0017-0021 教程学习笔记
0017 SpringBoot
1.默认配置
Spring Boot默认提供静态资源目录位置需置于classpath下,目录名需符合如下规则:
/static
/public
/resources
/META-INF/resources
举例:我们可以在src/main/resources/目录下创建static,在该位置放置一个图片文件。启动程序后,尝试访问http://localhost:8080/D.jpg。如能显示图片,配置成功。
2.全局捕获异常
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(RuntimeException.class)
@ResponseBody
public Map<String, Object> exceptionHandler() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("errorCode", "101");
map.put("errorMsg", "系統错误!");
return map;
}
}
3.分布式事务解决方案
1)automatic+jta(把多个数据源交给automatic处理,autuomatic会自动帮忙回滚事务)
2)两段提交事务
3) MQ推送
0018 redis
第一节
1.redis和memcached区别?
redis可以持久化,重启的时候可以再次加载使用,memcached不支持持久化
redis比memcached支持的数据类型更加丰富redis同时支持list,set,zset,hash
第二节 redis应用场景
1.redis应用场景?
1.减去数据访问压力
2.session共享解决方案
3.忘记密码中发送短信验证码,验证码有效期内放在redis中
2.jredis相关操作
public class TestRedis {
private Jedis jedis;
@Before
public void setup() {
//连接redis服务器,192.168.0.100:6379
jedis = new Jedis("192.168.0.100", 6379);
//权限认证
jedis.auth("admin");
}
/**
* redis存储字符串
*/
@Test
public void testString() {
//-----添加数据----------
jedis.set("name","xinxin");//向key-->name中放入了value-->xinxin
System.out.println(jedis.get("name"));//执行结果:xinxin
jedis.append("name", " is my lover"); //拼接
System.out.println(jedis.get("name"));
jedis.del("name"); //删除某个键
System.out.println(jedis.get("name"));
//设置多个键值对
jedis.mset("name","liuling","age","23","qq","476777XXX");
jedis.incr("age"); //进行加1操作
System.out.println(jedis.get("name") + "-" + jedis.get("age") + "-" + jedis.get("qq"));
}
/**
* redis操作Map
*/
@Test
public void testMap() {
//-----添加数据----------
Map<String, String> map = new HashMap<String, String>();
map.put("name", "xinxin");
map.put("age", "22");
map.put("qq", "123456");
jedis.hmset("user",map);
//取出user中的name,执行结果:[minxr]-->注意结果是一个泛型的List
//第一个参数是存入redis中map对象的key,后面跟的是放入map中的对象的key,后面的key可以跟多个,是可变参数
List<String> rsmap = jedis.hmget("user", "name", "age", "qq");
System.out.println(rsmap);
//删除map中的某个键值
jedis.hdel("user","age");
System.out.println(jedis.hmget("user", "age")); //因为删除了,所以返回的是null
System.out.println(jedis.hlen("user")); //返回key为user的键中存放的值的个数2
System.out.println(jedis.exists("user"));//是否存在key为user的记录 返回true
System.out.println(jedis.hkeys("user"));//返回map对象中的所有key
System.out.println(jedis.hvals("user"));//返回map对象中的所有value
Iterator<String> iter=jedis.hkeys("user").iterator();
while (iter.hasNext()){
String key = iter.next();
System.out.println(key+":"+jedis.hmget("user",key));
}
}
/**
* jedis操作List
*/
@Test
public void testList(){
//开始前,先移除所有的内容
jedis.del("java framework");
System.out.println(jedis.lrange("java framework",0,-1));
//先向key java framework中存放三条数据
jedis.lpush("java framework","spring");
jedis.lpush("java framework","struts");
jedis.lpush("java framework","hibernate");
//再取出所有数据jedis.lrange是按范围取出,
// 第一个是key,第二个是起始位置,第三个是结束位置,jedis.llen获取长度 -1表示取得所有
System.out.println(jedis.lrange("java framework",0,-1));
jedis.del("java framework");
jedis.rpush("java framework","spring");
jedis.rpush("java framework","struts");
jedis.rpush("java framework","hibernate");
System.out.println(jedis.lrange("java framework",0,-1));
}
/**
* jedis操作Set
*/
@Test
public void testSet(){
//添加
jedis.sadd("user","liuling");
jedis.sadd("user","xinxin");
jedis.sadd("user","ling");
jedis.sadd("user","zhangxinxin");
jedis.sadd("user","who");
//移除noname
jedis.srem("user","who");
System.out.println(jedis.smembers("user"));//获取所有加入的value
System.out.println(jedis.sismember("user", "who"));//判断 who 是否是user集合的元素
System.out.println(jedis.srandmember("user"));
System.out.println(jedis.scard("user"));//返回集合的元素个数
}
@Test
public void test() throws InterruptedException {
//jedis 排序
//注意,此处的rpush和lpush是List的操作。是一个双向链表(但从表现来看的)
jedis.del("a");//先清除数据,再加入数据进行测试
jedis.rpush("a", "1");
jedis.lpush("a","6");
jedis.lpush("a","3");
jedis.lpush("a","9");
System.out.println(jedis.lrange("a",0,-1));// [9, 3, 6, 1]
System.out.println(jedis.sort("a")); //[1, 3, 6, 9] //输入排序后结果
System.out.println(jedis.lrange("a",0,-1));
}
@Test
public void testRedisPool() {
RedisUtil.getJedis().set("newname", "中文测试");
System.out.println(RedisUtil.getJedis().get("newname"));
}
4.Springboot使用redis
1)引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
2)配置文件
spring.redis.database=0
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.password=123456
spring.redis.pool.max-idle=8
spring.redis.pool.min-idle=0
spring.redis.pool.max-active=8
spring.redis.pool.max-wait=-1
spring.redis.timeout=5000
3)调用
@Service
public class RedisService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void setStr(String key, String value) {
setStr(key, value, null);
}
public void setStr(String key, String value, Long time) {
stringRedisTemplate.opsForValue().set(key, value);
if (time != null)
stringRedisTemplate.expire(key, time, TimeUnit.SECONDS);
}
public Object getKey(String key) {
return stringRedisTemplate.opsForValue().get(key);
}
public void delKey(String key) {
stringRedisTemplate.delete(key);
}
}
第十一节 redis主从复制
1. redis怎样实现高可用? 用哨兵机制,在读写分离的模式中,当写的服务器宕机,利用心跳得到机器宕机,会重新选举一个服务器作为写的机器
2. 主从配置:
修改从redis中的 redis.conf文件
slaveof 192.168.33.130 6379
masterauth 123456--- 主redis服务器配置了密码,则需要配置
3. 什么是哨兵机制
Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务:
· 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
· 提醒(Notification):当被监控的某个 Redis出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
· 自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用Master代替失效Master。
哨兵(sentinel) 是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossipprotocols)来接收关于Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master.
每个哨兵(sentinel) 会向其它哨兵(sentinel)、master、slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的”主观认为宕机” Subjective Down,简称sdown).
若“哨兵群”中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective Down,简称odown),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置.
虽然哨兵(sentinel) 释出为一个单独的可执行文件 redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动哨兵(sentinel).
哨兵(sentinel) 的一些设计思路和zookeeper非常类似
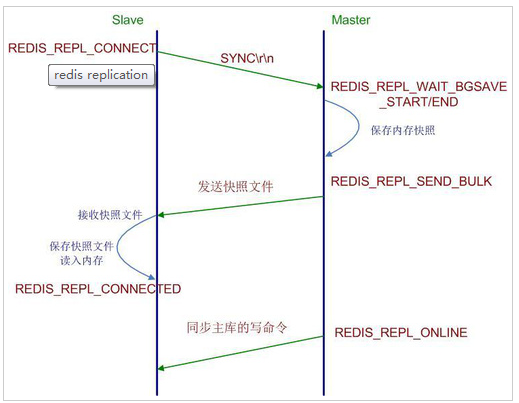
过程:
1:当一个从数据库启动时,会向主数据库发送sync命令,
2:主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来
3:当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。
4:从数据库收到后,会载入快照文件并执行收到的缓存的命令。
4. 哨兵模式修改配置
实现步骤:
1.拷贝到etc目录
cp sentinel.conf /usr/local/redis/etc
2.修改sentinel.conf配置文件
sentinel monitor mymast 192.168.110.133 6379 1 #主节点 名称 IP 端口号 选举次数
3. 修改心跳检测 5000毫秒
sentinel down-after-milliseconds mymaster 5000
4.sentinel parallel-syncs mymaster 2 --- 做多多少合格节点
5. 启动哨兵模式
./redis-server /usr/local/redis/etc/sentinel.conf --sentinel &
6. 停止哨兵模式
RDB持久化
5.RDB持久化
RDB 是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:使用单独子进程来进行持久化,主进程不会进行任何
IO 操作,保证了
redis 的高性能
缺点:RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
这里说的这个执行数据写入到临时文件的时间点是可以通过配置来自己确定的,通过配置redis 在 n 秒内如果超过 m 个 key 被修改这执行一次 RDB 操作。这个操作就类似于在这个时间点来保存一次 Redis 的所有数据,一次快照数据。所有这个持久化方法也通常叫做 snapshots。
#dbfilename:持久化数据存储在本地的文件 dbfilename dump.rdb #dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下 dir ./ ##snapshot触发的时机,save ##如下为900秒后,至少有一个变更操作,才会snapshot ##对于此值的设置,需要谨慎,评估系统的变更操作密集程度 ##可以通过“save “””来关闭snapshot功能 #save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。 save 900 1 save 300 10 save 60 10000 ##当snapshot时出现错误无法继续时,是否阻塞客户端“变更操作”,“错误”可能因为磁盘已满/磁盘故障/OS级别异常等 stop-writes-on-bgsave-error yes ##是否启用rdb文件压缩,默认为“yes”,压缩往往意味着“额外的cpu消耗”,同时也意味这较小的文件尺寸以及较短的网络传输时间 rdbcompression yes
5.AOF持久化
Append-only file,将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在 append 操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当 server 需要数据恢复时,可以直接 replay 此日志文件,即可还原所有的操作过程。AOF 相对可靠,它和 mysql 中 bin.log、apache.log、zookeeper 中 txn-log 简直异曲同工。AOF 文件内容是字符串,非常容易阅读和解析。
优点:可以保持更高的数据完整性,如果设置追加 file 的时间是 1s,如果
redis 发生故障,最多会丢失 1s 的数据;且如果日志写入不完整支持 redis-check-aof 来进行日志修复;AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的
flushall)。
缺点:AOF 文件比 RDB 文件大,且恢复速度慢。
我们可以简单的认为
AOF 就是日志文件,此文件只会记录“变更操作”(例如:set/del
等),如果
server 中持续的大量变更操作,将会导致
AOF 文件非常的庞大,意味着 server 失效后,数据恢复的过程将会很长;事实上,一条数据经过多次变更,将会产生多条
AOF 记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的;因为
AOF 持久化模式还伴生了“AOF
rewrite”。
AOF 的特性决定了它相对比较安全,如果你期望数据更少的丢失,那么可以采用
AOF 模式。如果 AOF 文件正在被写入时突然 server 失效,有可能导致文件的最后一次记录是不完整,你可以通过手工或者程序的方式去检测并修正不完整的记录,以便通过
aof 文件恢复能够正常;同时需要提醒,如果你的
redis 持久化手段中有 aof,那么在 server 故障失效后再次启动前,需要检测 aof 文件的完整性。
##此选项为aof功能的开关,默认为“no”,可以通过“yes”来开启aof功能 ##只有在“yes”下,aof重写/文件同步等特性才会生效 appendonly yes ##指定aof文件名称 appendfilename appendonly.aof ##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec appendfsync everysec ##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no” no-appendfsync-on-rewrite no ##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认“64mb”,建议“512mb” auto-aof-rewrite-min-size 64mb ##相对于“上一次”rewrite,本次rewrite触发时aof文件应该增长的百分比。 ##每一次rewrite之后,redis都会记录下此时“新aof”文件的大小(例如A),那么当aof文件增长到A*(1 + p)之后 ##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。 auto-aof-rewrite-percentage 100
AOF 是文件操作,对于变更操作比较密集的 server,那么必将造成磁盘 IO 的负荷加重;此外 linux 对文件操作采取了“延迟写入”手段,即并非每次 write 操作都会触发实际磁盘操作,而是进入了 buffer 中,当 buffer 数据达到阀值时触发实际写入(也有其他时机),这是 linux 对文件系统的优化,但是这却有可能带来隐患,如果 buffer 没有刷新到磁盘,此时物理机器失效(比如断电),那么有可能导致最后一条或者多条 aof 记录的丢失。通过上述配置文件,可以得知 redis 提供了 3 中 aof 记录同步选项:
always:每一条 aof 记录都立即同步到文件,这是最安全的方式,也以为更多的磁盘操作和阻塞延迟,是 IO 开支较大。
everysec:每秒同步一次,性能和安全都比较中庸的方式,也是 redis 推荐的方式。如果遇到物理服务器故障,有可能导致最近一秒内 aof 记录丢失(可能为部分丢失)。
no:redis 并不直接调用文件同步,而是交给操作系统来处理,操作系统可以根据 buffer 填充情况 / 通道空闲时间等择机触发同步;这是一种普通的文件操作方式。性能较好,在物理服务器故障时,数据丢失量会因 OS 配置有关。
其实,我们可以选择的太少,everysec 是最佳的选择。如果你非常在意每个数据都极其可靠,建议你选择一款“关系性数据库”吧。
AOF 文件会不断增大,它的大小直接影响“故障恢复”的时间,
而且 AOF 文件中历史操作是可以丢弃的。AOF rewrite 操作就是“压缩”AOF
文件的过程,当然 redis 并没有采用“基于原
aof 文件”来重写的方式,而是采取了类似 snapshot 的方式:基于 copy-on-write,全量遍历内存中数据,然后逐个序列到 aof 文件中。因此 AOF rewrite 能够正确反应当前内存数据的状态,这正是我们所需要的;*rewrite 过程中,对于新的变更操作将仍然被写入到原 AOF 文件中,同时这些新的变更操作也会被 redis 收集起来(buffer,copy-on-write 方式下,最极端的可能是所有的 key 都在此期间被修改,将会耗费 2 倍内存),当内存数据被全部写入到新的
aof 文件之后,收集的新的变更操作也将会一并追加到新的
aof 文件中,此后将会重命名新的
aof 文件为
appendonly.aof, 此后所有的操作都将被写入新的
aof 文件。如果在 rewrite 过程中,出现故障,将不会影响原 AOF 文件的正常工作,只有当 rewrite 完成之后才会切换文件,因为 rewrite 过程是比较可靠的。*
触发 rewrite 的时机可以通过配置文件来声明,同时 redis 中可以通过 bgrewriteaof 指令人工干预。
redis-cli -h ip -p port bgrewriteaof
因为 rewrite 操作 /aof 记录同步 /snapshot 都消耗磁盘 IO,redis 采取了“schedule”策略:无论是“人工干预”还是系统触发,snapshot 和 rewrite 需要逐个被执行。
AOF rewrite 过程并不阻塞客户端请求。系统会开启一个子进程来完成。
6.AOF与RDB区别
OF 和 RDB 各有优缺点,这是有它们各自的特点所决定:
1) AOF 更加安全,可以将数据更加及时的同步到文件中,但是 AOF 需要较多的磁盘 IO 开支,AOF 文件尺寸较大,文件内容恢复数度相对较慢。
*2) snapshot,安全性较差,它是“正常时期”数据备份以及
master-slave 数据同步的最佳手段,文件尺寸较小,恢复数度较快。
可以通过配置文件来指定它们中的一种,或者同时使用它们(不建议同时使用),或者全部禁用,在架构良好的环境中,master 通常使用 AOF,slave 使用 snapshot,主要原因是 master 需要首先确保数据完整性,它作为数据备份的第一选择;slave 提供只读服务(目前 slave 只能提供读取服务),它的主要目的就是快速响应客户端 read 请求;但是如果你的 redis 运行在网络稳定性差 / 物理环境糟糕情况下,建议你 master 和 slave 均采取 AOF,这个在 master 和 slave 角色切换时,可以减少“人工数据备份”/“人工引导数据恢复”的时间成本;如果你的环境一切非常良好,且服务需要接收密集性的 write 操作,那么建议 master 采取 snapshot,而 slave 采用 AOF。
0019 ActiveMQ
1.什么是消息中间件?
http通讯怎样保证数据一致性
如果订单发送失败,订单放在表中,每天定时任务将失败的订单信息重发
缺点:数据不能实时
第三节 消息模型
1.什么是JMS?
JMS是java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。
2.消息队列中的消息模型?
1) 点对点: 每个消息只能给一个消费者进行消费,不能进行重复消费
2)发布订阅
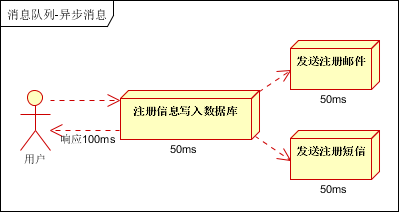
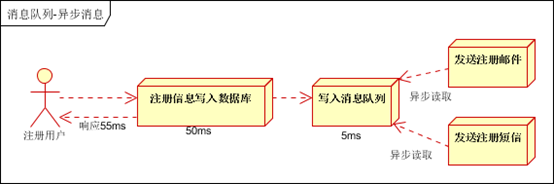
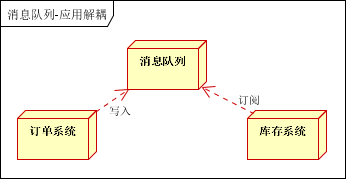
生产者
public class Producter {
public static void main(String[] args) throws JMSException {
// ConnectionFactory :连接工厂,JMS 用它创建连接
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory(ActiveMQConnection.DEFAULT_USER,
ActiveMQConnection.DEFAULT_PASSWORD, "tcp://127.0.0.1:61616");
// JMS 客户端到JMS Provider 的连接
Connection connection = connectionFactory.createConnection();
connection.start();
// Session: 一个发送或接收消息的线程
Session session = connection.createSession(Boolean.falst, Session.AUTO_ACKNOWLEDGE);
// Destination :消息的目的地;消息发送给谁.
// 获取session注意参数值my-queue是Query的名字
Destination destination = session.createQueue("my-queue");
// MessageProducer:消息生产者
MessageProducer producer = session.createProducer(destination);
// 设置不持久化
producer.setDeliveryMode(DeliveryMode.NON_PERSISTENT);
// 发送一条消息
for (int i = 1; i <= 5; i++) {
sendMsg(session, producer, i);
}
session.commit();
connection.close();
}
/**
* 在指定的会话上,通过指定的消息生产者发出一条消息
*
* @param session
* 消息会话
* @param producer
* 消息生产者
*/
public static void sendMsg(Session session, MessageProducer producer, int i) throws JMSException {
// 创建一条文本消息
TextMessage message = session.createTextMessage("Hello ActiveMQ!" + i);
// 通过消息生产者发出消息
producer.send(message);
}
}
消费者
public class JmsReceiver {
public static void main(String[] args) throws JMSException {
// ConnectionFactory :连接工厂,JMS 用它创建连接
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory(ActiveMQConnection.DEFAULT_USER,
ActiveMQConnection.DEFAULT_PASSWORD, "tcp://127.0.0.1:61616");
// JMS 客户端到JMS Provider 的连接
Connection connection = connectionFactory.createConnection();
connection.start();
// Session: 一个发送或接收消息的线程
Session session = connection.createSession(Boolean.TRUE, Session.AUTO_ACKNOWLEDGE);
// Destination :消息的目的地;消息发送给谁.
// 获取session注意参数值xingbo.xu-queue是一个服务器的queue,须在在ActiveMq的console配置
Destination destination = session.createQueue("my-queue");
// 消费者,消息接收者
MessageConsumer consumer = session.createConsumer(destination);
while (true) {
TextMessage message = (TextMessage) consumer.receive();
if (null != message) {
System.out.println("收到消息:" + message.getText());
session.commit();
} else
break;
}
session.close();
connection.close();
}
}
0021 Nginx
1.nginx解决网站跨域问题
server {
listen 80;
server_name www.itmayiedu.com;
location /A {
proxy_pass http://a.a.com:81/A;
index index.html index.htm;
}
location /B {
proxy_pass http://b.b.com:81/B;
index index.html index.htm;
}
}
2.nginx配置防盗链
location ~ .*\.(jpg|jpeg|JPG|png|gif|icon)$ {
valid_referers blocked http://www.itmayiedu.com www.itmayiedu.com;
if ($invalid_referer) {
return 403;
}
}
3.nginx配置DDOS
3.1 限制请求速度
设置Nginx、Nginx Plus的连接请求在一个真实用户请求的合理范围内。比如,如果你觉得一个正常用户每两秒可以请求一次登录页面,你就可以设置Nginx每两秒钟接收一个客户端IP的请求(大约等同于每分钟30个请求)。
limit_req_zone $binary_remote_addr zone=one:10m rate=30r/m;
server {
...
location /login.html {
limit_req zone=one;
...
}
}
limit_req_zone`命令设置了一个叫one的共享内存区来存储请求状态的特定键值,在上面的例子中是客户端IP($binary_remote_addr)。location块中的`limit_req`通过引用one共享内存区来实现限制访问/login.html的目的。
3.2 限制请求速度
设置Nginx、Nginx Plus的连接数在一个真实用户请求的合理范围内。比如,你可以设置每个客户端IP连接/store不可以超过10个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号