论文解读《Cross-Domain Few-Shot Graph Classification》
论文信息
论文标题:Cross-Domain Few-Shot Graph Classification
论文作者:Kaveh Hassani
论文来源:AAAI 2023
论文地址:download
论文代码:download
1 Introduction
2 Method
框架:
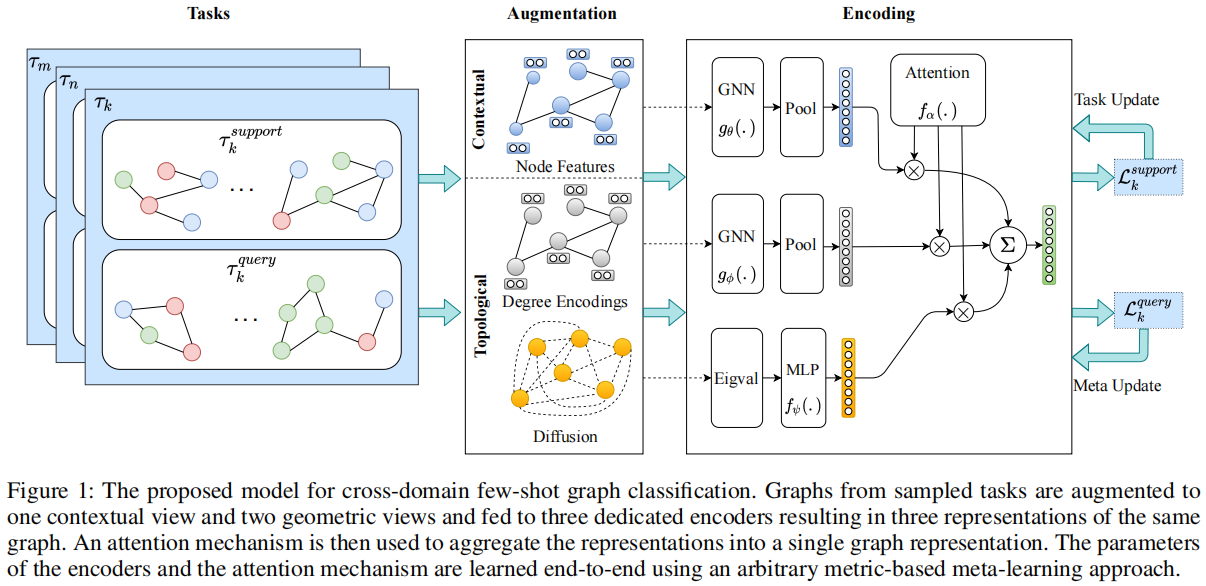
2.1 Augmentations
图上自监督学习的研究表明,对比图增强允许编码器学习丰富的节点、图表示。
Contextual view
- Heterogeneous feature augmentation where the initial feature and its projection by a linear layer are concatenated and padded to a predefined dimension.
- Deep set approach in which we considered the initial node feature space as a set, projecting each dimension independently to a new space using a linear layer, and aggregating them by a permutation-invariant function. This augmentation can capture the shared information across tasks with overlapping features when the alignment among the features is not available.
- Simple padding of the features to a predetermined dimension. Surprisingly, we observed that the simplest augmentation achieves better results. We speculate this is because the tasks are not sharing overlapping features.
- In the feature-space augmentation, we replace the task-dependent node features with sinusoidal node degree encodings which allow the model to extrapolate to node degrees greater than the ones encountered during meta-training stage. Because node degrees are universal properties of graph nodes, encoding a graph with such initial features will capture task-agnostic geometric structure of the graph. We also use graph sub-sampling to keep the degree distribution in a similar order of magnitude across domains.
- For the structurespace augmentation, we compute graph diffusion to provide a global view of the graph’s structure. We used Personalized PageRank (PPR) , a specific instantiation of the generalized graph diffusion. We compute the eigenvalues of the diffusion matrix, sort them in a descending order, and select the top-k eigenvalues as the structural representation. We also experimented heat kernel diffusion, eigen values of normalized graph Laplacian, and shortest path matrix, and found that diffusion produced better results.
2.2 Encoders
Assume a support set $D_{i}^{\text {sup }}=\left[g_{1}, g_{2}, \ldots, g_{N}\right]$ of $N$ graphs belonging to a randomly sampled task $i$ . Augmenting each graph $g$ produces three views: a contextual view represented as graph $g_{c}=(\mathbf{A}, \mathbf{X})$ where $\mathbf{A} \in\{0,1\}^{n \times n}$ and $\mathbf{X} \in \mathbb{R}^{n \times d_{x}}$ denote the adjacency matrix and the task-specific node features, a topological view represented as graph $g_{g}=(\mathbf{A}, \mathbf{U})$ where $\mathbf{U} \in \mathbb{R}^{n \times d_{u}}$ denotes sinusoidal node degree encodings, and another topological view represented as vector $\mathbf{z} \in \mathbb{R}^{d_{z}}$ denoting the sorted eigenvalues of the corresponding diffusion matrix $\mathbf{S} \in \mathbb{R}^{n \times n}$ . Our framework allows various choices of network architecture without any constraints. For encoding graph-structured views, we opted for expressive power and adopted graph isomorphism network (GIN). The $k^{t h}$ layer of our graph encoder consists of a GIN layer followed by a feature-wise transformafion layer (FWT) and a swish activation. FWT layer simulates various feature distributions under different domains: $h_{v}^{(k)}=\gamma^{(k)} \times h_{v}^{(k)}+\beta^{(k)}$ where $\gamma \sim \mathcal{N}\left(1, \operatorname{softplus}\left(\theta_{\gamma}\right)\right)$ and $\beta \sim \mathcal{N}\left(0, \operatorname{softplus}\left(\theta_{\beta}\right)\right)$ . $\theta_{\gamma}, \theta_{\beta}$ are the standard deviations of the Gaussian distributions for sampling the affine transformation parameters.
We use a dedicated graph encoder for each view: $g_{\theta}( . ) : \mathbb{R}^{n \times d_{x}} \times \mathbb{R}^{n \times n} \longmapsto \mathbb{R}^{n \times d_{h}}$ and $ g_{\phi}():. \mathbb{R}^{n \times d_{u}} \times \mathbb{R}^{n \times n} \longmapsto \mathbb{R}^{n \times d_{h}}$ resulting in two sets of node representations $\mathbf{H}^{x} , \mathbf{H}^{u} \in \mathbb{R}^{n \times d_{h}}$ corresponding to the contextual and the topological views of the sampled graph. For each view, we aggregate the node representations into a graph representation using a pooling (readout) function $ \mathcal{R}():. \mathbb{R}^{n \times d_{h}} \longmapsto \mathbb{R}^{d_{h}}$ . We experimented with global soft attention pooling, jumping knowledge network, and summation and mean pooling layers, and found that they produce similar results. Therefore, we opted for simplicity and used a simple mean pooling layer. This results in two graph representations: $ \mathbf{h}^{x}, \mathbf{h}^{u} \in \mathbb{R}^{d_{h}}$ . We also feed the topological view from the eigenvalues of the graph diffusion into a projection head $ f_{\psi}():. \mathbb{R}^{d_{z}} \longmapsto \mathbb{R}^{d_{h}}$, modeled as an MLP resulting in the third representation: $ \mathbf{h}^{z} \in \mathbb{R}^{d_{h}}$ .
To aggregate the learned representations, we feed the concatenation of the learned representations into an attention module $f_{\omega}():. \mathbb{R}^{3 \times d_{h}} \longmapsto \mathbb{R}^{3}$ that generates attention scores for each representation. The attention module is modeled as a single-layer MLP followed by a softmax function:
$\alpha=\operatorname{Softmax}\left(\operatorname{ReLU}\left(\left[\mathbf{h}^{x}\left\|\mathbf{h}^{u}\right\| \mathbf{h}^{z}\right] \mathbf{W}_{\mathbf{1}}\right) \mathbf{W}_{\mathbf{2}}\right)$
where $\mathbf{W}_{\mathbf{1}} \in \mathbb{R}^{\left(3 \times h_{d}\right) \times h_{d}}$ and $\mathbf{W}_{\mathbf{2}} \in \mathbb{R}^{h_{d} \times 3}$ are network parameters. The attention scores are then used to aggregate the learned features into a final graph representation.
The attention mechanism gates the representations and decides if the model should rely more on contextual or topological representations. If the samples are from a task that is similar to seen tasks, the model will pay more attention to contextual representation whereas if there is a drastic shift in feature space, the model will rely more on geometric representations. We assume that the target domain is not available during training and hence there is no information in advance about whether there are shared features among tasks. If there is, the attention module will pass the shared contextual information through, otherwise it will not attend to the contextual features and will let the learner to learn them from scratch during the meta-test adaptation phase. Hence, rather than naively throwing the information away and learning from scratch, we let the model decide if it can use the information. It is noteworthy that we are not introducing a new meta-learning framework. Instead we are introducing an encoder with attention module that can seamlessly be integrated into any meta-learning framework. As an example, we show the training procedure of the encoder within a minibatch of tasks using prototypical approach in Algorithm 1. Depending on the metalearner, the aggregated representation can be then fed into a linear classifier or a non-parametric classifier such as a prototypical classifier.

因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17002971.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号