


Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
源码下载链接:
https://files.cnblogs.com/files/Ambitious-LQF/%E5%89%8D%E7%A8%8B%E6%97%A0%E5%BF%A7%E7%88%AC%E8%99%AB.zip
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取前程无忧招聘信息
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
本爬虫主要是爬取岗位名称、公司名称、工作地点、薪资以及岗位发布时间。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本方案是利用requests库对目标页面进行爬取,而后再利用BeautifulSoup库对相关信息进行数据清洗,最后使用pandas库将爬取到的数据存储在xls文件中,并打印文件的前5行。主要的难点是数据清洗这一块,由于想要的数据在同级标签上,所以要多几个数据分析函数。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
以北京的python工作岗位为例,他的url链接如下:

我们可以看出我们想要的目标城市代码、所输入的工作岗位所在的位置以及页码,接下来我们只要对这三个位置进行修改即可。
2.Htmls页面解析
2.Htmls页面解析
页面部分源代码如下图所示:

从图中我们可以看出:每个岗位信息都是存放在属性为class="el"的div标签中,由于还有其他标签中也含有e1两个字符,所有我选取了属性为class="t1"的p标签,以及属性为class="t2"到"t5"的span标签。接下来只要对这些标签进行处理即可。
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
根据上面所分析的特征,我使用find_all()方法进行特定标签查找。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
程序代码如下:
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 import numpy as np 5 import os 6 7 8 9 #爬取前程无忧目标的HTML页面 10 def getHTMLText(url): 11 try: 12 #获取目标页面 13 r = requests.get(url) 14 #判断页面是否链接成功 15 r.raise_for_status() 16 #使用HTML页面内容中分析出的响应内容编码方式 17 r.encoding = r.apparent_encoding 18 #返回页面内容 19 return r.text 20 except: 21 #如果爬取失败,返回“爬取失败” 22 return "爬取失败" 23 24 #获取岗位名称 25 def getJobsName(ulist,html): 26 #创建BeautifulSoup对象 27 soup = BeautifulSoup(html,"html.parser") 28 #遍历所有属性为t1的p标签 29 for p in soup.find_all("p",attrs = "t1"): 30 #将p标签中的a标签中的内容存放在ulist列表中 31 ulist.append(str(p.a.string).strip()) 32 #返回列表 33 return ulist 34 35 #获取公司名称 36 def getCompanyName(ulist,html): 37 soup = BeautifulSoup(html,"html.parser") 38 #遍历所有属性为t2的span标签 39 for span in soup.find_all("span",attrs = "t2"): 40 #将span标签中的内容存放在ulist列表中 41 ulist.append(str(span.string).strip()) 42 #删除列表的第0个元素 43 ulist.pop(0) 44 return ulist 45 46 #获取工作地点 47 def getWorkingPlace(ulist,html): 48 soup = BeautifulSoup(html,"html.parser") 49 #遍历所有属性为t3的span标签 50 for span in soup.find_all("span",attrs = "t3"): 51 #将span标签中的内容存放在ulist列表中 52 ulist.append(str(span.string).strip()) 53 #删除列表的第0个元素 54 ulist.pop(0) 55 return ulist 56 57 #获取薪资 58 def getSalary(ulist,html): 59 soup = BeautifulSoup(html,"html.parser") 60 #遍历所有属性为t4的span标签 61 for span in soup.find_all("span",attrs = "t4"): 62 #将span标签中的内容存放在ulist列表中 63 ulist.append(str(span.string).strip()) 64 ulist.pop(0) 65 return ulist 66 67 #获取发布时间 68 def getReleaseTime(ulist,html): 69 soup = BeautifulSoup(html,"html.parser") 70 #遍历所有属性为t5的span标签 71 for span in soup.find_all("span",attrs = "t5"): 72 #将span标签中的内容存放在ulist列表中 73 ulist.append(str(span.string).strip()) 74 ulist.pop(0) 75 return ulist 76 77 #使用pandas进行数据存储、读取 78 def pdSaveRead(jobName,comnayName,workingPlace,salary,releaseTime): 79 try: 80 #创建文件夹 81 os.mkdir("D:\招聘信息") 82 except: 83 #如果文件夹存在则什么也不做 84 "" 85 #创建numpy数组 86 r = np.array([jobName,comnayName,workingPlace,salary,releaseTime]) 87 #columns(列)名 88 columns_title = ['岗位','公司名称','工作地点','薪资','发布时间'] 89 #创建DataFrame数据帧 90 df = pd.DataFrame(r.T,columns = columns_title) 91 #将数据存在Excel表中 92 df.to_excel('D:\招聘信息\岗位信息.xls',columns = columns_title) 93 94 #读取表中岗位信息 95 dfr = pd.read_excel('D:\招聘信息\岗位信息.xls') 96 print(dfr.head()) 97 98 99 #主函数 100 def main(): 101 #前程无忧招聘网 102 url = "https://search.51job.com/list/" 103 #目标城市代码的字典 104 citys = {"全国":"000000","北京":"010000","阿坝":"092200","阿克苏":"310600","阿拉尔":"310900","阿拉善盟":"281500","阿勒泰":"311300", 105 "鞍山":"230400","安康":"201000","安庆":"150400","安顺":"260500","安阳":"170900","巴彦淖尔":"280900","巴音郭楞":"311800", 106 "巴中":"092000","白城":"24100","白沙":"101800","白山":"240900","白银":"270800","百色":"141100","蚌埠":"150600","包头":"280400", 107 "保定":"160400","保山":"251200","保亭":"101700","宝鸡":"200400","北海":"140500","本溪":"231000","毕节":"260700","滨州":"121500", 108 "博尔塔拉":"311900","亳州":"151800","沧州":"160800","昌都":"300600","昌吉":"311200","昌江":"101900","常德":"190700","常熟":"070700", 109 "常州":"070500","长春":"240200","长沙":"190200","长治":"210600","朝阳":"231400","潮州":"032000","郴州":"190900","成都":"090200", 110 "澄迈":"101300","承德":"161000","池州":"151500","赤峰":"280300","崇左":"141400","滁州":"150900","楚雄":"251700","重庆":"060000", 111 "达州":"091700","大理":"250500","大连":"230300","大庆":"220500","大同":"210400","大兴安岭":"221400","丹东":"230800","丹阳":"072100", 112 "德宏":"251600","德阳":"090600","德州":"121300","邓州":"172000","迪庆":"252000","定安":"101100","定西":"271100","东方":"100900", 113 "东营":"121000","东莞":"030800","儋州":"100800","鄂尔多斯":"280800","鄂州":"181000","恩施":"181800","防城港":"140800","佛山":"030600", 114 "福州":"110200","抚顺":"230600","抚州":"131100","阜新":"231500","阜阳":"150700","甘南":"271500","甘孜":"092100","赣州":"130800", 115 "固原":"290600","广安":"091300","广元":"091600","广州":"030200","桂林":"140300","贵港":"141000","贵阳":"260200","果洛":"320800", 116 "哈尔滨":"220200","哈密":"310700","海北":"320500","海东":"320300","海口":"100200","海南":"320700","海宁":"081600","海西":"320400", 117 "邯郸":"160700","汉中":"200900","杭州":"080200","菏泽":"121400","和田":"311600","合肥":"150200","河池":"141200","河源":"032100", 118 "鹤壁":"171700","鹤岗":"221000","贺州":"141500","黑河":"221200","衡水":"161200","衡阳":"190500","红河州":"251000","呼和浩特":"280200", 119 "呼伦贝尔":"281100","葫芦岛":"230900","湖州":"080900","怀化":"191100","淮安":"071900","淮北":"151700","淮南":"151100","黄冈":"181100", 120 "黄南":"320600","黄山":"151000","黄石":"180400","惠州":"030300","鸡西":"220900","吉安":"130900","吉林":"240300","济南":"120200", 121 "济宁":"120900","济源":"171900","嘉兴":"080700","嘉峪关":"270400","佳木斯":"220800","江门":"031500","焦作":"170500","揭阳":"032200", 122 "金昌":"270300","金华":"080600","锦州":"230700","晋城":"210700","晋中":"211000","荆门":"180800","荆州":"180700","景德镇":"130400", 123 "靖江":"072500","九江":"130300","酒泉":"270500","喀什地区":"310400","开封":"170400","开平":"032700","克拉玛依":"310300","克孜勒苏柯尔克孜":"311700", 124 "昆明":"250200","昆山":"070600","拉萨":"300200","莱芜":"121800","来宾":"141300","兰州":"270200","廊坊":"160300","乐山":"090400", 125 "丽江":"250600","丽水":"081000","连云港":"071200","凉山":"092300","聊城":"121700","辽阳":"231100","辽源":"240400","林芝":"300400", 126 "临沧":"251800","临汾":"210500","临高":"101400","临夏":"271400","临沂":"120800","陵水":"102100","柳州":"140400","六安":"151200", 127 "六盘水":"260400","龙岩":"111000","陇南":"271200","娄底":"191200","吕梁":"211200","洛阳":"170300","泸州":"090500","漯河":"171500", 128 "马鞍山":"150500","茂名":"032300","梅州":"032600","眉山":"091200","绵阳":"090300", "牡丹江":"220700","那曲":"300700","南昌":"130200", 129 "南充":"091100","南京":"070200","南宁":"140200","南平":"110800","南通":"070900","南阳":"170600","内江":"090900","宁波":"080300", 130 "宁德":"110900","怒江":"251900","攀枝花":"091000","盘锦":"231300","萍乡":"130500","平顶山":"171000","平凉":"271000","莆田":"110600", 131 "普洱":"251100","濮阳":"171600","七台河":"221300","齐齐哈尔":"220600","黔东南":"260900","黔南":"261000","黔西南":"260800","潜江":"181500", 132 "钦州":"140900","秦皇岛":"160600","青岛":"120300","清远":"031900","庆阳":"271300","琼海":"100600","琼中":"101600","曲靖":"250300", 133 "泉州":"110400","衡州":"081200","日喀则":"300300","日照":"121200","三门峡":"171800","三明":"110700","三沙":"101500","三亚":"100300", 134 "山南":"300500","汕头":"030400","汕尾":"032400","商洛":"201100","商丘":"171300","上海":"020000","上饶":"131200","韶关":"031400", 135 "邵阳":"191000","绍兴":"080500","深圳":"040000","神农架":"181700","沈阳":"230200","十堰":"180600","石河子":"310800","石家庄":"160200", 136 "石嘴山":"290500","双鸭山":"221100","朔州":"210900","四平":"240600","松原":"240700","苏州":"070300","宿迁":"072000","宿州":"151600", 137 "随州":"181200","绥化":"220400","遂宁":"091500","塔城":"311500","台州":"080800","泰安":"121100","泰兴":"072300","泰州":"071800", 138 "太仓":"071600","太原":"210200","唐山":"160500","天津":"050000","天门":"181600","天水":"270600","铁岭":"231200","通化":"240500", 139 "通辽":"280700","铜川":"200500","铜陵":"150800","铜仁":"260600","图木舒克":"311100","吐鲁番":"311400","屯昌":"101200","万宁":"100700", 140 "威海":"120600","潍坊":"120500","渭南":"200700","温州":"080400","文昌":"100500","文山":"100500","乌海":"281000","乌兰察布":"281200", 141 "乌鲁木齐":"310200","无锡":"070400","芜湖":"150300","梧州":"140700","吴忠":"290300","武汉":"180200","武威":"270700","五家渠":"311000", 142 "五指山":"101000","西安":"200200","西昌":"091900","西宁":"320200","西双版纳":"251500","锡林郭勒盟":"281400","厦门":"110300","仙桃":"181400", 143 "咸宁":"181300","咸阳":"200300","襄阳":"180500","湘潭":"190400","湘西":"191500","孝感":"180900","新乡":"170700","新余":"130600", 144 "忻州":"211100","信阳":"171200","兴安盟":"281300","邢台":"161100","雄安新区":"160100","徐州":"071100","许昌":"171100","宣城":"151400", 145 "乐东":"102000","雅安":"091800","烟台":"120400","盐城":"071300","延安":"200600","延边":"241100","延吉":"240800","燕郊开发区":"161300", 146 "杨凌":"201200","扬州":"070800","杨浦经济开发区":"100400","阳江":"032800","阳泉":"210800","伊春":"220300","伊犁":"310500", 147 "宜宾":"090700","宜昌":"180300","宜春":"131000","义乌":"081400","益阳":"190800","银川":"290200","鹰潭":"130700","营口":"230500", 148 "永州":"191300","榆林":"200800","玉林":"140600","玉树":"320900","玉溪":"250400","岳阳":"190600","云浮":"032900","运城":"210300", 149 "枣庄":"121600","湛江":"031700","漳州":"110500","张家港":"071400","张家界":"191400","张家口":"160900","张掖":"270900","邵通":"251300", 150 "肇庆":"031800","镇江":"071000","郑州":"170200","中山":"030700","中卫":"290400","舟山":"081100","周口":"170800","珠海":"030500", 151 "株洲":"190300","驻马店":"171400","资阳":"091400","淄博":"120700","自贡":"090800","遵义":"260300"} 152 middle1 = ",000000,0000,00,9,99," 153 job = input("请输入工作岗位:") 154 middle2 = ",2," 155 last = ".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=" 156 city_name = input("请输入目标城市:") 157 city = citys[city_name] 158 159 #用来存放工作名称 160 jobName = [] 161 #用来存放公司名称 162 comnayName = [] 163 #用来存放工作地点 164 workingPlace = [] 165 #用来存放薪资 166 salary = [] 167 #用来存放发布时间 168 releaseTime = [] 169 170 #打印的页数加1 171 num = 11 172 #把第一页到第十页的招聘信息存放在相关的列表中 173 for page in range(1,num): 174 #组合成一个完整的链接 175 Url = url+city+middle1+job+middle2+str(page)+last 176 #获取目标链接的html页面 177 html = getHTMLText(Url) 178 179 #获取工作名称并存放在相关的列表中 180 getJobsName(jobName,html) 181 #获取公司名称并存放在相关的列表中 182 getCompanyName(comnayName,html) 183 #获取工作地点并存放在相关的列表中 184 getWorkingPlace(workingPlace,html) 185 #获取薪资并存放在相关的列表中 186 getSalary(salary,html) 187 #获取发布时间并存放在相关的列表中 188 getReleaseTime(releaseTime,html) 189 #数据存储 190 pdSaveRead(jobName,comnayName,workingPlace,salary,releaseTime) 191 192 193 #程序入口 194 if __name__ == "__main__": 195 main() 196 197 198
运行结果如下:

文件夹:
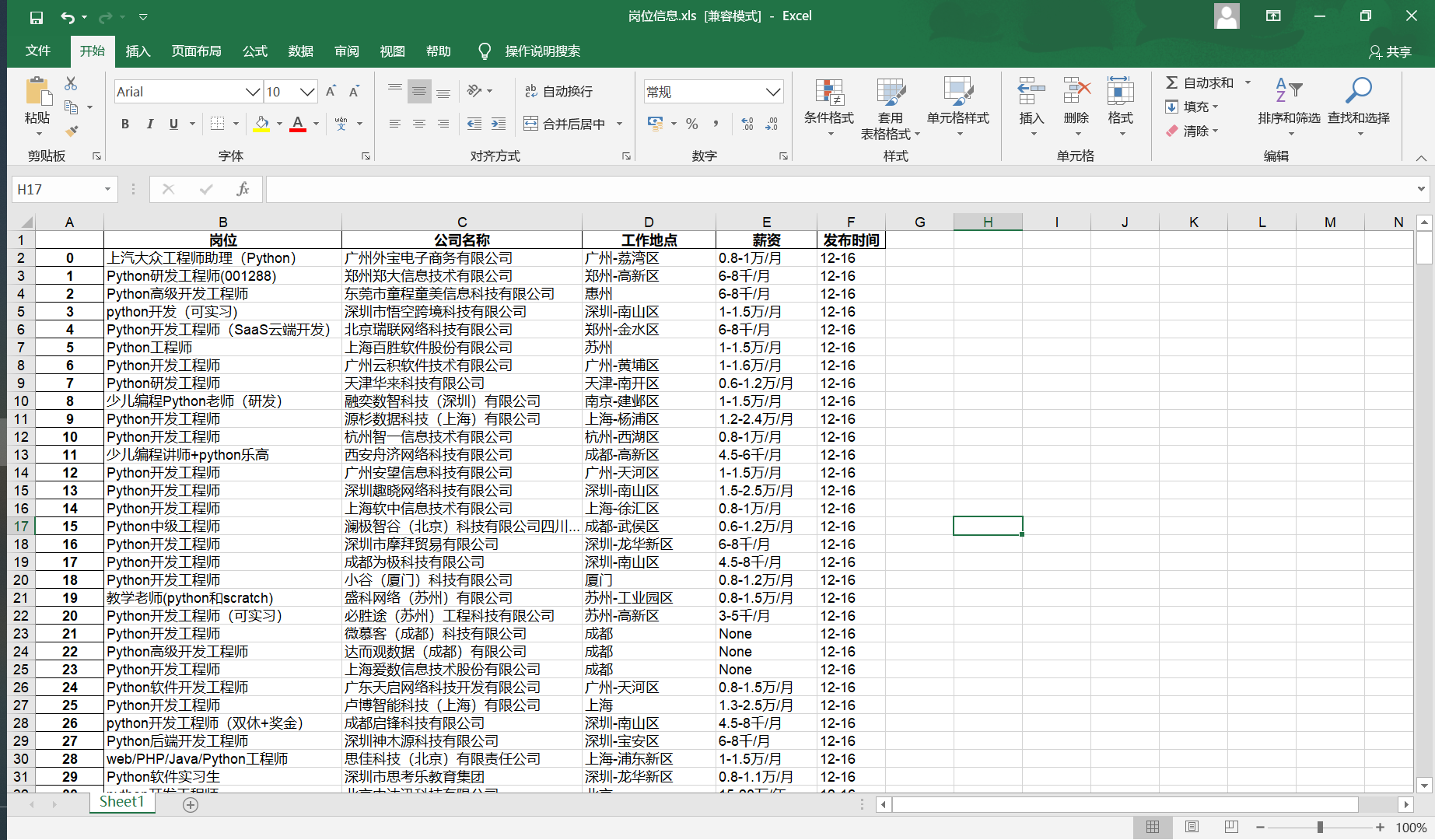
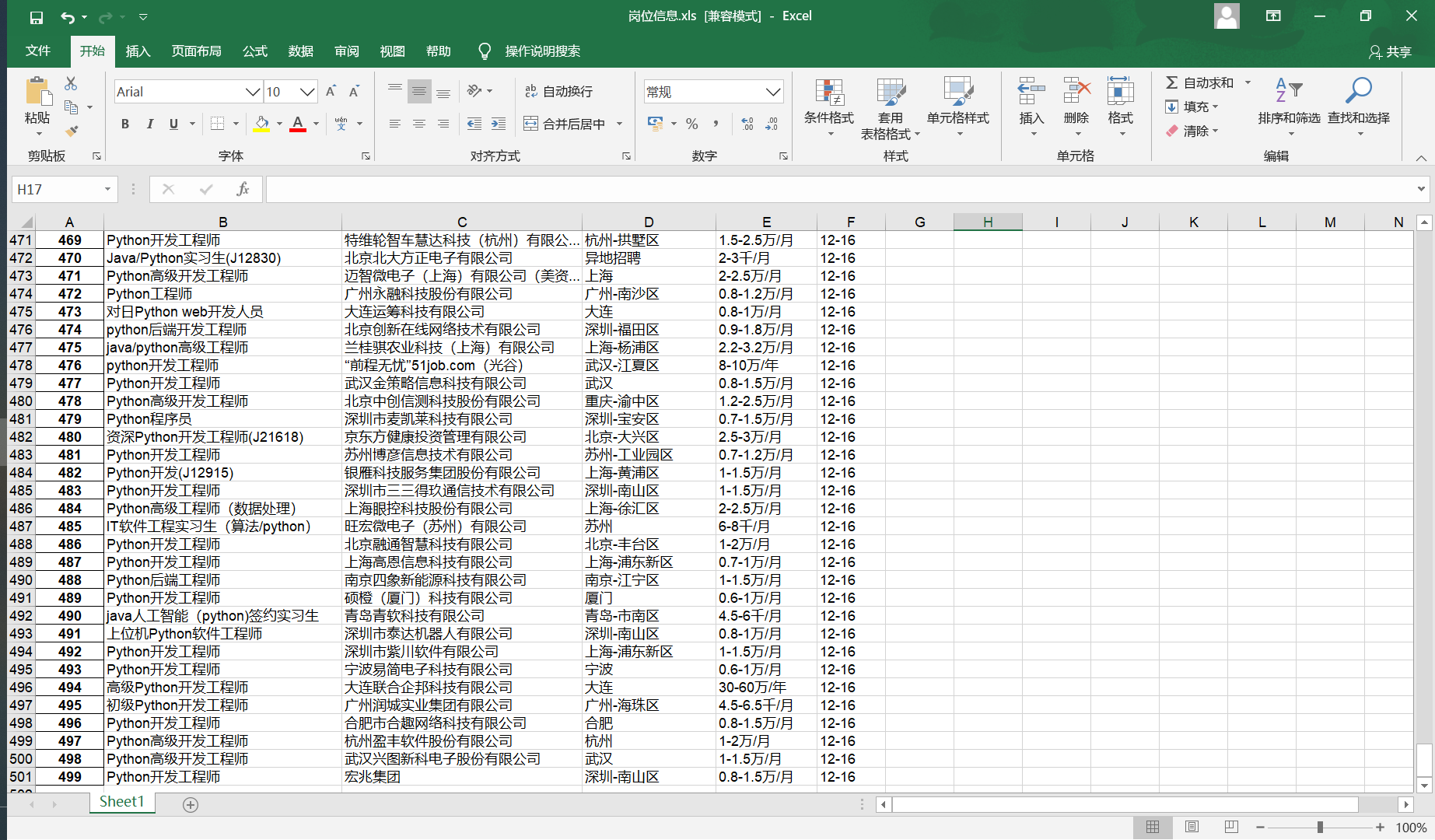
xls文件内容:
1.数据爬取与采集
使用requests库对目标页面进行爬取,相关代码如下:
#爬取前程无忧目标的HTML页面 def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
使用beautifulSoup库对爬取到的页面进行数据提取,具体代码如下:
#获取岗位名称 def getJobsName(ulist,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t1的p标签 for p in soup.find_all("p",attrs = "t1"): #将p标签中的a标签中的内容存放在ulist列表中 ulist.append(str(p.a.string).strip()) #返回列表 return ulist #获取公司名称 def getCompanyName(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t2的span标签 for span in soup.find_all("span",attrs = "t2"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist #获取工作地点 def getWorkingPlace(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t3的span标签 for span in soup.find_all("span",attrs = "t3"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist #获取薪资 def getSalary(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t4的span标签 for span in soup.find_all("span",attrs = "t4"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist #获取发布时间 def getReleaseTime(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t5的span标签 for span in soup.find_all("span",attrs = "t5"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist
5.数据持久化
使用pandas对数据进行存储,以便日后使用,相关模块代码如下:
#使用pandas进行数据存储、读取 def pdSaveRead(jobName,comnayName,workingPlace,salary,releaseTime): try: #创建文件夹 os.mkdir("D:\招聘信息") except: #如果文件夹存在则什么也不做 "" #创建numpy数组 r = np.array([jobName,comnayName,workingPlace,salary,releaseTime]) #columns(列)名 columns_title = ['岗位','公司名称','工作地点','薪资','发布时间'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel('D:\招聘信息\岗位信息.xls',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel('D:\招聘信息\岗位信息.xls') print(dfr.head())
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对主体数据的提取分析,可以直观的看出各城市相关岗位的薪资待遇、工作地点等信息。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
对于本次任务的自我要求基本实现,想要爬取的数据基本上都爬取下来了。理论结合实践,也进一步增加了自己的动手能力,发现自己存在的不足,并补缺补漏,水平也得到了一定的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号