OO第一单元作业总结
概述
这一单元的任务是表达式求导,从第一次作业仅要求简单多项式求导,到第二次作业加入三角函数和表达式因子,再到第三次作业加入格式检查以及嵌套因子。三次作业的要求层层递进,各次作业的难点分布均匀,合理!
第一次作业
本次作业的难点在于如何建立起整个多项式求导的框架。
基于度量分析自己的程序结构

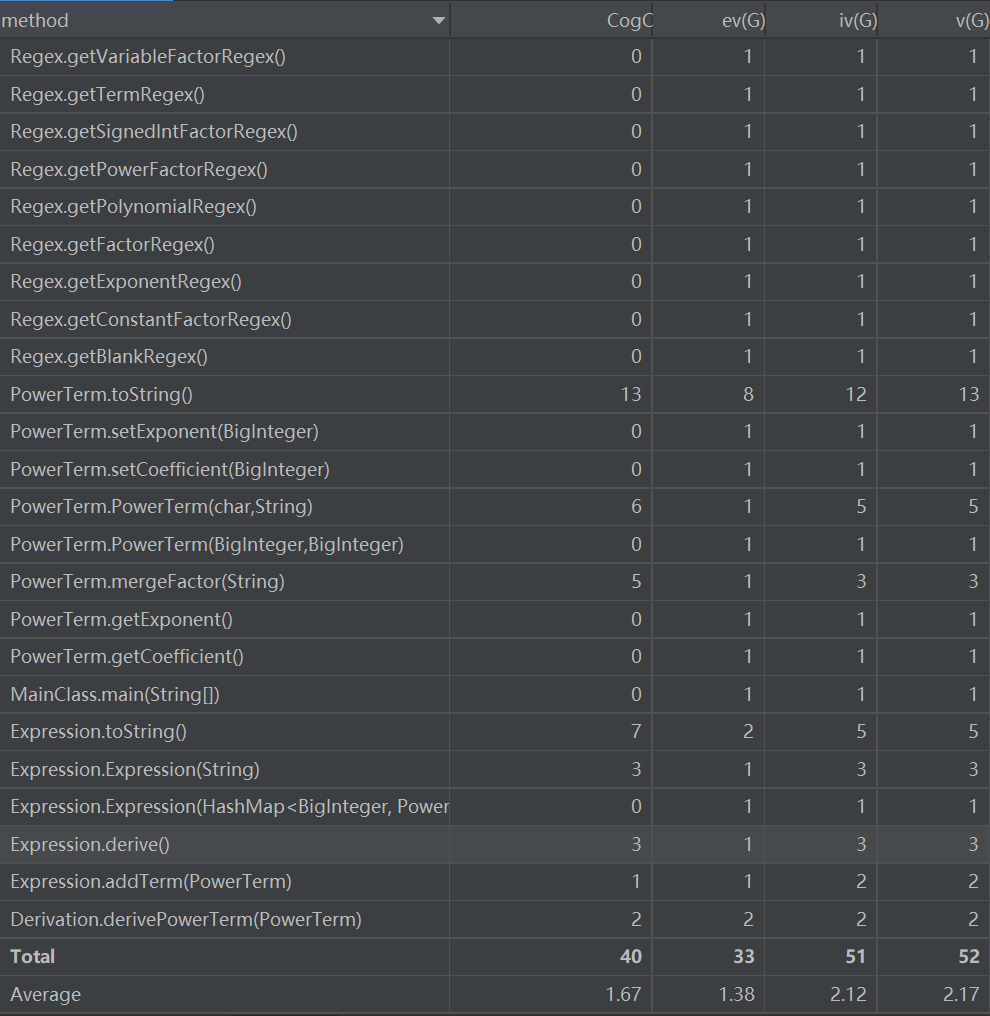

本次作业各类的度量如下
MainClass:主函数所在类Expression:表达式类- 成员变量
HashMap<BigInteger, PowerTerm> powerTermHashMap,用于存储幂项和幂项的指数的二元组
- 成员方法
public Expression(String input):构造函数,实现对符合表达式的字符串进行解析和构造,该方法共19行public Expression(HashMap<BigInteger, PowerTerm> powerTermHashMap):构造函数,实现通过对成员变量赋值来构造表达式,该方法共1行public void addTerm(PowerTerm term):优化函数,合并同指数的项,该方法共5行public Expression derive():求导函数,对表达式对象进行求导,返回表达式对象,该方法共8行public String toString():字符串转化函数,将表达式对象转化成字符串返回,该方法共15行
- 成员变量
PowerTerm:幂项类- 成员变量
BigInteger coefficient,用于存储幂项的系数BigInteger exponent,用于存储幂项的指数
- 成员方法
public PowerTerm(char pm, String str):构造函数,实现通过传入项前的符号以及符合幂项的字符串进行构造幂项,该方法共22行public PowerTerm(BigInteger coe, BigInteger exp):构造函数,实现通过对成员变量赋值来构造项,该方法共2行public void mergeFactor(String factor):优化函数,合并同一个项中的不同因子,该方法共14行public String toString():字符串转化函数,将幂项对象转化成字符串返回,该方法共22行
- 成员变量
Regex:正则表达式类- 成员变量
private static final String BLANK_REGEXprivate static final String SIGNED_INT_FACTOR_REGEXprivate static final String EXPONENT_REGEXprivate static final String POWER_FACTOR_REGEXprivate static final String CONSTANT_FACTOR_REGEXprivate static final String VARIABLE_FACTOR_REGEXprivate static final String FACTOR_REGEXprivate static final String TERM_REGEXprivate static final String POLYNOMIAL_REGEX
- 成员方法
public static String getFactorRegex()public static String getTermRegex()
- 成员变量
Derivation- 成员方法
public static PowerTerm derivePowerTerm(PowerTerm term):对幂项的求导函数,当时对接口接触不多,搞出这么个不伦不类的东西
- 成员方法
本次作业的结构较为简单,没有用到类的继承。从指导书的描述中,我很自然地抽象出Expression、PowerTerm和Derivation三个类,同时,为了实现对各表达式、项和因子的匹配,我将所有的正则表达式放在Regex类中便于统一管理以及此后的修改。
从度量分析上来看,除了PowerTerm.toString()这一函数之外,其余函数的复杂度基本在合理范围之内。至于PowerTerm.toString()函数复杂度高,这是因为我在设计这一函数时,大体借鉴了第一次实验的输出函数,导致该函数中存在8个if-else控制流,从而复杂度偏高。而我在第二次作业中也意识到了这个问题,并对该函数进行了简化。
关于优化,本次作业能够优化的点不多,一个是正项在前,另一个是x**2可以拆成x*x。我想到了前者而没有想到后者,导致强测中失掉了一些性能分。
从DSM图上来看,本次作业的耦合度不高,主要原因是本次作业比较简单,只要稍加思考就能将各类独立出来。
分析自己程序的bug
公测与互测均未被发现bug。
分析自己发现别人bug所采取的策略
大致可以采取以下两种策略
①采用自动测评机自动生成样例+获得输出+检测正确性
优点:实际上自动测评机在互测前就应已经写好,可以无脑跑循环,省时省力
缺点:自动评测机生成的随机样例实际上别人有大概率也能生成,因此hack效率并不高
②分析对方代码并手动构造测试样例
优点:对症下药,hack效率++;在自测时通过手动构造已经攒下了一沓特殊样例,这是别人所不能生成的
缺点:设计一个自己的程序尚且感到困难重重,并且仍可能存在逻辑上的bug,那么在一天半的时间里,在OS的压迫感之下,想要读完并分析6-7个人的代码基本上是不可能的事情,而且有很大概率是分析后也找不到对方的bug。因此我采取的策略是随机挑选1-2人的代码进行详读(实际上想再多读时间上也是不允许的了),以期找到hack别人的机会。
这次互测中并没有hack出别人的bug。
第二次作业
本次作业的难点是如何正确识别表达式因子并处理嵌套求导。
基于度量分析自己的程序结构
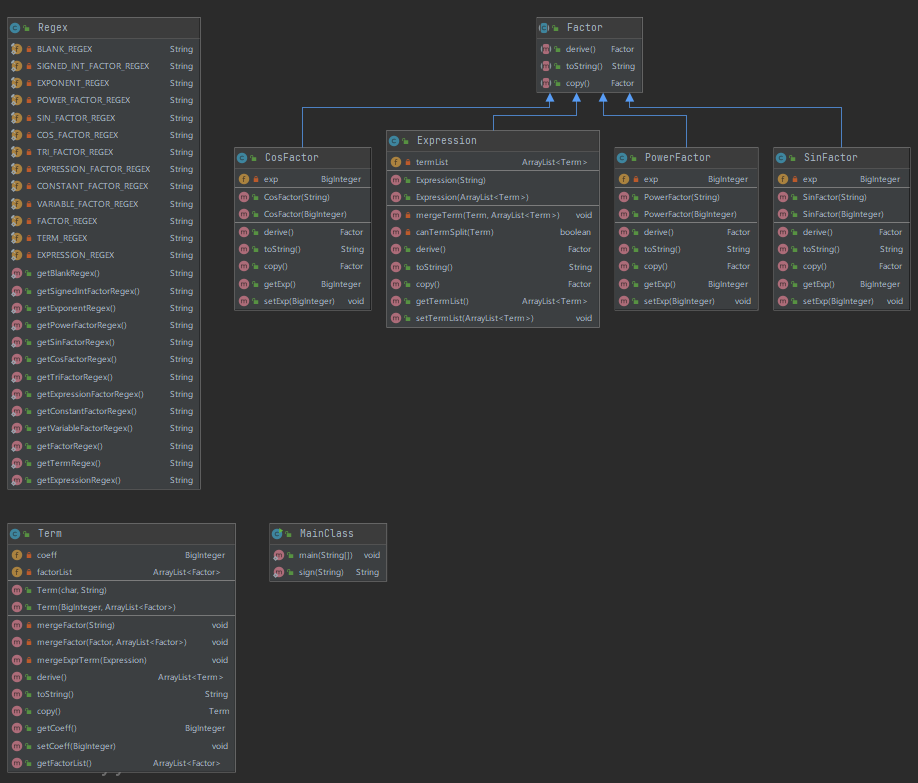


本次作业各类的度量如下
MainClass:主函数所在类- 成员方法
public static String sign(String str):该函数用于标记括号,从而实现对表达式因子的识别,该方法共24行
- 成员方法
Expression extends Factor:表达式因子类- 成员变量
ArrayList<Term> termList,利用ArrayList统一管理Term对象
- 成员方法
public Expression(String str):构造函数,实现对符合表达式的字符串进行解析和构造,该方法共18行public Expression(ArrayList<Term> termList):构造函数,实现通过对成员变量赋值来构造表达式,该方法共1行private void mergeTerm(Term term, ArrayList<Term> termList):优化函数,用于拆去系数为1,且只有一个表达式因子的项中的表达式因子的括号,该方法共5行private boolean canTermSplit(Term term):仅被mergeTerm函数调用,用于判断Term中是否仅有一个表达式因子,该方法共14行public Factor derive():求导函数,对表达式对象进行求导,返回表达式对象,该方法共9行public String toString():字符串转化函数,将表达式对象转化成字符串返回,该方法共18行public Factor copy():深克隆函数,该方法共5行public ArrayList<Term> getTermList()
- 成员变量
Term:项类- 成员变量
BigInteger coeff:用于存储项的系数,默认为BigInteger.ONEArrayList<Factor> factorList:用于存储项中的不同因子
- 成员方法
public Term(char pm, String str):构造函数,实现通过传入项前的符号以及符合项的字符串进行构造项,该方法共23行public Term(BigInteger coeff, ArrayList<Factor> factorList):构造函数,实现通过对成员变量赋值来构造项,该方法共2行private void mergeFactor(String factor):优化函数,用来将新产生的因子合并进原有因子中(只合并x**i,sin(x)**i,cos(x)**i),该方法共25行private void mergeFactor(Factor factor, ArrayList<Factor> factorList):临时新增的优化函数,用来将求导之后的因子进行合并,该方法共17行private void mergeExprTerm(Expression expr):优化函数,用来将只有一项的表达式因子展开,然后合并到本项中(主要用于展开表达式因子的多重括号嵌套),该方法共20行public ArrayList<Term> derive():求导函数,该方法共19行public String toString():字符串转化函数,该方法共21行public Term copy():深克隆函数,该方法共5行public BigInteger getCoeff()public void setCoeff(BigInteger coeff)public ArrayList<Factor> getFactorList()
- 成员变量
Factor:因子类(抽象类)- 成员方法
public abstract Factor derive()public abstract String toString()public abstract Factor copy()
- 成员方法
PowerFactor extends Factor:幂因子类- 成员变量
BigInteger exp:用于存储幂因子的指数
- 成员方法
public PowerFactor(String str):构造函数,实现通过传入符合幂因子的字符串进行构造,该方法共5行public PowerFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造幂因子,该方法共1行public Factor derive():求导函数,该方法共9行public String toString():字符串转化函数,该方法共9行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()public void setExp(BigInteger exp)
- 成员变量
SinFactor extends Factor:sin三角函数因子类- 成员变量
BigInteger exp:用于存储sin因子的指数
- 成员方法
public SinFactor(String str):构造函数,实现通过传入符合sin因子的字符串进行构造,该方法共5行public SinFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造sin因子,该方法共1行public Factor derive():求导函数,该方法共9行public String toString():字符串转化函数,该方法共9行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()public void setExp(BigInteger exp)
- 成员变量
CosFactor extends Factor:cos三角函数因子类- 成员变量
BigInteger exp:用于存储cos因子的指数
- 成员方法
public CosFactor(String str):构造函数,实现通过传入符合cos因子的字符串进行构造,该方法共5行public CosFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造cos因子,该方法共1行public Factor derive():求导函数,该方法共9行public String toString():字符串转化函数,该方法共9行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()public void setExp(BigInteger exp)
- 成员变量
Regex:正则表达式类- 成员变量
private static final String BLANK_REGEXprivate static final String SIGNED_INT_FACTOR_REGEXprivate static final String EXPONENT_REGEXprivate static final String POWER_FACTOR_REGEXprivate static final String SIN_FACTOR_REGEXprivate static final String COS_FACTOR_REGEXprivate static final String TRI_FACTOR_REGEXprivate static final String EXPRESSION_FACTOR_REGEXprivate static final String CONSTANT_FACTOR_REGEXprivate static final String VARIABLE_FACTOR_REGEXprivate static final String FACTOR_REGEXprivate static final String TERM_REGEXprivate static final String POLYNOMIAL_REGEX
- 成员方法
public static String getFactorRegex()public static String getTermRegex()
- 成员变量
根据本次作业的要求,程序中自然地添加了SinFactor类与CosFactor类,并将PowerTerm类更名为PowerFactor类并增添Term类。同时,本次作业中出现了表达式因子,从而出现“表达式→项→表达式因子→表达式”这样的循环调用的情况。基于上一次作业的架构,本次作业中增加了Factor抽象类,对Expression、PowerFactor、SinFactor、CosFactor四个类提供统一的管理,通过递归调用即可解决对表达式的存储和求导。Regex类没有较大改动,仅增加了表达式因子的正则表达式。
对于表达式因子的识别,本次作业采用的是标记法,即在括号内加上{#}这样的标识符用来标记括号以及括号的层数,从而避免类似于((sin(x))*(cos(x)))识别错误的情况。
从度量分析上来看,本次作业的复杂度较上次作业来说有了一定的改善,但是高复杂度的重灾区仍然是各类中的toString()函数,这是因为优化输出难以避免地带来复杂度的升高。另一较高复杂度的函数是预处理函数MainClass.sign(),这一函数将输入字符串进行预处理,在括号内加入标识符以便识别,这一过程较为面向过程,因此复杂度较高。
除了第一次作业的两个优化的点之外,本次作业中主要实现优化的点有两个,都是围绕表达式因子展开的。一个是如果表达式因子中只有一个项,并且项中只有一个表达式因子,就可以将内部的表达式因子拆开进行合并;另一个是如果项中只有一个表达式因子,并且表达式因子中只有一个项,就可以将内部的项拆开进行合并。两者都是为了解决诸如((((((((((x))))))))))这样的括号嵌套问题。
从DSM图上来看,本次作业的耦合度较高,上三角与下三角中都存在着大量的循环调用的情况。这是因为第二次作业的架构仍然保留着面向过程的思想,在优化的过程中图省事,直接在解析字符串的过程中直接进行去括号与合并同类项,同时在求导过程中,因子的导数定义为一个项(典型的面向过程T^T),导致类与类之间的不合理的调用较多。
分析自己程序的bug
公测与互测均未被发现bug。
分析自己发现别人bug所采取的策略
采取策略大体上同第一次作业,另外我发现有些人的程序能够通过自动评测机的覆盖性轰炸,却会在手动构造的简单样例上跌跟头,这也说明了手动构造简单样例是极为有必要的。
第三次作业
本次作业的难点是格式检查。
基于度量分析自己的程序结构
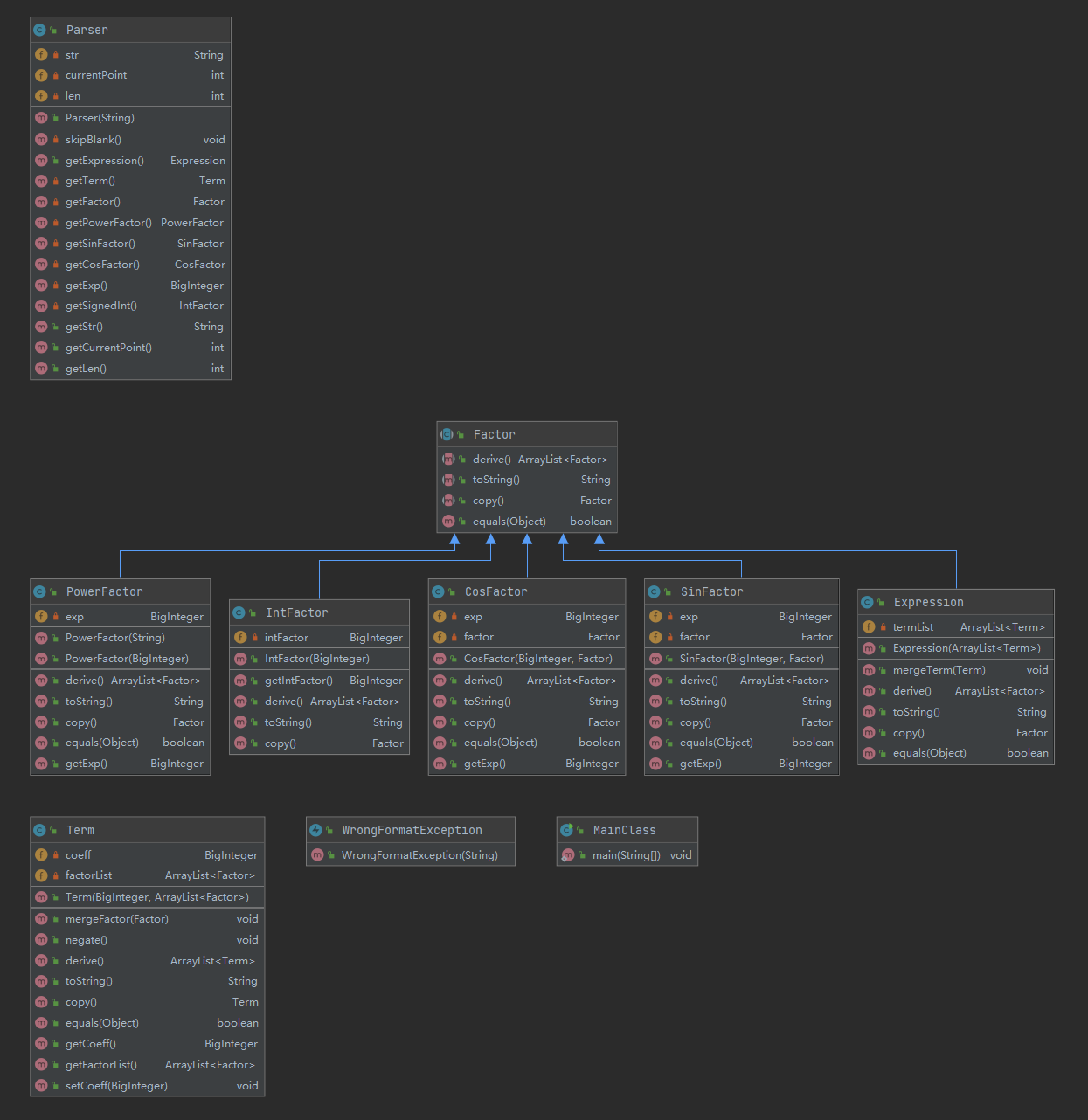


本次作业各类的度量如下
MainClass:主函数所在类Expression extends Factor:表达式因子类- 成员变量
ArrayList<Term> termList,利用ArrayList统一管理Term对象
- 成员方法
public Expression(ArrayList<Term> termList):构造函数,实现通过对成员变量赋值来构造表达式,该方法共1行public void mergeTerm(Term term, ArrayList<Term> termList):优化函数,用于拆去系数为1,且只有一个表达式因子的项中的表达式因子的括号,该方法共3行public ArrayList<Factor> derive():求导函数,对表达式对象进行求导,返回表达式对象,该方法共11行public String toString():字符串转化函数,将表达式对象转化成字符串返回,该方法共18行public Factor copy():深克隆函数,该方法共5行
- 成员变量
Term:项类- 成员变量
BigInteger coeff:用于存储项的系数,默认为BigInteger.ONEArrayList<Factor> factorList:用于存储项中的不同因子
- 成员方法
public Term(BigInteger coeff, ArrayList<Factor> factorList):构造函数,实现通过对成员变量赋值来构造项,该方法共2行private void mergeFactor(String factor):优化函数,用来将新产生的因子合并进原有因子中并将常数因子合并到coeff中,该方法共19行public void negate():将项的系数取反,该方法共1行public ArrayList<Term> derive():求导函数,该方法共19行public String toString():字符串转化函数,该方法共21行public Term copy():深克隆函数,该方法共5行public BigInteger getCoeff()
- 成员变量
Factor:因子类(抽象类)- 成员方法
public abstract Factor derive()public abstract String toString()public abstract Factor copy()
- 成员方法
PowerFactor extends Factor:幂因子类- 成员变量
BigInteger exp:用于存储幂因子的指数
- 成员方法
public PowerFactor(String str):构造函数,实现通过传入符合幂因子的字符串进行构造,该方法共5行public PowerFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造幂因子,该方法共1行public ArrayList<Factor> derive():求导函数,该方法共6行public String toString():字符串转化函数,该方法共7行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()
- 成员变量
SinFactor extends Factor:sin三角函数因子类- 成员变量
BigInteger exp:用于存储sin因子的指数Factor factor:用于存储sin因子内部的嵌套因子
- 成员方法
public SinFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造sin因子,该方法共1行public ArrayList<Factor> derive():求导函数,该方法共10行public String toString():字符串转化函数,该方法共9行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()
- 成员变量
CosFactor extends Factor:cos三角函数因子类- 成员变量
BigInteger exp:用于存储cos因子的指数Factor factor:用于存储cos因子内部的嵌套因子
- 成员方法
public SinFactor(BigInteger exp):构造函数,实现通过对成员变量赋值来构造cos因子,该方法共1行public ArrayList<Factor> derive():求导函数,该方法共10行public String toString():字符串转化函数,该方法共9行public Factor copy():深克隆函数,该方法共1行public BigInteger getExp()
- 成员变量
IntFactor extends Factor:常数因子类- 成员变量
BigInteger intFactor:存储常数因子
- 成员方法
public IntFactor(BigInteger intFactor):构造函数,实现通过对成员变量赋值来构造常数因子,该方法共1行public ArrayList<Factor> derive():求导函数,该方法共4行public String toString():字符串转化函数,该方法共1行public Factor copy():深克隆函数,该方法共1行
- 成员变量
Parser:递归下降解析字符串类- 成员变量
String str:存储待解析的字符串int currentPoint:存储当前解析到的字符的位置,相当于指针int len:存储字符串长度
- 成员方法
public Parser(String str):构造函数,该方法共3行private void skipBlank():跳过空格和制表符,该方法共8行public Expression getExpression():获取一个Expression,该方法共57行private Term getTerm():获取一个Term,该方法共51行private Factor getFactor():获取一个Factor,该方法共56行private PowerFactor getPowerFactor(),获取一个PowerFactor,该方法共21行private SinFactor getSinFactor():获取一个SinFactor,该方法共35行private CosFactor getCosFactor():获取一个CosFactor,该方法共35行private BigInteger getExp():获取一个指数,该方法共15行private IntFactor getSignedInt():获取一个常数因子,该方法共9行public int getCurrentPoint()public int getLen()
- 成员变量
本次作业中新增三角函数的嵌套因子,出现了另一组“三角函数→因子→三角函数”的循环调用的情况,借鉴第二次作业的经验,这一新增要求只需要对SinFactor类和CosFactor类进行简单的改动,很容易实现。而为了实现格式检查,本次作业对解析字符串部分进行了重构。面对复杂的形式化规则,为了保证程序的可读性,我不再选用正则表达式来实现格式检查和识别,而是借鉴递归下降分析法的思想,实现利用Parser类来检查并解析表达式。
从度量分析上来看,本次作业中复杂度较高的函数几乎都是Parser类中的函数,这是因为递归下降的思想在应用时更加贴近面向过程而不是面向对象,虽然较正则表达式来说提高了可读性,或者说是提高了对程序的把控程度,但随之也带来了高到爆炸的复杂度。从细节上来看,由于表达式与项的形式化表述最为复杂,所以getExpression()和getTerm()两个函数是复杂度最高的。
本次作业沉迷递归下降,没有新增优化函数。由于将输入进行了重构,新增了Parser类,因此我将原有的优化函数一并修改掉,进行了解耦合的过程。
从DSM图上来看,本次作业的耦合程度较上次作业有了很大改善,基本上所有调用都集中在下三角地带。这一方面是因为采用了递归下降的输入写法,将优化函数与输入彻底解耦;另一方面我重写了求导函数,将Factor的求导结果看成ArrayList<Factor>,成功减少了不合理的调用。
分析自己程序的bug
公测与互测均未被发现bug。
分析自己发现别人bug所采取的策略
本次作业由于加入了格式检查,因此对测评机进行了小小的修改,总体上策略保持不变。另外有一个新发现是,我本以为到了第三次作业了,应该不会有人没有使用BigInteger了,但事实证明并不是。所以无论何时,构造数据依然要保证全面的覆盖性(即使构造出来的样例很丑陋QAQ)。
重构经历总结
就本单元来说,较大的重构有两次:
第一次重构是在第二次作业中,要求中加入了三角函数因子和表达式因子。实际上,在做第二次作业的时候,大体上有拆括号或不拆括号两种思路,而在一般情况下不拆括号都能得到比拆括号更优的性能,并且更易于扩展。在上述思路的引导下,我选择不拆括号,从而导致Term中出现难以预知的表达式因子的乘积,因此第一次作业的架构不再适合本次作业的架构,所以我放弃了PowerTerm类,转而利用Factor抽象类进行统一管理,并且在Expression类中放弃了HashMap容器,转而使用ArrayList来存储项。这一次重构是成功的,从复杂度上来看,各类数据都有一定幅度的下降。但是,这一次重构显然没有考虑WF的扩展,因此,第二次重构不可避免。
第二次重构是在第三次作业中,要求中加入了格式检查和嵌套因子。利用第二次的架构,我很容易地实现了嵌套因子的存储和求导。然而第一次作业中设计的正则表达式在第二次作业中已显吃力,因此我思考再三,决定利用递归下降的方法对解析函数进行重构,同时实现格式检查的功能。
每一次决心重构都是经过深思熟虑的,每一次重构都是痛苦的,而每一次重构之后,看着自己手中“优美”的代码,心中也是充满成就感的。通过这两次的重构经历,我明白了在设计架构的时候最优先要考虑可扩展性。毕竟,在三次作业中我们可能会因为优化迭代远超三个的代码版本,如果能做到模块化的即插即用自然是最好不过的。
一个好的架构是能陪伴自己整个单元的作业的,重构最好的时间,就是现在。
心得体会
这一单元的三次作业,由于时间紧迫常常邻近ddl时才能彻底完成,赶工不说,在设计思想上也出现了很大的问题。第一单元,OO课程组的本意是让我们熟悉Java语言设计模式,同时体会面向对象设计思想。但是在实际的实践过程中,由于题目要求过于清晰(从输入到解析,再到求导和输出),我在设计时虽然在局部使用了面向对象的写法(诸如有层次的类、继承、重写),但是在整体看来仍没有摆脱面向过程的写法。这就导致了虽然我的每个类在下一次迭代时都能得到复用,但是都会多多少少进行一些这里那里的改动,令人十分烦躁,在第二次作业中整个PowerTerm类甚至只能被全盘推翻,当时在重构的时候已经发觉不妥(甚至第二次作业在不久之后被重构了第二次)。除此之外,我的程序中类的封装性也比较差,拿构造函数举个例子,起初我的设计中只要向构造函数中传入字符串,就可以构造这个类的对象,但在求导的过程中也需要多次构造对象,这时再传入字符串已显不妥,因此我又设计了一个通过传入本类所需的成员属性来构造对象的构造函数,很显然,这样的写法很不“面向对象”。这一缺陷我曾在第三次作业中试图修改,但是要修改的地方太多,积重难返,权衡时间之下还是放弃彻底优化架构。
思想的转变不是三次作业就能完成的,必然还要经历一段时间的酝酿成熟,实际上对于面向对象已经有前人开发出一系列的设计模式,如单例模式、工厂模式等等,在对这些设计模式进行学习的基础上,我将会尝试将其用好用巧,而不是像这一单元一样模糊地、局部地使用面向对象思想。总而言之,“高内聚、低耦合”,向着这个方向努力吧!
除此之外,本单元还有许多收获,一并总结如下
- 与同学之间的交流真的很重要,交流中往往能得到生成测试样例的灵感
- 自动评测机很重要,但是不能因此依赖自动评测机,写代码时仍应保证自己逻辑的正确性和完备性,正是基于此点我采用了递归下降而不是正则表达式,也正是基于此点我在三次作业中从未被发现bug
- 学会读别人的代码,常常能发现同一功能的更精巧的实现
- 构思当然很重要,但是更重要的是在能确定一部分架构后立即开始写代码,否则必然会遭受ddl和bug的双重折磨
- 好的架构是可以陪伴三次作业的,但是好的架构往往来自于正确的面向对象思想,首先要理清需要哪些类、类中需要哪些方法以及类与类之间的交互接口,而不是首先理清整个求导的过程
- 首先要保证正确性,在写出来能保证正确性的代码之后再考虑优化的问题,重构不可怕,可怕的是在此之前没有一个能过中测的程序
感谢OO课程组精心设计本单元的题目,希望在接下来的学习中能有更多的收获!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号