第3次作业-卷积神经网络
【第一部分】 视频学习心得及问题总结
赵玉杨
本次的第一个视频重新讲了线性代数,概率等数学知识在神经网络中的运用,第二个视频讲了卷积神经网络的有关知识,先讲了卷积神经网络的相关概念,然后讲卷积神经网络的典型结构,其中包括Alex Net,VGG,Google net等网络结构,对这些结构有了一定的了解。
刘璐瑶
学习心得:
特征向量和秩的讲解思路很不一样,好神奇啊!这次学过概率了,能看懂的终于多了一点点TAT,似然函数取最大值来估算参数是因为,其为样本事件的理论概率,事件发生,那么取理论上发生概率最大的那个情况,因此可以使用极大似然策略对模型参数进行优化。
全连接网络的参数太多,容易过拟合,卷积神经网络通过滑动窗口并且参数共享的形式,解决前面的过拟合问题。卷积核(滤波器,可有多个不同的通道)作为滑动窗口对输入处理得到特征图,大小不匹配的时候可进行零填充,不同的卷积核关注不同信息,且浅层关注整体上的信息,深层更关注语义信息。池化可以通过某领域最大值、平均值的计算使之缩小,减少参数。
问题:
batchsize、epoch怎么确定应该定为多少呢?
柳贺然
学习心得:
卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少。
问题:
辅助分类器是怎样解决由于模型深度过深导致的梯度消失的问题?
谢廷宇
总结
卷积神经网络比传统神经网络多了卷积计算层、激励层、池化层、全连接层,主要通过卷积和池化来挖掘图片信息。
卷积是两个变量在某范围内相乘后求和的结果。数字图像是一个二维的离散信号,对数字图像做卷积操作其实就是利用卷积核在图像上滑动,将图像点上的像素灰度值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素的灰度值,并最终滑动完所有图像的过程。 我们经常能看到的,平滑,模糊,去燥,锐化,边缘提取等等工作,其实都可以通过卷积操作来完成。
池化是一种形式的降采样,更加关注是否存在某些特征而不是特征具体的位置;会不断地减小数据的空间大小,因此参数的数量和计算量也会下降;在一定程度上也控制了过拟合。通常卷积层之间都会周期性地插入池化层。
观看视频,也见识到残差神经网络的强大了。
组会的时候董老师问感觉怎么样,我回答”云里雾里“。未来还有很长的路要走啊(小学生式感叹)。
疑问
卷积计算过程不懂,我好菜啊!
目前卷积网络有没有什么良好的改进,使其具有较好的可解释性?
赵峰
卷积神经网络
一、绪论
1.卷积神经网络的应用
基本应用:分类、检索、人脸识别、图像生成、自动驾驶
2.传统vs卷积神经网络
深度学习三部曲:搭建神经网络→寻找合适损失函数→寻找合适优化函数,更新参数
损失函数:用来衡量吻合度,可以调整参数和权重W,使得映射的结果和实际类别吻合。
常用分类损失:
交叉熵损失、hinge loss
常用回归损失:
均方误差、平均绝对值误差(L1损失)
传统(全连接)网络处理图像的问题:权重矩阵参数太多导致过拟合,而卷积神经网络局部关联、参数共享
二、卷积神经网络基本组成结构
1.卷积
卷积是对两个实变函数的一种数学操作。
在图像处理中,由于图像是以二维矩阵的形式输入的,因此需要二维卷积。
卷积的过程:感受野内的输入经过卷积核(或滤波器)中的权重处理,生成特征图。
2.池化
作用:保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力
3.全连接
两层之间所有神经元都有权重连接,通常全连接层在神经网络尾部,参数量最大。
三、卷积神经网络典型结构
-
1.AlexNet
-
2.ZFNet
-
3.VGG
-
4.GoogleNet
-
5.ResNet
四、代码实战
结论:在相同参数条件下,卷积神经网络在准确率上明显优于全连接神经网络,但打乱像素训练后卷积神经网络不再具有优势。
韩天悦
学习心得
数学基础
依然是数学废走马观花的环节,仅仅做了一些笔记。
数据降维:
较大奇异值包含了矩阵的主要信息
只保留前r个较大其奇异值及其对应的特征向量(一般r=d/10)可实现数据从nd降维到(nr+ rr + rd)。
矩阵线性变换:
矩阵相乘对原始变量同时施加方向变化和尺度变化;
对于特殊向量(特征向量),矩阵只作用尺度变化(特征值)没有方向变化。
矩阵秩:度量矩阵行列之间的相关性。
矩阵的各行或列之间是线性无关的---矩阵满秩(秩等于行数)。
数据点分布:表示数据需要的最小的基的数量:
数据分布模式容易捕捉;
数据冗余度;
结构化信息(各行之间相关性,一般是低秩的)。
卷积神经网络
卷积和池化是卷积神经网络的两大特质。
然后记录了一些速查短语:
input:输入
kernel/filter:卷积核/滤波器
weights:权重
receptive field:感受野
activation map 或者=feature map:特征图
padding
depth/channel:深度
output::输出
stride:步长
问题总结
光看视频课程对于滤波器实在是云里雾里,在代码实践里面逐渐明朗。许多概念还是要在经典代码里面学习更有效果。
梁峻
视频中尤其令我眼前一亮的就是关于线性代数中的“秩”的介绍,完全颠覆了我对之前在线性代数课所学到的理论的认知。
这里讲到,矩阵的秩其实就是在形容这个矩阵是否有规律,越乱的,也就是越复杂的,也就是越没秩序的,秩就越大,而一眼就能看出排列规律的就是越有秩序的,就是秩越小的。相比之前各行之间进行加减操作最后数最终矩阵非零行数这种死板、机械的方式,这次视频中的解释实在是新颖。
不过视频中其他时间讲到很多数学公式仍然难以理解,希望老师能课上进行串讲,为大家指出总的脉络。
【第二部分】代码练习
2.1 MNIST数据集分类:
全连接网络模型参数数量6442,卷积神经网络模型参数数量6422,卷积神经网络训练需要的参数少一些?,最终对测试集的判断正确率比传统神经网络高,但是打乱像素后卷积神经网络优势就体现不出来了。
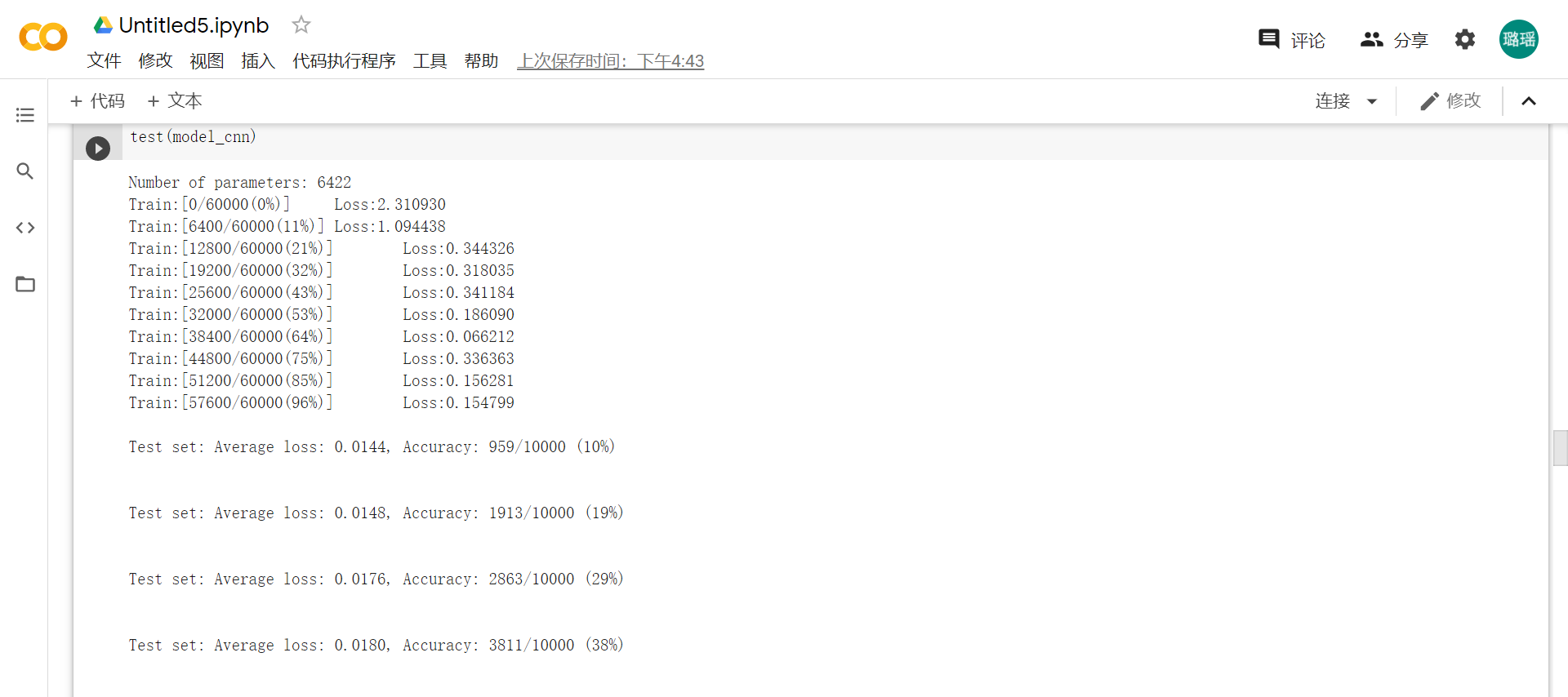
2.2 CIFAR10数据集分类:
改变batchsize和epoch可以提高模型的准确率吗?

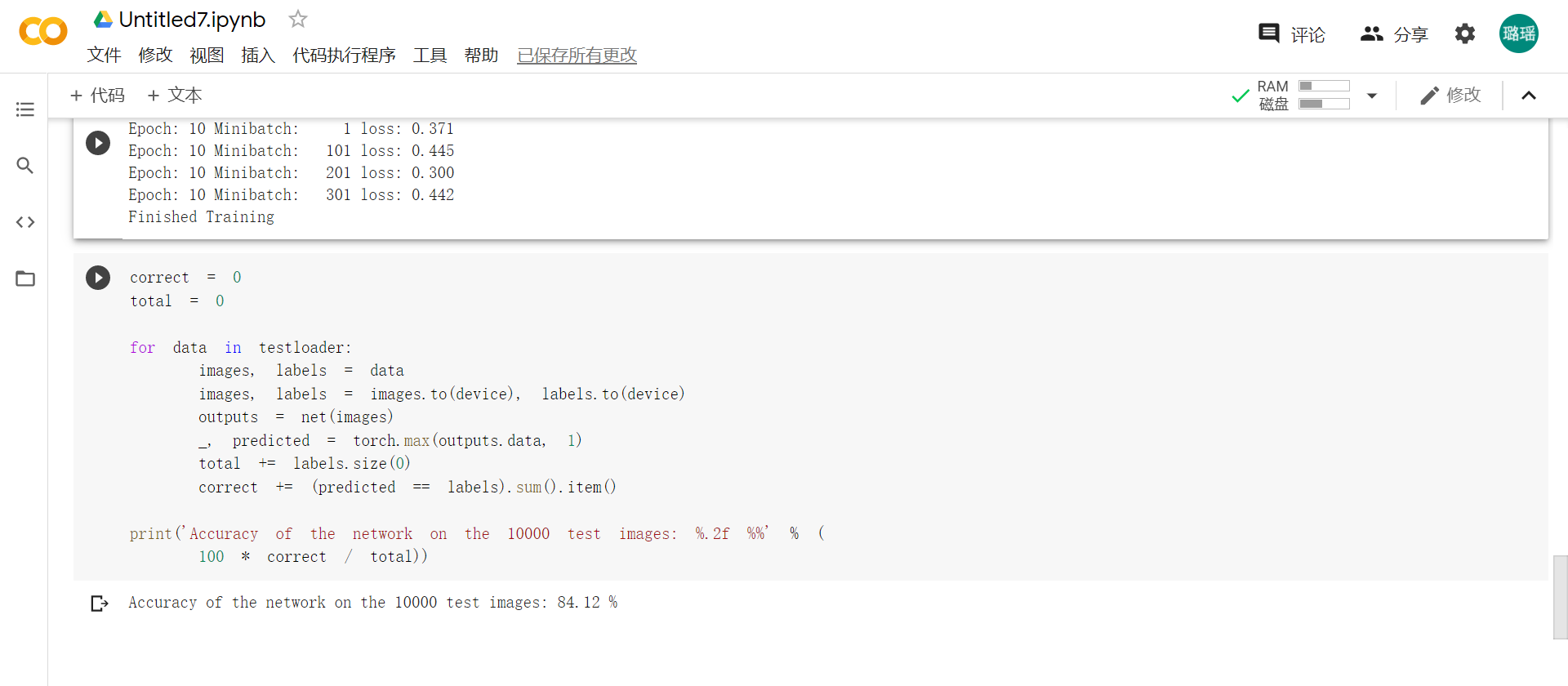
2.3 使用VGG16对CIFAR10数据集分类:
啊 换了种网络结构提高了?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号