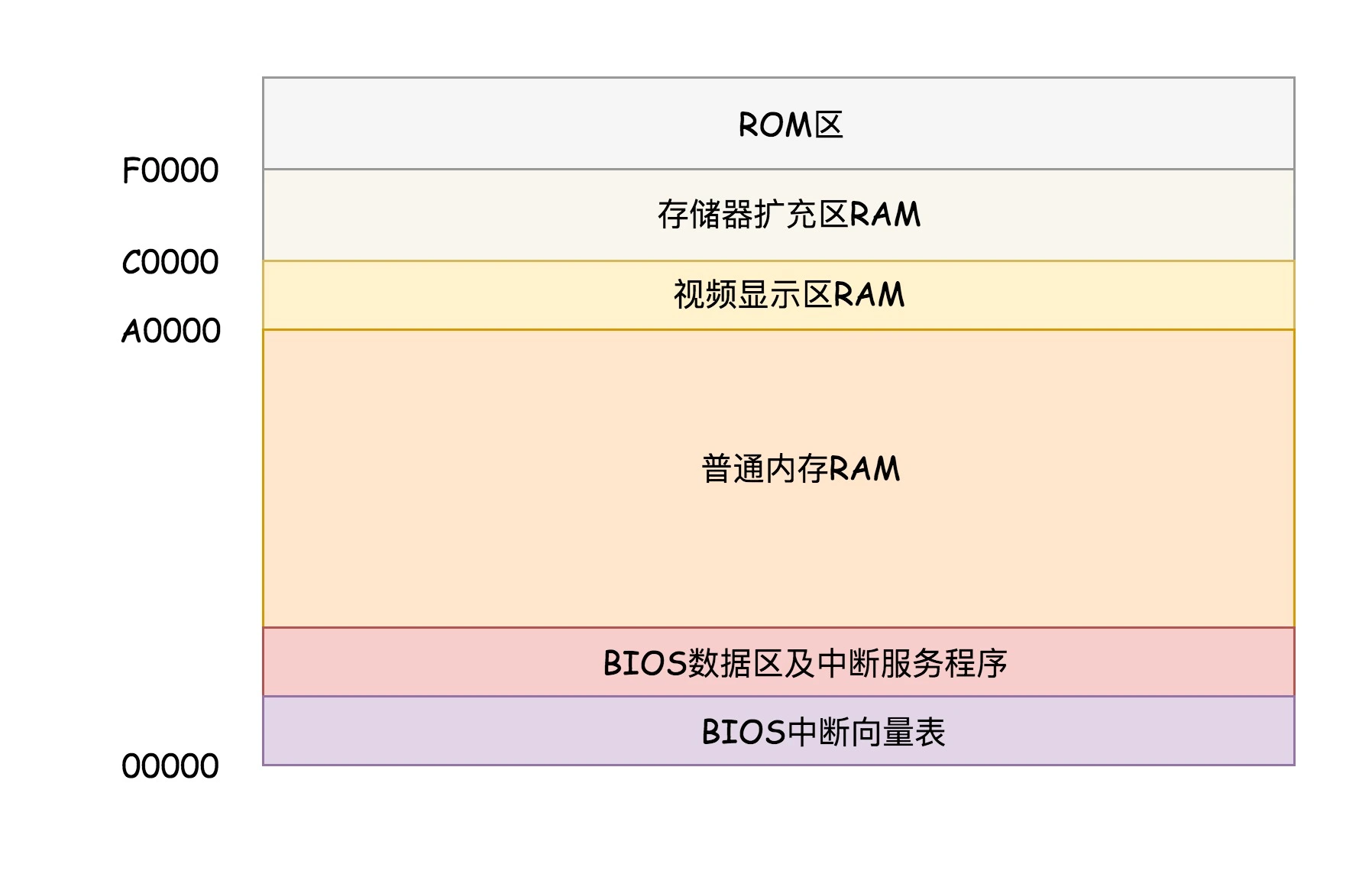
在 x86 系统中,将 1M 空间最上面的 0xF0000 到 0xFFFFF 这 64K 映射给 ROM,也就是说,到这部分地址访问的时候,会访问 ROM。
当电脑刚加电的时候,会做一些重置的工作,将 CS 设置为 0xFFFF,将 IP 设置为 0x0000,所以第一条指令就会指向 0xFFFF0,正是在 ROM 的范围内。在这里,有一个 JMP 命令会跳到 ROM 中做初始化工作的代码,于是,BIOS 开始进行初始化的工作。
bootloader 时期
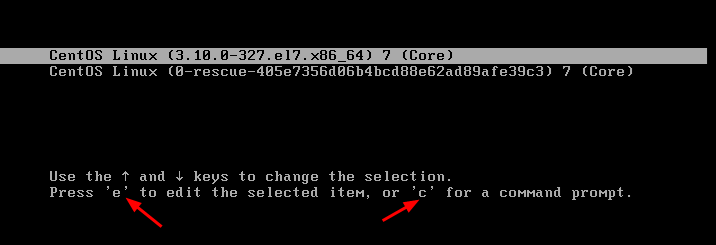
操作系统在哪儿呢?一般都会在安装在硬盘上,在 BIOS 的界面上。你会看到一个启动盘的选项。启动盘有什么特点呢?它一般在第一个扇区,占 512 字节,而且以 0xAA55 结束。这是一个约定,当满足这个条件的时候,就说明这是一个启动盘,在 512 字节以内会启动相关的代码。
这些代码是谁放在这里的呢?在 Linux 里面有一个工具,叫 Grub2,全称 Grand Unified Bootloader Version 2。顾名思义,就是搞系统启动的。
你可以通过 grub2-mkconfig -o /boot/grub2/grub.cfg 来配置系统启动的选项。你可以看到里面有类似这样的配置。
menuentry 'CentOS Linux (3.10.0-862.el7.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-862.el7.x86_64-advanced-b1aceb95-6b9e-464a-a589-bed66220ebee' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' b1aceb95-6b9e-464a-a589-bed66220ebee
else
search --no-floppy --fs-uuid --set=root b1aceb95-6b9e-464a-a589-bed66220ebee
fi
linux16 /boot/vmlinuz-3.10.0-862.el7.x86_64 root=UUID=b1aceb95-6b9e-464a-a589-bed66220ebee ro console=tty0 console=ttyS0,115200 crashkernel=auto net.ifnames=0 biosdevname=0 rhgb quiet
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img
}
这里面的选项会在系统启动的时候,成为一个列表,让你选择从哪个系统启动。最终显示出来的结果就是下面这张图。
使用 grub2-install /dev/sda,可以将启动程序安装到相应的位置。
grub2 第一个要安装的就是 boot.img。它由 boot.S 编译而成,一共 512 字节,正式安装到启动盘的第一个扇区。这个扇区通常称为 MBR(Master Boot Record,主引导记录 / 扇区)。
BIOS 完成任务后,会将 boot.img 从硬盘加载到内存中的 0x7c00 来运行。
由于 512 个字节实在有限,boot.img 做不了太多的事情。它能做的最重要的一个事情就是加载 grub2 的另一个镜像 core.img。
core.img 就是管理处,它们知道的和能做的事情就多了一些。core.img 由 lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做很多事情。
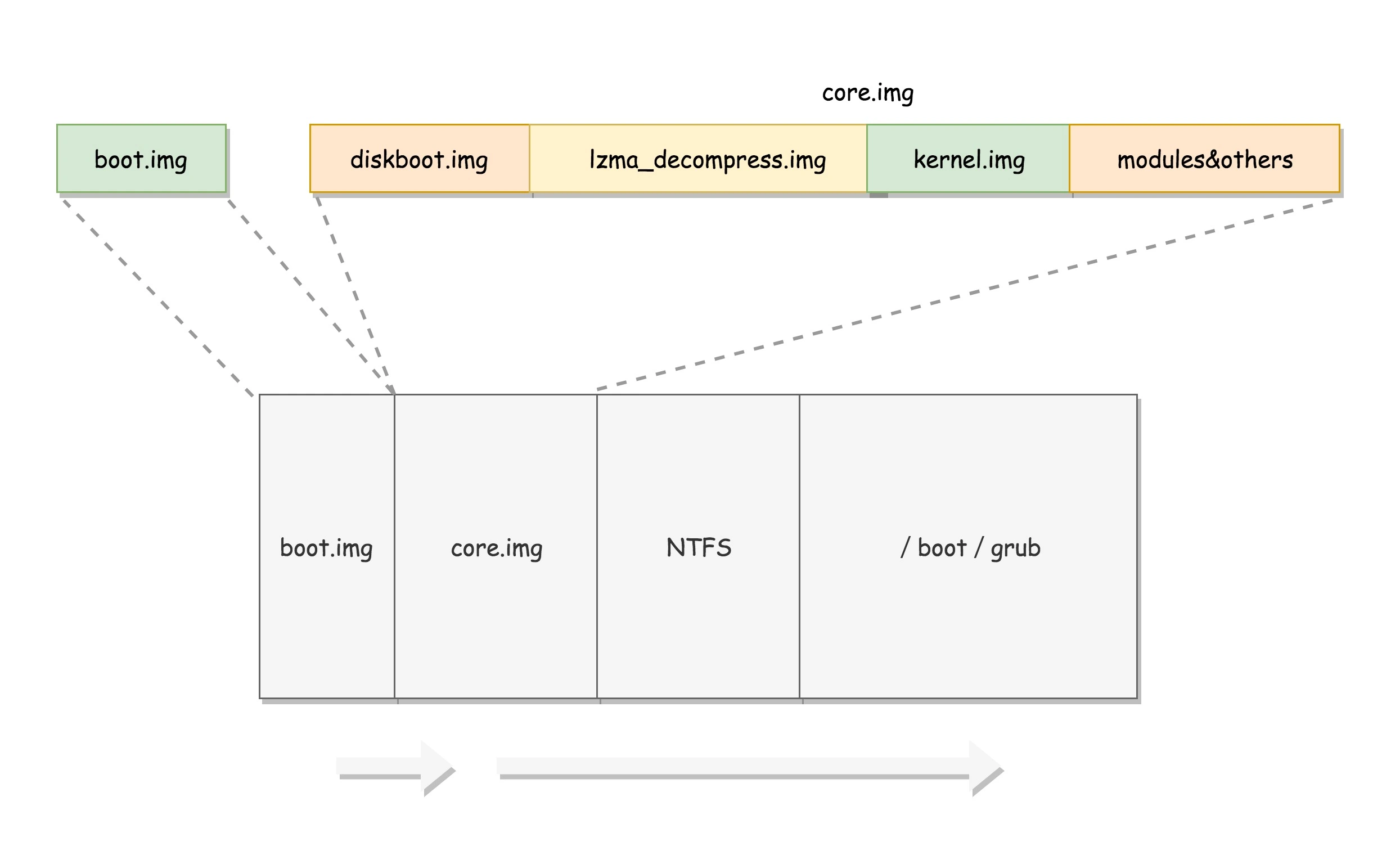
boot.img 先加载的是 core.img 的第一个扇区。如果从硬盘启动的话,这个扇区里面是 diskboot.img,对应的代码是 diskboot.S。
boot.img 将控制权交给 diskboot.img 后,diskboot.img 的任务就是将 core.img 的其他部分加载进来,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块 module 对应的映像。这里需要注意,它不是 Linux 的内核,而是 grub 的内核。
lzma_decompress.img 对应的代码是 startup_raw.S,本来 kernel.img 是压缩过的,现在执行的时候,需要解压缩。在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行,但是随着我们加载的东西越来越大,实模式这 1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 做了一个重要的决定,就是调用 real_to_prot,切换到保护模式,这样就能在更大的寻址空间里面,加载更多的东西。
从实模式切换到保护模式
切换到保护模式要干很多工作,大部分工作都与内存的访问方式有关。
-
第一项是启用分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。第二项是启动分页。能够管理的内存变大了,就需要将内存分成相等大小的块,这些我们放到内存那一节详细再讲。
-
那就是打开 Gate A20,也就是第 21 根地址线的控制线。在实模式 8086 下面,一共就 20 个地址线,可访问 1M 的地址空间。如果超过了这个限度怎么办呢?当然是绕回来了。在保护模式下,第 21 根要起作用了,于是我们就需要打开 Gate A20。
现在好了,有的是空间了。接下来我们要对压缩过的 kernel.img 进行解压缩,然后跳转到 kernel.img 开始运行。
切换到了老板角色,你可以正大光明地进入档案馆,寻找你的那本宝典。kernel.img 对应的代码是 startup.S 以及一堆 c 文件,在 startup.S 中会调用 grub_main,这是 grub kernel 的主函数。在这个函数里面,grub_load_config() 开始解析,我们上面写的那个 grub.conf 文件里的配置信息。
如果是正常启动,grub_main 最后会调用 grub_command_execute (“normal”, 0, 0),最终会调用 grub_normal_execute() 函数。在这个函数里面,grub_show_menu() 会显示出让你选择的那个操作系统的列表。
一旦,你选定了某个宝典,启动某个操作系统,就要开始调用 grub_menu_execute_entry() ,开始解析并执行你选择的那一项。接下来你的经营企业之路就此打开了。
例如里面的 linux16 命令,表示装载指定的内核文件,并传递内核启动参数。于是 grub_cmd_linux() 函数会被调用,它会首先读取 Linux 内核镜像头部的一些数据结构,放到内存中的数据结构来,进行检查。如果检查通过,则会读取整个 Linux 内核镜像到内存。
如果配置文件里面还有 initrd 命令,用于为即将启动的内核传递 init ramdisk 路径。于是 grub_cmd_initrd() 函数会被调用,将 initramfs 加载到内存中来。
当这些事情做完之后,grub_command_execute (“boot”, 0, 0) 才开始真正地启动内核。
内核初始化:生意做大了就得成立公司
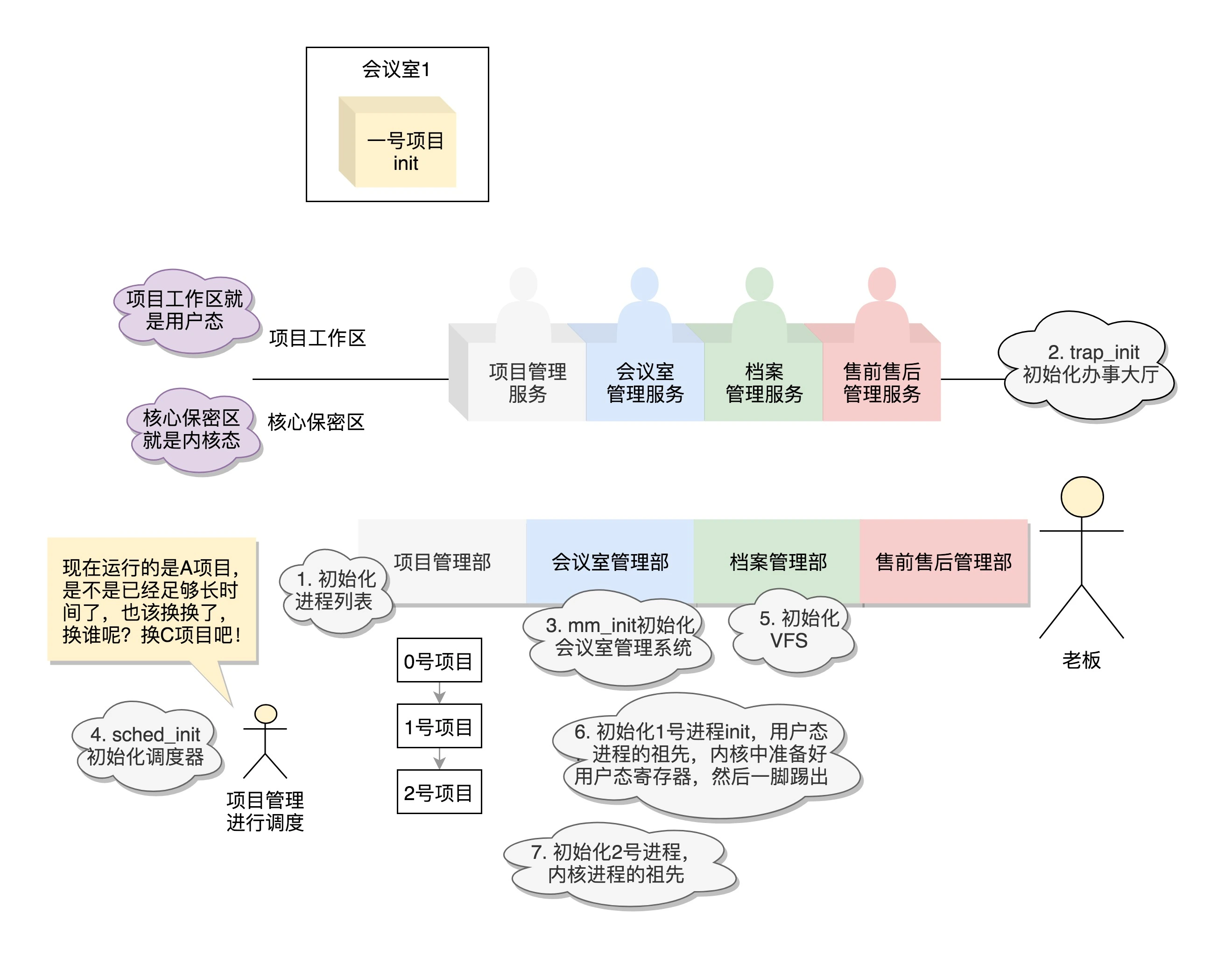
内核的启动从入口函数 start_kernel() 开始。在 init/main.c 文件中,start_kernel 相当于内核的 main 函数。打开这个函数,你会发现,里面是各种各样初始化函数 XXXX_init。
初始化公司职能部门
- 项目管理部门——进程管理
在操作系统里面,先要有个创始进程,有一行指令 set_task_stack_end_magic(&init_task)。这里面有一个参数 init_task,它的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为 0 号进程。这是唯一一个没有通过 fork 或者 kernel_thread 产生的进程,是进程列表的第一个。
- 办事大厅——系统调用
这里面对应的函数是 trap_init(),里面设置了很多中断门(Interrupt Gate),用于处理各种中断。其中有一个 set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32),这是系统调用的中断门。系统调用也是通过发送中断的方式进行的。当然,64 位的有另外的系统调用方法。
- 会议室管理系统——内存管理
mm_init() 就是用来初始化内存管理模块。
- 项目管理调度 —— CPU调度
sched_init() 就是用于初始化调度模块。
- 档案管理部 —— 文件系统
vfs_caches_init() 会用来初始化基于内存的文件系统 rootfs。在这个函数里面,会调用 mnt_init()->init_rootfs()。这里面有一行代码,register_filesystem(&rootfs_fs_type)。在 VFS 虚拟文件系统里面注册了一种类型,我们定义为 struct file_system_type rootfs_fs_type。
文件系统是我们的项目资料库,为了兼容各种各样的文件系统,我们需要将文件的相关数据结构和操作抽象出来,形成一个抽象层对上提供统一的接口,这个抽象层就是 VFS(Virtual File System),虚拟文件系统。
- 其他初始化
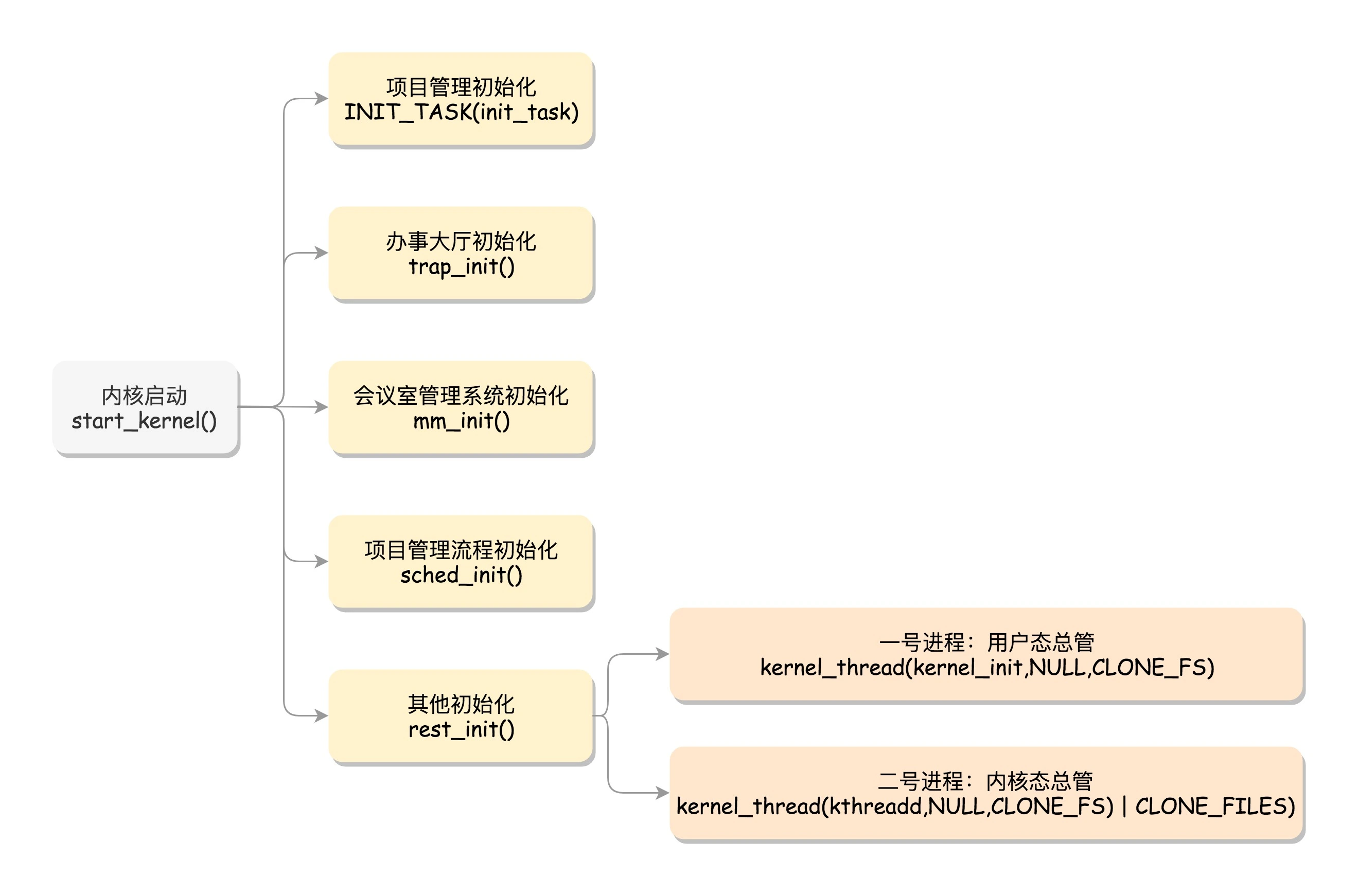
最后,start_kernel() 调用的是 rest_init(),用来做其他方面的初始化,这里面做了好多的工作。
初始化 1 号进程
rest_init 的第一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS) 创建第二个进程,这个是 1 号进程。
1 号进程对于操作系统来讲,有“划时代”的意义。因为它将运行一个用户进程。后续用户进程从 1 号进程 fork 产生。
一旦有了用户进程,公司的运行模式就要发生一定的变化。因为原来你是老板,没有雇佣其他人,所有东西都是你的,无论多么关键的资源,第一,不会有人给你抢,第二,不会有人恶意破坏、恶意使用。但是现在有了其他人,你就要开始做一定的区分,哪些是核心资源,哪些是非核心资源;办公区也要分开,有普通的项目人员都能访问的项目工作区,还有职业核心人员能够访问的核心保密区。
好在 x86 提供了分层的权限机制,把区域分成了四个 Ring,越往里权限越高,越往外权限越低。
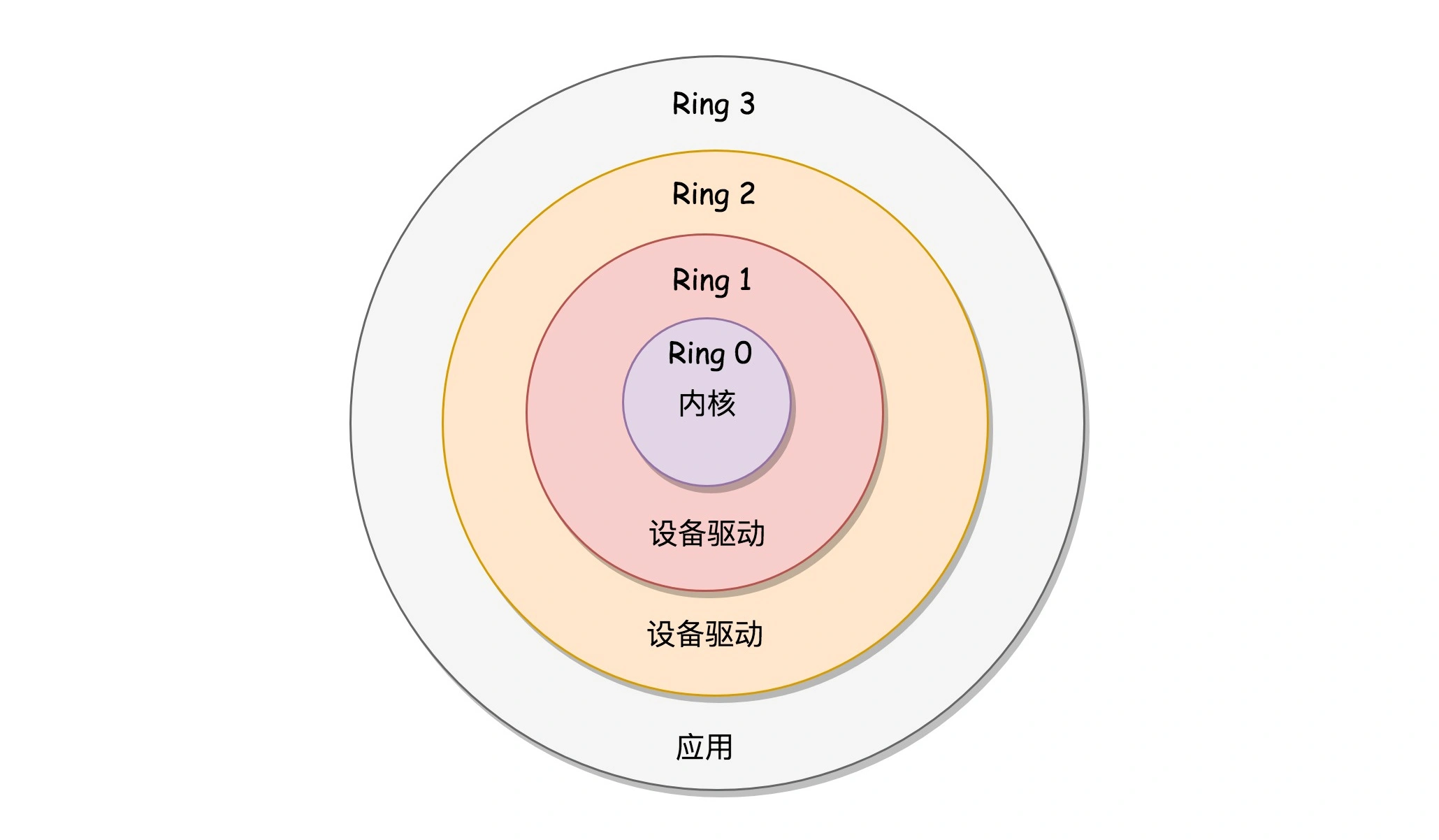
操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。
如果用户态的代码想要访问核心资源,怎么办呢?咱们不是有提供系统调用的办事大厅吗?这里是统一的入口,用户态代码在这里请求就是了。办事大厅后面就是内核态,用户态代码不用管后面发生了什么,做完了返回结果就可以了。

在切换时候需要做上下文切换。整个流程为:用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态,然后接着运行。
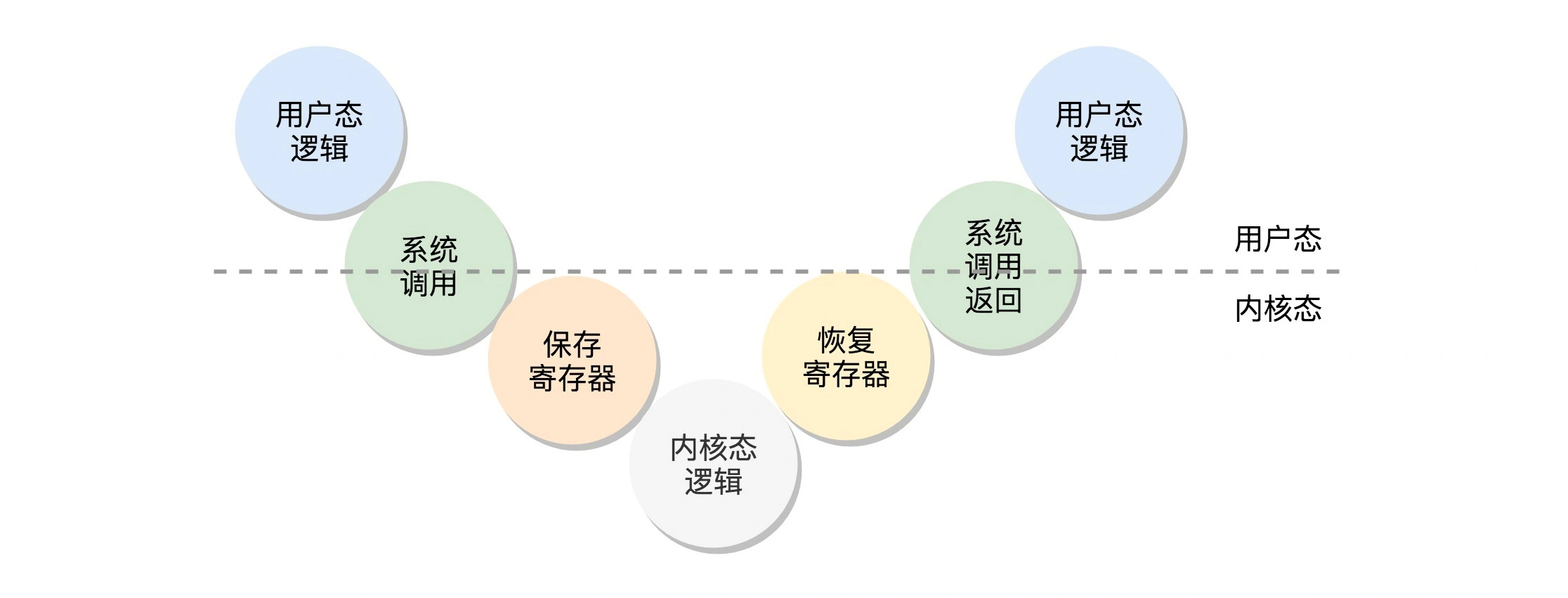
从内核态到用户态
我们再回到 1 号进程启动的过程。当前执行 kernel_thread 这个函数的时候,我们还在内核态,现在我们就来跨越这道屏障,到用户态去运行一个程序。这该怎么办呢?很少听说“先内核态再用户态”的。
1 号进程会执行一段代码,代码是在用户态做系统调用,在这过程中补全用户态的 IP、CS、DS、SP 寄存器的数据,相当于补上了原来系统调用里,保存寄存器的一个步骤。
最后的 iret 是干什么的呢?它是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS 和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句。DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。
ramdisk 的作用
init 终于从内核到用户态了。一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
为什么会有 ramdisk 这个东西呢?还记得上一节咱们内核启动的时候,配置过这个参数:
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img
就是这个东西,这是一个基于内存的文件系统。为啥会有这个呢?
是因为刚才那个 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是 ramdisk。这个时候,ramdisk 是根文件系统。
然后,我们开始运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
先别忙着高兴,rest_init 的第一个大事情才完成。我们仅仅形成了用户态所有进程的祖先。
创建2号进程
用户态的所有进程都有大师兄了,那内核态的进程有没有一个人统一管起来呢?有的,rest_init 第二大事情就是第三个进程,就是 2 号进程。
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES) 又一次使用 kernel_thread 函数创建进程。
这里的函数 kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。这下好了,用户态和内核态都有人管了,可以开始接项目了。
系统调用:公司成立好了就要开始接项目
有的时候,我们的客户觉得,直接去办事大厅还是不够方便。没问题,Linux 还提供了 glibc 这个中介。它更熟悉系统调用的细节,并且可以封装成更加友好的接口。你可以直接用。
glibc 对系统调用的封装
我们以最常用的系统调用 open,打开一个文件为线索,看看系统调用是怎么实现的。这一节我们仅仅会解析到从 glibc 如何调用到内核的 open
现在我们就开始在用户态进程里面调用 open 函数。为了方便,大部分用户会选择使用中介,也就是说,调用的是 glibc 里面的 open 函数。这个函数是如何定义的呢?
int open(const char *pathname, int flags, mode_t mode)
在 glibc 的源代码中,有个文件 syscalls.list,里面列着所有 glibc 的函数对应的系统调用,就像下面这个样子:
# File name Caller Syscall name Args Strong name Weak names
open - open Ci:siv __libc_open __open open
另外,glibc 还有一个脚本 make-syscall.sh,可以根据上面的配置文件,对于每一个封装好的系统调用,生成一个文件。这个文件里面定义了一些宏,例如 #define SYSCALL_NAME open。
glibc 还有一个文件 syscall-template.S,使用上面这个宏,定义了这个系统调用的调用方式。
T_PSEUDO (SYSCALL_SYMBOL, SYSCALL_NAME, SYSCALL_NARGS)
ret
T_PSEUDO_END (SYSCALL_SYMBOL)
#define T_PSEUDO(SYMBOL, NAME, N) PSEUDO (SYMBOL, NAME, N)
这里的 PSEUDO 也是一个宏,它的定义如下:
#define PSEUDO(name, syscall_name, args) \
.text; \
ENTRY (name) \
DO_CALL (syscall_name, args); \
cmpl $-4095, %eax; \
jae SYSCALL_ERROR_LABEL
里面对于任何一个系统调用,会调用 DO_CALL。这也是一个宏,这个宏 32 位和 64 位的定义是不一样的。
32 位系统调用过程
我们先来看 32 位的情况(i386 目录下的 sysdep.h 文件)。
/* Linux takes system call arguments in registers:
syscall number %eax call-clobbered
arg 1 %ebx call-saved
arg 2 %ecx call-clobbered
arg 3 %edx call-clobbered
arg 4 %esi call-saved
arg 5 %edi call-saved
arg 6 %ebp call-saved
......
*/
#define DO_CALL(syscall_name, args) \
PUSHARGS_##args \
DOARGS_##args \
movl $SYS_ify (syscall_name), %eax; \
ENTER_KERNEL \
POPARGS_##args
这里,我们将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器 eax 里面,然后执行 ENTER_KERNEL。
在 Linux 的源代码注释里面,我们可以清晰地看到,这些寄存器是如何传递系统调用号和参数的。
这里面的 ENTER_KERNEL 是什么呢?
# define ENTER_KERNEL int $0x80
int 就是 interrupt,也就是“中断”的意思。int $0x80 就是触发一个软中断,通过它就可以陷入(trap)内核。
在内核启动的时候,还记得有一个 trap_init(),其中有这样的代码:
set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);
这是一个软中断的陷入门。当接收到一个系统调用的时候,entry_INT80_32 就被调用了。
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax /* pt_regs->orig_ax */
SAVE_ALL pt_regs_ax=$-ENOSYS /* save rest */
movl %esp, %eax
call do_syscall_32_irqs_on
.Lsyscall_32_done:
......
.Lirq_return:
INTERRUPT_RETURN
通过 push 和 SAVE_ALL 将当前用户态的寄存器,保存在 pt_regs 结构里面。
进入内核之前,保存所有的寄存器,然后调用 do_syscall_32_irqs_on。它的实现如下:
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned int nr = (unsigned int)regs->orig_ax;
......
if (likely(nr < IA32_NR_syscalls)) {
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
syscall_return_slowpath(regs);
}
在这里,我们看到,将系统调用号从 eax 里面取出来,然后根据系统调用号,在系统调用表中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,就能发现,这些参数所对应的寄存器,和 Linux 的注释是一样的。
根据宏定义,#define ia32_sys_call_table sys_call_table,系统调用就是放在这个表里面。至于这个表是如何形成的,我们后面讲。
当系统调用结束之后,在 entry_INT80_32 之后,紧接着调用的是 INTERRUPT_RETURN,我们能够找到它的定义,也就是 iret。
#define INTERRUPT_RETURN iret
iret 指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态进程恢复执行。
这里我总结一下 32 位的系统调用是如何执行的。

64 位系统调用过程
我们再来看 64 位的情况(x86_64 下的 sysdep.h 文件)。
/* The Linux/x86-64 kernel expects the system call parameters in
registers according to the following table:
syscall number rax
arg 1 rdi
arg 2 rsi
arg 3 rdx
arg 4 r10
arg 5 r8
arg 6 r9
......
*/
#define DO_CALL(syscall_name, args) \
lea SYS_ify (syscall_name), %rax; \
syscall
和之前一样,还是将系统调用名称转换为系统调用号,放到寄存器 rax。这里是真正进行调用,不是用中断了,而是改用 syscall 指令了。并且,通过注释我们也可以知道,传递参数的寄存器也变了。
syscall 指令还使用了一种特殊的寄存器,我们叫特殊模块寄存器(Model Specific Registers,简称 MSR)。这种寄存器是 CPU 为了完成某些特殊控制功能为目的的寄存器,其中就有系统调用。
在系统初始化的时候,trap_init 除了初始化上面的中断模式,这里面还会调用 cpu_init->syscall_init。这里面有这样的代码:
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
rdmsr 和 wrmsr 是用来读写特殊模块寄存器的。MSR_LSTAR 就是这样一个特殊的寄存器,当 syscall 指令调用的时候,会从这个寄存器里面拿出函数地址来调用,也就是调用 entry_SYSCALL_64。
在 arch/x86/entry/entry_64.S 中定义了 entry_SYSCALL_64。
ENTRY(entry_SYSCALL_64)
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
movq PER_CPU_VAR(current_task), %r11
testl $_TIF_WORK_SYSCALL_ENTRY|_TIF_ALLWORK_MASK, TASK_TI_flags(%r11)
jnz entry_SYSCALL64_slow_path
......
entry_SYSCALL64_slow_path:
/* IRQs are off. */
SAVE_EXTRA_REGS
movq %rsp, %rdi
call do_syscall_64 /* returns with IRQs disabled */
return_from_SYSCALL_64:
RESTORE_EXTRA_REGS
TRACE_IRQS_IRETQ
movq RCX(%rsp), %rcx
movq RIP(%rsp), %r11
movq R11(%rsp), %r11
......
syscall_return_via_sysret:
/* rcx and r11 are already restored (see code above) */
RESTORE_C_REGS_EXCEPT_RCX_R11
movq RSP(%rsp), %rsp
USERGS_SYSRET64
这里先保存了很多寄存器到 pt_regs 结构里面,例如用户态的代码段、数据段、保存参数的寄存器,然后调用 entry_SYSCALL64_slow_pat->do_syscall_64。
__visible void do_syscall_64(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned long nr = regs->orig_ax;
......
if (likely((nr & __SYSCALL_MASK) < NR_syscalls)) {
regs->ax = sys_call_table[nr & __SYSCALL_MASK](
regs->di, regs->si, regs->dx,
regs->r10, regs->r8, regs->r9);
}
syscall_return_slowpath(regs);
}
在 do_syscall_64 里面,从 rax 里面拿出系统调用号,然后根据系统调用号,在系统调用表 sys_call_table 中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,你就能发现,这些参数所对应的寄存器,和 Linux 的注释又是一样的。
所以,无论是 32 位,还是 64 位,都会到系统调用表 sys_call_table 这里来。
在研究系统调用表之前,我们看 64 位的系统调用返回的时候,执行的是 USERGS_SYSRET64。定义如下:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;
这里,返回用户态的指令变成了 sysretq。
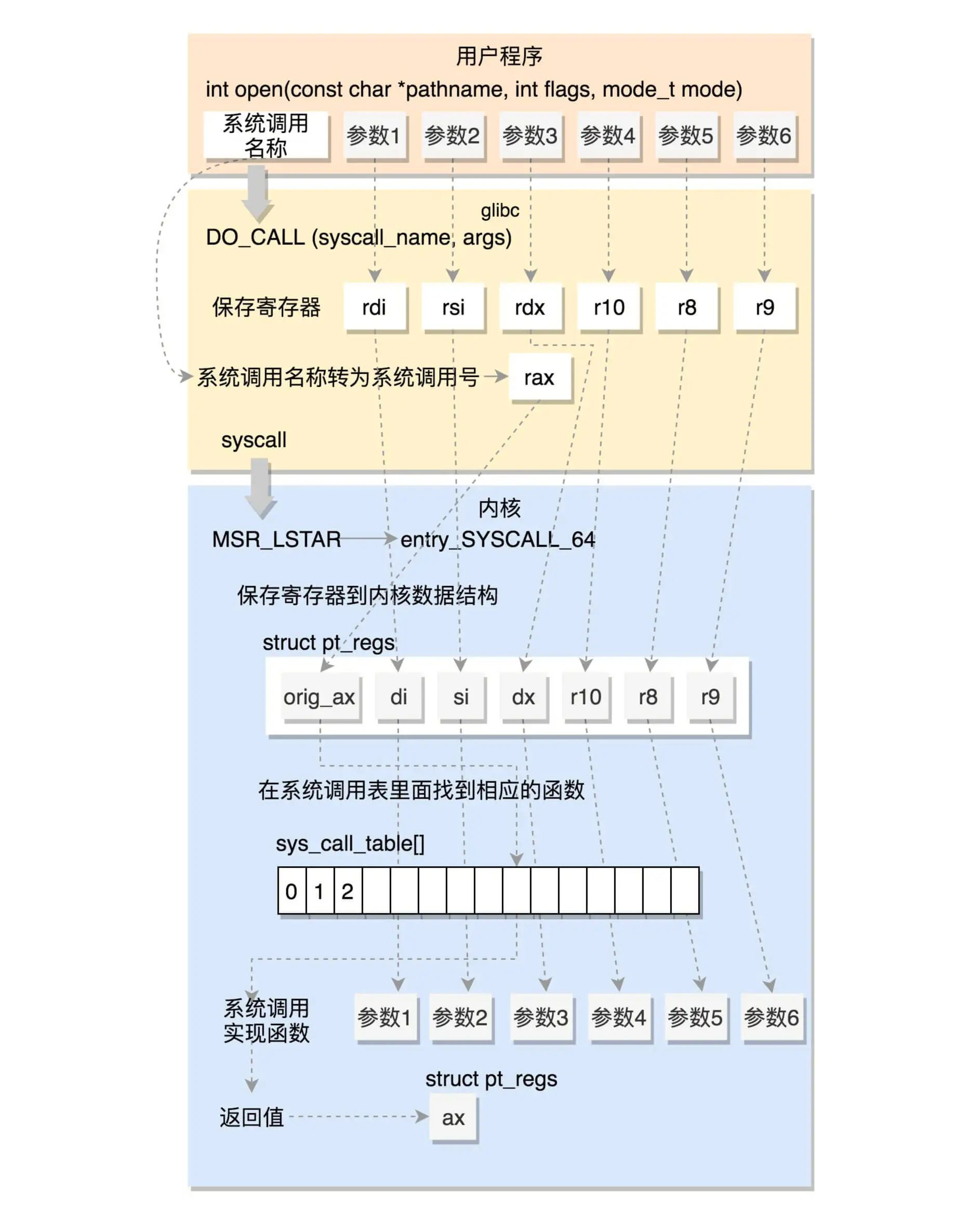
系统调用表
前面我们重点关注了系统调用的方式,都是最终到了系统调用表,但是到底调用内核的什么函数,还没有解读。现在我们再来看,系统调用表 sys_call_table 是怎么形成的呢?
32 位的系统调用表定义在 arch/x86/entry/syscalls/syscall_32.tbl 文件里。例如 open 是这样定义的:
5 i386 open sys_open compat_sys_open
64 位的系统调用定义在另一个文件 arch/x86/entry/syscalls/syscall_64.tbl 里。例如 open 是这样定义的:
2 common open sys_open
第一列的数字是系统调用号。可以看出,32 位和 64 位的系统调用号是不一样的。第三列是系统调用的名字,第四列是系统调用在内核的实现函数。不过,它们都是以 sys_ 开头。
系统调用在内核中的实现函数要有一个声明。声明往往在 include/linux/syscalls.h 文件中。例如 sys_open 是这样声明的:
asmlinkage long sys_open(const char __user *filename,
int flags, umode_t mode);
真正的实现这个系统调用,一般在一个.c 文件里面,例如 sys_open 的实现在 fs/open.c 里面,但是你会发现样子很奇怪。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
SYSCALL_DEFINE3 是一个宏系统调用最多六个参数,根据参数的数目选择宏。具体是这样定义的:
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)
如果我们把宏展开之后,实现如下,和声明的是一样的。
asmlinkage long sys_open(const char __user * filename, int flags, int mode)
{
long ret;
if (force_o_largefile())
flags |= O_LARGEFILE;
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
声明和实现都好了。接下来,在编译的过程中,需要根据 syscall_32.tbl 和 syscall_64.tbl 生成自己的 unistd_32.h 和 unistd_64.h。生成方式在 arch/x86/entry/syscalls/Makefile 中。
这里面会使用两个脚本,其中第一个脚本 arch/x86/entry/syscalls/syscallhdr.sh,会在文件中生成 #define __NR_open;第二个脚本 arch/x86/entry/syscalls/syscalltbl.sh,会在文件中生成 __SYSCALL(__NR_open, sys_open)。这样,unistd_32.h 和 unistd_64.h 是对应的系统调用号和系统调用实现函数之间的对应关系。
在文件 arch/x86/entry/syscall_32.c,定义了这样一个表,里面 include 了这个头文件,从而所有的 sys_ 系统调用都在这个表里面了。
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};
同理,在文件 arch/x86/entry/syscall_64.c,定义了这样一个表,里面 include 了这个头文件,这样所有的 sys_ 系统调用就都在这个表里面了。
/* System call table for x86-64. */
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
总结时刻
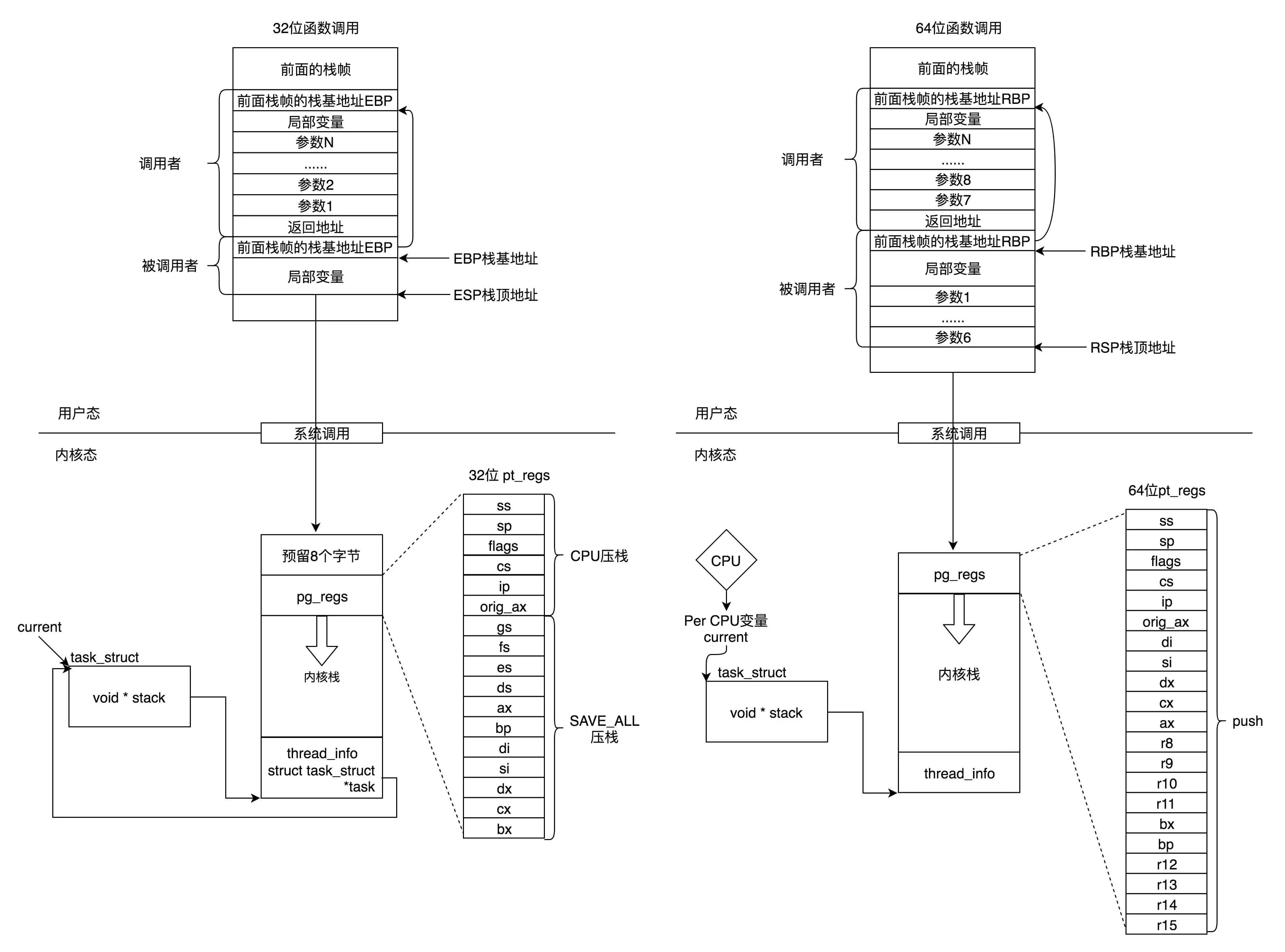
系统调用的过程还是挺复杂的吧?如果加上上一节的内核态和用户态的模式切换,就更复杂了。这里我们重点分析 64 位的系统调用,我将整个完整的过程画了一张图,帮你总结、梳理一下。
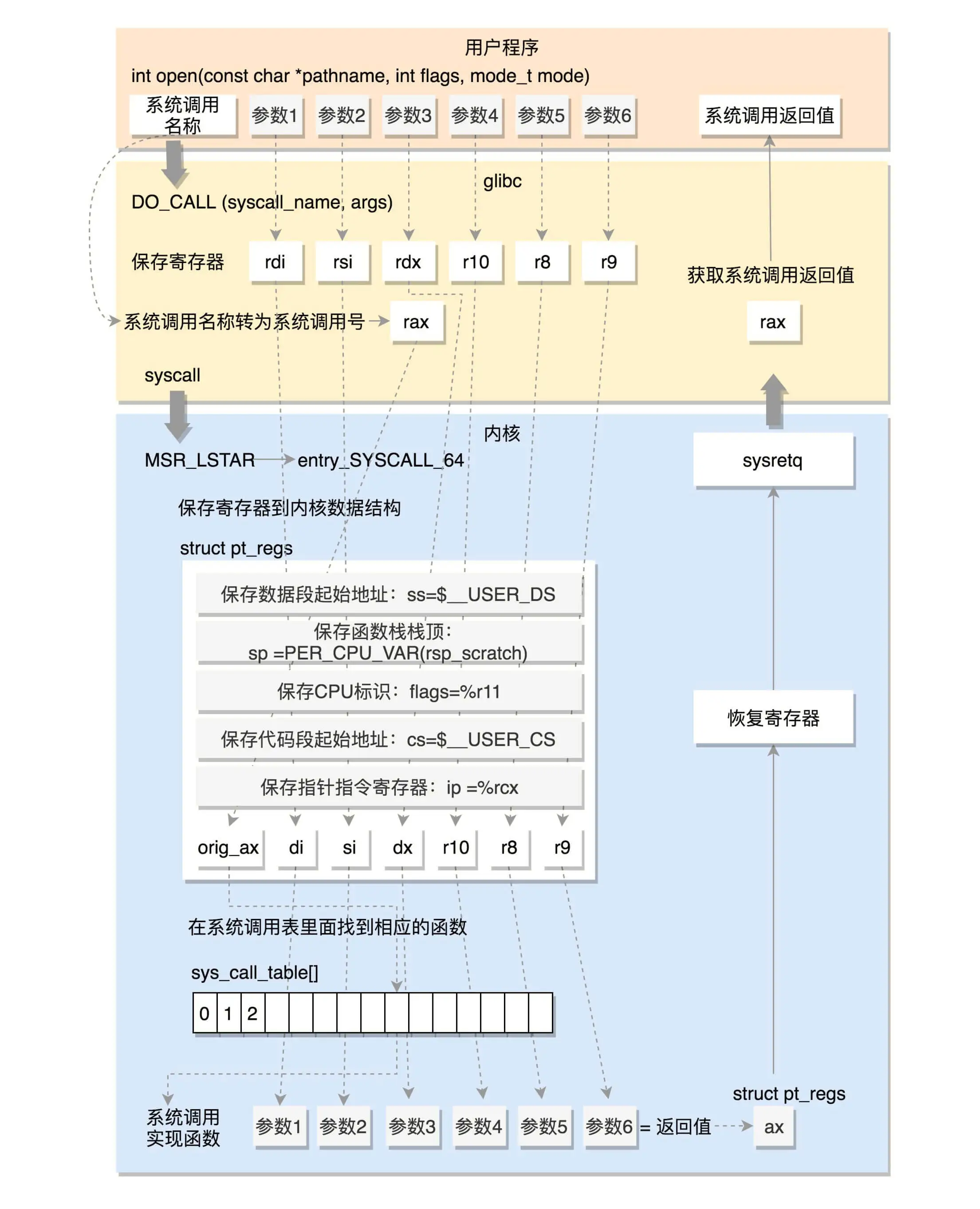
14 | 进程数据结构(下):项目多了就需要项目管理系统
上两节,我们解读了 task_struct 的大部分的成员变量。这样一个任务执行的方方面面,都可以很好地管理起来,但是其中有一个问题我们没有谈。在程序执行过程中,一旦调用到系统调用,就需要进入内核继续执行。那如何将用户态的执行和内核态的执行串起来呢?这就需要以下两个重要的成员变量:
struct thread_info thread_info;
void *stack;
用户态函数栈
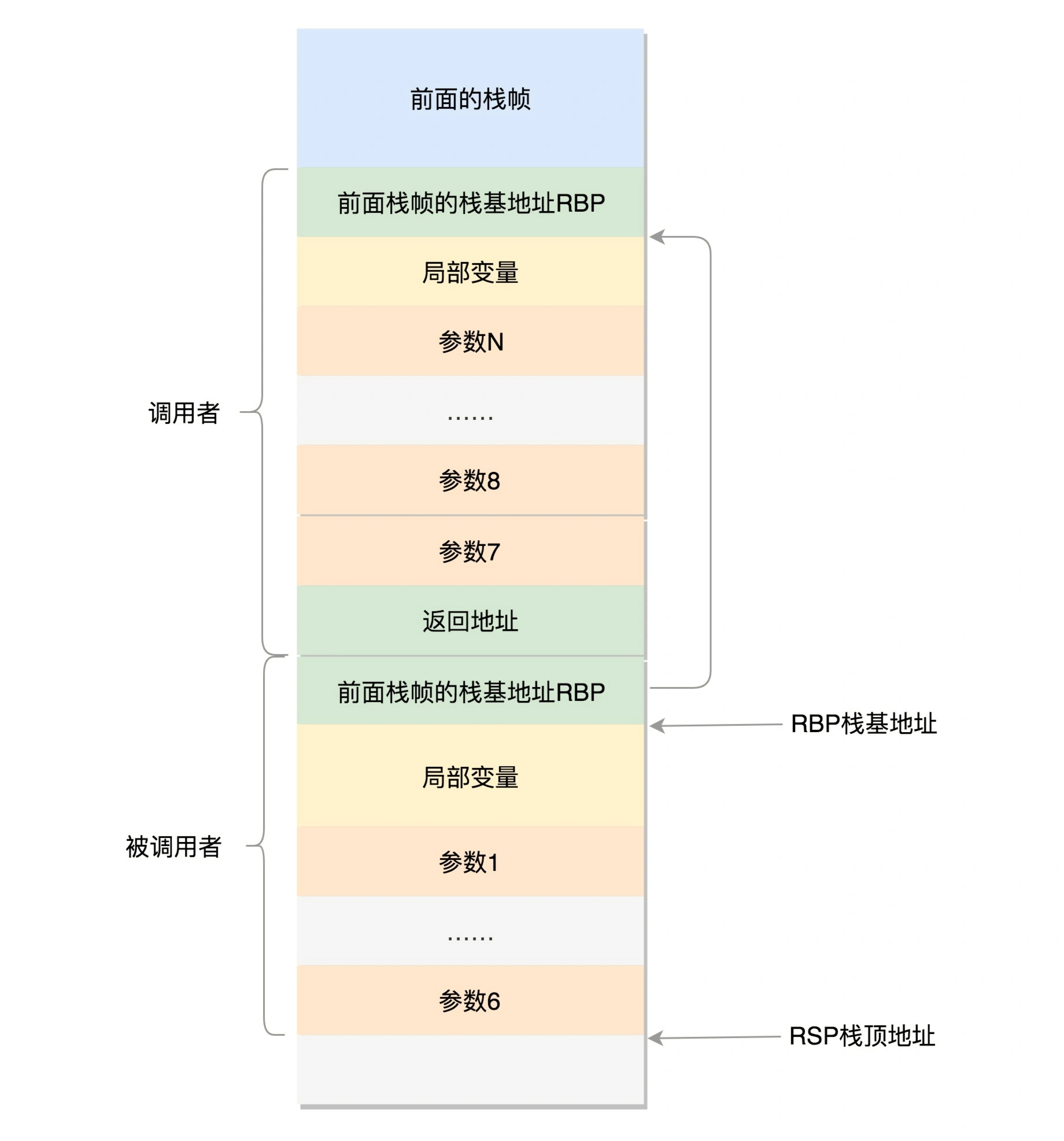
在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构,也就是上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
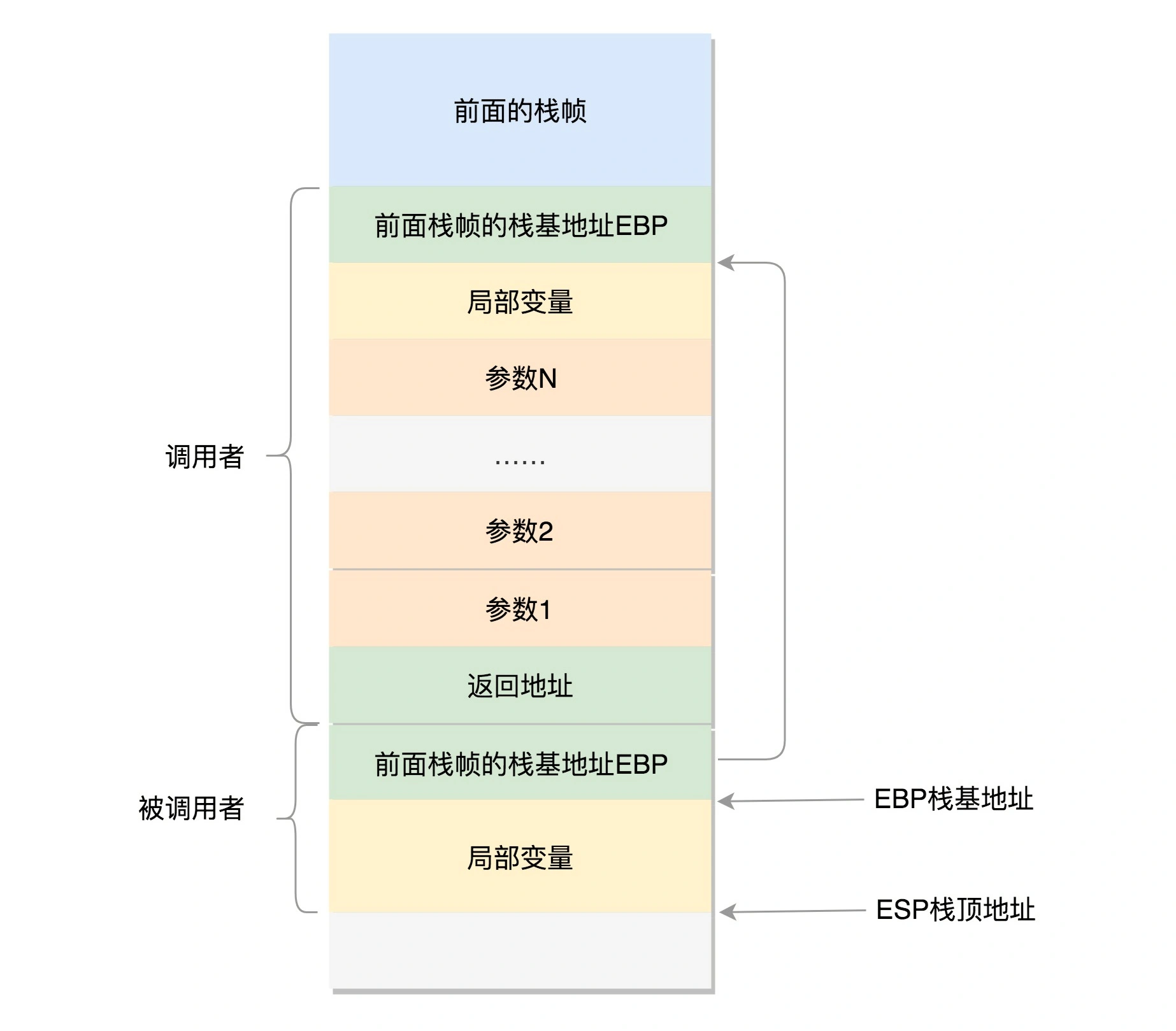
我们先来看 32 位操作系统的情况。在 CPU 里,ESP(Extended Stack Pointer)是栈顶指针寄存器,入栈操作 Push 和出栈操作 Pop 指令,会自动调整 ESP 的值。另外有一个寄存器 EBP(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
A 调用 B,A 的栈里面包含 A 函数的局部变量,然后是调用 B 的时候要传给它的参数,然后返回 A 的地址,这个地址也应该入栈,这就形成了 A 的栈帧。接下来就是 B 的栈帧部分了,先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,接下来保存的是 B 的局部变量等等。
当 B 返回的时候,返回值会保存在 EAX 寄存器中,从栈中弹出返回地址,将指令跳转回去,参数也从栈中弹出,然后继续执行 A。
对于 64 位操作系统,模式多少有些不一样。因为 64 位操作系统的寄存器数目比较多。rax 用于保存函数调用的返回结果。栈顶指针寄存器变成了 rsp,指向栈顶位置。堆栈的 Pop 和 Push 操作会自动调整 rsp,栈基指针寄存器变成了 rbp,指向当前栈帧的起始位置。
改变比较多的是参数传递。rdi、rsi、rdx、rcx、r8、r9 这 6 个寄存器,用于传递存储函数调用时的 6 个参数。如果超过 6 的时候,还是需要放到栈里面。然而,前 6 个参数有时候需要进行寻址,但是如果在寄存器里面,是没有地址的,因而还是会放到栈里面,只不过放到栈里面的操作是被调用函数做的。
以上的栈操作,都是在进程的内存空间里面进行的。
内核态函数栈
Linux 给每个 task 都分配了内核栈。在 32 位系统上 arch/x86/include/asm/page_32_types.h,是这样定义的:一个 PAGE_SIZE 是 4K,左移一位就是乘以 2,也就是 8K。
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
内核栈在 64 位系统上 arch/x86/include/asm/page_64_types.h,是这样定义的:在 PAGE_SIZE 的基础上左移两位,也即 16K,并且要求起始地址必须是 8192 的整数倍。
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
内核栈是一个非常特殊的结构,如下图所示:
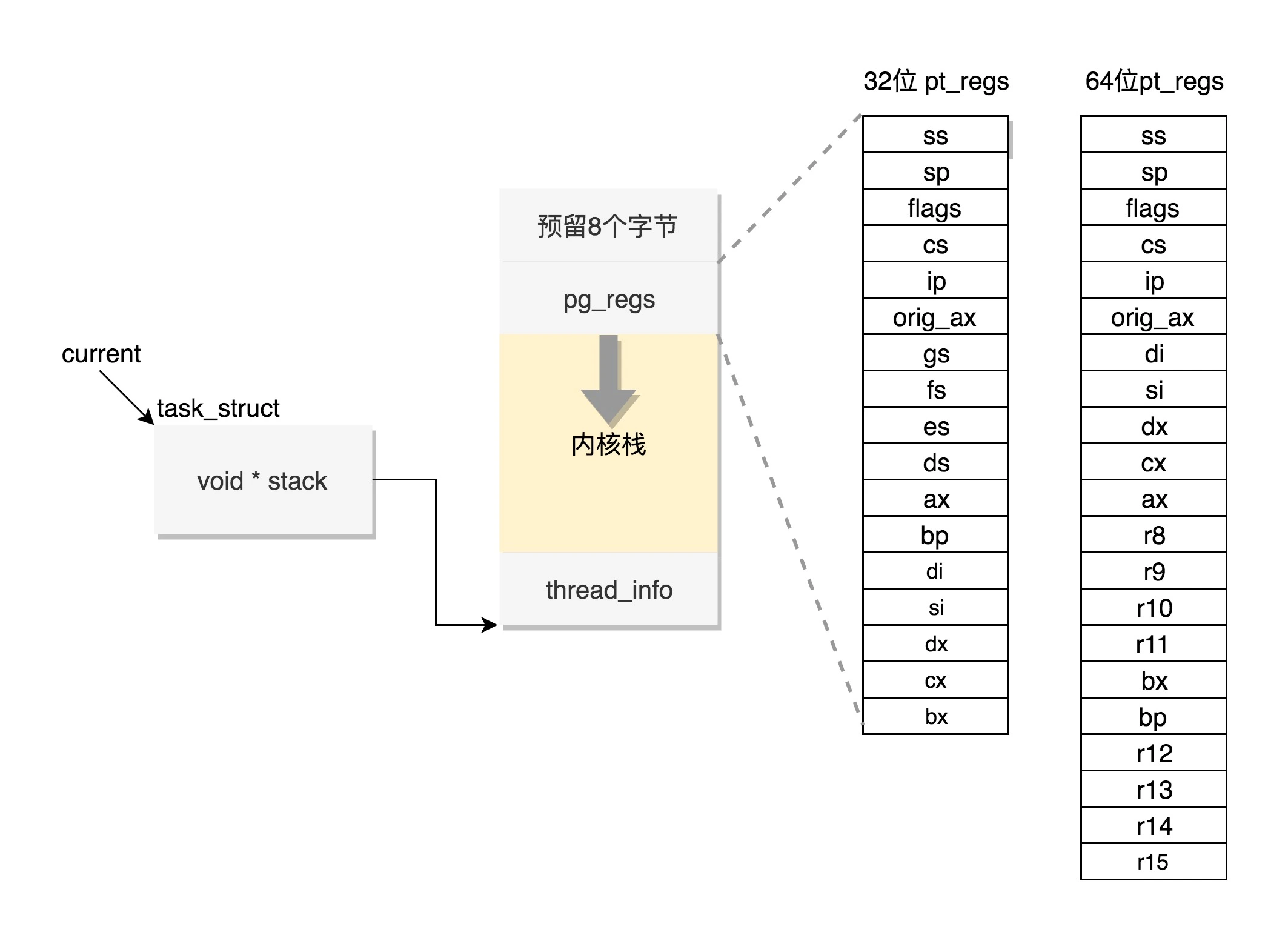
这段空间的最低位置,是一个 thread_info 结构。这个结构是对 task_struct 结构的补充。因为 task_struct 结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在 thread_info 里面。
在内核代码里面有这样一个 union,将 thread_info 和 stack 放在一起,在 include/linux/sched.h 文件中就有。
union thread_union {
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
这个 union 就是这样定义的,开头是 thread_info,后面是 stack。
在内核栈的最高地址端,存放的是另一个结构 pt_regs,定义如下。其中,32 位和 64 位的定义不一样。
#ifdef __i386__
struct pt_regs {
unsigned long bx;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long bp;
unsigned long ax;
unsigned long ds;
unsigned long es;
unsigned long fs;
unsigned long gs;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
};
#else
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
};
#endif
看到这个是不是很熟悉?咱们在讲系统调用的时候,已经多次见过这个结构。当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的 CPU 上下文保存起来,其实主要就是保存在这个结构的寄存器变量里。这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去。
如果我们对比系统调用那一节的内容,你会发现系统调用的时候,压栈的值的顺序和 struct pt_regs 中寄存器定义的顺序是一样的。
在内核中,CPU 的寄存器 ESP 或者 RSP,已经指向内核栈的栈顶,在内核态里的调用都有和用户态相似的过程。
通过 task_struct 找内核栈
如果有一个 task_struct 的 stack 指针在手,你可以通过下面的函数找到这个线程内核栈:
static inline void *task_stack_page(const struct task_struct *task)
{
return task->stack;
}
从 task_struct 如何得到相应的 pt_regs 呢?我们可以通过下面的函数:
/*
* TOP_OF_KERNEL_STACK_PADDING reserves 8 bytes on top of the ring0 stack.
* This is necessary to guarantee that the entire "struct pt_regs"
* is accessible even if the CPU haven't stored the SS/ESP registers
* on the stack (interrupt gate does not save these registers
* when switching to the same priv ring).
* Therefore beware: accessing the ss/esp fields of the
* "struct pt_regs" is possible, but they may contain the
* completely wrong values.
*/
#define task_pt_regs(task) \
({ \
unsigned long __ptr = (unsigned long)task_stack_page(task); \
__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; \
((struct pt_regs *)__ptr) - 1; \
})
你会发现,这是先从 task_struct 找到内核栈的开始位置。然后这个位置加上 THREAD_SIZE 就到了最后的位置,然后转换为 struct pt_regs,再减一,就相当于减少了一个 pt_regs 的位置,就到了这个结构的首地址。
这里面有一个 TOP_OF_KERNEL_STACK_PADDING,这个的定义如下:
#ifdef CONFIG_X86_32
# ifdef CONFIG_VM86
# define TOP_OF_KERNEL_STACK_PADDING 16
# else
# define TOP_OF_KERNEL_STACK_PADDING 8
# endif
#else
# define TOP_OF_KERNEL_STACK_PADDING 0
#endif
也就是说,32 位机器上是 8,其他是 0。这是为什么呢?因为压栈 pt_regs 有两种情况。我们知道,CPU 用 ring 来区分权限,从而 Linux 可以区分内核态和用户态。
因此,第一种情况,我们拿涉及从用户态到内核态的变化的系统调用来说。因为涉及权限的改变,会压栈保存 SS、ESP 寄存器的,这两个寄存器共占用 8 个 byte。
另一种情况是,不涉及权限的变化,就不会压栈这 8 个 byte。这样就会使得两种情况不兼容。如果没有压栈还访问,就会报错,所以还不如预留在这里,保证安全。在 64 位上,修改了这个问题,变成了定长的。
好了,现在如果你 task_struct 在手,就能够轻松得到内核栈和内核寄存器。
通过内核栈找 task_struct
那如果一个当前在某个 CPU 上执行的进程,想知道自己的 task_struct 在哪里,又该怎么办呢?这个艰巨的任务要交给 thread_info 这个结构。
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
这里面有个成员变量 task 指向 task_struct,所以我们常用 current_thread_info()->task 来获取 task_struct。
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE);
}
而 thread_info 的位置就是内核栈的最高位置,减去 THREAD_SIZE,就到了 thread_info 的起始地址。
但是现在变成这样了,只剩下一个 flags。
struct thread_info {
unsigned long flags; /* low level flags */
};
那这时候怎么获取当前运行中的 task_struct 呢?current_thread_info 有了新的实现方式。
在 include/linux/thread_info.h 中定义了 current_thread_info。
#include <asm/current.h>
#define current_thread_info() ((struct thread_info *)current)
#endif
那 current 又是什么呢?在 arch/x86/include/asm/current.h 中定义了。
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
#define current get_current
到这里,你会发现,新的机制里面,每个 CPU 运行的 task_struct 不通过 thread_info 获取了,而是直接放在 Per CPU 变量里面了。
多核情况下,CPU 是同时运行的,但是它们共同使用其他的硬件资源的时候,我们需要解决多个 CPU 之间的同步问题。
Per CPU 变量是内核中一种重要的同步机制。顾名思义,Per CPU 变量就是为每个 CPU 构造一个变量的副本,这样多个 CPU 各自操作自己的副本,互不干涉。比如,当前进程的变量 current_task 就被声明为 Per CPU 变量。
要使用 Per CPU 变量,首先要声明这个变量,在 arch/x86/include/asm/current.h 中有:
DECLARE_PER_CPU(struct task_struct *, current_task);
然后是定义这个变量,在 arch/x86/kernel/cpu/common.c 中有:
DEFINE_PER_CPU(struct task_struct *, current_task) = &init_task;
也就是说,系统刚刚初始化的时候,current_task 都指向 init_task。当某个 CPU 上的进程进行切换的时候,current_task 被修改为将要切换到的目标进程。例如,进程切换函数 __switch_to 就会改变 current_task。
__visible __notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
......
this_cpu_write(current_task, next_p);
......
return prev_p;
}
当要获取当前的运行中的 task_struct 的时候,就需要调用 this_cpu_read_stable 进行读取。
#define this_cpu_read_stable(var) percpu_stable_op("mov", var)
好了,现在如果你是一个进程,正在某个 CPU 上运行,就能够轻松得到 task_struct 了。
总结时刻
调度(上):如何制定项目管理流程?
对于操作系统来讲,它面对的 CPU 的数量是有限的,干活儿都是它们,但是进程数目远远超过 CPU 的数目,因而就需要进行进程的调度,有效地分配 CPU 的时间,既要保证进程的最快响应,也要保证进程之间的公平。这也是一个非常复杂的、需要平衡的事情。
调度策略与调度类
在 Linux 里面,进程大概可以分成两种。
一种称为实时进程,也就是需要尽快执行返回结果的那种。这就好比我们是一家公司,接到的客户项目需求就会有很多种。有些客户的项目需求比较急,比如一定要在一两个月内完成的这种,客户会加急加钱,那这种客户的优先级就会比较高。
另一种是普通进程,大部分的进程其实都是这种。这就好比,大部分客户的项目都是普通的需求,可以按照正常流程完成,优先级就没实时进程这么高,但是人家肯定也有确定的交付日期。
那很显然,对于这两种进程,我们的调度策略肯定是不同的。在 task_struct 中,有一个成员变量,我们叫调度策略。
unsigned int policy;
它有以下几个定义:
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
配合调度策略的,还有我们刚才说的优先级,也在 task_struct 中。
int prio, static_prio, normal_prio;
unsigned int rt_priority;
优先级其实就是一个数值,对于实时进程,优先级的范围是 0~99;对于普通进程,优先级的范围是 100~139。数值越小,优先级越高。从这里可以看出,所有的实时进程都比普通进程优先级要高。毕竟,谁让人家加钱了呢。
实时调度策略
对于调度策略,其中 SCHED_FIFO、SCHED_RR、SCHED_DEADLINE 是实时进程的调度策略。
-
SCHED_FIFO 就是交了相同钱的,先来先服务,但是有的加钱多,可以分配更高的优先级,也就是说,高优先级的进程可以抢占低优先级的进程,而相同优先级的进程,我们遵循先来先得。
-
另外一种策略是,交了相同钱的,轮换着来,这就是 SCHED_RR 轮流调度算法,采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,而高优先级的任务也是可以抢占低优先级的任务。
-
还有一种新的策略是 SCHED_DEADLINE,是按照任务的 deadline 进行调度的。当产生一个调度点的时候,DL 调度器总是选择其 deadline 距离当前时间点最近的那个任务,并调度它执行。
普通调度策略
对于普通进程的调度策略有,SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE。
-
SCHED_NORMAL 是普通的进程,就相当于咱们公司接的普通项目。
-
SCHED_BATCH 是后台进程,几乎不需要和前端进行交互。这有点像公司在接项目同时,开发一些可以复用的模块,作为公司的技术积累,从而使得在之后接新项目的时候,能够减少工作量。这类项目可以默默执行,不要影响需要交互的进程,可以降低它的优先级。
-
SCHED_IDLE 是特别空闲的时候才跑的进程,相当于咱们学习训练类的项目,比如咱们公司很长时间没有接到外在项目了,可以弄几个这样的项目练练手。
上面无论是 policy 还是 priority,都设置了一个变量,变量仅仅表示了应该这样这样干,但事情总要有人去干,谁呢?在 task_struct 里面,还有这样的成员变量:
const struct sched_class *sched_class;
调度策略的执行逻辑,就封装在这里面,它是真正干活的那个。
sched_class 有几种实现:
- stop_sched_class 优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;
- dl_sched_class 就对应上面的 deadline 调度策略;
- rt_sched_class 就对应 RR 算法或者 FIFO 算法的调度策略,具体调度策略由进程的 task_struct->policy 指定;
- fair_sched_class 就是普通进程的调度策略;
- idle_sched_class 就是空闲进程的调度策略。
这里实时进程的调度策略 RR 和 FIFO 相对简单一些,而且由于咱们平时常遇到的都是普通进程,在这里,咱们就重点分析普通进程的调度问题。普通进程使用的调度策略是 fair_sched_class,顾名思义,对于普通进程来讲,公平是最重要的。
完全公平调度算法
在 Linux 里面,实现了一个基于 CFS 的调度算法。CFS 全称 Completely Fair Scheduling,叫完全公平调度。听起来很“公平”。那这个算法的原理是什么呢?我们来看看。
首先,你需要记录下进程的运行时间。CPU 会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫 Tick。CFS 会为每一个进程安排一个虚拟运行时间 vruntime。如果一个进程在运行,随着时间的增长,也就是一个个 tick 的到来,进程的 vruntime 将不断增大。没有得到执行的进程 vruntime 不变。
那些 vruntime 少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
如何给优先级高的进程多分时间呢?这个简单,就相当于 N 个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
在更新进程运行的统计量的时候,我们其实就可以看出这个逻辑。
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
......
delta_exec = now - curr->exec_start;
......
curr->exec_start = now;
......
curr->sum_exec_runtime += delta_exec;
......
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
......
}
/*
* delta /= w
*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
/* delta_exec * weight / lw.weight */
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
在这里得到当前的时间,以及这次的时间片开始的时间,两者相减就是这次运行的时间 delta_exec ,但是得到的这个时间其实是实际运行的时间,需要做一定的转化才作为虚拟运行时间 vruntime。转化方法如下:
虚拟运行时间 vruntime += 实际运行时间 delta_exec * NICE_0_LOAD/ 权重
这就是说,同样的实际运行时间,给高权重的算少了,低权重的算多了,但是当选取下一个运行进程的时候,还是按照最小的 vruntime 来的,这样高权重的获得的实际运行时间自然就多了。
调度队列与调度实体
看来 CFS 需要一个数据结构来对 vruntime 进行排序,找出最小的那个。这个能够排序的数据结构不但需要查询的时候,能够快速找到最小的,更新的时候也需要能够快速地调整排序,要知道 vruntime 可是经常在变的,变了再插入这个数据结构,就需要重新排序。
能够平衡查询和更新速度的是树,在这里使用的是红黑树。
红黑树的的节点是应该包括 vruntime 的,称为调度实体。
在 task_struct 中有这样的成员变量:
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
这里有实时调度实体 sched_rt_entity,Deadline 调度实体 sched_dl_entity,以及完全公平算法调度实体 sched_entity。
看来不光 CFS 调度策略需要有这样一个数据结构进行排序,其他的调度策略也同样有自己的数据结构进行排序,因为任何一个策略做调度的时候,都是要区分谁先运行谁后运行
而进程根据自己是实时的,还是普通的类型,通过这个成员变量,将自己挂在某一个数据结构里面,和其他的进程排序,等待被调度。如果这个进程是个普通进程,则通过 sched_entity,将自己挂在这棵红黑树上。
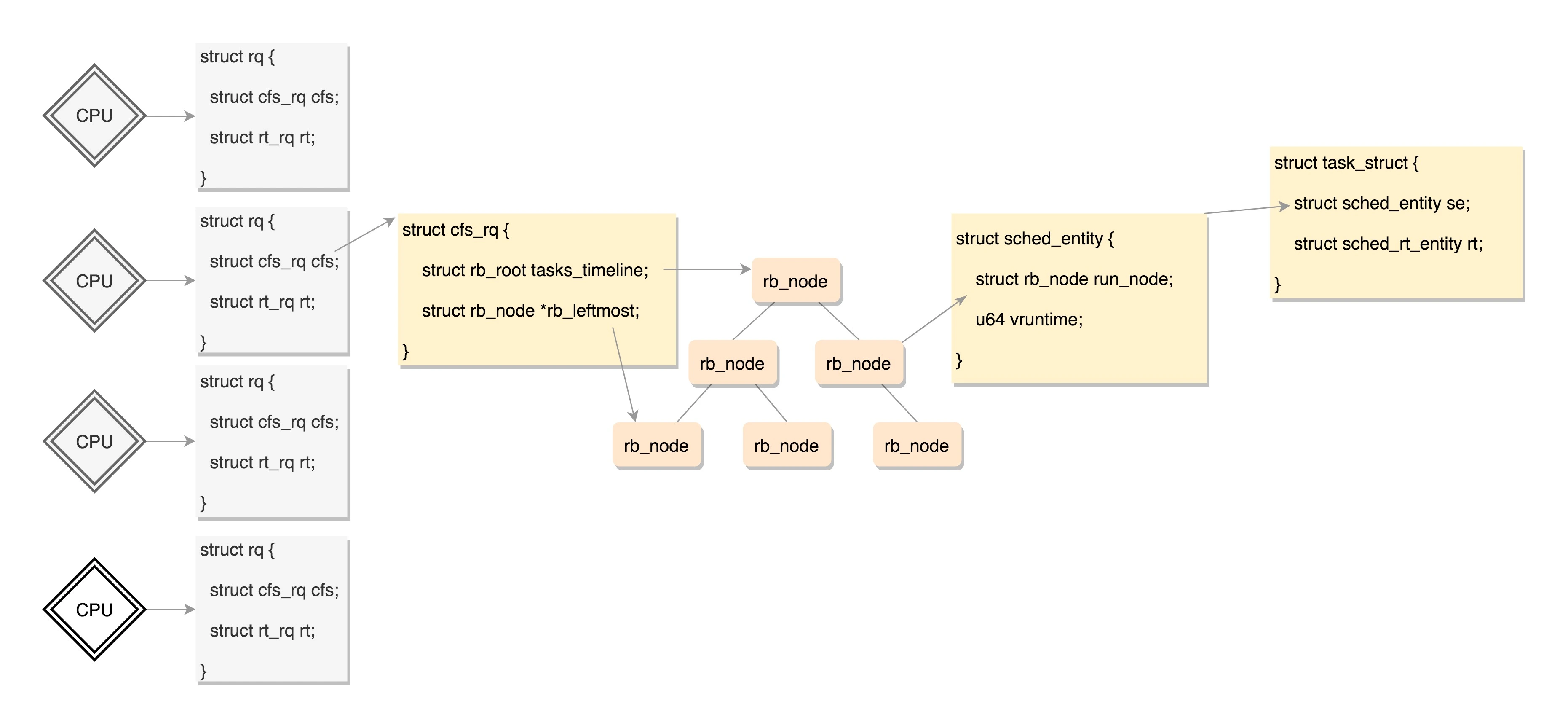
对于普通进程的调度实体定义如下,这里面包含了 vruntime 和权重 load_weight,以及对于运行时间的统计。
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
......
};
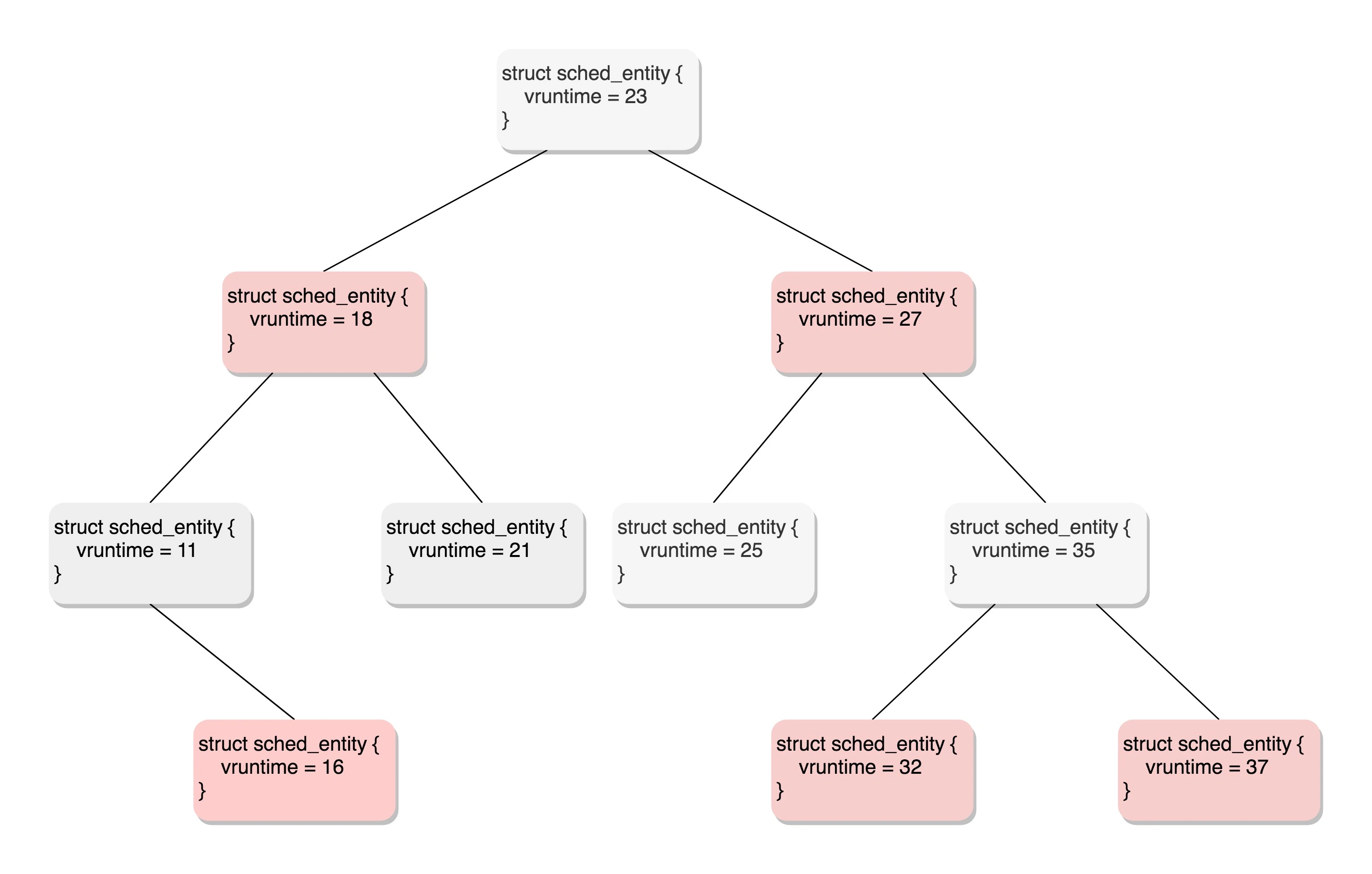
所有可运行的进程通过不断地插入操作最终都存储在以时间为顺序的红黑树中,vruntime 最小的在树的左侧,vruntime 最多的在树的右侧。 CFS 调度策略会选择红黑树最左边的叶子节点作为下一个将获得 CPU 的任务。
这棵红黑树放在哪里呢?就像每个软件工程师写代码的时候,会将任务排成队列,做完一个做下一个。
CPU 也是这样的,每个 CPU 都有自己的 struct rq 结构,其用于描述在此 CPU 上所运行的所有进程,其包括一个实时进程队列 rt_rq 和一个 CFS 运行队列 cfs_rq,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去 CFS 运行队列找是否有进程需要运行。
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};
对于普通进程公平队列 cfs_rq,定义如下:
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct sched_entity *curr, *next, *last, *skip;
......
};
这里面 rb_root 指向的就是红黑树的根节点,这个红黑树在 CPU 看起来就是一个队列,不断地取下一个应该运行的进程。rb_leftmost 指向的是最左面的节点。
到这里终于凑够数据结构了,上面这些数据结构的关系如下图:
调度类是如何工作的?
调度类的定义如下:
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq)
这个结构定义了很多种方法,用于在队列上操作任务。这里请大家注意第一个成员变量,是一个指针,指向下一个调度类。
上面我们讲了,调度类分为下面这几种:
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
它们其实是放在一个链表上的。这里我们以调度最常见的操作,取下一个任务为例,来解析一下。可以看到,这里面有一个 for_each_class 循环,沿着上面的顺序,依次调用每个调度类的方法。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
......
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}
这就说明,调度的时候是从优先级最高的调度类到优先级低的调度类,依次执行。而对于每种调度类,有自己的实现,例如,CFS 就有 fair_sched_class。
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
};
对于同样的 pick_next_task 选取下一个要运行的任务这个动作,不同的调度类有自己的实现。fair_sched_class 的实现是 pick_next_task_fair,rt_sched_class 的实现是 pick_next_task_rt。
我们会发现这两个函数是操作不同的队列,pick_next_task_rt 操作的是 rt_rq,pick_next_task_fair 操作的是 cfs_rq。
static struct task_struct *
pick_next_task_rt(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;
......
}
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
......
}
这样整个运行的场景就串起来了,在每个 CPU 上都有一个队列 rq,这个队列里面包含多个子队列,例如 rt_rq 和 cfs_rq,不同的队列有不同的实现方式,cfs_rq 就是用红黑树实现的。
当有一天,某个 CPU 需要找下一个任务执行的时候,会按照优先级依次调用调度类,不同的调度类操作不同的队列。当然 rt_sched_class 先被调用,它会在 rt_rq 上找下一个任务,只有找不到的时候,才轮到 fair_sched_class 被调用,它会在 cfs_rq 上找下一个任务。这样保证了实时任务的优先级永远大于普通任务。
下面我们仔细看一下 sched_class 定义的与调度有关的函数。
- enqueue_task 向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数;
- dequeue_task 将一个进程从就绪队列中删除;
- pick_next_task 选择接下来要运行的进程;
- put_prev_task 用另一个进程代替当前运行的进程;
- set_curr_task 用于修改调度策略;
- task_tick 每次周期性时钟到的时候,这个函数被调用,可能触发调度。
在这里面,我们重点看 fair_sched_class 对于 pick_next_task 的实现 pick_next_task_fair,获取下一个进程。调用路径如下:pick_next_task_fair->pick_next_entity->__pick_first_entity。
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = rb_first_cached(&cfs_rq->tasks_timeline);
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
从这个函数的实现可以看出,就是从红黑树里面取最左面的节点。
总结时刻
好了,这一节我们讲了调度相关的数据结构,还是比较复杂的。一个 CPU 上有一个队列,CFS 的队列是一棵红黑树,树的每一个节点都是一个 sched_entity,每个 sched_entity 都属于一个 task_struct,task_struct 里面有指针指向这个进程属于哪个调度类。
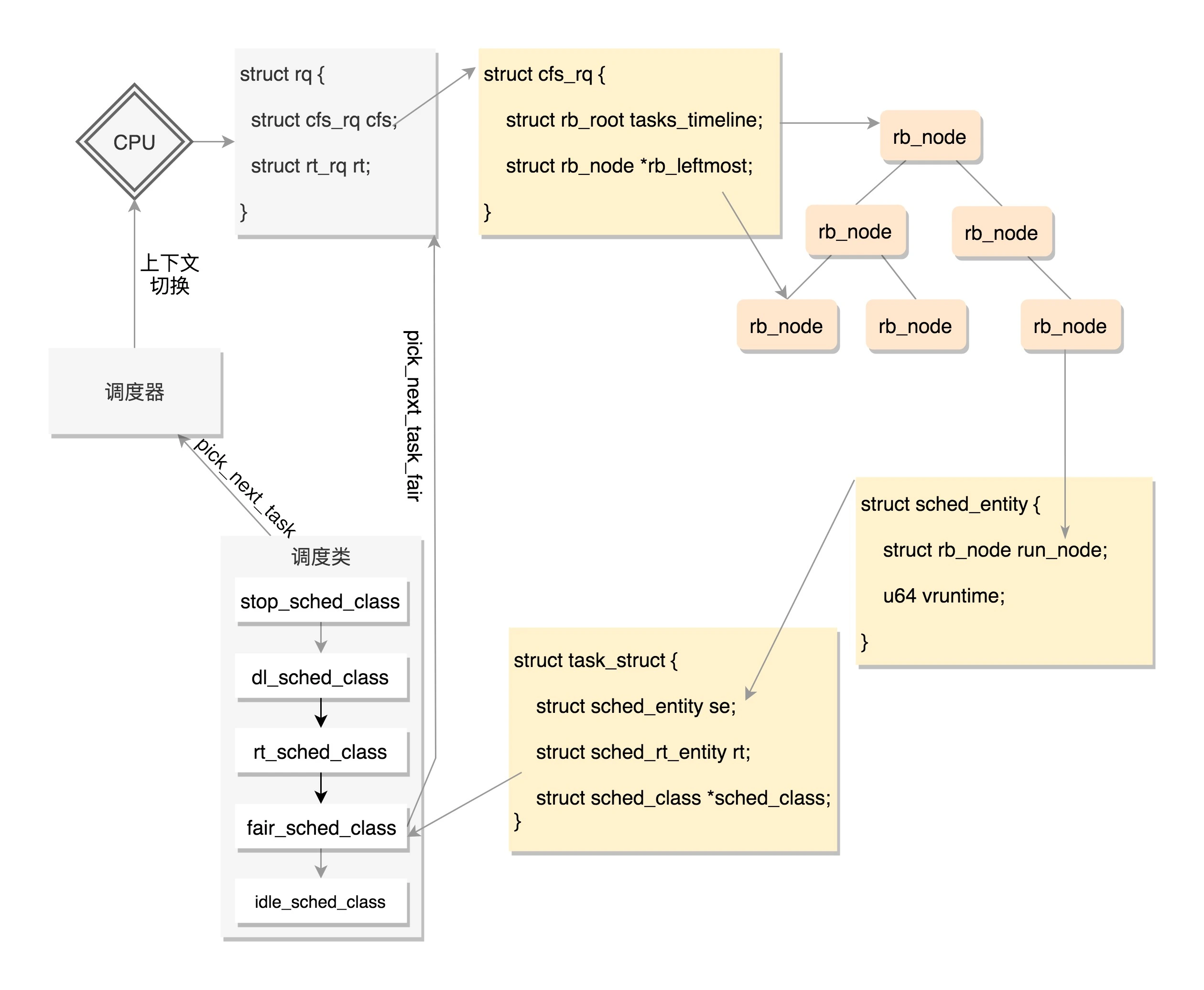
在调度的时候,依次调用调度类的函数,从 CPU 的队列中取出下一个进程。上面图中的调度器、上下文切换这一节我们没有讲,下一节我们讲讲基于这些数据结构,如何实现调度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号