操作系统-IA32的地址转换
概述
该篇介绍的是 IA-32/Linux中的地址转换 , 转化的动机是什么? 是如何转化的 ?
下文的 段描述符 和 描述符表 太难理解, 可以近似认为
段描述符 = 段表项 , 描述符表 = 段表
逻辑地址 线性地址 物理地址

逻辑地址和线性地址的的转化如下 :
逻辑地址 --- (分段) ---> 线性地址 --- (分页) ---> 物理地址
寄存器
IA-32 的寄存器
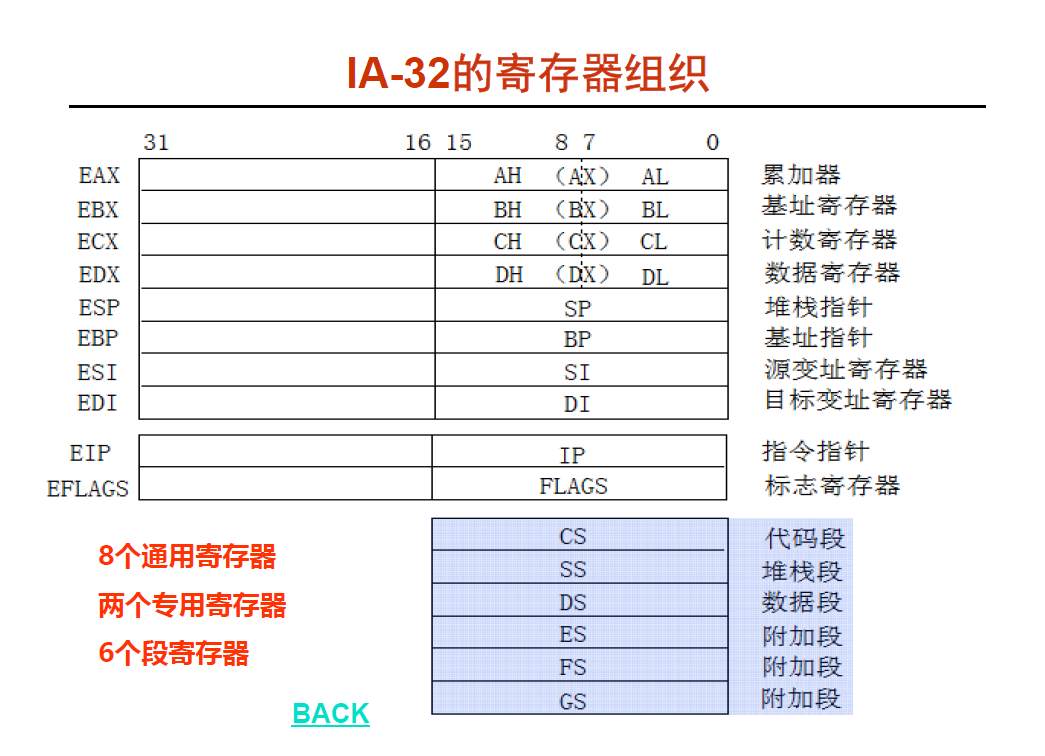
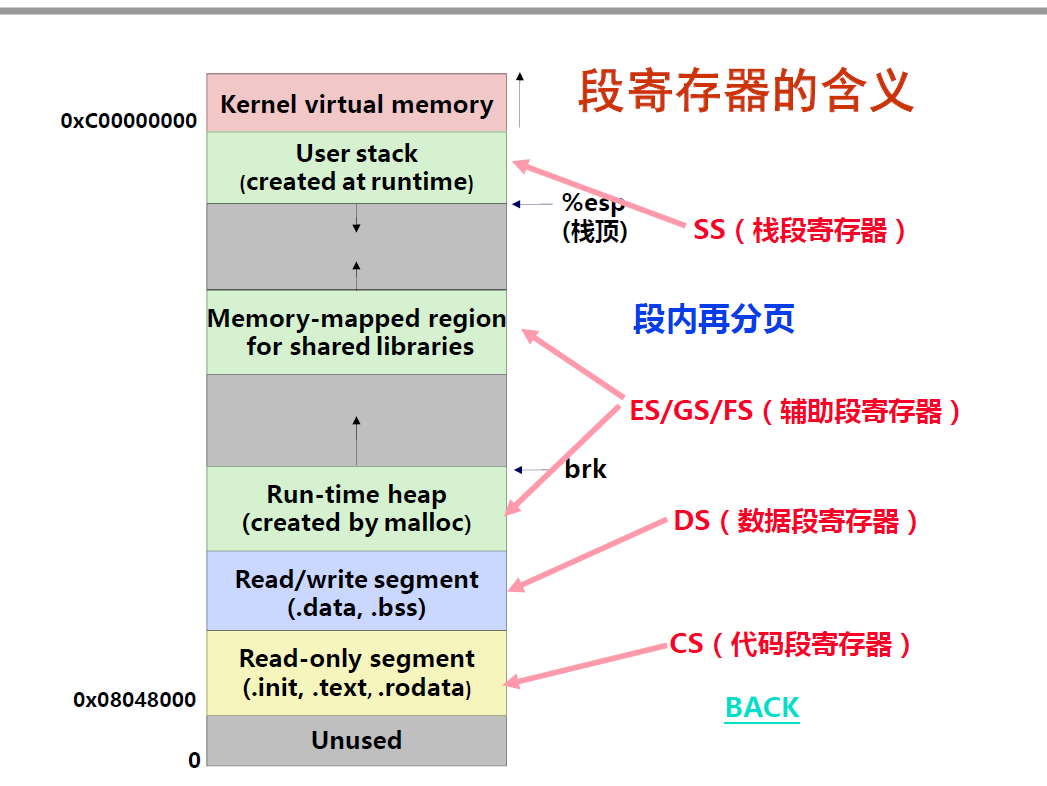
下面很明显是个进程, 而进程中的各种段存在在哪些段寄存器
段选择符
作用 : 指定哪一个段表 , 在段表的什么位置的那一个段表项(段表的偏移量)
目的 : 程序获取到了段选择符最终是为了获取到段描述符 ,记住这一点很重要
每个进程都有一个段表
段寄存器(16位就是 CS SS DS那些) : 每个进程都有不同的段区间 ,就是不同的section , 假如进程A ,取指令的时候 ,那么 CS 段寄存器存放的就是 进程A 代码段的一个描述符(描述这个段信息的结构称之为 "段描述符") , 段描述符由三部分组成 : 权限 + 类型 + 索引 , 段描述符类型分两种 ,一种 GDT ,一种 LDT

全局描述表(GDT) 和 局部描述符表(LDT) , 这两个是段表 , 即是表明这个段描述符是来自哪个段表的!!
段表 段表项分类
我们认真想想, 按照功能分 ,肯定会有不同的段表 , 每种段表既然功能不同 ,那么里面的段表项就不一样 .
(这张PPT , 上面的是段表项的分类 ,下面的是段表的分类 )

介绍段表
GDT整个系统只有一个 , TSS在 GDT 中, 可以看到GDT 的第16项是 TSS , 段选择符是 0x80
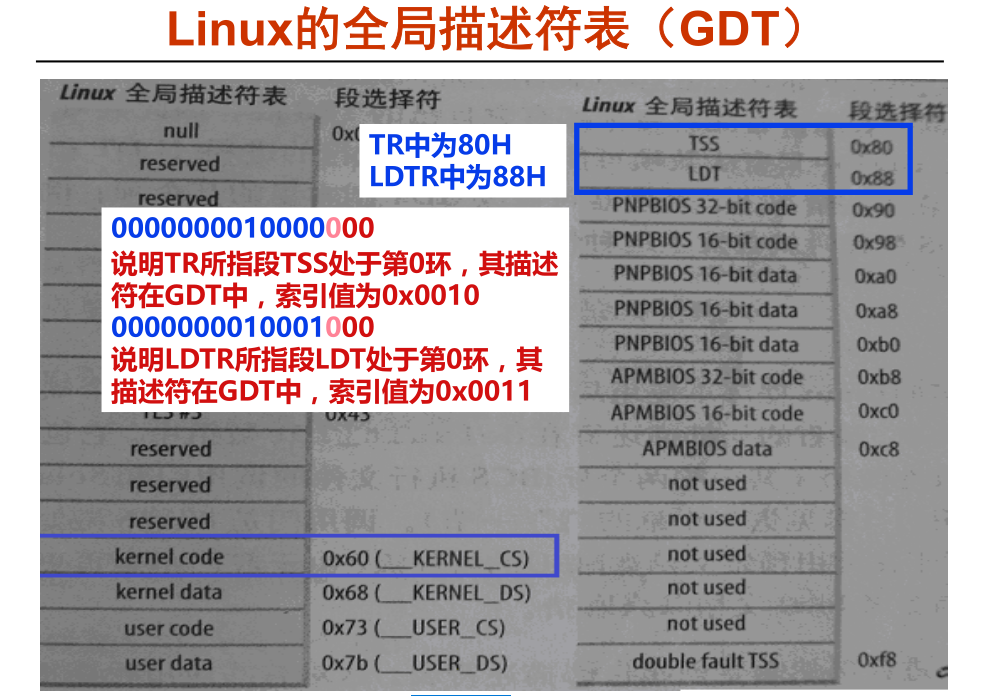
左下角 kernel_code , kernel_data , user_code , user_data , 后面的段选择符 ,__KERNEL_CODE (值 : 0x60) 是Linux 的宏(常量),
问题1 : 全局描述表(GDT Global Descriptor Table) 只有一个,里面有用户代码段,用户数据段以及TSS , 也就是说每个进程的代码段都要放进 GDT 里去吗??
问题2 : 段表放在哪 ? 什么时候加载进去的
段表在内存里面 , 在操作系统启动就得加载进去吧?
介绍段表项
通过 GDT 或是 LDT 找到段描述符 , 我们来看一下段描述符长什么样
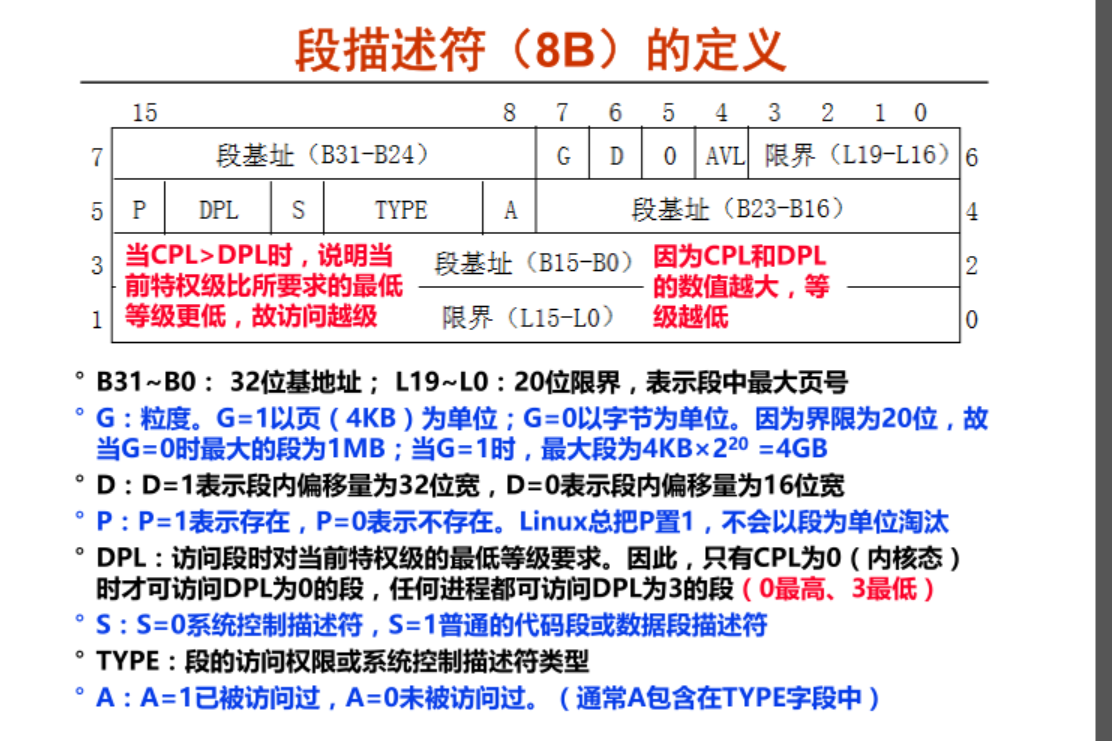
可以看到组成有 : 段基地址 + 限界 + 标志位 , S 这个表示的是: 系统段表项还是普通段表项 , A 类似于脏页一样的标识 , 这里还有一个 P ,
问题1 : 段表项 P 的作用是啥 ?
P = 0 表示这一页在不在主存 , Linux 默认它总是为 1 ,表示段一直在内存 ,即是 Linux 只考虑分页 ,不考虑分段, 假如是8086 这些机器的呢? P=0 表示该段不在内存中 ,那么得先加载段 .
段表项的缓存
换进程的时候 ,CS ,SS ,DD 这些寄存器里的段选择符就会给换走 , 段选择符目的 : 程序获取到了段选择符最终是为了获取到段描述符 ,段选择符 --> 段表 --> 段表项 那要是CPU 每次都去内存拿段表项太慢了, 所以肯定有个缓存 ,这个缓存就是寄存器 ,GDTR 会放 GDT 的首地址
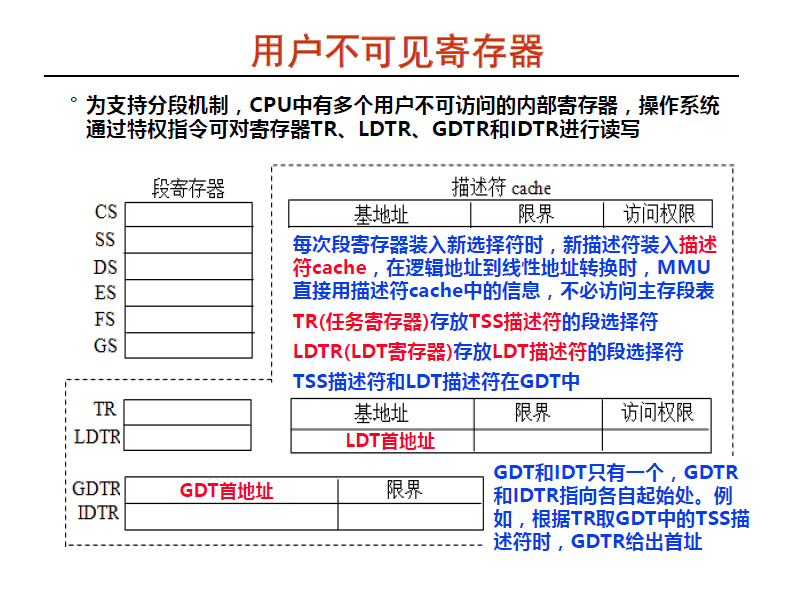
上面PPT 的蓝色字写到换新进程的时候 , 会利用cache缓存段表项 , 还有一个点就是Linux 把描述符 cache 的基地址设置为 0 , 表示那某个段表的第一项 ,而Linux 中 GDT 的第一项是空的,
我们再看回刚才介绍段表的图片 :
GDT 的第16项是 TSS , 段选择符是 0x80 , 那么寄存器 TR 里面放的就是 0x80 .
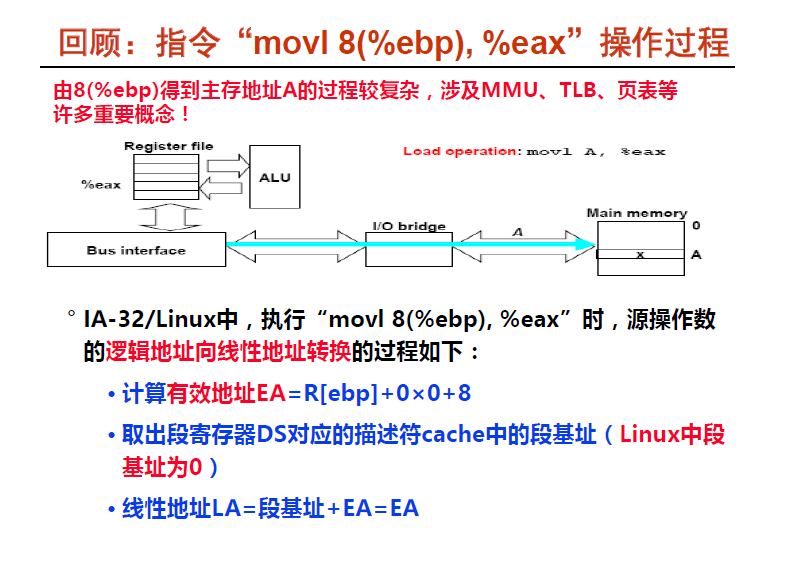
逻辑地址如何转化为线性地址
下图是是一个概括图, 得到一个逻辑地址后分为两部分, 一部分为了找到 段基址 , 另一部分是段内偏移量, 这两部分结合形成了线性地址
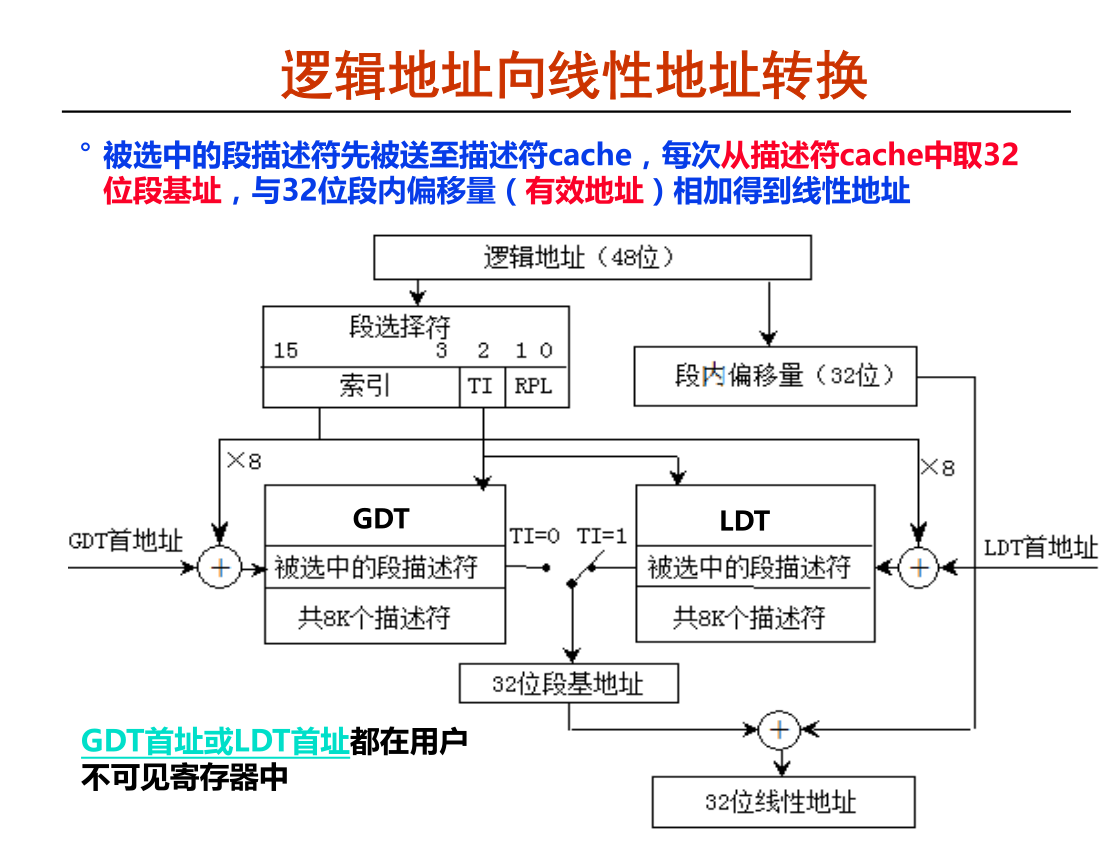
步骤
(1) 根据段描述符中的T1 的值判断是 GDT 还是 LDT
(2) 到 GDTR 中获取到 GDT 段首地址 , 加上偏移量, 就获取到了段表项 , 然后会把段表项放在 cache中去
(3) 段表项里有基地址 , 获取基地址加在段内偏移量 , 得到线性地址
这是第一次取的时候是这样 , 后面就可以到 cache 中去取
下面两张图也是阐述这个过程
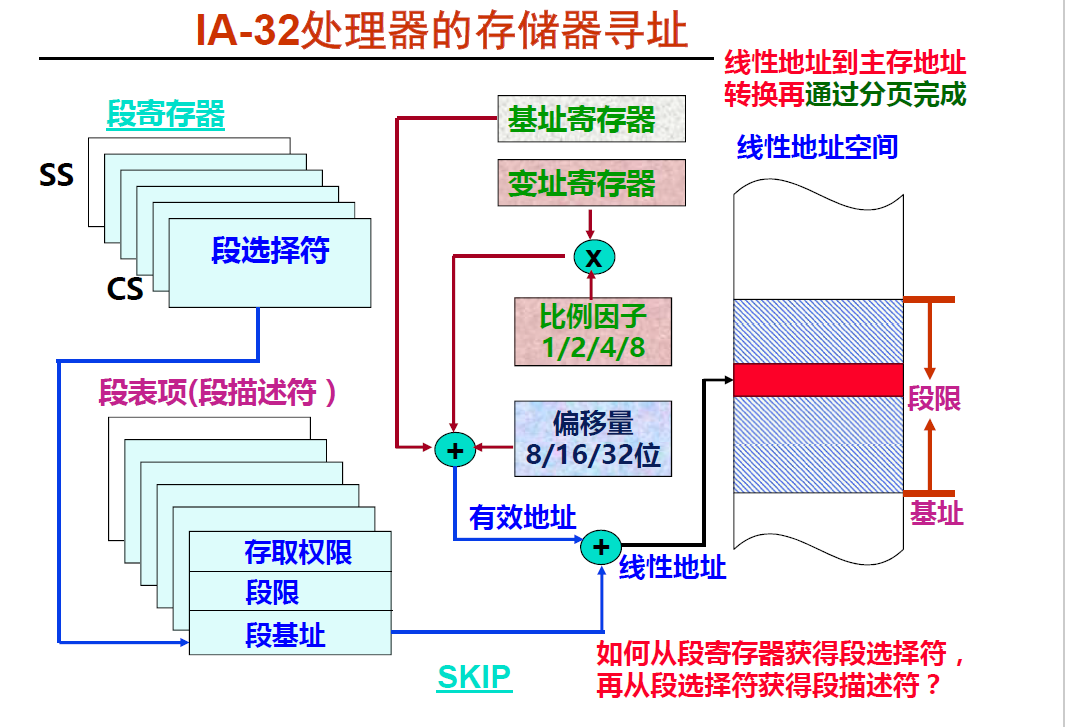
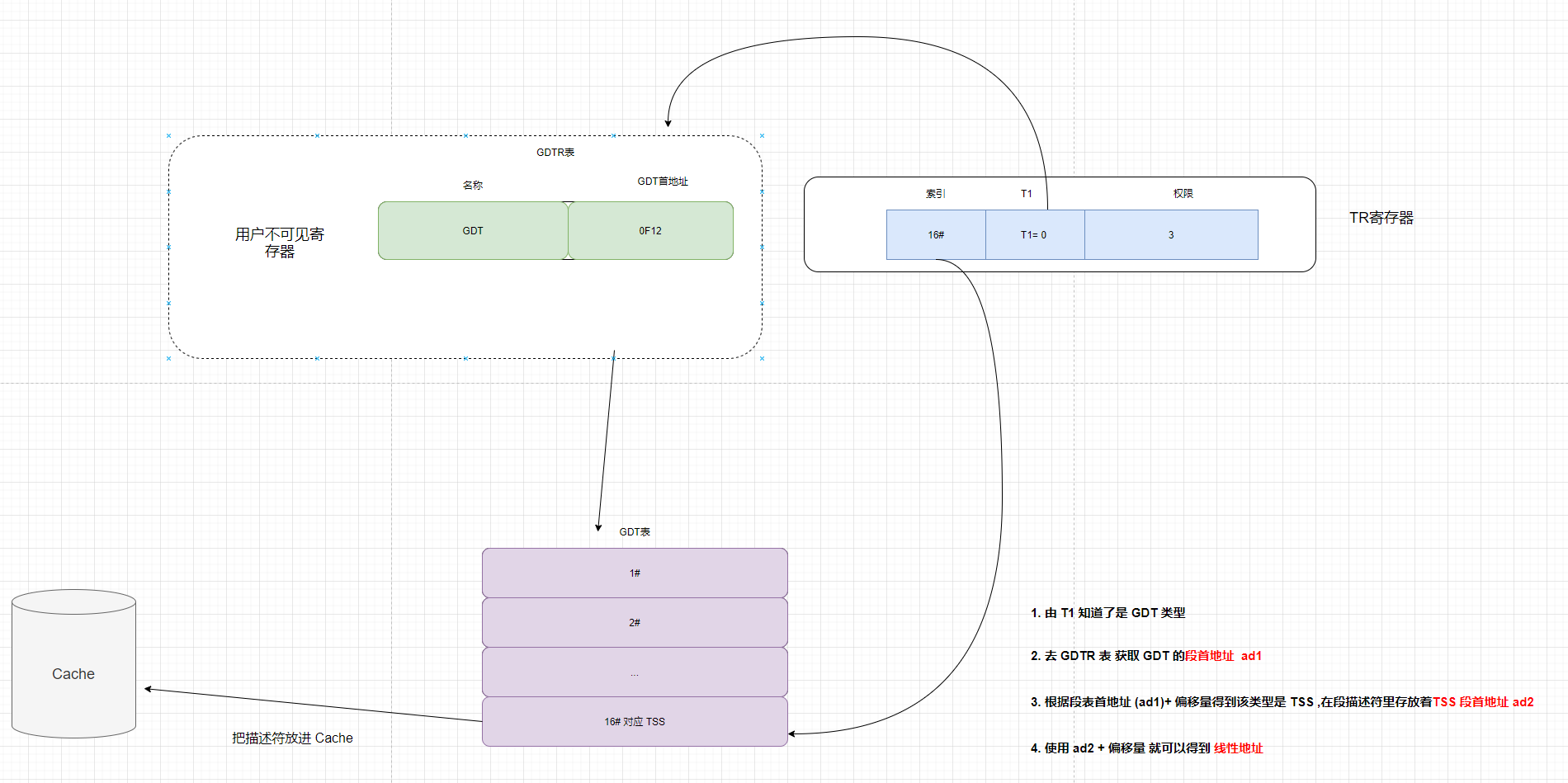
我们可以看到段寄存器中存放着段选择符, 而根据选择符又可以获得段表项 ,段表项又可以获得段基址, 得到段基址最终就得到了线性地址.
段寄存器 ---> 段选择符 ----> 段表项 ---> 段基址 ---> 线性地址
Linux 的分段处理
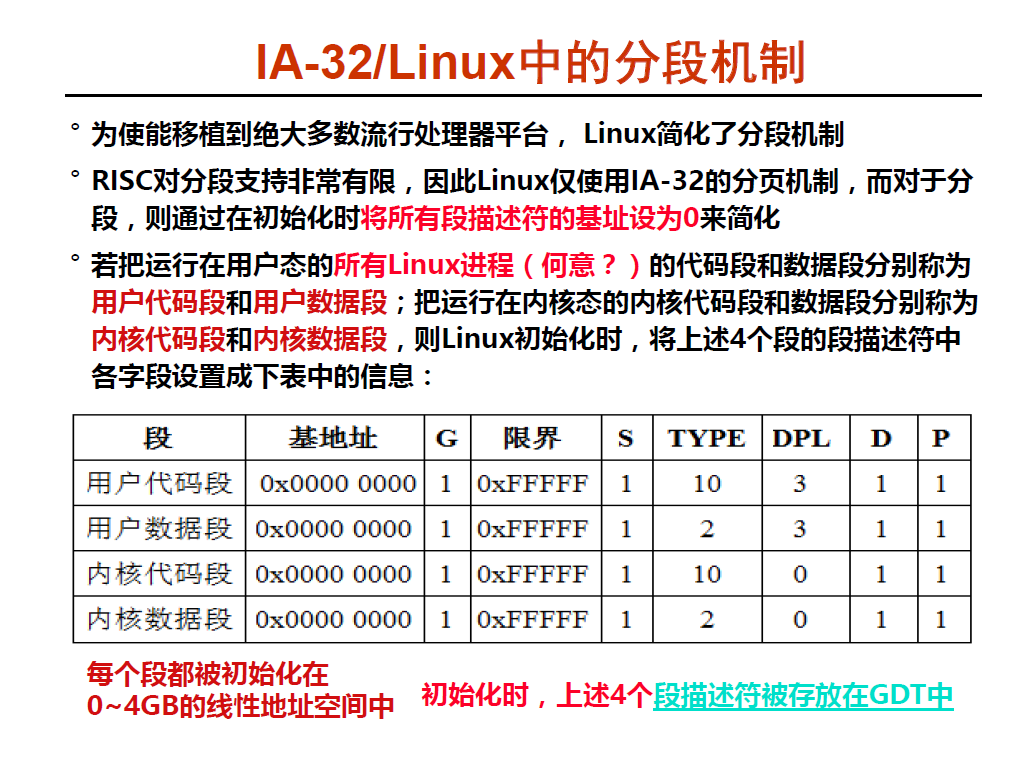

上图是 Linux 下的分段机制, 其为了扩展性,简化了分段机制, RISC 对分段支持非常有限, 但是IA-32 底层的硬件又提供了分段的功能,所以只能对其简化 ,可以看到用户和内核相关的代码和数据段的 基地址 全部设置为 0 , 限界设置为最大 ,全部为 1 , G = 1 , P = 1 , 相当于说每一个段都占了 4GB 的空间, 也就是说它不分段了, P = 1 ,表示它没有使用硬件的分段机制调进调出, 而是使用分页进行调进调出 .
可以看出来,它们的TI为0,表示都保存在全局段描述符表中。可能看到这里大家会有个疑问,既然用户段的RPL为3,那怎么去访问DPL为0的内核段呢,这就是linux精明的地方,它就是禁止用户态访问内核态的数据,但是内核为用户态开了两个小门,然用户态能够通过这两个小门进入到内核态中,这两个小门就是系统调用与中断和异常。
题外话
来自参考文章 :
Linux与Windows的分段机制原理上类似,都是扁平式的,段基址为0,也就是说CS,SS这些寄存器全部都是0,直接把整个虚拟内存看成一整个“段”。所以简单来说,它们并不想使用这个从16位系统遗留下来的分段机制,而CPU为了保持兼容性还保留了这些分段机制,所以现代OS大都使用这种扁平式的分段管理,将CPU「糊弄」过去。不过,这并不是说 Linux完全没有利用到段寄存器。事实上,Linux在实现线程本地存储(Thread Local Storage)的时候使用到了GS寄存器,用GS寄存器存储了TLS的基址,这样做的好处是加快了访问速度。之所以可以这么做也是因为Intel对FS,GS这些段寄存器的管理比较松散,Linux就刚好用它来干这个事儿了。
例子

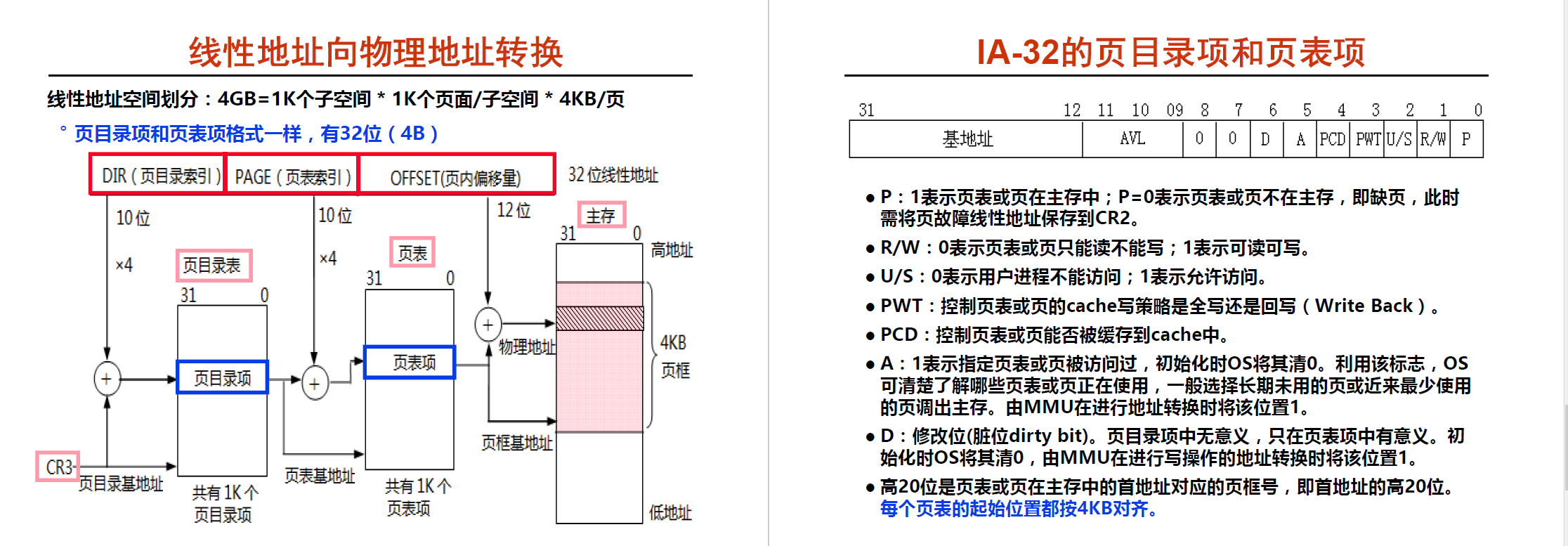
线性地址向物理地址转化
假如我们的主存是 4GB , 每页的大小是 4KB 我们来算一下分页模式下的页表项的数目 , 页表项的数目 = 主存大小 / 页大小 = 4GB / 4KB = 1024 * 1024
我们学过java知道假如用 hashmap 来储存这些页表项那么这个hashmap 也太大了吧, 所以可以进行分级 ,即 HashMap <页表项, HashMap <页表项, 内容> > ,即是说一级页表(称为页目录)就有1024 项(页目录项), 假设每一项大小为 4个字节(32位), 那么页目录项刚好为 4KB 一页. 明白了这个, 我们看一下分页地址过程
补充 I7 CPU 寻址过程
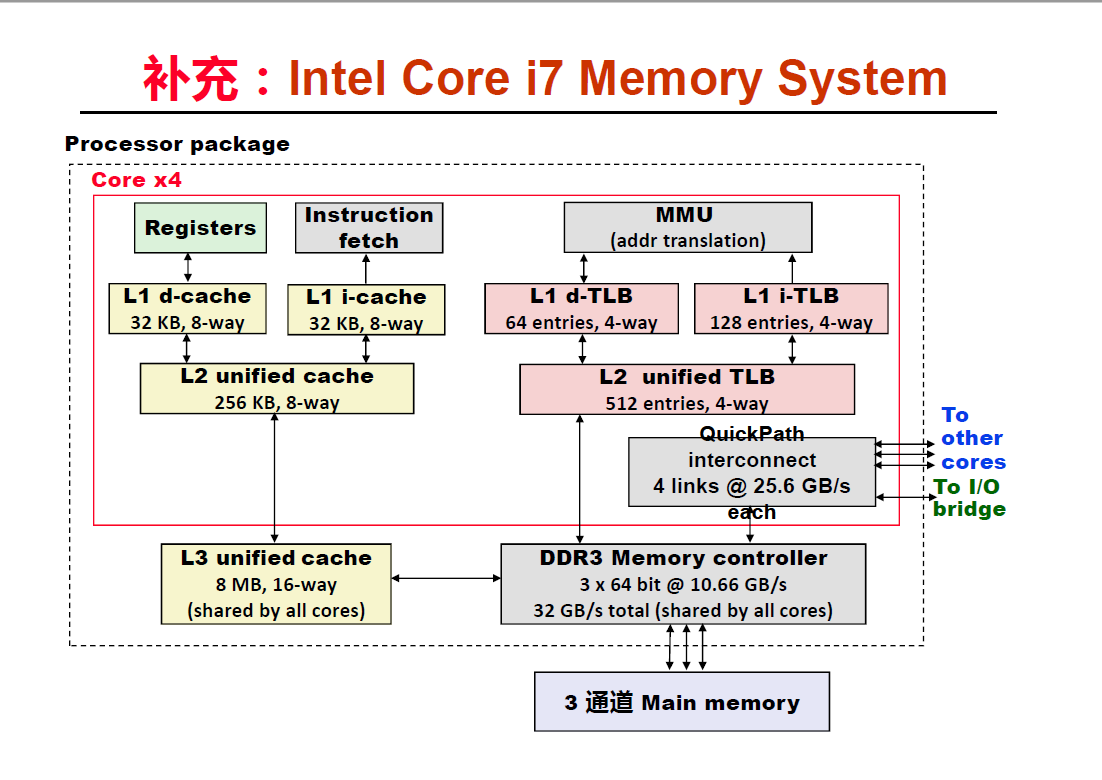
MMU 那个位置就是逻辑地址进行转换的地方
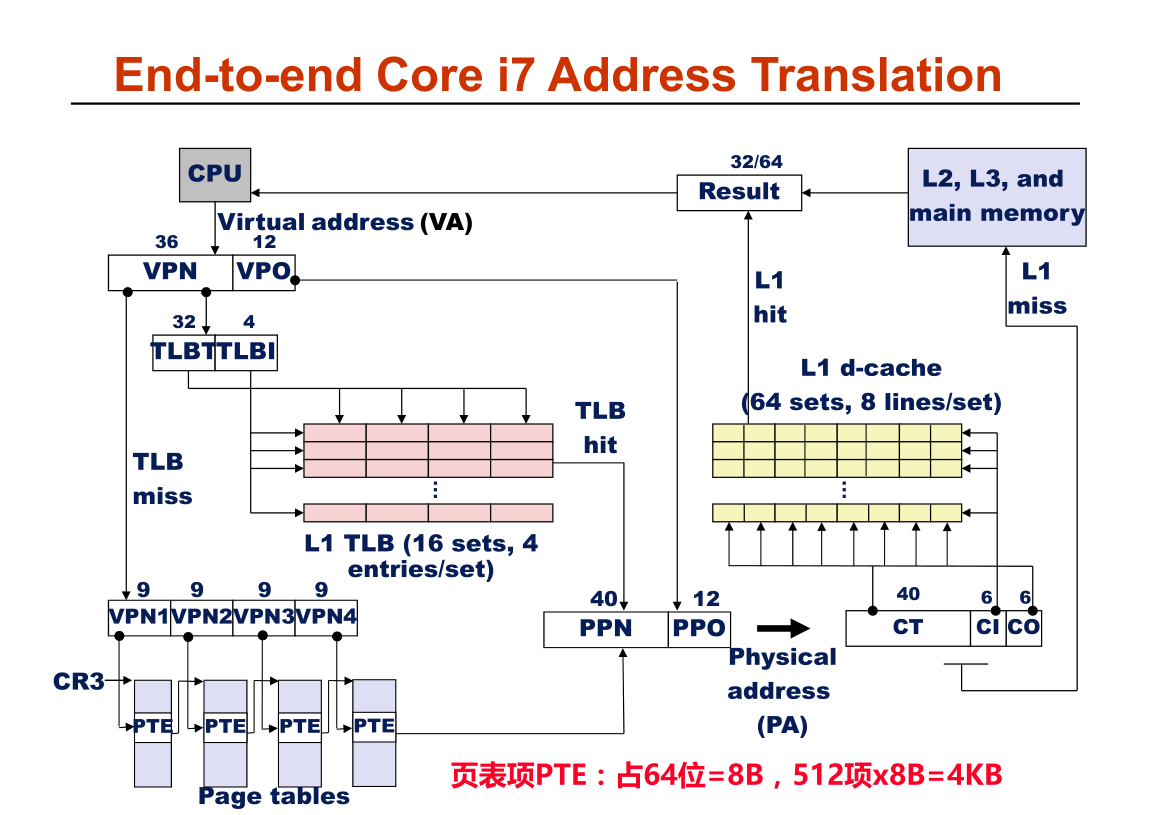
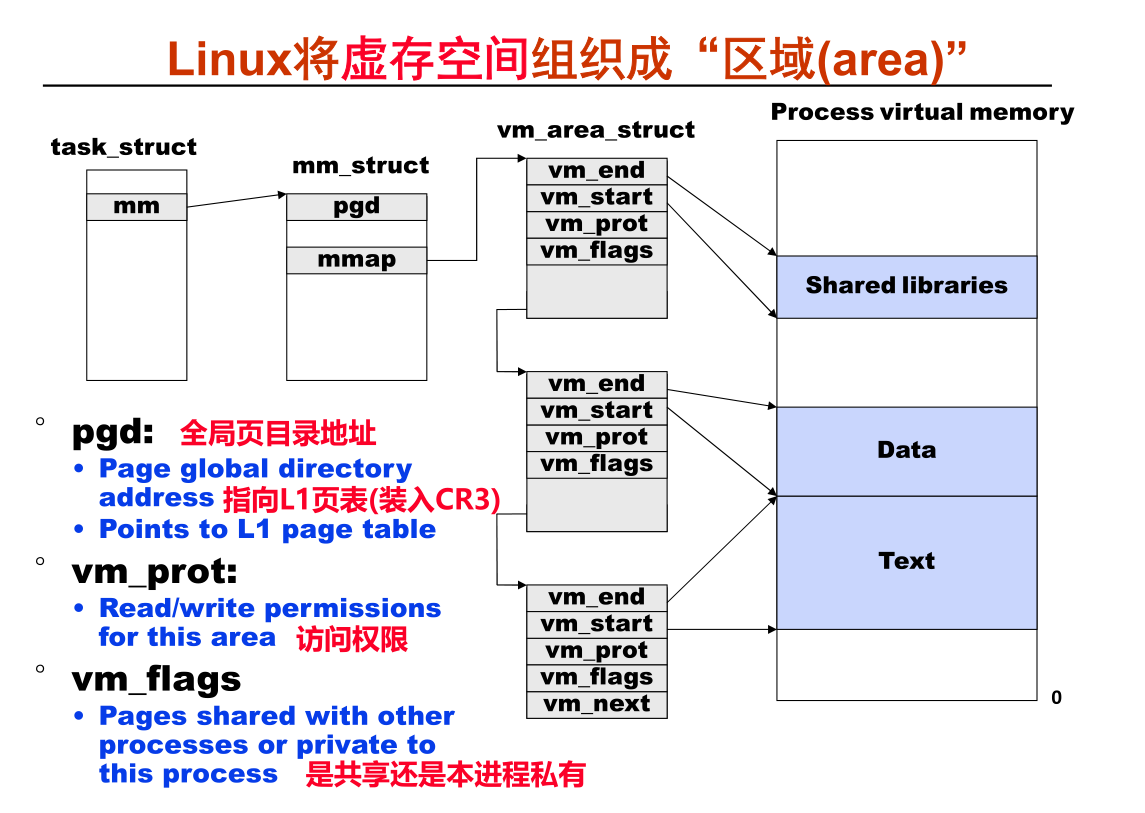
这里 linux 的任务的表示 ,其中 mm 这个字段存放这页表, 表示这个进程,占用的数据, 而这些数据被映射到物理内存中去, 于是就有页表映射,CPU 切换到那个进程, 该进程就应该把进程里的 全局目录地址 放置到 CR3 这个寄存器中 , 而今该寄存器才会去找对应的数据 (见上面两张图) ; mmap 指向的是一个链表 ,同时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号