
Attention 和self-attention
一、Attention
1.基本信息
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
encoder-decoder模型通常的做法是将一个输入的句子编码成一个固定大小的state,然后将这样的一个state输入到decoder中的每一个时刻,这种做法对处理长句子会很不利,尤其是随着句子长度的增加,效果急速下滑。
motivation:是针对encoder-decoder长句子翻译效果较差的问题。
解决原理:仿造人脑结构,对一张图片或是一个句子,有选择性的关注重点部分。
论文解决思路:在生成当前词的时候,只要把上一个state与所有的input word融合,而后做一个权重计算。通过这种方式生成的词就会有针对性,在句子长度较长时效果尤其明显。
2.核心算法
假设当前的输出的词位置为i,j是输入的词位置,$s_{i-1}$输出位置的上一个隐藏状态,$h_{j}$是输入的隐藏状态,$h_{j}$对应的权重,就是将$s_{i-1}$和$h_{j}$融合都一块,计算在所有的输入隐藏状态的比重。具体可参照如下公式。

二、Self-attention
1.基本信息
出自于Google团队的论文:Attention Is All You Need ,2017年发表在NIPS。
1)motivation:RNN本身的结构,阻碍了并行化;同时RNN对长距离依赖问题,效果会很差。
2)解决思路:通过不同词向量之间矩阵相乘,得到一个词与词之间的相似度,进而无距离限制。
3)优势:
- attention的计算可以并行化,tensor之间的矩阵乘法,不存在时序;
- 同一个句子中每个词之间均可以做相似度计算,无视距离;
- 多头机制,关注每一部分维度的表示,比如第一部分是词性,第二部分是语义等等;
- 可以增加到非常深的深度,堆叠很多块,充分发掘DNN模型的特性。
4)整体结构:
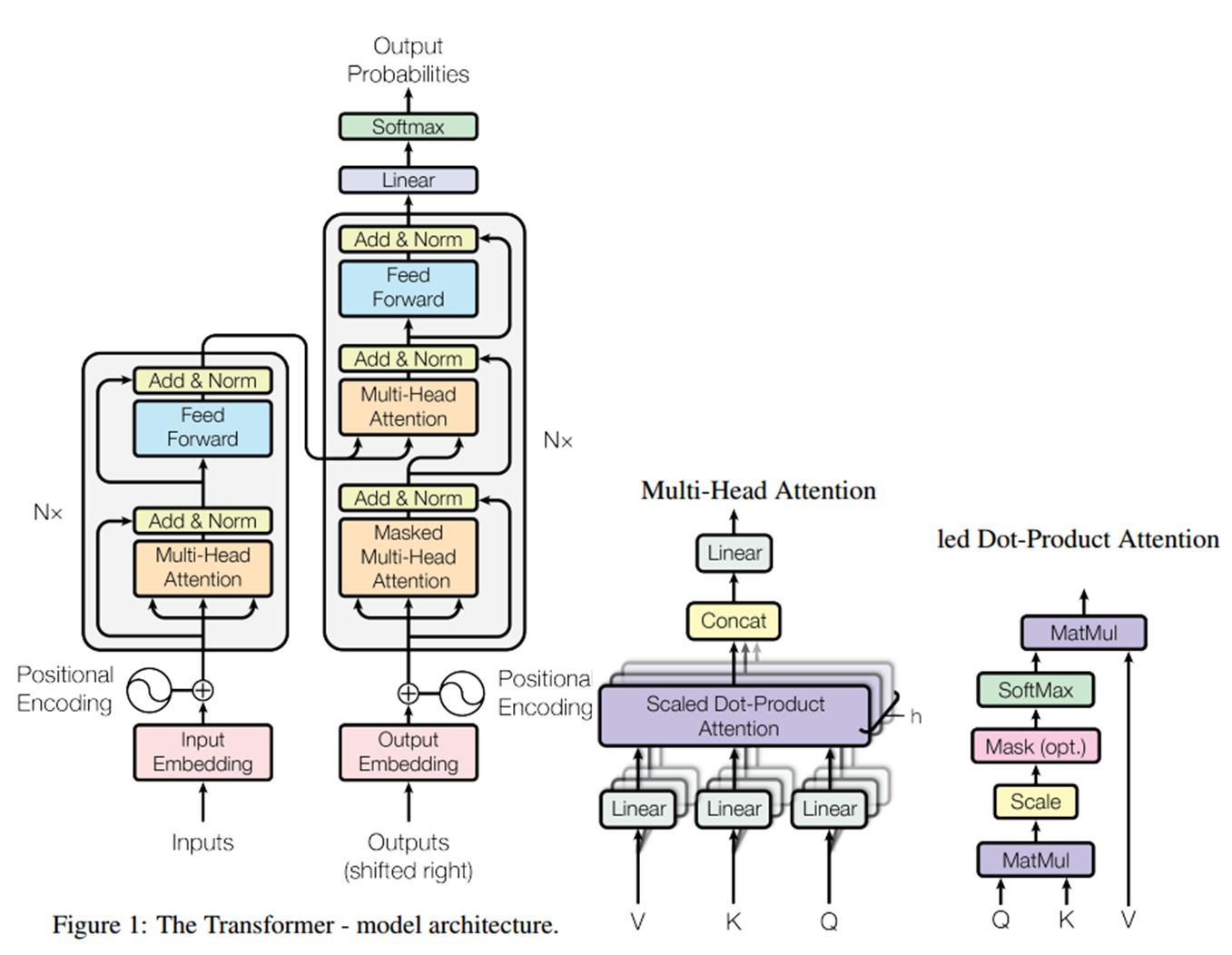
2.self-attention
$Attention(Q;K;V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$
对于$ softmax(\frac{QK^T}{\sqrt{d_k}})$,是得到一个相似度,而$ softmax(\frac{QK^T}{\sqrt{d_k}})V$是将相似度溶于embedding中。
每个位置的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如下图这个句子,每个单词和同句其他单词之间都有一条边,边的颜色越深表明相关性越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。

3.multi-head attention
1)multi-head的实现方式
将一个词的词向量切分成h个块,求attention相似度时是一个句子中每个词之间第i个块的相似度。原论文是有h次线性映射,后来的bert是切分为h个部分。
原论文multi-head操作方式:引自原论文
| Instead of performing a single attention function with dmodel-dimensional keys, values and queries,we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively.
|
2)bert实现代码:先线性映射,而后reshape,之后再矩阵乘法
# Scalar dimensions referenced here: # B = batch size (number of sequences) # F = `from_tensor` sequence length # T = `to_tensor` sequence length # N = `num_attention_heads` # H = `size_per_head` from_tensor_2d = reshape_to_matrix(from_tensor) to_tensor_2d = reshape_to_matrix(to_tensor) # `query_layer` = [B*F, N*H] query_layer = tf.layers.dense( from_tensor_2d, num_attention_heads * size_per_head, activation=query_act, name="query", kernel_initializer=create_initializer(initializer_range)) # `key_layer` = [B*T, N*H] key_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=key_act, name="key", kernel_initializer=create_initializer(initializer_range)) # `value_layer` = [B*T, N*H] value_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=value_act, name="value", kernel_initializer=create_initializer(initializer_range)) # `query_layer` = [B, N, F, H] query_layer = transpose_for_scores(query_layer, batch_size, num_attention_heads, from_seq_length, size_per_head) # `key_layer` = [B, N, T, H] key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads, to_seq_length, size_per_head) # Take the dot product between "query" and "key" to get the raw # attention scores. # `attention_scores` = [B, N, F, T] attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) attention_scores = tf.multiply(attention_scores, 1.0 / math.sqrt(float(size_per_head)))
3)multi-head的意义
由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
4.分类和生成任务
1)分类任务
分类任务只是用到了encoder,不需要decoder部分。encoder输出的tenser可以直接reshape,加一个全连接即可分类;也可以对每一个词求权重和,而后再分类。
2)生成式任务
生成式任务需要decoder部分,而decoder需要把当前位置i之后的词mask掉,就是设置为负无穷,因为生成当前词的时候,是无法看到之后的词。整个encoder完成之后,才开始decoder部分,其中decoder的K和Q是来源于encoder,V是decoder的上一个状态。
对应的multi_attention的代码如下, causality指示是否mask。
def multihead_attention(queries, keys, num_units=None, num_heads=8, dropout_rate=0, is_training=True, causality=False, scope="multihead_attention", reuse=None): '''Applies multihead attention. Args: queries: A 3d tensor with shape of [N, T_q, C_q]. keys: A 3d tensor with shape of [N, T_k, C_k]. num_units: A scalar. Attention size. dropout_rate: A floating point number. is_training: Boolean. Controller of mechanism for dropout. causality: Boolean. If true, units that reference the future are masked. num_heads: An int. Number of heads. scope: Optional scope for `variable_scope`. reuse: Boolean, whether to reuse the weights of a previous layer by the same name. Returns A 3d tensor with shape of (N, T_q, C) ''' with tf.variable_scope(scope, reuse=reuse): # Set the fall back option for num_units if num_units is None: num_units = queries.get_shape().as_list[-1] # Linear projections Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C) K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C) V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C) # Split and concat Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h) K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h) V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h) # Multiplication outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k) # Scale outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5) # Key Masking key_masks = tf.sign(tf.abs(tf.reduce_sum(keys, axis=-1))) # (N, T_k) key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k) key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k) paddings = tf.ones_like(outputs) * (-2 ** 32 + 1) outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k) # Causality = Future blinding if causality: diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k) #生成一个下三角矩阵,就是对角线全为0 tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (T_q, T_k) masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k) paddings = tf.ones_like(masks) * (-2 ** 32 + 1) #将outputs上三角的值,都改成负无穷, outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k) #outputs的上三角全为0 outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k) # Dropouts outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training)) # Weighted sum outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h) # Restore shape outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2) # (N, T_q, C) # Residual connection outputs += queries # Normalize outputs = normalize(outputs) # (N, T_q, C) return outputs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号