unicode 字符,将普通的英文字符转换成各种“花式”字体
先放字:
𝓜𝔂 𝓵𝓸𝓿𝓮 𝓯𝓸𝓻 𝔂𝓸𝓾 𝔀𝓲𝓵𝓵 𝓷𝓮𝓿𝓮𝓻 𝓬𝓱𝓪𝓷𝓰𝓮!
今天在网上冲浪时,发现了一个非常有趣的网站:Visual Font。这个网站提供了一种“字体”样式转换功能,可以将普通的英文字符转换成各种“花式”字体。
更神奇的是,这些样式在复制到记事本、浏览器输入框,甚至是 QQ 聊天窗口中时,仍然能够保持样式不变!这明显超过了 windows 自带剪切板保留文字样式的能力,看起来非常不可思议 —— 🤟🤠🤡 果真如此吗?
📝 示例
先来看一个例子:
-
原始文本:Hello, this is beijiux, please follow me
-
转换后:
- 样式 1:𝓗𝓮𝓵𝓵𝓸, 𝓽𝓱𝓲𝓼 𝓲𝓼 𝓫𝓮𝓲𝓳𝓲𝓾𝔁, 𝓹𝓵𝓮𝓪𝓼𝓮 𝓯𝓸𝓵𝓵𝓸𝔀 𝓶𝓮
- 样式 2:𝗛𝗲𝗹𝗹𝗼, 𝘆𝗵𝗶𝘀 𝗶𝘀 𝗯𝗲𝗶𝗷𝗶𝘂𝘅, 𝗽𝗹𝗲𝗮𝘀𝗲 𝗳𝗼𝗹𝗹𝗼𝘄 𝗺𝗲
- 样式 3:HELLO, THIS IS BEIJIUX, PLEASE FOLLOW ME
分析与实现
不难猜测:这些“花式字体”实际上是利用了 Unicode 的特性。Unicode 是一种字符编码标准,包含了几乎所有语言和符号的字符。这些“花式字体”实际上是 Unicode 中的特殊字符,它们看起来像英文字母,但实际上并不是标准的 ASCII 字符。
print(isinstance("𝕰𝖝𝖆𝖒𝖕𝖑𝖊",str))
print(ord("𝖆"))
print(ord("𝖇"))
输出
True
120198
120199
我并不知道一共有多少 unicode 字符符合我的需求,也不知道它的编码范围,所以先输出 1~1114111 内的所有 unicode 字符
import unicodedata
# 打开文件以写入 UTF-8 编码
with open("unicode_chars.txt", "w", encoding="utf-8") as file:
for i in range(1, 1114111):
try:
# 获取码位对应的字符
c = chr(i)
# 检查字符是否是定义的 Unicode 字符
if unicodedata.category(c)[0] != 'C':
file.write(c + " ")
except UnicodeEncodeError:
# 如果发生编码错误,跳过该码位
pass
提醒您:
1.Unicode 字符数量庞大,基本上没有一个字体包含了所有 Unicode 字符,而如果你使用的是 windows 的默认字体,写入的字符得有将近一半无法正确显示.一个建议是更改当前编辑器的默认字体:Noto 字体 是由 Google 和 Adobe 联合开发的一种字体,旨在覆盖所有 Unicode 字符,避免显示“豆腐块”(即无法显示的字符) 2.而我使用的是NotoUnicode-5.otf,该项目声称包含了几乎所有 unicode 字符,实际使用效果是:99%以上的 unicode 字符可以被正确显示 3.当然,如果你只是想将普通英文文本转换为“花式字体”,那么不必进行这一步,这些字符在大部分字体的涵盖范围内.
题外话:汉字的整齐排列实在优雅,赏心悦目,尽管我基本上不认识,实在汗颜 😥😦😧😨😩😪😫😬😭
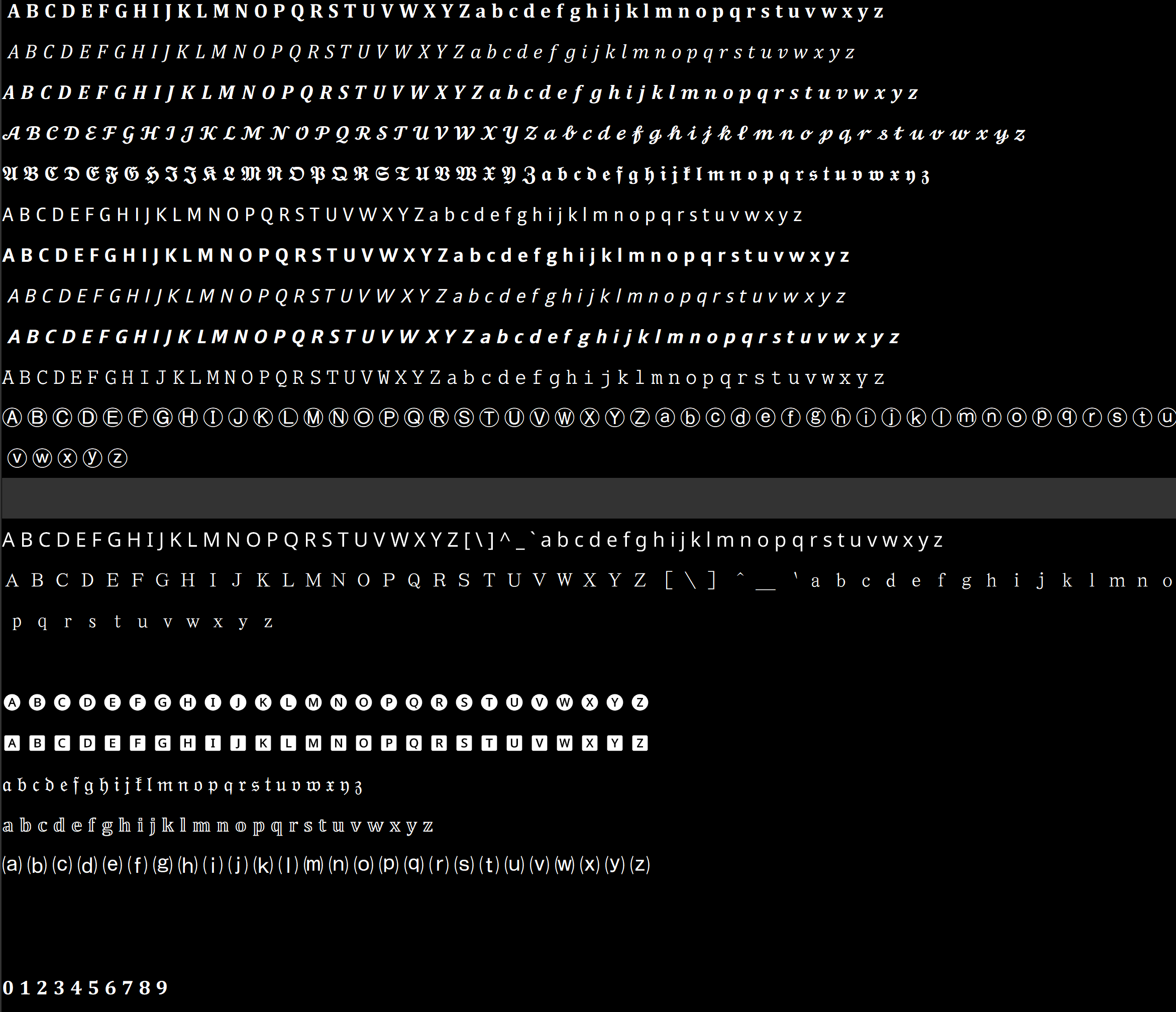
我们从中凭肉眼找到可以作为"英文字体"字符,再手动去除掉不合适的(字母数不全的,顺序不一样的).
剩下的可以分为三类:
- 和基本英文字符一样:先大写字母,再小写字母,中间隔了
[ \ ] ^ _ `这六个字符 - 先大写,紧接着小写
- 只有大写或小写
计算编码差
# 例
print(ord("𝓐")-ord("A"))
print(ord("A")-ord("⒜"))
以下是一个简单的 Python 实现,可以将普通文本转换为这些“花式字体”:
difference_1 = [119743,119795,119847,119951,120107,120159,120211,120263,120315,120367,9333]
difference_2 = [127247,127279,120029,120081,9307]
Bstart,Bend,bstart,bend = map(ord,["A","Z","a","z"])
def ConvertFormate_1(IPT):
for i in IPT:
try:
tmp = ord(i)
if tmp >= Bstart and tmp <= bend:
tmp += 65248
print(chr(tmp),end = "")
else:
print(i,end = "")
except:
print(i,end = "")
def ConvertFormate_2(IPT):
for difference in difference_1:
print()
for i in IPT:
try:
tmp = ord(i)
if tmp >= Bstart and tmp <= Bend:
tmp += difference
print(chr(tmp),end = "")
elif tmp >= bstart and tmp <= bend:
tmp += difference
tmp -= 6
print(chr(tmp),end = "")
else:
print(i,end = "")
except:
print(i,end = "")
def ConvertFormate_3(IPT):
for difference in difference_2:
print()
for i in IPT:
try:
tmp = ord(i)
if tmp >= Bstart and tmp <= Bend:
tmp += difference
print(chr(tmp),end = "")
elif tmp >= bstart and tmp <= bend:
tmp += difference
tmp -= 32
print(chr(tmp),end = "")
else:
print(i,end = "")
except:
print(i,end = "")
ipt = list(input())
ConvertFormate_1(ipt)
ConvertFormate_2(ipt)
ConvertFormate_3(ipt)
输出样例
Hello, my friend.这里是 BeijiuX
𝐇𝐞𝐥𝐥𝐨, 𝐦𝐲 𝐟𝐫𝐢𝐞𝐧𝐝.这里是 𝐁𝐞𝐢𝐣𝐢𝐮𝐗
𝐻𝑒𝑙𝑙𝑜, 𝑚𝑦 𝑓𝑟𝑖𝑒𝑛𝑑.这里是 𝐵𝑒𝑖𝑗𝑖𝑢𝑋
𝑯𝒆𝒍𝒍𝒐, 𝒎𝒚 𝒇𝒓𝒊𝒆𝒏𝒅.这里是 𝑩𝒆𝒊𝒋𝒊𝒖𝑿
𝓗𝓮𝓵𝓵𝓸, 𝓶𝔂 𝓯𝓻𝓲𝓮𝓷𝓭.这里是 𝓑𝓮𝓲𝓳𝓲𝓾𝓧
𝕳𝖊𝖑𝖑𝖔, 𝖒𝖞 𝖋𝖗𝖎𝖊𝖓𝖉.这里是 𝕭𝖊𝖎𝖏𝖎𝖚𝖃
𝖧𝖾𝗅𝗅𝗈, 𝗆𝗒 𝖿𝗋𝗂𝖾𝗇𝖽.这里是 𝖡𝖾𝗂𝗃𝗂𝗎𝖷
𝗛𝗲𝗹𝗹𝗼, 𝗺𝘆 𝗳𝗿𝗶𝗲𝗻𝗱.这里是 𝗕𝗲𝗶𝗷𝗶𝘂𝗫
𝘏𝘦𝘭𝘭𝘰, 𝘮𝘺 𝘧𝘳𝘪𝘦𝘯𝘥.这里是 𝘉𝘦𝘪𝘫𝘪𝘶𝘟
𝙃𝙚𝙡𝙡𝙤, 𝙢𝙮 𝙛𝙧𝙞𝙚𝙣𝙙.这里是 𝘽𝙚𝙞𝙟𝙞𝙪𝙓
𝙷𝚎𝚕𝚕𝚘, 𝚖𝚢 𝚏𝚛𝚒𝚎𝚗𝚍.这里是 𝙱𝚎𝚒𝚓𝚒𝚞𝚇
Ⓗⓔⓛⓛⓞ, ⓜⓨ ⓕⓡⓘⓔⓝⓓ.这里是 ⒷⓔⓘⓙⓘⓤⓍ
🅗🅔🅛🅛🅞, 🅜🅨 🅕🅡🅘🅔🅝🅓.这里是 🅑🅔🅘🅙🅘🅤🅧
🅷🅴🅻🅻🅾, 🅼🆈 🅵🆁🅸🅴🅽🅳.这里是 🅱🅴🅸🅹🅸🆄🆇
𝔥𝔢𝔩𝔩𝔬, 𝔪𝔶 𝔣𝔯𝔦𝔢𝔫𝔡.这里是 𝔟𝔢𝔦𝔧𝔦𝔲𝔵
𝕙𝕖𝕝𝕝𝕠, 𝕞𝕪 𝕗𝕣𝕚𝕖𝕟𝕕.这里是 𝕓𝕖𝕚𝕛𝕚𝕦𝕩
⒣⒠⒧⒧⒪, ⒨⒴ ⒡⒭⒤⒠⒩⒟.这里是 ⒝⒠⒤⒥⒤⒰⒳
🎯 应用场景
这种“花式字体”转换技巧可以用于:
- 社交媒体:让你的文案更具个性。
- 聊天工具:在 QQ、微信等聊天工具中发送独特的消息。
- 网页设计:为网页内容添加视觉效果。
🚧 注意事项
- 兼容性:并非所有平台都支持这些特殊字符,可能会显示为乱码。
- 可读性:过于花哨的字符可能会影响阅读体验,需谨慎使用。
- 编码范围:Unicode 字符数量庞大,需确保转换后的字符在合法范围内。
你可以复制上面代码,在本地尝试一下,如果你本地没有安装 python 解释器,后面我也会制作一个简单的在线转换工具,以供使用
关注公众号,私信我,发送关键词: 不可更改的字体,获取相关所有资料.
@ 𝒃𝒚 𝑩𝒆𝒊𝒋𝒊𝒖𝑿,𝑩𝒆𝒊𝒋𝒊𝒖𝑺
CONVERSION
│ conversion.py # 可执行文件
│
├─材料
│ [全]unicode_chars.txt
│ [处理后]UNICODE.txt # 处理后
│
└─相关图片
hanzi.gif
list.png
如果你想要我直接提供转换后的“花式字体”,可以直接在评论区或私信告诉我,非常乐意效劳!
注:您可以自由复制,更改和使用本文内容以及我提供的材料,但必须注明来源——材料来源自微信公众号 BeijiuX
关注 BeijiuX 公众号,查看更多内容.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号









