《深入拆解消息队列47讲》功能篇——小记随笔
基础功能:Topic、分区、订阅等基本功能是如何实现的?
如何实现静态和动态配置
静态配置
静态配置是我们在业务开发中经常用到的,配置信息一般以 YAML、JSON、Properties 等格式存储。在服务启动时加载配置文件到内存当中,进行业务逻辑处理。静态配置的好处是简单易用,能满足大部分的需求。缺点是每次变更都需要修改文件内容,并重启服务。在一些业务中,重启应用是比较重的操作,可能会对业务产生一定的影响。所以,就需要引入动态配置。
动态配置
动态配置是指服务可以从某个地方动态加载配置信息。
由于动态配置在技术上的实现方式比较多,这里我们就介绍两种常用的。一种是基于第三方组件,另一种是基于本地文件。
第三方组件,我们以 ZooKeeper 的实现为例。
基于 ZooKeeper 是指我们可以在 ZooKeeper 创建持久节点存储配置信息,然后 Broker 通过 ZooKeeper 提供的 Watch 机制来监听节点。当节点内容变更时可以及时感知,并进行后续的处理。

从运行机制上来看,Broker 监听 ZooKeeper 有以下两种思路:
- Broker 会通过 ZooKeeper 的 Watch 机制监听 /config 下的每个节点,感知到节点内容的变化,再进行后续的操作,比如更新配置。
- Broker 会监听一个专门通知配置更新的节点,比如 /config/notification,然后根据这个通知节点的内容,再去判断哪个配置发生了变更。
这两种思路的主要区别在于:第一种方案变更了配置后,Broker 会立刻监听到,立即生效。第二种方案允许先变更配置而不立即生效,在需要生效的时候再给 /config/notification 写入通知数据,触发配置生效。
集群和节点元数据的格式和存储
集群元数据
集群元数据是用来保存集群维度的一些基本信息。最简单的集群元数据一般只需要包含集群 ID 和集群名字两个信息。
{
"ClusterId":"bmfursdfk",
"ClusterName":"Trade"
}
集群维度的元数据需要持久化存储,所以我们可以在 ZooKeeper 上创建持久化节点 /Cluster 来存储集群的的元数据。
因此集群初始化的流程是:Broker 启动时检查 ZooKeeper 的 /Cluster 节点是否创建,以确保集群已经经过了初始化。一般是集群中的第一台 Broker 节点启动时,会触发集群初始化的逻辑。初始化的逻辑会自动生成一个集群 ID,然后根据配置好的集群名称,一起写入到 /Cluster 节点里面。
节点元数据
节点元数据是用来保存 Broker 维度的一些基本信息。Broker 元数据一般至少要包含节点的唯一标识 BrokerID、节点的 IP、节点监听的端口 3 个字段。
{
"BrokerID":1, //BrokerID的类型可以是Int型,也可以是字符串型,区别不大。
"BrokerIP":"192.2.1.1",
"BrokerPort":8901
}
所以在持久化存储方面,我们可以在 ZooKeeper 上创建持久化的 /brokers 节点,然后在这个节点下为每台 Broker 创建名称为 BrokerID 的临时节点,用来存储 Broker 的元数据。所以 Broker 在集群中的元数据的存储结构就如下图所示:

Broker 初始化的流程是:Broker 启动时会在 /Brokers 下面创建名称为自身 BrokerID 的临时节点,然后写入自己的元数据。Broker 异常时,会自动删除注册的节点。
在集群中支持 Topic 和分区
一定要有 Topic 和分区吗?
在消息队列中 Topic 和分区是必须的概念,Topic 是用来组织分区的逻辑概念,分区用来存储实体的消息数据。
从性能角度来看,如果只有一个分区,就会有性能瓶颈,无法提供水平扩容的能力。此时就需要在前面包一层概念,让它来组织多个分区,这就是 Topic。
Topic 和分区的元数据
Topic 至少需要 TopicID、Topic 名称、分区和副本在集群中的分布 3 个元素。我们用一个简单的 JSON 格式字符串来表示 Topic 的元数据信息。
{
"TopicID": "shlnjdlfsakw",
"TopicName": "test",
"Replica": [
{
"Partition": 0,
"Leader": 0,
"Rep": [
0,
1
]
}
]
}
可以看到,在上面的示例中,TopicID、TopicName、Replica 分别表示 Topic 的唯一 ID、Topic 的名称以及分区副本的分布信息。其中 Replica 里面的 Partition 表示当前是第几个分区,Leader 表示分区的 Leader 是哪台 Broker,Rep 表示副本是分布在哪些 Broker 上的。
元数据的持久化存储
在基于 ZooKeeper 的架构中,我们可以在 ZooKeeper 集群中创建一个持久化的节点来存储 Topic 的相关信息。

在集群启动时,就会为每一个分区选举出来一个 Leader,然后更新对应的 Leader 字段信息。当节点出现变动时,也会触发 Leader 节点切换流程和更新 Leader 节点信息的逻辑。
消费分组(订阅)的进度管理
消费进度主要有两个关联操作:
- 消费者根据消费分组名称来获取分区的消费进度信息。
- 消费者在消费分组维度提交分区的消费进度信息。
获取消费进度的频率比较低,一般初始化的时候拉取一次,而更新 Offset 是每次消费请求都要执行的,所以消费进度是一个低查询、高更新的操作。
消费进度的存储格式
消费进度的信息是在消费分组记录的,一个消费分组可以消费多个 Topic。所以我们应该根据“消费分组 + Topic + 分区号”三元组来记录消费进度。
从存储格式上来看,一般存储的格式会用 JSON 格式或者自定义的行格式(行格式也可以是二进制格式),用 JSON 格式和行格式存储的示例如下所示:
// 存储格式:
{
"GroupName":"group1",
"TopicName": "topic1",
"Partition":0,
"Offset":0
}
// 行格式
group1,topic1,0,0
消费进度的保存机制
最常用的保存消费进度的思路有存 ZooKeeper、存本地文件、存内部的 Topic、存其他存储引擎 4 种思路。
存 ZooKeeper
因为 ZooKeeper 自带了分布式存储和一致性,所以从功能实现上是最简单直接的。但是当消费分组或者消费者数量很多时,就会占用较多的 ZooKeeper 存储空间。另外消费进度提交时都需要频繁对 ZooKeeper 节点进行更新,这样会给 ZooKeeper 造成较大的压力,从而容易使 ZooKeeper 集群高负载,导致集群异常。
存本地文件
这种方案需要选择合适的数据结构来存储数据,以便进行高效的写入和更新。一般情况下,如果实现优雅,性能则不用担心。另外存本地文件,数据在本地硬盘存储,存储容量一般是够的。
这个方案最大的问题是,消费进度的数据文件不是分布式存储的。当单机节点损坏或单机故障时,就会导致无法读取消费进度数据或者消费进度丢失。为了解决这个问题,我们就需要在不同节点上同步消费进度数据,并保持消费数据的一致性。
存内部的 Topic
是指在集群中创建一个特殊名字的 Topic,比如 consumer_group_offset。此时这个 Topic 不允许普通用户读写,只允许用来保存消费进度。
如下图所示,我们知道分区的数据是顺序存储的,并且消息队列的分区是没有搜索和更新的能力的。此时就有一个问题,消费进度如何读取和更新呢?

从功能特性上来看,一个消费分组在一个分区维度的消费进度的值只有一个,即最新的那个值。所以有一种思路是:提供有压缩功能的 Topic,即 Topic 支持根据消息的 Key 对消息进行压缩。比如消费分组 group 消费 Topic1 的 0 分区的进度的消息 Key 为 group1-topic1-0,Value 为消费位点,比如 100。根据消息的 Key 进行压缩,只保留最后一条数据。此时提交 Offset 的时候就不需要更新,只需要将最新的消费进度的数据 “group1-topic1-0:101” 写入到 Topic 中。
存其他存储引擎
存其他存储引擎是指将消费进度存储在其他的存储引擎中,比如 MySQL、Redis 或其他第三方引擎等。这种方案本质上和存 ZooKeeper 的思路是一样的。遇到的问题也一样,主要是性能和稳定性方面的不足。和存 ZooKeeper 最大的区别在于,如果在消息队列 Broker 上采用这个方案,就得单独为存储消费进度信息而引入一个存储组件,这样会增加系统复杂度,还要考虑第三方组件的稳定性问题。
顺序消息和幂等:如何实现顺序消息和数据幂等?
顺序消息的定义和实现
在消息队列中,消息的顺序性一般指的是时间的顺序性,排序的依据就是时间的先后。从功能来看,即生产端发送出来的消息的顺序和消费端接收到消息的顺序是一样的。
消息队列的存储结构特性
消息队列的底层消息是直接顺序写入到文件的,没有用到 B 树、B+ 树等任何数据结构。所以,理想情况下顺序消息的实现是:生产端按顺序发送消息,Broker 端按接收到的顺序存储消息,消费端按照 Broker 端存储的顺序消费消息。

基于顺序存储结构的设计,是指保持消息队列底层顺序存储结构不变的前提下,实现顺序消息的技术方案。
如上图所示,这是一个三分区的 Topic 的底层存储结构。结合前面提到的 3 种实际的场景,为了实现顺序消息就需要满足单一生产者、同步发送、单一分区三个因素。就是说在当前的顺序存储结构中,消息队列实现顺序消息的前提是: 一个生产者同步发送消息到一个分区才能保证消息的有序。
主流消息队列的实现机制
幂等机制的定义和实现
消息队列中幂等的定义
-
生产幂等通常指同一条消息不会被重复写入到 Broker。即同一条消息客户端无论重复发送多少次,服务端也只会保存一份这条消息。
-
消费幂等很少被单独提到。消息队列主要是基于消费位点的消费机制。只要客户端不提交消费位点信息,此时消费天生就是幂等的。即不管怎么消费,返回的都是同一条消息。而如果提交了 Offset,就会自动消费下一条数据,也符合设计预期。在提交位点的操作中,即使重复提交了同一个位点,消费位点保存的都是同一个值,对消费也不会产生影响。
生产幂等的设计实现
Broker 怎么识别接收到的多条消息是指同一条消息?即如果 Broker 不知道收到的消息是否为同一条,那就无法拒绝重复的消息。
我们就知道了消息的唯一性应该是以 Producer 的 send 调用为准。即 Producer send 一次就表示发送了一条消息,send 两次表示发送两条消息。所以就需要在客户端调用 send 的时候标识消息的唯一性,以标识消息的唯一。
通过消息唯一 ID 实现幂等
通过消息唯一 ID 实现幂等是指在发送消息的时候,为每条消息分配唯一的消息 ID(MsgID),来表示消息的唯一性。

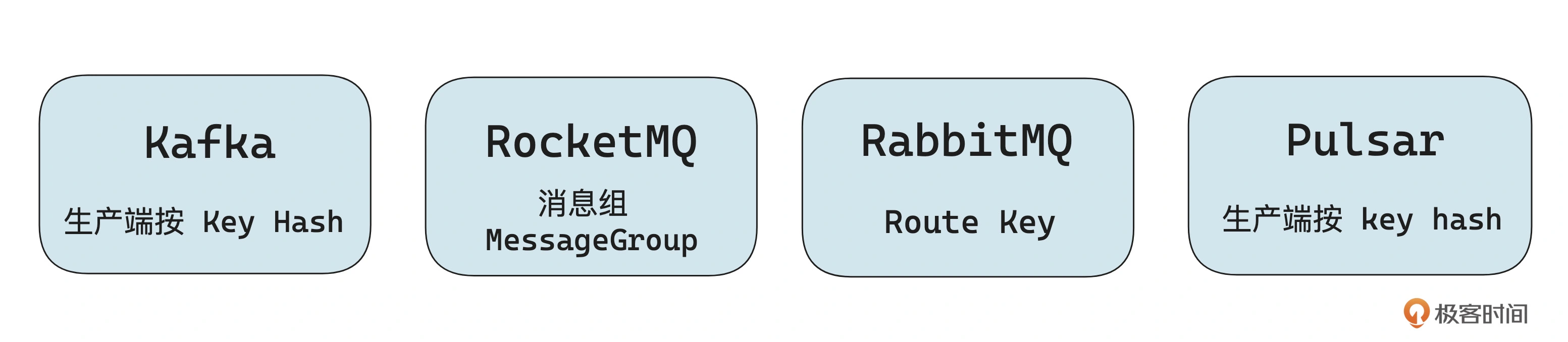
基于这种方案的前提是,需要在生产端开启按 Key Hash 的机制,以保证同一个 MsgID 的消息可以发送到同一个分区中。否则如果同一条消息多次发送投递到不同分区,此时就无法判断之前是否接收过这条消息了。
有两个技术问题需要重点解决:
- 一个是消息唯一 ID 的生成策略
** UUID
** 雪花(Snowflake)算法生成分布式唯一 ID
** 基于 MySQL/Redis/ZooKeeper 等第三方系统生成分布式唯一 ID - Broker 如何识别之前没有接收过这个消息 ID。
就是说需要在 Broker 端设计保存已经接收到的所有 MsgID,用来在接收到消息后将消息 ID 和当前接收过的所有的消息 ID 做一个比较,以判断消息是否重复。
通过生产者 ID 和自增序号实现幂等
该方案的核心思路是:为每个生产者赋予唯一的 ID,生产者 ID 是全局唯一的。然后生产者启动时生成一个从 0 开始的自增序号,用来表示这个生产者发送出去的消息,每条消息分别有一个自增序号,比如 0、1、2……即通过 Producer 和 seqnum 二元组来唯一标识消息。

在上图中,生产者有一个唯一 ID p1,消息中会携带 ProducerID 和 seqnum 两个值来唯一标识这条消息。此时 Broker 会根据这个二元组判断是否收到过这条消息,是就保存,否就拒绝。
实现的角度,服务端理论上依旧要保留这个生产者所有发送成功的 seqnum 的集合,这样才能判断消息是否有重复。此时如果生产者很多并且生产者一直没有重启的话,服务端就需要保留非常多的 Producer 和 seqnum 数据。此时开发复杂度和上一个方案是差不多的,技术实现上只是把标识从 MsgID 换为 Producer + seqnum 而已,没有本质区别。
这个技巧的思路是:我们不保留所有的 seqnum,只保留最新收到的 seqnum。此时如果收到的消息的 seqnum 是下一条 msg,那么就正常保存数据。否则就放进队列中先等待,等待下一条 msg 收到后,再来判断是否保存该数据,甚至可以直接拒绝消息写入。

Broker 收到的 Producer ID 为 p1 的生产者的最新的 seqnum 为 4(current seqnum),那么下一条允许收到的 seqnum 是 5。如果下一条是 5,则保存数据,然后 current seqnum 更新为 5,并等待 seqnum 为 6 的数据。而如果此时发送过来的是 8,就可以有两种策略:
- 策略一:先把 8 缓存在 Broker 内存中,等待收到 6 和 7 后,再把 8 写入存储。这种方案的缺点是 6 和 7 可能永远接收不到,而 Broker 就需要一直保存 8 这条数据。因此可能会发生内存溢出或占用额外的存储空间。
- 策略二:给客户端返回可重试错误,触发客户端的重复发送机制。此时客户端重试写入时,如果 Broker 已经收到 7 的数据,在等待 8 了,此时这条消息就可以顺序写入了。
Kafka 的幂等机制的实现方案
目前业界主流的消息队列只有 Kafka 支持幂等,其他三款消息队列 RocketMQ、RabbitMQ、Pulsar 都不支持。所以接下来我们简单看一下 Kafka 幂等机制的实现方式。
kafka 的生产者在启动时会为每个生产者分配一个唯一 ID。这个唯一 ID 是客户端从 Broker 申请的,不是自己生成的。
Kafka 在每个 Topic-Partition 维度都会有一个独立的 seqnum,即通过 PID、Topic、PartitionNum、seqnum 四元组来唯一标识一条消息。
从具体实现上看,Broker 端会缓存 PID 对应 Topic-Partition 的五个最近的 batch 信息。比如曾经接收过 1、2、3、4、5、6 六个消息,此时只会缓存 2~6 五个消息 ID。如下图所示,Broker 接收到数据后,会循环缓存中的数据,判断是否重复,重复就拒绝,不重复就直接保存。

Kafka 的实现方案可以说是一个取舍的方案。因为 Kafka 主打的是高性能,不能因为幂等的特性导致性能下降太多。通过缓存少量的数据来实现大部分情况下的幂等,也不会对内存和性能造成太大影响,只是付出的代价是不能支持完全的幂等。
因为数据是存在内存中的,需要保证这个功能的缓存数据不会对内存造成压力,因此需要控制内存的使用总量。因此我们假设单台 Broker 可支持的分区数为 P,单台生产者的数量为 M,存的消息数量为 N,此时消耗的内存总量为 T,因此:
T = P * M * N
因为 M 是完全不可控的,P 取决于用户的运营策略,某种意义也不可控,所以内核可控的就是 N。因此 N 如果太大,则会对内存造成太多压力,所以 N 就不能太大。基于此,可能就拍了个 5 吧。值得一提的是,5 是 hard code 在代码里面的,不能改动。
延时消息:如何实现高性能的定时/延时消息?
延时消息的场景和定义
先来看一个延时消息典型的使用场景。在网上购买商品下单的过程中,有个功能是:下单完成后 30 分钟如果没有完成支付,则这个订单就自动被取消。如下图所示,从技术上来看,为了实现这个功能,最直观的思路是我们可以将订单数据存在 DB 的表中。然后通过定时程序每秒定时去扫描订单数据,判断如果超过 30 分钟则进行后续的处理。

这个方案的问题是,业务方维护成本较高,需要开发维护定时任务并处理扩缩容,以保证数据处理的及时性。当订单数据量很大时,就容易出现性能问题。另外可能无法实现高精度的延时。
因此理想状态是延时逻辑下沉到某个底层的引擎去实现,业务不需要感知任何延时逻辑,正常处理数据即可。在技术体系中,这个底层引擎一般由消息队列来担任。因此只要在类似这种需要定时或者延时触发某个行为的场景,都可以用到延时消息。
从功能表现来看,就是 Broker 接收到客户端发送的延时消息后,将消息设置为不可见,在时间到期后把消息从不可见变为可见,从而让下游可以消费到数据。
从技术上拆解延时消息
从使用上来看,假设生产端发送定时 30 分钟后或者明天早上 8 点可见的消息给 Broker,Broker 在接收到延时消息后,会先持久化存储消息,然后标记这个消息不可见。再通过内部实现的定时机制,延时到期后将不可见消息变为可见消息,从而让客户端可以正常消费到这条数据。
所以从技术上来看,消息队列实现延时消息主要包含数据存储、如何让消息可见、定时机制、主动推送四个部分。
如何让消息可见
在技术上看,消息队列让消息从不可见变为可见的核心思路都是:先将数据写入到一个临时存储,然后根据一定的机制在数据到期后让消费端可以消费到这条消息。这个临时存储一般有以下 3 种选择:
- 单独设计的数据结构
- 独立的 Topic
- 本地的某个存储引擎(如 RocksDB、Mnesia 等)
为了在延时到期后消费者可以消费到这些消息,从技术上看主要两个实现思路:
- 定时检测写入
- 消费时判断数据是否可见
定时写入检测
是指 Broker 收到数据后先将数据存储到某一个存储中(比如某个内置 Topic),同时有独立的线程去判断数据是否到期。如果数据到期,则将数据拉出来写入到实际的 Topic,从而让消费端可以正常消费数据。
这种方案的好处是,对生产消费的主流程改造较小。只需要在写入的时候做一个区分逻辑,然后独立实现定时检测,将到期数据写入到目标 Topic 即可。缺点是在延时消息量大的时候,到期时间不会那么精准。
消费时判断数据是否可见
是指每次消费时判断是否有到期的延时消息,是的话就从第三方存储拉取延时消息返回给消费者,从而实现消息从不可见到可见。
这种方案的好处是省去了定时线程的检测写入逻辑,流程简单许多。但是因为消费操作的 QPS 一般很高,在设计这个第三方存储的时候,需要尽量提高获取操作的性能,并降低对内存的占用。另外每次都去检测是否有延时消息,可能会出现性能问题。
定时机制的实现
直观上来看,定时机制的核心逻辑是:随着时间的推进,拿出到期的延时消息进行处理。所以从技术上看,定时机制可以拆解为定时器和延时消息定位处理两部分。
- 定时器指按照时间向前推进,比如毫秒、秒级、分钟级向前推进
- 延时消息定位处理指的是随着定时器推进,在每个时间刻度可以高效定位,获得需要处理的延时消息列表。即需要重点关注添加、获取的时间复杂度。
延时消息的技术方案
基于轮询检测机制的实现
该方案的核心思路是:将延时消息写入到独立的存储中,利用类似 while + sleep 的定时器,来推进时间,通过独立线程检测数据是否到期,然后从第三方存储中取出到期的数据进行处理。
该方案不需要维护时间刻度,只要设计合适的数据结构来存储延时消息列表,以达到精度和性能的要求即可。从操作上看,主要由插入和获取两个操作组成,此时需要关注的是插入和获取的时间复杂度。我们追求的目标是这两个操作的时间复杂度尽量低,因此关键的工作是选择合适的底层存储结构。
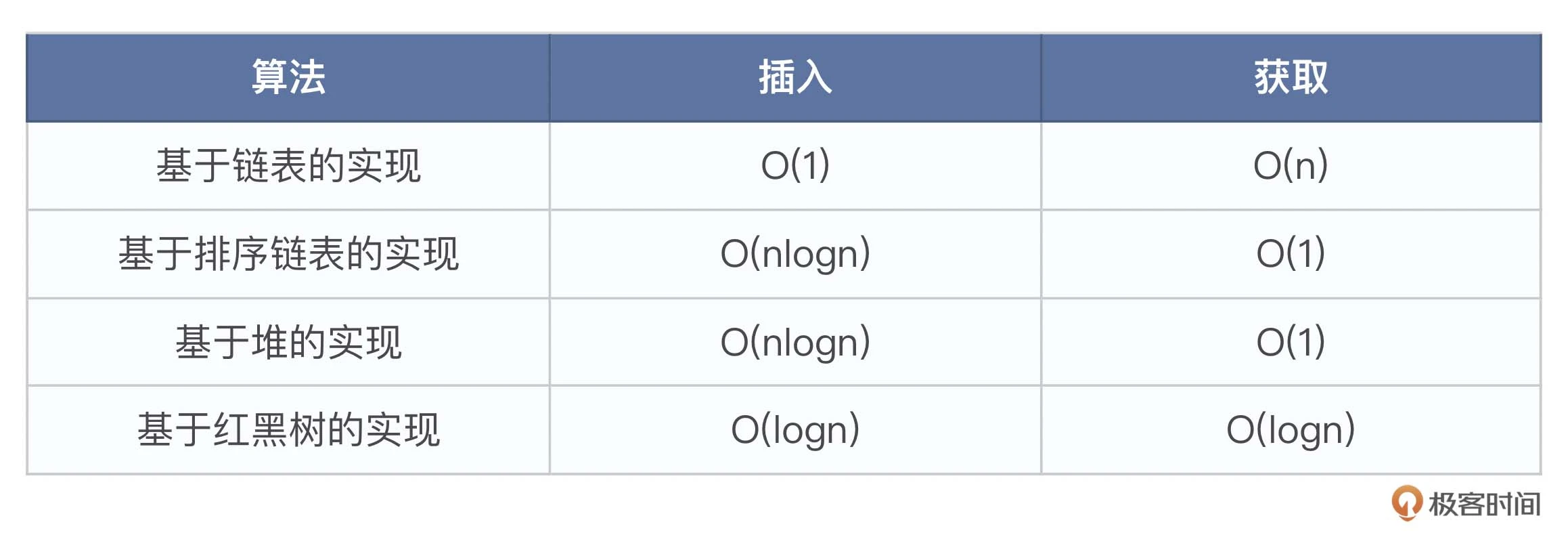
由表格数据可以知道,如果更关注插入的性能,那么就得选择红黑树和链表。如果更关注获取的性能,则可以选择排序链表和堆。因为插入和获取的时间复杂度不全是 O(1),所以当某个 Topic 的数据量很大时,还是会出现性能问题。
我们可以通过分治的思想来缓解性能并提高精度。
我们可以将原来的每个 Topic 一个存储结构,拆分为多个存储结构。比如可以根据时间进行拆分,如 1 小时、6 小时、12 小时、1 天、大于 1 天等 5 个维度。从而降低每个存储结构的长度,在一定程度上解决性能问题。
这种方案的优点是实现相对简单,开发成本较低。缺点是延时的精度太粗,无法做到精准的延时。但是从实际业务上来看,因为大部分业务不需要非常精准的延时消息,也允许在延时消息的场景中有一定的性能下降。所以这种方案基本能够满足大部分延时消息的需求,这也是业界很多主流消息队列都采用的方案。
基于时间轮机制的实现
然后通过构建多级时间轮,在每个时间刻度上挂载需要处理的延时消息的索引列表。再依赖时间轮的推进,获取到需要处理的延时消息列表,进行后续的处理。

本质上看,时间轮和基于轮询检测的思路是一样的。区别在于,基于时间轮机制可以达到以下 4 个效果:
- 插入和获取的时间复杂度都是 O(1)
- 可以支持任意时间精度的延时消息
- 可以支持任何时长的延时消息
- 每个时间刻度都可以支持任意多的元素
时间轮是一个很成熟的算法,分为单级时间轮和多级时间轮,多级时间轮是单级时间轮的扩展。它的核心思想是:
- 先设定好最小的时间精度,然后将时间划分为多个维度,比如年、月、日、时、分、秒。通过多级的时间轮来表示时间。
- 在每个刻度上挂上一个待处理的延时消息链表,链表的元素存储了延时消息的索引信息。
- 添加延时消息时,找到刻度对应的链表,在链表最后加上该元素,所以时间复杂度为 O(1)。
- 获取延时消息时,找到刻度对应的链表,把这个刻度对应的链表都拿出来处理,时间复杂度也是 O(1)。
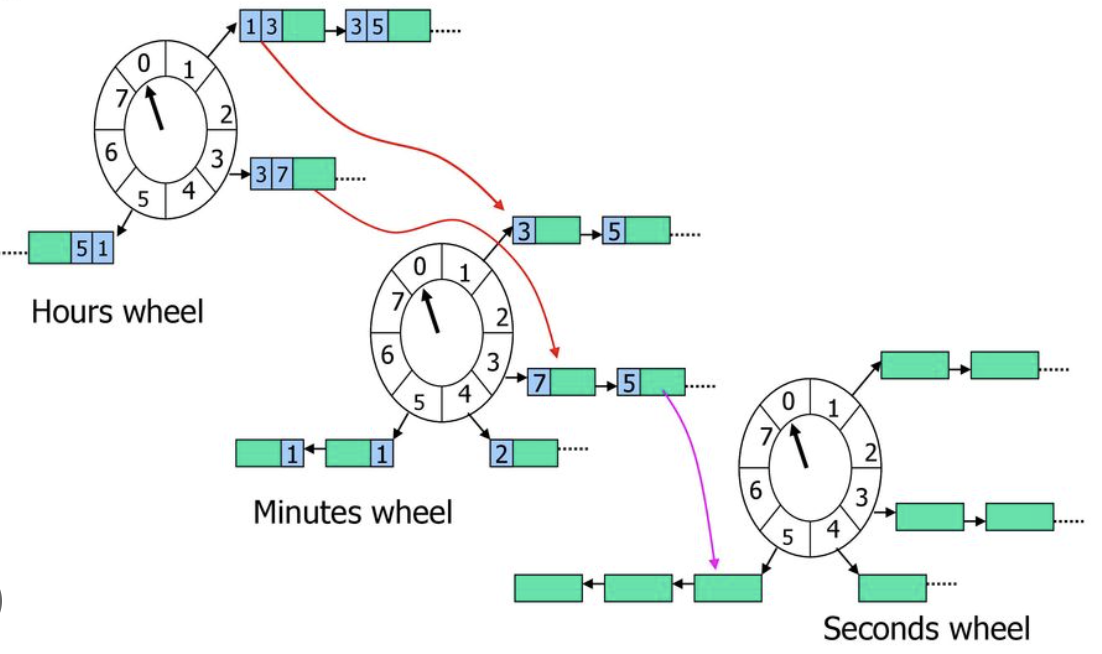
这是包含 Seconds、Minutes、Hours 三个级别的时间轮,每一个时间轮的最大刻度为 8,上一级时间轮最小刻度等于下一级时间轮刻度的总和。当我们设定好时间精度和时间轮的维度后,如果是添加延时消息,则在多级时间轮上找到对应时间的延时消息列表,把消息插入到列表中。如果是获取到期的延时消息,也是根据时间轮找到当前时间的延时消息列表,然后把整个列表拿出来处理即可。
主流消息队列的延时机制实现
RocketMQ 延时消息的设计思路
社区版本的 RocketMQ,不支持任意时间的延迟,它提供了 18 个级别的延时消息,分别是:
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
从原理来看,RocketMQ 的延时消息是基于轮询检测机制的思路来实现的。
在 RocketMQ 中,会有专门的线程池去处理延迟消息。比如 18 个延迟级别,就会生成 18 个定时任务,每个任务对应一个队列。这个任务每隔 100 毫秒就会去查看对应队列中的消息,判断消息的执行时间。如果到了执行时间,那么就会把消息发送到其本该投递的 Topic 中,这样消费者就能消费到消息了。
RabbitMQ 延时消息的设计思路
RabbitMQ 的延迟消息有基于死信队列和集成延迟插件两种实现方案。
基于死信队列是指使用两个队列,一个队列接收消息不消费,然后等待指定时间过后消息过期,再由该队列绑定的死信 Exchange 机制再次将其路由到另一个队列提供业务消费。

集成延迟插件(rabbitmq-delayed-message-exchange)是指延时消息不直接投递到队列中,而是先转储到本地 Mnesia 数据库中,然后定时器在消息到期后再将其投递到队列中。实际流程如下所示:

Pulsar 延时消息的设计思路
Pulsar 实现延迟消息的思路是比较特殊,也比较取巧,没有独立线程来检测消息到期,而是在消费的时候通过消费动作来触发检测。
如上图所示,延迟投递的消息会先保存到一个叫做 Delayed Message Tracker 的数据结构中。Delayed Message Tracker 在堆外内存维护一个 delayed index 优先级队列,这个优先级队列会根据延迟时间进行堆排序,延迟时间最短的会放在队列的头部,时间越长越靠近队列尾部。消费者消费时,会先去 Delayed Message Tracker 检查,是否有到期需要投递的消息。如果有到期的消息,则从 Tracker 中拿出对应的 index,找到对应的消息进行消费。如果没有到期的消息,则直接消费正常的消息。如果集群出现 Broker 宕机或者 Topic 的 Leader 切换,Pulsar 会重建 delayed index 队列,来保证延迟投递的消息能够正常工作。
Kafka 延时机制的设计思路
kafka 本身不支持延时消息,但是支持延时机制,用于延时回包、延时确认的场景。
从技术上看,Kafka 的延时机制是典型的基于时间轮算法来实现的。它的实现核心是多级时间轮以及使用 Java 的 DelayQueue 来保存延时数据和推进时间,整体实现性能和实现方案是非常优雅的。这块网上的资料很多,就不展开讲细节了,有兴趣的话可以自己去研究下。
事务消息:如何实现一个完整的事务消息模块?
消息队列中的事务是什么
从原始概念来看,事务是并发控制的单位,是用户定义的一个操作序列。简单解释,事务是一批操作的集合。它有 ACID 四个特性,分别是:原子性、一致性、隔离性、持久性。
- 原子性指这批操作要么全部成功,要么全部失败。
- 一致性指事务中的所有操作的结果符合预期,都能达到想要的结果。
- 隔离性指不同事务间是完全隔离的,不相互干扰。
- 持久性指事务一旦被提交,那么它的执行结果则是永久的。
我们知道消息队列中的核心操作是生产、消费、集群管控三种类型的操作。其中值得引入事务的主要是生产和消费操作。从客户端的视角来看,就有
- 生产事务
- 消费事务
- 生产 + 消费事务
- 消费 + 处理 + 生产
主流消息队列的事务功能
RabbitMQ 的事务消息
RabbitMQ 支持的事务满足的是生产消息的事务。即一批生产操作要么全部成功,要么全部失败
RabbitMQ 的事务是在 Channel 维度实现的。将通道(Channel)设置为事务模式后,所有发送到该通道的消息都将被缓存下来。事务提交后,这些消息才会被投递到具体的 Exchange 中。
RocketMQ 的事务消息
RocketMQ 支持的事务满足的是生产消息和本地事务相结合的一种事务形态
在下单流程中,我们一般需要将订单数据插入 DB,并往消息队列发送订单消息。此时可能有两种情况:出现消息生产成功,DB 插入失败;DB 插入成功,生产写入失败。
生产者发送事务消息到 Broker,Broker 会在 Commitlog 持久化存储这条消息并标记为不可见。当客户端本地操作执行完成后,再提交二次确认结果,将消息标记为可见,让消费端可以消费到消息。但特殊的是 RocketMQ 提供了客户端回查机制,也就是说当生产消息成功、本地事务失败时,Broker 会根据一定的策略对客户端的本地事务发起回查,以尽量保证事务的成功率。
RocketMQ 事务消息仅支持在 MessageType 为 Transaction 的 Topic 内使用。也就是说事务是在 Topic 维度生效的,事务消息也只能发送到类型为事务消息的 Topic 中。
Kafka 的事务消息
Kafka 支持的是生产消息的事务。

Kafka 的事务是在事务 ID 维度生效的。客户端会先设置一个事务 ID,多个生产者中设置的事务 ID 可以是一样的。用这个事务 ID 开启事务后,可以实现对多个 Topic 、多个 Partition 的原子性的写入。Broker 收到消息后,会按正常流程保存事务消息,只是将这些消息标记为不可见。当提交事务后,才将这些消息标记为可见,让消费端可以消费到。
在底层实现中,事务 ID 以及事务相关的状态保存在一个叫做 __transaction_state 的内部 Topic 中,用来持久化保存事务 ID、状态等信息。
Pulsar 的事务消息
Pulsar 主要满足的是消费 + 处理 + 生产的事务。简单理解就是用来满足流场景将消费、处理、生产消息整个过程定义为一个原子操作,以保证整个操作的原子性,所以 Pulsar 事务包含的操作有消费、处理、生产三种操作。
从底层实现来看,Pulsar 的事务处理流程与 Kafka 的事务处理思路大致保持一致。都是通过事务 ID 来标记事务,开启事务投递消息,都会将消息标记为不可见,同时往一个内部的 Topic 记录事务的状态数据。等全流程处理都成功后,才会提交事务。此时在生产端标记消息可见,在消费端提交消费位点,从而完成整个流程。Pulsar 的事务可以看作是 Kafka 事务的升级版,它保证的是流处理操作的原子性。
总结
我们可以总结出三点关键信息:
- 不同消息队列对事务消息的功能定义都不一样。
- 都是基于两阶段事务来设计的,分为生产消息(准备阶段)和提交事务(确认阶段)。
- 生产事务都是先将消息标记为不可见,等提交事务后再将消息标记为可见。
分布式事务理论基础
事务可以分为单机事务和分布式事务。分布式事务的解决方案一般有 XA(2PC/3PC)和 TCC 两种。XA 指的是 XA 分布式事务协议,通常包含两阶段事务(2PC)和三阶段事务(3PC)两种实现方式。
两阶段事务(2PC)
- 协调者询问所有参与者是否可以进行提交,并等待所有参与者响应。
- 所有参与者开始执行事务(但是不提交事务),并告知协调者自己的执行结果是成功(本地事务执行成功)还是失败(本地事务执行失败),然后等待协调者通知最终是提交事务还是回退事务。
- 如果协调者收到所有节点都执行成功了,那么通知所有节点全部进行提交事务操作,否则只要存在一个参与者执行失败,或者协调者超时了还没有收到全部参与者的执行结果,那么就通知所有参与者回退事务。
- 所有参与者根据协调者的通知,统一进行提交或者回退事务,并反馈信息。
三阶段事务(3PC)
三阶段事务是二阶段事务的改进版,将 2PC 中的准备阶段一分为二,用于保证在最后提交阶段之前,所有的节点状态都是一致的。并且在协调者和参与者中都引入了超时机制,一旦参与者长时间没有收到协调者的通知,那么参与者将执行提交事务操作。
-
CanCommit 阶段:
** 协调者询问所有参与者是否可以进行提交,并等待所有参与者响应;
** 所有参与者预估判断是否可以提交(这里不执行事务),将结果(YES/NO)反馈给协调者;
** 如果上一阶段存在参与者返回 NO,或者协调者等待超时,那么中断事务,不继续后面的操作;
** 如果所有参与者都返回 YES,则进入 PreCommit 阶段。 -
PreCommit 阶段:
** 协调者通知参与者进入准备阶段,并等待参与者响应;
** 参与者执行事务(但不提交),并将执行结果反馈给协调者,然后等待协调者通知最终是提交事务还是回退事务。
二阶段事务本身存在一些缺陷,比如同步阻塞问题、单点故障、数据不一致等
- DoCommit 阶段:
** 如果所有参与者都反馈了 YES,那么协调者向参与者发送提交事务的通知;
** 参与者返回 NO,或者协调者等待超时,那么协调者向参与者发送回退事务的通知。
3PC 存在的问题是,协调者在向所有参与者发送回退事务指令的情况下,如果因为网络原因导致参与者没有收到通知,当参与者等待超时后会自动执行提交事务,这样就造成了数据不一致的现象。
TCC
TCC 主要在应用层面上,需要我们自己编写业务逻辑,TCC 将业务分为 Try、Confirm、Cancle 三部分逻辑。Try 为尝试执行业务,如果 Try 阶段执行成功则进入 Confirm 阶段,确认执行业务,否则进入 Cancle 阶段,取消执行业务。
- Try 阶段:尝试执行业务,完成业务的检查,预留业务需要的资源。
- Confirm 阶段:直接使用 Try 阶段的预留资源执行业务,这里不需要进行业务校验,因为在 Try 阶段已经校验过了。
- Cancle 阶段:取消执行业务。
消息队列的事务方案设计
消息队列事务其实就是 XA 两阶段提交的实现。先以生产事务举例说明来拆解一下技术核心点

- 初始化事务,假设我们以事务 ID 来标识一个事务,初始化的时候我们就需要把事务 ID 信息存储到事务协调者上。
- 第一阶段客户端会把消息都发送到不同的 Topic 和不同的分区中,因此数据是发送到不同 Broker 的,此时在事务没有提交的时候,数据应该是不可见的。
- 第二阶段客户端会提交事务,告诉协调者所有的操作都成功了,此时可以把这次事务相关的信息都提交给事务协调者,比如本次事务所包含的 Topic 和分区等。
- 当客户端提交事务后,协调者会通知把所有 Broker 上的这些数据都变为可见。
从中我们可以拆解出以下 3 个技术点:
- 因为事务的状态需要存储、查询,所以需要将事务状态信息进行持久化存储。
- 因为多台数据是发送到多台 Broker,所以在提交事务时客户端需要通知事务协调者,让事务协调者去通知所有 Broker 的数据变为可见,所以需要一个事务协调器。
- 因为第一阶段提交的事务消息是不可见,第二阶段事务提交后可见或回滚,所以需要设计一个将数据从不可见变为可见的机制。
如何存储事务状态信息
事务状态是用来记录、查询的,在提交事务的阶段去通知各个 Broker 去执行提交事务的操作,所以需要为事务相关的元数据找一个地方存储。我们知道,消息队列本身就是一个存储引擎,所以很多消息队列就会选择创建一个内部的 Topic 用来存储事务相关的数据,这样实现起来就没有额外的开发成本。
事务协调者如何设计
事务的协调者从具体实现来讲就是一段代码逻辑。它主要负责保存事务的状态信息和通知事务的提交、回滚。
在消息队列中,比如 Kafka 或 Pulsar,它们的实现是:
- 先创建一个内部的 Topic 来存储事务状态数据。
- 通过一定的算法将事务 ID 哈希计算后,算出这个事务 ID 的数据存储在哪个分区。
- 这个分区 Leader 所在的 Broker 就是这个事务 ID 的事务协调者。
选出事务协调者后,客户端就和这台 Broker 进行交互,直接将事务状态数据写入到算出来的这个分区中。然后当接收到客户端提交事务的请求时,再通过内部接口通知各个 Broker 提交事务。
如何实现消息从不可见到可见
- 先将消息写入到其他的地方,然后等事务提交的时候再将数据写入到实际的 Topic 当中,目前主流消息队列 RabbitMQ 用的是这个方案。
- 数据按照原先的流程直接写入原先的 Topic 中,只是这条消息会加上事务 ID 相关信息,同时标记为事务消息,在事务没有提交的时候标记这条消息为不可见。
我们在基础篇讲过,消息队列底层是顺序存储的结构。所以如上图所示,如果以事务 ID 为标识来实现事务,此时在某个 Topic 中就有可能既有事务消息,又有非事务消息。其中事务消息可能有已提交的事务(如上图中黄色的 m3),也有未提交的事务(如上图中粉色的 m2)。
此时在顺序存储结构中,数据是顺序消费的。不过这里有一个问题,如果遇到未提交的事务,消费端能不能继续往下消费呢?
- 不能向下消费。这种相当于消费者顺序消费,如果遇到有未确认的事务消息,此时依旧不往下消费。因为事务消息有过期时间,等到这条事务消息过期了或者被提交了再继续消费。这种方案是最简单的,没有太多工作量,也不需要对主流程进行修改。
- 可以向下消费。此时相当于会跳过这些未确认的消息,但是在后续的消费过程中都需要来判断一下这些消息是否已经被确认,是的话就需要投递给消费者。这种方式一般需要单独维护未确认的事务消息列表,以提高消费时检查的性能,实现起来成本较高。
第一种方案可能会出现消费卡顿、消费较慢的问题,但是可以保持消费顺序,且实现简单。第二种方案,消费速度较高,但是会有消费乱序的情况,且实现相对复杂。
我们知道在消息队列的顺序存储结构中,消息的内容是不能改的。那在这种模式下如何将一个消息从未确认变为已确认、从不可见变为可见呢?

如上图所示,为了解决这个问题,因为消息内容是不能更改的,所以一般需要引入另外一个数据结构来存储事务的状态,标记这个事务消息是否提交,然后在消费的时候进行判断。
死信队列和优先级队列:如何实现死信队列和优先级队列?
什么是死信队列
从本质上来看,死信队列不是一个队列,而是一个功能

当数据写入失败、数据过期、消费处理失败后,自动将有问题的数据投递到另一个存储的功能就叫做死信队列。在实际业务中,用得最频繁的就是生产失败和消费失败时的死信队列。
死信队列实现的技术方案
生产和消费的死信队列的效果,业务端都能自定义实现,将业务自定义处理这部分复杂重复的工作包装在消息队列内部完成, 从而降低业务的使用成本。
死信队列的存储目标
如果是业务自定义实现的死信队列,那么一般可以灵活选择其他存储引擎或其他集群的 Topic。
如果是消息队列内核 SDK 实现的死信队列,一般只支持同一个集群内的另外一个 Topic 作为目标存储,最多支持跨集群 Topic 的投递
死信队列的方案设计
从功能上看,我们可以分为生产死信队列、消费死信队列、Broker 死信队列三种场景。
生产和消费的死信队列的功能都是在客户端完成的,基本不需要服务端参与。
主流消息队列的死信功能
只有 RocketMQ、RabbitMQ 支持死信队列。
RocketMQ 实现的是消费死信队列。即当一条消息消费失败,RocketMQ 会自动进行重试。达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息。此时如果开启了死信队列,则不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
这种正常情况下无法被消费的消息我们称之为死信消息(Dead-Letter-Message),存储死信消息的特殊队列我们称之为死信队列(Dead-Letter Queue)。在具体实现中,RocketMQ 会自动创建内部 Topic,然后将消息投递到这个内部 Topic 中。
RabbitMQ 实现的是生产和 Broker 内的死信队列。RabbitMQ 的死信队列我们称之为死信交换机(Dead-Letter-Exchange,DLX)。在功能上,当消息变成死信消息后,它会被重新发送到另一个交换机中,这个交换机就是 DLX ,绑定 DLX 的队列就称之为死信队列。
什么是优先级队列
优先级队列的定义就是:客户端在发送消息的时候会给每条消息加上优先级信息,不管客户端发送消息的顺序是怎样,Broker 都会保证消费端一定会先消费到优先级高的消息。
如何设计实现优先级队列
业务实现优先级队列的效果
我们可以基于 Topic 和分区模型来实现优先级队列的效果。
我们的核心思路是:为每个优先级分配一个分区,写入时将不同的优先级数据写入到不同的分区。消费时指定分区消费,优先消费优先级高的分区。进一步说,为了保证性能和横向扩容的能力,我们可以为每个优先级级别分一个独立的 Topic 来存储数据。比如优先级 1 的数据存储在 Topic1 中,优先级 2 的数据存储在 Topic2 中,以此类推。
内核支持优先级队列
那么要在 Broker 内核实现优先级队列,从技术上看主要分为两步。
- 协议层面:客户端发送消息时需要给消息加上优先级信息,所以请求协议就需要支持添加优先级信息的字段。
- 内核层面:Broker 接收到数据后,需要经过某种机制保证消费者优先消费到高优先级的消息。
这里我们主要看看内核层面如何支持,从技术上来看,主要有以下几个思路:
- 正常写入数据,同时维护一个按照优先级排序后的消息索引,消费的时候根据索引的顺序去定位读取数据。
- 数据写入时对存量的消息数据进行全量重排序,然后按正常逻辑进行消费。
- 用空间换时间,只支持固定维度的优先级,比如总共 100 个优先级。在底层对于开启优先级队列的数据,进行分文件顺序存储。在写入的时候根据优先级顺序写入不同文件段,消费的时候优先消费优先级高的数据。
从实际实现的角度来看,第二和第三种方案用得比较少,因为需要对消息队列的顺序存储模型做较大改动。比如第二种方案需要频繁把数据全部取出来,排序后再重新写入,对资源的消耗太大。第三种方案需要修改底层数据的存储模型,改动也较大。
所以方案一是比较常用的方案,它的主要思路是:在内核中维护一个按优先级信息排序的索引结构,索引指向消息数据的实际存储位置。当数据写入时,会先把数据按照原先的流程写入到分区里面,然后根据消息的优先级信息去更新优先级索引。消费的时候会先读取优先级队列中的数据,判断应该读取哪些数据,定位到具体消息数据返回给客户端。

从功能上来看,因为只有排序没有搜索的需求,所以我们可以基于排序链表来构建优先级索引。接下来我们需要选择合适的排序算法,排序算法主要关注的是时间复杂度和空间占用。
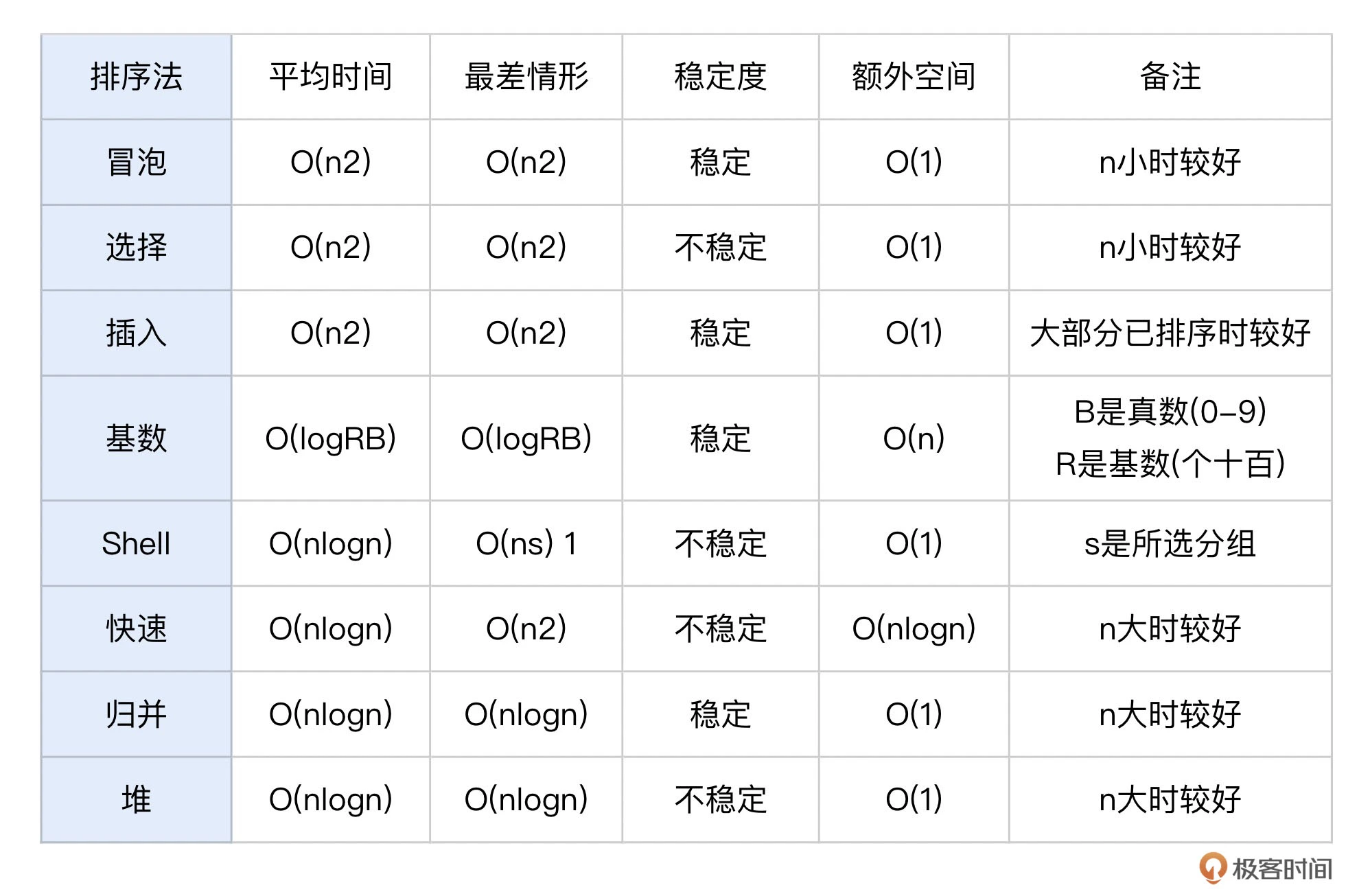
因为消息队列堆积的数据可能会很大,所以我们需要选择数据量大时性能仍然优秀且稳定的算法。从具体业务使用场景分析,消息队列优先级一般是相对固定的、有阶梯的,比如固定的 5 个、10 个优先级这样子。基于这两个信息,结合上面的表格,我会建议你选择归并排序。
目前主流消息队列对优先级队列支持的较少,只有 RabititMQ 支持。接下来我们就来看一下 RabbitMQ 中优先级队列的实现方式。
消息查询:如何实现消息查询功能?
最常见的场景是:用户觉得某条消息丢了,需要查询这条消息是否保存在 Broker 中,此时你会怎么做呢?
从用户视角看,一般就有以下 4 种查询需求:
- 根据消息位点(Offset)信息查询消息。
- 根据某个时间点或时间范围查询消息。
- 根据消息 ID 查询消息。
- 根据消息 Key 或消息中的某个内容查询消息。
如果能在 Topic 中实现查询功能,那么就能省掉轨迹数据导出和第三方引擎的成本。这也是消息队列内核内置查询功能的收益之一。
消息队列支持查询的理论基础
基于每个分区单独一个存储“文件”实现的分区维度的底层分段数据结构图

每个数据段里面的数据由多个数据组成,每个数据又由消息位点和消息组成。

那怎么在这个数据结构上进行数据查询呢?从技术上来看,核心是数据索引的构建
关于索引的一些知识点
问题 1:为什么一定要构建索引呢?
从技术上看,查询的核心就是速度,不能每次都去遍历所有的数据,也不能直接从硬盘中检索数据,因为基于硬盘搜索数据的性能很低。所以构建索引最主要的原因是,可以把数据加载进内存,提高数据的处理效率。
问题 2:如何构建索引?
一是索引不能占用太多内存空间,二是索引元素的增加、删除、检索的时间复杂度要尽量低。
索引的持久化存储肯定是存储在文件上的,而消息数据底层是分段存储的。所以如下图所示,从技术上看,在索引的构建上有所有段文件构建一个索引和每个数据段构建索引两个思路。
这两种方案都会用到,根据不同的场景来选择合适的方案即可。
内核支持简单查询
根据 Offset 查询数据
分区的存储结构已经是一个多级索引,具体说是一个三级索引。我们的主要工作是实现第三级索引。
- 第一级:Topic。因为每个 Topic 的数据单独存储。
- 第二级:分区。因为每个分区的数据单独存储。
- 第三级:Offset 索引。构建 Offset 和具体文件位置的索引。
我们知道消息队列底层是顺序存储的模型,所以 Offset 是顺序递增的。简单理解,数据已经是一个天然顺序了,基于一个天然顺序的数据来做检索就非常简单,直接引入二分查找就可以。
所以我们索引文件的数据结构实现就很简单。
我们可以用顺序链表来存储索引数据。每个链表节点存储消息位点(Offset)和消息所在的文件的位置(Position)两个元素。基于顺序链表,如果要搜索某个 Offset 的数据,直接使用二分查找(折半查找)即可,查找的时间复杂度为 O(logn),顺序链表的插入的时间复杂度为 O(1)
因为要持久化存储,所以文件中索引数据的格式可以用下面的格式进行存储。
offset: 1 position: 10
offset: 10 position: 20
offset: 20 position: 55
offset: 30 position: 70
offset: 300 position: 90
不知道你是否注意到了 Offset 和 Position 是单向递增的,但都不是连续的,这是为什么呢?
假设我们有 10 亿条数据,按照上面的设计应该也有 10 亿个索引节点。以此类推,如果数据更大,索引数据会占用大量的存储空间,所以我们在顺序链表的基础上,可以引入跳跃表来节省空间。
- 通过二分算法找到离 22 最近的前一个跳跃表元素 20,得到 20 对应的 Offset=20 和 Position=55,查找的时间复杂度为 O(logn)。
- 因为步骤 1 找到的节点不是我们需要的 22,所以我们向后遍历两个元素就可以找到数据 22,这一步理论的时间复杂度为 O(n)。但是我们可以通过控制两个跳跃表索引元素之间的节点数量,来降低时间复杂度。比如我们固定为间隔 10,此时时间复杂度就是一个常量 10,所以从算法来看,这个时间复杂度是可以忽略的。
引入跳跃表结构后,通过牺牲一定的时间复杂度换取了空间复杂度的大幅度降低,是一个蛮推荐的方案。
根据时间戳查询数据
从需求上看,根据时间戳查询主要有以下两种查询场景:
- 根据时间戳查询到指定位置的数据。
- 根据时间戳范围查询到范围内的数据。
消息队列内核一般只支持第一种场景。
消息队列实现根据时间查询的思路是:先根据时间戳找到对应的 Offet,然后再根据 Offset 查询到对应的数据。技术上的核心思路是:构建时间戳和 Offset 对应的索引。
因为消息数据是根据时间戳递增存储的,所以时间戳和 Offset 索引也是基于顺序链表构建的。链表节点由毫秒时间戳和消息位点组成。

同样的因为需要持久化存储,所以底层索引文件内容格式可以如下所示:
timestamp: 1691236897071 offset: 744267032
timestamp: 1691236898193 offset: 744267036
timestamp: 1691236899167 offset: 744267040
timestamp: 1691236899752 offset: 744267044
timestamp: 1691236900204 offset: 744267048
现在你应该会发现,时间戳和 Offset 也不是连续的。时间戳不连续是合理的,因为可能有的时间没有数据。但是 Offset 理论上应该是连续的,不连续的原因和其实上面一样,主要是为了节省空间引入了跳跃表的实现。
基于上面的设计,我们来看一个示例。假设我们需要根据时间戳来找到某条数据实,流程就是:
- 通过二分算法查找到最近的前一个时间戳,获取到它对应的 Offset,时间复杂度为 O(logn)。
- 根据这个 Offset 去读取文件,遍历后续的数据找到大于等于这个时间戳的的数据,读取数据。
根据消息 ID 查询数据
按照上面的思路,我们应该通过构建消息 ID 和 Offset 组成的二元索引来完成查询需求,索引的格式可以是下面这样子。即根据消息 ID 找到对应的 Offset,然后再根据 Offset 找出消息内容。
msgID:dfangjfjhs offset:10
msgID:mbvnjdlfjd offset:21
msgID:otidfkjifd offset:33
msgID:ddnbklfdid offset:40
从技术上来看,根据消息 ID 查询数据有简单实现和复杂实现两种方案。
简单方案
简单实现的本质是,结合消息队列本身底层顺序存储的特征而设计的一种取巧的方法。
- 客户端通过 SnowFlake 算法生成唯一的消息 ID。
- 查询的时候根据消息 ID 反解析出消息 ID 对应的时间戳,因为 SnowFlake 算法中有一部分数据是时间戳。
- 结合这个时间戳去搜索消息。
这个方案的好处是,几乎不需要开发工作量,流程简单通用。缺点是可能会误判,即消息明明存在,但是却搜索不出来。因为消息 ID 在客户端生成,SnowFlake 算法的时间戳也是客户端的时间,所以在一些异常或延时消息的场景中,数据写入 Topic 或分区的时间和客户端发送出来的时间相差很大,从而导致根据 SnowFlake 解析出的客户端时间无法查询到消息。
复杂方案
复杂方案则是是基于哈希表、B+ 树、红黑树等数据结构来构建消息 ID 和 Offset 的索引,同时保证在索引元素添加和获取的时候的时间复杂度较低,从而满足查询需求。因为根据消息 ID 查询消息的需求是很固定的,所以我会建议你使用哈希表来构建索引,因为哈希索引结构能够实现高效的消息查询。
业界主流消息队列 RocketMQ 就是基于哈希表来构建消息 ID 和 Offset 的索引的。我们简单来看一下底层的实现原理,大概分为以下 4 点:
- RocketMQ 的索引存储在 IndexFile(索引文件)中,通过使用哈希索引结构来构建索引。
- 在 IndexFile 中,消息 ID 被哈希成一个固定长度的 Key。这个 Key 通过哈希函数映射到一个哈希槽(Slot)上。哈希槽里存储的是该 Key 对应消息在 CommitLog 中的物理偏移量。
- RocketMQ 使用开放寻址法(Open Addressing)来解决哈希冲突问题。当不同的 Key 映射到相同的哈希槽时,会根据预设的步长(step)逐个检查其他槽位,直到找到一个空闲槽位。
- 同时哈希索引结构为每个 Key 维护一个链表,用于将 Key 映射到多个物理偏移量(例如当一个消息发送到多个队列时)。 这种哈希索引结构使得 RocketMQ 在查询消息时能够通过 Key 快速定位到对应的哈希槽,再根据物理偏移量找到实际消息,从而提高查询效率。
借助第三方工具实现复杂查询
第三方引擎支持查询
将 Kafka 的数据导入到下游引擎,依赖引擎的能力来实现复杂的数据查询,比如 Kafka + Hive、Kafka + Elasticsearch、Kafka + Trino(以前的 Presto SQL)。
工具化简单查询
工具化简单查询是指我们自定义编码去消费数据,然后在代码里面加过滤条件,从而实现查询。

这个方案直观看上去,存在性能低、时间复杂度高、不灵活等严重缺点,但在实际场景中它是非常实用的。例如,我们在出问题的时候,偶尔需要根据消息内容或者消息 Key 模糊查询数据是否在集群中。这个需求非常常见,但是使用频率低。
Schema:如何设计实现Schema模块?
Schema 是什么
消费者和生产者需要线下对齐数据格式,然后消费者根据约定的消息格式编写相应的处理逻辑。当生产端的数据格式或者某个字段的数据类型发生变化时,如果没有及时通知下游消费者,消费者就会无法解析数据,导致数据消费异常。
Schema 就是用来解决全流程中的数据格式的规范定义问题,即保证上下游数据在传递过程中,消息可以根据指定的格式和定义进行传递。
Ps: 可以通过 MySQL 中表的 Schema,来理解消息队列中的 Schema。它们都是表达这批数据有几个字段、这个字段是什么类型、长度是多长这些信息。
Schema 技术方案设计

在当前消息队列架构的基础上,我们引入了一个新的组件:Schema Register,即 Schema 注册中心。SchemaRegister 的作用是持久化保存具体的 Schema 信息,并提供接口给客户端增删改查 Scheme 信息。
在消息全生命周期中,Scheme 的使用可以拆解为五个步骤。
- 生产者或消费者可以自动调用 SchemaRegister 创建 Schema 信息,也可以通过运营端增加 Schema 的信息。
- 一旦开启了 Schema,生产者、消费者初始化时需要配置 SchemaRegister 的访问地址。启动的时候,从 SchemaRegister 获取所需的 Schema 信息,并缓存起来。
- 生产者启动时会配置好本次需要发送的数据的 Schema。此时 SDK 会根据客户端配置的 Schema 信息判断这个 Schema 是否存在。如果存在就正常发送,如果不存在则判断集群是否允许自动注册 Schema。如果允许自动注册,则调用 SchemaRegister 提供的 CreateSchema 接口进行注册。SchemaRegister 会为每个 Schema 分配唯一的 ID,生产者会将这个 ID 写入到消息的属性中。
- Broker 启动时会从 Schema 注册中心获取全量的 Schema 信息,缓存到本地。当接收到消息数据后,拿出消息中的 SchemaID,获取到具体的 Schema 信息,然后使用这个 Schema 信息对数据进行校验。
- 消费端启动时也会加载 Schema 信息,获取到数据后,根据消息 ID 及其对应的 Schema 去解析、处理数据。如果不符合格式的数据,就丢弃或者报错。
Schema Register
Schema Register 本质上是一个 Server,由计算逻辑层和存储层两部分组成。计算逻辑层负责提供增删改查的接口支持对 Schema 信息的操作,持久层负责分布式、持久化存储 Schema 信息。

从技术上看,Schema Register 有独立部署和 Broker 内核集成两种实现形态。
- 独立部署是指 Schema Register 独立成一个 Server 进行部署,比如它可以是一个 HTTP Server,通过 MySQL 存储 Schema 信息,暴露 Restful 接口提供服务。但是一般会把数据存储在消息队列的 Topic,因为 Topic 也是分布式的可靠存储,从而避免引入 MySQL。
- Broker 内核集成是指在 Broker 内核实现 Schema Register。如下图所示,即在 Broker 上提供四层或七层的接口来满足 Schema 信息的增删改查等操作,同时集群内部创建一个内部 Topic 来保存 Schema 信息。
Schema 格式设计
因为 Schema 是和具体的消息队列集群绑定的,所以 Schema 信息应该包含集群信息。进一步,如果有租户的概念,那么 Schema 信息也需要包含租户的信息。从技术上看,Schema 都是和 Topic 进行绑定的,即表示当前这个 Topic 允许接收什么格式的数据。所以,Schema 信息也需要包含 Topic 信息。
除了这些基础信息,最关键的是要标识这个消息数据的格式。
{
"id":"kjdsjfudfd",
"version":1,
"cluster":"cluster1",
"tenant":"tenant1",
"topic":"topic1",
"name": "schema1",
"properties": [
{
"name":"name",
"type":"string",
"maxLength":100
},
{
"name":"region",
"type":"string",
"maxLength":40
}
]
}
Schema 一般是跟 Topic 绑定的,所以拉长时间周期来看,Topic 的 Schema 肯定变更。可能是从一个 Schema 换成了另外一个 Schema,或者在当前的基础上添加、删除字段,修改字段类型等等。

那么当生产者发送消息时,每条消息就需要携带所属的 SchemaID 和 Version 标记。此时:
- 当 Broker 收到数据,会根据 SchemaID 和 Version 去找到对应的 Schema 详情,进行数据校验。
- 当消费端收到数据时,会根据 SchemaID 和 Version 去找到对应的 Schema 详情,进行数据解析处理。
所以,在消息的协议结构中,就需要增加 SchemaID 和 SchemaVersion 两个字段。
服务端集成 Schema
从 Broker 的角度来看,它对 Schema 的支持主要分为以下四个部分:
- 添加 Schema Register 相关配置,比如 Schema Register 的地址。
- 启动时从 Schema Register 加载本集群的 Schema 信息,缓存在本地。
- 判断是否开启 Schema,或者在什么维度(比如集群维度、租户维度、Topic 维度)开启 Schema。
- 接收到数据时,从消息中解析出 SchemaID,根据 ID 找到对应的 Schema 对数据进行校验。
客户端集成 Schema
在生产端,集成 Schema 后的主要流程如下:
- 生产端加上 Schema Register 相关配置。
- 生产端启动时,从 Schema Register 加载相关的 Schema 信息,比如本次发送的集群、Topic 等。
- 定义好要发送的数据格式,并构建数据。
4.在发送服务端之前,SDK 会根据客户端配置的 Schema 信息判断这个 Schema 是否存在。如果存在就正常发送,如果不存在则判断集群是否允许自动注册 Schema。如果允许自动注册,则调用 SchemaRegister 提供的 CreateSchema 接口进行注册。SchemaRegister 会为每个 Schema 分配唯一的 ID,生产者会将这个 ID 写入到消息的属性中。
消费端集成 Schema 的流程和生产端基本类似,具体如下:
- 消费端加上 Schema Register 相关配置。
- 消费端启动时,从 Schema Register 加载相关的 Schema 信息,比如本次消费的集群、Topic 等。
- 同时也会把消费端设置的 Schema 和 Topic 与实际的 Schema 进行比对,然后判断是否使用还是自动注册这个 Schema,流程和生产的第四步是一样的。
- 拿到数据,先判断是否携带 SchemaID,然后判断是否是有效的 Schema,再解析处理。
序列化和反序列化
消息内容数据是以什么格式发送的呢?消息内容是以什么格式序列化和反序列化后发送呢?这里一定要约定好使用的格式,否则下游就不知道如何解析数据了。
在消息队列中,编解码一般是在生产端和消费端配置的
WebSocket:如何在消息队列内核中支持WebSocket?
WebSocket 是什么
WebSocket 是一种基于 TCP 传输协议的应用层协议,它设计的初衷是解决 Web 应用程序中的实时双向通信问题。它跟 HTTP 协议一样,也是一种标准的公有协议。所以它也有协议头、协议体、数据帧格式、建立连接、维持连接、数据交换等等各个细节。
只要记住一个重点:WebSocket 是一个可以在浏览器中使用的支持双向通信的应用层协议,就可以了。
双工(双向)通信
- 单工通信指的是数据只能在一个方向上传输,而不能在另一个方向上传输。例如,广播电台只能向接收者发送信息,接收者无法向电台发送信息,这是单工通信的一种。
- 双工通信指的是数据可以在两个方向上传输。例如,电话通信就是双工通信的一种,通话双方可以同时说话和倾听对方的声音。
如下图所示,在计算机网络中,HTTP 是一种单向通信协议,即浏览器请求服务器上的信息并从服务器接收响应,但服务器不能主动向浏览器发送信息。
而 TCP/IP 协议则是一种双向通信协议,数据可以在客户端和服务器之间相互传输,即客户端可以发数据给服务端,服务端也可以发数据给客户端。
特点和应用场景
从某种角度讲,WebSocket 协议可以理解为 HTTP 协议的升级版本,它主要有这样五个特点。
- 持久化连接:WebSocket 建立了一个持久化的 TCP 和 TLS 连接,从而减少了握手过程中的延迟并提高性能。
- 全双工通信:WebSocket 允许客户端和服务器在同一时刻发送和接收消息,实现了全双工通信。
- 低带宽开销:WebSocket 在数据分帧处理方面采用了紧凑的二进制格式,并对附加元数据进行了优化,以实现低带宽开销。
- 与 HTTP 兼容:WebSocket 协议兼容 HTTP 协议,使用与 HTTP 相同的默认端口(80 和 443),能够通过现有的网络基础设施进行传输,并得到大多数现代浏览器的支持。
- 跨域通信:WebSocket 协议允许跨域通信(在配置允许的情况下),使得客户端可以与不同域名上的服务器建立连接。
WebSocket 协议和消息队列
从应用场景来看,消息队列需要的是 WebSocket 协议支持的双工通信的特性。
如果引入 WebSocket 协议,消费者通过 WebSocket 协议和 Broker 建立连接。因为 WebSocket 协议是双向通信的,所以 Broker 就可以直接将数据推送给消费者,而不需要在客户端实现一个 Server。因此开发工作量就降低特别多。
长连接和双向通信是 WebSocket 实现高度实时性和低延迟的技术核心,也是消息队列需要支持 WebSocket 协议的重要原因。
内核中支持 WebSocket 协议
支持多协议一般有内核支持和 Proxy 模式两种形态。因为实现方式基本差不多,下面我们就重点看一下如何在消息队列的内核中支持 WebSocket 协议。
从技术拆解来看,在内核中支持 WebSocket 协议,主要分为以下四部分工作:
- 确定在 WebSocket 上支持哪些功能,比如生产、消费。
- 设计生产、消费等功能的请求和返回协议。
- 在内核中支持 WebSocket Server。
- Broker 通过 WebSocket 协议推送数据。
支持功能
消息队列数据流的操作主要是生产和消费,所以在 WebSocket 协议上主要也是支持生产、消费等操作。
生产消费协议设计
WebSocket 兼容 HTTP。可以简单理解成,WebSocket 是基于 HTTP 的。所以从使用的角度,如下所示,WebSocket 协议包含 URI 和 Body 两个部分。
URI:
wss://mqserver.com/send/ns1/tp1
body:
{
"key":"k1",
"value": "v1",
"properties":"{"p1":1,"p2":2}"
}
在上面的示例中,/send/ns1/tp1 表示发送数据到租户 ns1 中的 Topic tp1,body 是 JSON 格式的数据,包含 key、value、properties 三个字段,分别表示消息的 key、消息的 value、消息的属性。
接下来看一下返回值,示例如下:
// 请求成功
{
"result": "ok",
"messageID": "CAAQAw=="
}
// 请求失败
{
"result": "send-error:3",
"errorMsg": "Failed to de-serialize from JSON"
}
这个返回值就是一个普通的 JSON 格式的返回值。result 表示请求结果,messageID 表示这条消息的 ID,errorMsg 表示错误信息。
支持 WebSocket Server
在内核中支持 WebSocket Server 并不复杂,因为各个语言都有对应的库来实现。下面我们通过 Netty 来实现一个 WebSocket Server,举例说明一下如何在 Broker 内支持 WebSocket,代码示例如下:
public static void StartWebServer() throws InterruptedException {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new HttpServerCodec()); // HTTP 协议解析,用于握手阶段
pipeline.addLast(new HttpObjectAggregator(65536)); // HTTP 协议解析,用于握手阶段
pipeline.addLast(new WebSocketServerCompressionHandler()); // WebSocket 数据压缩扩展
3
}
});
ChannelFuture f = b.bind(80).sync();
f.channel().closeFuture().sync();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
class MyWebSocketServerHandler extends SimpleChannelInboundHandler<WebSocketFrame> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, WebSocketFrame frame) throws Exception {
if (frame instanceof TextWebSocketFrame) {
String request = ((TextWebSocketFrame) frame).text();
ctx.channel().writeAndFlush(new TextWebSocketFrame("receive: " + request));
}
}
}
要需要关注的是 pipeline.addLast 和 writeAndFlush 两部分代码。addLast 主要用来做协议相关的解析,writeAndFlush 是给客户端返回数据的,它是双工通信的重要环节.只要往 Channel 回写数据,此时客户端就可以收到数据,从而实现主动推送消息给客户端。
主动消息推送
当数据写入到 Broker 中的 Topic tp1 时,因为 WebSocket 是双向通信的,所以 Broker 收到消息后,可以直接将消息推送给客户端。这个推送的逻辑一般是在内核中维护异步线程去回写数据到客户端实现的。
目前业界主流消息队列只有 Pulsar 和 RabbitMQ 支持了 WebSocket 协议。从技术上看,两者的实现思路基本一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号