关于注意力机制(《Attention is all you need》)
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。(https://kexue.fm/archives/4765)

第一个思路是RNN层,递归进行,但是RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
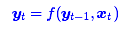
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,比如尺寸为3的卷积,就是
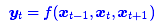
在FaceBook的论文中,纯粹使用卷积也完成了Seq2Seq的学习,是卷积的一个精致且极致的使用案例,CNN方便并行,而且容易捕捉到一些全局的结构信息,
Google的大作提供了第三个思路:纯Attention!单靠注意力就可以!RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;Attention的思路最为粗暴,它一步到位获取了全局信息!它的解决方案是:

Attention层
Attention的定义:
Attention顾名思义,是由人类观察环境的习惯规律总结出来的,人类在观察环境时,大脑往往只关注某几个特别重要的局部,获取需要的信息,构建出关于环境的某种描述,而Attention机制正是如此,去学习不同局部的重要性,再结合起来。
从数学公式上可以理解为加权求和;从形式上可以理解为键值查询;最后,从物理意义上,可以理解为相似性度量。
Google的一般化Attention思路也是一个编码序列的方案,因此我们也可以认为它跟RNN、CNN一样,都是一个序列编码的层。
前面给出的是一般化的框架形式的描述,事实上Google给出的方案是很具体的。首先,它先把Attention的定义给了出来:


其中Q∈R^n×dk,K∈R^m×dk,V∈R^m×dv。如果忽略激活函数softmax的话,那么事实上它就是三个n×dk,dk×m,m×dv的矩阵相乘,最后的结果就是一个n×dvn×dv的矩阵。于是我们可以认为:这是一个Attention层,将n×dkn×dk的序列Q编码成了一个新的n×dv的序列。

(http://ir.dlut.edu.cn/news/detail/486)
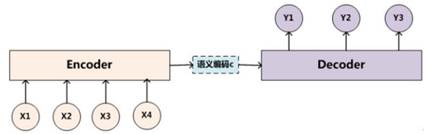
对于传统的机器翻译,我们可以使用sequence to sequence(encoder-decoder)模型来进行翻译,如下图所示。

这里,我们可以把上图抽象出来得到下图。输入序列{x1, x2, x3, x4},传入编码器(encoder)中进行编码,得到语义编码c,然后通过解码器(decoder)进行解码,得到输出序列{y1, y2, y3},输入与输出的个数可以不相等。对于句子<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target.
Source=<x1,x2,x3,...xm>
Target=<y1,y2,...yn>
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
C=F(x1,x2,...xm)
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息y1,y2,..yi-1,来生成i时刻要生成的单词yi:
yi=g(C,y1,y2,y3,..yi-1).
(一般而言,文本处理和语音识别的Encoder一般采用RNN模型,图像处理的Encoder一般采用CNN模型。)
但是,这种方式会有一个问题:对于长句子的翻译会造成一定的困难,而attention机制的引入可以解决这个问题。(为什么引入注意力模型?因为没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入的句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多的细节信息,所以要引入注意力机制)如下图所示:
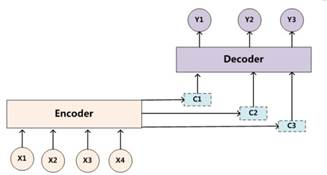
这里,我们可以看到,decoder中有几个输出序列,对应的语义编码c则有相同的数量,即一个语义编码ci对应一个输出yi。而每个ci就是由attention机制得到,具体公式如下:
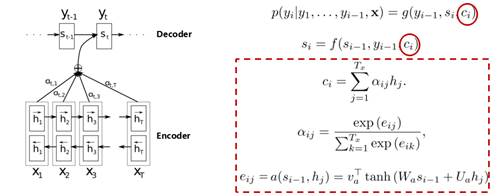
回顾了传统的attention模型之后,我们看一下google翻译团队对attention模型的高度抽取概况。他们将其映射为一个query和一系列<key, value>,最终得到输出attention value的过程。这里的query相当于decoder中的si-1,key与value都来自于encoder的hj,区别在于前后状态的hj。然后计算query与keyi的相似度,并与valuei进行相乘,然后求和。
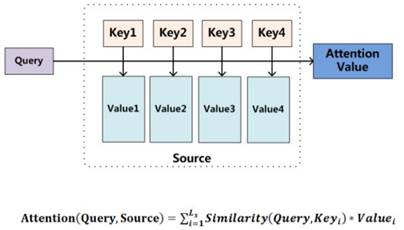
下图揭示了Attention机制的本质:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
理解Attention模型的关键就是,由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci.而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布。
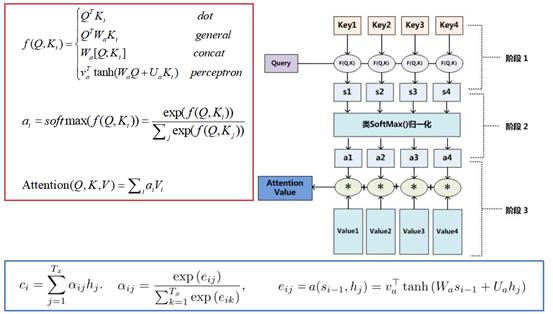
上面提到的query与key之间计算相似度有许多方法,如dot、general、concat和MLP等方式,具体公式如下所示。而attention模型抽象为query、key和value之间的相似度计算,总共有3个阶段。第一阶段:query与keyi使用特定的相似度函数计算相似度,得到si;第二阶段:对si进行softmax()归一化得到ai;第三阶段,将ai与valuei对应相乘再求和,得到最终的attention value。其实对比传统的attention公式,我们可以看出,这两套公式还是很像的。
Attention机制:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
---------------------
作者:张俊林博客
来源:CSDN
原文:https://blog.csdn.net/malefactor/article/details/78767781?utm_source=copy
(补充:softmax() (https://blog.csdn.net/red_stone1/article/details/80687921)
什么是Softmax?Softmax在机器学习和深度学习中有着非常广泛的应用。尤其在处理多类(C>2)问题,分类器最后的输出单元需要Softmax函数进行数值处理。
关于Softmax函数的定义如下:
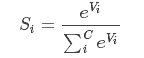
其中,Vi 是分类器前级输出单元的输出。i 表示类别索引,总的类别个数为 C。Si 表示的是当前元素的指数与所有元素指数和的比值。Softmax 将多分类的输出数值转化为相对概率,更容易理解和比较。我们来看下面这个例子。
一个多分类问题,C = 4。线性分类器模型最后输出层包含了四个输出值,分别是:
经过Softmax处理后,数值转化为相对概率:

很明显,Softmax 的输出表征了不同类别之间的相对概率。我们可以清晰地看出,S1 = 0.8390,对应的概率最大,则更清晰地可以判断预测为第1类的可能性更大。Softmax 将连续数值转化成相对概率,更有利于我们理解。
实际应用中,使用 Softmax 需要注意数值溢出的问题。因为有指数运算,如果 V 数值很大,经过指数运算后的数值往往可能有溢出的可能。所以,需要对 V 进行一些数值处理:即 V 中的每个元素减去 V 中的最大值。

补充:
掩膜的用法
2.1 提取感兴趣区:用预先制作的感兴趣区掩膜与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0;
2.2 屏蔽作用:用掩膜对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计;
2.3 结构特征提取:用相似性变量或图像匹配方法检测和提取图像中与掩膜相似的结构特征;
2.4 特殊形状图像的制作。
---------------------
作者:bitcarmanlee
来源:CSDN
原文:https://blog.csdn.net/bitcarmanlee/article/details/79132017?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号