面向对象程序设计第一单元总结
面向对象第一单元总结
我的理解:面向对象是一种编程范式、设计思想和开发方法。同面向过程一样,对于面向对象来说,最终程序的运行、数据的处理仍要按照输入→处理→输出三段式划分,但其思想核心更偏重于对模型的构造:各个步骤共同建立一个问题解决的模型,而建立这一模型(对象)则集成了事物在整个过程中的状态和行为。
基于度量的结构分析
写在前面
从整体流程的角度讲,第一次作业将字符串化整为零直接构建表达式对象,而后两次都是直接使用递归下降的方法边解析字符串边构建表达式对象。
两次构建对象的过程都采用了面向对象的思想:即递归地传递字符串和字符串指针,使得构建过程中上层表达式不用关注底层表达式构建的细节。
但是,与直接向构造函数传递字符串不同,采用递归下降处理字符串则需要一个公共的字符串指针,因此如何扫描字符串并构造相应类型就称为了一个挑战。 在设计第二次作业时,针对递归下降,我考虑了两种构建方式:①边解析边构建和②先解析后构建。
解析与构建解耦的方式虽然从逻辑划分上比较干净,但是这种方法需要临时存储解析出的结果——仍需要选择合适的数据结构(以树的形式存储),然后在此基础上再递归构建。存储结果和再构建相对比较困难,最终我选择了边解析边构建的思路。
同上述方法一样,边解析边构建表达式也是对过程的封装——上层表达式/项,不需用关注底层具体的构建方式。但是随之而来的问题是,构建和解析这两个过程难以解耦,最终我采取了全局变量的方式来指示构建过程。
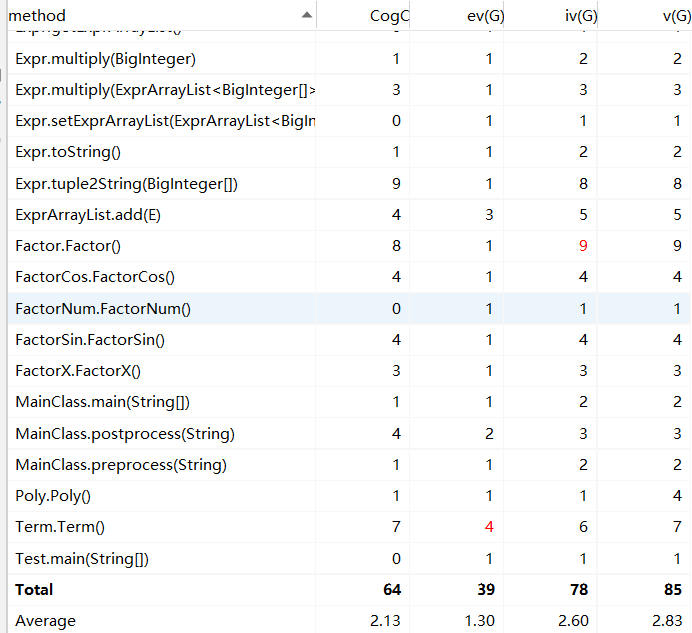
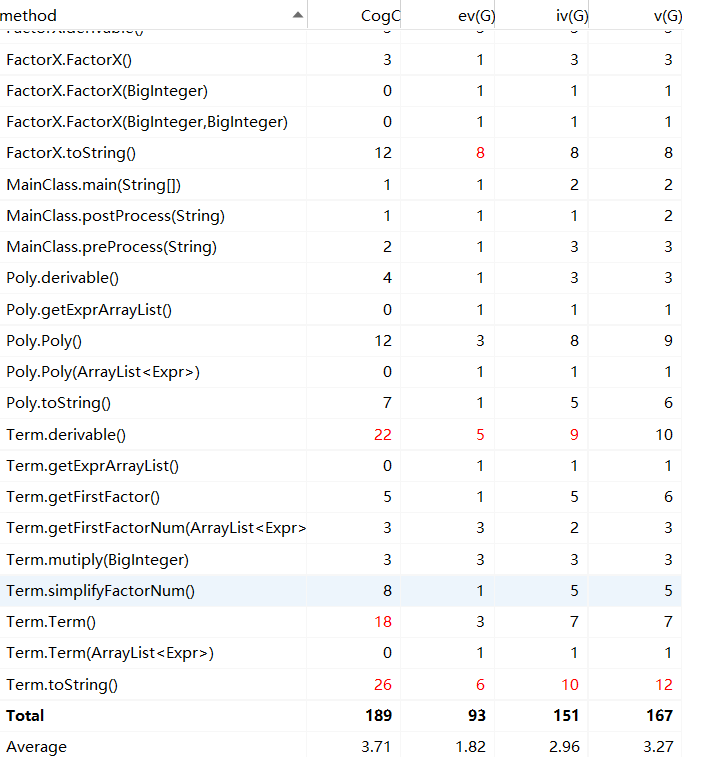
以上展示了HW1 ~ HW3的度量结果,总的来说,三次作业中类的类的属性较少(1~2个),个别类方法过多(三次作业中乘法类都是方法大户),使得功能较为集中,提高了耦合度。大部分方法控制的分支数目都在2个以内,而核心类则承担了更多分支控制(三次作业的乘法类所属方法);同时,虽然类中各个方法间耦合度较低,但是部分方法内部分支条目过多(主要集中在第三次作业的乘法类),这也能从侧面反映出架构设计初,各个方法间的功能划分没有做到平衡。
除此之外可以看出,程序复杂和混乱的地方主要都出现在乘法类中,原因除了乘法类具有承上启下的作用之外,主要是乘法类承担了过多优化功能,增添了许多分支和语句,也因此增加了程序的耦合度。其余部分也因为没有提前设计好优化过程而导致需要在内部扩展一些分支和判断。
作业类图

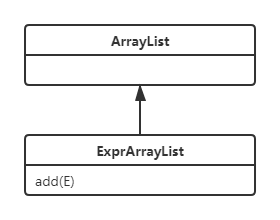
由于第一次作业结构非常直观,因此就直接采用idea生成的类图作为例子。可以看出MainClass主要负责字符串的读入和解析、结果的优化和输出,而Poly承载了加减类的作用,Item承载了乘类的作用,Factor作为因子类;在Poly和Item类中均有优化函数。
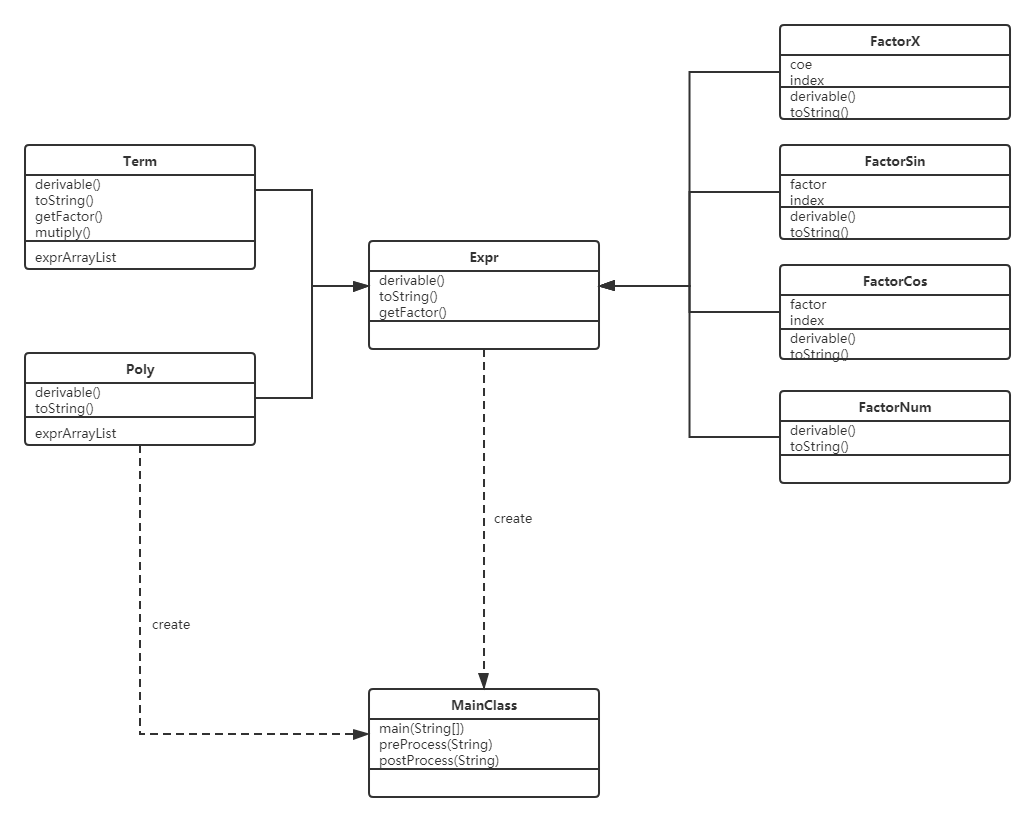
以上是第二三次作业的类图,整体架构基本没有改动,构建过程还是采用递归下降的方法,在第一次作业的基础之上,优化了Poly类和Term类作为加法类和乘法类的作用,将因子类细分为FactorX、FactorSin、FactorCos、FactorNum和Poly(这里递归地重用了Poly类),每种因子配有自己的求导和输出方法。
以上HW3程序类图,基本符合了表达式类(加法乘法)和项的统一与分类,实现了不同功能项之间的统一和分装。缺点很明显就是乘法类存在一部分冗余方法,类之间的存储与集成还有待优化:如HW3中我没有设计嵌套类,而是在乘法类中利用递归下降直接判断需要解析乘何种因子(幂函数、表达式因子以及三角函数等)。
有关bug的分析、寻找与解决
个人bug分析
这三次作业中我虽然只出现了一个bug(空多项式toString返回值应该为0,而不是空串),但是这个bug却反映出个人在整体作业架构设计中思路的混乱之处:为了最终结果优化,修改建立好的架构,使得各处理环节之间耦合度提升,进而导致复杂程度提升,出现了设计时没有考虑到的情况。
更优的处理思路应该是:解耦各环节,新增数据整合环节simplify()(对应到各种表达式类中,就是新增一个方法来优化存储的数据)作为构建过程、求导过程、输出过程这三个环节之间的接口,进而起到润滑剂的作用,辅助最终输出结果的优化。
对比分析出现了bug的方法和未出现bug的方法在代码行和圈复杂度上的差异
第三次作业中bug所在方法是表达式的toString方法,长度并不长(~15行),但是圈复杂度v(G)=7。表明bug所在方法分支判断过多,因此容易出现漏判的情况。更本质的问题还是架构设计,没能降低该方法和其他方法的耦合度的,导致此toString方法需要给其他地方擦屁屁,但是老牛擦不过来了啦。
其他人bug分析
整体思路:随机覆盖+定点测试
首先,每个人虽然架构细节不同,但整体处理一定遵循输入(解析字符串)→处理(求导)→输出(toString)三部,因此利用随机生成的数据可以大致覆盖性地测试到同学代码中绝大多数错误(第一次第二次均利用这种方法测到同学的错误)。
随机生成覆盖性数据,我采用的方法是基于python利用语法树反向生成的方法,设置depth参数控制表达式的深度,利用random函数获得随机系数、指数和符号。
由于每个人的代码架构都不同,可能发生错误的点也不尽相同,因此最好的方法是通读代码并针对性构造数据。由于时间有限,我选择了大家最有可能发生问题的环节构造数据,构造特殊数据也站在生成数据的角度,比如
- 特殊的非法串 :全空格、空串、空括号、括号不匹配等
- 特殊的乘表达式:Factor*0
- 特殊的因子表达式:①大数字,数字+/-1;②幂函数:特殊指数③sin**0等
面向对象思想的再应用
分析自己的三次作业,识别应用对象创建模式的机会,并给出具体的重构说明
在第一次作业中,字符串处理的比较面向过程,但是在创建类时已经采用了面向对象的思想,将表达式细分为Poly、Term、Factor这几个类,最终toString时再统一处理。
在第二次作业中,新增了三角函数和多项式因子,标准的面向对象处理应该是严格按照递归下降的方式处理字符串,递归调用的方式输出表达式,然后再对输出的表达式进行优化。但我为了更方便地优化输出,采用了每一层表达式都维护一个四元组(a,b,c,d),将每个表达式等价地视为a*x^b *sin^c *cos^d,最终创建表达式简化为创建这个四元组。
在最后一次作业中,新增了格式检查和三角函数嵌套,因此上述简化方法就行不通了,只能严格按照递归下降的方法来解析字符串,并同时构建相应的类。不过可以在非递归构建时(幂函数、常数)采用工厂模式简化对象的构建。
通过类图和/或者度量数据来对比重构前和重构后的程序结构,并进行说明
三次作业中,在第一、二次作业之间进行了一次重构,两次作业的类图在上文中已给出。可以看出,两次作业的架构思想上是一致的,重构的原因在于需要应用递归下降的方法来处理字符串,并且程序中存在递归调用,因此修改了各类间的调用关系和相应传递的参数。
新架构思路一
总结来说,面向对象的思想不仅可以应用在实体的构建、操作和处理上。对于规模较大的程序,面向对象的思想还须应用在处理流程的划分上:各处理环节之间应该做到提前确定功能和接口,因而使得内部实现解耦,各部分只需关注自身内部实现,而不用考虑各部分间的复杂影响。同时还需注意,功能划分、接口的设计会对各部分内部实现造成直接影响,不好的划分和设计会对内部实现带来极大困难。
对应到这次作业中,如果优化环节处于输出环节之后,那么优化部分将面对的是一条难以下手的复杂字符串。而如果将优化环节提前到求导环节与输出环节之间,那么就能大大减轻优化的压力。
新架构思路二——优化表达式对象的构建过程
该思路基于面向对象的思想,将递归下降过程中的字符串指针抽象为一个对象Args,集合了递归下降过程需要的所有方法(比如eatBlank、eatChar、getToken等等)。利用工厂模式递归地构建所需对象Poly,而Args作为构建过程的参数传递,这样可以降低构建过程中被创建对象之间的耦合程度)
对比和心得体会
对比学习自己和同学的代码,发现自己主要存在的问题:
- 代码中,面向对象思想体现的不淋漓尽致。这主要可能是:未经严格设计考察的优化过程,增加了代码的复杂性,降低了可读性;对象思维缺乏,过分关注对象的构建过程,而非对象内禀属性对编程提出的要求。
- 架构设计不清晰,类与类之间耦合程度太高,尤其是采用递归下降的方法构建表达式,由于表达式因子的存在而使类之间耦合程度加深了。
- 第三次作业在解析、求导两部分做的不错,但是没有考虑到优化过程新提出的需求,导致在输出环节需要改动解析求导部分的代码,大大提高了代码的复杂性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号