Redis(八)理解内存
Redis所有的数据都存在内存中,当前内存虽然越来越便宜,但跟廉价的硬盘相比成本还是比较昂贵,因此如何高效利用Redis内存变得非常重要。
高效利用Redis内存首先需要理解Redis内存消耗在哪里,如何管理内存,最后才能考虑如何优化内存。
一、内存消耗
有些内存消耗是必不可少的,而有些可以通过参数调整和合理使用来规避内存浪费。
内存消耗可以分为进程自身消耗和子进程消耗。
1.内存使用统计
root@bigjun:~# redis-cli 127.0.0.1:6379> info memory # Memory used_memory:848336 Redis分配器分配的内存总量,也就是内部存储所有数据内存占用量 used_memory_human:828.45K 以可读的形式返回user_memory used_memory_rss:4304896 从操作系统的角度显示Redis进程占用的物理内存空间 used_memory_rss_human:4.11M 以可读的形式返回used_memory_rss used_memory_peak:848336 内存使用的最大值,表示used_memory的峰值 used_memory_peak_human:828.45K 以可读的形式返回used_memory_peak used_memory_peak_perc:100.01% used_memory_overhead:836078 used_memory_startup:786448 used_memory_dataset:12258 used_memory_dataset_perc:19.81% total_system_memory:4112789504 系统总内存大小 total_system_memory_human:3.83G 以可读的形式返回total_system_memory used_memory_lua:37888 Lua引擎所消耗的内存大小 used_memory_lua_human:37.00K 以可读的形式返回used_memory_lua maxmemory:0 maxmemory_human:0B maxmemory_policy:noeviction mem_fragmentation_ratio:5.07 used_memory_rss/used_memory比值,表示内存碎片率 mem_allocator:jemalloc-4.0.3 Redis使用的内存分配器,默认为jemalloc active_defrag_running:0 lazyfree_pending_objects:0 需要重点关注的指标有:used_memory_rss、used_memory以及他们的比值mem_fragmentation_ratio 当mem_fragmentation_ratio > 1时,说明used_memory_rss - used_memory多处的部分内存并没有用于数据存储,而是被内存碎片所消耗,如果两者相差很大,说明碎片率严重。 当mem_fragmentation_ratio < 1 时,这种情况一般出现在操作系统把Redis内存交换到硬盘导致,出现这种情况要格外关注,由于硬盘速度远远慢于内存,Redis性能会变得很差,甚至僵死。
2.内存消耗划分
Redis进程内消耗主要包括:自身内存+对象内存+缓冲内存+内存碎片,其中Redis空进程自身内存消耗非常少,通常used_memory_rss在3MB左右,used_memory在800KB左右,一个空的Redis进程消耗内存可以忽略不计。
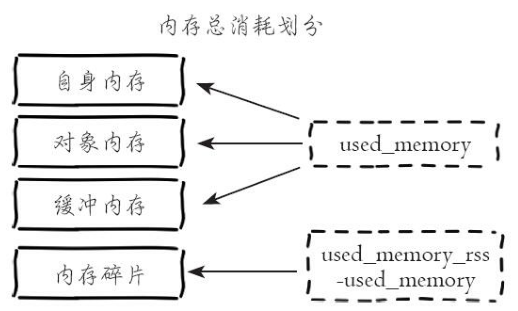
(1)对象内存
对象内存是Redis内存占用最大的一块,存储着用户所有的数据。Redis所有的数据都采用key-value数据类型,每次创建键值对时,至少创建两个类型对象:key对象和value对象。
对象内存消耗可以简单理解为sizeof(keys)+sizeof(values)。
键对象都是字符串,在使用Redis时很容易忽略键对内存消耗的影响,应当避免使用过长的键。
value对象更复杂些,主要包含5种基本数据类型:字符串、列表、哈希、集合、有序集合。
其他数据类型都是建立在这5种数据结构之上实现的,如:Bitmaps和HyperLogLog使用字符串实现,GEO使用有序集合实现等。每种value对象类型根据使用规模不同,占用内存不同。在使用时一定要合理预估并监控value对象占用情况,避免内存溢出。
(2)缓冲内存
缓冲内存主要包括:客户端缓冲、复制积压缓冲区、AOF缓冲区。
- 客户端缓冲指的是所有接入到Redis服务器TCP连接的输入输出缓冲。输入缓冲无法控制,最大空间为1G,如果超过将断开连接。
- 复制积压缓冲区是指Redis提供了一个可重用的固定大小缓冲区用于实现部分复制功能,根据repl-backlog-size参数控制,默认1MB。对于复制积压缓冲区整个主节点只有一个,所有的从节点共享此缓冲区,因此可以设置较大的缓冲区空间,如100MB,这部分内存投入是有价值的,可以有效避免全量复制。
- AOF缓冲区用于在Redis重写期间保存最近的写入命令,AOF缓冲区空间消耗用户无法控制,消耗的内存取决于AOF重写时间和写入命令量,这部分空间占用通常很小。
(3)内存碎片
Redis默认的内存分配器采用jemalloc,可选的分配器还有:glibc、tcmalloc。
内存分配器为了更好地管理和重复利用内存,分配内存策略一般采用固定范围的内存块进行分配。
例如jemalloc在64位系统中将内存空间划分为:小、大、巨大三个范围。每个范围内又划分为多个小的内存块单位,如下所示:
- 小:[8byte],[16byte,32byte,48byte,...,128byte],[192byte,256byte,...,512byte],[768byte,1024byte,...,3840byte]
- 大:[4KB,8KB,12KB,...,4072KB]
- 巨大:[4MB,8MB,12MB,...]
比如当保存5KB对象时jemalloc可能会采用8KB的块存储,而剩下的3KB空间变为了内存碎片不能再分配给其他对象存储。内存碎片问题虽然是所有内存服务的通病,但是jemalloc针对碎片化问题专门做了优化,一般不会存在过度碎片化的问题,正常的碎片率(mem_fragmentation_ratio)在1.03左右。
但是当存储的数据长短差异较大时,以下场景容易出现高内存碎片问题:
- 频繁做更新操作,例如频繁对已存在的键执行append、setrange等更新操作。
- 大量过期键删除,键对象过期删除后,释放的空间无法得到充分利用,导致碎片率上升。
出现高内存碎片问题时常见的解决方式如下:
- 数据对齐:在条件允许的情况下尽量做数据对齐,比如数据尽量采用数字类型或者固定长度字符串等,但是这要视具体的业务而定,有些场景无法做到。
- 安全重启:重启节点可以做到内存碎片重新整理,因此可以利用高可用架构,如Sentinel或Cluster,将碎片率过高的主节点转换为从节点,进行安全重启。
3.子进程内存消耗
子进程内存消耗主要指执行AOF/RDB重写时Redis创建的子进程内存消耗。
Redis执行fork操作产生的子进程内存占用量对外表现为与父进程相同,理论上需要一倍的物理内存来完成重写操作。但Linux具有写时复制技术(copy-on-write),父子进程会共享相同的物理内存页,当父进程处理写请求时会对需要修改的页复制出一份副本完成写操作,而子进程依然读取fork时整个父进程的内存快照。
子进程内存消耗总结如下:
- Redis产生的子进程并不需要消耗1倍的父进程内存,实际消耗根据期间写入命令量决定,但是依然要预留出一些内存防止溢出。
- 需要设置sysctl vm.overcommit_memory=1允许内核可以分配所有的物理内存,防止Redis进程执行fork时因系统剩余内存不足而失败。
- 排查当前系统是否支持并开启THP,如果开启建议关闭,防止copy-on-write期间内存过度消耗。
二、内存管理
Redis主要通过控制内存上限和回收策略实现内存管理。
1.设置内存上限
Redis使用maxmemory参数限制最大可用内存。限制内存的目的主要有:
- 用于缓存场景,当超出内存上限maxmemory时使用LRU等删除策略释放空间。
- 防止所用内存超过服务器物理内存。
需要注意,maxmemory限制的是Redis实际使用的内存量,也就是used_memory统计项对应的内存。由于内存碎片率的存在,实际消耗的内存可能会比maxmemory设置的更大,实际使用时要小心这部分内存溢出。通过设置内存上限可以非常方便地实现一台服务器部署多个Redis进程的内存控制。
比如一台24GB内存的服务器,为系统预留4GB内存,预留4GB空闲内存给其他进程或Redis fork进程,留给Redis16GB内存,这样可以部署4个maxmemory=4GB的Redis进程。得益于Redis单线程架构和内存限制机制,即使没有采用虚拟化,不同的Redis进程之间也可以很好地实现CPU和内存的隔离性。
2.动态调整内存上限
Redis的内存上限可以通过config set maxmemory进行动态修改,即修改最大可用内存。
例如之前的示例,当发现Redis-2没有做好内存预估,实际只用了不到2GB内存,而Redis-1实例需要扩容到6GB内存才够用,这时可以分别执行如下命令进行调整:
Redis-1>config set maxmemory 6GB Redis-2>config set maxmemory 2GB
通过动态修改maxmemory,可以实现在当前服务器下动态伸缩Redis内存的目的。
如果此时Redis-3和Redis-4实例也需要分别扩容到6GB,这时超出系统物理内存限制就不能简单的通过调整maxmemory来达到扩容的目的,需要采用在线迁移数据或者通过复制切换服务器来达到扩容的目的。
3.内存回收策略
Redis的内存回收机制主要体现在以下两个方面:
- 删除到达过期时间的键对象。
- 内存使用达到maxmemory上限时触发内存溢出控制策略。
(1)删除过期键对象
Redis所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存大量的键,维护每个键精准的过期删除机制会导致消耗大量的CPU,对于单线程的Redis来说成本过高,因此Redis采用惰性删除和定时任务删除机制实现过期键的内存回收。
- 惰性删除:惰性删除用于当客户端读取带有超时属性的键时,如果已经超过键设置的过期时间,会执行删除操作并返回空,这种策略是出于节省CPU成本考虑,不需要单独维护TTL链表来处理过期键的删除。但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内存不能及时释放。正因为如此,Redis还提供另一种定时任务删除机制作为惰性删除的补充。
- 定时任务删除:Redis内部维护一个定时任务,默认每秒运行10次(通过配置hz控制)。定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键,流程如下:
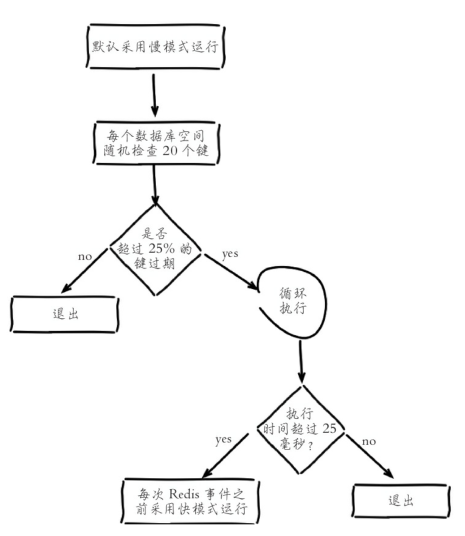
流程说明:
- 定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。
- 如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或运行超时为止,慢模式下超时时间为25毫秒。
- 如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1毫秒且2秒内只能运行1次。
- 快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
(2)内存溢出控制策略
当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制,Redis支持6种策略,如下所示:
- noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOM command not allowed when used memory,此时Redis只响应读操作。
- volatile-lru:根据LRU算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
三、内存优化
1.RedisObject对象
Redis存储的所有值对象在内部定义为redisObject结构体,内部结构如图
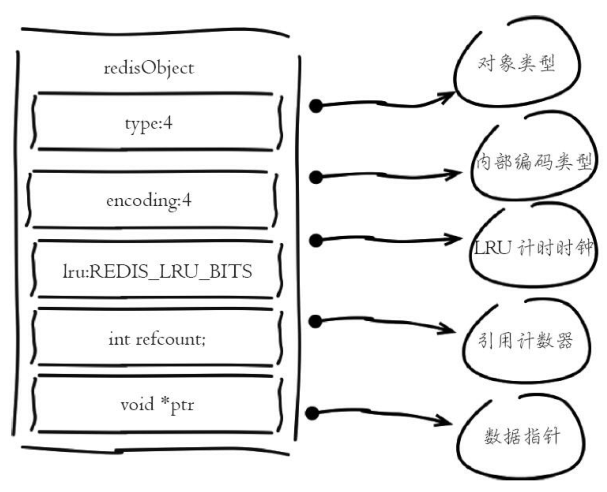
Redis存储的数据都使用redisObject来封装,包括string、hash、list、set、zset在内的所有数据类型。
- type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string、hash、list、set、zset。可以使用type {key}命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型。
- encoding字段:表示Redis内部编码类型,encoding在Redis内部使用,代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
- lru字段:记录对象最后一次被访问的时间,当配置了maxmemory和maxmemory-policy=volatile-lru或者allkeys-lru时,用于辅助LRU算法删除键数据。可以使用object idletime{key}命令在不更新lru字段情况下查看当前键的空闲时间。
- refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount {key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。
- *ptr字段:与对象的数据内容相关,如果是整数,直接存储数据;否则表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作即可。
2.缩减键值对象
降低Redis内存使用最直接的方式就是缩减键(key)和值(value)的长度。
- key长度:如在设计键时,在完整描述业务情况下,键值越短越好。如user:{uid}:friends:notify:{fid}可以简化为u:{uid}:fs:nt:{fid}。
- value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二进制数组放入Redis。首先应该在业务上精简业务对象,去掉不必要的属性避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工具来降低字节数组大小。
- 以Java为例,内置的序列化方式无论从速度还是压缩比都不尽如人意,这时可以选择更高效的序列化工具,如:protostuff、kryo等,Java常见序列化工具空间压缩对比。

值对象除了存储二进制数据之外,通常还会使用通用格式存储数据比如:json、xml等作为字符串存储在Redis中。这种方式优点是方便调试和跨语言,但是同样的数据相比字节数组所需的空间更大,在内存紧张的情况下,可以使用通用压缩算法压缩json、xml后再存入Redis,从而降低内存占用,例如使用GZIP压缩后的json可降低约60%的空间。
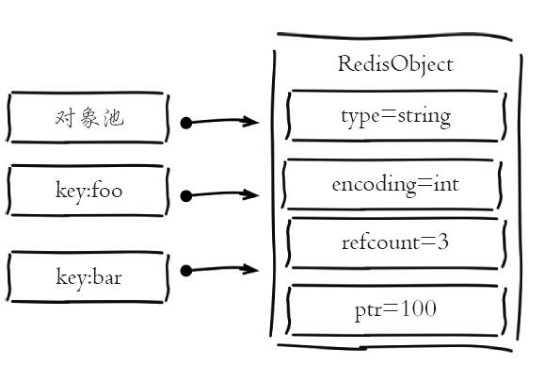
3.共享对象池
共享对象池是指Redis内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个[0-9999]的整数对象池,用于节约内存。除了整数值对象,其他类型如list、hash、set、zset内部元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。
Object refcount命令主要用于调试,能够返回指定key所对应的value被引用的次数,在0-9999之间的整数,都是共享内存的,所以返回值是同一个数:2147483647。
由于100是0-9999之间的数,所以都会共享内存。 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379> set test:1 100 OK 127.0.0.1:6379> object refcount test:1 (integer) 2147483647 127.0.0.1:6379> set test:2 100 OK 127.0.0.1:6379> object refcount test:2 (integer) 2147483647
开启共享对象池之后,
redis> set foo 100 OK redis> object refcount foo (integer) 2 redis> set bar 100 OK redis> object refcount bar (integer) 3
4.字符串优化
字符串对象是Redis内部最常用的数据类型。所有的键都是字符串类型,值对象数据除了整数之外都使用字符串存储。
比如执行命令:lpush cache:type "redis" "memcache" "tair" "levelDB",Redis首先创建"cache:type"键字符串,然后创建链表对象,链表对象内再包含四个字符串对象,排除Redis内部用到的字符串对象之外至少创建5个字符串对象。
(1)字符串结构
Redis没有采用原生C语言的字符串类型而是自己实现了字符串结构,内部简单动态字符串(simple dynamic string,SDS)。
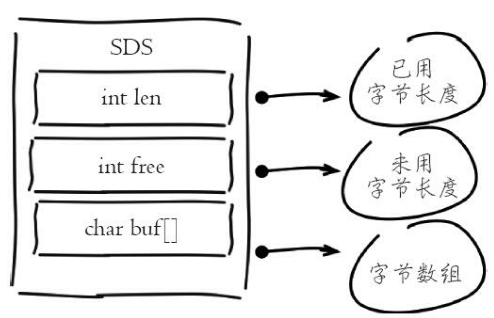
Redis自身实现的字符串结构有如下特点:
- O(1)时间复杂度获取:字符串长度、已用长度、未用长度。
- 可用于保存字节数组,支持安全的二进制数据存储。
- 内部实现空间预分配机制,降低内存再分配次数。
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
(2)预分配机制
字符串之所以采用预分配的方式是防止修改操作需要不断重分配内存和字节数据拷贝。但同样也会造成内存的浪费。字符串预分配每次并不都是翻倍扩容,空间预分配规则如下:
- 第一次创建len属性等于数据实际大小,free等于0,不做预分配。
- 修改后如果已有free空间不够且数据小于1M,每次预分配一倍容量。如原有len=60byte,free=0,再追加60byte,预分配120byte,总占用空间:60byte+60byte+120byte+1byte。
- 修改后如果已有free空间不够且数据大于1MB,每次预分配1MB数据。如原有len=30MB,free=0,当再追加100byte,预分配1MB,总占用空间:1MB+100byte+1MB+1byte。
(3)字符串重构
字符串重构:指不一定把每份数据作为字符串整体存储,像json这样的数据可以使用hash结构,使用二级结构存储也能帮我们节省内存。同时可以使用hmget、hmset命令支持字段的部分读取修改,而不用每次整体存取。例如下面的json数据:
{ "vid": "413368768", "title": " 搜狐屌丝男士 ", "videoAlbumPic":"http://photocdn.sohu.com/60160518/vrsa_ver8400079_ae433_pic26.jpg", "pid": "6494271", "type": "1024", "playlist": "6494271", "playTime": "468" }
分别使用字符串和hash结构,可以看到使用内存的差异:

根据测试结构,第一次默认配置下使用hash类型,内存消耗不但没有降低反而比字符串存储多出2倍,而调整hash-max-ziplist-value=66之后内存降低为535.60M。因为json的videoAlbumPic属性长度是65,而hash-max-ziplist-value默认值是64,Redis采用hashtable编码方式,反而消耗了大量内存。调整配置后hash类型内部编码方式变为ziplist,相比字符串更省内存且支持属性的部分操作。
5.编码优化
(1)编码类型
Redis对外提供了string、list、hash、set、zet等类型,但是Redis内部针对不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实现。编码不同将直接影响数据的内存占用和读写效率。使用object encoding {key}命令获取编码类型。
127.0.0.1:6379> set str:1 hello OK 127.0.0.1:6379> object encoding str:1 "embstr" 127.0.0.1:6379> lpush list:1 1 2 3 (integer) 3 127.0.0.1:6379> object encoding list:1 "quicklist"
Redis针对每种数据类型(type)可以采用至少两种编码方式来实现。
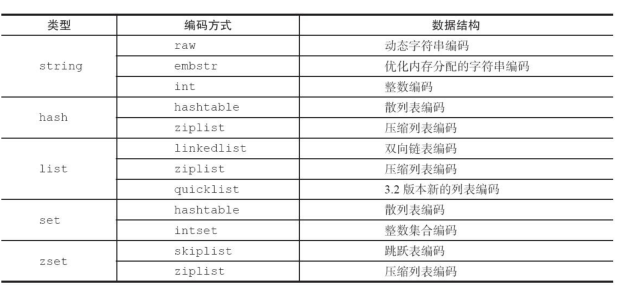
(2)控制编码类型
编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换。
Redis旧版本: redis> lpush list:1 a b c d (integer) 4 // 存储 4 个元素 redis> object encoding list:1 "ziplist" // 采用 ziplist 压缩列表编码 redis> config set list-max-ziplist-entries 4 OK // 设置列表类型 ziplist 编码最大允许 4 个元素 redis> lpush list:1 e (integer) 5 // 写入第 5 个元素 e redis> object encoding list:1 "linkedlist" // 编码类型转换为链表 redis> rpop list:1 "a" // 弹出元素 a redis> llen list:1 (integer) 4 // 列表此时有 4 个元素 redis> object encoding list:1 "linkedlist" // 编码类型依然为链表,未做编码回退
Redis之所以不支持编码回退,主要是数据增删频繁时,数据向压缩编码转换非常消耗CPU,得不偿失。以上示例用到了list-max-ziplist-entries参数,这个参数用来决定列表长度在多少范围内使用ziplist编码。当然还有其他参数控制各种数据类型的编码。

6.控制键的数量
当使用Redis存储大量数据时,通常会存在大量键,过多的键同样会消耗大量内存。
Redis本质是一个数据结构服务器,它为我们提供多种数据结构,如hash、list、set、zset等。使用Redis时不要进入一个误区,大量使用get/set这样的API,把Redis当成Memcached使用。
对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存。
可以通过在客户端预估键规模,把大量键分组映射到多个hash结构中降低键的数量,如图:
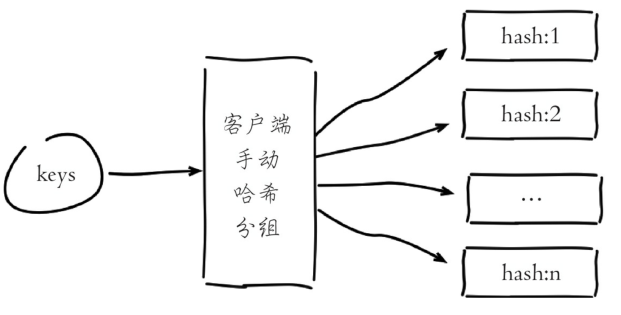
hash结构降低键数量分析:
- 根据键规模在客户端通过分组映射到一组hash对象中,如存在100万个键,可以映射到1000个hash中,每个hash保存1000个元素。
- hash的field可用于记录原始key字符串,方便哈希查找。
- hash的value保存原始值对象,确保不要超过hash-max-ziplist-value限制。

通过这个测试数据,可以说明:
- 同样的数据使用ziplist编码的hash类型存储比string类型节约内存。
- 节省内存量随着value空间的减少越来越明显。
- hash-ziplist类型比string类型写入耗时,但随着value空间的减少,耗时逐渐降低。
使用hash重构后节省内存量效果非常明显,特别对于存储小对象的场景,内存只有不到原来的1/5。下面分析这种内存优化技巧的关键点:
- hash类型节省内存的原理是使用ziplist编码,如果使用hashtable编码方式反而会增加内存消耗。
- ziplist长度需要控制在1000以内,否则由于存取操作时间复杂度在O(n)到O(n2)之间,长列表会导致CPU消耗严重,得不偿失。
- ziplist适合存储小对象,对于大对象不但内存优化效果不明显还会增加命令操作耗时。
- 需要预估键的规模,从而确定每个hash结构需要存储的元素数量。
- 根据hash长度和元素大小,调整hash-max-ziplist-entries和hash-max-ziplist-value参数,确保hash类型使用ziplist编码。
关于hash键和field键的设计:
- 当键离散度较高时,可以按字符串位截取,把后三位作为哈希的field,之前部分作为哈希的键。如:key=1948480哈希key=group:hash:1948,哈希field=480。
- 当键离散度较低时,可以使用哈希算法打散键,如:使用crc32(key)&10000函数把所有的键映射到“0-9999”整数范围内,哈希field存储键的原始值。
- 尽量减少hash键和field的长度,如使用部分键内容。
使用hash结构控制键的规模虽然可以大幅降低内存,但同样会带来问题,需要提前做好规避处理。如下所示:
- 客户端需要预估键的规模并设计hash分组规则,加重客户端开发成本。
- hash重构后所有的键无法再使用超时(expire)和LRU淘汰机制自动删除,需要手动维护删除。
- 对于大对象,如1KB以上的对象,使用hash-ziplist结构控制键数量反而得不偿失。
不过瑕不掩瑜,对于大量小对象的存储场景,非常适合使用ziplist编码的hash类型控制键的规模来降低内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号