Tensorflow object detection API排雷记录【一】【适用新版本TensorFlow2.0x】
 Tensorflow object detection API排雷记录【一】 记录一下新版本TensorFlow安装和测试的一些问题。
Tensorflow object detection API排雷记录【一】 记录一下新版本TensorFlow安装和测试的一些问题。
这几天想要学习一下机器学习和物体检测,没想到却在安装和环境配置的地方卡了好久。
现如今把问题记录下来,希望以后看到的朋友可以少走弯路。
安装部分主要是参照两篇博客:
https://blog.csdn.net/dy_guox/article/details/79081499 【安装并测试自带样例】
https://blog.csdn.net/weixin_39290638/article/details/80045236【详细的安装介绍】
注意:
1. 安装TensorFlow最重要的是注意版本问题,尤其是CUDA的版本,要根据自己的显卡型号以及TensorFlow去寻找可行兼容的版本。
我的显卡是NVDIA GEFORCE MX150,于是选择了CUDA9.0和CUDNN7.1
CUDA官网下载速度很慢,如果觉得下载慢的一定要看准了再下载,而且尽量不要下载多个版本的CUDA,本人下载了CUDA8.0和CUDA9.0,后续安装过程会出现不知名的报错,后来卸载了CUDA8.0之后成功。
2. 安装时可能在第一篇博客的测试API部分的python object_detection/builders/model_builder_test.py指令时出现no module of TensorFlow报错的情况,原因在于只在anaconda环境下安装了TensorFlow,而没有在系统的python中安装TensorFlow。
具体的进入系统cmd的TensorFlow环境下安装TensorFlow参考了下面这篇博客:
https://blog.csdn.net/mysunday2/article/details/104300701
3. 前面都没有问题以后,在测试自带的样例部分会出现诸如RuntimeError: The Session graph is empty或者No module named session或者module 'tensorflow' has no attribute 'get_default_graph'等问题。
这些问题通常都是因为之前的安装教程博客都是前些年的,当时可能TensorFlow的最高版本就是1.7,而现在已经最高到2.0x版本,而直接执行pip install --upgrade tensorflow等命令时,会直接默认安装高版本2.0x的TensorFlow,导致与所给样例不兼容。
面对这种一般来讲不兼容的问题,我们一般只需要在报错的函数部分的tf部分加上.compat.v1变成与1.0x版本兼容即可。【下面附上修改过的各部分样例测试代码,如有需要需要可以参照修改】
【P.S】可以通过cmd的conda list命令来判断自己有没有安装TensorFlow以及安装的TensorFlow版本(如图)

import numpy as np import os import six.moves.urllib as urllib import sys import tarfile import tensorflow as tf import zipfile from distutils.version import StrictVersion from collections import defaultdict from io import StringIO from matplotlib import pyplot as plt from PIL import Image # This is needed since the notebook is stored in the object_detection folder. sys.path.append("..") from object_detection.utils import ops as utils_ops if StrictVersion(tf.__version__) < StrictVersion('1.9.0'): raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!') # This is needed to display the images. %matplotlib inline from utils import label_map_util from utils import visualization_utils as vis_util # What model to download. MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17' MODEL_FILE = MODEL_NAME + '.tar.gz' DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/' # Path to frozen detection graph. This is the actual model that is used for the object detection. PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb' # List of the strings that is used to add correct label for each box. PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt') ''' opener = urllib.request.URLopener() opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE) tar_file = tarfile.open(MODEL_FILE) for file in tar_file.getmembers(): file_name = os.path.basename(file.name) if 'frozen_inference_graph.pb' in file_name: tar_file.extract(file, os.getcwd()) ''' detection_graph = tf.Graph() with detection_graph.as_default(): od_graph_def = tf.compat.v1.GraphDef() with tf.compat.v1.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True) def load_image_into_numpy_array(image): (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8) # For the sake of simplicity we will use only 2 images: # image1.jpg # image2.jpg # If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS. PATH_TO_TEST_IMAGES_DIR = 'test_images' TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ] # Size, in inches, of the output images. IMAGE_SIZE = (12, 8) def run_inference_for_single_image(image, graph): with graph.as_default(): with tf.compat.v1.Session() as sess: # Get handles to input and output tensors ops = tf.compat.v1.get_default_graph().get_operations() all_tensor_names = {output.name for op in ops for output in op.outputs} tensor_dict = {} for key in [ 'num_detections', 'detection_boxes', 'detection_scores', 'detection_classes', 'detection_masks' ]: tensor_name = key + ':0' if tensor_name in all_tensor_names: tensor_dict[key] = tf.compat.v1.get_default_graph().get_tensor_by_name( tensor_name) if 'detection_masks' in tensor_dict: # The following processing is only for single image detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0]) detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0]) # Reframe is required to translate mask from box coordinates to image coordinates and fit the image size. real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32) detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1]) detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1]) detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks( detection_masks, detection_boxes, image.shape[0], image.shape[1]) detection_masks_reframed = tf.cast( tf.greater(detection_masks_reframed, 0.5), tf.uint8) # Follow the convention by adding back the batch dimension tensor_dict['detection_masks'] = tf.expand_dims( detection_masks_reframed, 0) image_tensor = tf.compat.v1.get_default_graph().get_tensor_by_name('image_tensor:0') # Run inference output_dict = sess.run(tensor_dict, feed_dict={image_tensor: np.expand_dims(image, 0)}) # all outputs are float32 numpy arrays, so convert types as appropriate output_dict['num_detections'] = int(output_dict['num_detections'][0]) output_dict['detection_classes'] = output_dict[ 'detection_classes'][0].astype(np.uint8) output_dict['detection_boxes'] = output_dict['detection_boxes'][0] output_dict['detection_scores'] = output_dict['detection_scores'][0] if 'detection_masks' in output_dict: output_dict['detection_masks'] = output_dict['detection_masks'][0] return output_dict for image_path in TEST_IMAGE_PATHS: image = Image.open(image_path) # the array based representation of the image will be used later in order to prepare the # result image with boxes and labels on it. image_np = load_image_into_numpy_array(image) # Expand dimensions since the model expects images to have shape: [1, None, None, 3] image_np_expanded = np.expand_dims(image_np, axis=0) # Actual detection. output_dict = run_inference_for_single_image(image_np, detection_graph) # Visualization of the results of a detection. vis_util.visualize_boxes_and_labels_on_image_array( image_np, output_dict['detection_boxes'], output_dict['detection_classes'], output_dict['detection_scores'], category_index, instance_masks=output_dict.get('detection_masks'), use_normalized_coordinates=True, line_thickness=8) plt.figure(figsize=IMAGE_SIZE) plt.imshow(image_np)
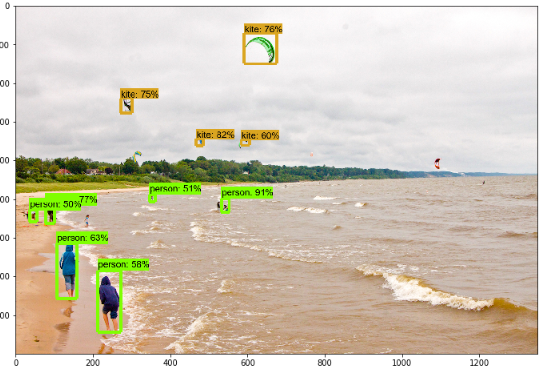
修改过后,运行样例,成功!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号