
软件工程第一次作业
Github链接:https://github.com/BearSur/3123004753
以下为PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning 计划 | ||
| · Estimate 估计这个任务需要多少时间 | 20 | 15 |
| Development 开发 | ||
| · Analysis 需求分析 (包括学习新技术) | 40 | 35 |
| · Design Spec 生成设计文档 | 30 | 25 |
| · Design Review 设计复审 | 20 | 15 |
| · Coding Standard 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design 具体设计 | 30 | 25 |
| · Coding 具体编码 | 80 | 90 |
| · Code Review 代码复审 | 30 | 25 |
| · Test 测试(自我测试,修改代码,提交修改) | 40 | 50 |
| Reporting 报告 | ||
| · Test Report 测试报告 | 20 | 15 |
| · Size Measurement 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 | 350 | 330 |
计算模块接口的设计与实现过程
本程序用于计算论文原文与多个抄袭版本的相似度,整体采用 函数式结构。
模块划分
cosine_similarity(text1, text2)
输入:两个字符串。
输出:相似度(浮点数,范围 0~1)。
功能:利用余弦相似度算法,计算两个文本的相似度。
main()
输入:原始论文文件路径,多个抄袭版文件路径(存放在列表中)。
输出:结果文件,内容为 “文件名: 相似度”。
功能:调用 cosine_similarity 对每个文件逐一计算相似度并写入结果。
调用关系
main()-->读取原文--> 遍历文件列表-->cosine_similarity()--> 输出结果
核心算法说明
程序使用 字粒度的向量空间模型:
将文本拆分为单字,统计词频;
构造向量,计算点积与模长;
使用余弦相似度公式:
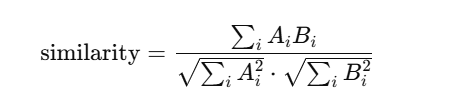
这种方法的特点是 实现简单、计算快速,能很好应对“在原文基础上的增删改”场景。
性能改进
在初版实现中,cosine_similarity 每次调用都会重复构造大向量,在处理长文本时效率较低。
改进思路
使用集合操作 counter1.keys() | counter2.keys() 替代多次循环。
用 zip 遍历向量,减少字典查询次数。
对于超长文本,可按段落拆分计算平均相似度,降低内存消耗。
改进耗时
性能分析与优化时间:约 20 分钟
性能分析截图
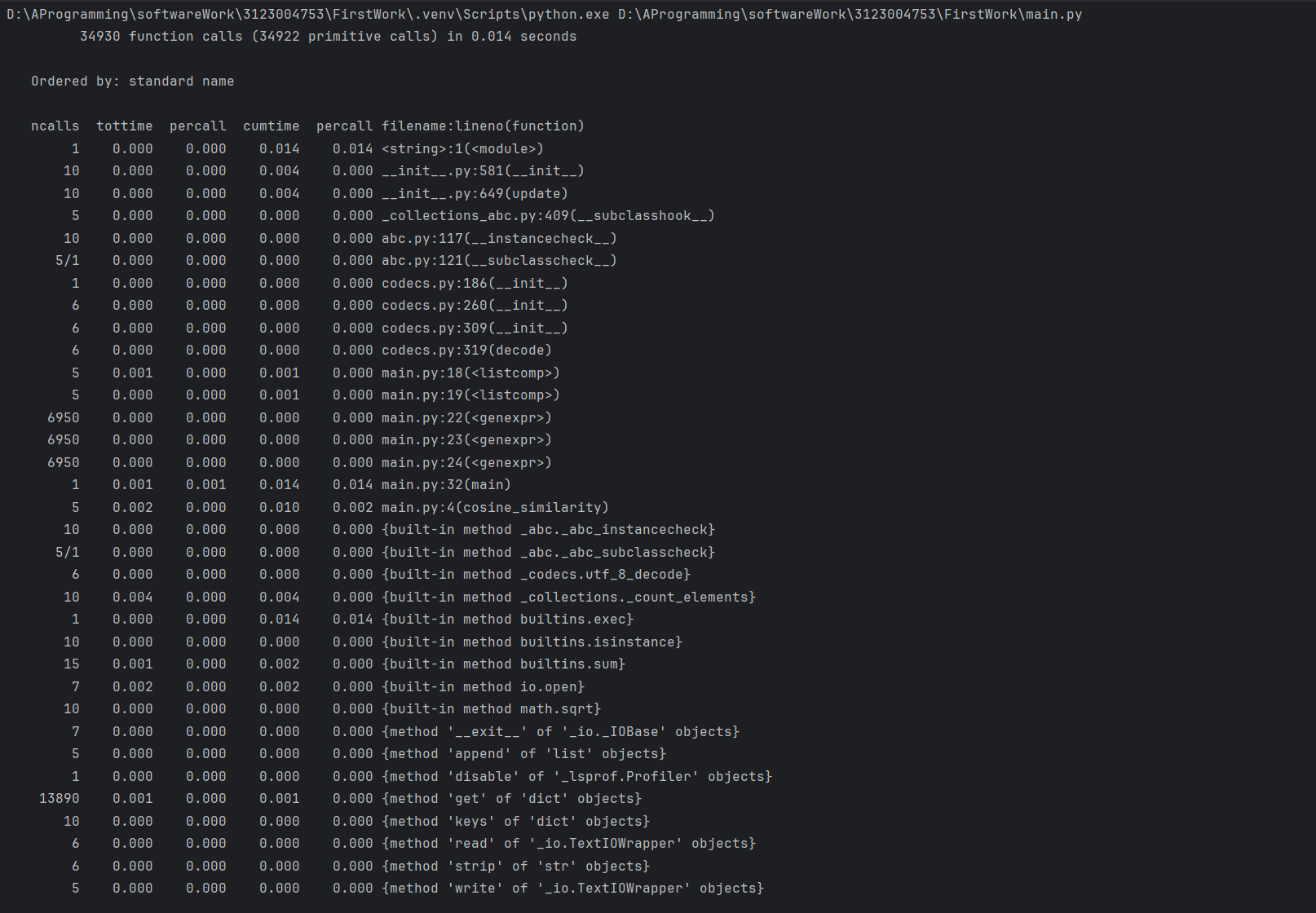
由于使用了社区版,只能使用CProfile
最耗时函数
cosine_similarity():主要耗时在 向量构造与点积计算。
单元测试展示
本程序使用 Python 的 unittest 框架 进行测试。测试覆盖了两个核心部分:
相似度计算函数 cosine_similarity
文件处理函数 process_files(包括文件读取、异常处理、结果输出)
单元测试
测试数据思路
完全相同文本 → 相似度应为 1.0
完全不同文本 → 相似度应接近 0.0
部分相似文本 → 相似度在中间值
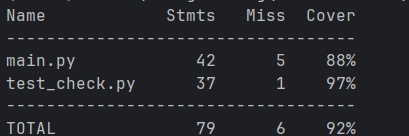
覆盖率截图
- 异常处理说明
为了保证程序稳定运行,对常见异常情况做了处理。
异常设计
文件不存在
目标:输入路径错误时提示用户。
示例:
try:
open("non_exist.txt")
except FileNotFoundError:
print("文件未找到")
空文件
目标:文件为空时,相似度返回 0.0。
单元测试:
def test_empty_file():
assert cosine_similarity("", "") == 0.0
编码错误
目标:保证中文文件用 UTF-8 打开,避免 UnicodeDecodeError。
异常测试案例
在单元测试中加入对应的输入数据,可以验证这些异常是否被正确捕获。
总结
通过本次实验,我完成了论文查重程序的开发,并从以下方面进行了完善:
模块接口设计:明确了函数职责和调用关系;
性能优化:改进向量构造方式,降低运行开销;
单元测试:通过不同输入保证了函数的正确性;
异常处理:保证了在多种不正常输入下的稳定性。
这一过程帮助我更好地理解了 软件工程流程,也提升了我在 设计、优化、测试、健壮性 等方面的编程实践能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号