Blink SQL 回撤解密
因为目前我司使用的版本还是和Blink对齐的版本,所以本文还是先针对Blink中对于回撤的实现来进行源码分析。
概念
回撤这个概念,是流计算中特有的,简单理解起来就是将先前的计算结果回撤,那什么场景下会出现回撤呢?当"中间计算结果"被提前下发时,后续更新结果时,需要将先前的中间值回撤,并下发更新后的值。因此回撤的使用场景,主要是在会产生中间计算结果的场景。
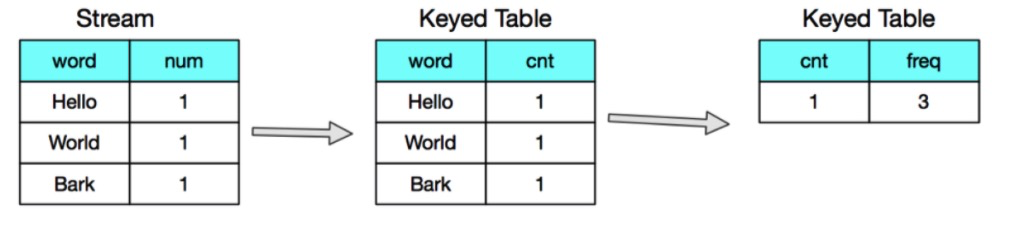
在流计算中,因为上游的数据集是持续流入的,因此计算的结果都是中间结果。例如
- group aggregate 计算中,每来一条数据,都会去更新某个维度的聚合值下发,这个时候下发的就是中间结果。
- 双流join中,left join场景下,右表没有数据时会先下发一条 (left, null) 下去,而当后续右表相对应的key的数据到达时,要将先前发送的(left, null)的数据回撤掉,在发送(left, right)
- 在window 算子中,如果我们设置了early trigger,那么就会发送中间计算结果,就会需要发送回撤消息。
以第一种场景为例,如果下游是一个按主键更新的存储,其结果会被不断的覆盖,计算结果没有正确性的问题。但是如果计算的sql是如下场景。
SELECT
cnt,
COUNT (word) AS freq
FROM
(
SELECT
word,
COUNT(num) AS cnt
FROM
Table
GROUP BY
word
)
GROUP BY
cnt;
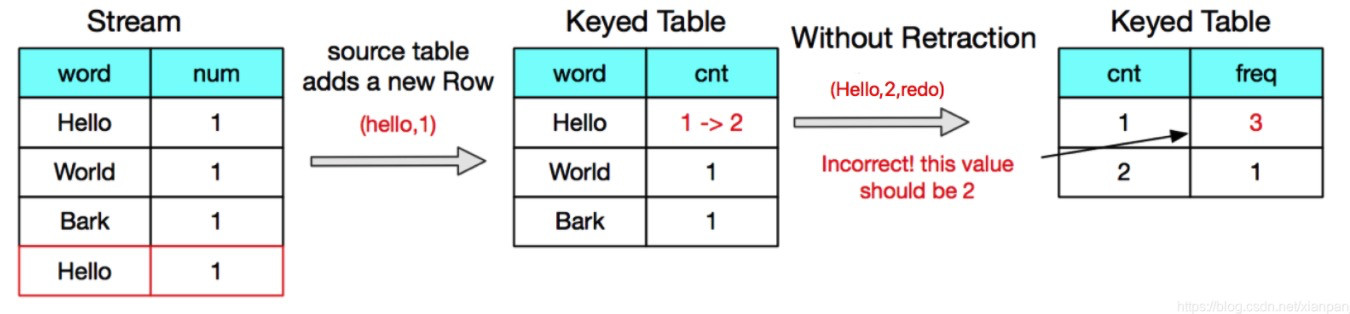
第一阶段产生的count值,会作为第二个阶段的group by维度,因此当count值发生变化时,如果不发送回撤消息,产生的聚合值就是错误的
我们可以看到发送回撤消息,最终目的是实现计算结果的准确性,最终一致性。
规则推导
在了解回撤的作用之后,我们再来看看blink中具体是怎么实现回撤功能的。在StreamExecRetractionRules中定义了三个规则
- StreamExecRetractionRules.DEFAULT_RETRACTION_INSTANCE
- StreamExecRetractionRules.UPDATES_AS_RETRACTION_INSTANCE
- StreamExecRetractionRules.ACCMODE_INSTANCE
这三个规则的主要作用是给StreamPhysicalRel节点上去分配AccModeTrait。AccModeTrait 是一种RelTrait,表示了每个节点的物理属性。而AccModeTrait中的属性有以下两种
- Acc
- insert: (true, newRow)
- update: (true, newRow)
- delete: (false, oldRow)
- AccRetract
- insert: (true, newRow)
- update: (false, oldRow), (true, newRow)
- delete: (false, oldRow)
以上表示的是两种模式下,针对insert,update和delete三种消息,向下游发送具体message的差异,其中true或者false表示的是BaseRow中的header头,用来表示是否是回撤消息。
可以看到这两个模式的主要差别是发送更新消息时的行为不一样。 AccRetract模式下update消息会先发送一条oldRow的回撤消息。
AssignDefaultRetractionRule
首先我们来分析第一个RetractRule。
override def onMatch(call: RelOptRuleCall): Unit = {
val rel = call.rel(0).asInstanceOf[StreamPhysicalRel]
val traits = rel.getTraitSet
// init AccModeTrait
val traitsWithAccMode =
if (
AccModeTrait.DEFAULT == traits.getTrait(AccModeTraitDef.INSTANCE) &&
((rel.isInstanceOf[StreamExecDataStreamScan] &&
rel.asInstanceOf[StreamExecDataStreamScan].isAccRetract) ||
(rel.isInstanceOf[StreamExecIntermediateTableScan] &&
rel.asInstanceOf[StreamExecIntermediateTableScan].isAccRetract))) {
// if source is AccRetract
traits.plus(new AccModeTrait(AccMode.AccRetract))
} else {
traits
}
// transform
if (traits != traitsWithAccMode) {
call.transformTo(rel.copy(traitsWithAccMode, rel.getInputs))
}
}
第一个是规则,只针对源头节点进行分析。FlinkRelBuilder中传入了五个Flink自定义的RelTraitDef,这里我们需要关注的是AccModeTraitDef。
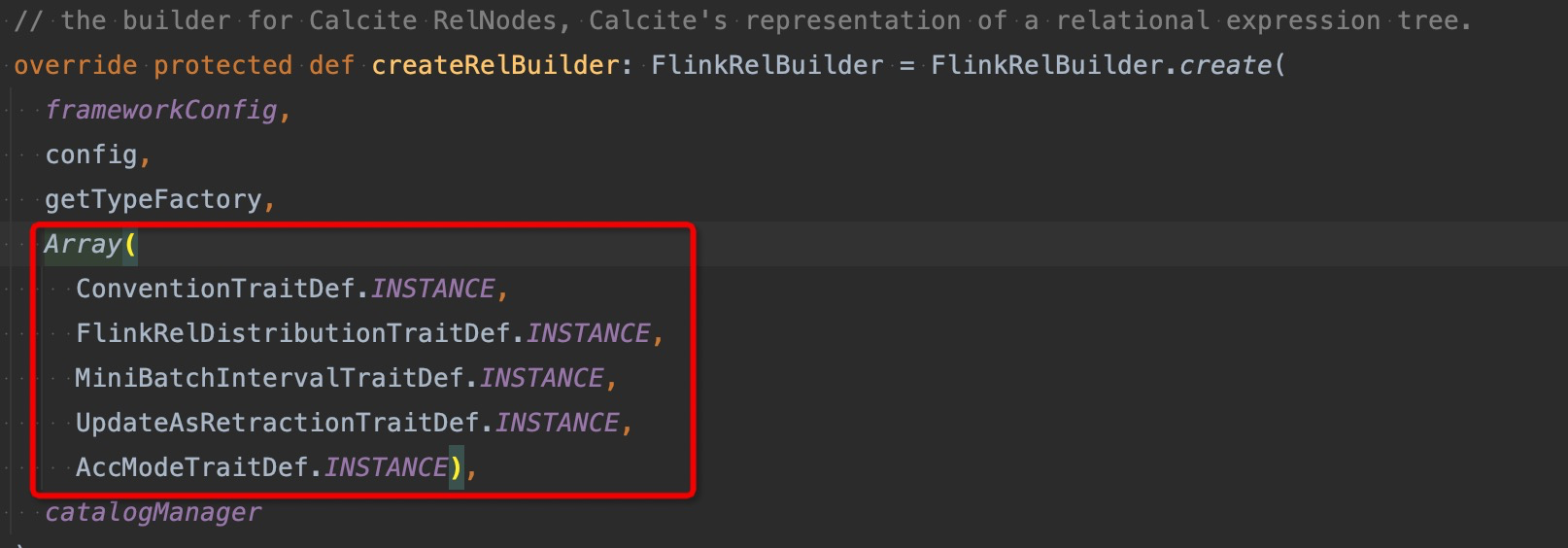
这里定义的几个traitDef,会在创建关系表达式时,作为默认的triat注入。因此在进行rule检测之前,默认所有的RelNode中的AccModeTrait都是AccMode.Acc,因此这个规则就是检测source节点,如果source节点的物理节点具有 xxx.isAccRetract的属性,就将其AccModeTrait设置为AccMode.AccRetract
SetUpdatesAsRetractionRule
/**
* Annotates the children of a parent node with the information that they need to forward
* update and delete modifications as retraction messages.
*
* A child needs to produce retraction messages, if
*
* 1. its parent requires retraction messages by itself because it is a certain type
* of operator, such as a [[StreamExecGroupAggregate]] or [[StreamExecOverAggregate]], or
* 2. its parent requires retraction because its own parent requires retraction
* (transitive requirement).
*
*/
override def onMatch(call: RelOptRuleCall): Unit = {
val parent = call.rel(0).asInstanceOf[StreamPhysicalRel]
val children = getChildRelNodes(parent)
// check if children need to sent out retraction messages
val newChildren = for (c <- children) yield {
if (needsUpdatesAsRetraction(parent, c) && !containUpdatesAsRetraction(c)) {
setUpdatesAsRetraction(c)
} else {
c
}
}
// update parent if a child was updated
if (children != newChildren) {
call.transformTo(parent.copy(parent.getTraitSet, newChildren.asJava))
}
}
}
child: 在关系代数的执行树中处于靠下位置,如source节点。
根据规则的注释,他所做的是将parent的child节点(也就是输入节点)标记上UpdateAsRetractionTrait,以下场景中的输入节点需要被标记
- 下游节点依赖Retract消息,例如
StreamExecGroupAggregate等 - 下游节点的下游间接依赖Retract消息
具体流程中,是首先根据parent节点获取其所有的输入(child), 遍历输入节点,当两个条件满足时,将child节点设置指定的trait。
- needsUpdatesAsRetraction
- !containUpdatesAsRetraction 这个表示当前child没有UpdateAsRetraction的标记
setUpdatesAsRetraction
def setUpdatesAsRetraction(relNode: RelNode): RelNode = {
val traitSet = relNode.getTraitSet
relNode.copy(traitSet.plus(new UpdateAsRetractionTrait(true)), relNode.getInputs)
}
这个方法就是将当前的relNode节点添加上UpdateAsRetractionTrait的trait
containUpdatesAsRetraction
def containUpdatesAsRetraction(node: RelNode): Boolean = {
val retractionTrait = node.getTraitSet.getTrait(UpdateAsRetractionTraitDef.INSTANCE)
retractionTrait != null && retractionTrait.sendsUpdatesAsRetractions
}
判断输入节点是否有UpdateAsRetraction的属性
needsUpdatesAsRetraction
其入参是下游节点和输入节点
// node是下游节点
def needsUpdatesAsRetraction(node: StreamPhysicalRel, input: RelNode): Boolean = {
node match {
case _ if shipUpdatesAsRetraction(node) => true
case dsr: StreamPhysicalRel => dsr.needsUpdatesAsRetraction(input)
}
}
def shipUpdatesAsRetraction(node: StreamPhysicalRel): Boolean = {
containUpdatesAsRetraction(node) && !node.consumesRetractions
}
- 下游节点已经被标记为了UpdateAsRetraction,并且下游节点不会consumeRetraction消息(这个是StreamPhysicalRel的一个属性,由各个物理节点各自实现)
- 或者检测下游节点是否需要 needsUpdatesAsRetraction,这个也是StreamPhysicalRel的一个属性。
SetAccModeRule
/**
* Updates the [[AccMode]] of a [[RelNode]] and its children if necessary.
*/
override def onMatch(call: RelOptRuleCall): Unit = {
val parent = call.rel(0).asInstanceOf[StreamPhysicalRel]
val children = getChildRelNodes(parent)
// check if the AccMode of the parent needs to be updated
if (!isAccRetract(parent) &&
(producesRetractions(parent) || forwardsRetractions(parent, children))) {
call.transformTo(setAccRetract(parent))
}
}
/**
* Checks if a [[StreamPhysicalRel]] produces retraction messages.
*/
def producesRetractions(node: StreamPhysicalRel): Boolean = {
containUpdatesAsRetraction(node) && node.producesUpdates || node.producesRetractions
}
/**
* Checks if a [[StreamPhysicalRel]] forwards retraction messages from its children.
*/
def forwardsRetractions(parent: StreamPhysicalRel, children: Seq[RelNode]): Boolean = {
children.exists(c => isAccRetract(c)) && !parent.consumesRetractions
}
- node 包含有UpdatesAsRetraction 并且node会产生更新消息,那么就需要发送回撤
- 或者node本身就会发送回撤消息,node.producesUpdates 和 node.producesRetractions 这两者也都是StreamPhysicalRel的一个属性。
- 或者上游节点存在AccRetract的节点,并且当前节点不能consumeRetraction
这几种情况下,当前算子就需要加上AccRetract的属性。
StreamPhysicalRel
/**
* Whether the [[FlinkRelNode]] produces update and delete changes.
*/
def producesUpdates: Boolean = false
/**
* Whether the [[FlinkRelNode]] requires retraction messages or not.
*/
def needsUpdatesAsRetraction(input: RelNode): Boolean = false
/**
* Whether the [[FlinkRelNode]] consumes retraction messages instead of forwarding them.
* The node might or might not produce new retraction messages.
*/
def consumesRetractions: Boolean = false
/**
* Whether the [[FlinkRelNode]] produces retraction messages.
*/
def producesRetractions: Boolean = false
- producesUpdates表示该节点是否会产生更新消息
- producesRetractions表示该节点是否会直接产生回撤消息
- needsUpdatesAsRetraction表示该节点是否需要上游将update编译成retract消息发送
- consumesRetractions 表示该节点是否会处理上游的retract消息,而不是直接转发。但是该节点仍然可能会发送retract消息下去。
小结
所以大致逻辑就是
- 首先检测每个node是否需要UpdatesAsRetraction,如果是的话,就将其上游节点标记为UpdatesAsRetraction。
- 然后检测每个node是否包含UpdatesAsRetraction,如果包含,并且该节点会发送update消息,那么就将其更新为AccRetract。或者上游已经是AccRetract,并且下游不会处理retract消息,则将下游标记为AccRetract。
其中会中断retract传播链的,只是有consumesRetractions的节点会阻断。
优化规则执行顺序
这里面在测试的时候,还注意到一个细节,例如以下的计算链路,按照推导:
因为StreamExecLocalGroupAggregate会consumesRetractions,那么他被标记为UpdatesAsRetraction,而其needsUpdatesAsRetraction的属性也为false,那么它是如何告知上游的GroupAggregate需要发送回撤消息呢,其使用的agg函数为什么会有retract的后缀呢?

其原因是,sql优化的规则执行是有顺序的,在physical rewrite阶段,首先会进行AccTrait的设置,随后才会进行诸如两阶段之类的rewrite优化,因此在前面的过程中不会涉及StreamExecLocalGroupAggregate节点的判断,这个是在两阶段中生成的物理节点。这个规则的执行顺序和calcite的Volcano的优化规则模型执行优化,后续有时间再写文研究下。
以更低的代价retract
我们再回头看,实际上以上的规则就是对Acc消息分为Acc和AccRetract已经是针对retract场景做了优化,因为不是所有的场景都需要上游发送retract消息,如果每种场景都会发送retract,消息量和网络开销就直接double,因此才有了上述的这套推导规则。只有当下游需要上游以retract的方式发送更新消息,上游才发送retract消息。
发送retract消息一般会带来一些额外的开销,包括
- 网络数据量翻倍 像一般retract时,都会判断当前的计算值和先前的计算值不一样了,才会发送回撤消息,这也是减少发送量的一种优化
- 下游的agg函数为了处理回撤,可能只能采取性能较差的实现,典型的例如Max和Max_with_retract
- 需要在上游存储先前已经发送的值,保存于状态中
参考
https://docs.google.com/document/d/18XlGPcfsGbnPSApRipJDLPg5IFNGTQjnz7emkVpZlkw/edit?spm=ata.21736010.0.0.7e47793201xpBs
https://issues.apache.org/jira/browse/FLINK-6047
本文来自博客园,作者:Aitozi,转载请注明原文链接:https://www.cnblogs.com/Aitozi/p/15733747.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号