

逻辑斯蒂回归
B站视频链接 5 逻辑斯蒂回归
0 模型引入
该模型主要是一个分类问题,这一次主要用的就是逻辑斯蒂回归.
在上一届课程中我们使用了线性回归,咱们使用的模型是普通的一阶线性模型\(\hat{y}=x*\omega+b\),并且使用求和损失的方式计算损失函数\(loss=(\hat{y}-y)^{2}=(x\cdot\omega-y)^{2}\)。

但是在很多的学习过程中,我们要做的是分类的处理操作。譬如下面这个例子,将模型分成各个数据的分类集合,我们需要估算任何一个图像属于哪一种数据。

这个是很难使用线性模型进行输出的,因为这个玩意儿并非是具体数据上的比较,而是抽象的特征上面的类别比较。
我们这里输出的应当是个概率,在这个例子中,我们输出的就是该图像属于每一个分类的一个概率值,最后我们要找到概率最大的一项。
1 数据集的使用
这里咱们用的就是\(torch\)中自带的一些数据集可以直接进行使用。
1 MNIST dataset
import torchvision
train_set = torchvision.datasets.MNIST(root='../../dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='../../dataset/mnist', train=False, download=True)
2 CIFAR dataset
import torchvision
train_set = torchvision.datasets.CIFAR10(...)
test_set = torchvision.datasets.CIFAR10(...)
2 初步介绍
2.1 二分模型
之前咱们在举例使用线性模型的时候举了一个比较简单的例子:
假设咱们的输入参数是学习的时间,输出参数是该门科目最后期末考试的分数。
现在咱们将这个分数进行一次重新定义,我们将分数大于6的定义成通过\(pass\),分数小于6的定义成未通过\(fail\)。
这个时候咱们的模型就成了,输入的是学习时间,输出的是两个类型(要么是1要么是0)。
像是这样子的只有两个类型的分类问题就是所谓的二分问题。最后我们需要计算的是这两个类别的概率分布。
但是由于他的输出只有两个参数因此,满足下面的公式.
因此对于二分问题咱们只需要求解其中一个类型的概率即可,也就是计算\(P(\hat{y}=1)\)的概率。
2.2 逻辑斯蒂函数
之前咱们的线性模型输出的是一个实数\(R\),但是现在这个的是一个概率,因此我们需要将实数上的数用一个函数映射到\([0,1]\)之前中,这个函数就是在概率论里面经常用到的函数:
现在我们看一下这个函数的两个极限:
- 当\(x\)区域正无穷时,函数的极限为\(1\)。
- 当\(x\)趋于负无穷时,函数的极限为\(0\)。
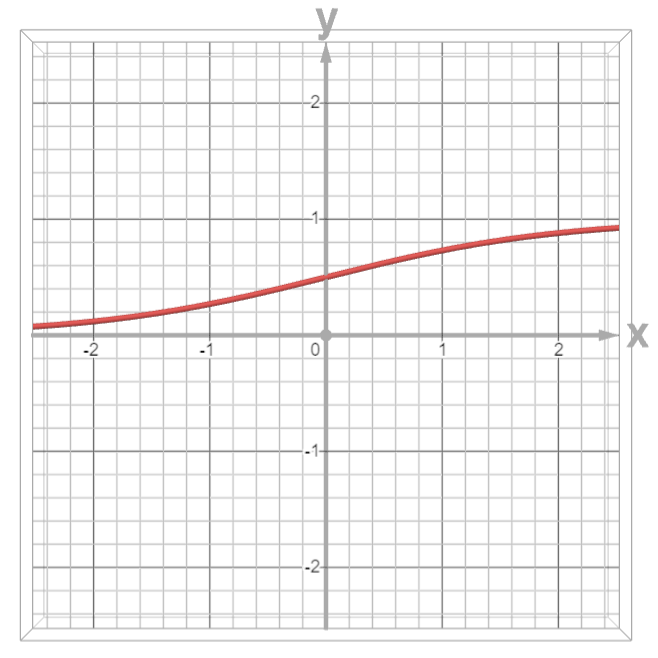
这个时候咱们就可以进行分类了。咱们现在可以使用线性模型配合这个函数进行相对应的变换了。将函数从原本的线性模型变换成这个逻辑斯蒂模型。,仅仅只是多计算一个函数罢了。
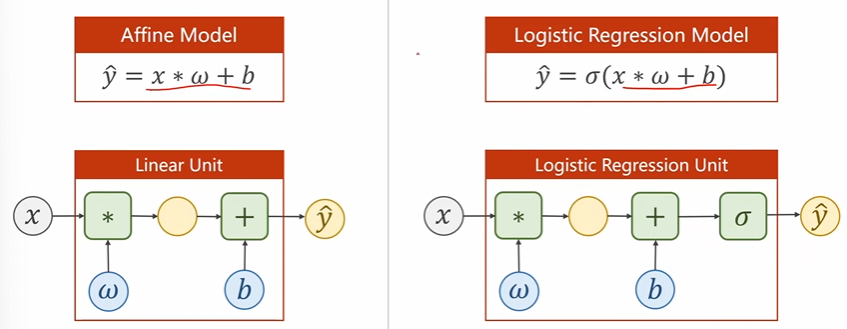
原本的线性模型函数为:\(\hat{y}={x*\omega+b}\)
现在的逻辑斯蒂模型函数为:\(\hat{y}=\sigma(x*\omega+b)\)
又因为逻辑斯蒂的函数为:\(f(x) = \frac{1}{1+e^{-x}}\)
因此将其全部带入可以得到他的基本模型为:
那么他的损失函数也要相应的进行变化:
原本的是:
现在的是:
注意:我们这里求解的是分布之间的差异,这里用的就是交叉熵\(corss - entropy\)。
举个例子吧:
现在有一个分布\(P_{D}\):\(\begin{gathered}P_{D}(x=1)=0.2\\P_{D}(x=2)=0.3\\P_{D}(x=3)=0.5\end{gathered}\);另一个分布\(P_{T}\):\(\begin{gathered}P_{T}(x=1)=0.3\\P_{T}(x=2)=0.4\\P_{T}(x=3)=0.3\end{gathered}\)。
那么就可以用:\(\sum_{i}P_{0}(x-i)\ln P_{T}(x=i)\)来表示两个分布之间的差异大小,我们希望这个数据越大越好,这也就是交叉熵。
而上面用的是二分形的交叉熵:\(loss=-(y\log\hat{y}+(1-y)\log(1-\hat{y}))\)
而这个损失就是BCE损失函数。
但是实际上由很多的变换饱和函数。
这个函数由几个性质:
- 是饱和函数;
- 左极限为0,右极限为1;
- 函数是严格单调递增的。
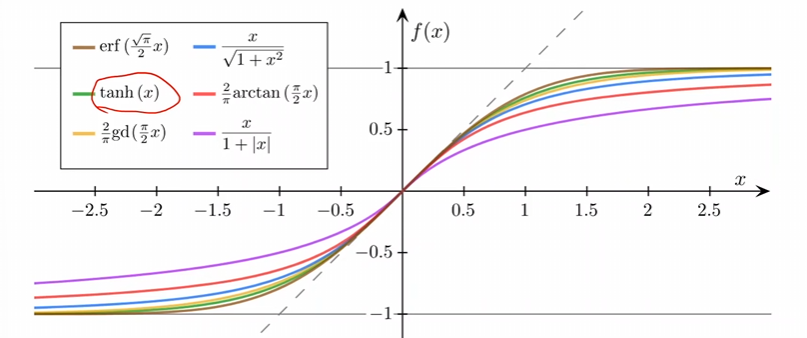
如果有多个样本直接求均值即可。
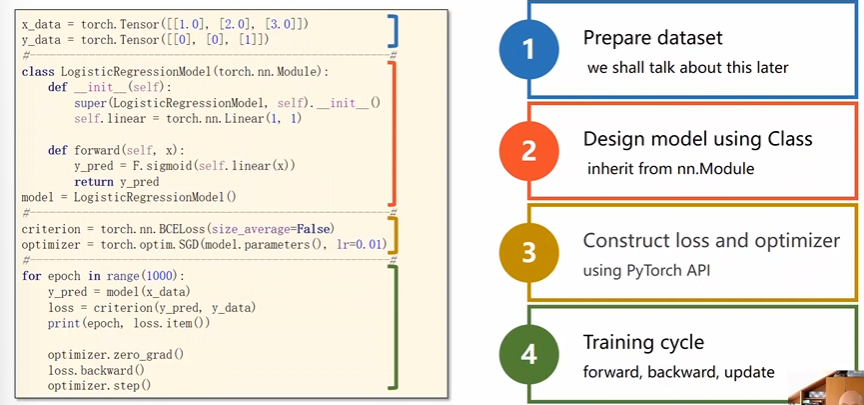
3 代码说明
3.1 分块说明
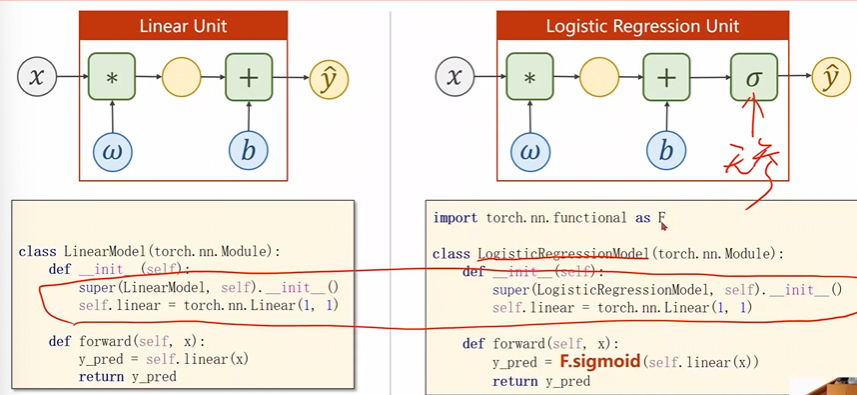
多了一步逻辑斯蒂函数的变化

原本咱们使用的是\(MSE\)损失现在用的是\(BCE\)损失,这个\(size_average\)是规定是否需要求各个批量的均值,影响的就是学习率的选择。

数据准备上的变化
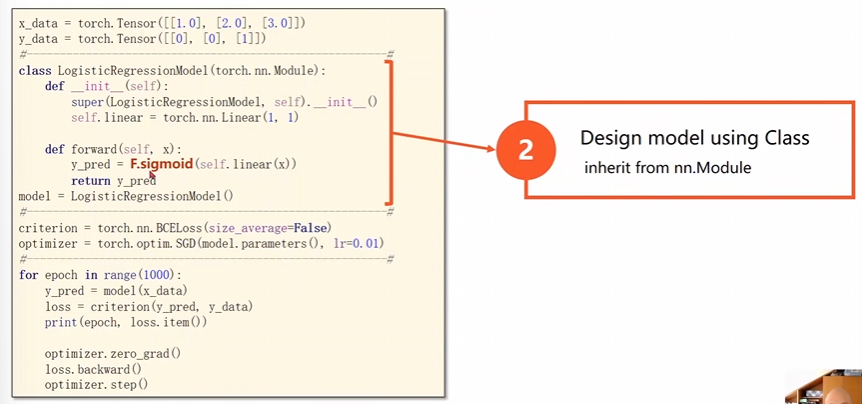


上面就是和之前的线性模型之间的区别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号