总结:
A、recall=sensitivity=TPR,即召回率=灵敏度=真正例率
B、FPR=1-specify,即假阳性率(误诊率)=1-特异度
C、PR曲线的横坐标为ROC曲线的纵坐标
D、正负例样本比例变化较大的情况下,PR曲线受影响较大,ROC曲线相对鲁棒,所以,ROC曲线能降低不同测试集带来的干扰,客观衡量模型性能;但关注模型在不均衡数据集下的结果时,PR曲线则能较好反应指标情况。
E、AP是PR曲线下面积,各个数据集计算AP方式有区别
F、IOU与DICE可以互推:IOU=DICE/(2-DICE)
详细内容介绍如下:
1.混淆矩阵
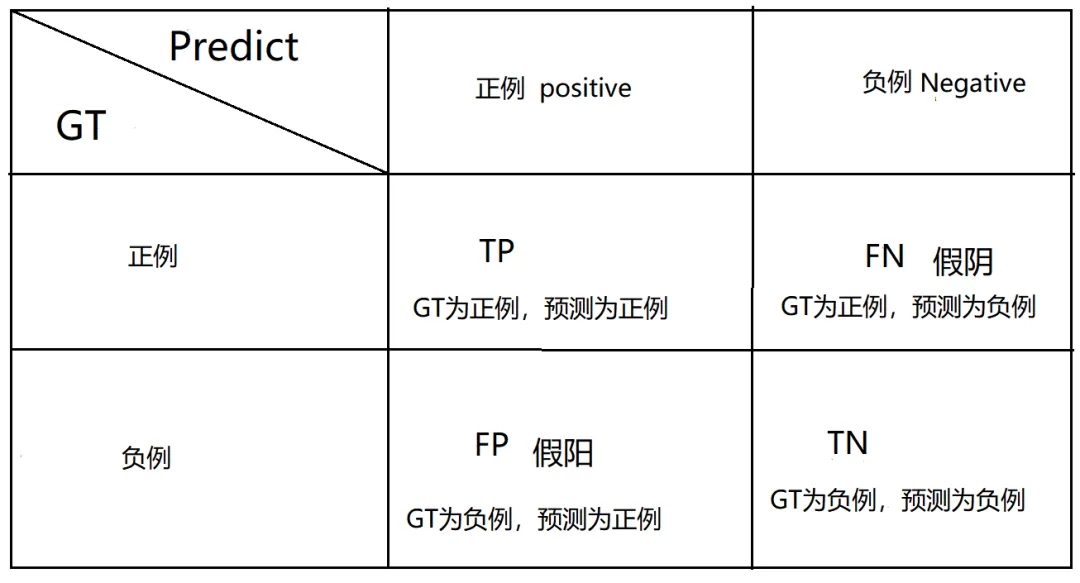
行索引为GT,列索引为预测
TP(True Positive):实际为正例,预测为正例的数量
TN(True Negative):实际为负例,预测为负例的数量
FP(False Positive):实际为负例,预测为正例的数量
FN(False Negative):实际为正例,预测为负例的数量
a.T和F代表预测是否正确(T代表预测正确,F代表预测错误)
b.P和N则代表预测的结果,P代表预测为正例,N代表预测为负例
c.T/F与P/N相结合起来,就是最终的GT,例如TP代表GT为正例,FP代表GT为负例。
d.正例和负例是人为确定的,一般设定关注的类别为正例
e.设定当前类为正例后,其余类均为负例
2.分类指标总结
Accuracy(准确率):预测对的数量占整体数量的比例
acc=(TP+TN)/(TP+TN+FP+FN)
Recall(召回率/查全率/检出率):预测对的正例的数量占整体正例的比例,即正例的检出比例(正例比较重要时,容易关注这个指标,比如希望查出所有患癌症的病人)
recall=TP/(TP+FN)
Precision(精确率/查准率):预测对的正例的数量占所有预测为正例的数量的比例,用于衡量预测的准不准
precision=TP/(TP+FP)
F1-Score:是precision和recall的调和平均数,例如,模型A的recall高,precision低,模型B相反,那怎么综合比较模型A和B的性能呢,用这个
F1-Score=2*(Precision*Recall)/(Precision+Recall)
Sensitivity(灵敏度):正例的召回率(或检出率)
sensitivity=TP/(TP+FN)=Recall
Specify(特异度):负例的召回率(或检出率)
specify=TN/(TN+FP)
PPV(Positive Predictive Value):阳性预测值,等同于精确率,预测为正例的人中,真的正例所占比例。
PPV=TP/(TP+FP)=precision
NPV(Negative predictive value):阴性预测值,预测为负例的人中,真的负例所占比例,等同于负例的精确率
NPV=TN/(TN+FN)
TPR(True Positive rate):真正例率,等同于正例的召回或灵敏度
TPR=TP/(TP+FN)=recall=sensitivity
FPR(False Positive Rate):假正例率,即误诊率(没病检测出有病是误诊,有病检测出没病是漏诊),没病检测出有病占整体没病人数的比例。
FPR=FP/(FP+TN)=1-specify (参考混淆矩阵)
FNR(False Negative Rate):假阴性率,即漏诊率,有病检测出没病占真正有病的比例:
FNR=FN/(TP+FN)=1-sensitivity=1-recall
ROC曲线
按照模型输出的正例预测概率排序,顺序为从高到低,之后将每个概率值作为阈值,得到多个混淆矩阵,对应多对TPR和FPR,将FPR的值作为X轴的值,TPR的值作为Y轴的值,以此作图,图中的点连成的曲线就是ROC曲线,体现的是随着检出率的增加,误诊率的增加情况,好模型的ROC曲线应该随着阈值变化,检出率持续增加,而误诊率几乎保持恒定为零,如下图。

AUC(area under curve):ROC曲线下的面积,认为曲线面积越大,模型效果越好(只凭ROC曲线难以判断具体哪个模型好)。AUC的特点是不会受正负样本比例的影响。
PR曲线:是recall和precision点所连成的曲线,recall的值为x轴,precision的值为y轴。由于TPR=recall,所以PR曲线的横坐标为ROC曲线的纵坐标,正负例样本比例变化较大的情况下,PR曲线受影响较大,ROC曲线相对鲁棒。
所以,在正负例样本不均衡情况下,ROC曲线更能客观衡量模型性能,降低不同测试集的干扰;如果就想看模型在不均衡数据集下的结果,PR曲线则能较好反应指标情况。
2. 目标检测指标总结
介绍指标之前先介绍一下什么是IOU(后面会用到):
IOU(Intersection over Union):交并比,取值范围为[0,1]

IOU=|GT∩Predict|/|GT∪Predict|
=intersection/(GT+Predict-intersection)
目标检测的输出有:预测目标的位置坐标(bbox)、分类(classification)和置信度(confidence)
TP,FP,FN定义如下:
TP:iou>0.5,一个GT计算一次,即使多个预测框满足条件;
FP:iou<=0.5,或在一个GT上多出来的iou>0.5检测框;
FN:没有检测出来的GT;
既然有TP、FP、FN,那么分类任务的指标在这里也是可以用的,除此之外,再介绍一下仅适用于目标检测任务的指标AP和mAP:
AP(average precision):平均精确率,是PR曲线下的面积。
对某一类别预测框的置信度进行排序,从大到小,以每个置信度为阈值,计算precision和recall,将点连成线,连线的每个峰值均向x轴和y轴做垂线(重复区域合并),这些曲线所包含的面积就是这个类别对应的AP(每个类别均有AP)
mAP(mean average precision):对各个类别的AP取平均,即 MAP = 各类别的AP求和/类别数量
实际上,不同数据集对AP的计算方式不同,介绍如下:
PASCAL Voc 2008的AP计算:
(1)IOU阈值为0.5
(2)一个GT只有一个正例,冗余检测框为负例
(3)在平滑之后的pr曲线上进行计算,即将横轴均分十段(recall=0也是一个点,共11个点),AP为每个点对应的presion值的平均值(先求11个点的precision值的和,再除以11)
PASCAL Voc 2010之后的AP计算:
依然在平滑值的pr曲线上计算,这次是利用积分计算曲线下的面积,作为AP值
COCO数据集的AP计算:
与VOC 2008分10段不同,COCO采样了100个点,且IOU是从0.5到0.95,每隔0.05取值一次,作为阈值,COCO的AP是已经对不同阈值、不同类别取平均之后的结果,已经相当于mAP了,此外,COCO还有AP50、AP75、APS、APM、APL指标,分别代表:
AP50代表iou阈值为0.5时,各个分类的AP均值
AP75代表iou阈值为0.75时,各个分类的AP均值
APS代表GT面积小于32x32的各分类的AP均值
APM代表GT面积介于32x32到96x96之间的各分类的AP均值
APL代表GT面积大于96x96的各分类的AP均值
3. 语义分割指标总结
由于语义分割是像素级别的分类,所以分类任务的指标也是可以用到语义分割任务上的,此处再介绍两个语义分割任务的常用指标IOU和DICE.
IOU:计算方式上文已有提及,与目标检测计算两个矩形框的交并比不同,语义分割的iou计算的是像素级别的交并比。
DICE(dice similarity coefficient)公式:
DICE = 2|GT∩Predict| / (|GT|+|Predict|)
此外:
IOU与DICE可以互推:
IOU=DICE/(2-DICE)
参考文献
PR与F1-score的关系参考:https://www.cnblogs.com/dataanaly/p/12924002.html
AP绘制参考:https://blog.csdn.net/wzk4869/article/details/130778741
不同数据集的AP计算参考:https://zhuanlan.zhihu.com/p/360539304


 浙公网安备 33010602011771号
浙公网安备 33010602011771号