第一次个人编程作业
第一次修改:看了大佬的代码,下了Pycharm来跑一下profile,更新性能部分。
-
GitHub链接(3')
首先,应作业要求,先给出GitHub连接
-
PSP表格(6')
| PSP2.1 | Persnal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | 480 | 600 |
| · Analysis | · 需求分析(包括学习新技术) | 100 | 180 |
| · Design Spec | 生成设计文档 | 30 | ---- |
| · Design Review | 设计复审 | 15 | ---- |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 30 |
| · Design | · 具体设计 | 20 | 45 |
| · Coding | · 具体编码 | 60 | 200 |
| · Code Review | · 代码复审 | 20 | 15 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | ---- | ---- |
| · Test Repor | · 测试报告 | ---- | ---- |
| · Size Measurement | · 计算工作量 | ---- | ---- |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ---- | ---- |
| · 合计 | 800 | 1170 | |
| 表格中----的内容为未估计、未做。 |
-
计算机模块的设计与实现过程(18')
这次的作业用到了Python来完成,含有以下几个部分。
文本的输入输出部分
# 文本输入函数,将文本从硬盘读入内存
def Readin(TextAddress):
f = open(TextAddress,"r",encoding="UTF-8")
Str = f.read()
f.close()
return Str
# 结果输入函数,将内存中的结果写入硬盘
def WriteOut(Jaccard, TextAddress):
f = open(TextAddress,"w",encoding="UTF-8")
f.write( str(Jaccard) )
f.close()
Jaccard系数计算部分
这部分是整个程序的核心,当然也不是我自己写出来的。在我面向百度的程序设计的时候,查到文本相似度计算方法。原贴的链接在这儿,(在此感谢这位大佬让我有了做完作业的机会)。这篇文章介绍了几个可以用于计算文本相似度的系数,在用代码跑了几个测试之后,还是选择了好理解、结果也好看的Jaccard系数。
Jaccard系数是一个基于词频的、用于比较有限样本集之间的相似性,系数越大,相似度越高。
用一个例子来解释一下这个过程。
比如有两句话,“你是什么人”,“你是哪里人”。
经过 Sklearn 库中的 CountVectorizer 后得到:
["你", "是", "什", "么", "哪", "里", "人"]
然后再经过 fit_transform 得到:
[ [1 1 1 1 0 0 1]
[1 1 0 0 1 1 1] ]
之后再借助第三方模块 numpy 中的函数来求得这两个集合的交集 numerator 和并集 denominator,Jaccard就等于 numerator / denominator。
在此附上 sklearn(scikit-learn)的 ·官网 和 ·中文文档
至于第三方模块jieba,我放在改进性能来讲。
# Jaccard系数计算模块
# 输入两个string,输出一个int的系数
def Jaccard_Similarity(Str1, Str2):
def Add_Space(Str):
# 引入第三方模块jieba来进行中文分词
Str_list = jieba.cut(Str, cut_all=False)
# 把分词后的词用空格连接成string,以便转化成TF矩阵
return ' '.join(list(Str_list))
Str1, Str2 = Add_Space(Str1), Add_Space(Str2)
# 记录词频,分词器为以' '为分隔符的lambda
cv = CountVectorizer(tokenizer=lambda s: s.split())
corpus = [Str1, Str2]
# 转化为TF(Term Frequencies)矩阵
vectors = cv.fit_transform(corpus).toarray()
# 用第三方模块numpy求交并集
numerator = numpy.sum(numpy.min(vectors,axis=0)) # 交集
denominator = numpy.sum(numpy.max(vectors,axis=0)) # 并集
# 返回Jaccard系数
return 1.0 * numerator / denominator
性能测试部分
# 性能分析函数
def Analyze():
print(u'当前进程的内存使用:%.4f MB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024) )
print(u'当前进程的使用的CPU时间:%.4f s' % (psutil.Process(os.getpid()).cpu_times().user) )
-
计算模块接口部分的性能改进(12')
性能测试来自psutil模块和os模块。
在刚写出代码的时候,没有引入分词系统,只是简单的Jaccard系数。

然后引入了分词系统。

只是增加了运行时间和占用的内存,而我才疏学浅,主要内容也是引用第三方库,暂时无力改进性能
从大佬的博客中学到的Pycharm Profile:
-
函数调用图
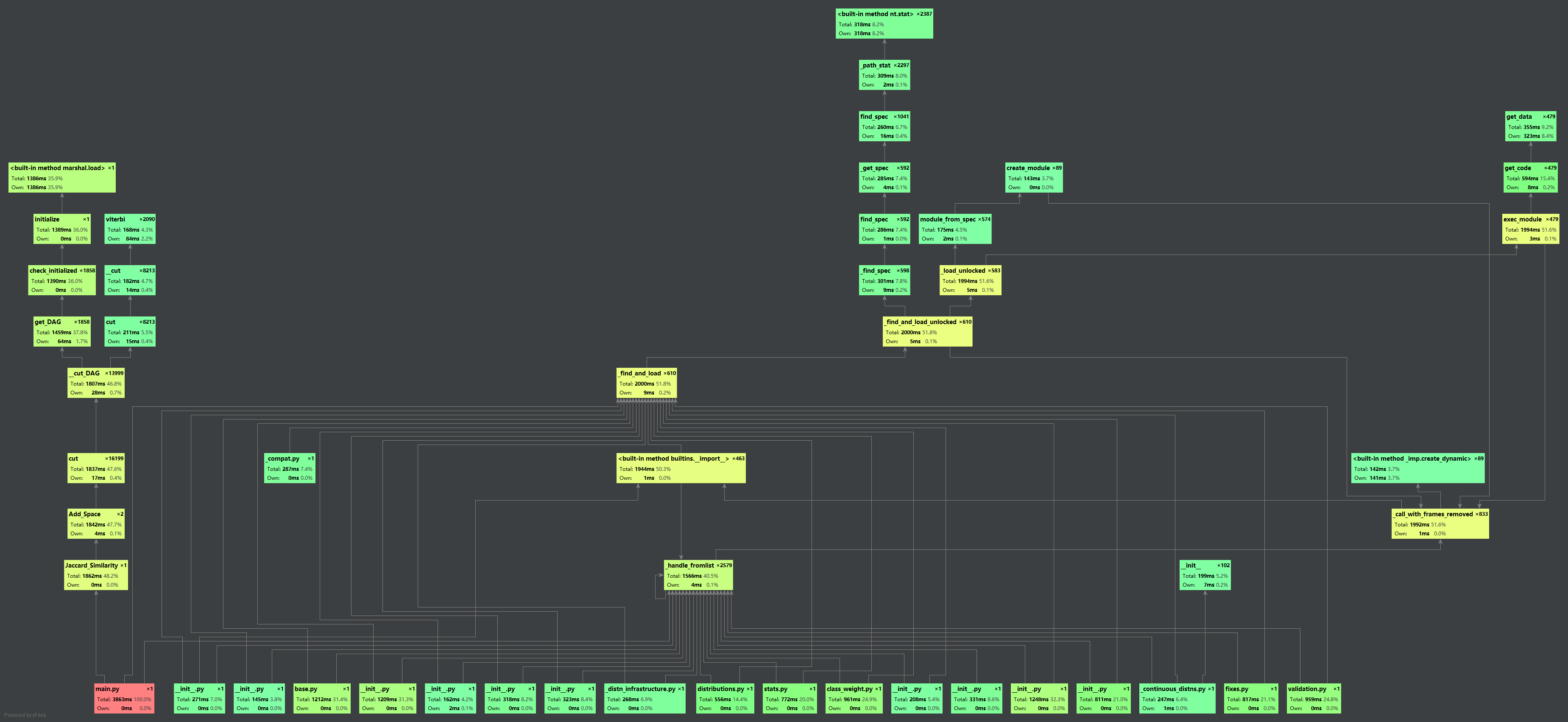
-
各个部分的运行时间
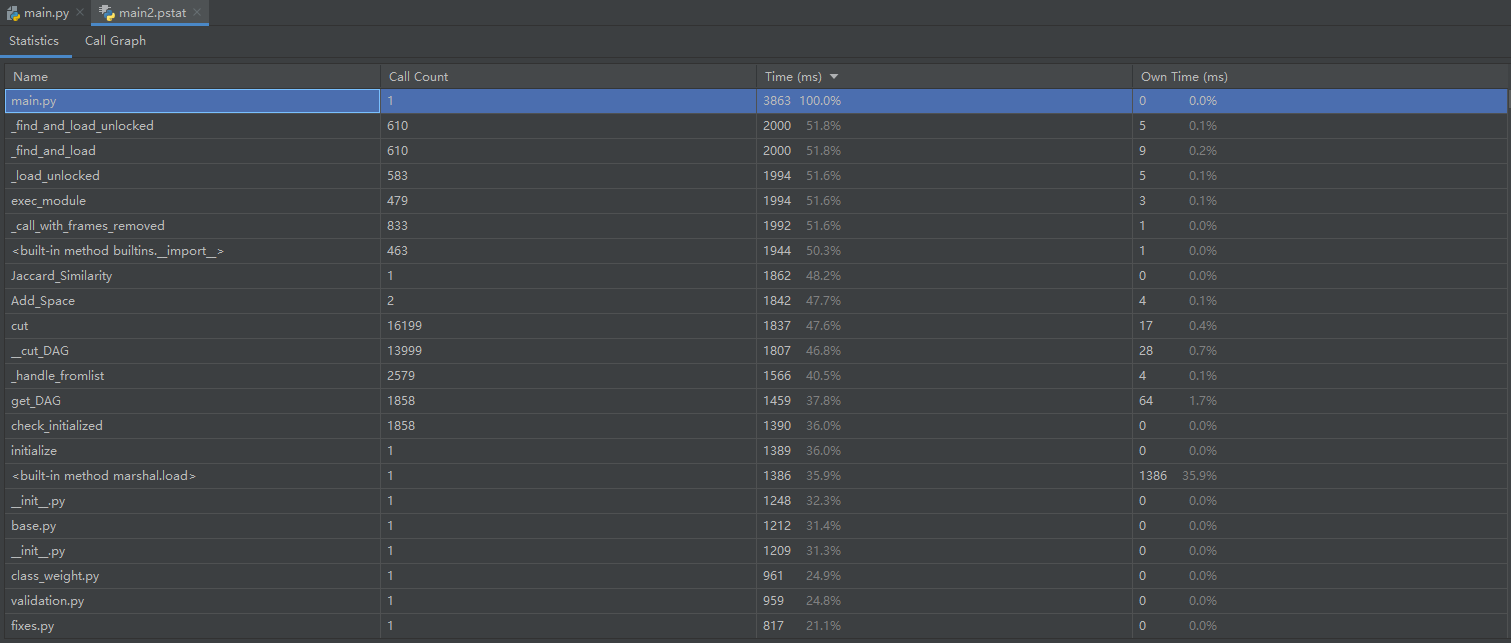
-
整个程序的用时
-
计算模块部分单元测试处理说明(12')
首先是没有分词系统的测试结果:

在图中可以看出来,dis的文本的Jaccard都崩溃了。后来找到结果,因为Jaccard是基于词频的系数,dis文件的将文本中的字序进行改变,那这样一来得到的TF矩阵就没有差别。
为了解决问题,我从大佬们的博客学到了分词,所以就找到了第三方模块,·jieba。
举个例子
["我来自福州大学"]
经过jieba里面的函数之后可以得出:
["我", "来自", "福州大学"]
借此来减轻因为Jaccard系数纯基于词频而导致的结果不如意。
引入了jieba之后:
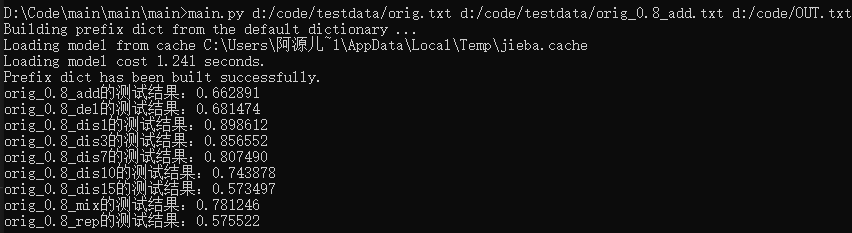
大部分的结果就相对更尽人意。(虽然比不上大佬们个个都在0.8上下的结果,但是对于我这种菜鸡真的是尽力了)
-
计算模块部分异常处理说明(6')
这个方面是我没有想到的,暂时没有内容,希望在今后的学习里面,能有机会学到并且更新博客的这个部分。
-
记录PSP表格(3')
PSP表格已经填写在上面了。
最后是自己的一点瞎逼逼:
1.这门课真的是妙啊,作业一出来的时候就让我觉得我是不是比大家少上了一年的课,咋无从下手呢。在自己学了一点点python之后,似乎稍微能够理解一点“人生苦短,我选Python”了。
2.在自己做作业期间,大佬们开始交博客了,看到大佬们的博客思路又清晰,代码又规范,果然,我还是个垃圾。
3.明明自己花了蛮多时间才写出来的,稍微有点样子的结果,但是在写博客的时候又感觉确实没有做什么东西。好像是做事效率特别低的感觉。
4.不知道后面还有什么样的作业,to be continue。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号