

《Improving Calibration for Long-Tailed Recognition》阅读笔记
论文标题
《Improving Calibration for Long-Tailed Recognition》
改进长尾识别的校准工作
作者
Zhisheng Zhong、 Jiequan Cui、Shu Liu 和 Jiaya Jia
香港中文大学和 SmartMore
初读
摘要
- 深度神经网络在训练数据集类别极度不平衡时可能会表现不佳。最近,两阶段方法将表示学习和分类器学习解耦以提高性能。但仍然存在一个重要问题,即误校准(miscalibration)。
- 为了解决这个问题,我们设计了两种方法来改善这类场景中的校准和性能。
- 受到预测类别概率分布与类别实例数量高度相关的启发,我们提出了标签感知平滑(label-aware smoothing)来处理不同类别的过度自信问题,并改进分类器学习。
- 由于这两个阶段使用了不同的采样器,导致数据集之间存在偏差,我们在解耦框架中进一步提出了移位批量归一化(shifted batch normalization)。
- 我们提出的方法在多个流行的长尾识别基准数据集上创造了新的记录,包括 CIFAR-10-LT、CIFAR-100-LT、ImageNet-LT、Places-LT 和 iNaturalist 2018。
结论
- 在本文中,我们发现相比于在平衡数据集上训练的模型,在长尾数据集上训练的模型更容易出现误校准和过度自信(miscalibrated and overconfident)的问题。
- 因此,我们相应地提出了两种解决方案:
- 使用 mixup 和设计标签感知平滑(label-aware smoothing)来处理不同类别的过度自信问题。
- 我们注意到在长尾识别的两阶段重采样方法中存在数据集偏差(或域偏移)。为了减少解耦框架中的数据集偏差,我们提出了在批量归一化层上的移位学习(shift learning),这进一步提高了性能。
- 在各种基准上的大量定量和定性实验表明,我们的 MiSLAS 在 top-1 识别准确性和置信度校准方面都取得了不错的性能,并达到了新的最先进水平。
再读
Section 1 Introduction
-
背景:
随着众多大规模、高质量的数据集的可用,例如 ImageNet,COCO 和 Places,深度卷积神经网络(CNNs)在各种计算机视觉任务中取得了显著的突破,例如图像识别,目标检测和语义分割。这些数据集通常在每个对象/类别实例数量上是人为平衡的。然而,在许多现实世界应用中,数据可能遵循意料之外的长尾分布,其中不同类别的实例数量严重不平衡。当在这些长尾数据集上训练 CNNs 时,性能显著下降。为了解决这个严重的问题,提出了一系列用于长尾识别的方法。
-
两阶段方法与一阶段方法:
最近,许多两阶段方法与一阶段方法相比取得了显著的改进。
- 延迟重采样(Deferred Re-sampling,DRS)和延迟重加权(Deferred Reweighting,DRW)首先在第一阶段以正常方式训练 CNN。DRS 在第二阶段通过类平衡重采样调整 CNN,而 DRW 在第二阶段通过为不同类别分配不同权重来调整 CNN。
- Zhou 等人在一阶段提出了双边分支网络(Bilateral Branch Network,BBN),通过动态结合实例平衡采样器和反向平衡采样器来模拟DRS的过程。
- Kang 等人提出了两个两阶段解耦模型,分类器重新训练(Classifier Retraining,cRT)和学习权重缩放(Learnable Weight Scaling,LWS),以进一步提升性能,其中解耦模型冻结了主干网络,仅在第二阶段使用类平衡重采样训练分类器。
-
置信度校准(Confidence calibration):
-
置信度校准是通过估计真实正确可能性的代表性来预测概率。在许多应用中,对于识别模型来说,置信度校准非常重要。
-
期望校准误差(Expected Calibration Error,ECE)被广泛用于测量网络的校准程度。为了计算 ECE,首先将所有 \(N\) 个预测分到 \(B\) 个等大小的间隔箱中。ECE 定义如下:
\[\text{ECE}=\sum_{b=1}^B\frac{|\mathcal{S}_b|}{N}\left|\text{acc}(\mathcal{S}_b)-\text{conf}(\mathcal{S}_b) \right|\times100\% \]- 参数字典:
- \(\mathcal{S}_b\) 是预测得分属于 \(Bin-b\) 的样本集。
- \(acc(\cdot)\) 和 \(conf(\cdot)\) 分别是 \(\mathcal{S}_b\) 的准确度和预测置信度。
- 参数字典:
-
-
误校准和过度自信(miscalibrated and overconfident):
-
我们的研究表明,由于每个类别的组成比例不平衡,训练于长尾数据集的网络更容易出现误校准和过度自信。
-
我们在图 1 中绘制了具有 15 个箱子(bins)的可靠性图表,比较了在原始 CIFAR-100 数据集上训练的普通交叉熵(cross-entropy,CE)模型,以及在 CIFAR-100-LT 上训练的普通 CE 模型、cRT 和 LWS,后者具有 100 的不平衡因子(imbalanced factor,IF)。

- 图片注解:ResNet-32 的可靠性图表。从左上角到右下角依次为:
- 在原始平衡的 CIFAR-100 数据集上训练的普通模型,
- 以及在具有100的不平衡因子(IF)的 CIFAR-100-LT 上训练的普通模型、
- cRT 和 LWS。
- 图片注解:ResNet-32 的可靠性图表。从左上角到右下角依次为:
-
可以注意到,在长尾数据集上训练的网络通常具有更高的 ECE。两阶段模型 cRT 和 LWS 也遭受过度自信的问题。此外,附录 C 中的图 9 和图 10(前两个图)描述了这种现象在其他长尾数据集上,如 CIFAR-10-LT 和 ImageNet-LT,也同样存在。
-
-
两阶段解耦的问题:
- 另一个问题是,两阶段解耦忽略了两个阶段中的数据集偏差或域偏移(the dataset bias or domain shift)。
- 具体来说,两阶段模型首先在第一阶段在实例平衡数据集 \(\mathcal{D}_I\) 上进行训练。然后,模型在第二阶段在类别平衡数据集 \(\mathcal{D}_C\) 上进行训练。显然,\(P_{\mathcal{D}_I}(\boldsymbol{x},y) \ne P_{\mathcal{D}_C}(\boldsymbol{x},y)\),且不同采样方式的数据集分布不一致。
- 受到迁移学习(transfer learning)的启发,我们专注于批量归一化层(the batch normalization layer)来处理数据集偏差问题。
-
本文贡献:
在这项工作中,我们提出了一个混合移位标签感知平滑模型(Mixup Shifted Label-Aware Smoothing model,MiSLAS),以有效地解决上述问题。我们的主要贡献如下:
- 我们发现,与在平衡数据上训练的模型相比,在长尾数据集上训练的模型存在更多的误校准和过度自信(miscalibrated and overconfident)问题。两阶段模型也遭受这个问题。
- 我们发现,mixup 可以缓解过度自信问题,并对表示学习有积极影响,但对分类器学习的负面影响或可以忽略不计。为了进一步强化分类器学习和校准,我们提出了标签感知平滑来处理不同类别的过度自信问题。
- 这是首次尝试指出长尾识别的两阶段重采样方法中的数据集偏差或域偏移问题。为了在解耦框架中处理这个问题,我们提出了在批量归一化层上的移位学习(shift learning on the batch normalization layer),这可以大大提高性能。
Section 2 Related Work
-
重采样和重加权(Re-sampling and re-weighting)
-
有两种重采样策略:一种是过采样尾部类别的图像,另一种是欠采样头部类别的图像。
- 过采样(over-sampling)通常在大数据集上有效,但在小数据集上可能会特别容易过度拟合尾部类别。
- 对于欠采样(under-sampling),它丢弃了大量的数据,这不可避免地导致深度模型泛化能力的下降。
-
重加权(Reweighting)是另一种显着的策略。
-
它为不同的类别甚至实例分配不同的权重。传统的重加权方法根据类别的样本数量成反比分配类别权重。
-
然而,在大型数据集上,重加权使得深度模型在训练过程中难以优化。
- Cui 等人使用有效数量来计算类别权重,从而缓解了这个问题。
- 另一项工作是自适应地重加权每个实例。例如,焦点损失(focal loss)为易于分类的样本分配较小的权重。
-
-
-
置信度校准和正则化(Confidence calibration and regularization)
- 在许多应用中,校准的置信度对于分类模型非常重要。现代神经网络的校准问题首先在 [9] 中讨论。作者发现,模型容量、规范化和正则化对网络校准有强烈的影响。
- mixup 是一种正则化技术,通过输入和标签的插值进行训练。
- mixup 启发了后续的 manifold mixup、CutMix 和 Remix,这些技术都显示出显著的改进。Thulasidasan 等人发现,使用 mixup 训练的 CNN 更好地校准了。
- 标签平滑(label smoothing)是另一种正则化技术,它鼓励模型减少过度自信。
- 与在地面真实(ground truth)标签上计算损失的交叉熵不同,标签平滑在标签的软化版本上计算损失。它减轻了过拟合,并增加了校准和可靠性。
-
两阶段方法(Two-stage methods)
- Cao 等人提出了延迟重加权(Deferred Reweighting,DRW)和延迟重采样(Deferred Re-sampling,DRS),这些方法比传统的单阶段方法效果更好。它的第二阶段从更好的特征开始,调整决策边界并进行局部特征调整。
- 最近,Kang 等人和 Zhou 等人得出结论,尽管类别重新平衡对于联合训练表示和分类器很重要,但实例平衡采样提供了更一般的表示。基于这一观察,Kang 等人通过分解表示学习和分类器学习实现了最先进的结果。
- 它首先使用实例平衡采样训练深度模型,然后在与表示学习参数固定的情况下,使用类别平衡采样微调分类器。
- 类似地,Zhou 等人将 mixup 训练集成到提出的累积学习策略中。
- 它桥接了表示学习和分类器重新平衡。累积学习策略需要实例平衡和反向实例平衡的双重采样器。
Section 3 Main Approach
3.1.Study of mixup Strategy
mixup 策略研究
-
相关工作与实验目的:
在两阶段学习框架中,Kang 等人和 Zhou 等人发现,实例平衡采样为长尾识别提供了最一般的表示。此外,Thulasidasan 等人展示了对 mixup 进行训练的网络具有更好的校准。基于这些发现,在使用实例平衡采样的情况下,我们探索了 mixup 在两阶段解耦框架中的作用,以实现更高的表示泛化和减少过度自信。
-
实验:
-
实验设置:
-
我们在 ImageNet-LT 上训练了一个普通的交叉熵模型,以及两个两阶段模型 cRT 和 LWS,第一阶段训练 180 个周期,第二阶段分别微调 10 个周期。
-
我们变化训练设置(是否使用 mixup \(\alpha=0.2\))对两个阶段都进行了实验。这些变体的 Top-1 准确率列于表 1 中。
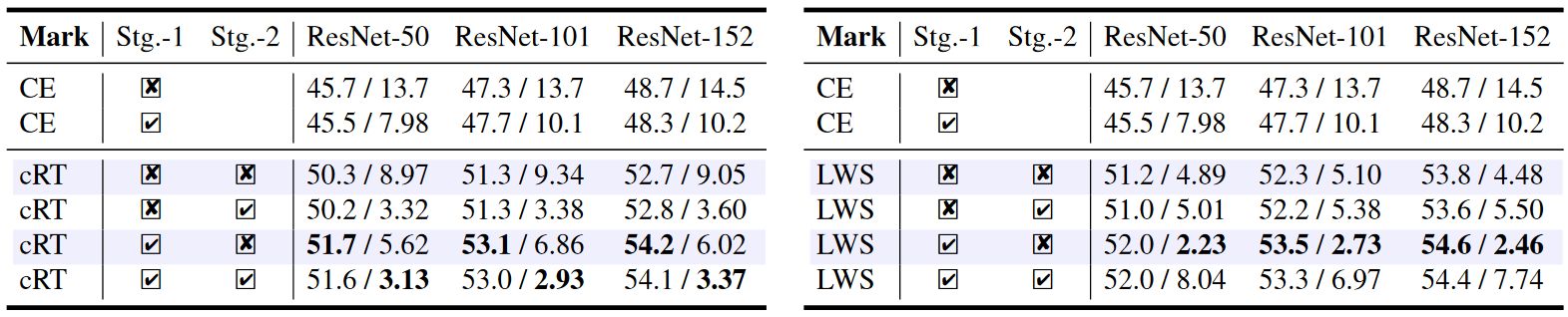
- 图片注解:对于 ImageNet-LT 验证集,分类器权重范数,其中类别按 \(N_j\) 的降序排列,\(N_j\) 表示 Class-\(j\) 的训练样本数量。
- 左图:cRT 模型使用或不使用 mixup 的权重范数。
- 右图:LWS 模型使用或不使用 mixup 的权重范数。
- 浅色阴影:真实范数。
- 深色线条:平滑版本。最好在屏幕上查看。
- 图片注解:对于 ImageNet-LT 验证集,分类器权重范数,其中类别按 \(N_j\) 的降序排列,\(N_j\) 表示 Class-\(j\) 的训练样本数量。
-
-
mixup 有效性分析:
它揭示了以下几点。
- 应用 mixup 时,CE 模型的改进可以忽略不计。但对于 cRT 和 LWS,性能得到了极大的提升。
- 在第二阶段应用额外的 mixup 并没有带来明显的改进,甚至可能损害性能。原因是 mixup 鼓励表示学习,但对分类器学习有不利或可忽略的影响。
-
分类器权重范数分析:
-
此外,我们在图 2 中绘制了这些变体的最终分类器权重范数。我们展示了所有类别的权重向量的 \(L_2\) 范数,以及按实例数量降序排列的训练数据分布。
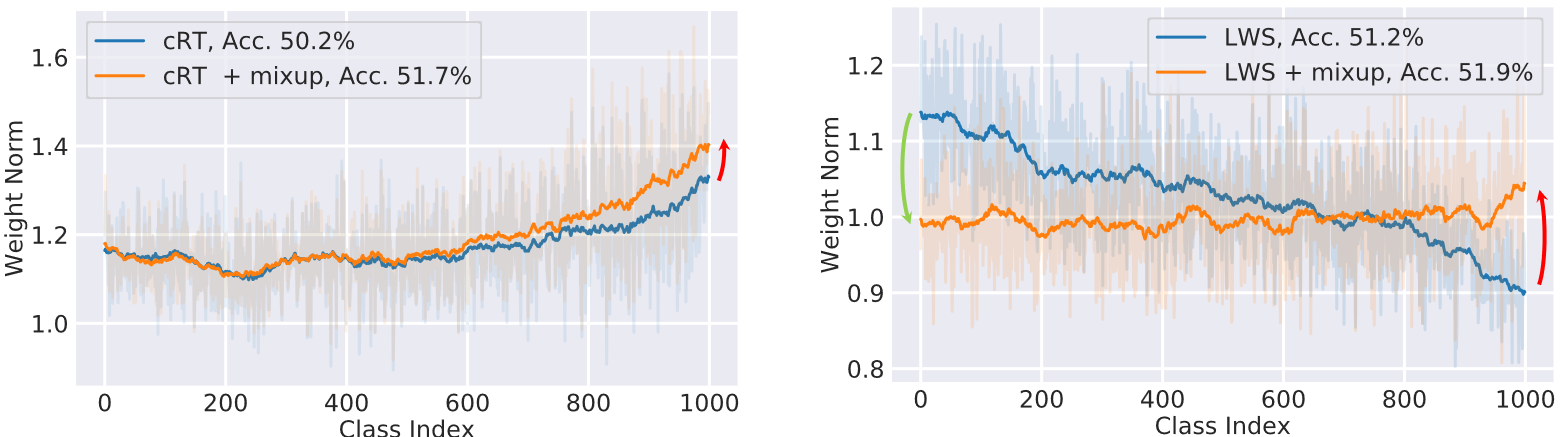
- 图片注解:展示了 ImageNet-LT 验证集上分类器权重范数的图表,其中类别按照 \(N_j\) 的降序排列, \(N_j\) 表示 Class-\(j\) 的训练样本数量。
- 左图:显示了 cRT 模型在有无 mixup 情况下的权重范数。
- 右图:显示了 LWS 模型在有无 mixup 情况下的权重范数。
- 浅色阴影区域代表真实的权重范数。
- 深色线条代表平滑后的版本。最好在屏幕上查看。
- 图片注解:展示了 ImageNet-LT 验证集上分类器权重范数的图表,其中类别按照 \(N_j\) 的降序排列, \(N_j\) 表示 Class-\(j\) 的训练样本数量。
-
我们观察到,应用 mixup(橙色)时,尾部类别的权重范数倾向于变大,而头部类别的权重范数减小。这意味着 mixup 可能对尾部类别更友好。
-
-
期望校准误差分析:
我们还列出了上述模型的 ECEs 于表 1 中。
- 仅在第一阶段添加 mixup 时,cRT 和 LWS 模型能够一致地获得更好的 Top-1 准确率和更低的 ECEs,适用于不同的主干网络(第 4 行和第 6 行)。
- 由于对分类器学习(通过在第二阶段添加 mixup)的 Top-1 准确率提升不满意且 ECE 下降不稳定,我们提出了一个标签感知平滑来进一步改善校准和分类器学习。
-
3.2.Label-aware Smoothing
标签感知平滑
在本小节中,我们分析和解决过度自信以及分类器学习改进受限这两个问题。
-
过度自信(over-confidence):
-
假设分类器的权重为 \(\boldsymbol{W}\in\R^{M\times K}\),其中 \(M\) 是特征的数量,\(K\) 是类别的数量。
-
交叉熵损失函数会导致网络对头部类别产生过度自信。经过 softmax 激活后的交叉熵损失为 \(l(y,\boldsymbol{p})=−\log(\boldsymbol{p}_y)=−\boldsymbol{w}^⊤_y\boldsymbol{x}+\log(\sum\exp(\boldsymbol{w}^⊤_i\boldsymbol{x}))\),其中 \(y\in\{1, 2,\dots,K\}\) 是标签。\(x\in\R^M\) 是发送到分类器的特征向量,\(\boldsymbol{w}_i\) 是 \(\boldsymbol{W}\) 的第 \(i\) 列向量。最优解是 \(\boldsymbol{w}^{∗T}_y\boldsymbol{x}=\text{inf}\),而其他 \(\boldsymbol{w}^T_i\boldsymbol{x},\ i\ne y\) 足够小。
-
因为头部类别包含更多的训练示例,网络会使头部类别的权重范数 \(‖w‖\) 变大以接近最优解。这导致预测概率主要接近 1.0(参见 Fig. 3,上半部分浅蓝色部分)。
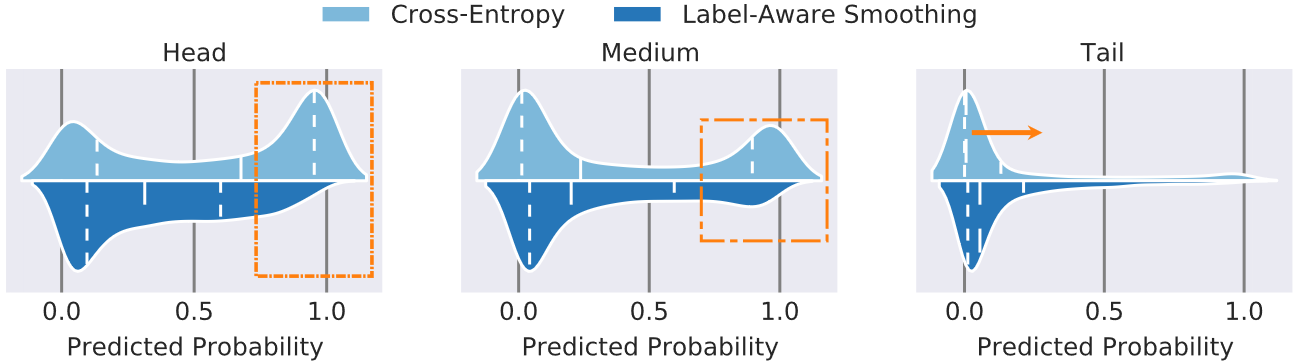
- 图片注解:在 CIFAR-100-LT 上,当 IF 为 100 时,不同类别部分(头部(每个类 100+ 张图像)、中部(每类 20-100 张图像)和尾部(每类少于 20 张图像))的预测概率分布的提琴图。
- 上半部分浅蓝色表示“LWS + 交叉熵”。
- 下半部分深蓝色代表“LWS + 标签感知平滑”。
- 图片注解:在 CIFAR-100-LT 上,当 IF 为 100 时,不同类别部分(头部(每个类 100+ 张图像)、中部(每类 20-100 张图像)和尾部(每类少于 20 张图像))的预测概率分布的提琴图。
-
另一个事实是,预测概率的分布与实例数量有关。与平衡识别不同,为了解决长尾问题,对这些类别应用不同的策略是必要的。
-
-
标签感知平滑(label-aware smoothing):
-
标签感知平滑的表达式:
在这里,我们提出了标签感知平滑(label-aware smoothing)来解决交叉熵中的过度自信问题以及预测概率分布不均的问题。它被表达为:
\[l(\boldsymbol{q},\boldsymbol{p})=-\sum_{i=1}^K\boldsymbol{q}_i\log\boldsymbol{p}_i, \]\[\begin{align} q_i=\begin{cases}1-\epsilon_y=1-f(N_y),&\text{if } i = y, \\ \epsilon_{K-1} = f(N_{K-1}) / (K-1), & \text{otherwise,} \end{cases}\qquad\qquad(1) \end{align} \]-
参数字典:
其中 \(\epsilon_y\) 是类别 \(y\) 的小标签平滑因子,与它的类别数量 \(N_y\) 相关。
现在最优解变成了(证明见附录E):
\[w^{*T}_ix = \begin{cases} \log\left( \frac{(K-1)(1-\epsilon_y)}{\epsilon_y} \right) + c, &i = y, \\ c, & \text{otherwise,} \end{cases}\qquad\qquad(2) \]- 其中 \(c\) 是一个任意实数。
与交叉熵中的最优解相比,标签感知平滑鼓励有限的输出,更加一般化,并且可以缓解过拟合。
-
-
相关函数(related function):
-
我们假设长尾数据集中的标签是按照实例数量降序分配的,即 $N_1\ge N_2\ge\cdots\ge N_K $。因为头部类别包含更多样化的示例,所以预测概率比尾类更有希望。
-
因此,我们要求实例数量较大的类别使用更强的标签平滑因子——即相关函数 \(f(N_y)\) 应该与 \(N_y\) 负相关。我们定义了三种相关函数 \(f(N_y)\) 如下:
-
凹形式(Concave form):
\[f(N_y)=\epsilon_K+(\epsilon_1-\epsilon_K)\sin\left[\frac{\pi\left(N_y-N_K\right)}{2(N_1 - N_K)}\right];\qquad(3.a) \] -
线性形式(Linear form):
\[f(N_y)=\epsilon_K+(\epsilon_1-\epsilon_K)\frac{N_y-N_K}{N_1-N_K}\qquad; (3.b) \] -
凸形式(Convex form):
\[f(N_y)=\epsilon_1+(\epsilon_1-\epsilon_K)\sin\left[\frac{3\pi}{2}+\frac{\pi\left(N_y-N_K\right)}{2(N_1-N_K)}\right];\qquad(3.c) \] -
参数字典:
其中 \(\epsilon_1\) 和 \(\epsilon_K\) 是两个超参数。
-
-
这些函数的说明在图 6 中展示。如果我们将 \(\epsilon_1\ge\epsilon_K\),则得到 \(\epsilon_1 \ge\epsilon_2 \ge\cdots\ge\epsilon_K\)。对于类别 \(y\) 的大实例数量 \(N_y\),标签感知平滑分配了一个强平滑因子。它降低了拟合概率,缓解过度自信,因为头部和中部类别比尾类别更容易过度自信(见图3)。
-
-
-
特定的通用分类器学习框架:
-
由于标签感知平滑(label-aware smoothing)的形式比交叉熵(cross-entropy)更复杂,我们提出了一种通用的分类器学习框架来适应它。
-
相关工作回顾:
在这里,我们快速回顾一下 cRT 和 LWS。
- cRT 学习一个包含 \(K\ M\) 个可学习参数的分类器权重,而 LWS 则限制于学习一个只有K个可学习参数的权重缩放向量 \(s\in\R^K\)。
- 相比之下,cRT 具有更多的可学习参数和更强的表示能力。LWS 倾向于在大型数据集上获得更好的验证损失和性能(请参阅[15]中的实验部分)。因此,LWS 具有更好的泛化性质。
-
分类器框架:
为了结合 cRT 和 LWS 的优势,我们在第二阶段设计了分类器框架如下:
\[z=\text{diag}(\boldsymbol{s}) (r\boldsymbol{W}+\boldsymbol{\Delta W})^\top x.\qquad\qquad(4) \]- 在等式(4)中,我们在第二阶段固定了原始分类器权重 \(\boldsymbol{W}\)。
- 如果我们使可学习的缩放向量 \(\boldsymbol{s}\) 固定,设置 \(\boldsymbol{s}=1\) 和保留因子 \(r=0\),并且只学习新的分类器权重 \(\boldsymbol{\Delta W}\in\R^{M\times K}\),等式(4)将退化为 cRT。
- 因为 LWS 固定了原始分类器权重 \(\boldsymbol{W}\) 并只学习缩放 \(\boldsymbol{s}\),如果我们设置 \(r=1\) 和 \(\boldsymbol{\Delta W}=0\),等式(4)将退化为 LWS。
- 在大多数情况下,LWS 在大型数据集上取得了更好的结果。因此,我们使 \(\boldsymbol{s}\) 可学习并设置 \(r=1\)。
- 我们还使 \(\boldsymbol{\Delta W}\) 可学习,以提高表示能力并使用不同的学习率来优化 \(\boldsymbol{\Delta W}\)。
- \(\boldsymbol{\Delta W}\) 可以被视为 \(\boldsymbol{W}\) 上权重向量 \(\boldsymbol{w}\) 的位移变换。它改变了 \(\boldsymbol{W}\) 中权重向量 \(\boldsymbol{w}\) 的方向,这是 LWS 无法实现的。
-
3.3.Shift Learning on Batch Normalization
批量归一化移位学习
-
概述:
- 在两阶段训练框架中,模型首先在第一阶段使用实例平衡采样进行训练,然后在第二阶段使用类别平衡采样进行训练。
- 由于该框架涉及两个采样器,或者两个数据集——实例平衡数据集 \(\mathcal{D}_I\) 和类别平衡数据集 \(\mathcal{D}_C\),我们将这个两阶段训练框架视为迁移学习的一种变体。
- 如果我们从迁移学习的角度来看待这个两阶段解耦训练框架,固定主干部分并在第二阶段仅调整分类器显然是不合理的,尤其是对于批量归一化(batch normalization,BN)层。
-
均值/方差分析:
具体来说,我们假设网络的输入是 \(x_i\),某个批量归一化(BN)层的输入特征是 \(g(x_i)\),且迷你批次的大小是 \(m\)。这两个阶段中,通道 \(j\) 的均值和运行方差分别为:
-
对于第一阶段(实例平衡采样):
\[\begin{align} &\boldsymbol{x}_i\sim P_{\mathcal{D}_I}(\boldsymbol{x},y),\quad\boldsymbol{\mu}^{(j)}_I=\frac{1}{m}\sum_{i=1}^m g(\boldsymbol{x}_i)^j,\\ &\boldsymbol{\sigma}^{2(j)}_I=\frac{1}m\sum_{i=1}^m[g(\boldsymbol{x}_i)^{(j)}-\boldsymbol{\mu}^{(j)}_I]^2\qquad\qquad(5) \end{align} \] -
对于第二阶段(类别平衡采样):
\[\begin{align} &\boldsymbol{x}_i\sim P_{\mathcal{D}_C}(\boldsymbol{x},y),\quad\boldsymbol{\mu}^{(j)}_C=\frac{1}{m}\sum_{i=1}^m g(\boldsymbol{x}_i)^j,\\ &\boldsymbol{\sigma}^{2(j)}_C=\frac{1}m\sum_{i=1}^m[g(\boldsymbol{x}_i)^{(j)}-\boldsymbol{\mu}^{(j)}_C]^2\qquad\qquad(6) \end{align} \]
-
-
分析与解决:
- 由于不同的采样策略,头部、中部和尾部类别的组成比例也不同,这导致 \(P_{\mathcal{D}_I}(\boldsymbol{x},y)\ne P_{\mathcal{D}_C}(\boldsymbol{x},y)\)。通过等式(5)和(6),在两种采样策略下均值 \(\boldsymbol{\mu}\) 和方差 \(\boldsymbol{\sigma}\) 存在偏差,即 \(\boldsymbol{\mu}_I\ne\boldsymbol{\mu}_C\) 和 \(\boldsymbol{\sigma}^2_I\ne\boldsymbol{\sigma}^2_C\)。因此,对于解耦框架来说,BN 在两个具有不同采样策略的数据集之间共享均值和方差是不可行的。
- 受到 AdaBN 和 TransNorm 的启发,我们在第二阶段更新运行均值 \(\boldsymbol{\mu}\) 和方差 \(σ\),同时固定可学习的线性变换参数 \(\alpha\) 和 \(\beta\),以实现更好的标准化。
Section 4 Experiments
4.1.Datasets and Setup
我们的实验设置,包括实现细节和评估协议,主要遵循[4]用于 CIFAR10-LT 和 CIFAR-100-LT,以及[15]用于 ImageNet-LT、PlacesLT 和 iNaturalist 2018。更多有关训练和超参数设置的详细信息,请参见附录A。
4.1.1 Datasets Explanation
-
CIFAR-10 和 CIFAR-100
- CIFAR-10 和 CIFAR-100 都包含 60,000 张图像,其中 50,000 张用于训练,10,000 张用于验证,分别有 10 个类别和 100 个类别。
- 为了公平比较,我们使用与[4]中相同设置的长尾版本的 CIFAR 数据集。这是通过控制数据不平衡的程度,使用不平衡因子 \(\beta=\frac{\boldsymbol{N}_\max}{\boldsymbol{N}_\min}\),其中 \(\boldsymbol{N}_\max\) 和 \(\boldsymbol{N}_\min\) 是最多和最少频繁类别的训练样本数量。
- 遵循 Cao 等人[4]和Zhou等人[39]的方法,我们进行了 IF 为100、50 和 10 的实验。
-
ImageNet-LT 和 Places-LT
- ImageNet-LT 和 Places-LT 是由 Liu 等人提出的。ImageNet-LT 是大规模物体分类数据集 ImageNet 的长尾版本,通过遵循帕累托分布(Pareto distribution)采样一个子集,幂值 \(\alpha=6\)。它包含来自 1,000 个类别的 115.8 K 张图像,类别的基数从 5 到 1,280 不等。
- Places-LT 是大规模场景分类数据集 Places 的长尾版本。它由来自 365 个类别的 184.5 K 张图像组成,类别的基数从 5 到 4,980 不等。
-
iNaturalist 2018
iNaturalist 2018 是一个大规模的分类数据集,并且遭受极其不平衡的标签分布。它由来自 8,142 个类别的 437.5 K 张图像组成。此外,在 iNaturalist 2018 数据集上,我们还面临着细粒度问题。
4.1.2 Implementation Details
实现细节
- 对于所有实验,我们使用带有动量 0.9 的 SGD 优化器来优化网络。
- 对于 CIFAR-LT,
- 我们主要遵循 Cao 等人的方法。我们在一个 GPU 上训练所有 MiSLAS 模型,并使用多步学习率计划,在第一阶段的 160 个和 180 个周期时将学习率降低 0.1。
- 对于 ImageNetLT、Places-LT 和 iNaturalist 2018,
- 我们主要遵循 Kang 等人的方法,并使用余弦学习率计划来训练所有 MiSLAS 模型,后端网络分别为 ResNet-10、50、101 和 152,在四个 GPU 上进行训练。
4.2.Ablation Study
-
校准性能(Calibration performance):
-
在这里,我们在图 4 中展示了我们的方法在 CIFAR-100-LT 上 IF 为 100 的 15 个箱子的可靠性图。与图 1 相比,mixup 和标签感知平滑不仅可以大大提高网络的校准性能(即使是低于平衡数据集的 ECE),还可以大大提高长尾识别的性能。
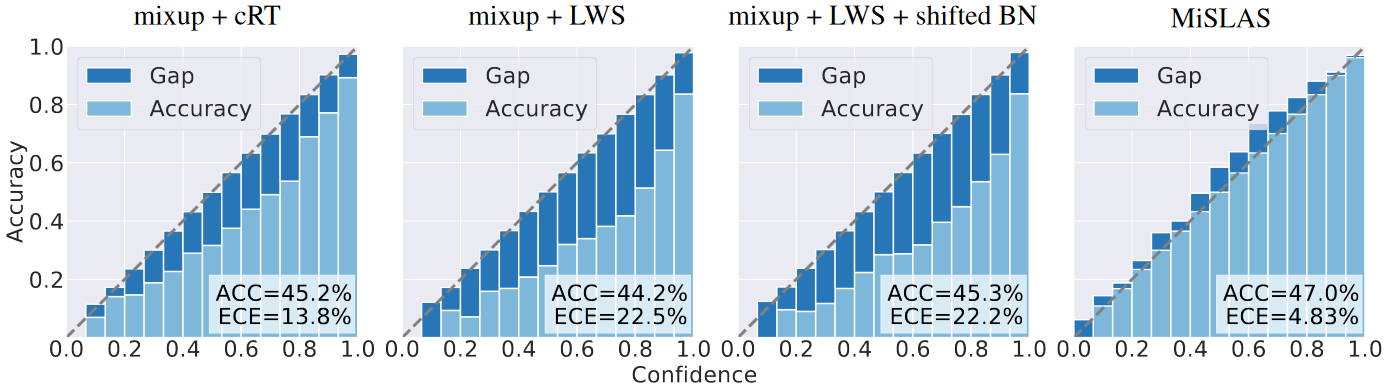
- 图片注解:图 4 展示了在 CIFAR-100-LT 上 IF 为 100 的 ResNet-32 模型的可靠性图。从左至右依次为:使用 mixup 的 cRT、使用 mixup 的 LWS、使用 mixup 和 移位 BN 的 LWS,以及 MiSLAS(符合图 1 的设置)。
-
类似的趋势也可以在 CIFAR-10-LT、ImageNet-LT 和 Places-LT 上观察到(具体细节请参见表 1 和附录 C 中的图),这证明了所提出方法在校准方面的有效性。
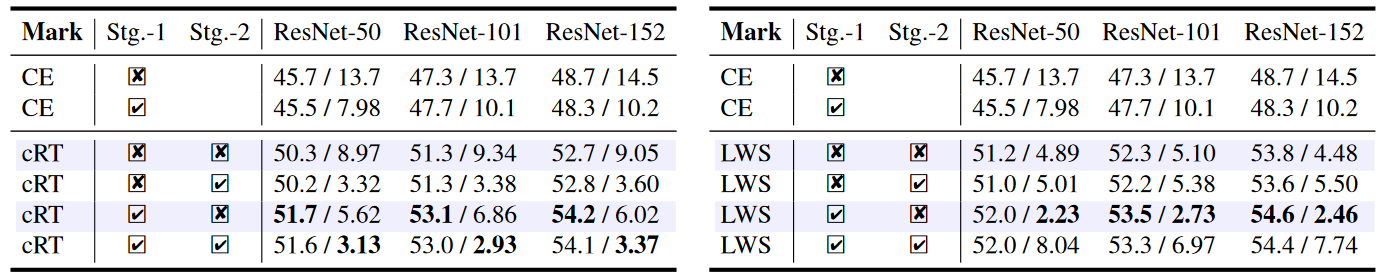
- 图片注解:表 1 展示了在 ImageNet-LT 数据集上训练的 ResNet 系列模型的普通交叉熵(CE)模型,以及 cRT(左)和 LWS(右)解耦模型的 Top-1 准确率(%)和 ECE(%)。我们在两个阶段上变化增强策略,包括使用 \(\alpha=0.2\)(\(\checkmark\))或不使用(\(\times\))mixup。
-
所有实验结果表明,在非平衡数据集上训练网络会导致严重的过度自信。由于传统的 mixup 和标签平滑都包含了软化地面真实标签(softening the ground truth labels)的操作,这可能表明,使用硬标签进行训练可能是导致网络过度自信的另一个促成因素。
-
-
比较标签感知平滑与重加权(re-weighting with label-aware smoothing):
在这里,我们比较了提出的标签感知平滑(LAS)与重加权方法。
-
主要的区别在于标签转换。特别是,标签感知平滑根据标签分布将硬标签转换为软版本(参见等式(1)的其他情况:\(\boldsymbol{q}_i=\frac{f(\boldsymbol{N}_y)}{(K−1)},\ i\ne y\))。而重加权方法不包含这种关键转换,只是通过 \(\boldsymbol{q}_i=0,i\ne y\) 将值设置为零。
-
此外,由于标签的转换,LAS 中 \(w^{∗\top}_i\boldsymbol{x}\) 的最优解变成了等式(2)。相比之下,重加权的最优解与交叉熵相同,即 \(w^{∗\top}_i\boldsymbol{x}=\inf\),这无法适当改变预测分布并导致过度自信。
-
根据我们在表 2 中的实验结果,在第二阶段使用重加权方法会比使用LAS的情况降低性能和校准。
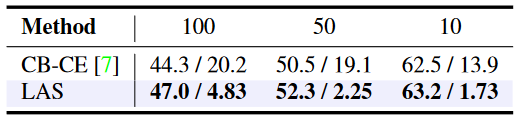
- 图片注解:表 2 展示了标签感知平滑(LAS)与重加权方法在第二阶段基于类平衡交叉熵(CB-CE)的测试准确率(%)/ ECE(%)的比较。两个模型都基于 ResNet-32,并在 CIFAR-100-LT 上进行了训练,不平衡因子(IF)为 100、50 和 10。
-
-
\(\epsilon_1\) 和 \(\epsilon_K\) 如何影响标签感知平滑?
-
在我们的标签感知平滑中,等式(3.a)、(3.b)和(3.c)中有两个超参数。它们是 \(\epsilon_1\) 和 \(\epsilon_K\),它们控制类别的惩罚。
-
在一个识别系统中,如果类别 \(y\) 的预测概率大于 0.5,分类器会将输入分类为类别 \(y\)。因此,为了使其合理,我们限制 \(0\le\epsilon_1\le\epsilon_K\le0.5\)。
-
在这里,我们在 CIFAR-10-LT 上进行了实验,IF 为 100,并变化了 \(\epsilon_1\) 和 \(\epsilon_K\) 都在 0.0 到 0.5 之间。我们绘制了所有可能变体的性能矩阵,以 \(\epsilon_1\) 和 \(\epsilon_K\) 为横纵坐标,如图 5 所示。
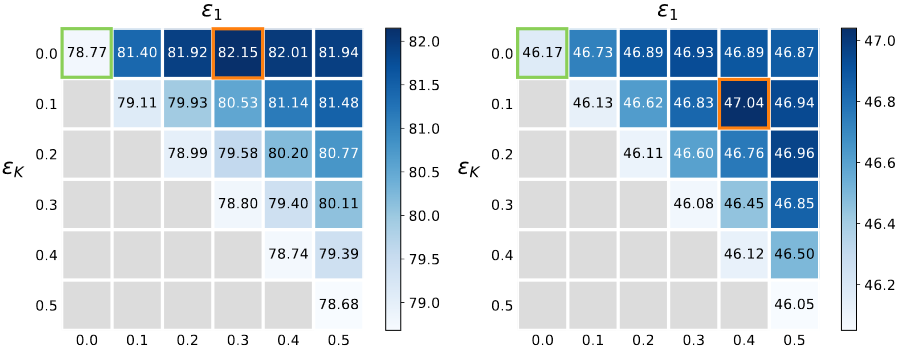
- 图片注解:标签感知平滑中两个超参数 \(\epsilon_1\) 和 \(\epsilon_K\) 的消融研究。热图可视化在 CIFAR-10-LT(左)和 CIFAR100-LT(右)上,IF 为 100 的情况。
-
结果显示,
- 当我们选择 \(\epsilon_1=0.3\) 和 \(\epsilon_K=0.0\) (橙色方块)进行标签感知平滑时,与传统的交叉熵(绿色方块, \(\epsilon_1=0\) 和 \(\epsilon_K=0\) )相比,分类准确率提高了 3.3%。
- 当选择 \(\epsilon_1=0.4\) 和 \(\epsilon_K=0.1\) 进行标签感知平滑时,在 CIFAR-100-LT 上,IF 为 100,一致地提高了 0.9% 的准确率。
-
-
\(f(\cdot)\) 如何影响标签感知平滑?
-
正如第 3.2 节讨论的,相关函数 \(f(\cdot)\) 对于最终模型性能可能发挥重要作用。我们在图 6 中绘制了等式(3.a)、(3.b)和(3.c)的说明。
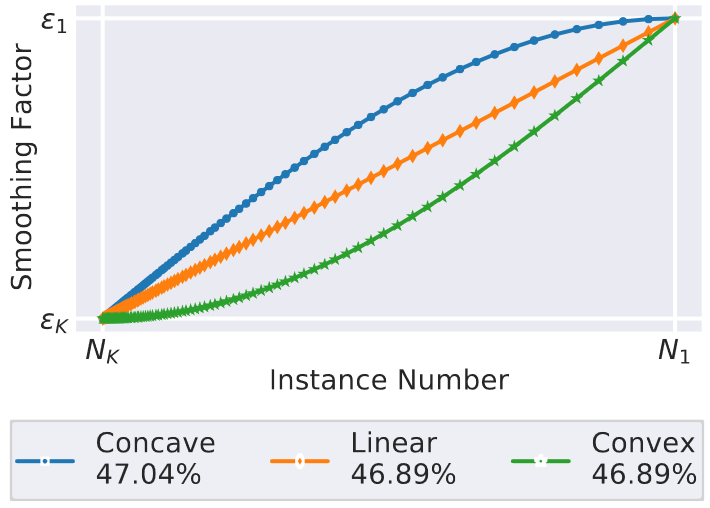
- 图片注解:函数说明以及等式(3.a)、(3.b)和(3.c)的测试性能。凹形式取得了最佳结果。
-
对于 CIFAR-100-LT,IF 为 100,我们设置 \(K=100\),\(N_1=500\),\(N_{100}=5\)。基于上述关于 \(\epsilon_1\) 和 \(\epsilon_K\) 的消融研究结果,我们在这里设置 \(\epsilon_1=0.4\) 和 \(\epsilon_{100}=0.1\)。
-
在第二阶段的第 10 个周期调整后,凹模型(convex model)的准确率最佳。
-
我们还探索了其他形式,例如 \(f(\cdot)\) 的指数形式,具体见附录 B。与改变 \(\epsilon_1\) 和 \(\epsilon_K\) 相比,改变形式带来的收益非常有限。
-
-
标签感知平滑(label-aware smoothing)如何影响预测分布?
- 为了可视化预测概率分布的变化,我们在 CIFAR-100-LT 上 IF 为 100 训练了两个 LWS 模型,一个使用交叉熵,另一个使用标签感知平滑。
- 交叉熵基础的头部、中部和尾部类别的分布显示在图 3 上方的浅蓝色部分。基于标签感知平滑的分布显示在下半部分的深蓝色中。
- 我们观察到,使用标签感知平滑时,头部和中部类别的过度自信大大减少,尾部类别的整个分布略有向右移动。这些经验结果与我们在第 3.2 节的分析一致。
-
进一步分析移位学习(shift learning):
在这一部分,我们进行了实验来展示在 BN 上进行移位学习的效果和适用性。
-
我们在 CIFAR100-LT 上 IF 为 100 训练了 LWS 模型。
-
在第二阶段的 10 个周期微调后,使用 BN 移位的模型达到了 45.3% 的准确率,比不使用 BN 移位的模型高出 1.1%。
-
我们还可视化了 BN 的变化。如图 7 所示,使用不同采样策略的数据集之间存在 \(\mu\) 和 \(\sigma^2\) 的偏差。
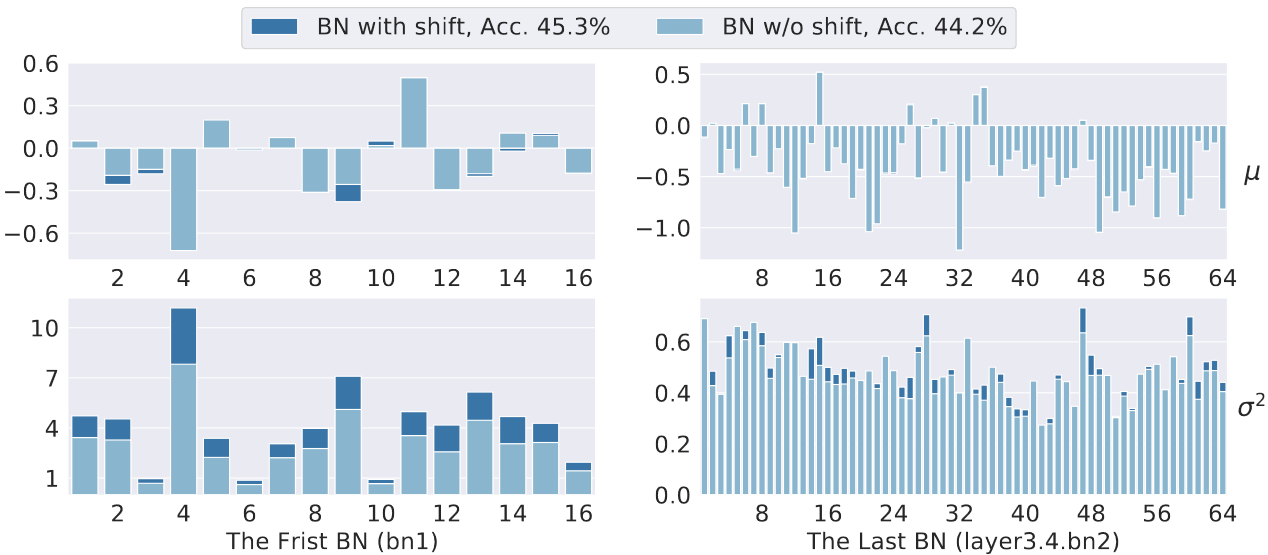
- 图片注解:展示了 BN 中运行均值 \(\mu\) 和方差 \(\sigma^2\) 的变化的可视化。该图基于在 CIFAR-100-LT 上 IF 为 100 训练的 ResNet-32 模型。
- 左图显示了 ResNet-32 中的第一个 BN 层,该层包含 16 个通道的 \(\mu\) 和 \(\sigma^2\)。
- 右图显示了 ResNet-32 中的最后一个 BN 层,该层包含 64 个通道的 \(\mu\) 和 \(\sigma^2\)
- 图片注解:展示了 BN 中运行均值 \(\mu\) 和方差 \(\sigma^2\) 的变化的可视化。该图基于在 CIFAR-100-LT 上 IF 为 100 训练的 ResNet-32 模型。
-
由于头部、中部和尾部类别的组成比例不同,统计均值 \(\mu\) 和方差 \(\sigma^2\) 也会变化。我们还在图 7 中注意到了一些有趣的现象:
- 方差 \(\sigma^2\) 的变化大于均值 \(\mu\) 的变化。
- 深层 BN 层中的 \(\mu\) 和 \(\sigma^2\) 的变化远小于浅层 BN 层。
-
-
总结:
-
总体而言,表 3 展示了关于 mixup(在第一阶段添加 mixup,MU)、批量归一化上的移位学习(SL)和标签感知平滑(LAS)的消融研究。
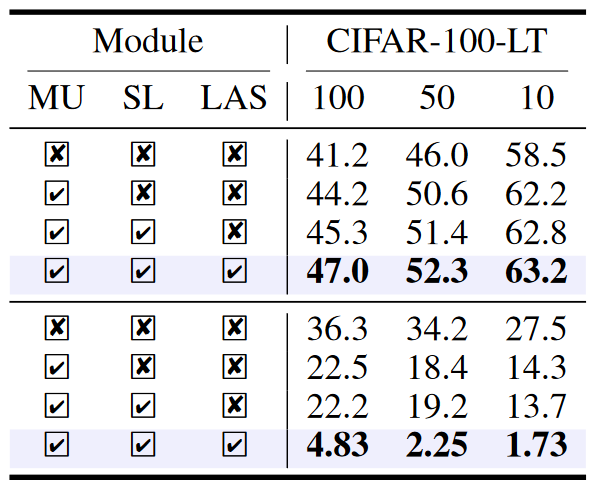
- 图片注解:表 3 展示了所有提出的模块在 CIFAR-100-LT 上的消融研究。顶部是准确率(%),底部是ECE(%)。
- MU:仅在第一阶段应用 mixup。
- SL:在 BN 上进行移位学习。
- LAS:标签感知平滑。
- 图片注解:表 3 展示了所有提出的模块在 CIFAR-100-LT 上的消融研究。顶部是准确率(%),底部是ECE(%)。
-
我们注意到,每个提出的模块不仅提高了准确率(表 3 顶部),而且显著减轻了在 CIFAR-100LT 上的过度自信问题(表 3 底部),对于所有常用的不平衡因子,即 100、50 和 10都是如此。这充分证明了它们的有效性。
-
4.3.Comparison with State-of-the-arts
与最先进技术的比较
-
为了验证有效性,我们将所提出的方法与之前的一阶段方法 Range Loss,LDAM Loss,FSLwF 和 OLTR 进行比较,并与之前的两阶段方法进行比较,包括 DRS-like、DRWlike,LFME,cRT 和 LWS。为了公平比较,我们在 LWS 和 cRT 模型上添加了 mixup。Remix 是一种最近提出的用于长尾识别的增强方法。由于 BBN具有双重采样器和以类似 mixup 的方式进行训练,我们直接将我们的方法与它进行比较。
-
CIFAR-LT 的实验结果
我们在 CIFAR-10-LT 和 CIFAR-100-LT 上进行了大量实验,不平衡因子分别为 100、50 和 10,使用与之前工作[4, 39]相同的设置。结果总结在表 4 中。与之前的方法相比,我们的 MiSLAS 在 top-1 准确率和 ECE 方面都明显优于所有之前的方法,并且这种优势在所有不平衡因子(即 100、50 和 10)上都是成立的,无论是在 CIFAR-10-LT 还是 CIFAR-100-LT 上。

- 图片注解:表 4 展示了基于 ResNet-32 的模型在 CIFAR-10-LT 和 CIFAR-100-LT 上的训练结果,包括 Top-1 准确率(%)和ECE(%)。
-
大规模数据集的实验结果
我们进一步在三个大规模不平衡数据集上验证了我们方法的有效性,即 ImageNet-LT、iNaturalist2018和Places-LT。表 5 列出了在 ImageNet-LT(左)、iNaturalist 2018(中)和 Places-LT(右)上的实验结果。值得注意的是,我们的 MiSLAS 超越了其他方法,并在几乎所有三个大规模长尾基准数据集上都取得了更好的准确性和置信度校准,从而设定了新的最先进水平。关于这三个数据集上的拆分类别准确率和不同主干网络的更多结果列在附录 D 中。
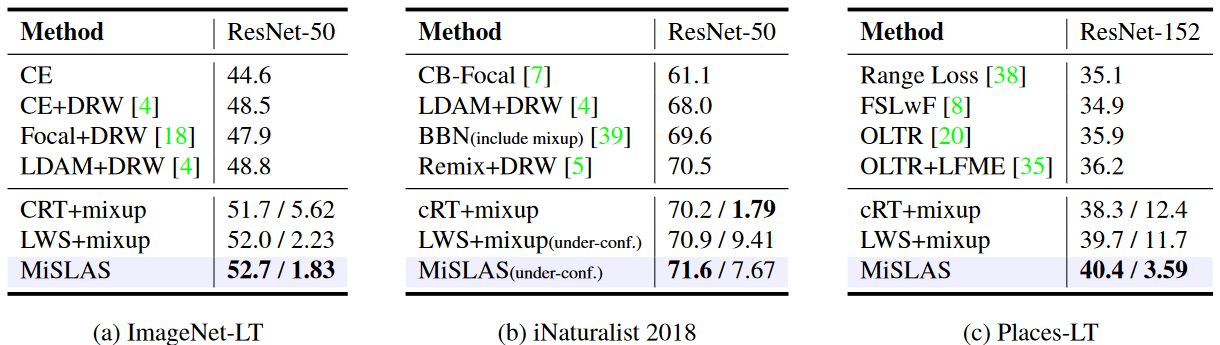
- 图片注解:表 5 展示了在 ImageNet-LT(左)、iNaturalist 2018(中)和 Places-LT(右)上的 Top-1 准确率(%)和 ECE(%)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号