EWCMF ERA5 小时尺度数据 Python API Windows 多线程下载教程(.grib)
ERA5 hourly data on single levels from 1940 to present -- Python API Download
1. ERA5下载网址-注册ECMWF账号-登录



注意:记得勾选权限,不然可能会导致 API request 连接不成功。
在ERA5网站中个人主页“Your profile”-“Licences”-“Dataset licences”-“Licence to use Copernicus Products”权限打勾,即可。


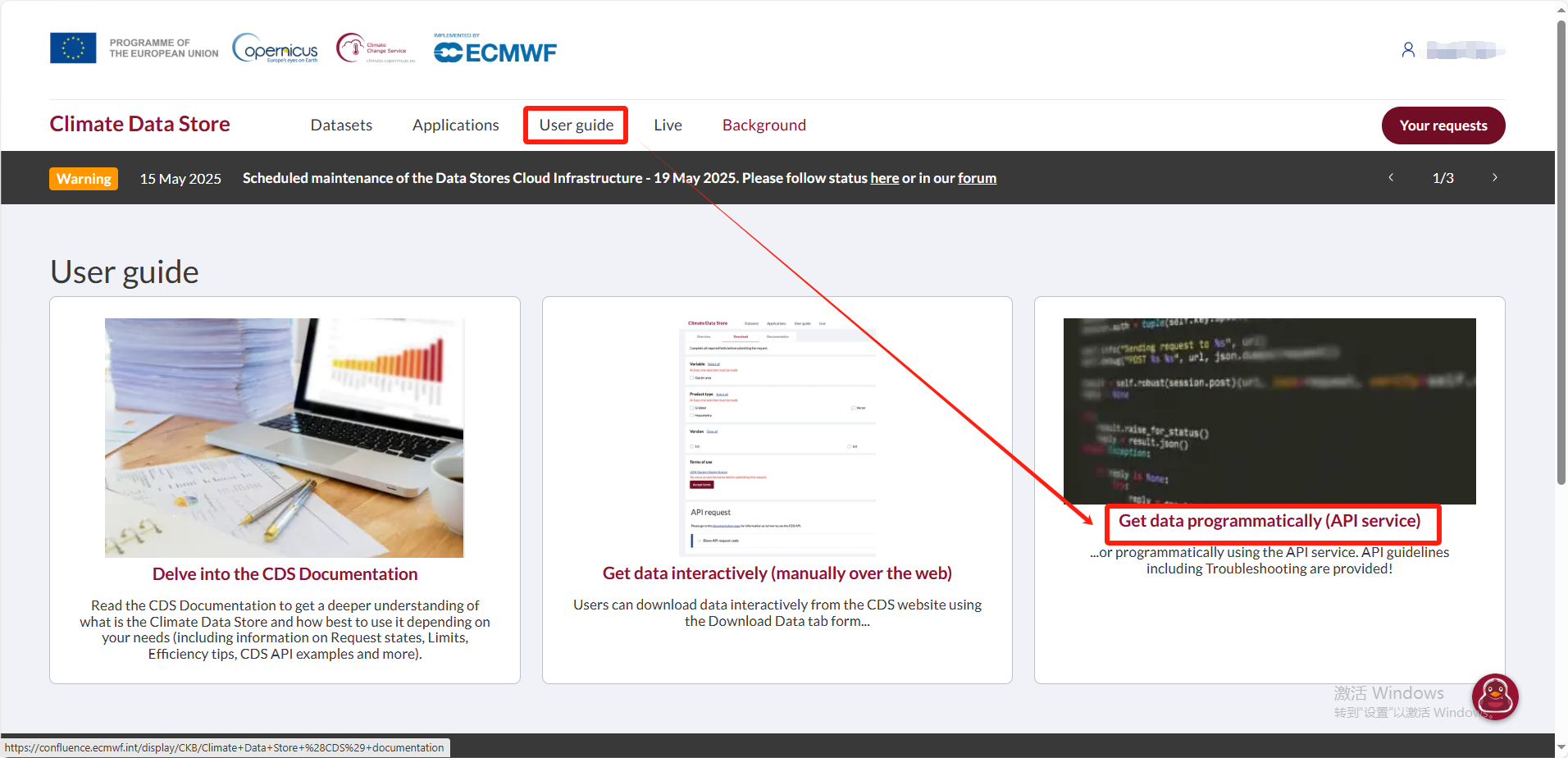
2. 找到密钥
“User guide"-"Get data programmatically (API service)",点开下滑找到自己的“url”和“key”,复制保存代码。
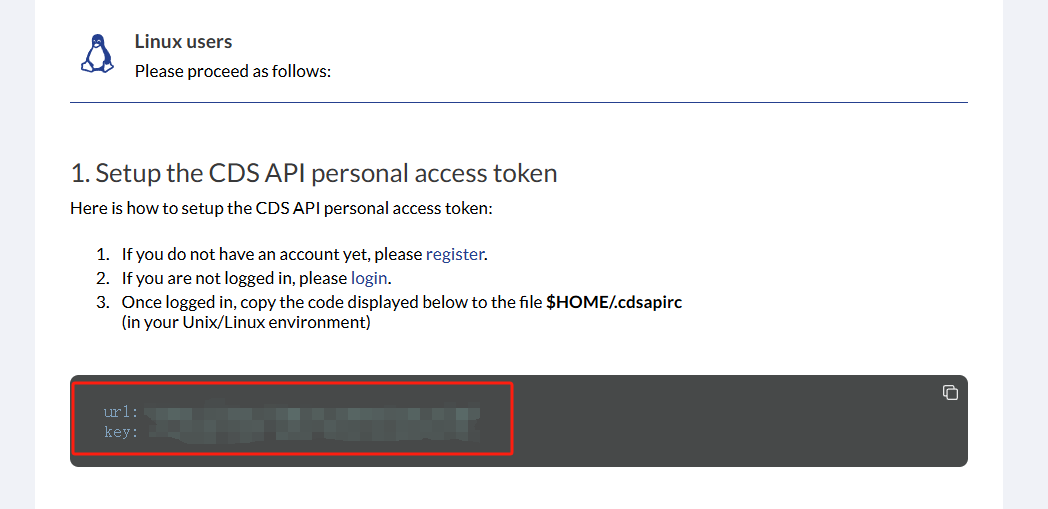
3. 配置 .cdsapirc文件
在 ‘C:\Users\用户名’ 路径下新建文本文档,将步骤2中的两行文字复制进新建的文本文档,保存退出后,将文档重命名为 .cdsapirc。

4. 准备Python运行环境
在 cmd 或 Vscode 或 Pycharm 中安装 cdsapi 库(必要):
pip3 install cdsapi # for Python 3 或尝试 pip3 install --user cdsapi # for Python 3
其他库可根据代码自行添加。
5. 自选指标得到 API request

6. 并行下载
将得到的API request 代码带入如下并行下载脚本(下载变量、保存路径、时间等需要自行修改)
import os import time import datetime from queue import Queue from threading import Thread, Lock import cdsapi import logging from tqdm import tqdm # 配置参数(按需更改) VARS = ['total_precipitation'] BASE_DIR = "F:/O/Data/era5/" MIN_FILE_SIZE = 10 * 1024 * 1024 # 10MB MAX_RETRIES = 5 REQUEST_TIMEOUT = 600 # 10分钟超时 MAX_WORKERS = 2 # 降低并发数以符合CDS API限制 # 配置日志 logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('era5_download.log'), logging.StreamHandler() ] ) # 文件锁避免并发写入冲突 file_lock = Lock() def ensure_dir(var): """确保目录存在""" path = os.path.join(BASE_DIR, var) os.makedirs(path, exist_ok=True) return path def download_one_file(var, riqi): """带重试机制的安全下载函数""" filename = os.path.join(ensure_dir(var), f"era5.{var}.{riqi}.grib") # 检查文件是否已完整存在 if os.path.exists(filename) and os.path.getsize(filename) >= MIN_FILE_SIZE: logging.info(f"File exists: {filename}") return True for attempt in range(MAX_RETRIES): try: # 创建临时文件 temp_file = f"{filename}.tmp" c = cdsapi.Client(timeout=REQUEST_TIMEOUT) # 按需更改 c.retrieve( 'reanalysis-era5-single-levels', { 'product_type': 'reanalysis', 'variable': var, 'year': riqi[0:4], 'month': riqi[-2:], "day": [ "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31" ], 'time': [ f"{h:02d}:00" for h in range(24) ], "format": "grib" }, temp_file ) # 验证文件完整性 if os.path.getsize(temp_file) >= MIN_FILE_SIZE: with file_lock: os.replace(temp_file, filename) logging.info(f"Download succeeded: {filename}") return True else: os.remove(temp_file) raise ValueError("Downloaded file is too small") except Exception as e: logging.warning(f"Attempt {attempt + 1} failed for {filename}: {str(e)[:200]}") time.sleep(2 ** attempt) # 指数退避 if os.path.exists(temp_file): os.remove(temp_file) logging.error(f"Max retries exceeded for {filename}") return False class DownloadWorker(Thread): def __init__(self, queue): Thread.__init__(self) self.queue = queue def run(self): while True: var, riqi = self.queue.get() try: download_one_file(var, riqi) except Exception as e: logging.error(f"Error processing {var} {riqi}: {str(e)[:200]}") finally: self.queue.task_done() def generate_dates(start_date, end_date): """生成日期序列""" dates = [] d = start_date delta = datetime.timedelta(days=1) while d <= end_date: dates.append(d.strftime("%Y%m")) d += delta return sorted(list(set(dates))) # 去重并排序 def main(): start_time = time.time() # 日期范围 start_date = datetime.date(2024, 1, 1) end_date = datetime.date(2024, 12, 31) date_list = generate_dates(start_date, end_date) # 创建任务队列 queue = Queue() # 填充队列 for var in VARS: for riqi in date_list: queue.put((var, riqi)) # 创建工作线程 for _ in range(MAX_WORKERS): worker = DownloadWorker(queue) worker.daemon = True worker.start() # 进度监控 with tqdm(total=len(VARS)*len(date_list), desc="Download Progress") as pbar: while not queue.empty(): pbar.n = len(VARS)*len(date_list) - queue.qsize() pbar.refresh() time.sleep(1) queue.join() logging.info(f"Total time: {(time.time() - start_time)/60:.1f} minutes") if __name__ == '__main__': main()
下载请求进程可以在官网上看到
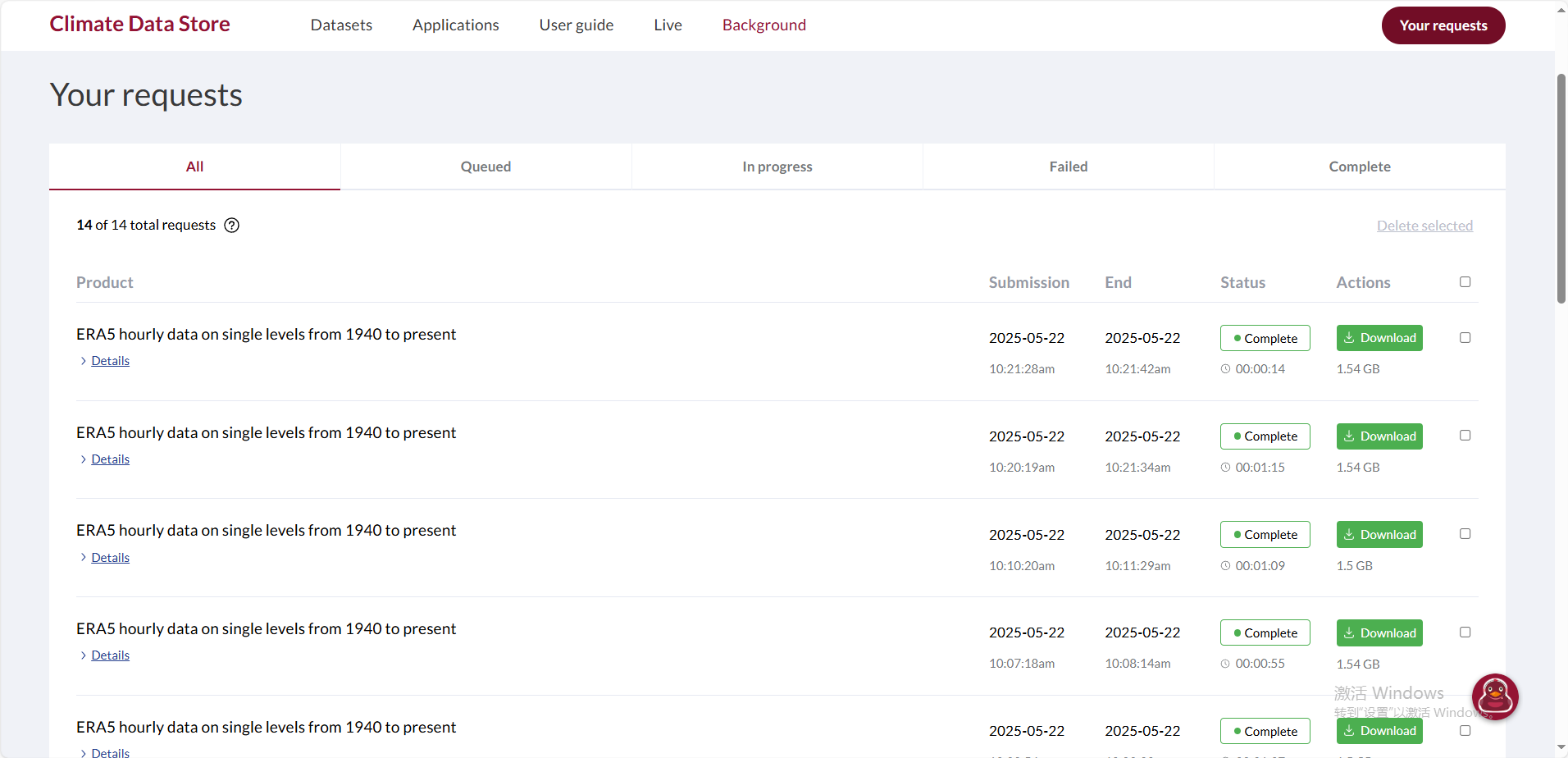
注意: 如果代码报错,没有在官网上看到下载请求进程,则可能是 .cdsapirc文件内容有问题,可以尝试将“url"和"key"冒号后的空格删除,即可。
7. 下载成功界面(部分)

另外,nc文件下载同理,但是nc文件会更大,且下载时间会更长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号