代码练习&论文阅读
代码练习
-
nn.Conv2d的groups参数:
groups参数控制分组卷积,参数默认为1,即普通二维卷积。当groups=1时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=1) conv.weight.data.size() #torch.Size([6, 6, 1, 1])当groups=2时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=2) conv.weight.data.size() #torch.Size([6, 3, 1, 1])当groups=in_channels时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=6) conv.weight.data.size() #torch.Size([6, 1, 1, 1])out_channels必须能被groups整除。
-
由于参数初始化不同,训练结果差异很大。固定参数方法如下
#cudnn确保精度。实际上影响不大,会导致计算效率降低 from torch.backends import cudnn cudnn.benchmark = False # if benchmark=True, deterministic will be False cudnn.deterministic = True #pytorch设置随机种子 torch.manual_seed(seed) # 为CPU设置随机种子 torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子 torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子 #数据读取中的随即预处理。可对python,numpy设置随机种子 import random import numpy as np random.seed(seed) np.random.seed(seed) #dataloader中的读取顺序运行结果也会有差异 -
 论文中最后一层是sotfmax+fc,然而在代码最后一层中加入sotfmax反而损失不下降。查阅官方文档发现在PyTorch中由于损失函数采用cross_entropy,而cross_entropy中这么描述his criterion combines
论文中最后一层是sotfmax+fc,然而在代码最后一层中加入sotfmax反而损失不下降。查阅官方文档发现在PyTorch中由于损失函数采用cross_entropy,而cross_entropy中这么描述his criterion combines log_softmaxandnll_lossin a single function.,实现代码如下:def cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean'): if not torch.jit.is_scripting(): tens_ops = (input, target) if any([type(t) is not Tensor for t in tens_ops]) and has_torch_function(tens_ops): return handle_torch_function( cross_entropy, tens_ops, input, target, weight=weight, size_average=size_average, ignore_index=ignore_index, reduce=reduce, reduction=reduction) if size_average is not None or reduce is not None: reduction = _Reduction.legacy_get_string(size_average, reduce) return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)总结:PyTorch中如果损失函数采用nn.CrossEntropyLoss(),那么最后一层不需要加softmax。
-
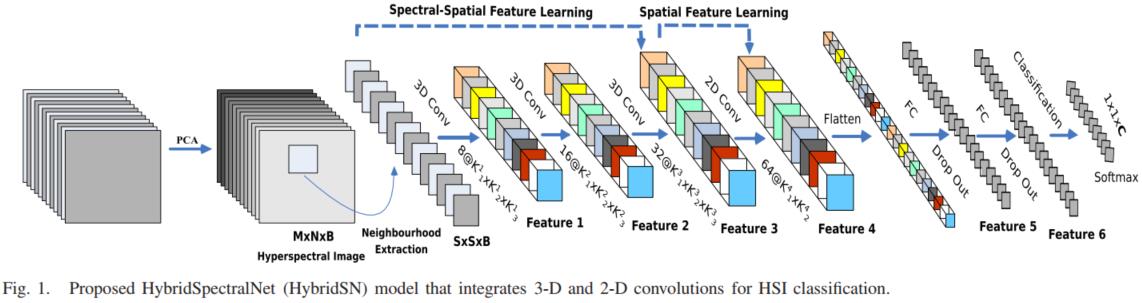
附上HybridSN实现代码与测试结果
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv1=nn.Conv3d(in_channels=1,out_channels=8,kernel_size=(7,3,3)) self.conv2=nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3)) self.conv3=nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3)) self.conv4 = nn.Conv2d(576, 64, 3) self.fc1=nn.Linear(18496,256) self.fc2=nn.Linear(256,128) self.fc3=nn.Linear(128,class_num) def forward(self, x): x=F.relu(self.conv1(x)) x=F.relu(self.conv2(x)) x=F.relu(self.conv3(x)) x=torch.reshape(x,[x.shape[0],576,19,19]) x=F.relu(self.conv4(x)) x=torch.flatten(x,start_dim=1) x=F.relu(self.fc1(x)) x=F.dropout(x,p=0.4) x=F.relu(self.fc2(x)) x=F.dropout(x,p=0.4) x=self.fc3(x) return x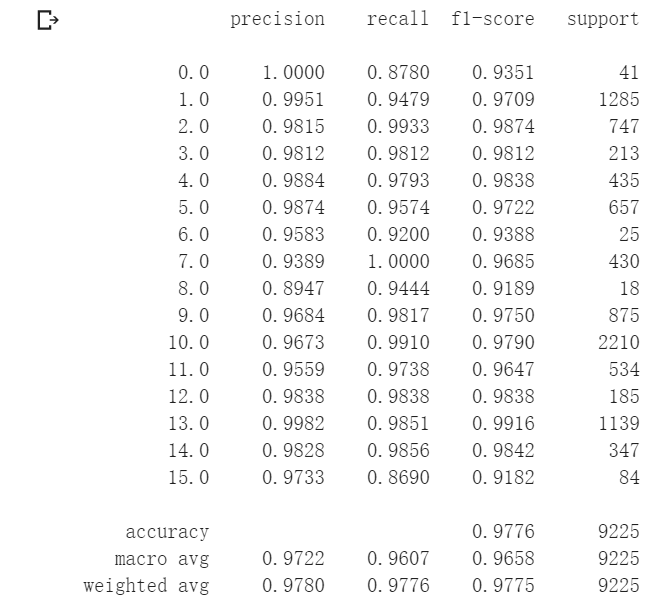
论文阅读
DnCNNs
paper:Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
亮点:残差学习,BN
设纯净图片为x,噪声图片为y,假设y=x+v,则v为残差图片。DnCNNs网络期望学习R(y)=v。即该网络设计的目的就是将真实图片从噪声图片中消去。
ResNet认为直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) +x。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。而DnCNNs的作者注意到,在图像去噪中,噪声图片与纯净图片的残差很小,几乎等价于恒等映射。于是作者在模型中加入残差并证明有效。
BN将神经元的输入值拉回,从而避免梯度消失。实验表明BN与残差结合可提高性能。
SENet
paper:Squeeze-and-Excitation Networks
亮点:注意力机制(通道间),自动学习特征通道的重要程度,并根据重要程度提高或抑制不同特征。
模块结构:Squeeze 和 Excitation
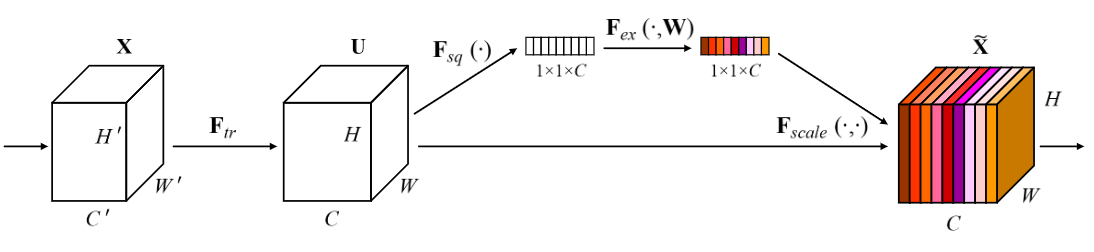
- 模块通过一系列常规卷积操作,将特征通道数C'的输入X经过常规变换得到特征通道数C的输出U。
- Squeeze。对U进行Global Average Pooling,对每个维度进行特征压缩,输出\(1\times1\times C\),将每个二位通道特征变为一个实数,使其具有全局感受野
- Excitation。通过连个FC层去形成每个特征通道的权重。FC中跟了ReLu激活。通过两个FC层,既增加了非线性,又降低了参数量。
- Reweight。将Excitation的输出看作每个特征通道的重要性,并以其作为权重应用在先前特征上。
DSCMR
paper:Deep Supervised Cross-modal Retrieval
亮度:找到不同模态样本的通用表示空间,三个loss
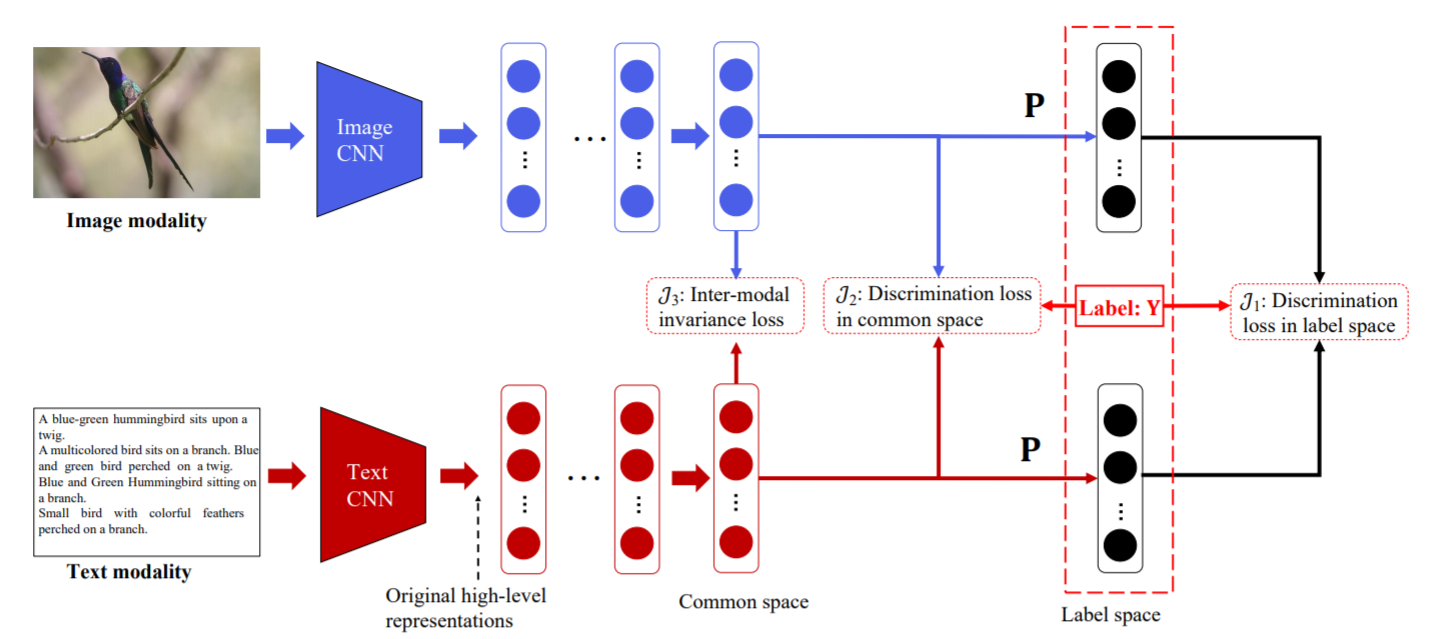
结构:两个子网络。ImageNet处理图像,TextCNN处理文本。之后通过几个FC得到通用表示空间的表达,并强制共享最后一层的权重,使其表达尽可能相似。
损失函数:
\(J_1\)用来表示分类结果与\(Y\)的差别,衡量标签空间的判别损失。
\(J_2\)表示两个特征属于同一类别的概率,即图像与文本,图像与图像,文本与文本的相似性。
\(J_3\)表示通用表示空间中样本的距离度量。
最终损失函数是三者相加:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号