激活函数以零为中心的问题
收敛速度
这里首先需要给收敛速度做一个诠释。模型的最优解即是模型参数的最优解。通过逐轮迭代,模型参数会被更新到接近其最优解。这一过程中,迭代轮次多,则我们说模型收敛速度慢;反之,迭代轮次少,则我们说模型收敛速度快。
参数更新
深度学习一般的学习方法是反向传播。简单来说,就是通过链式法则,求解全局损失函数 $L(\vec x)$ 对某一参数 $w$ 的偏导数(梯度);而后辅以学习率 $\eta$,向梯度的反方向更新参数 $w$。
$w \gets w - \eta\cdot\frac{\partial L}{\partial w}.$
考虑学习率 $\eta$ 是全局设置的超参数,参数更新的核心步骤即是计算 $\frac{\partial L}{\partial w}$ 。再考虑到对于某个神经元来说,其输入与输出的关系是
$f(\vec x; \vec w, b) = f(z) = f\Bigl(\sum_iw_ix_i + b\Bigr).$
因此,对于参数$w_i$来说
$\frac{\partial L}{\partial w_i} = \frac{\partial L}{\partial f}\frac{\partial f}{\partial z}\frac{\partial z}{\partial w_i} = x_i \cdot \frac{\partial L}{\partial f}\frac{\partial f}{\partial z}.$
因此,参数的更新步骤变为
$w_i \gets w_i - \eta x_i\cdot \frac{\partial L}{\partial f}\frac{\partial f}{\partial z}.$
更新方向
由于 $w_i$ 是上一轮迭代的结果,此处可视为常数,而 $\eta$ 是模型超参数,参数 $w_i$ 的更新方向实际上由 $x_i\cdot \frac{\partial L}{\partial f}\frac{\partial f}{\partial z}$ 决定。
又考虑到 $\frac{\partial L}{\partial f}\frac{\partial f}{\partial z}$ 对于所有的 $w_i$ 来说是常数,因此各个 $w_i$ 更新方向之间的差异,完全由对应的输入值$x_i$的符号决定。
以零为中心的影响
至此,为了描述方便,我们以二维的情况为例。亦即,神经元描述为
$f(\vec x; \vec w, b) = f\bigl(w_0x_0 + w_1x_1 + b\bigr).$
现在假设,参数 $w_0$, $w_1$的最优解$w_0^{*}$ , $w_1^{*}$ 满足条件
$\begin{cases}w_0 < w_0^{*}, \\ w_1\geqslant w_1^{*}.\end{cases}$
这也就是说,我们希望适当增大,但希望 $w_1$ 适当减小。考虑到上一小节提到的更新方向的问题,这就必然要求 $x_0$ 和 $x_1$ 符号相反。
但在 Sigmoid 函数中,输出值恒为正。这也就是说,如果上一级神经元采用 Sigmoid 函数作为激活函数,那么我们无法做到 $x_0$ 和 $x_1$符号相反。此时,模型为了收敛,不得不向逆风前行的风助力帆船一样,走 Z 字形逼近最优解。
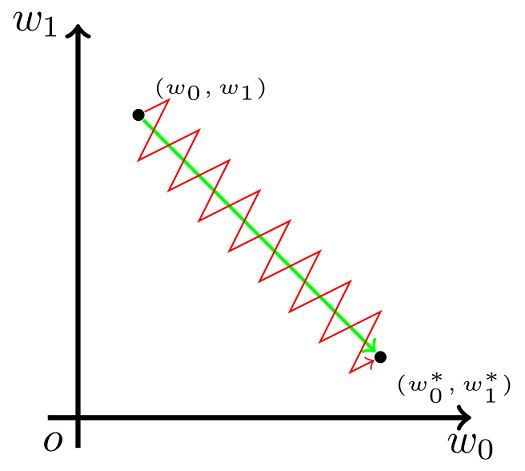
之所以是类似与红色这样的折线图,是因为每一小段折线都是一次参数更新,经过很多次更新才能到达最优解 $w_0^{*}$\、$w_1^{*}$,但每一次更新 $w_i$ 的式子中,下面式子
$\frac{\partial L}{\partial f} \frac{\partial f}{\partial z}$
对于所有的 $w_i$ 都是相同的:
损失函数相同,则
$\frac{\partial L}{\partial f}$
相同,激活函数相同,则
$\frac{\partial f}{\partial z}$
相同,在同一层更新的参数肯定是相同的损失函数和激活函数。也就是说在同一次更新的过程中,如果 $x_i$ 是同号的,那么 $w_i$ 就是往同一个方向变化的,所以会看见图中每一段红色的折线上,$w_0 , w_1 $ 都是要么同变大,要么同变小的。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15085674.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号