
认识http缓存
HTTP缓存在生产环境中是相当重要的一环,既可以节省流量,也帮助缓解服务器压力。
错误的缓存配置往往导致客户端内容出错。因此需要了解http缓存的机制,防止类似问题出现。
HTTP缓存的用途
在HTTP/1.1[1]的最新RFC中,缓存的目标定义为:重复使用之前的响应信息,满足当前的请求,从而显著提高性能。
从该定义可以得知:
- 缓存会存储之前服务器返回的响应信息;
- 缓存会检查当前请求;
- 缓存以请求信息作为键(通常是URI)。
HTTP缓存提升性能
根据HTTP/1.1的文档,缓存通过两种手段来提升性能:
- 减少请求发起的数量;
- 减少响应信息的大小。
如果比较熟悉“强缓存”和“协商缓存”概念,那么就会发现,第一种手段就是本地返回的“强缓存”,第二种手段就是服务器返回304的“协商缓存”。
HTTP缓存控制在消息头部的实现
由于HTTP cache没有用户API,因此对HTTP cache策略的控制实际上通过请求头中的指令实现。翻看HTTP/1.0和HTTP/1.1的文档,可以发现,缓存控制的请求头参数是逐渐增加的。
此外,由于请求的性质原因,cache一般来说在GET请求中应用。
HTTP/1.0中的请求头参数
| 属性 | 取值 |
|---|---|
| Date | 绝对时间,每条信息都返回 |
| Expires | 绝对时间 |
| Last-Modified | 绝对时间 |
| If-Modified-Since | 绝对时间,客户端发起 |
| Pragma | 提供了 no-cache 指令 |
HTTP/1.1中的请求头参数
| 属性 | 取值 |
|---|---|
| Age | 相对时间,代表从服务器发出后经过的时间 |
| Cache-Control | 缓存控制专用指令,常用的指令大概有4类:max-age=int; no-cache; no-store/public/private; must-revalidate |
| ETag | 资源标签,由服务器计算 |
| If-系列 | If-Modified-Since / If-None-Match |
强缓存?协商缓存?
实际上,官方文档中没有这两个概念的定义。(如果有面试官问,可以请他去MDN或者RFC里找出来。)
HTTP真正设计的是两个缓存机制:过期和验证。顾名思义:过期,就是指资源过期;验证,就是验证过期的资源。
这两个机制刚好对应服务端与客户端的策略,即:
- 服务端拥有资源,并且派发给客户端,因此服务端能够决定资源何时过期;
- 客户端使用资源,因此客户端可以自行决定哪些资源可以重用,哪些资源需要向服务器再次获取。
举个例子:网站的LOGO图可能很久不变,因此服务器可以通知客户端:LOGO图上次更新是1年前。而客户端也会有类似的逻辑:虽说已经1年没有更改,但是也考虑每隔一段时间就在查询一次。
客户端与服务端双方都通过这些缓存相关字段进行交流,但是并不强制指定对方的行为。
有一点需要注意:实际网络中,请求与响应会流经多个节点,因此请求/响应头中的参数可能对流过的节点造成影响。
构造响应的机制
可以参考这篇文章[2]。
- 请求的有效URI与缓存中的响应匹配
- 请求方法允许使用缓存(通常是GET请求)
- 缓存中的响应头,指定的参数与请求头参数相匹配
- 没有no-cache指令(Pragma与Cache-Control)
- 缓存中的响应头不包含 no-cache 指令,且:缓存未过期/允许使用过期缓存/已成功验证
过期机制
最小的模型
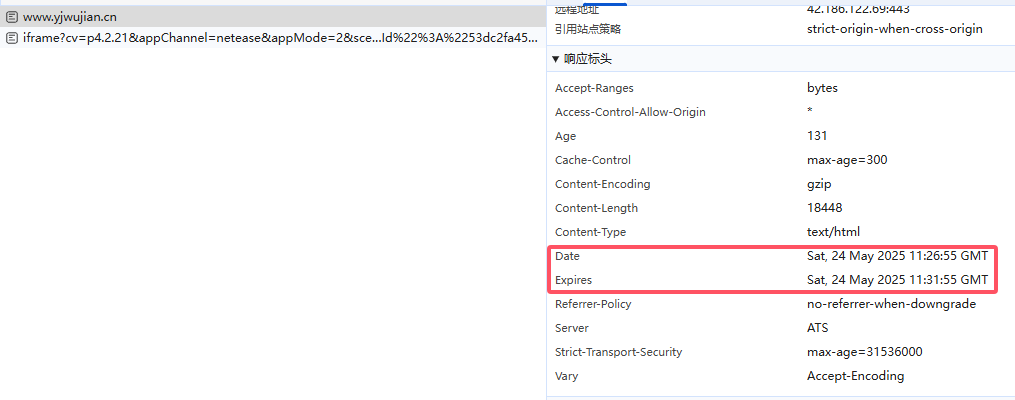
HTTP/1.0 中提出的字段:Expires / Date 构成了一个最小过期模型。客户端得到内容后,即可根据Expires - Date来计算资源的新鲜度。
如果没有过期,那么下次请求的时候,缓存可以直接构造这条响应,返回给用户。这条请求并没有真正发出,而是在本地就响应了。也就是常见的 200 (from memory / from disk)。
HTTP/1.1的增强
HTTP/1.1 中通过字段 Age 和 Cache-Control 的 max-age 增强了这个机制。采用新字段原因是,Expires使用绝对日期,会受到客户端本机时间的影响。
Age 字段可能包含请求链路上所有缓存的时间,因此返回时可能相当接近max-age的值。

验证机制
过期机制使得部分请求的新鲜响应可以直接复用。但是过期的资源也需要处理,这就是验证机制。
验证机制同样一目了然:既然本地资源已经不能确保新鲜,那么就向服务器请求新资源。
而HTTP协议并不希望将带宽浪费在重复发送资源副本上,因此设计出了验证机制的核心:条件请求(也可以称之为“协商请求”,如果想和“协商缓存”联系起来)。
条件请求
条件请求的核心是If-系列请求头参数。带有这些参数的请求,表面上看是普通的GET,但是服务器可以根据条件,选择返回新的资源(200 OK),或者通知缓存复用资源(304 Not Modified)。
| 请求头参数 | if-参数 |
|---|---|
| Last-Modified | If-Modified-Since |
| ETag | If-None-match |
显然,无论是复用,还是使用新资源,都会面临刷新缓存的问题。
强/弱校验
验证机制的字段又归类为强校验与弱校验。主要的作用是鉴别缓存的响应,是否需要被替换。
强弱校验的主要区别在于其值改变的机制:强校验值基于响应内容变化,甚至可以基于响应头信息变化,而弱校验往往基于一些特定参数,变化的频率更低,意味着更有倾向使用缓存。
| 请求头参数 | 校验情况 | 说明 |
|---|---|---|
| Last-Modified | 弱 | 多次响应该值仍可能不变 |
| ETag | 强 | 默认是强校验 |
| ETag+W/ | 弱 | 如果服务器生成的ETag不满足强校验要求 |
缓存拿到响应之后,如果匹配上强缓存值,就更新该条记录,否则更新最新的弱缓存值记录。
缓存指令 Cache-Control
Cache-Control的特点:
- 请求/响应头部都可以使用
- 对整个链路上的节点都产生影响
- 包含多种指令
请求指令列表
| 指令名 | 可选参数值 | 说明 |
|---|---|---|
| max-age | 相对时间 | 指示请求愿意接收响应的age最大值 |
| no-cache | 要求链路上的缓存必须与源服务器校验成功后,才能构造缓存响应 | |
| no-store | 链路上的缓存不应保存信息的任何内容,包括此请求,以及与之相关的任意响应。 |
响应指令列表
| 指令名 | 可选参数值 | 说明 |
|---|---|---|
| must-revalidate | 指示当此响应过期时,缓存应成功校验后再构造响应。 | |
| no-cache | 域名 | 此响应信息必须与源服务器验证后,才可以用于构造响应。(必须“协商”) |
| no-store | 缓存不得存储请求和响应的任何部分。 | |
| public | 任意缓存均可存储此响应,即使此响应不可缓存/仅四有缓存。 | |
| private | 域名 | 响应信息仅用于单一用户,不得存储于共享缓存。 |
| max-age | 相对时间 | 响应在age大于指定值时过期失效。(等于需要验证。) |
实际的缓存应用场景
index.html
index文件实际上是整个app的入口文件,因此一般不希望用户缓存。即使缓存,也应当进行验证后再使用。
因此配置项目的服务器参数时,可以配置为no-cache。也可以配合no-store使用。
另外,如果想控制请求频率,也可以使用max-age。
location / {
add_header Cache-Control "no-cache no-store max-age=300"
}
静态资源
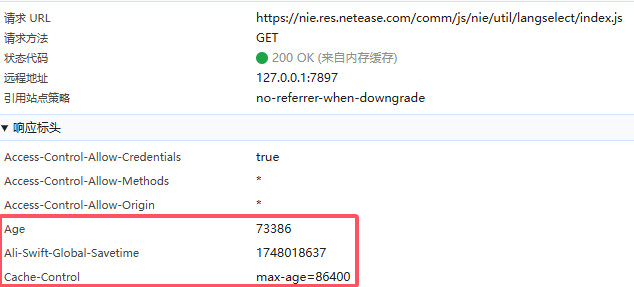
如果是使用现代打包工具(如webpack、vite等)的项目,静态资源可以直接按照max-age=31536000来设置。
这是因为打包工具一般会为文件生成哈希值,文件随index.html交付。只要更新,一定会重新下载,不需要特地设置缓存策略。
可以参考Next.js官方文档的说法[3]。

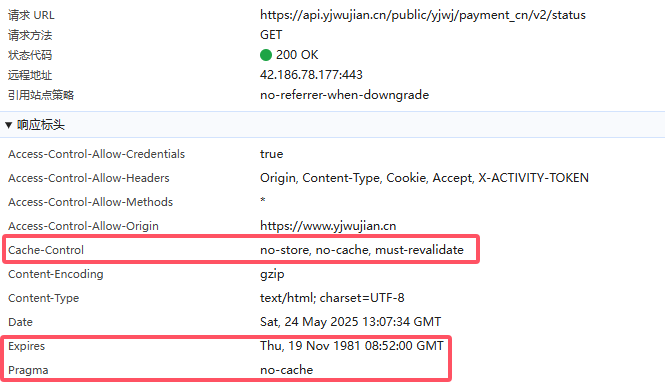
后端接口
后端接口所在的HTTP服务器一般会非常严格地要求禁止缓存。因此,一般会看到这样的接口响应头:
不推荐的meta标签
<meta http-equiv="pragma" content="no-cache" />
<meta http-equiv="Cache-Control" content="no-cache, must-revalidate" />
<meta http-equiv="expires" content="Wed, 26 Feb 1997 00:00:00 GMT" />
有些项目里可能会为index.html文件添加这些头部。这些头部的用法是HTML 4.01版本支持的内容。
目前在HTML5情况下,不支持这些http-equiv指令,因此也不需要添加。
小结
- HTTP协议设计缓存的目的是为了减少网络请求数量,降低响应消息大小。
- 实际生产中,HTTP服务器、应用框架等已经提供了默认缓存策略,一般考虑关键文件的缓存策略即可。
- 请求与响应实际上存在相当长的链路,链路上的每个节点都有可能存在缓存。
- 缓存的核心是过期-验证机制,简单来说,没过期的就可以直接用,过期了就先问服务器。
- 强缓存、协商缓存是辅助记忆的概念,不是文档规范。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号