论文解读(RvNN)《Rumor Detection on Twitter with Tree-structured Recursive Neural Networks》
论文信息
论文标题:Rumor Detection on Twitter with Tree-structured Recursive Neural Networks
论文作者:Jing Ma, Wei Gao, Kam-Fai Wong
论文来源:ACL,2018
论文地址:download
论文代码:download
Abstract
本文提出了两种基于自下向上和自上而下的树状结构神经网络的递归神经模型用于谣言表示学习和分类,自然符合推文的传播布局。
1 Introduction
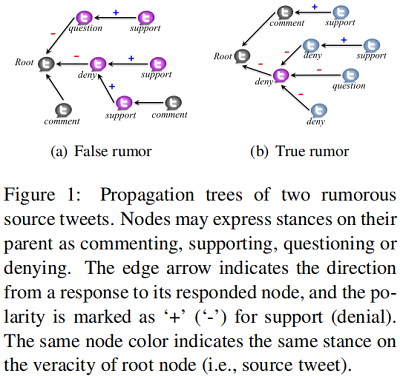
Figure 1 举例说明了两个谣言传播树,一个是假,一个是真。对于结构不敏感的方法,帖子回复通常有支持或者否定的回答,这种方法基本上依赖于文本中不同态度的比例。同时存在一些推文不是直接回复源推文,而是直接对其祖先进行回应,表明交互作用具有明显的局部特征。
本文贡献:
-
- 这是第一个基于树状结构递归神经网络的结构和内容语义,用于检测微博帖子的谣言;
- 提出了两种基于自下而上和自上而下的树状结构的 RvNN 模型的变体,通过捕获结构和纹理属性来为一个声明生成更好的集成表示;
- 基于真实世界的Twitter数据集的实验在谣言分类和早期检测任务上都取得了比最先进的基线更好的改进;
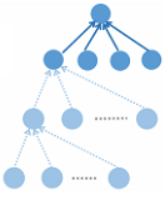
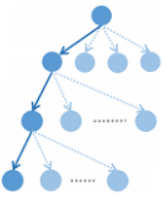
2 RvNN-based Rumor Detection
方法的核心思想是通过对树中不同分支上的传播结构的递归来加强树节点的高级表示。例如,确认或支持一个节点的响应节点(例如,“我同意”,“正确”等)可以进一步加强该节点的立场,而拒绝或质疑回答(例如,“不同意”,真的吗?!)否则就会削弱它的立场。
2.1 Standard Recursive Neural Networks
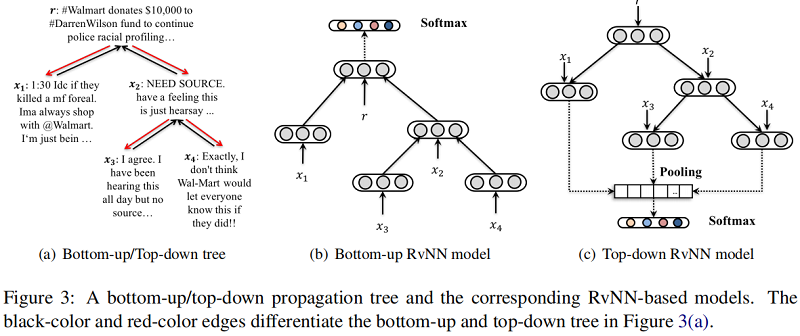
RvNN 是一种树状结构的神经网络。RvNN 的原始版本使用了二值化的句子解析树,其中与解析树的每个节点相关联的表示是从其直接子节点计算出来的。标准 RvNN 的整体结构如 Figure 2 的右侧所示,对应于左侧的输入解析树。
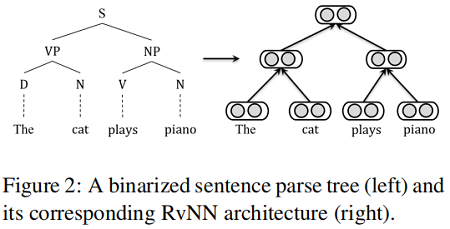
叶节点是一个输入句子中的单词,每个单词都由一个低维的单词嵌入来表示。非叶节点是句子的组成部分,通过基于子节点的表示进行递归计算。假设 $p$ 是用有两个子节点 $c_{1}$ 和 $c_{2}$ 的父节点 特征向量,且可以通过子节点特征向量计算 $p=f\left(W \cdot\left[c_{1} ; c_{2}\right]+b\right)$,其中 $f(\cdot) $ 代表着激活函数。
这个计算是在所有树节点上递归完成的;学习到的节点的隐藏向量可以用于各种分类任务。
2.2 Bottom-up RvNN
自底向上模型的核心思想是通过递归地访问从底部的叶子到顶部的根节点的每个节点,为每个子树生成一个特征向量。通过这种方式,具有类似上下文的子树,例如那些具有拒绝父树和一组支持性子树的子树,将被投影到表示空间中的邻近区域。因此,这些局部谣言指示特征沿着不同的分支聚集成整个树的一些全局表示。
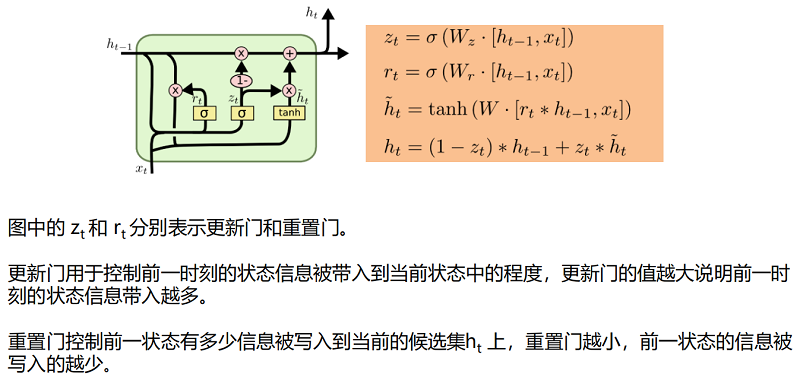
在本文中,选择扩展 GRU 作为隐藏单元来建模树节点上的长距离交互作用,因为它由于参数更少,效率更高。设 $S (j)$ 表示节点 $j$ 的直接子节点的集合。自底向上模型中节点 $j$ 的过渡方程公式如下:
-
- $x_{j}$ 是节点 $j$ 的原始输入向量;
- $E$ 表示参数矩阵转换后输入;
- $\tilde{x}_{j}$ 是 $j$ 的转换后表示;
- $\left[W_{*}, U_{*}\right]$ 是 GRU 内部的权重连接;
- $h_{j}$ 和 $h_{s}$ 分别指 $j$ 的隐藏状态及 $s$ 的隐藏状态;
- $h_{\mathcal{S}}$ 表示 $j$ 的所有孩子的隐藏状态的和;
- 重置门 $r_{j}$ 决定如何将当前输入 $\tilde{x}_{j}$ 与子节点组合;
- 更新门 $z_{j}$ 定义有多少子节点的级联到当前节点;
标准 GRU 回顾:
经过自下到上的递归聚合后,根节点的状态(即源推文)可以看作是用于监督分类的整个树的表示。因此,一个输出层连接到根节点,使用 softmax 函数来预测树的类:
$\hat{y}=\operatorname{Softmax}\left(V h_{0}+b\right) \quad\quad\quad(2)$
其中,$h_{0}$ 为学习到的根节点隐藏向量;
2.3 Top-down RvNN
这种自上而下的方法的想法是为每个帖子的传播路径生成一个增强的特征向量,其中指示谣言的特征沿着路径上的传播历史聚合。言下之意就是当前节点的父节点支持、否定源帖的行为有很大的参考价值。话是这么说,但是公式没有体现出来,只是单纯的聚合消息。
假设节点 $j$ 的隐藏状态为 $h_{j}$,然后,通过将其父节点 $j$ 的隐藏状态 $h_{\mathcal{P}(j)}$ 与其自己的输入向量 $x_{j}$ 相结合,可以计算出节点j的隐藏状态 $h_{j}$ 。因此,节点 $j$ 的转移方程可以表示为一个标准的 GRU:
$\begin{aligned}\tilde{x}_{j} &=x_{j} E \\r_{j} &=\sigma\left(W_{r} \tilde{x}_{j}+U_{r} h_{\mathcal{P}(j)}\right) \\z_{j} &=\sigma\left(W_{z} \tilde{x}_{j}+U_{z} h_{\mathcal{P}(j)}\right) \\\tilde{h}_{j} &=\tanh \left(W_{h} \tilde{x}_{j}+U_{h}\left(h_{\mathcal{P}(j)} \odot r_{j}\right)\right) \\h_{j} &=\left(1-z_{j}\right) \odot h_{\mathcal{P}(j)}+z_{j} \odot \tilde{h}_{j}\end{aligned} \quad\quad\quad(3)$
因此,我们添加了一个最大池化层,以取所有叶节点上向量的每个维度的最大值。这还可以帮助从所有传播路径中捕获最吸引人的指示性特性。
基于池化的结果,我们最终在输出层中使用一个 softmax 函数来预测树的标签:
2.4 Model Training
$L(y, \hat{y})=\sum\limits_{n=1}^{N} \sum\limits _{c=1}^{C}\left(y_{c}-\hat{y}_{c}\right)^{2}+\lambda\|\theta\|_{2}^{2}\quad\quad\quad$
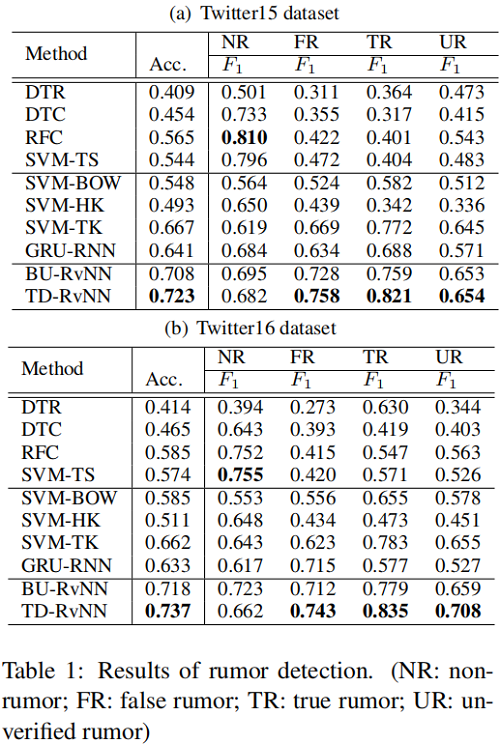
3 Experiments
4 Conclusions
我们提出了一种基于递归神经网络的自下而上和自顶向下的树结构模型,用于推特谣言检测。递归模型的固有特性允许它们使用传播树来指导从推文内容中学习表示,例如嵌入隐藏在结构中的各种指示性信号,以便更好地识别谣言。在两个公开的推特数据集上的结果表明,与最先进的基线相比,我们的方法在非常大的利润范围内提高了谣言检测性能。
在我们未来的工作中,我们计划将其他类型的信息,如用户属性,集成到结构化的神经模型中,以进一步增强表示学习,同时检测谣言散布者。我们还计划通过利用结构信息来使用无监督模型。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16695667.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号