OO第一单元总结
OO第一单元总结
引言
整篇总结共分为四部分:
- 架构分析
- Bug分析
- 重构经历总结
- 心得体会
其中架构分析部分较长,展现了三次作业的整体架构与与设计过程中的思路;心得体会部分是笔者对这一单元作业思考的结晶,希望能对大家有所启发。
三次作业,三种读入 ——架构分析
从第一次作业说去
第一次设计的类图如下:
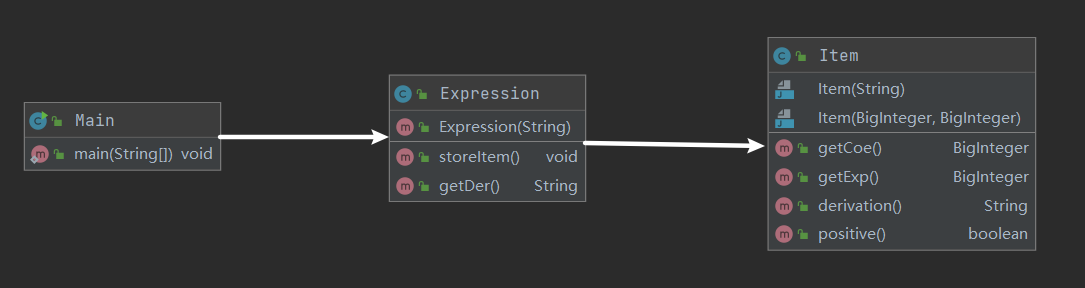
Main类较为简单,主要实现的功能是从控制台读入输入数据,再对表达式进行求导;Expression类包括一个构造函数,通过读入字符串生成表达式,用getDer函数进行求导;Item为单项式类,包括两个构造函数,两个得到成员变量的函数,一个求导函数。总代码行数共计248行。
读到这可能会发现有两个成员函数我并没有介绍,因为这两个函数实在是太失败啦。首先是Item类里的正负判断函数,这个函数是用来干嘛的呢?我写博客的时候也费了一通脑筋,最终发现是在Expression类里求导时判断项是否为正,如果为正就要添上一个加号。好家伙,真是一个天才的设计!既增加了Item类与Expression类之间的耦合度,又使得Expression的求导函数的控制逻辑变得很复杂,而这个函数更是完全没有必要的——这件事为什么不能直接在Item求导的时候做好呢?
而从中也能看到另一个问题,就是求导和字符串的输出交融在了一起,边求导边输出字符串,虽然在这次题目要求比较简单的时候没有出问题,但还是令笔者感到一阵恶心,这样处理很丑陋,完全违背了面向对象的设计思路,此时求导不再是求导,而是单纯的为了满足字符串输出的要求,如果此时将求导换做求二阶导,整个求导的代码就要进行大改,十分复杂;但如果将求导与输出分开,则只需要对求导的的部分进行简单的修改即可,几乎可以在5行之内解决,这就是面向对象设计的好处,因为求完导之后得到的还是一个项,而项的输出方式是不变的,所以只需要改操作方式即可。
另一个奇怪的函数是Expression类里的storeItem,这相当于是一个合并同类项的函数,问题在于我在构造的时候已经把读进来的项存入ArrayList里了,调用这个函数是把ArrayList里的项进行合并存入TreeMap中,现在看来是毫无必要且臃肿的,为什么不能直接在构造的时候通过TreeMap存储呢?
再谈到整体的设计,最难处理的一块在于怎么读入所提供的表达式,由于指导书推荐使用正则,于是...
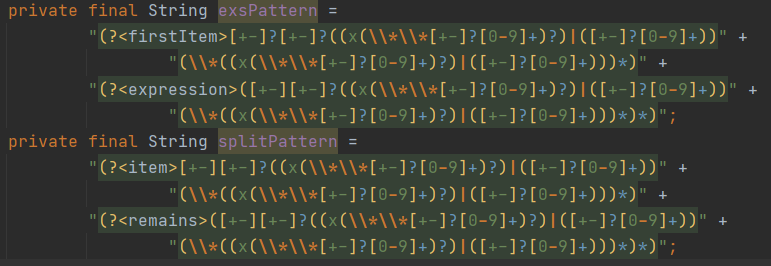

这里无脑地使用了大正则对输入字符串进行匹配,由于对正则表达式掌握不熟练,中间出现了各式各样的bug,处理过程也相当的面向过程,这里就不详细描述了。值得一提的是,由于正则表达式不支持递归匹配,所以接下来的作业只能另谋出路,但究竟该用什么方法呢?
徘徊游离,回归原始
第二周仔细揣摩了老师上课所讲的内容,然后仔细阅读了学长写的那份用C语言实现四则运算的面向对象设计的代码,对这一次作业的设计思路有了很明显的启发,于是仅用了一点点时间,我就把该有的类都建好了: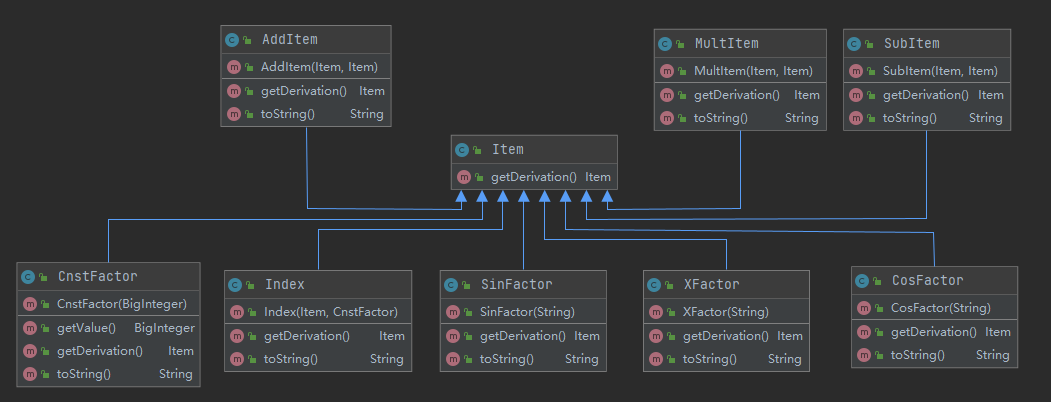
其中,所有的xxxItem都继承于父类Item,上半部分为组合项,下半部分为原子类项,除了常数因子需要访问其值之外,其余类都只有一个构造函数、一个求导函数和一个输出函数,非常简洁。这样设计有两个好处,一是设计思路清晰,对于每一个类,只需要实现自己需要做的事——求导和输出即可,至于外界要干什么都不关心,这就极大的减小了类与类之间的耦合度,无论是写还是用都相当方便;二是将求导与输出分离,求导只管求导的事,输出只管输出的事,方法之间的耦合度较低,能够先保证正确性再化简。
但随后就出现了大危机:怎么读入?
大正则肯定是不行了,那还能怎么解析字符串呢?经过查看讨论区的帖子以及和同学的探讨,心中渐渐被两种方法所占据——递归下降和后缀表达式生成表达式树。经过对递归下降的从入门到放弃,最终还是选择了后者,之后的工作全花在了怎么生成表达式树上,然后出了很多面向过程的bug,诸如符号的管理范围、字符串的解析顺序等等,耗费了大量的时间,以至于到了最后已经没有时间进行优化了,感觉很可惜。
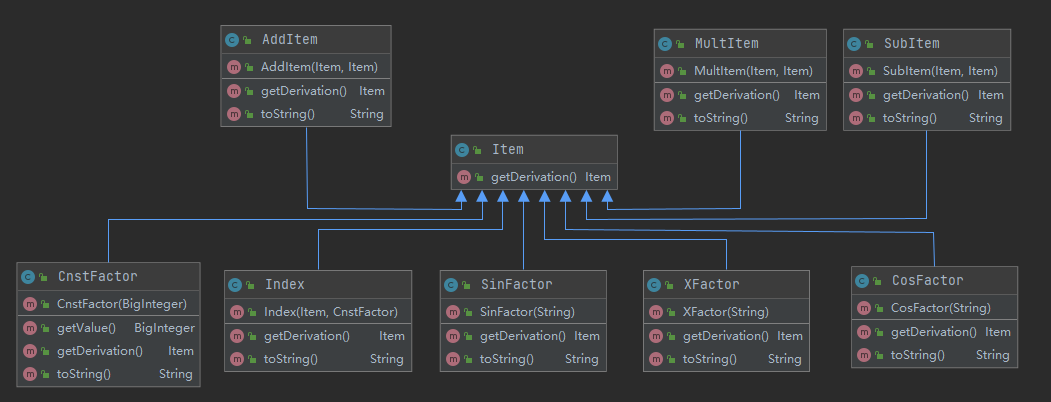
完整的UML图如下:
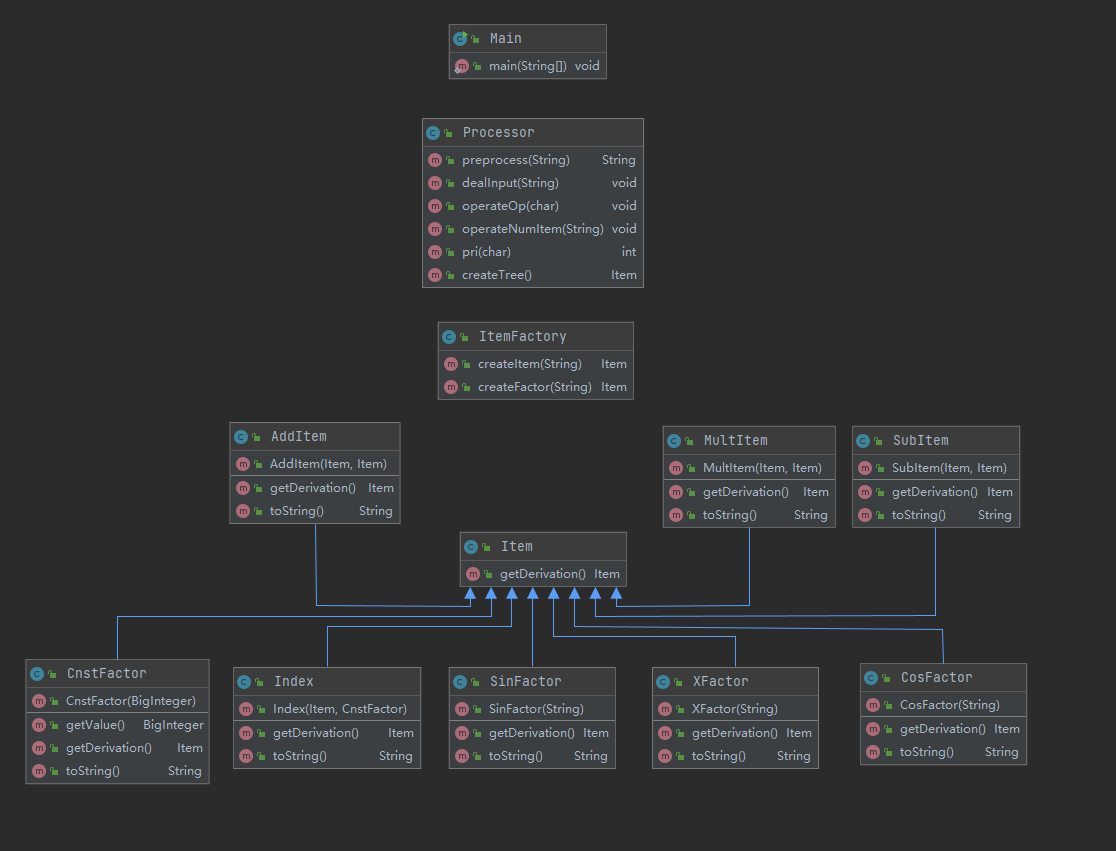
Item及其子类的设计考虑想必无需多说,不过在设计上还可以更加更加优化:将上半部的运算组合类抽象出一个组合类出来,组合类中的成员属性以及构造函数都可以进行统一使用,只有求导和输出的方法需要进行改写;下半部的因子类可以抽象成乘方类,因为都可以看作底数**指数的形式,无非是指数有可能是1罢了。如此一来,可拓展性可以得到大大的增强,之后无论是加入其他组合运算符,如除法、取模,还是加入表达式乘方、tan(x)函数,都能纳入这一架构中,并通过很简单代码修改进行实现。
而对于外部的控制单元,Main函数从控制台读入数据,将字符串交予Processor进行解析,Processor通过预处理以及后缀表达式生成树的算法,生成表达式的根节点,再通过根节点进行链式求导,得到求导后的根节点,用此根节点调用toString进行输出,整个处理流程还是比较清晰的。美中不足的是字符串解析时进行了删空格、连续符号替换等预处理,导致第三次作业需要判断格式错误时又多了很多麻烦;其次是没有进行优化,损失了较多的性能分。
另外值得一提的是,如果对Item及其子类进行上述优化的话,还可以对Processor中的建树过程进行简化,减小Processor与Item的各子类间的耦合性,使代码更为简洁,附代码如下:
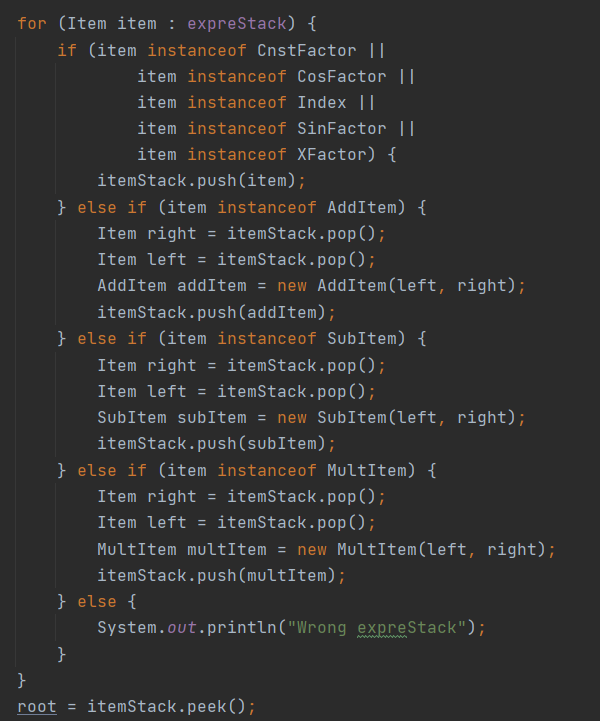
其中上半部的判断可都换为对是否为乘方类的判断,之后连续三个的if-else都可以换为对组合类的判断,而且构造方式也可以保持一致,可将这近25行的代码简化为6、7行,而且之后如果有新的需求加入时,此处便不需要进行改动,无论是可拓展性还是低耦合性,都将得到相当有效的提升。
总体的复杂度分析如下:(只显示标红部分)
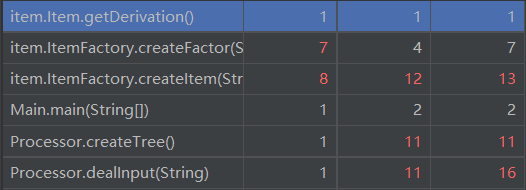
其中工厂类制造对象时与解析字符串生成后缀表达式时复杂度较高。工厂类制造对象时可以理解,因为需要通过解析接受的字符串来生成各种各样不同种类的对象,无论是逻辑判断和类的耦合程度都比较高,而这是可以通过建立有层次的工厂类进行的,大的工厂类可以管小的工厂类,降低工厂与各种类之间的耦合性,这样做的优势体现在增加相似的类别时,可以改小工厂而不改大工厂,使大工厂不至于过于复杂。管理起来也比较方便。至于解析字符串生成后缀表达式再生成树的过程,由于是面向过程的,复杂度较高,这是算法层面的问题,在此不再详细展开。
分配失调,不进反退
首先还是来看Item及其子类的UML图,相比于第二次作业,最突出的特点是多了一个接口:
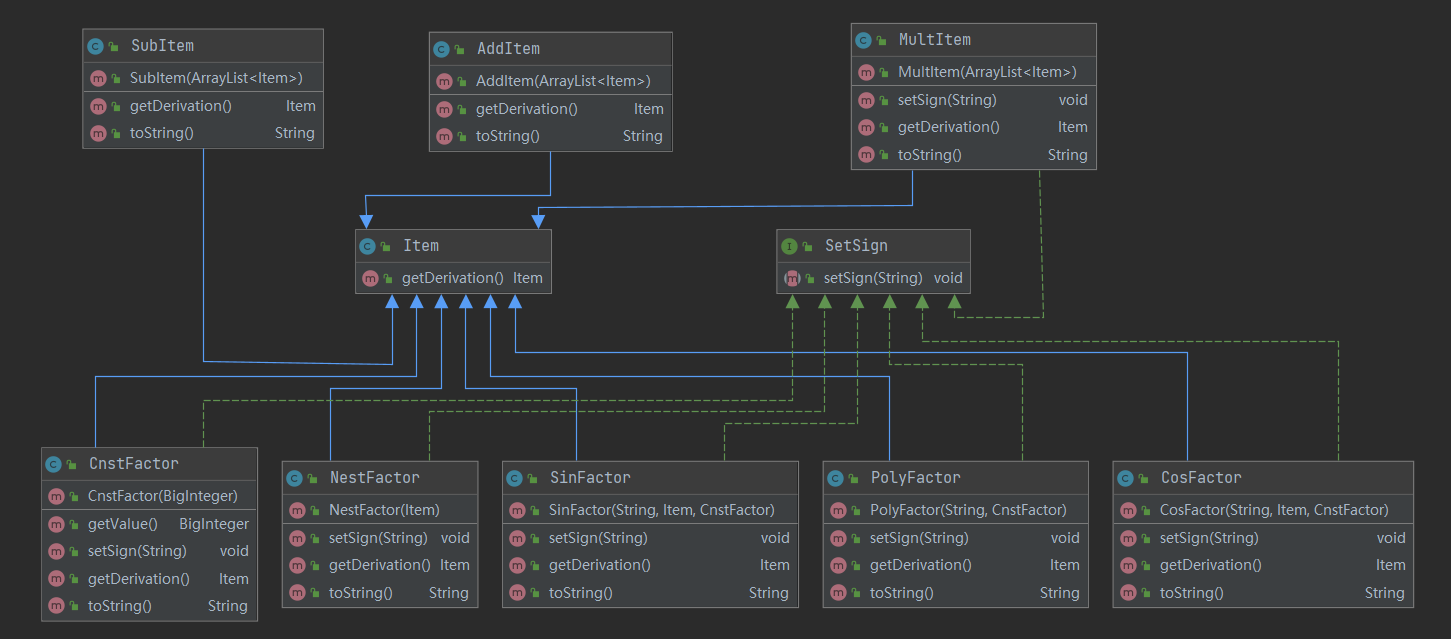
我们仔细看这个接口的名字,它竟然不是求导,而是一个设置符号的接口!为什么会有这个接口呢?是因为这次需要进行格式检查,不能再把多个符号在预处理时合并了,所以这些Item类(除加减法之外)里都有一个成员属性表示其符号,这无疑是一个很愚蠢的设计,直接导致需要在各个Item里增加一个几乎一模一样的函数,但究竟要怎么改呢?这个与读入过程息息相关,在这里先卖个关子,等写到输入的处理再详细说明。
另外如果再仔细对照的话,会发现乘方类已经消失不见了,取而代之的嵌套类,那乘方因子应该怎么表示呢?如果读者火眼金睛的话,会发现第二次作业当中的XFactor的名字变为了PolyFactor,仔细想想就能发现两者的不同之处——我把乘方有关的东西全放进了变量因子当中,即x\sin()\cos()类中都包括了一个指数!联系到在第二次作业中所分析的,这无疑是一种倒退,如此一来,如果再要实现表达式乘方求导的功能,当然可以在嵌套类中加入指数变量来实现,但这从设计层面来说是很不优雅的,因为完全可以将这种形式抽象出来,这样各个底层的类的实现就会变得简单很多;打个简单的比方,如果乘方变成了另一种含义,那四个底层类都需要进行改动,而且改动的内容几乎一模一样!而这种设计上的倒退是由于有个问题造成了大量精力的浪费,其他只想着怎么方便、怎么能过怎么来,至于实现的好不好看完全不在考虑范围之类。而这个问题其实也就是上面所提到的设置符号的接口的由来。
那这个问题是什么呢?我把第二次作业分析中的描述再迁移过来:

过了一周,再次相见,分外亲切。
有了格式检查的需求,生成后缀表达式、表达式树那一套,感觉就不是那么适用了,核心的问题在于两点:连续符号的合并与空格的消除;而这些在我当时看来是难以简单解决的(现在想来其实并不难),主要原因是第二周经历了递归下降的从入门到放弃,现在看到格式检查又开始蠢蠢欲动了,怎么看后缀表达式怎么麻烦,于是又开始我的第三次对输入的重构。
这次输入采用的是递归下降的解析方法,将对文法和词法的分析分开,按形式化表述进行翻译,并消除左递归,一个一个字符对输入字符串进行分析。具体如何实现的其实与总体的设计关系不大,在此也不再赘述。(尽管这一个类就超过了代码行数的1/3)
所以整体架构自然也是清晰的:
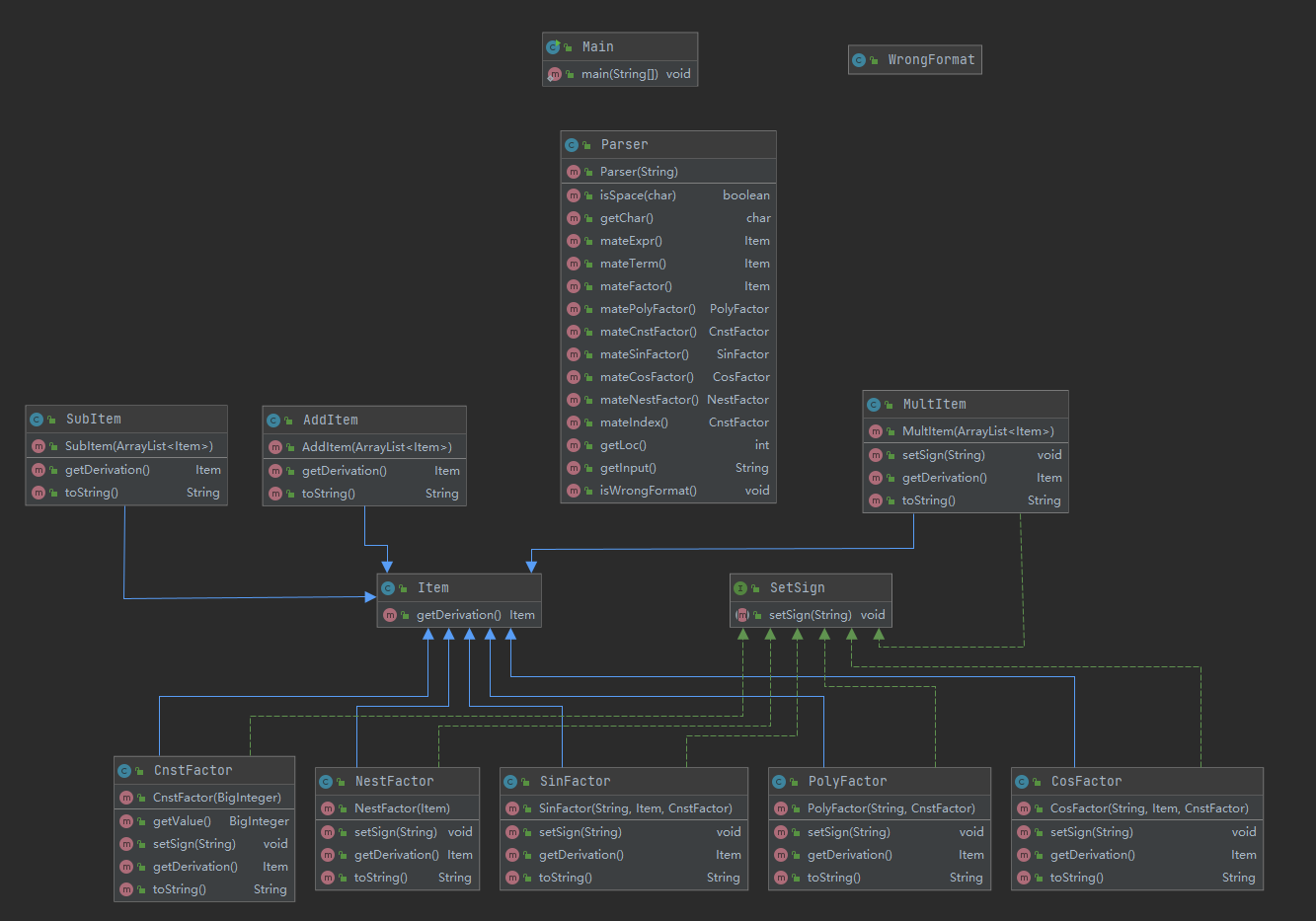
Main类依然负责与控制台的交互,处理字符串的工作全交由Parser处理,最终也得到一个类似于根节点的Item,如果在处理过程中出现匹配错误,则抛出异常,然后在main函数中处理异常,输出Wrong Format;如果不出现异常,则由根节点进行链式求导,得到求导后的根节点,再通过其进行求导表达式的输出,在输出时可以进行简单的化简,即可得到最终的结果。
对于复杂度分析,此次作业各个方法的复杂性较为平均,没有出现“一家独大”的情况,但有两类比较典型的高复杂度的地方(只展示标红部分):
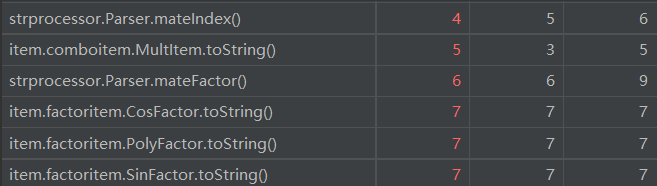

一类是某些类的toString方法由于化简加入了许多判断条件,较为复杂,另一类是在解析字符串时个别函数比较复杂,但完全在可以接受的范围之内,因此也不再过多阐述。
和符号的爱恨纠缠 ——Bug分析
读题不成蚀把米
第一次作业倒是没有在强测中被测出bug,却在互测中被找出27次bug之多,刚看到bug这么多的时候有点懵,然后就突然意识到是自己的符号处理出了问题——由于大正则复杂性以及对指导书语言描述和形式化描述的混淆,我的程序无法处理连续三个符号的情况!这无疑是会被人hack成筛子的,而最终房间里只有我一人被刀,这就是因为不仔细读题而犯下的大错。而最终稍改动正则即可解决,倒也无需贴图了。
复杂的预处理所引发的惨案
第二次作业也没被强测找出错误来,想到自己毕竟是没化简的,应该不存在有其他的问题,以致前一天没找出问题的时候挺放心的,最终还是被人测出问题来,结果竟然是预处理的时候把“-+-”换成了“-”,又一个符号上的错误,而这个错误是由于预处理的过程较为复杂,很容易出现各种各样的失误,因此这样无脑预处理实际上不应当出现(虽然改的时候直接改为“+”就通过了,但在之后的设计中应当注意)。
符号!符号!
之所以Bug分析版块要取这个小标题,不仅是因为在强测和互测中出现了问题,更是因为在本地测试的时候,出了无数和符号相关的bug,比如-(x+1)读成-x+1,-cos(x)**2读成(-cos(x))**2,诸如此类,不胜枚举,也在处理这些问题上耗费了大量的时间,而这些问题都是能够通过良好的架构实现优雅的处理的,比如增加乘方项,就能很好的统领所有的单项式,对于符号的处理由这个父类统一调配,在输出的时候则能以统一的方法输出,对化简也容易。设计上偷的懒,总要从coding的过程中被补上。
他人Bug
由于没有做自动评测机,在测试他人的代码时主要是通过自己构造一些比较特殊的样例,诸如嵌套层数较多、指数较大以及自己提交之前出现的一些错误样例,最后也只有在第二次作业中发现了他人无法处理多层嵌套的问题,无太多值得分享的地方。
一大三小,或是一小三大 ——重构经历总结
对比第一次作业和第二次作业,两者的类图发生了翻天覆地的变化:
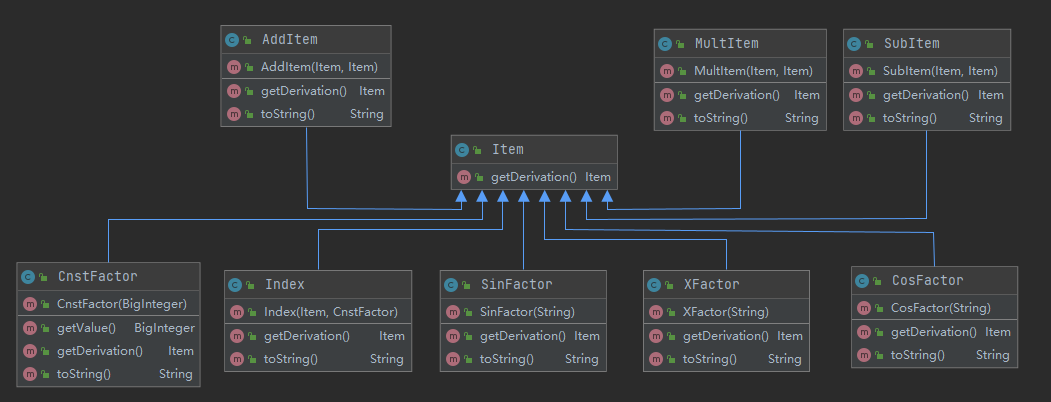
通过对题中的各个单元进行抽象,形成了组合类和单项式类两个大类,而这两个大类中又有各小类,所有的类又都继承于Item,实现良好的代码风格和可拓展性,相当于一次架构上大刀阔斧的改革。但真正写起代码来,这样的改动其实相当轻松,因为所有的类只需要写好自己的求导方法和输出函数即可。可见,如果设计上过了关,即便是像这样翻天覆地的重构,也是比较轻松的。
与之相对应的,是对输入处理的重构。这其实并非架构的核心,却使我在编码时与其斗智斗勇,费尽周折:从大正则到后缀表达式再到递归下降,每一次改动都可以说是“小”改动——只改了输入处理的方法,但真正改起来却远比改类的架构要困难,耗费的时间与精力要多的多。这可能也从侧面印证了面向对象与面向过程的区别:面向过程一旦要增加需求、进行改动,那就得推倒重来,复用性较低;而面向对象则能从底层单元进行构建,高层对底层单元进行调用,以实现较高的复用性与灵活性,这是面向对象的很突出的优势。
心得体会
什么叫面向对象
第一单元作业使我感受最深的,就是什么是对象,或者更贴切的说,是什么是抽象。在第一次作业的时候,虽然已经听到老师说表达式中所有的东西都能看作一个类,但实现的时候仍然觉得用多项式-单项式处理方便;而到了第二次作业的时候,发现这样就完全行不通了,因为无论是表达式嵌套还是三角函数类,处理起来都会很麻烦,简单的说,第一次作业面向过程的感觉还特别明显,把“+”当成了纯粹的加法,仍然是模拟处理的流程;而经过重构之后,能把“+”“-”这类的运算符也当做一个类,当作一种对象,我觉得这是一次思维的一种根本的转变,更不用说,在把“+”“-”看作类之后,其求导所得到的仍然是一个类,这也是第一次作业中所完全想不到的。正是因为面向过程的思维,所以在求导的过程中就想顺手把化简也进行了,而有了面向对象的思维,对象处理完以后还是对象,就不容易再混淆。也正是有了这种思维路径,当“+”所代表的含义不再是加法时,就不需要在整个的架构里进行大改,而只需要对“+”这个类进行集中改动即可,只要“+”所代表的有左值、右值的抽象属性不变,这种设计就是有效的,可拓展的。这是这一单元我所体会的面向对象的精华。
设计与架构的重要性
这个可能大家都提的比较多了,我就用自己的实例分析。首先是第二次作业类的重构,如果不是经老师点拨和学长C代码的帮助,真正想做出来可能还是相当困难的,也许又会回到面向过程的路上,然后进行很多麻烦的分析;其次是在架构分析中所提到的再建立两个父类的想法,写作业的过程中有这个冲动,但没有实现,现在仔细思考的确尤其方便,能节省很多面向过程的步骤,这就是设计的重要性。
父类与接口的统一化管理
Java里很重要的三大特征是封装、继承和多态,封装可能在C语言中也有体现,而继承和多态则是这个单元是我感触颇深的。在存储的时候,无论是什么类型,都能用Item类去存,而在用的时候,用的却又都是子类自己的方法,比如求导,尽管最顶层只知道是一个Item在求导,但在调用求导函数的时候,却是加法、乘法类在求导,而求导结束之后,又以都以统一的Item形式进行管理,再对其进行输出,调用起来非常方便,省略了无数的细节,这也是第一单元的重要收获。
递归下降学习心得
最后简要提一下自己在学习递归下降时的一些要点(篇幅所限,就不展开了):
-
以字符为单位的格式扫描(重点中的重点)
-
终止符是什么(这一级核心的断点在什么地方)
-
消除简单的左递归,否则会无限循环
-
文法与词法的分离

 浙公网安备 33010602011771号
浙公网安备 33010602011771号