论文解读(CSSL)《Contrastive Self-supervised Learning for Graph Classification》
论文信息
论文标题:Contrastive Self-supervised Learning for Graph Classification
论文作者:Jiaqi Zeng, Pengtao Xie
论文来源:2020, AAAI
论文地址:download
论文代码:download
1 Introduction
任务:图分类。
贡献:
-
- global-global 对比
- 提出 CSSL-Reg
- 提出 CSSL-Pretrain
2 Methods
在 CSSL-Pretrain 中,我们使用CSSL对图编码器进行预训练,在CSSL-Reg中,我们使用CSSL任务来规范图编码器。
2.1 Data Argumentations
本文采用数据增强策略如 Figure 1 所示:

分别对应于:
-
- 边删除(Edge deletion):随机选择一条边,并将其从图中删除。例如,在 Figure 1(b) 中,我们随机选择一条边(即节点1和节点3之间的一条边),并删除它。
- 节点删除(Node deletion):随机选择一个节点并将其从图中移除,并删除连接到此节点的所有边。例如,在 Figure 1(c) 中,我们随机选择一个节点(节点4),删除该节点和与节点4连接的所有边。
- 边插入(Edge insertion):随机选择两个节点,如果它们没有直接连接,但它们之间有一条路径,则在这两个节点之间添加一条边。例如,在 Figure 1 (d),节点2和节点3没有直接连接,但它们之间有一条路径(2→1→3)。我们用一条边把这两个节点连接起来。
- 节点插入(Node insertion):随机选择一个强连通子图 $S$,去掉 $S$ 中的所有边,添加一个节点 $n$,在 $S$ 中的每个节点之间添加一条边。例如,在 Figure 1 (e)中,节点1、3、4形成一个完整的子图。我们插入一个新的节点 5,将节点1、3、4 连接到节点 5,并删除节点 1、3、4 之间的边。
步骤一:给定一个原始图 $ G$, 有 $t$ 个步骤进行增强,每次进行增强都是基于上一次增强的图进行增强,并且每次增强的方式是随机选择四个增强方式中一个增强方式。
$\begin{array}{l} G_{1}&=&o_{1}\left(G\right)\\G_{2}&=&o_{2}\left(G_{1}\right)\\G_{3}&=&o_{3}\left(G_{2}\right)\\&\vdots& \\G_{t}&=&o_{t}\left(G_{t-1}\right)\\\end{array}$
举例:
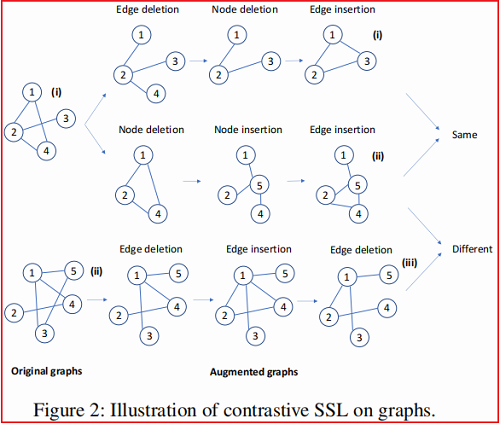
步骤二:定义增广图上的对比损失。如果从相同的原始图创建两个增广图,它们被标记为相似;否则,它们被标记为不同。
网络由两个模块组成:
-
- 一个图嵌入模块 $f(\cdot)$ 用于提取图的潜在表示 $\mathbf{h}=f(\mathbf{x})$;
- 一个多层感知器模块 $g(\cdot)$,用来生成另一个潜在表示 $\mathbf{z}=g(\mathbf{h})$ ,$\mathbf{z}$ 用于预测两个图是否相似;
给定一个相似对 $\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)$ 和一组与 $\mathbf{x}_{i}$ 不同图$\left\{\mathbf{x}_{k}\right\}$,对比损失可以定义如下:
${\large -\log \frac{\exp \left(\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right) / \tau\right)}{\exp \left(\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right) / \tau\right)+\sum_{k} \exp \left(\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{k}\right) / \tau\right)}}\quad\quad\quad\quad\quad(1) $
本文利用 MoCo 优化该对比损失函数:
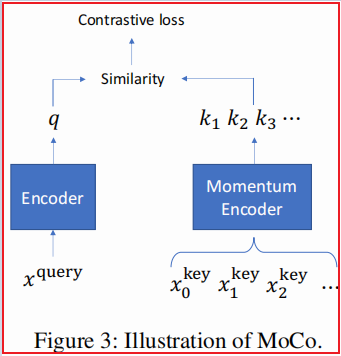
定义一个与 $\text{batch}$ 大小无关的队列,该队列中包含一组动态的增强图($\text{key}$)。每次迭代过程中,将最新的 $\text{minbatch}$ (一系列增强图)加入到队列中,同时最老的 $\text{minbatch}$ 从队列中剔除。Figure 3 即是 $\text{MoCo }$ 框架,这里的 $\text{keys}$ 是用动量编码器编码的。给定当前 $\text{minbatch}$ 中的一个增强图(称之为 $\text{query}$)和一个 $\text{key}$ ,如果他们来自同一个图,则认为他们是正对,否则认为是负对,计算每个 $\text{query}$ 和 $\text{key}$ 的相似度得分。
2.2 CSSL-based Pretraining
框架如下:
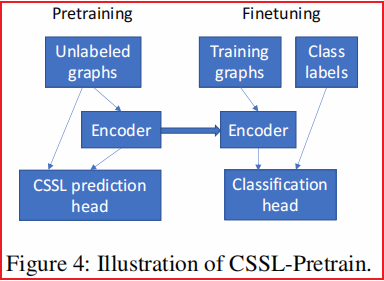
预训练:对于一个不带标记的图,使用 CSSL prediction head(MLP) 结合上述对比损失(判断两个视图是否是同一个图的增强图),训练好一个 Graph Encoder。
微调:使用上述生成的 Graph Encoder ,并丢弃 CSSL prediction head,仅结合分类损失进行微调。
2.3 CSSL-based Regularization
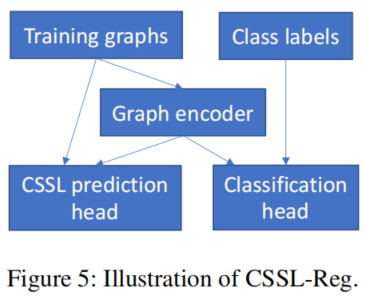
即:联合学习(joint learning),同时使用对比损失和分类损失进行训练。损失函数如下:
$ \mathcal{L}^{(c)}\left(D, L ; \mathbf{W}^{(e)}, \mathbf{W}^{(c)}\right)+\lambda \mathcal{L}^{(p)}\left(D, \mathbf{W}^{(e)}, \mathbf{W}^{(p)}\right) \quad\quad\quad\quad(2)$
其中,$\mathcal{L}^{(c)} $ 为分类损失,$\mathcal{L}^{(p)}$ 为图对比损失。
2.4 Graph Encoder
本文采用 Graph Encoder 是 Hierarchical Graph Pooling with Structure Learning (HGP-SL) encoder 。
HGP-SL 由图卷积和图池的交错层组成
-
- 图卷积通过利用相邻节点的嵌入来学习图中每个节点的多层潜在嵌入;
- 图池化操作选择一个信息节点的子集来形成一个子图;
如果一个节点的表示可以被它的邻居很好地重建,那么它就被认为是信息量较少的。给定池化后的子图结构,HGP-SL进行结构学习来细化子图的结构。HGP-SL计算子图中两个节点的相似度,并在相似度得分足够大时将它们连接起来。给定改进的子图,再次进行图的卷积和池化。卷积、池化和结构细化的层重复多次。
3 Experiments
数据集
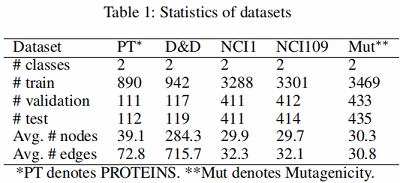
图分类

4 Conclusion
关于 Moco 的代码还没有看过,可惜了。
修改历史
2021-04-16 创建文章
2022-06-13 修订文章(完结,不可能再看了)
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16103821.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号