进程运行轨迹的跟踪与统计
实验过程
-
基于模板
process.c编写多进程的样本程序,实现如下功能:- 所有子进程都并行运行,每个子进程的实际运行时间一般不超过 30 秒。
- 父进程向标准输出打印所有子进程的 id,并在所有子进程都退出后才退出;
-
在
Linux0.11上实现进程运行轨迹的跟踪。 基本任务是在内核中维护一个日志文件/var/process.log,把从操作系统启动开始过所有进程的运行轨迹都记录在这个log文件中。- 修改
init/main.c。- 在
进程0中打开log文件:把文件描述符3关联到log文件。
- 在
- 修改
kernel/printk.c。- 实现内核状态下写文件操作函数
fprintk。
- 实现内核状态下写文件操作函数
- 修改
include/linux/kernel.h。- 声明
int fprink(int fd, const char *fmt, ...);
- 声明
- 修改
kernel/sched.c。- 修改
sleep_on函数,记录状态切换,写入log文件。 - 修改
interruptible_sleep_on函数。 - 修改
wake_up函数。 - 修改
sys_pause函数,但是特殊判断 0号进程不写入log文件。因为系统无事可做的时候,进程0会不停地调用sys_pause()。 - 修改
schedule函数。
- 修改
- 修改
kernel/fork.c文件。- 修改
copy_process函数。
- 修改
- 修改
kernel/exit.c文件。- 修改
sys_waitpid函数。 - 修改
do_exit函数。
- 修改
- 修改
-
在修改过的
Linux0.11上运行样本程序,利用程序stat_log.py分析log文件,统计该多进程程序的所有进程的等待时间、完成时间(周转时间)和运行时间,然后计算平均等待时间,平均完成时间和吞吐量。- 解决
stat_log.py在python3环境下的报错。
- 解决
-
修改
Linux0.11进程调度的时间片,重复实验,对比分析不同时间片情况下的数据。- 修改
include/linux/kernel.h的INIT_TASK。
- 修改
内核报错
在修改完Linux0.11内核代码后,运行Bochs,出现了如下问题:
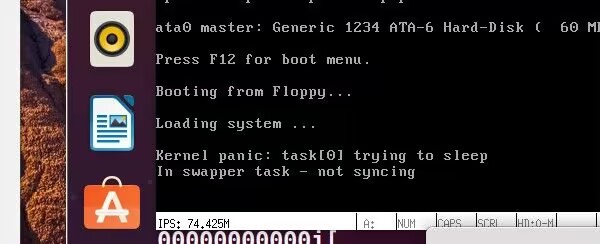
通过安装Bochs 2.4.5解决了问题。
安装Bochs 2.4.5
- 官网下载
bochs-2.4.5.tar.gz Ubuntu下解压,进入目录。- 输入如下命令:
./configure \
--prefix=$HOME/oslab/bochs2.4.5/ \
--enable-debugger \
--enable-disasm \
--enable-iodebug \
--enable-x86-debugger \
--with-x \
--with-x11
- 输入
sudo make install命令。 - 安装完毕,在该版本
bochs上运行Linux 0.11。 - 成功运行操作系统。
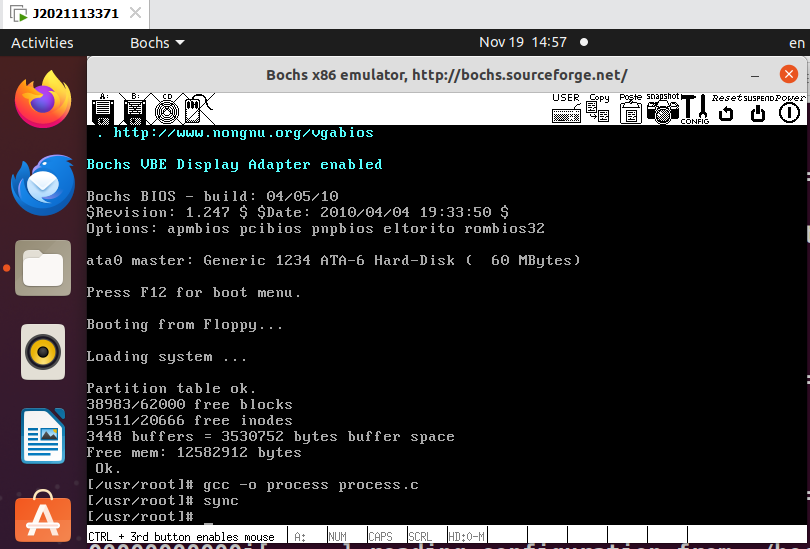
实验结果
- 运行
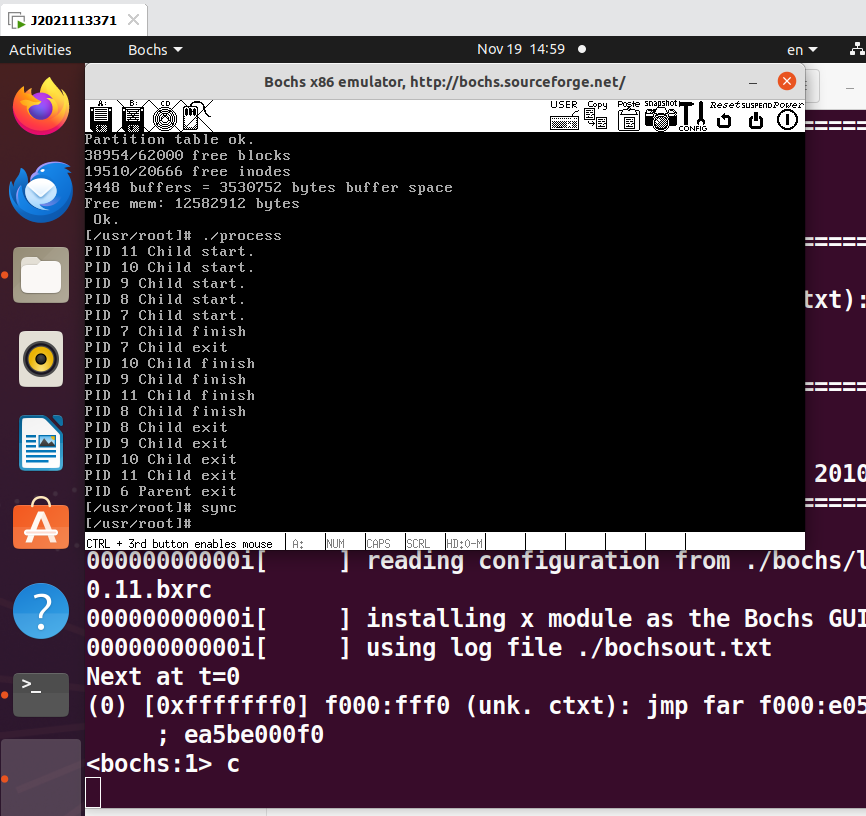
process多进程程序。可见,7,8,9,10,11为子进程,6为父进程。
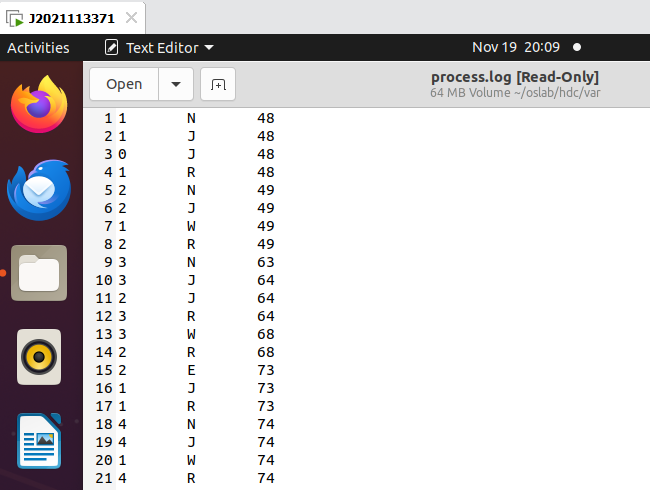
- 查看
/var/process.log。日志文件建立成功,能向日志文件输出信息,5种状态都能输出。
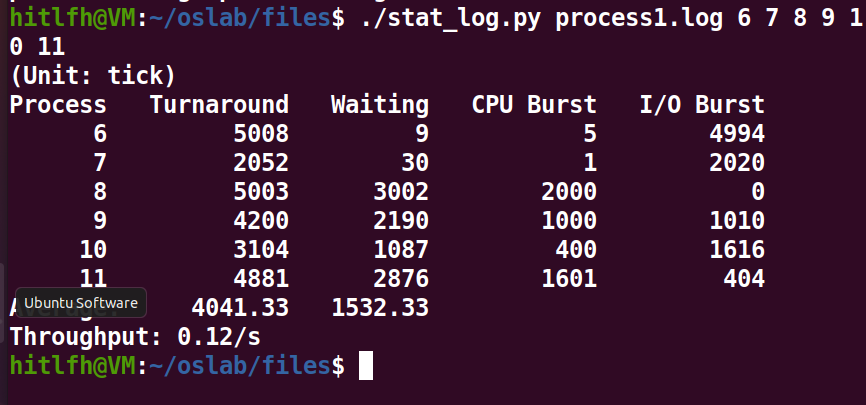
- 运行
stat_log.py程序分析process.log。可见20 s的调度cpuio_bound,产生了约2000 tick工作状态信息,符合预期。
- 修改
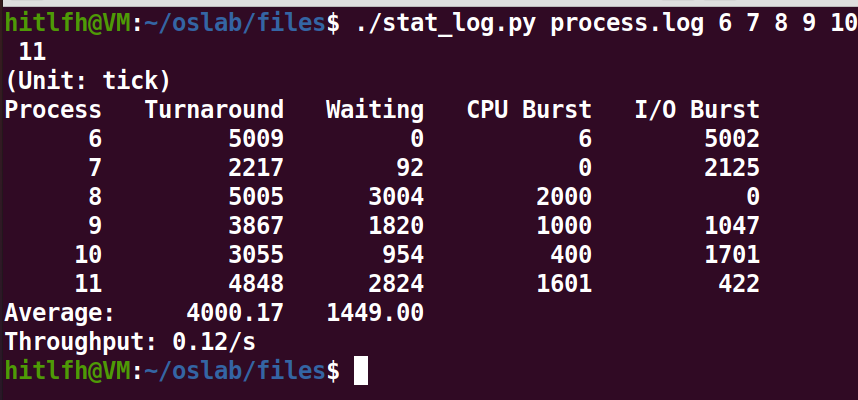
INIT_TASK的priority值为150。
- 修改
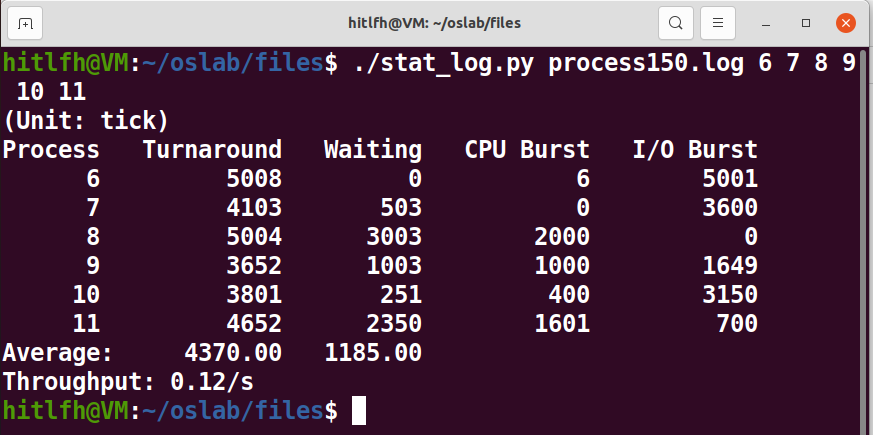
INIT_TASK的priority值为300。
- 修改
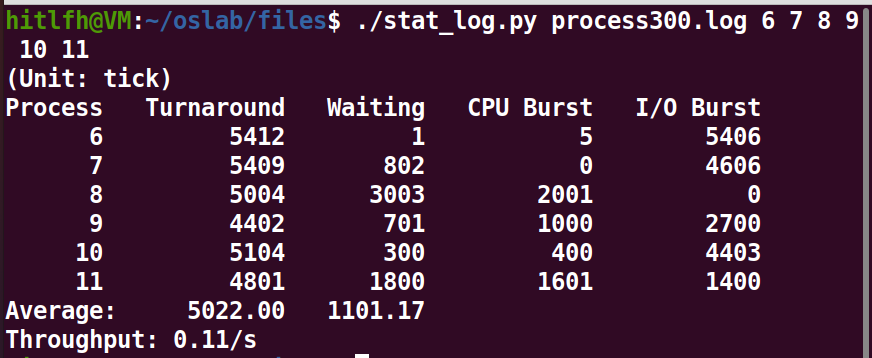
INIT_TASK的priority值为10。
- 修改
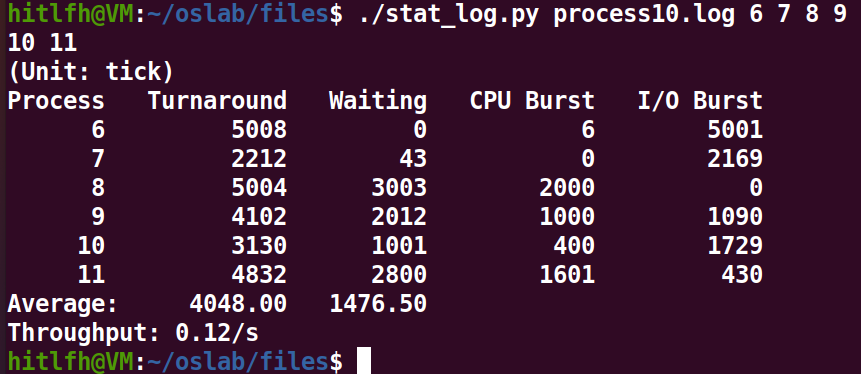
INIT_TASK的priority值为1。
实验报告
结合自己的体会,谈谈从程序设计者的角度看,单进程编程和多进程编程最大的区别是什么?
- 执行顺序:单进程是自上而下的设定好的流程,而多进程则不是,它们是并发执行的。不仅需要考虑它们之间调度顺序,还要考虑每个进程的执行顺序。
- 资源使用:每个进程都有自己的内存空间和系统资源。这些内存空间和系统资源有些是公有的,有些是私有的。
- 进程间通信:多进程编程通常比单进程编程更复杂,因为需要处理进程间的通信和同步。
总的来说,选择单进程编程还是多进程编程取决于应用程序的需求和约束。对于需要高并发性和健壮性的应用程序,多进程编程可能是一个好的选择。对于资源受限或需要简单性的应用程序,单进程编程可能更合适。
你是如何修改时间片的?仅针对样本程序建立的进程,在修改时间片前后, log 文件的统计结果(不包括Graphic)都是什么样?结合你的修改分析一下为什么会这样变化,或者为什么没变化?
我是通过修改include/linux/kernel.h的 INIT_TASK来修改时间片的。
随着时间片的增大,总体上来说,平均等待时间下降。但是切换进程变缓,导致I/O Burst时间上升,最终导致平均完成时间上升。也就是说,在I/O过程中,部分时间是在空闲状态,没有进行I/O操作,需要等待(当前运行进程)时间片消耗完,然后切换任务,调用schedule()函数,才会唤醒等待的进程。具体原因,见schedule函数与进程调度。
而随着时间片的减小,总体上,平均等待时间上升。这是切换进程太快导致cpu忙于进程调度,从而让进程等待时间增加。
但,无论时间片减小或增大,统计出进程的CPU占用时间是没有变化的,这也符合逻辑。因为,进程占用CPU后,如果还有I/O操作(sleep(1)),那么它会进入阻塞状态,如果没有,那就会调用exit退出。
schedule函数与进程调度
schedule函数是sched.c的核心,实现了进程调度的过程。
-
检查Alarm: 函数首先遍历所有进程,检查它们是否设置了警报(由
(*p)->alarm表示)。如果某个进程的警报时间已经到达((*p)->alarm < jiffies),函数会向该进程发送SIGALRM信号,并重置其警报。 -
唤醒中断的任务: 如果一个进程是可中断睡眠状态(
TASK_INTERRUPTIBLE)并且收到了一个不能被阻塞的信号((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)),该进程的状态会被设置为运行状态(TASK_RUNNING)。 -
调度器主体: 调度器进入一个循环,寻找具有最高计数器值(
(*p)->counter)的运行态(TASK_RUNNING)进程。这个计数器值是一个衡量进程应该运行多久的度量,相当于它的时间片。 -
选择进程: 如果找到一个或多个运行态进程,调度器会选择具有最高计数器值的进程进行切换。如果所有运行态进程的计数器值都用尽(即为0),则会重新计算每个进程的计数器值,基于它们的优先级(
(*p)->priority)。 -
上下文切换: 最后,调度器使用
switch_to(next)切换到选择的进程。
在 Linux 0.11 的进程调度机制中,当前运行的进程会继续执行直到其计数器(代表分配给该进程的时间片)消耗完毕。一旦这发生,操作系统(内核)会调用 schedule 函数来选择下一个要运行的进程。
这个过程分析如下:
- 时间片消耗: 当一个进程正在运行时,其计数器(时间片)逐渐减少。这个计数器的减少反映了进程消耗的 CPU 时间。
- 调用
schedule函数: 一旦当前运行的进程的计数器降至零,表明其分配的时间片已经用完,内核将调用schedule函数来决定下一个运行哪个进程。 - 唤醒等待的进程: 在
schedule函数中,内核会检查所有进程,特别是那些处于可中断睡眠状态(如执行了sleep调用的进程)。如果这些进程的睡眠时间已经过去或它们接收到了信号,它们的状态将被设置为可运行(TASK_RUNNING)。 - 选择新的进程执行: 内核接着会从可运行的进程中选择一个具有最高计数器值的进程来执行。如果
sleep(1)的进程已被标记为可运行,它将有机会被选中。但是,如果有其他进程具有更高的计数器值,或者sleep(1)的进程尚未被标记为可运行,它可能需要等待下一个调度周期。
由于这种调度机制,如果系统负载高或其他进程的时间片设置较大,处于 sleep 的进程可能会在阻塞状态中停留超过预期的时间。而等待schedule调用可能会受到当前运行进程的时间片大小和系统整体负载的影响。
参考文献
本文来自博客园,作者:江水为竭,转载请注明原文链接:https://www.cnblogs.com/Az1r/p/17955544

 浙公网安备 33010602011771号
浙公网安备 33010602011771号