网课三
4-Melplotlib
导入相关包:import matplotlib.pyplot as plt
·线图:plot():变化趋势
·散点图:scatter():数据的相关性
·条形图:bar():数据大小和变化趋势
·饼图:pie():部分在总体的占百分比
·直方图和密度图:hist():数据的分布趋势
·多图合并显示:subplot()和subplots()
·linestyle:指定折线的类型,可以是实线、虚线、点虚线、点点线等,默认文实线;
·linewidth:指定折线的宽度
·marker:可以为折线图添加点,该参数是设置点的形状;
·markersize:设置点的大小;
·markeredgecolor:设置点的边框色;
·markerfacecolor:设置点的填充色:
·label:为折线图添加标签,类似于图例的作用;
5-数据探索
1.数据基本情况
·基本信息:data.head(),data.info(),data.decribe()
·基本分布:data['列名'].hist(),data.value counts()
2.相关性分析
查看各个列之间的关联:correlation_matrix= data.corr()
3.检测异常值、缺失值、重复值
缺失值检测:data.isnull().sum()
重复值检测:data.duplicated().sum()
异常值检测:plt.boxplot(data['列名'])
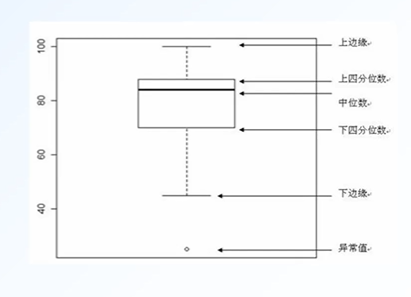
箱线图
6-数据处理
·去除重复值,并覆盖原数据集:
data.drop_duplicates(inplace=True)
·去除缺失值:
删除法:data.dropna()
填充法:data.fillna()
·去除异常值:
符合正态分布时-3o原则、箱线图
·数据类型的转换:
.astype()、pd.to_datetime()
·数据标准化:
极值标准化、标准差标准化、小数定标标准化
Pandas基础
- Pandas是什么
- Pandas是基于NumPy数组构建的,也是Python语言的第三方库,主要用于数据分析,专门为处理表格和混杂数据设计的,相当于Python的Excel,而Numpy更适合处理统一的数组数据。
- 常用数据对象
pandas提供了三种常用数据对象,分别是:
- eries用于保存一维类的数据
- DataFrame用于保存二维类的数据
- panel用于保存三维类或者可变维
度的数据
- 1 创建DataFrame对象
- series 对象用于存储一维数据
- DataFrame专门用于存储二维数据,每个数据库中的表都是一个二维数据
- 创建Dataframe对象
pd.DataFrame(data=None, index=None,columns=None, dtype=None)
data: 可以是嵌套列表,二维数组,字典或者DataFrame对象
index: 可以是索引对象或者类数组对象跟Series一样,index=None时,则会按照默认的0,1,2...顺序建立索引
columns: 可以是索引对象或者类数组对象,其含义是列索引
-
2 DataFrame对象常用基本属性
1.查看数据维度
dataframe.ndim
dataframe.shape
2.查看数据的行名称
dataframe.index
3.查看数据的列名称
dataframe.columns
4.查看数据的前几行:(n为设置查看几行,默认为5行)
dataframe.head(n)
5.查看数据的后几行:(n为设置查看几行,默认为5行)
dataframe.tail(n)
6.数据转置
dataframe.T
7.查看数据是否存在空值(可以连用,dataframe.isnull().sum()统计列中含有缺失值的个数,
dataframe.isnull().any().sum()统计含有缺失值的列数)
dataframe.isnull()
8.按照行名称或列名称进行排序:(axis参数:指定排序的数轴;ascending:默认按照升序排序;当设置为False时,按照降序排序)
dataframe.sort_index(axis=1, ascending=False)
9.按照数据值排序:(axis参数指定排序的数轴;by参数指定按照哪一列或行进行排序;ascending参数指定
是升序还是降序)
dataframe.sort_values(by='列名, ascending=False, axis=0)
10.对数据直接进行统计分析
dataframe.describe()
11.打印DataFrame对象的信息
dataframe.info()
12.查看数据类型
dataframe.dtypes
13.根据数据类型选取特征
dataframe.select_dtypes(include=None, exclude=None) -
数据的读取与保存
3.1. 读取excel文件
pd.read_excel('./data/xxx.xlsx')#括号内为excel文件路径
3.2 读取csv文件
pd.read_csv('./xxx/data1.csv')
3.3将DataFrame保存成csv文件
df.to_csv('xxx.csv')
Numpy基础
- Numpy是什么
是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算。 -
- Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
- Ndarray 对象
-
ndarray 对象是用于存放同类型元素的多维数组。
-
ndarray 中的每个元素在内存中都有相同存储大小的区域。
-
ndarray 内部由以下内容组成:
-
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
-
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
-
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
-
NumPy 数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。 -
NumPy数组属性
- ndim 数组维度
- shape 数组每个维度大小
- size 数组的总大小
- dtype 数据类型
- itemsize 每个数组元素字节大小
- nbytes 数组总字节大小
- flags ndarray对象的内存信息
- real ndarray元素的实部(复数的实部)
- imag ndarray元素的虚部(复数的虚部)
-
数据类型转换
用astype方法进行转化:
In [ ]:
a = np.array([1,2,3],dtype=float)
b = a.astype(int) -
便捷创建一个Numpy数组
ndarray 数组除了可以使用 ndarray 来创建外,也可以通过以下几种方式来创建
- 6.1 np.zeros
*创建指定大小的数组,数组元素以 0 来填充: - 6.2 np.ones
创建指定形状的数组,数组元素以 1 来填充: - 6.3 np.eye
创建指定形状的单位矩阵。 - 6.4 np.random 创建随机数组
除了创建元素全为 0 和 1 的数组之外,NumPy 也支持创建元素为随机值的数组。 -
- 6.4.1 np.random.rand
-
- 创建指定维度大小的,样本位于[0, 1)的随机样本。
-
- 6.4.2 np.random.randint
-
- 创建指定维度大小的,样本为随机整数样本的数组。
-
- 6.4.3 np.random.randn
-
- 创建指定维度大小的,样本为正态分布随机值的数组
- 6.5从数值范围创建数组
NumPy 也可以从某个范围中,创建所需的数组。 -
- 6.5.1 np.arange
根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。注意,停止的 stop 值不在生成的数组的范围之内。
- 6.5.1 np.arange
-
- 6.5.2 np.linspace
np.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的。
生成开始值为10,结束值为20,大小为51的等差数组
np.linspace(start=10, stop=20, num=51)
- 6.5.2 np.linspace
-
- 6.5.3 np.logspace
np.logspace 函数用于创建一个对数等比数列
- 6.5.3 np.logspace
- NumPy 统计函数
NumPy 数组中提供了一些简单的统计函数,可以帮助我们计算数组的最大、最小值、平均值、中位数等。
- 7.1最大、最小值
可以使用.max()/.min()或np.amax()/np.amin(),计算数组的最大最小值 - 7.2平均值
可以使用np.mean()/np.average()或.mean()方法获取数组中所有元素的均值 - 7.3中位数
使用np.median()计算数组的中位数 - 7.4标准差
使用np.std计算标准差
8.Nump数据-索引&切片&排序
ndarray对象的内容可以通过索引或切片来访问和修改
通过sort函数进行排序
- 8.1索引
ndarray 数组可以基于 0 - n 的下标进行索引 - 8.2 切片
切片对象通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。 - 冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的
项。
多维数组同样适用上述索引提取方法:
In [ ]:
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
从某个索引处开始切割
print('从数组索引 a[1:] 处开始切割')
print(a[1:])
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
In [ ]:
print (a[...,1]) #
第2列元素
print (a[1,...]) #
第2行元素
print (a[...,1:]) #
第2列及剩下的所有元素 - 8.3 排序
通过np.sort()可以对数组对象进行排序
In [ ]:
import numpy as np
s = np.random.rand(1,3)
print(s)
print(np.sort(s,axis = 1))
axis=1表示按行对元素排序,0表示按列对元素排序
- 数组的相关运算
数组的运算可以分为:
数组内的运算
数据与数组之间的运算
0.1 数组内的运算
Numpy提供了丰富的函数进行数组内的运算——
- 求和
- 求乘积
- 求最值
- 求均值
- 求方差和标准差
- 幂运算
- 对数运算
In [ ]:
import numpy as np
a = np.random.randint(low=1,high=100,size=(10)) #创建一个随机从1~100取数,10个元素的数组
In [ ]:
print(np.sum(a)) #求和
print(np.prod(a)) #求乘积
print(np.max(a)) #最大值
print(np.min(a)) #最小值
print(np.mean(a)) #均值
print(np.var(a)) #方差
print(np.std(a)) #标准差
print(np.sqrt(a)) #开方(每个元素)
print(np.square(a)) #平方(每个元素)
print(np.exp(a)) #以e为底的指数次方
print(np.log(a)) #自然对数
print(np.log2(a)) #底数为2对数
print(np.log10(a)) #底数为10对数 - 9.2 数组间的运算
数组间的运算依然是包括了加(+)、减( - )、乘( x )除( / )等,这些运算可以适合于具有相同的行数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号