


GPT5.1 告诉你如何与电脑对话控制一切软件:复现 Caddy(YC F25)的愿景丨社区来稿
本文来自 thinkingloop 的 k,一个手搓过实时翻译语音智能体的投资人。
Caddy是什么?
Caddy — 用你的声音控制所有工作应用
Caddy号称是:下一代计算界面,由语音和屏幕上下文驱动。Caddy 通过让知识工作者直接与电脑对话,消除了点击和复制粘贴的混乱。当今的知识工作者已经生活在以语音为先的世界中——他们在 WhatsApp、iMessage 和 Discord 上说话。现在也是我们的工具倾听的时候了。
创始人: Caddy 由 Connor Waslo 和 Rajiv Sancheti 联合创立。两位创始人在创办 Caddy 前共同在视频通信独角兽 Loom 工作了四年,分别领导 Loom 的 AI 套件产品和设计团队。Rajiv 曾担任 Loom AI 功能的设计负责人,此前也在 Airbnb 及 Kleiner Perkins (KP) 孵化器参与产品设计项目。Connor 是 Loom AI 套件的产品负责人,并带领过 Loom 的定价与营收团队,对企业软件的商业化和用户需求有深入理解。这样强强组合的背景使他们深刻认识到语音交互在办公场景的潜力。
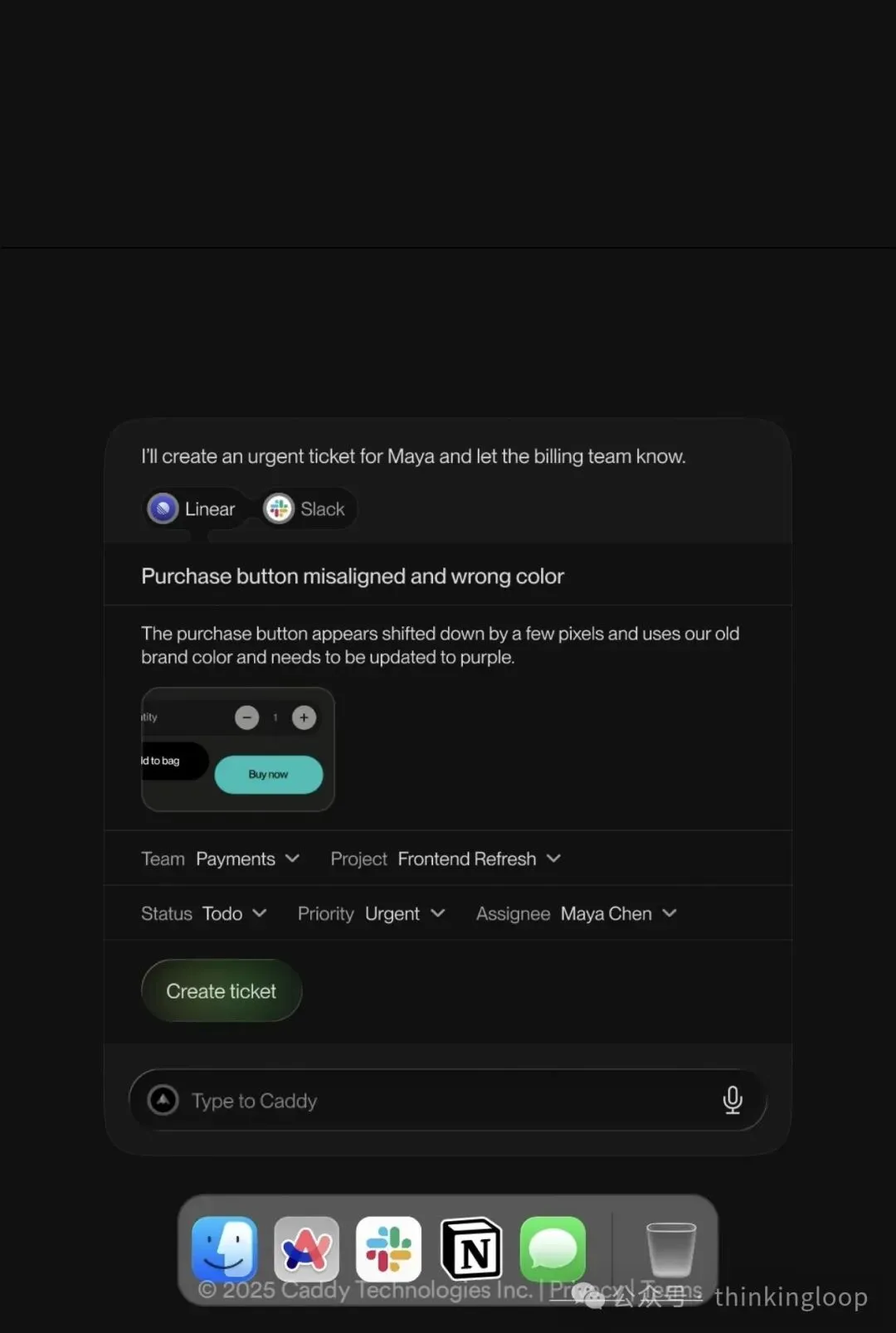
产品: Caddy 打造“工作版 Siri”,让用户用语音完成跨应用的复杂工作流程。简单来说,Caddy 将用户的声音变成计算机的新型输入接口。它能够“读懂”用户屏幕上的内容和当前意图,从而在用户持续专注时自动替用户执行操作。例如,当用户说出“创建一个 Linear 工单并分享给 Slack”这样的指令后,Caddy 会理解上下文并在后台立即于 Linear 中创建工单,再将链接发到 Slack 指定频道,无需用户手动切换应用来回操作。
Caddy 提供两种模式:
操作模式(Action mode): 用户口述意图,Caddy 即可跨应用执行相应任务(如发送 Slack 消息、在日历安排会议等),因为 Caddy 能看到当前屏幕内容并连接相关应用,所以用户可以免除频繁在各工具间切换。
听写模式(Dictation mode): 用户可以在任意文本输入框直接用语音输入文字(邮件、即时消息、评论等),完全替代键盘打字且适用于全局,不论当前聚焦在哪个应用窗口。
让 GPT5.1 复现一个 Caddy
Caddy 本质上是「桌面代理 + 语音前端 + LLM 编排 + App Connectors」,挂在 OS 最底层,把“说话 → 操作多应用”的链路打通。
我按工程链路拆一遍,从你按下说话键,到 Linear 里真的多了一条 ticket。
1.顶层架构图
可以粗暴分成 5 层:
-
客户端/OS 集成层:桌面 App、快捷键、麦克风、屏幕上下文抓取、输入注入
-
语音管线层:VAD、流式 ASR、命令式文本后处理
-
上下文与状态层:屏幕内容解析、当前应用/选中对象、用户会话状态
-
LLM/Agent 编排层:意图理解、工具调用规划、多步 Workflow
-
Connectors 执行层:Slack / Linear / Calendar 等 API + 必要的 UI 自动化
2.客户端:常驻桌面的小 daemon(守护进程)
目标:抢占「入口」,掌握输入/屏幕/部分输出。
关键组件:
-
桌面常驻进程
-
Mac:菜单栏 App + 后台 daemon
-
Windows:Tray app + 后台 service
-
全局唤起方式
-
全局快捷键(比如 Fn 或自定义),区分两种模式:
-
Fn + 单击:Dictation Mode
-
Fn + 长按:Action Mode
-
或者在当前窗口边缘挂一个“对讲机”小按钮
-
麦克风采集 + 本地 VAD
-
16k/24k PCM 流式上传(WebSocket/gRPC)
-
本地语音活动检测(VAD)做:
-
减少静音上传
-
判断一句话的结束,触发“开始理解 + 执行”
-
屏幕上下文采集
-
当前 前台 App:bundle id、window title
-
当前 URL(浏览器场景下):通过浏览器扩展或自动化接口拿
-
选中内容:浏览器:content-script 读 selection/原生 App:Accessibility API / clipboard hack
-
截图:整个屏幕 or 活动窗口截图(高质量 PNG)——后面给 OCR/vision 模型做 fallback
-
输入注入(用于 Dictation 模式)
-
通过 OS API / IME:模拟键盘输入或走 Text Input API(Mac Text Services / Windows TSF)
-
要处理:光标位置/撤销(Cmd+Z)与重试
-
这层 80% 是 OS & 桌面工程,AI 只是上游/下游。
3.语音管线:从“声音”到“可用文本”
目标:低延迟、高准确、偏命令语气的 ASR。
链路:
-
本地 VAD / Chunking
-
把长语音切成合适 chunk,减少 RTT
-
可先丢给 ASR 做“热启动”,边听边转
-
流式 ASR
-
典型:WebSocket/gRPC 发送音频帧,返回增量 transcript
-
要支持:中途修正(partial result replace)/实时显示给用户,做“我听懂了”的反馈
-
文本后处理
-
命令场景的特殊优化:
-
专有名词(Linear、Figma、Jira、Notion…)自定义词表
-
标点补全(尤其是 Dictation:句号、换行)
-
简单格式化(邮箱、链接、代码块 etc.)
-
可以在 ASR 后再走一个轻量 LLM 或规则引擎:
-
把“帮我建一个 linear ticket 然后丢 slack”→ 标准化成相对规范的英文或结构化意图文本
Dictation 模式里,很多时候 ASR + 轻后处理 = 可直接注入;
Action 模式则将文本交给下一层 LLM/Agent。
4.屏幕上下文引擎:让“这个”有具体指代
Caddy 卖点之一就是“看得见你的屏幕”,否则“share this to Slack”这样的应用程序交互会懵。
可以设计一个 Context Service(大部分逻辑在客户端,本地优先):
-
基础元数据
-
active_app: Slack / Chrome / Linear …
-
active_url: 当前 tab URL
-
selection: 文本内容 / DOM node path
-
clipboard: 最近复制的内容(选配)
-
结构化上下文抓取策略
-
浏览器里:
-
content script → 把当前页面标题、部分可见文本、选中内容抽取出来
-
做一个摘要 + 关键信息提取(本地 or 远端轻量模型)
-
原生 App:
-
通过 Accessibility API 读当前窗口文本(Slack 消息列表、邮件标题等)
-
或者只能拿到 window title,但也有用:
-
比如 Linear ticket 标题/ID 通常挂在 title
-
截图 + OCR / 多模态 fallback
-
“只知道这是一个截图里的 Figma 图层”时:
-
截图 → 本地 OCR(names / labels)→ 再给 LLM
-
或截图 → vision 模型 → 解析“当前是 Slack 对话,选中消息是 xxx”
-
上下文对象化
-
对 Agent 暴露一个统一 JSON,例如:
{
"active_app": "Linear",
"active_url": "https://linear.app/...",
"selection_text": "Bug report: ...",
"screen_summary": "User is viewing a bug report in Linear tagged 'P1 - Production'.",
"entities": [
{"type": "ticket", "id": "LIN-123", "title": "Login fails on Safari", "url": "..."}
]
}
隐私友好做法:
尽可能在本地做提取 + 摘要,只把“压缩后的语义信息”发给服务器,而不是裸截图/全文。
5.LLM / Agent 编排:把“话”和“屏幕”变成一串 API 调用
这里是整套系统的大脑。
5.1 模式识别(Action vs Dictation)
-
客户端已经大致知道你按的是哪个键(模式),但仍然可以:
-
对 ASR 文本做一次简单分类:“帮我写一段回复…” + 光标在输入框 → Dictation 优先/“创建一个 Linear 工单并分享到 Slack” → Action
-
有冲突时,提示用户短确认,例如弹个 Toast:“我理解为执行操作,而不是输入文字”。
5.2 意图解析 + Workflow 规划
在 Action 模式下:
-
构造一个大 Prompt / System message:
-
你是谁:“你是一个桌面工作流助手,可以调用以下工具…”
-
你能做什么:列出工具(SlackTool / LinearTool / CalendarTool / GmailTool…)的 function schema
-
屏幕上下文:把上面那份 Context JSON 裁剪后塞进来
-
用户语音转写文本
-
通过 tool calling / function calling:
-
LLM 生成一组工具调用:
-
先 LinearTool.create_issue(…)
-
再 SlackTool.post_message(channel=…, text=issue_url)
-
对多步流程可:
-
在一次对话中串联多个 tool calls
-
或分多轮:工具执行 → 结果(issue_url)作为新的上下文 → 下一个工具
-
歧义与确认
-
比如用户说“发到产品群”,渠道名模糊:
-
LLM 先调用 SlackTool.list_channels
-
再根据结果选择最可能的那个
-
不确定时进行回问:“是 #product-team 还是 #product-roadmap?”
在 Dictation 模式下,LLM 主要是做“润色/格式化”,而不是 orchestrator。
6.Connectors:跨应用执行层(API & UI 自动化)
目标:让 Agent 的工具调用变成真实世界的 side-effect。
6.1 API Connectors
每个 SaaS app 就是一套小 SDK + 工具定义:
-
认证 & 授权
-
OAuth 2.0 / OIDC
-
后端安全存储 access_token/refresh_token(KMS + 加密)
-
Scope 设计:只申请必须的(只读?读写?只读 metadata?)
-
统一的 Tool Schema
-
比如 Linear:
-
create_issue(title, description, project_id, labels, assignee)
-
list_projects()
-
Slack:
-
post_message(channel, text, thread_ts)
-
find_channel_by_name(name)
-
错误处理 & 重试 & 速率限制
-
API 明确返回给 Orchestrator:失败原因(权限不足、字段缺失、配额限制)/是否建议让用户补充信息
6.2 UI 自动化 fallback(无 API / 用户本地状态)
有些事情需要直接“动鼠标键盘”:
-
比如往一个非标准应用里粘贴文本、点击按钮。
-
方案:
-
在客户端实现一层 UI Automation:
-
模拟快捷键(Cmd+C / Cmd+V / Cmd+N …)
-
根据 Accessibility Tree 找按钮位置,再点击
-
Orchestrator 发给客户端一个执行计划:
{
"actions": [
{"type": "key", "combo": "Cmd+L"},
{"type": "text", "value": "https://linear.app/..."},
{"type": "key", "combo": "Enter"}
]
}
这块做深了就是“桌面 RPA + LLM planner”的组合。
7.Dictation 模式的专用链路
相对简单但对“体验细节”要求极高:
-
客户端:
-
开始录音 → 流式 ASR
-
实时显示文本(overlay or inline)
-
后端:
-
ASR → 轻量 LLM(可选)做:
-
标点
-
口语转书面
-
简单自动纠错(可只在句尾做)
-
客户端注入:
-
根据光标位置持续插入文本
-
支持用户打断、撤销、重说
-
一些语音指令要拦截:“撤销刚刚那句”→ 不要当普通文本打进去,要当命令
一个硬指标:端到端延迟最好控制在 < 200ms 级别,才有“说一句话字就跟着出来”的错觉。
8.账户、个性化与“工作版 Siri”的持续进化
这层是“产品力”,但背后也有技术栈:
-
用户账户 & 设备绑定
-
多设备同步:家里 iMac、公司 MacBook,用同一套指令映射与 app 连接
-
个性化指令记忆
-
“我说‘丢给前端’,你就知道是发到 #frontend-team”
-
技术上是一层小 DSL / mapping:LLM 提取出 pattern → 存成 rule/下次类似话术命中时先走 rule,再 fallback LLM
-
历史记录 & 可审计
-
Action 模式所有动作要能在 UI 上回放:“昨天帮你创建了这 3 个 Linear ticket、发了这 5 条 Slack”
-
这既是安全需求,也是 trust & debug 工具
9.基础设施:服务划分与观测
后端大致可以拆成:
-
API Gateway(面向客户端)
-
Realtime Service(WebSocket / gRPC,处理音频流 & 实时事件)
-
ASR Service(可托管 or 自研)
-
Orchestrator Service(LLM 调度 & tool calling)
-
Connectors Service(与外部 SaaS 对接)
-
Auth & User Service(账户、OAuth、权限)
-
Telemetry & Metrics(日志、trace、指标:ASR 延迟、LLM 延迟、成功率…)
链路是典型的 event-driven:
-
用户说话 → 音频帧事件
-
ASR 输出 → Transcript 事件
-
Orchestrator 输出 → ToolCall 事件
-
Connector 执行完 → Result 事件 → 推回客户端/日志
10.安全、隐私与“我到底给了你多少权力”
这类产品非常敏感,安全/隐私几乎是技术架构的一等公民:
-
最小权限:
-
OAuth scopes 尽量细粒度
-
屏幕读取可以允许“只读当前窗口文本,不截屏”
-
本地优先处理:
-
能在本地摘要就不传 raw screen
-
敏感字段(邮箱、token、金额)在发送前做脱敏/mask
-
清晰可见的权限边界:
-
UI 中显式展示:“我现在可以在这些工具里代表你执行操作”
-
每条自动执行操作都带来源记录(话术 + 时间)
11.串一下你给的例子:
“创建一个 Linear 工单并分享给 Slack”
从工程链路看就是:
-
客户端捕获语音 + 当前屏幕(可能正在浏览一个 bug 描述页面)。
-
语音 → VAD → 流式 ASR → 文本:“创建一个 Linear 工单并分享给 Slack”。
-
Context Service 提供:
-
active_app: Chrome
-
active_url: 某 bug 报告文档
-
selection_text: 用户选中的 bug 描述
-
Orchestrator:
-
结合文本 + context,规划:
-
LinearTool.create_issue(title=…, description=selection_text, project=…)
-
SlackTool.post_message(channel=”#eng-bugs”, text=“New bug created: ”)
-
Connectors:
-
调用 Linear API 创建 issue → 得到 issue_url
-
调用 Slack API 发消息
-
客户端:
-
弹个 Toast:“已创建 LIN-123 并发到 #eng-bugs”,并提供撤销/跳转按钮。
整条链路跑顺了,就是“语音 + 屏幕上下文”变成“真正的多 app 自动化”。为了这个愿景和Dafdef/AI Key、Voice In + RPA、或浏览器侧 Copilot做对比时,可以直接按这几个层级做差异分析:入口(OS vs 浏览器)、上下文深度、Agent 编排能力、Connector 丰富度、以及安全/隐私策略。


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么


 浙公网安备 33010602011771号
浙公网安备 33010602011771号