
oracle基础知识(二)笔记——高级查询
oracle基础知识(二)笔记:高级查询
目录
分组查询
分组函数:avg,sum,min,max,count,wm_concat(行转列)
--求出员工的平均工资和工资的总额,最小和最大值
select avg(sal),sum(sal),min(sal),max(sal) from emp;
--统计员工个数
select count(*) from emp;
--distinct()求部门数
select count(distinct(deptno)) from emp;
--WM_concount(行专列)
--调整列
col 部门中员工的姓名 for a60
select deptno 部门号,wm_concat(ename) 部门中员工的姓名 from emp group by deptno;
--空值
--统计员工的平均工资
select sum(sal)/count(*) 一,sum(sal)/count(sal) 二,avg(sal) from emp;
--统计员工的平均奖金
select sum(comm)/count(*) 一,sum(comm)/count(comm) 二,avg(comm) from emp;
--注:分组函数会自动忽略空值;
--注:NVL函数使分组函数无法忽略空值;
select count(*),count(nvl(comm,0)) from emp;
--group by子句的使用
--部门的平均工资,编号,平均工资
select deptno,avg(sal) from emp
group by deptno;
-- 分组函数的嵌套
案例:求部门平均工资的最大值;
select max(avg(sal)) from emp
group by deptno;
- 多个列的分组
抽象:1.在select列表中所有未包含在组函数中的列都应该包含在groupby子句中;2.包含在group by子句中的列不必包含在select列表中;
多属性分组语法:
select a,b,c,组函数(x) from table group by a,b,c;
案例:
--案例:求部门的平均工资,要求显示:部门的平均工资
select avg(sal) from emp group by deptno
--多个列的分组
--案例:按部门、不同的职位,统计员工的工资总额
select deptno,job,sum(sal) from emp
group by deptno,job
order by deptno;
过滤查询
where 和having 的区别:
不能在where子句中使用分组函数;
可以在having可以使用分组函数;
--注意:从sql优化的角度上看,尽量使用where;
having:先分组再过滤
where:先过滤再分组
--过滤分组
--having子句的使用
--案例:平均工资大于2000的部门
select deptno,avg(sal) from emp
group by deptno
having avg(sal)>2000;
--案例:查询10号部门的平均工资
select deptno,avg(sal) from emp
where deptno=10
group by deptno
/
select deptno,avg(sal) from emp
group by deptno
having deptno=10
/
--注意:从sql优化的角度上看,尽量使用where;
having:先分组再过滤
where:先过滤再分组
--使用order by排序
--案例:求每个部门的平均工资,要求显示:部门号,部门的平均工资,
并且按照工资升序排列
--可以按照:列、别名、表达式、序号(列序号)进行排序;
--a命令 append a (两个空格)desc;
--ed命令
group by 语句增强
--group by语句的增强
--红色:按部门、不同的职位,统计工资总额
select deptno,job,sum(sal) from emp
group by deptno,job;
--蓝色:按部门统计工资总额
select deptno,sum(sal) from emp
group by deptno;
--紫色:统计工资总额
select sum(sal) from emp;
--以上三句相加====
select distinct(deptno),job,sum(sal)
from emp group by rollup(deptno,job);
抽象:
group by rollup(a,b)
等价于:
group by a,b
+group by a
+group by null(不按照任何条件分组
--报表格式设置
--相同的部门号只显示1次,跳过2行
break on deptno skip 2
select deptno,job,sum(sal)
from emp group by rollup(deptno,job);
sqlplus报表功能
--sqlplus报表功能
报表包括:标题、页码、别名等;
title col 15 '我的报表' col 35 sql.pno
col deptno heading 部门号
col job heading 职位
col sum(sal) heading 工资总额
break on deptno skip 1
多表查询
- 笛卡尔积
笛卡尔积:(m1,n1)和(m2,n2)-->>>(m1*m2,n1+n2) 至少存在n-1组关系(n表示表的个数) 连接的类型
等值连接、不等值、外连接、自连接
![在这里插入图片描述]()
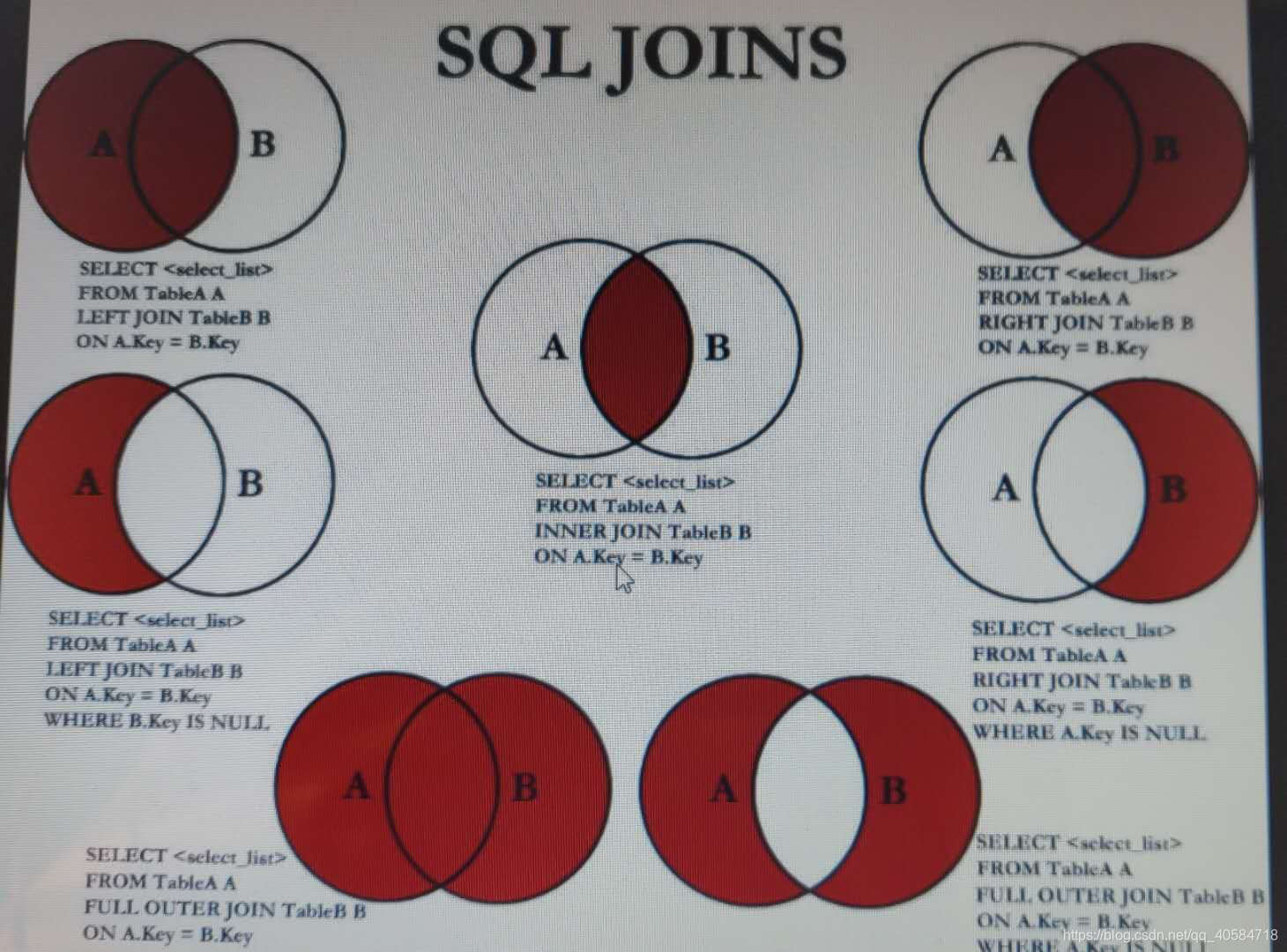
等值连接
--等值连接(连接关系是等号)
--案例:查询员工信息,要求显示员工号、姓名、月薪、部门名称;
select empno,ename,sal,dname
from emp e,dept d
where e.deptno=d.deptno;
--不等值连接
--案例:查询员工信息,要求显示:员工号,姓名,月薪,薪水等级
select e.empno,e.ename,e.sal,s.grade
from emp e,salgrade s
where e.sal between s.losal and s.hisal;
外连接
注意:--(+)放在副表的位置的使用
--外连接
--案例:按部门统计员工人数,要求显示:部门号,部门名称,人数
select d.deptno,d.dname,count(e.empno)
from dept d left join emp e on d.deptno=e.deptno
group by d.deptno,dname
order by d.deptno;
select d.deptno,d.dname,count(e.empno)
from dept d ,emp e
--(+)放在副表的位置
where d.deptno=e.deptno(+)
group by d.deptno,dname
order by d.deptno;
select d.deptno,d.dname,count(e.empno)
from emp e ,dept d
where e.deptno(+)=d.deptno
group by d.deptno,dname
order by d.deptno;
自连接
--自连接
--案例:查询员工姓名和员工的老板姓名
select e1.ename 员工的姓名,e2.ename 老板的姓名
from emp e1,emp e2
where e1.mgr=e2.empno;
--自连接存在的问题
--不适合操作大表
--解决办法:层次查询(本质上,是单表查询)
--树的深度 :level(查询结果可以表示成树结构)
select level,empno,ename,sal,mgr
from emp
--connect by 上一层的员工号=老板号
connect by prior empno=mgr
--起始条件
--start with empno=7839;
start with mgr is null
order by level;
子查询
--子查询
--单行子查询,多行子查询
实例:查询工资比scott高的员工信息;
select * from emp
where sal>(select sal from emp where ename='SCOTT');
--子查询注意的10个问题
--子查询语法中的小括号
--子查询的书写风格
-- 可以使用子查询的位置:where,select ,having ,from
--不可以使用子查询的位置:group by
--强调:from后面的子查询
--主查询和子查询可以不是同一张表
--一般不在子查询中,使用排序;但在Top_N分析中,
必须对子查询排序;
--一般先执行子查询,再执行主查询;但是相关子查询例外;
--案例:找到员工表中薪水大于本部门平均薪水的员工
--将主查询的参数传递给子查询
select empno,ename,sal,(select avg(sal) from emp where deptno=e1.deptno) avgsal
from emp e1
where e1.sal>(select avg(sal) from emp where deptno=e1.deptno) ;
--单行(返回一个)子查询只能使用单行操作符;多行子查询只能使用多行操作符;
/*
单行操作符:=,>,>=,<,<=,<>
多行操作符:in(等于列表中的任何一个);any(和子查询中的任意一个比较);
ALL(和子查询返回的所有值比较)
*/
select 后面的子查询必须是单行子查询
select empno,ename,sal,(select job from emp where empno=7839) 第四列
from emp;
--having 后面放一条子查询
select deptno,avg(sal)
from emp
group by deptno
having avg(sal)>(select max(sal)
from emp
where deptno=30);
--from 后面
select * from (select empno,ename,sal from emp);
--子查询的排序问题
--案例:找到员工表中工资最高的前三名
--rownum 行号 伪列
--行号永远按照默认的顺序生成
select rownum,ename,empno,sal
from (select * from emp order by sal desc) b
where rownum<=3;
子查询中的空值问题
注意:子查询中是null值问题
--例:单行子查询是空值的问题
select ename,job from emp
where job =(select job from emp where ename='Tom');
--多行子查询的空值问题
--案例:查询不是老板的员工
select *
from emp
where empno not in (select mgr from emp);
--返回空值
--原因:当多行子查询中存在空值时,使用not in相当于<>all;
--修改:
select *
from emp
where empno not in (select mgr from emp where mgr is not null);
案例1;已在说明子查询的效率的要高于多表查询
sql执行计算:语句前加+explain plan for
综合案例:
--案例1;分页查询显示员工信息:显示员工编号,姓名、月薪
--每页显示4条记录
--显示第二页的员工
--按照月薪降序排列
--行号只能使用<,<=;不能使用>,>=
select *
from (select rownum rm,e1.* from (select * from emp order by sal desc) e1 where rownum<=8) e2
where rm>=5;
--案例二:找到员工表中薪水大于本部门平均薪水的员工;
explain plan for
select e.empno,e.ename,e.sal,(select avg(sal) avg_sal from emp where deptno=e.deptno) avg_sal
from emp e
where sal>(select avg(sal) avg_sal from emp where deptno=e.deptno);
--查看执行计划
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 2385781174
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 44 | 8 (25)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | TABLE ACCESS FULL | EMP | 5 | 40 | 3 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 1 | 44 | 8 (25)| 00:00:01 |
| 4 | VIEW | VW_SQ_1 | 3 | 78 | 4 (25)| 00:00:01 |
| 5 | HASH GROUP BY | | 3 | 24 | 4 (25)| 00:00:01 |
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 6 | TABLE ACCESS FULL| EMP | 14 | 112 | 3 (0)| 00:00:01 |
| 7 | TABLE ACCESS FULL | EMP | 14 | 252 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------
--不使用相关子查询
explain plan for
select e.empno,e.ename,e.sal,e2.avg_sal
from emp e,(select deptno,avg(sal) avg_sal from emp group by deptno) e2
where e.deptno=e2.deptno and e.sal>e2.avg_sal;
--查看执行计划
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 269884559
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 44 | 8 (25)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 44 | 8 (25)| 00:00:01 |
| 2 | VIEW | | 3 | 78 | 4 (25)| 00:00:01 |
| 3 | HASH GROUP BY | | 3 | 24 | 4 (25)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMP | 14 | 112 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 252 | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------
案例2:按照部门统计员工人数,总人数,1980,1081,1982,1987
案例三:按照部门统计员工人数,总人数,1980,1081,1982,1987
select (select count(*) from emp) Total,e2.year,count(e2.empno)
from (select to_char(hiredate,'yyyy') year,e.* from emp e) e2
group by e2.year
order by e2.year;
--使用decode函数
--select decode(to_char(hiredate,'yyyy'),'1981',1,0) from emp;
select count(*) Total,
sum(decode(to_char(hiredate,'yyyy'),'1980',1,0)) "1980",
sum(decode(to_char(hiredate,'yyyy'),'1981',1,0)) "1981",
sum(decode(to_char(hiredate,'yyyy'),'1982',1,0)) "1982",
sum(decode(to_char(hiredate,'yyyy'),'1987',1,0)) "1987"
from emp;
--使用伪表
select
(select count(8) from emp) Total,
(select count(*) from emp where to_char(hiredate,'yyyy')='1980') "1980",
(select count(*) from emp where to_char(hiredate,'yyyy')='1981') "1981",
(select count(*) from emp where to_char(hiredate,'yyyy')='1982') "1982",
(select count(*) from emp where to_char(hiredate,'yyyy')='1987') "1987"
from dual;
案例3:选择每门课程的学生
--提示:
1.需要两个表进行连接查询,为两个表取别名
2使用instr(a,b)函数:如果字符串b在字符串a的里面,则返回b在a中的位置;
3.需要分组查询
4.使用wm_concat(cols)函数对学生姓名进行逗号拼接;
- 创建表格
create table pm_ci(
CI_ID varchar2(10) not null primary key,
stu_IDS varchar2(10)
);
insert into pm_ci values('1','1,2,3,4');
insert into pm_ci values('2','1,4');
create table pm_stu(
stu_ID varchar2(10) not null primary key,
stu_name varchar2(10)
);
insert into pm_stu values('1','张三');
insert into pm_stu values('2','李四');
insert into pm_stu values('3','王五');
insert into pm_stu values('4','赵六');
- 查询结果
-- 设置列宽
col ci_id format a20
col stu_names format a20
--行显示设置
set linesize 100
-- sql查询语句
select pc.ci_id ci_id,wm_concat(pt.stu_name) stu_names
from pm_ci pc,pm_stu pt
where instr(pc.stu_ids,pt.stu_id)>0
group by pc.ci_id;
关于回收站表恢复与彻底清除
--查看已经删除的表
select * from tab(or cat);
--其中前边带bin的就是
--恢复表
flashback table table_name to before drop;
--彻底删除
drop table_name
--删除回收站的表‘
purge recyclebin
--查询所有此类表
select * from recyclebin where type='TABLE';
--用来删除回收站中所有的表
PURGE RECYCLEBIN
--用来删除指定的表
PURGE TABLE tablename
--用来闪回被删除的表
FLASHBACK TABLE tablename

 浙公网安备 33010602011771号
浙公网安备 33010602011771号