第一次作业:深度学习基础
【第一部分】视频学习心得及问题总结
赵玉杨
本次的两个视频主要是深度学习的绪论和一些概念的阐述。从这两个视频里我了解了深度学习的历史,特点以及相关概念定理。希望在以后对于深度学习的深入学习当中,这些概念和定理能够起到明显的作用。
谢廷宇
总结:
以前学吴恩达的英文网课,十分痛苦。
吴恩达老师在coursera平台上的《机器学习》课程,无论在国内、还是在国外,都是最受欢迎的入门课程,没有之一。无数新手都是从这门课开始,进入机器学习领域的。
该课程的最大特点是:易学、易用。正如吴老师本人所说,
我非常注重“实践算法”这部分内容。实际上,就这些内容而言,我不知道还有哪所大学会介绍到。给你讲授学习算法就好像给你一套工具,相比于提供工具,可能更重要的,是教你如何使用这些工具。我喜欢把这比喻成学习当木匠。想象一下,某人教你如何成为一名木匠,说这是锤子,这是螺丝刀、锯子,祝你好运,再见。这种教法不好,不是吗?你拥有这些工具,但更重要的是,你要学会如何恰当地使用这些工具。会用与不会用的人之间,存在着鸿沟。
作者:AI传送门
链接:https://www.zhihu.com/question/36541936/answer/257420243
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
知乎大佬,害人不浅。
我建议初学者来上一上高峰老师的软件工程课。
周五参加了高峰老师的组会,受益匪浅。会上展示了有关比HDRNet更优秀的三重增强P图等内容,由于没能及时记录下来,几乎过目就忘,下次我还是带个笔记本好了。期间甘师兄对关于数据集包含错误数据的处理方式提出了质疑,而我这种小白只会给予“哇好有道理”这样的反应,真是惭愧不已。
疑问:
第一个学习视频59分之后为啥有好长一段时间没声音哇?
反向传播除了用于计算梯度外还有啥作用吗?
梁峻
视频心得
通过看视频,我了解了当前的人工智能很大程度上和人类的智能是两回事。人工智能更可以被解释为一种基于庞大数据库的自动找规律程序,它在把从之前的样例中得到的规律套用在以后它遇到的问题上,看似能以很强大的能力解决很多我们人类无法解决的问题,但实际上并没有任何“智能“可言,仅仅是简单重复。
就像课程里讲到的鹦鹉学舌和乌鸦喝水的例子一样,今天的人工智能就像学舌的鹦鹉,能达到与人类相似甚至更强的解题能力,但是实际上它本身并不知道如何解题,更不会研究出更好的解题方式。同时,它高度的”机械性“也导致了其他相关的问题,比如为了一个场景训练的人工智能几乎无法移植到另一个场景中,而是需要重新训练。
相比之下,我们人类一直期待的,是创造一种能像人类一样,总结经验后能继续按照经验推演、发展更好思路的”类生物“,只可惜这种设想在视频课程中预估的”后人工智能”时代都不是实现的目标。
问题
第二个视频中提到的各种公式和定理难以理解,希望老师能作以指点。
另外我对视频中提到的关于人工智能的偏见的问题及其解决方案持反对态度。毕竟人工智能需要现实世界人类创造的样例来进行训练,所以必然会带上现实世界的特征。而队于视频提到的应该额外加入所谓各种准则,它们同样是人类创造的,同样会有偏见,乃至意识形态的对立。就像中国人认为强制戴口罩是保护安全而欧美人认为是剥夺自由一样,人类从来就没有在道德观念层面达成过完全统一。所以加入额外的所谓准则,不是火上浇油就是矫枉过正,因为它们也只是代表准则制定者的群体。甚至可以总结说,在人类自身的观念有重大进步前,不带有偏见的人工智能不可能存在,因为我们甚至还无法定义何为偏见。
韩天悦
内容笔记
1.深度学习应用
已经深入:特征提取,物体检测,语义标注;
有待解决:描述生成:多媒体问答,多媒体叙事。
2.深度学习的当前弱点:
a.算法输出稳定性差。改变图像某个像素,输出就会被影响。
b.模型复杂度低,难以纠错和调试。无意义输出倾向于给出一个有意义输出。(Google毛利语翻译英语,采用圣经语调。)
c.模型层级复合程度高,参数不透明。
d.端到端的训练模式对数据依赖性强,模型增量性差。(只有数据量大到一定的程度,才能 语义标注+关系检测=图像描述)
e.专注直观感知问题,对开放性推理问题无能为力。(鹦鹉智能,乌鸦智能(乌鸦喝水,乌鸦马路坚果),奥巴马大象民主党(隐喻))
f.无法引入人类监督,机器偏见难以避免。(种族歧视,联想偏见,语调偏激,COMPAS评估犯罪风险,违反社会伦理)
(阿西莫夫机器人三定律:1.机器人不得伤害人类,或者坐视人类受到伤害;2.除非违背第一法则,否则机器人必须服从人类命令;3.除非违背第一或者第二法则,否则机器人必须保护自己。)
3.连接主义与符号主义从对立到合作:
符号主义:逻辑结构,知识图谱。
联结主义:神经网络,深度学习。
4.深度神经网络的问题:梯度消失:增加深度造成梯度消失,误差无法传播;多层网络容易陷入局部极值,难以训练。
5.受限玻尔兹曼:
自编码器:输出等于输入,输入+隐层(最大程度代表原输入信号)+输出
最初降维
堆叠自编码器:
个人总结
神经网络采用了逻辑回归的思想,同时借以梯度下降法来应对损失函数的问题。向量化是训练大数据集的前提,考虑迟到GPU更加擅长SIMD计算,避免使用明确的for循环,从而提高代码速度。
问题
在自己试图设计模型的时候,怎么选择神经网络的层数,具体是三层还是四层?
刘璐瑶
学习心得:
在整体上更清楚一些啦~
介绍了人工智能、机器学习、深度学习相关概念、关系等。深度学习是机器学习的一种,神经网络更深,有更多的参数需要学习,也有很多不能做到的事情。目前要求要有比较大的数据量(资料越多,学的越好)。通过引入激活函数,神经网络可以进行非线性拟合。sigmoid存在容易饱和、输出不对称的问题,relu解决了饱和问题。单层感知器只能解决线性问题,组合得到的多层感知器可以来解决非线性问题。万有逼近定理感觉很神奇,好像也挺有道理。深层神经网络存在梯度消失的问题,解决方法有relu、预训练。
问题:
三层前馈神经网络的BP算法那里不太懂呢
柳贺然
视频学习心得
通过第一个视频的学习,我了解到了人工智能的发展现状以及未来的应用场景,并且还了解到传统机器学习的缺陷,以及深度学习的基本原理。在第二个视频中学习了有关深度学习的基本理论知识,深入了解了激活函数,单多层感知器以及万有逼近定理。在神经元总数相当的情况下,增加网络的深度可以比增加宽度带来更强的网络表示能力。视频为我普及了有关深度学习的概念,感受到了人工智能技术的蓬勃发展,也为后续的学习奠定了基础。
赵峰
绪论:
一、人工智能热的背景
1、现在世界各国政府都开始重视人工智能技术发展,争相出台战略
2.人工智能人才缺口大,高校纷纷推出教育计划
二、人工智能的起源
地点:达特茅斯会议
人工智能的前身是机器智能,由图灵提出
三、人工智能发展阶段
现在处于高速发展期,算法获得突破,应用场景扩大
人工智能的三个层面:计算智能,感知智能,认知智能
人工智能+跨领域前景广阔
四、AI的两个学派:逻辑演绎vs归纳总结
实现的两条脉络:知识工程/专家系统vs神经网络
机器学习的优势:省时省力,灵活性强,数据处理轻松,结果客观
知识工程的发展&融合
五、机器学习的定义:从数据中自动提取知识
机器学习的方式:
- 建模,确定假设空间
- 确定目标函数
- 求解模型参数
监督vs无监督学习模型的区别:
监督学习的样本具有标记(输出目标)
- 无监督学习适于学习描述,适用于描述数据
- 监督学习适于标记分界面,适用于预测数据分类
半监督学习:部分数据标记已知,适用于标记样本成本过高,无标记成本廉价
强化学习:数据未标记,但知道离目标的远近反馈,适用于决策问题
参数vs无参数模型:
对数据分布进行假设,待求解的数据模型可以用一组有限且固定书目的参数进行刻画,即为有参数模型,其他都为无参
生成模型vs判别模型:
前者要先学习联合概率分布,然后从中求条件分布,有点:信息更多,更快收敛到真实分布,支持复杂训练情况;缺点:数据需求大,预测准确率不如判别模型
六、机器学习的发展历程
传统机器学习:人工设计特征,特征比分类器更重要
深度学习→后深度学习
七、神经网络结构的发展
历史突破:AlexNet
1958:第一次兴起 Perception
1986:第二次兴起 BP
2012:第三次兴起 CNN
神经网络的未来:应用更广,搭建更容易,输入数据量更少
人们希望深度学习对问题的理解和解决方案是简洁通用的
八、深度学习理论研究:深度学习“不能”做什么?
- 算法输出不稳定,易被攻击(对抗样本问题)
- 模型复杂度高,难以纠错、调试。(例:谷歌翻译语料bug)
- 模型层级复合程度高,参数不透明(只能控制第一层,深层无法分析特征)
- 对数据依赖过强,样本数据大时才能体现准确拟合优势,缺乏认知迁移能力
- 擅长直观感知问题,不能处理开放型推理问题,缺乏真正的理解能力
- 人类无法监督学习,机器可能会产生偏见和歧视问题
总结:稳定性低,可调试性差,参数不透明,增量性差,推理能力差,机器偏见
→解释性的三个层次:找得到(12),看得懂(36),留得下(45)
深度学习普遍准确性高,但是解释性差。
神经网络基础:
一、浅层神经网络
神经网络需要激活函数f来进行非线性拟合
激活函数举例:线性函数,S性函数(容易饱和,输出不对称),双极S性(解决对称问题),ReLU(解决饱和区问题),Leaky relu(跳出负值)
首个可以学习的人工神经网络:单层感知器,能实现与非或门,不能实现异或
多层感知器通过组合单层感知器实现更复杂的逻辑功能
万有逼近定理:若一个隐层包含足够多的神经元,三层单隐层神经网络能无限逼近任意预定的连续函数/双隐层感知器能逼近任意非连续函数。
训练数据的作用就是让神经网络学习按照期待的模式将一个非线性问题的原始输入空间投影到线性可分的空间去分类/回归。
- 增加节点数=增加维度=增加线性转换能力
- 增加层数=增加激活函数的次数=增加非线性转换次数
神经网络的参数学习:链式求导导致反向传播,误差通过梯度传播
深层神经网络的问题:增加深度会造成梯度消失,多层网络容易陷入局部极值,这导致神经网络普遍三层
二、从神经网络到深度学习
回避局部极小值和梯度消失问题的解决办法:逐层预训练
经过逐层预训练,解会更收敛,且得到解的速度更快
自编码器一般是一个多层神经网络结构,其学习目标是最小化重构错误
堆叠自编码器:将多个自编码器得到的隐层串联,所有层预训练完后,进行基于监督学习的全网络微调
RBM:二分图结构的两层神经网络,目的是让隐藏层作为可见层的特征
【第二部分】代码练习
2.1 pytorch基础练习:
如果早知道colab的话,我可能就不会去安装pycharm、anaconda、pip之类的了。我觉得我安装配置的时间貌似比敲代码的时间还长。
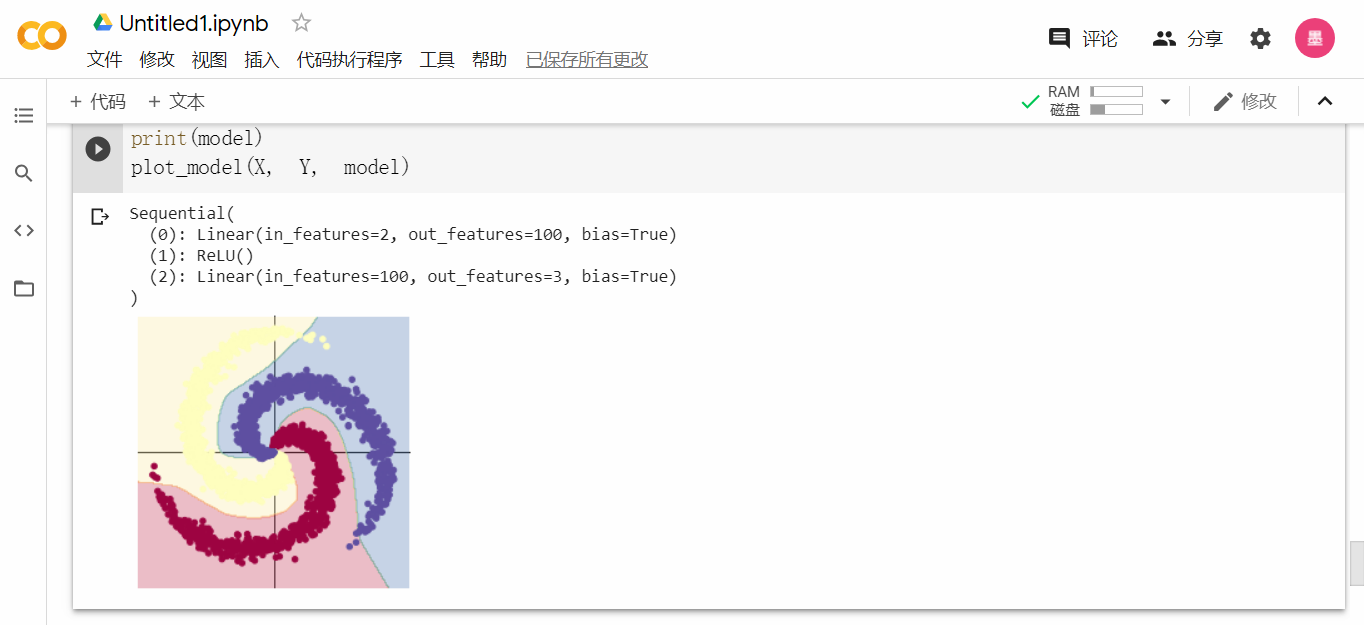
2.2 螺旋数据分类:
此次为监督学习,利用一组已知类别的样本调整分类器的参数,使机器学习达到所要求性能。通过本次学习,我学会且不仅学会了神经网络的汉语拼写及发音。
刚开始学习机器学习时,我在笔记本上记录了大量的公式,后来我沉痛地发觉,这是走了歪路。公式是记不完的,就算记住一时也终将忘记,更重要的是掌握思路。
!wget 这个操作、长见识 了。
注意点每一次反向传播前,都要把梯度清零。
问:所以ReLU 是干啥的?
答:增加下一层的非线性因素、克服梯度消失。本例中,使用ReLU后分界线出现了弧形扭曲。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号