谣言检测——(Bi-GCN)《Rumor Detection on Social Media with Bi-Directional Graph ConvolutionalNetworks》
论文信息
论文标题:Rumor Detection on Social Media with Bi-Directional Graph ConvolutionalNetworks
论文作者:Tian Bian, Xi Xiao, Tingyang Xu, Peilin Zhao, Wenbing Huang, Yu Rong, Junzhou Huang
论文来源:2020,WWW
论文地址:download
论文代码:download
1 Abstract
目前的深度学习方法只考虑了深度传播的模式,而忽略了谣言检测中广泛分散的结构。
在本文中,提出了一种新的双向图模型,即双向图卷积网络(Bi-GCN),通过操作自上而下和自下而上的谣言传播来探索这两个特性。它利用一个具有自顶向下的谣言传播有向图的 GCN 来学习谣言传播的模式;以及一个具有相反的谣言扩散有向图的GCN来捕获谣言分散的结构。此外,来自来源帖子的信息都涉及到GCN的每层,以增强来自谣言根源的影响。
2 Introduction
近年来的深度学习方法,如使用 LSTM 、GRU、RvNN 能够从谣言传播中学习顺序特征,忽略了谣言分散的影响。有使用 CNN 获得谣言的传播结构信息,但是该类基于CNN 的方法只注意到了局部邻居的特征,忽略了全局的特征信息。传统的GCN 可以认为是无向图GCN ,如 Figure 1(a) 所示,显然对于谣言检测这种带顺序的任务是不可行的。
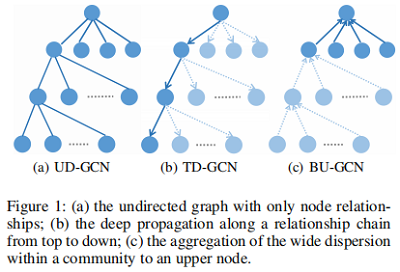
本文提出一种新的双向GCN(BiGCN),它可以同时操作 both top-down 和 bottom-up 的谣言传播。该方法通过两部分得到了 propagation 和dispersion 的特征,Top-Down graph convolutional Networks (TD-GCN) 【Figure 1(b)】和 Bottom-Up graph convolutional Networks (BU-GCN) 【Figure 1(c)】。
-
- 使用 GCN 做谣言检测;
- 提出 Bi-GCN 模型,该模型不仅考虑了谣言从上到下沿关系链传播的因果特征,而且还通过自下而上的收集从社区内的谣言分散中获得了结构特征;
- 将源帖子的特征与每个 GCN 层上的其他帖子连接起来,以全面利用来自根特征的信息,并在谣言检测中取得优异的性能;
3 Related Work
-
- 基于手工特征的谣言检测方法——严重依赖手工特征;
- 基于高阶特征的深度学习方法——(当前)对于传播和扩散效果不如GCN 好;
4 Preliminaries
-
- $c_{i} $ 代表着 第 $i$ 个事件;
- $m$ 代表着事件数;
-
- $n_{i}$ 代表着 $c_{i}$ 中的帖子数;
- $r_{i}$ 代表源贴,即 根节点【root node】;
- $w_{j}^{i}$ 代表 $r_{i}$ 的第 $j$ 个转发贴;
- $G_{i}$ 代表这源帖和转发贴之间的图结构;
-
- $r_{i}$ 代表这根节点;
- $V_{i}=\left\{r_{i}, w_{1}^{i}, \ldots, w_{n_{i}-1}^{i}\right\}$ ;
- $E_{i}=\left\{e_{s t}^{i} \mid s, t=0, \ldots, n_{i}-1\right\}$ 代表了从回复的帖子到转发的帖子或回复的帖子的一组边,如 Figure 1(b) 所示。如果 $w_{2}^{i}$ 是 $w_{1}^{i}$ 的回复帖,那么将有一个有向边 $w_{1}^{i} \rightarrow w_{2}^{i}$ ,即 $e_{12}^{i}$。如果 $w_{1}^{i}$ 是 $r_{i}$ 的回复帖,那么有 $e_{01}^{i}$。
- $G_{i}$ 的邻接矩阵 $\mathbf{A}_{i} \in\{0,1\}^{n_{i} \times n_{i}}$ 可以定义为:
4.1 Graph Convolutional Networks
4.2 DropEdge
为避免过拟合问题,提出的 DropEdge。
形式上,假设图 $A$ 中的边总数为 $N_{e}$,丢弃率为 $p$ ,则 DropEdge $\boldsymbol{A}^{\prime}$ 后的邻接矩阵计算如下:
$\mathbf{A}^{\prime}=\mathbf{A}-\mathbf{A}_{d r o p}$
其中,$\mathbf{A}_{\text {drop }}$ 是使用从原始边集随机抽样的新 $N_{e} \times p$ 边构造的矩阵。
5 Bi-GCN Rumor Detection Model
如 Figure 2 所示,我们使用 Bi-GCN 分 $4$ 个步骤详细说明了谣言检测过程。
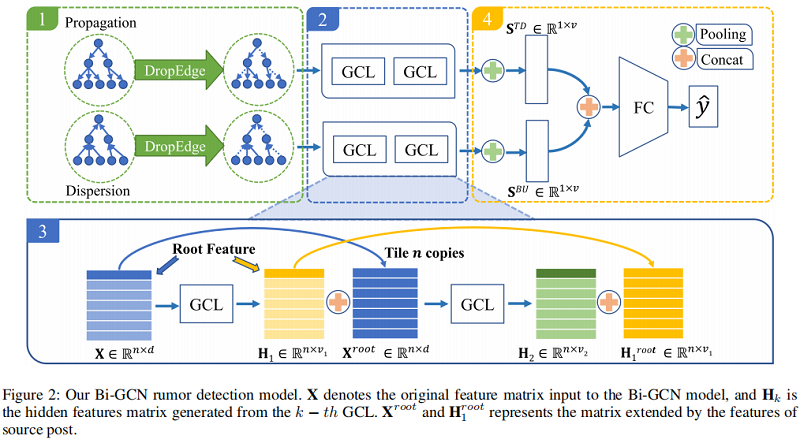
5.1 Construct Propagation and Dispersion Graphs
基于转发和回复关系,构建一个谣言事件 $c_{i}$ 的传播结构 $\langle V, E\rangle$。然后,设 $\mathbf{A} \in \mathbb{R}^{n_{i} \times n_{i}}$ 和 $X$ 分别为其对应的邻接矩阵和基于谣言传播树的 $c_{i}$ 的特征矩阵。$A$ 只包含从 upper nodes 到 lower nodes 的边,如 Figure 1 (b) 所示。在每个训练阶段,通过 $\text{Eq.3}$ 删除边的 $p$ 个百分比形成 $\mathbf{A}^{\prime}$,避免了惩罚性的过拟合问题。
基于 $\mathbf{A}^{\prime}$ 和 $X$,可以建立 Bi-GCN 模型。 Bi-GCN 由两个组件组成:
-
- a Top-Down Graph Convolutional Network (TDGCN)
- a Bottom-Up Graph Convolutional Network (BUGCN)
两个部分的邻接矩阵是不同的。对于TD-GCN,邻接矩阵表示为 $\mathbf{A}^{T D}=\mathbf{A}^{\prime}$。同时,对于 BU-GCN,邻接矩阵为 $\mathbf{A}^{T D}=\mathbf{A}^{\prime}$。TD-GCN 和 BU-GCN 采用相同的特征矩阵 $\mathbf{X}$。
5.2 Calculate the High-level Node Representations
经过 DropEdge 操作后,通过 TD-GCN 和 BU-GCN 分别得到了自顶向下的传播特征和自底向上的传播特征。
两层的 TD-GCN 如下:
$\mathbf{H}_{2}^{T D}=\sigma\left(\hat{\mathbf{A}}^{T D} \mathbf{H}_{1}^{T D} \boldsymbol{W}_{1}^{T D}\right) \quad\quad\quad(5)$
其中,$\mathbf{H}_{1}^{T D} \in \mathbb{R}^{n \times v_{1}}$ 和 $\mathbf{H}_{2}^{T D} \in \mathbb{R}^{n \times v_{2}}$ 代表着 TDGCN 的 hidden features,$\boldsymbol{W}_{0}^{T D} \in \mathbb{R}^{d \times v_{1}}$ 和 $\boldsymbol{W}_{1}^{T D} \in \mathbb{R}^{v_{1} \times v_{2}} $ 代表着 TDGCN 的参数矩阵。
在训练的时候,DropEdge 在 GCL(GCN Layers)层中使用。
5.3 Root Feature Enhancement
一个谣言事件的来源帖子总是有丰富的信息来产生广泛的影响。有必要更好地利用来自源帖子的信息,并从节点和源帖子之间的关系中学习更准确的节点表示。
因此,除了TD-GCN和BU-GCN的隐藏特征外,还提出一种根特征增强操作来提高谣言检测的性能,如 Figure 2 所示。具体来说,对于第 $k$ 层的 GCL 的 TD-GCN,将每个节点的隐藏特征向量与 $(k−1)$ 层的 GCL 中根节点的隐藏特征向量连接起来,构造一个新的特征矩阵:
$\tilde{\mathbf{H}}_{k}^{T D}=\operatorname{concat}\left(\mathbf{H}_{k}^{T D},\left(\mathbf{H}_{k-1}^{T D}\right)^{\text {root }}\right) \quad\quad\quad(6)$
并有 $\mathbf{H}_{0}^{T D}=\mathbf{X}$,且有 :
$\tilde{\mathbf{H}}_{1}^{T D}= concat \left(\mathbf{H}_{1}^{T D}, \mathbf{X}^{\text {root }}\right)$
$\mathbf{H}_{2}^{T D}=\sigma\left(\hat{\mathbf{A}}^{T D} \tilde{\mathbf{H}}_{1}^{T D} \boldsymbol{W}_{1}^{T D}\right) \quad\quad\quad(7)$
$\tilde{\mathbf{H}}_{2}^{T D}=\operatorname{concat}\left(\mathbf{H}_{2}^{T D},\left(\mathbf{H}_{1}^{T D}\right)^{r o o t}\right) \quad\quad\quad(8)$

同理,BU-GCN 类似。
5.4 Representations of Propagation and Dispersion for Rumor Classification
传播和分散的表示分别是来自 TD-GCN 和 BU-GCN 的节点表示的聚合。在这里,使用平均池操作符来聚合来自这两组节点表示的信息。它被表述为
$\mathbf{S}^{T D}=\operatorname{MEAN}\left(\tilde{\mathbf{H}}_{2}^{T D}\right)\quad\quad\quad(9)$
$\mathbf{S}^{B U}=\operatorname{MEAN}\left(\tilde{\mathbf{H}}_{2}^{B U}\right) \quad\quad\quad(10)$
然后,将 propagation 表示和 dispersion 表示连接起来,将信息合并为
$\mathbf{S}=\operatorname{concat}\left(\mathbf{S}^{T D}, \mathbf{S}^{B U}\right) \quad\quad\quad(11)$
最后,通过几个完整的连接层和一个 softmax 层来计算事件 $\hat{\mathbf{y}}$ 的标签:
$\hat{\mathbf{y}}=\operatorname{Softmax}(F C(\mathbf{S})) \quad\quad\quad(12)$
其中,$\hat{\mathbf{y}} \in \mathbb{R}^{1 \times C}$ 是用于预测事件标签的所有类的概率向量。
6 Experiments
Datasets

nodes refer to users, edges represent retweet or response relationships, and features are the extracted top-5000 words in terms of the TF-IDF values.
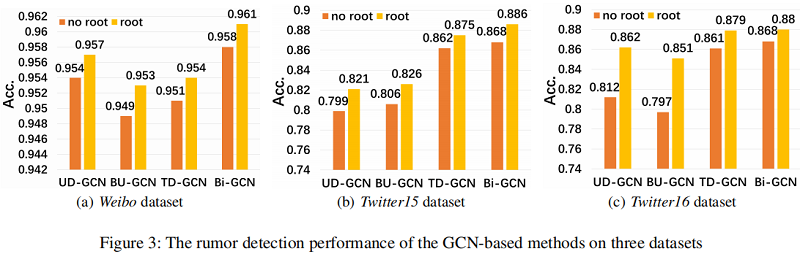
谣言检测结果
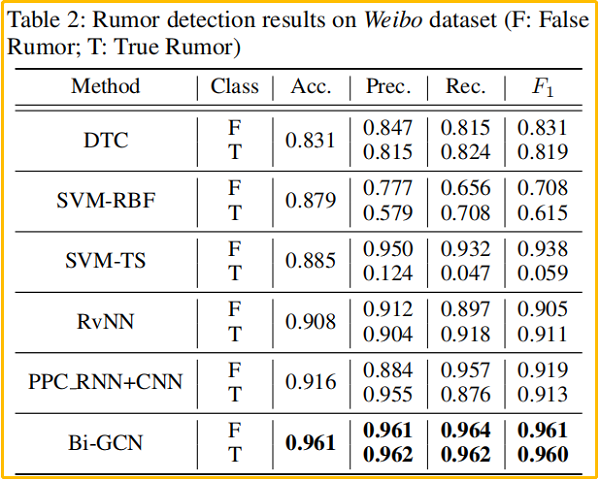
Weibo dataset 谣言检测结果:
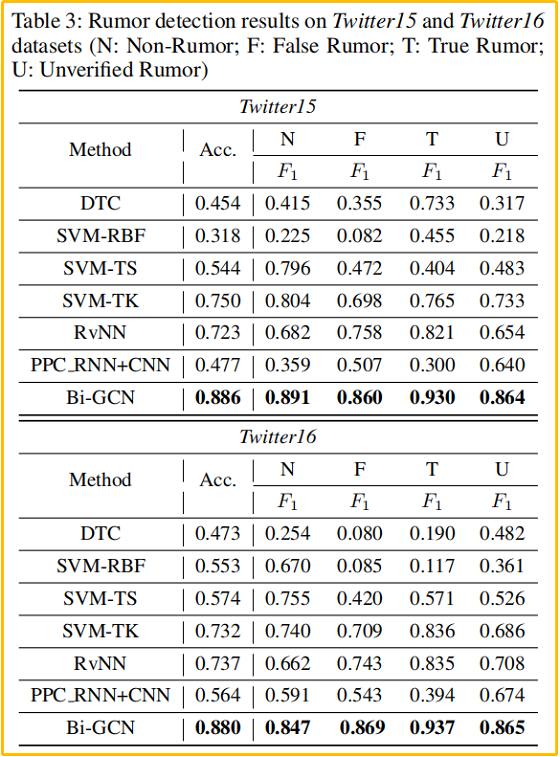
Twitter15 and Twitter16 谣言检测结果:
Ablation Study
Early Rumor Detection

7 Conclusions
在本文中,我们提出了一种基于GCN的社交媒体上的谣言检测模型,称为Bi-GCN。其固有的GCN模型使该方法具有处理图/树结构和学习更高层次表示的能力,更有利于谣言检测。此外,我们还通过连接GCN的每个GCL后的源柱的特征来提高模型的有效性。同时,我们构建了Bi-GCN的几种变体来建模传播模式,即UD-GCN、TD-GCN和BU-GCN。在三个真实数据集上的实验结果表明,基于GCN的方法在准确性和效率方面都有非常大的利润率,优于最先进的基线。特别是,BiGCN模型既考虑了谣言从上到下传播模式传播的因果特征,以及通过自下而上聚集在社区内谣言分散的结构特征,从而获得了最佳的性能。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16689366.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号