


深度学习基础(基础知识0)
深度学习各种网络其实基础就是各种基础知识累积,今天主要想把这三个讲清楚:梯度下降、神经网络、反向传播算法。
一、神经网络(一切的基石)
工智能的底层模型是"神经网络"(neural network)。许多复杂的应用(比如模式识别、自动控制)和高级模型(比如深度学习)都基于它。学习人工智能,一定是从它开始。
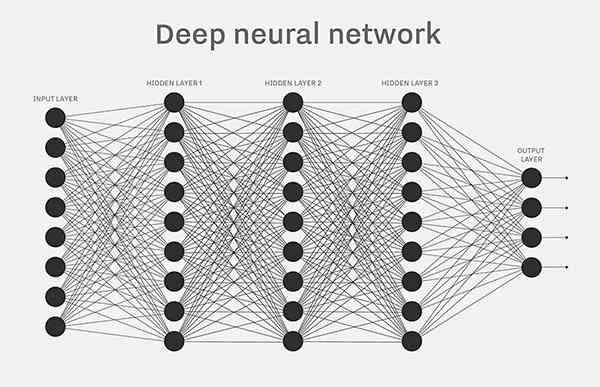
什么是神经网络呢?
1、感知器
历史上,科学家一直希望模拟人的大脑,造出可以思考的机器。人为什么能够思考?科学家发现,原因在于人体的神经网络。
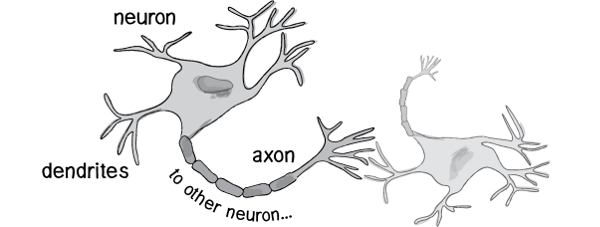
既然思考的基础是神经元,如果能够"人造神经元"(artificial neuron),就能组成人工神经网络,模拟思考。上个世纪六十年代,提出了最早的"人造神经元"模型,叫做"感知器"(perceptron),直到今天还在用。
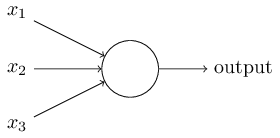
上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
为了简化模型,我们约定每种输入只有两种可能:1 或 0。如果所有输入都是1,表示各种条件都成立,输出就是1;如果所有输入都是0,表示条件都不成立,输出就是0。
2、感知器的例子
下面来看一个例子。城里正在举办一年一度的游戏动漫展览,小明拿不定主意,周末要不要去参观。

他决定考虑三个因素。
这就构成一个感知器。上面三个因素就是外部输入,最后的决定就是感知器的输出。如果三个因素都是 Yes(使用1表示),输出就是1(去参观);如果都是 No(使用0表示),输出就是0(不去参观)。
3、权重和阈值
看到这里,你肯定会问:如果某些因素成立,另一些因素不成立,输出是什么?比如,周末是好天气,门票也不贵,但是小明找不到同伴,他还要不要去参观呢?
现实中,各种因素很少具有同等重要性:某些因素是决定性因素,另一些因素是次要因素。因此,可以给这些因素指定权重(weight),代表它们不同的重要性。
上面的权重表示,天气是决定性因素,同伴和价格都是次要因素。
如果三个因素都为1,它们乘以权重的总和就是 8 + 4 + 4 = 16。如果天气和价格因素为1,同伴因素为0,总和就变为 8 + 0 + 4 = 12。
这时,还需要指定一个阈值(threshold)。如果总和大于阈值,感知器输出1,否则输出0。假定阈值为8,那么 12 > 8,小明决定去参观。阈值的高低代表了意愿的强烈,阈值越低就表示越想去,越高就越不想去。
上面的决策过程,使用数学表达如下。
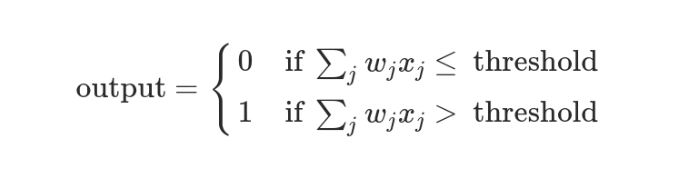
上面公式中,x表示各种外部因素,w表示对应的权重。
4、决策模型
单个的感知器构成了一个简单的决策模型,已经可以拿来用了。真实世界中,实际的决策模型则要复杂得多,是由多个感知器组成的多层网络。
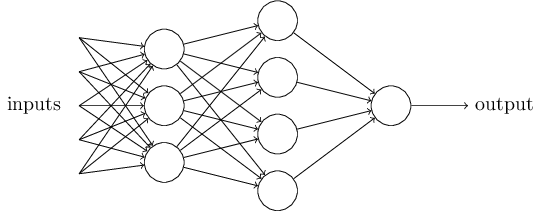
上图中,底层感知器接收外部输入,做出判断以后,再发出信号,作为上层感知器的输入,直至得到最后的结果。(注意:感知器的输出依然只有一个,但是可以发送给多个目标。)
这张图里,信号都是单向的,即下层感知器的输出总是上层感知器的输入。现实中,有可能发生循环传递,即 A 传给 B,B 传给 C,C 又传给 A,这称为"递归神经网络"(recurrent neural network),本文不涉及。
5、矢量化
为了方便后面的讨论,需要对上面的模型进行一些数学处理。
感知器模型就变成了下面这样。
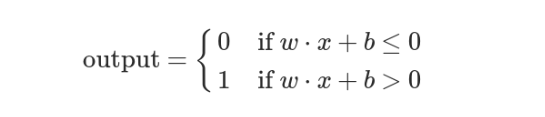
6、神经网络的运作过程
一个神经网络的搭建,需要满足三个条件。
也就是说,需要事先画出上面出现的那张图。
其中,最困难的部分就是确定权重(w)和阈值(b)。目前为止,这两个值都是主观给出的,但现实中很难估计它们的值,必需有一种方法,可以找出答案。
这种方法就是试错法。其他参数都不变,w(或b)的微小变动,记作Δw(或Δb),然后观察输出有什么变化。不断重复这个过程,直至得到对应最精确输出的那组w和b,就是我们要的值。这个过程称为模型的训练。
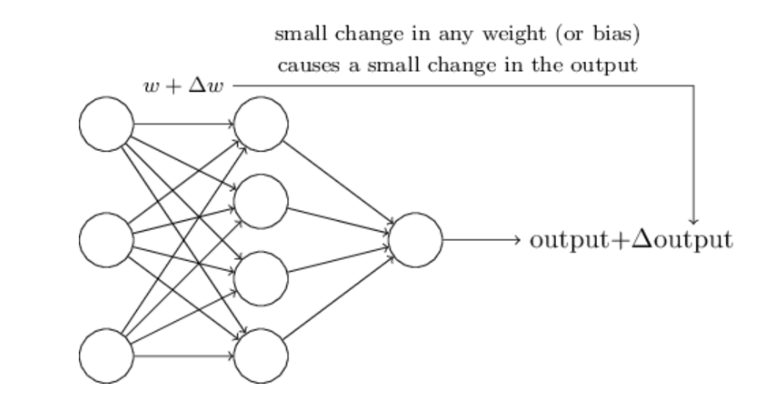
因此,神经网络的运作过程如下。
- 确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算
w和b - 一旦新的数据产生,输入模型,就可以得到结果,同时对
w和b进行校正
可以看到,整个过程需要海量计算。所以,神经网络直到最近这几年才有实用价值,而且一般的 CPU 还不行,要使用专门为机器学习定制的 GPU 来计算。
7、神经网络的例子
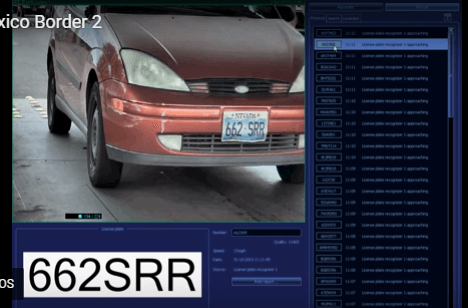
下面通过车牌自动识别的例子,来解释神经网络。

所谓"车牌自动识别",就是高速公路的探头拍下车牌照片,计算机识别出照片里的数字。
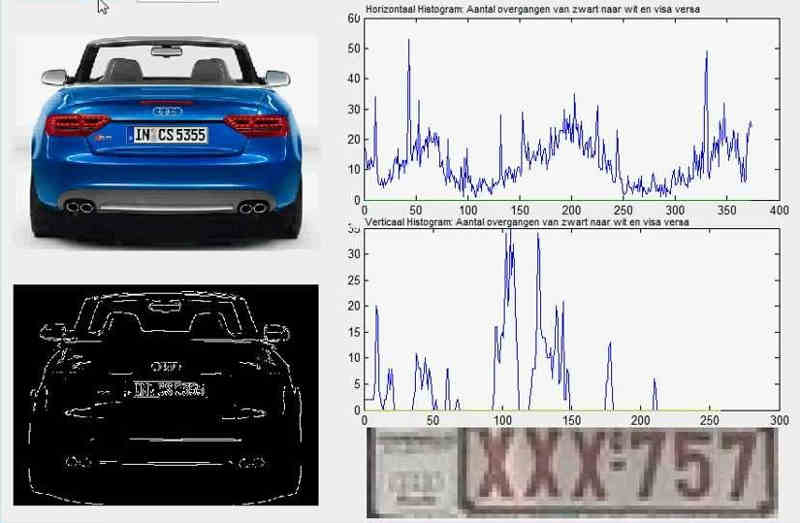
这个例子里面,车牌照片就是输入,车牌号码就是输出,照片的清晰度可以设置权重(w)。然后,找到一种或多种图像比对算法,作为感知器。算法的得到结果是一个概率,比如75%的概率可以确定是数字1。这就需要设置一个阈值(b)(比如85%的可信度),低于这个门槛结果就无效。
一组已经识别好的车牌照片,作为训练集数据,输入模型。不断调整各种参数,直至找到正确率最高的参数组合。以后拿到新照片,就可以直接给出结果了。
8、输出的连续性
上面的模型有一个问题没有解决,按照假设,输出只有两种结果:0和1。但是,模型要求w或b的微小变化,会引发输出的变化。如果只输出0和1,未免也太不敏感了,无法保证训练的正确性,因此必须将"输出"改造成一个连续性函数。
这就需要进行一点简单的数学改造。
首先,将感知器的计算结果wx + b记为z。
然后,计算下面的式子,将结果记为σ(z)。
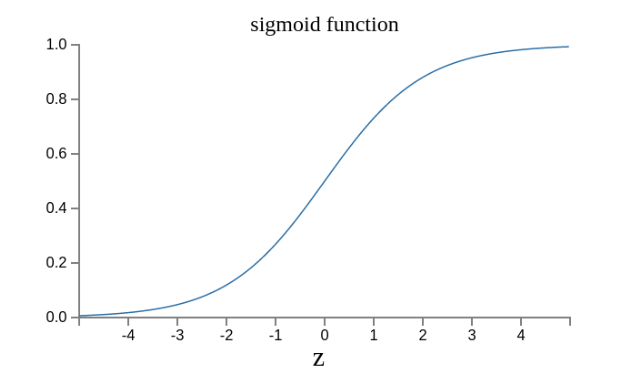
这是因为如果z趋向正无穷z → +∞(表示感知器强烈匹配),那么σ(z) → 1;如果z趋向负无穷z → -∞(表示感知器强烈不匹配),那么σ(z) → 0。也就是说,只要使用σ(z)当作输出结果,那么输出就会变成一个连续性函数。
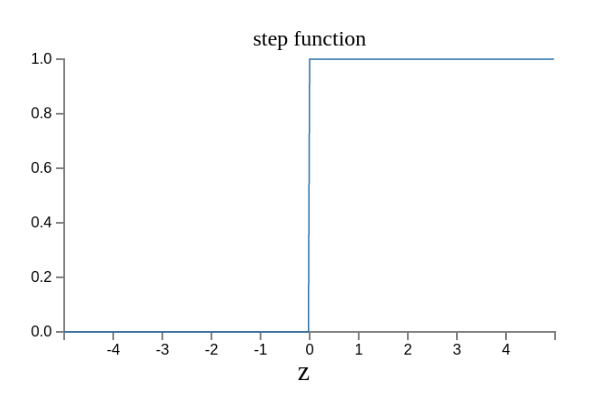
原来的输出曲线是下面这样。
现在变成了这样。
实际上,还可以证明Δσ满足下面的公式。
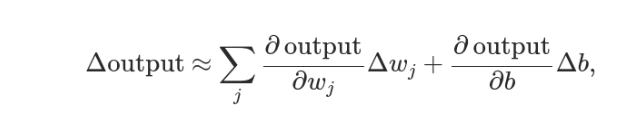
即Δσ和Δw和Δb之间是线性关系,变化率是偏导数。这就有利于精确推算出w和b的值了。
这里可以看到Sigmoid 函数是使用深度学习范围最广的一类激活函数,具有指数函数形状 。正式定义为:

在深度学习中,信号从一个神经元传入到下一层神经元之前是通过线性叠加来计算的,而进入下一层神经元需要经过非线性的激活函数,继续往下传递,如此循环下去。由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的特征。
为什么要使用非线性激活函数?
答:如果不使用激活函数,这种情况下每一层输出都是上一层输入的线性函数。无论神经网络有多少层,输出都是输入的线性函数,这样就和只有一个隐藏层的效果是一样的。这种情况相当于多层感知机(MLP)。
具体参考:http://www.360doc.com/content/17/1102/21/1489589_700400500.shtml
二、梯度下降和ANN—人工神经元网络训练
ANN网络:输入层/输入神经元,输出层/输出神经元,隐层/隐层神经元,权值,偏置,激活函数
ANN网络训练过程:
假设ANN网络已经搭建好了,在所有应用问题中(不管是网络结构,训练手段如何变化)我们的目标是不会变的,那就是网络的权值和偏置最终都变成一个最好的值,这个值可以让我们由输入可以得到理想的输出,于是问题就变成了y=f(x,w,b)(x是输入,w是权值,b为偏置)
最后的目标就变成了尝试不同的w,b值,使得最后的y=f(x)无限接近我们希望得到的值t,也就是让loss最小,loss可以用(y-t)^2的值尽可能的小。于是原先的问题化为了C(w,b)=(f(x,w,b)-t)^2取到一个尽可能小的值。这个问题不是一个困难的问题,不论函数如何复杂,如果C降低到了一个无法再降低的值,那么就取到了最小值(假设我们不考虑局部最小的情况)。
梯度下降方法求解下降最快:
网络权值偏置更新问题 ==> f(x,w,b)的结果逼近t ==> C(w,b)=(f(x,w,b)-t)^2取极小值问题 ==> C(w,b)按梯度下降问题 ==>取到极小值,网络达到最优。
推导基于一个前提:我们已经提前知道了当前点的梯度。然而事实是我们不知道。
那么怎么解决呢?
三、反向传播方法更新权重矩阵求下降梯度
为什么要用反向传播?
主要是训练过程中,我们知道了输入和输出和groudtruth最后的真实结果,那么我们可以根据真实的结果-output得到误差值,再反向去推导前一层的误差,这样就可以更新我们的W 和B,比单纯的梯度下降去慢慢穷举一个个试试,速度快多了。
所以步骤就是:
step1、前向传播:
1.输入层---->隐含层:
计算神经元h1的输入加权和,神经元h1的输出o1:(此处用到激活函数为sigmoid函数),同理,可计算出神经元h2的输出o2。
2.隐含层---->输出层:
计算输出层神经元o1和o2的值。
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)。真实值-output
2.隐含层---->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则),算出整体误差E(total)对w5的偏导值。
最后我们来更新w5的值。同理可更新w6,w7,w8。
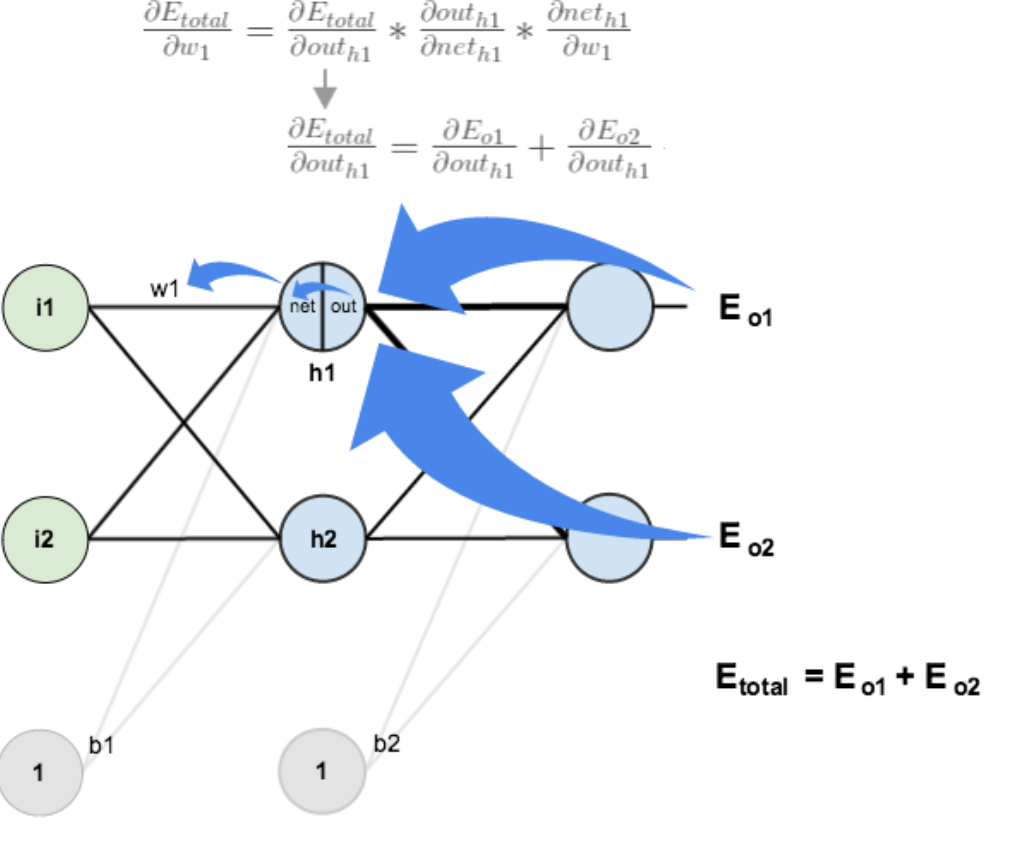
3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。
1、反向传播的原理
首先,需要记住两点:
1.反向传播算法告诉我们当我们改变权值(weights)和偏置(biases)的时候,损失函数改变的速度。
2.反向传播也告诉我们如何改变权值和偏置以改变神经网络的整体表现。
2.一个很好的例子
假设,你有这样一个网络层:
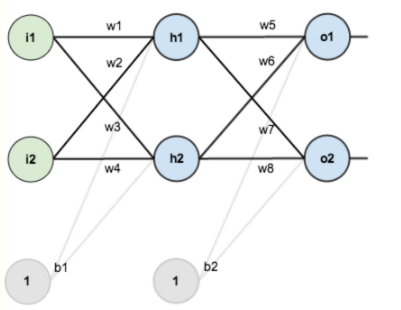
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
现在对他们赋上初值,如下图:
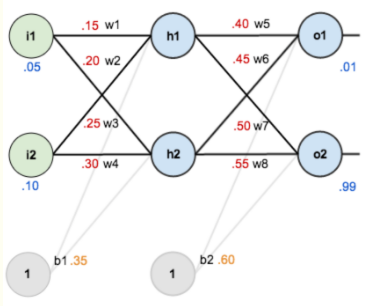
其中,输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01,o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.88
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
1.输入层---->隐含层:
计算神经元h1的输入加权和:

神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
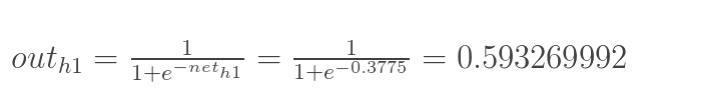
同理,可计算出神经元h2的输出o2:

2.隐含层---->输出层:
计算输出层神经元o1和o2的值:

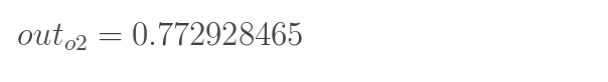
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)
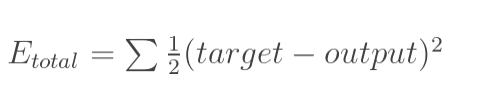
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:

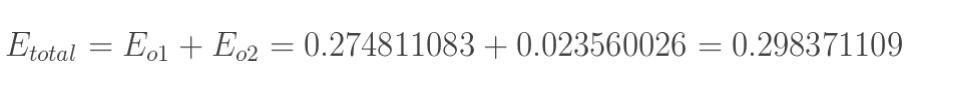
2.隐含层---->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
下面的图可以更直观的看清楚误差是怎样反向传播的:

现在我们来分别计算每个式子的值:
计算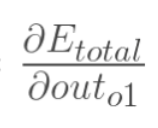 :
:

计算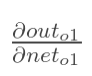 :
:

(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
计算 :
:
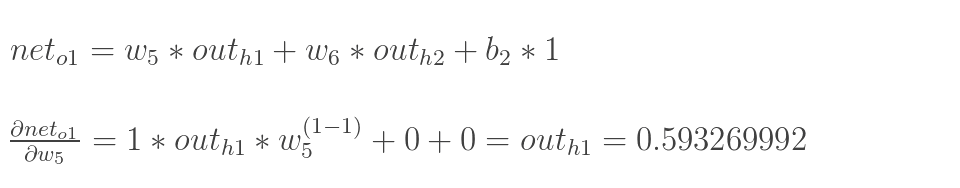
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:

为了表达方便,用 来表示输出层的误差:
来表示输出层的误差:

因此,整体误差E(total)对w5的偏导公式可以写成:

如果输出层误差计为负的话,也可以写成:

最后我们来更新w5的值:
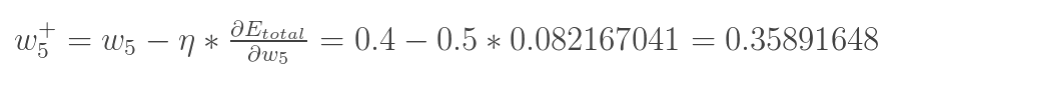
(其中,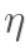 是学习速率,这里我们取0.5)
是学习速率,这里我们取0.5)
同理,可更新w6,w7,w8:

3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
计算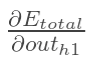 :
:

先计算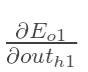 :
:
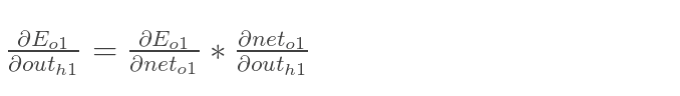

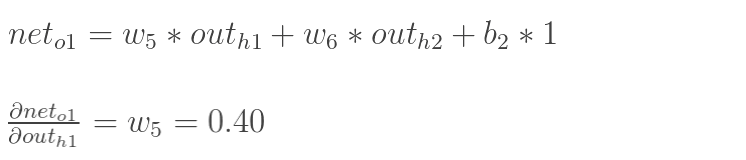
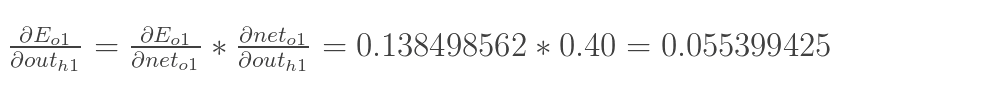
同理,计算出:
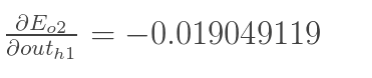
两者相加得到总值:
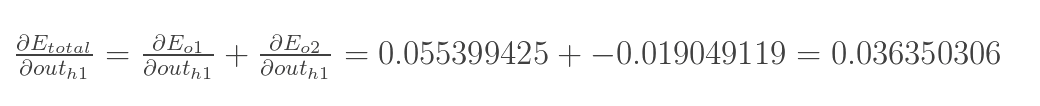
再计算 :
:

再计算 :
:

最后,三者相乘:

为了简化公式,用sigma(h1)表示隐含层单元h1的误差:

最后,更新w1的权值:

同理,额可更新w2,w3,w4的权值:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的
3、算法步骤
前向传递输入信号直至输出产生误差,反向传播误差信息更新权重矩阵。
后向传播算法是深度学习中一种训练与学习方法,用来调整深度网络中各个节点之间的权重,使得网络输出的样本标签与实际标签相一致。本文将对后向传播算法的实现细节进行总结。
后向传播算法是将输出层的误差向后进行传播来实现权重的调整。如图1所示,一个含有1个隐藏层的网络,输入层有2个节点,隐藏层有3个节点,输出层有2个节点。
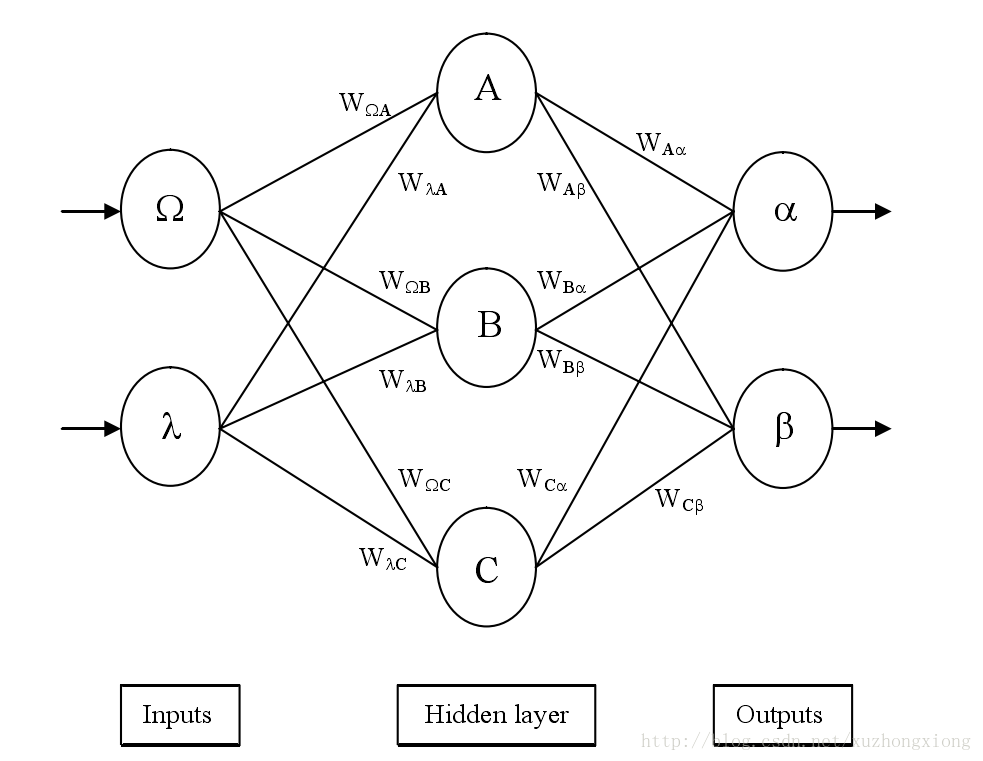
则后向传播的实现细节如下:

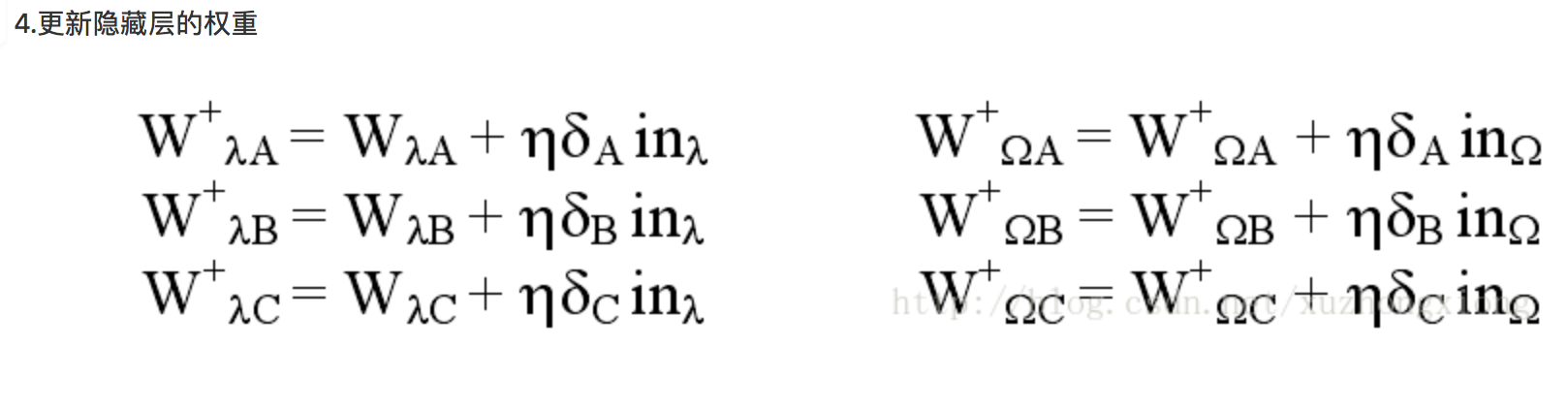
下面给出一个计算示例:
如图2为一个简单的网络
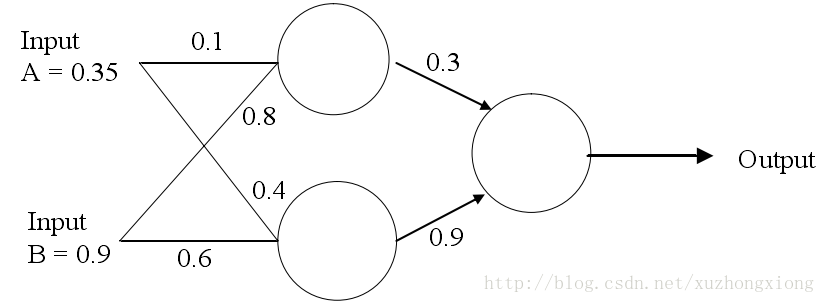
假设目标输出为0.5,即target=0.5,则按照以上的方法计算如下:
1.计算各节点的值与激活值
a.隐藏层最顶端节点:(0.35×0.1)+(0.9×0.8)=0.755;
节点输出:out=sigmoid(0.755)=0.68;
b.隐藏层最低端节点:(0.9×0.6)+(0.35×0.4)=0.68;
节点输出:out=sigmoid(0.68)=0.6637;
c.输出层节点:(0.3×0.68)+(0.9×0.6637)=0.80133
节点输出:sigmoid(0.80133)=0.69
2.后向传播更新权重
a.输出误差:δ=(t-o)(1-o)o=(0.5-0.69)(1-0.69)0.69=-0.0406;
b.更新输出层权重:
W1+=W1+(δ×input)=0.3+(-0.0406×0.68)=0.272392
W2+=W2+(δ×input)=0.9+(-0.0406×0.6637)=0.87305
c.隐藏层误差与权重更新
误差计算:
δ1=δ×W1=-0.0406×0.272392×(1-o)o=-2.406×10−3
δ2=δ×W2=-0.0406×0.87305×(1-o)o=-7.916×10−3
权重更新:
W3+=0.1+(−2.406×10−3×0.35)=0.09916
W4+=0.8+(−2.406×10−3×0.9)=0.7978
W5+=0.4+(−7.916×10−3×0.35)=0.3972
W6+=0.6+(−7.916×10−3×0.9)=0.5928

 浙公网安备 33010602011771号
浙公网安备 33010602011771号