
人工智能的iPhone时刻:ChatGPT原理,风险与机遇
恰逢OpenAI发布了GPT4,来蹭一波热度 :P
从2022年底到2023年初,由OpenAI推出的ChatGPT可谓是最火的科技名词了,哪怕是不了解科技新闻的普通人,也会听说过ChatGPT这个词。
由于我并不是专业的NLP从业人员,所以难免有些理解是错误的,希望大家看到之后可以不吝赐教 :)。那么结合自己的学习和思考,我想从两个方面分享自己的所思所得:
- 什么是ChatGPT
- ChatGPT会带来哪些风险和机遇
1 什么是ChatGPT
ChatGPT是“Chat”和“GPT”的组合,“GPT”是“Generative Pre-Training”的缩写,即生成式的预训练。组合起来就是,生成式预训练的聊天模型。
ChatGPT推出时是用的是GPT3.5,本文完成时(北京时间2023年3月15日),刚好发布了GPT4。
ChatGPT之所以效果可以这么好,与以下三点密不可分,通过查阅资料,我讲结合自己的理解尽量简洁明了的说一下大概原理:
- GPT:生成式的预训练
- Zero-shot
- 贴近人类智能成长的训练方式
1.1 GPT:生成式的预训练
那什么是生成式的预训练(Generative Pre-Training)呢?我举一个大概的例子,比如这样一句话:
“梅西是2022年世界杯金球奖得主”,GPT在生成的时候,会基于前文的内容,预测后面1个字的输出;然后把这一个字加到前文中,再根据此预测下一个字的输出。
对应到这个例子,根据“梅西是2022年世”,会推断出““梅西是2022年世界”;然后再根据“梅西是2022年世界”,推断出“梅西是2022年世界杯”;以此类推。
问题来了,你可能会好奇,理论上说,一句话之后的一个字有非常多非常多的可能性,比如GPT是怎么知道“梅西是2022年世界”之后的字是“杯”,而不是“球”或者其他的字呢?这种预测是基于什么做的呢?答案是基于训练数据,比如书籍、新闻报刊、网页等等,这些文字内容都可以作为训练数据,通过神经网络训练的方式,结合损失函数,经过超大规模数据+超大规模运算,才能得到这样一个大家口中的拥有超量参数的“大模型”。需要介绍的是,GPT的生成式预训练是无监督的:

那么这个大模型有多“大”呢?给你一个直观的感受:
- 关于训练数据量之庞大:
2018年6月GPT-1:约5GB文本,1.17亿参数量
2019年2月GPT-2:约40GB文本,15亿参数量
2022年5月GPT-3:约45TB文本,1750亿参数量
- 关于数据的生成量之庞大:
GPT3在2022年的5月,每天产生450亿词,换算成每小时生产100W本书
- 关于有多费钱:
OpenAI背后的金主是微软,传闻GPT3的训练耗费了1万多块高端GPU和1200万刀的电费
1.2 “Zero-shot”
这次ChatGPT给人们最大的惊喜在于,这是让人们第一次感受到什么是真正的“人工智能”,更深入的说,人们觉得ChatGPT是第一款可以“听懂人话”的人工智能。因为以前所谓的人工智能,比如SIRI、微软小冰、小爱同学等等,只能够理解精确而简单的命令,无法真正理解日常生活中人与人之间交流时,复杂语句中的意图和含义。以前大模型如果想完成一些下游任务,仍需要根据处理的任务,对大模型本身进行微调训练,就如同GPT-1做的那样:
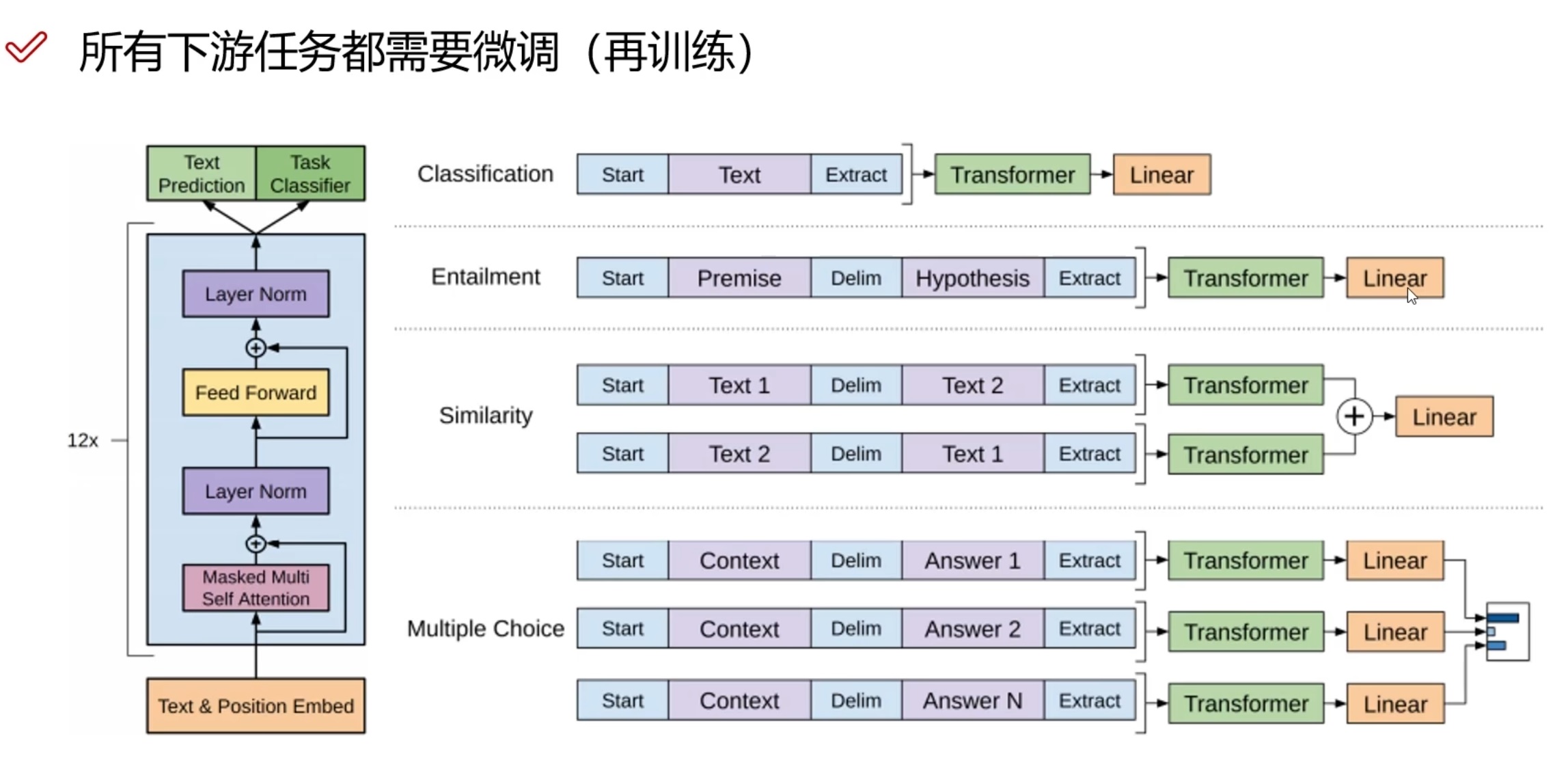
而ChatGPT跨越的秘诀在于“Zero-shot”,不需要再训练。
为了回答什么是“Zero-shot”,我们首先要介绍“下游任务”的概念。在以往,一款人工智能模型训练出来之后,是无法直接帮助人们处理工作的,比如翻译、根据规则进行推理和计算等。这些翻译等人们想要人工智能进行的工作,就是“下游任务”。
在人工智能模型与下游任务之间,需要人们进行举例,告诉人工智能模型,要进行什么样的任务,即“打个样”。有以下三种:

- Few-shot:需要举多个例子理解任务。
- One-shot:需要举1个例子理解任务。
- Zero-shot:不需要举例子,完全通过自然语言的描述来理解任务。
显然,ChatGPT做到了不需要微调,用“Chat”提示(自然语言)告诉模型需要完成什么样的任务。
那么你会好奇,这是如何做到的呢?答案是把自然语言的提示和ChatGPT的回答相结合,以此进行有监督学习。
不熟悉机器学习的人可能会有疑问,这里的监督是?其实就是人工标注,由海量的人工来判定,ChatGPT的回答究竟是否符合自然语言的提示;自然而然,在有监督学习的干预下,ChatGPT的“Zero-shot”的能力会越来越强。而需要海量的人工来帮助做监督学习,也是为什么许多人调侃这真的是“人工”“智能”。另外,通过人工标注,还可以对宗教、政治、种族歧视、人身安全等敏感话题进行特殊处理,以此来规避道德与伦理问题的危险。
1.3 贴近人类智能成长的训练方式
根据前面的介绍,大家有没有发现,“ChatGPT”的“成长史”,与人类出生之后学习语言、学习逻辑、学习解决问题的能力的过程特别像。比如人在咿呀学语的阶段,刚开始是无法说出有意义的一句话的,而经过“训练”,这里的训练数据就是爸爸妈妈、身边的人和环境说的话,慢慢就学会了说完整的句子。而人类“Few-shot”的能力,也来自于爸爸妈妈、亲人老师的“有监督学习”,使得可以理解对话中的“意义”和“任务”。

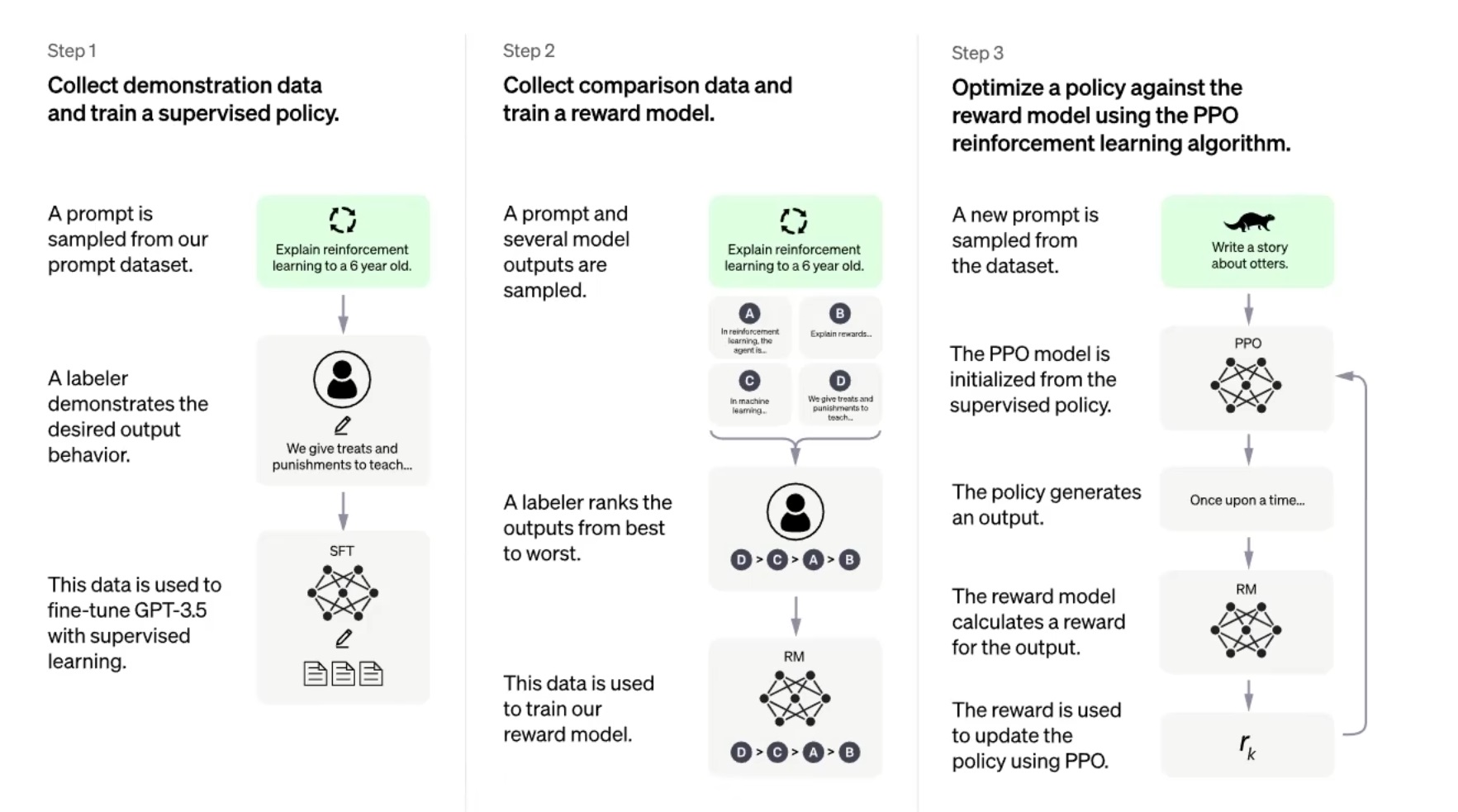
在这其中,需要介绍的是强化学习和奖励模型的概念。

由于GPT是无监督的,而ChatGPT是有监督的,所以针对同一个问题,ChatGPT会有多种贴近提示的回答,显然,这些回答里面有的回答的好,有的回答的差,为了让ChatGPT更聪明,自然就需要对这些回答进行排序,选出那些更合适更聪明的答案。这个过程救引入了奖励模型的概念:通过人工前期标注(比较)回答质量的高低,通过计算奖励模型中的损失函数,奖励模型可以对回答的质量进行排序。一般会采用Top k或者Top p的方式进行筛选,即保证了答案的多样性,也保证了答案的质量:

以下是OpenAI官网给的ChatGPT训练的流程图:
2. ChatGPT的风险与机遇
2.1 风险:训练集的偏见
我们之前提到,GPT3的训练数据来自于书籍、新闻报刊、网络等,这里需要注意的是,GPT3只用了英文的数据。这里面值得令人警惕的是,书籍、新闻报刊、网络等信息,这些信息在生成的时候往往就是带有偏见性的,就好比孩童会下意识的模仿父母和周围人的说话方式与观念。
假如是训练数据是“苹果手机比华为手机”之类的偏见信息还好,只会形成商业上的偏见。
但如果有的偏见信息是“第二次世界大战中攻占柏林的是美军”等这样的信息,GPT就会形成危险的政治偏见。
可以预见到的是,由于人工智能大模型带来的巨大生产力的提升,今后人们会更多的依赖和看重人工智能对工作和生产效率的提升,与此同时也会深受ChatGPT这类人工智能的意见与观念的影响,因而这种训练集偏见带来的人工智能的偏见是十分危险的,并且也必将是各国在意识形态、社交舆论领域争夺的制高点。
2.2 风险:潜在的信息泄露、依赖与“卡脖子”
一方面,可以预见的是,ChatGPT这类人工智能的强大,定会使得将来越来越多的人们习惯依靠这类人工智能完成工作。我们之前讲过,ChatGPT这类人工智能大模型并非是离线的,需要将交互信息上传至服务器进行在线推理才能获得结果。在这个过程中,大量的工作数据、会议记录、文件摘要、科研数据资料会上传至ChatGPT的服务器,因此政府、科研等敏感信息有被泄露的风险。
另一方面,在不久的将来,由于ChatGPT这类人工智能的强大功能对人类工作效率的巨大提升,使得在将来,一个人能够完成多个人的工作量,极有可能成为如同水、电、石油一样重要的生产资料;另外考虑到中国面临的出生人口不足引起的劳动力缺口隐患,在未来我国的经济高速增长对人工智能大模型的依赖有可能会超越我们的想象,那么中国将又面临在关键领域被美国卡脖子的风险。
2.3 机遇
基于上述风险与ChatGPT可预见的巨大机遇,中国要开发自己的人工智能大模型是必然的发展趋势,不仅大型互联网公司一定会进行激烈的竞争,出于国家安全与战略的考虑,发展国家人工智能大模型也是可预见的。作为从业者,那么对芯片市场而言,伴随而来的机遇在于2个方面:训练与推理。
显然,训练过程中需要的巨大数量的GPU进行“炼丹”。人工智能大模型依赖于巨大的训练量,而巨大的训练量又离不开高端GPU的算力支持。由于人工智能大模型是需要一直发展的,这代表几乎每时每刻都需要不停的对大模型进行训练。这里有两点需要考虑到,一是对GPGPU芯片的需求规模特别大,每一个人工智能大模型背后都需要庞大规模的GPU芯片数量支持。二是由于这种规模的训练对能源的消耗是惊人的,因此当GPU的架构和制程的发展降低了能耗时,也会产生GPU更新换代以降低能源消耗的需求。
另一方面,在大模型训练好之后,并不是一个离线的程序,仍然需要在线交互与推理才能获得答案,因此应用过程中,一定会涉及到处理任务过程中海量的推理需求,推理的过程也需要AI推理芯片的支持,这里的需求也必定是一个惊人的数量级。
在中美对抗的大背景下,我相信ChatGPT的横空出世,就是国产GPGPU的“iPhone时刻”。
参考链接:
- OpenAI官网:https://openai.com/
- B站一个很好的讲解ChatGPT原理的视频:https://www.bilibili.com/video/BV1TG4y1C7MT/?spm_id_from=333.999.0.0&vd_source=70714d81c1a84e52a152354bc31f1406

 浙公网安备 33010602011771号
浙公网安备 33010602011771号