OO第三单元总结
OO第三单元总结
设计策略——阅读理解与实践
本单元中运用JML规格作为具体的文档需求来进行开发,从根本的角度来说,是使我们理解设计与实现相分离的开发思路,运用JML为载体作为设计说明,而让我们来具体实现其提出的要求,能在这个过程中对这一理念理解的更为深刻,因而我觉得除了要讲实现规格的设计策略之外,还要讲讲规格设计和这种实现之间的微妙区别。
规格实现
首先还是说明对规格实现的设计策略。首先,为了找到比较合适的设计思路,需要首先将规格通读一遍,了解每一个函数要实现的功能,而不是每读一个函数的规格就写一个函数,因为此时对于整体的把握还不够,如果刚开始读规格就写,必然需要涉及一些容器的选择、函数的实现方式方面的问题,而接着往下写时,发现之前的实现方式导致新的函数功能很难实现,就得改之前写的代码,严重时甚至要进行重构,既浪费时间精力,又导致出错率上升,这是得不偿失的。正如我们做阅读理解一样,如果只是看了题目,看了文章的一部分,觉得这一部分和题目对应上了,就开始做题,就很容易出现断章取义的错误,其含义很可能有偏差,甚至和你写的恰好相反,而把文章看完之后再改,只能追悔莫及。
在通读完一遍规格之后,还是不能写代码的,因为这时候还只是对于功能有大致的把握,具体实现的方法却是模糊的,更况且每次作业中总是有几只“拦路虎”呢。借用毛主席一句话说,要“集中优势兵力歼灭敌人”,对于功能简单的函数,实现的方法各种各样,其效率本质都区别不大,但对于功能比较复杂的函数——诸如第一次的“query_block_sum”、"query_circle",第二次的"send_message",第三次的“send_indirect_message”、“delete_cold_emoji”等,在很大程度上决定了数据结构、别的函数的算法应该怎么设计,因此需要投入时间去思考这些“拦路虎”的具体实现,在想清楚之后再开始写代码,进度就会顺畅很多。这也是“二八定律”的一种体现,花80%的时间在20%比较难的工作上,才能起到比较好的效果。
而在具体实现的过程中,那些更复杂一些的函数我也是先留着不写的,这样反过来能起到一个验证的效果,验证之前实现的函数会不会对这个比较复杂的函数产生影响,之前那些简单些的函数在实现过程中是不是引入了一些不必要的实现措施等等。由于之前在设计阶段已经做了比较详细的考虑,此处出现的问题大多是小问题,很快能纠正,这样保证一个前后呼应,不至于把这一次作业中出现的多余的东西遗留下来,为下一次的增量开发带来不必要的麻烦。
规格设计
以上是我通过规格设计进行实现时的一些思考,下面讲讲规格设计是什么和为什么这个问题。老师上课说,“设计要与实现相分离,实现要与测试相分离”,这种正交化的开发模式,是很值得细细品味的。一方面,设计时如果考虑实现上的种种细节,很容易顾此失彼,因小失大,使整个设计陷入细节的漩涡中;另一方面,如果没有设计,那么测试时也都是白盒测试,根据已经实现的代码构造测试样例,就很有可能忽略很多的情况,达不到测试的效果。因此老师上课还说,像现在这种工程量比较小的项目,完全可以先把函数写完,但函数体都不实现,等所有的函数都写完之后再对函数体进行填充。这样的一种方法,体现的正是正交化的开发模式,而其所解决的问题,也正如老师所说,“设计上出现的问题往往要花十倍的时间才能从实现上补回来”,这的确是不假的。由此可以看出,规格设计其实是粗线条的,轮廓的,注重类与类、函数与函数之间的协调配合,注重所期望达到的效果和功能;而在规格的实现上,则更注重于代码的细节,如边界值的处理等,注重容器的选择,注重算法、效率,两者的关注点的侧重,我觉得是这一单元的核心所在。
测试——由小及大、由大及小
这个单元另一收获比较大的点在于学会的测试方面的内容,单元测试、随机化数据测试都有涉及一些,也就记录一下关于测试方面的一些体会。
单元测试
首先是单元测试。这是自己第一次接触到这个概念,之前的测试都是自己构造几个测试样例,然后总体进行输入输出,判断对应的输出对不对,如果不对的话就由最高层往最底层不断深入的单步调试,直到找到问题所在,这也是我之前对测试的所有理解。而深入了解单元测试之后,我觉得我对测试有了一个新的认识——测试,应该从最底层开始测;做单元测试,就像是一个向上搭积木的过程,只有把下面的部分搭好了,搭结实了,上面的东西才能稳固,才能有信心不会轰然倒塌。
而关于单元测试,我就要推荐一下下面这本书了:《单元测试之道Java版:使用JUnit》,它从一个小故事出发,几乎涵盖了单元测试的各个方面,首先可以看一下对单元测试概念的理解:

在这样的基础上,我们可以总结出单元测试的几个优势:
- 增强对已完成代码的信心
- 减少代码全部写完之后调试的时间
- 梳理设计思路,作为“可执行的代码规格”
- 不需要运行整个程序即可测试,自动化程度高
大概了解了单元测试的一些要点,那么重头戏就来了,怎么写单元测试呢?我想不只是单元测试,所有的测试都会有这个问题:如何构造测试样例?我们可以首先看看书里是怎么说的:

首先是值得测试的一些方面,在我们这单元的测试中,除了“强制错误条件发生”,其余可以说都有涉及——正确性和边界条件不用多说,反向关联如增加人和删除人、交叉检查如不同算法对结果的印证、性能要求如运算时间的限制,这些都是我们测试的方法,而具体的测试用例的构造,可以看看边界条件的说明:

这7个测试方面恰好是英文单词“CORRECT”的缩写,可以用来帮助记忆,从这7个方面可以简单介绍一下如何构造测试样例:
- 一致性:用和正常输入八竿子打不着的输入进行测试,看看程序能否正常处理而不崩溃(如输入一串乱码
- 顺序性:如果输入有序构造无序序列、反向有序序列测试,如果输入序列要求无序则构造有序序列
- 区间性:构造等价类——正常值、异常值、边界值
- 依赖性:一个测试用例中用到了好几个类的函数,或者依赖于外部设备的状况,需要进行模拟(本单元出现情况较少)
- 存在性:构造输入之前假设已经存在的对象还未存在的情况等
- 基数性:计数时采用“0-1-n”原则,测试是否能处理0个、1个或者多余一个的情况,其实也是一个等价类的划分
- 时间性:多线程时是否能准时发生,是否能按照特定的顺序进行(本单元中出现的较少)
了解了一些基本的原则,自然是可以从这些方面入手来构造测试用例的,然而还有一点要注意的是由于已经提供了JML,对于异常情况的处理也是测试时要分类注重的,因此单元测试的原则大概可以概括为:先把行为分为正常与异常,分别构造样例;再在正常情况里对可能出现的各种等价情况进行细分,尽可能做到分支的覆盖,再分别构造测试样例。如下图所示:
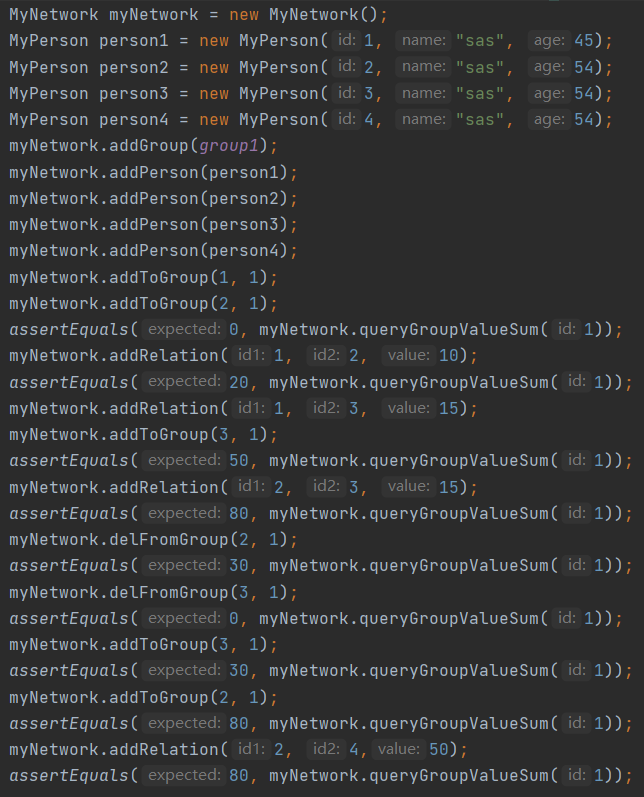
这是测试Group中socialValue的函数的测试用例,没有测试异常的情况,但对正常行为中可能出现的情况进行了分类,如先把人加入Group当中,再加关系后查询;先加关系,再把人加入Group当中查询;把和Group中没有关系的人加入Group再查询等等,还包括删除人时的分类,在此不再赘述,大体展示了一个分类的过程。
随机数据测试
当然单元测试只是一个基础,另外的随机测试也是在这个单元有所用到的,用python生成数据,用命令行运行jar包,在用python进行对拍检查,到之后写脚本进行自动化测试,虽然也是因为这个单元生成数据以及对拍检查比较简单,但也大概体会到了自动化测试的乐趣,写一个评测机也不算什么难事,重要的是克服了心理上的一些障碍吧。
总得来说,单元测试由小及大,随机数据测试由大及小,两者相得益彰,很大程度上保障了程序的正确性。
容器——实事求是、因地制宜
这个单元另一个很重要的能力培养在于对容器的选择与使用,以下是我自己的一些思考与总结:
索引容器
首先是对于JML中的数组,如果是增删改查较多的,而且往往只对单独一个元素进行操作的,利用HashMap这样的索引容器效率往往是很高的。像这三个单元中Network里的Person、Group、Message,基本上都是增加一个元素,查询其中某一个元素的属性的等等,因此我都用了HashMap的方式进行存储:

线性容器
而对于JML中经常需要遍历的、甚至对于存储顺序有特定要求的,则一般使用ArrayList或Vector这样的线性存储容器更能满足要求,首先在线性容器当中遍历,直接遍历了对应的元素,而如果在索引容器中遍历valueSet,还要维护对应元素与索引之间的关系,效率上是不比线性容器的;其次,线性容器很容易维护元素加入的顺序,天然具有顺序性,而索引容器则很难实现。
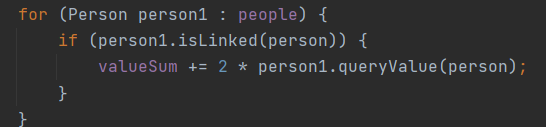
举例而言,我在Group中存Person的时候,用的就是ArrayList,因为Group中增删人、查询特定属性时往往是查询Group中所有Person的统计值,需要经常遍历,因此用了线性容器:(addPerson时)
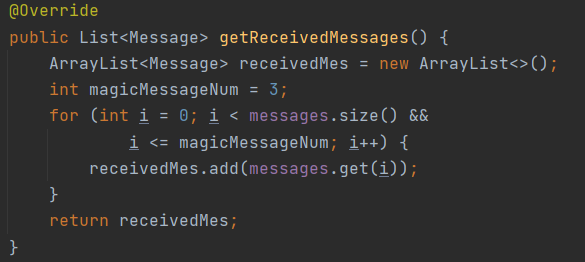
而在Person类中,由于getReceivedMessages()方法要按序输出这个Person最近收到的四条消息,因此在增加Message和调用此方法输出时,都利用了线性容器的特性:

当然,如果内存足够的话,可以把对同一个事物进行描述的线性容器和索引容器封装成一个类,当索引容器实现容易时用索引容器,当线性容器实现容易时用线性容器,可以充分发挥两者的优势;当然,天下没有白吃的午餐,由于是对同一事物进行描述的,当一个容器变化时,另一个容器也要跟着变,所以得放到一起进行维护,否则很容易出现问题。
嵌套容器
而对于更复杂的情况,可以采用容器嵌套的方法实现。例如我想遍历某一个Person所在所有Group,就可以采取如下的方式实现:

这里既利用了索引查找的效率性,又利用了线性遍历的效率性,可以说是以上所说到的两者的一种结合。至于更更复杂的情况,可能就需要再设计单独的类来解决了,当然类里放的也还是容器,但在这里就不再多说了。
性能问题——错误往往来自简单引起的大意
这一单元在设计难度上少了一些,但会遇到实现上的性能问题,在这里也一一总结一下,以为后人提供一点借鉴。虽然是从作业进行总结的,但里面总有一些东西是“道”的东西,希望自己能够说的有用些吧。
存在路径与最大连通子图数
第一次作业复杂度最高,对性能要求最高的就是这两个功能,到后来才听说大家都是用并查集来做的,我却有点不太相同,是自己建了一个“连通子图”的类,对这两个函数进行管理和实现,当Network加入Person时,由于他和其他人其他人都没有关系,就直接加入这个类当中;而对两个Person之间增加关系时,就把其中一个人所在的最大联通子图中的点都挪到另一点的最大联通子图当中(用上面讲到的嵌套容器进行实现)

这样在判断两个Person是否存在路径时,只需要判断他们是否在同一个点所代表的ArrayList里即可,而最大连通子图数更是只要查询这个容器的大小,基本上能把每一个操作的复杂度降为O(n)。
如果用传统的邻接矩阵的方式进行存储的话,时间复杂度都在O(n^2)左右,因此是可能出性能问题的。但并查集的实现应该是比我的这个比较直观、形象、容易想到的方法效率更高,不过没有研究过,所以也不说太多了吧。
群(Group)综合属性计算
关于Group中属性计算的性能问题,在第二、三次作业中都有涉及(因为我第二次作业优化的不彻底),主要集中在年龄平均数、年龄方差和群社交值(group social value sum)上,所以在这里统一总结一下。
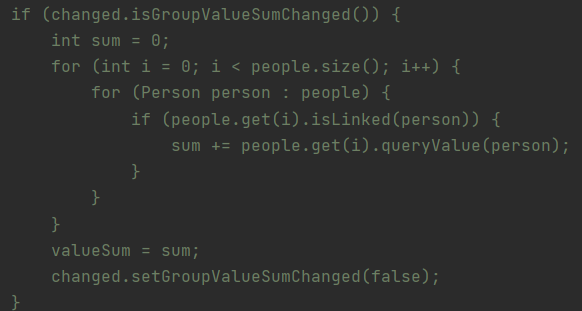
首先对于这三者,有一件事是可以做的,那就是“不变不算”,这也是我犯的第一个错误,就算Group根本没有变化过,每次调用函数时都需要再算一遍,这就是纯粹的多余计算,为什么不能记录下来,直到群里的属性发生变化了再进行计算呢?当然,真正算的时候也应该是变化完之后调用函数的时候,颇有一点“写时复制”的味道。
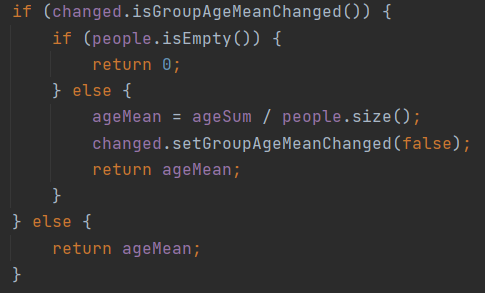
其次是关于平均值和方差,是可以利用冗余存储进行优化的。每次添加或删除Person的时候,变化一下年龄总和和年龄平方和,这里是O(1)的复杂度,而查询两者的时候,也只是做一些简单的加减乘除,也是O(1)的复杂度,这就从每次都要遍历的O(n)复杂度大大下降了。不过其中平均值的计算倒还好说,而方差就历经坎坷,一开始只想到了按定义算,就以为只能遍历,后来又听同学分享了方差的计算公式,结果由于这次作业算方差时是要进行地板除的,而化简之后的方差计算公式直接把这个除法融合进去了,结果一直不对,又使我以为还是只能遍历,后来又是听同学说还有一个不化简的计算公式可以用(是没脑子的人没错了),这才真正的大功告成;这才发现学科之间的融合交叉有多么的神奇与重要,用概统的知识降低时间复杂度,实在是一件很有乐趣、很奇妙的事。
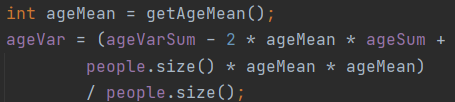
最后是关于social value sum的计算,之前也是觉得只能遍历,而且还是O(n2)复杂度的遍历,因为还需要判断每一个人是否和其他人存在路径,但觉得每次加人、加关系都要进行遍历的话效率更低,于是也就没多想,结果发现O(n2)复杂度还是太高了,而反倒加人、加关系、减人的都对数组进行遍历的O(n)时间少的很多,这让我对复杂度的理解大大加深了,O(n2)和O(n)的差距还是相当之大的,即使O(n)无论从写代码还是感觉的效率上都要复杂很多,但实际上运行起来速度还是快很多的,这次算是长了个教训吧,之后对于复杂度的分析,不能只停留于感觉上,为了图代码简单就随随便便写O(n2),效率还是很差的。
加权最短路径
这个其实问题不大,标准的迪杰特斯拉加上堆优化就能比较轻松的通过测试点,这里也是分享同学的一个经历,就是标准的迪杰特斯拉复杂度是O(n2),而堆优化之后是O(nlogn),这两者的运行时间同样差了不少,结合上一点来看,复杂度在运行时间上的效果是立杆见影的,这也是这个单元给我留下的深刻教训。
总体来说,自己犯的错误都是自己不太重视的地方,像对于Group中属性的计算,我感觉没有任何问题,却犯了无数的性能上的失误,倒是像图论当中复杂度要求较高的地方,反而实现的要好一些,因此对于大量数据的统计计算,是万不可马虎大意的。
架构设计
首先讲讲自己的架构设计,所规定的那几个类就不用再多说了,主要是讲讲自己维护图模型的几个类,但其实也没什么太多可以描述的,一方面是为了求最大连通子图数设计了一个连通子图类,上文也已经讲得比较清楚了,另一方面为了计算两点之间的最短路径,构造了一个图类,用了邻接表的数据结构来进行存储,用迪杰斯特拉加堆优化进行计算,整个的思路是分类的,同一个对象用不同的数据结构表示,从而实现特定的功能,我觉得这是这一单元设计上的一个要点。
当然,在这个单元中,自己设计的部分是比较少的,主要的设计任务都还是在官方包当中,每个类的设计、每个函数的功能,都已经完成的比较全面了,这里也是做一个梳理,把这个层次化处理的结构作为自己学习的样例。
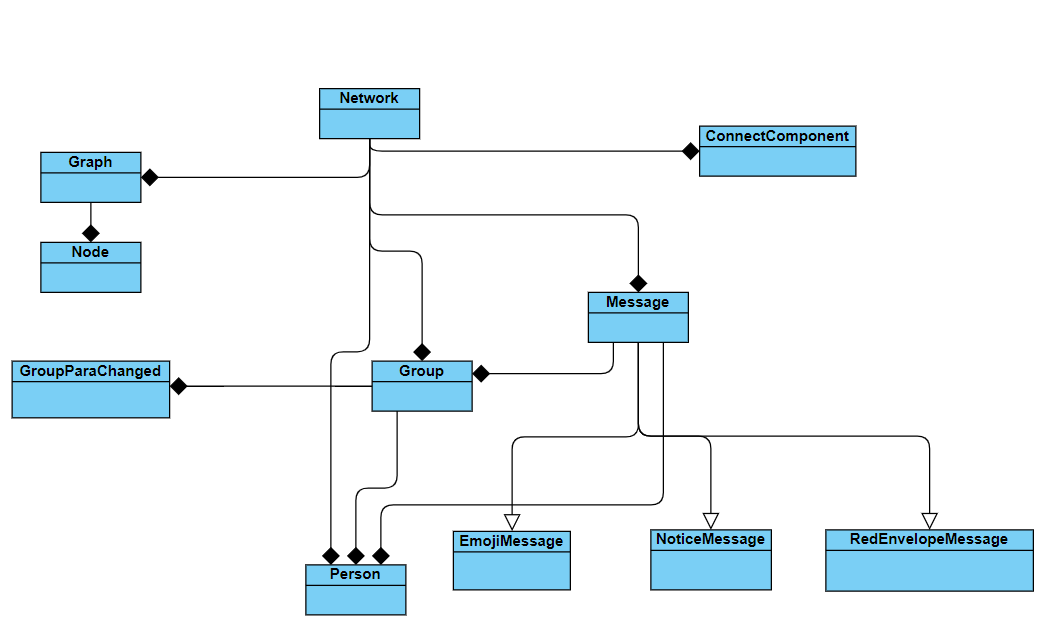
总体而言,Person作为比较底层的类,经常被其他的类作为属性所应用,是构成整个社交网络的基本组成部分,在此基础上生发出群类,用于对一部分人进行统一管理、统一查询等等,在人和群的基础上,又引入了消息类,用于人与人、人与群之间的消息互通,其被三个具体的消息类所继承,用于实现特定的功能。而对于社交网络的总体管理,则交由Network类进行负责规划,人、群、消息都作为属性存储在社交网络这个类当中,同时为了辅助进行的图计算处理,在Network中引入一个邻接表图类和一个连通图类管理相应功能,做到层层细化,分层管理,设计逻辑比较清晰,从中能学到什么是真正的迭代开发,高瞻远瞩。
感受
这个单元总体难度不大,设计部分的工作量由官方代码承担了很多的部分,理解JML的过程让我找到了高中做文言文和英语阅读理解的感觉,还挺有意思的。虽然工作量不大,但能学习到的东西细细体会还是比较多的,像单元测试、评测机、复杂度控制、容器的选择等等,也算是在比较轻松的过程当中慢慢收获吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号