编译原理实验二(全部存储到数组再逐行验证语法版.....这种思路被老师否了,应该是验证一行扔掉一行才对)
编译原理实验二(可能还有BUG,不确定继续找)
要大改一次23333,老师的意思是不能用数组存储,而是一边识别单词,然后识别完一行就判断一次语法
写实验二的时候找到的实验一的一个逻辑错误
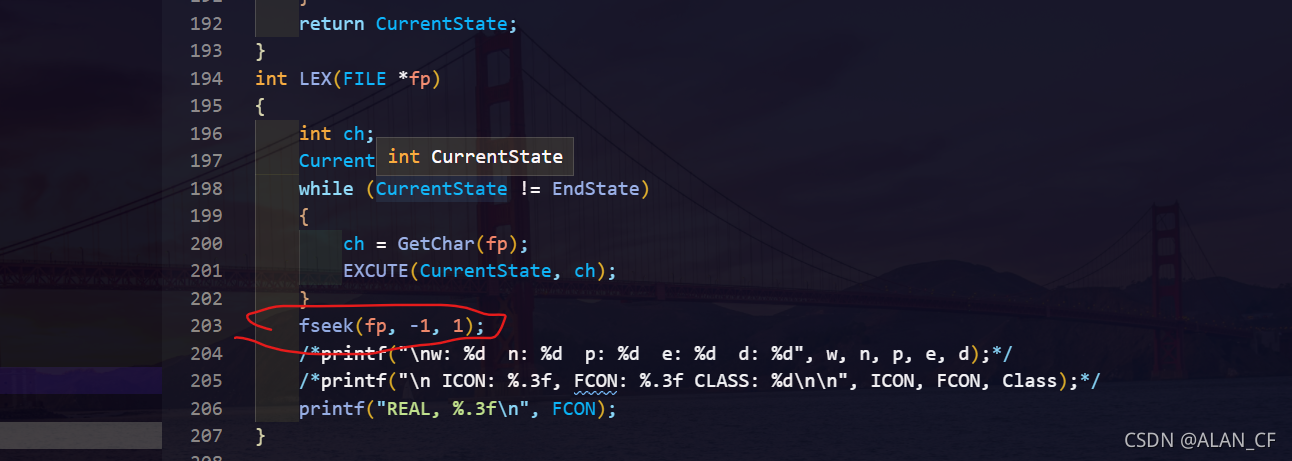
一开始没有写这句回退fp指针,结果就是: “字符c实数字符a字符b”这样的字符串在判断的时候,会在识别出实数之后把fp指针向后多走一位,这样字符A就根本没有被识别的机会,这个事情是在实验二识别基础算术表达式的时候发现的
实验一的结果的显示是.3f,所以太小的数字可能看不见,但是逻辑应该没有问题
改动了实验一的代码,实验一和实验二在一个代码文件中写(文件格式由C改为C++,为后面用栈的时候可以直接调用C++STL的现成的模板 ,代码可能还存在bug?不太清楚)
暂时结果
等待判断的语法公式:
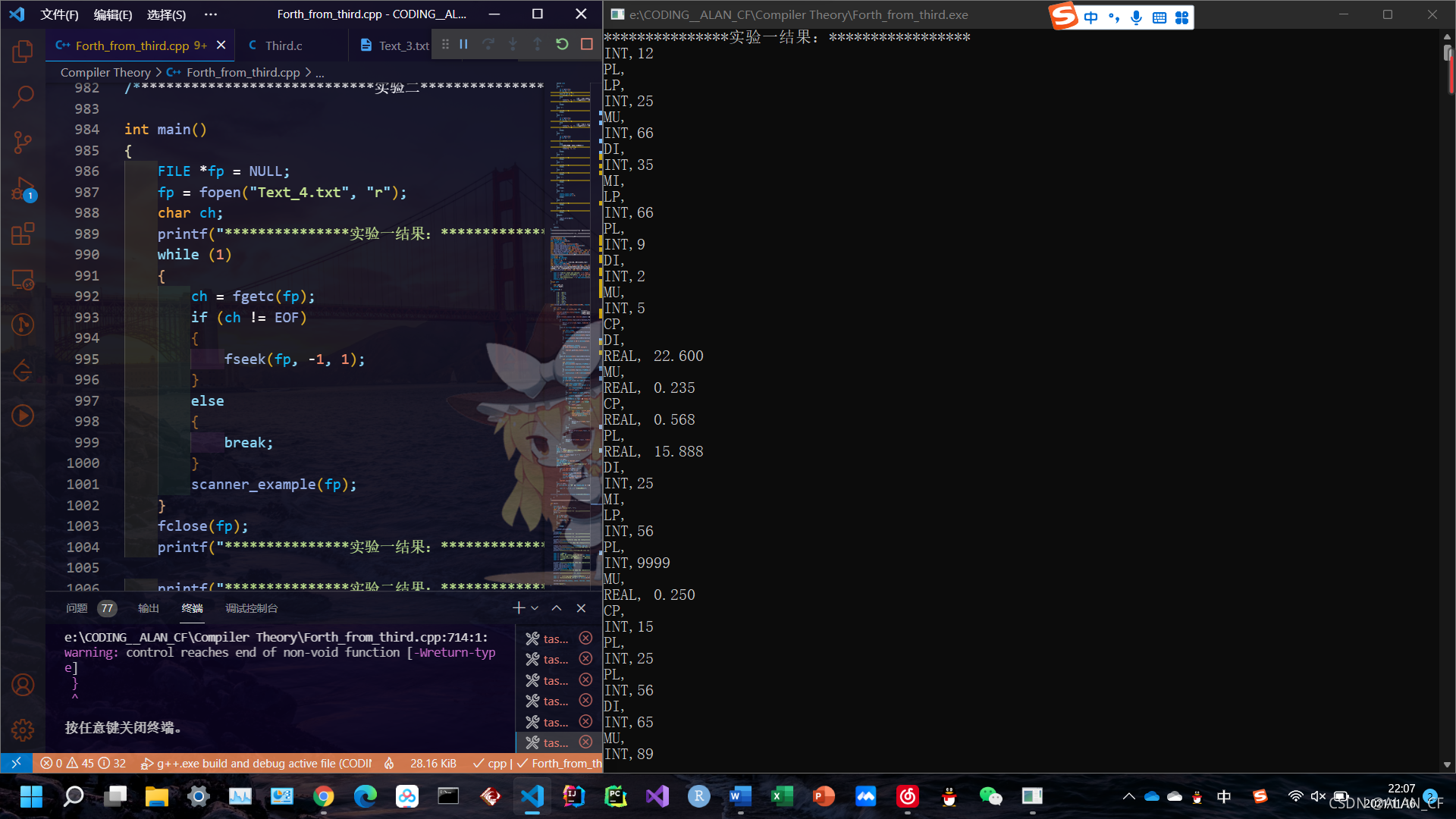
***************实验一结果:*****************
INT,12
PL,
LP,
INT,25
MU,
INT,66
DI,
INT,35
MI,
LP,
INT,66
PL,
INT,9
DI,
INT,2
MU,
INT,5
CP,
DI,
REAL, 22.600
MU,
REAL, 0.235
CP,
REAL, 0.568
PL,
REAL, 15.888
DI,
INT,25
MI,
LP,
INT,56
PL,
INT,9999
MU,
REAL, 0.250
CP,
INT,15
PL,
INT,25
PL,
INT,56
DI,
INT,65
MU,
INT,89
PL,
INT,89
MU,
INT,90
LP,
INT,12
PL,
INT,56
DI,
INT,65
MU,
INT,20
MI,
INT,800
CP,
INT,15
PL,
INT,25
PL,
INT,69
MU,
REAL, 7.630
PL,
REAL, 88.560
MU,
INT,9999
INT,55
PL,
PL,
REAL, 65.560
REAL, 0.236
MU,
MU,
MU,
MU,
INT,56789
REAL, 0.560
LP,
PL,
REAL, 23689.119
LP,
INT,56
PL,
INT,88
PL,
INT,65
REAL, 22.500
CP,
***************实验一结果:*****************
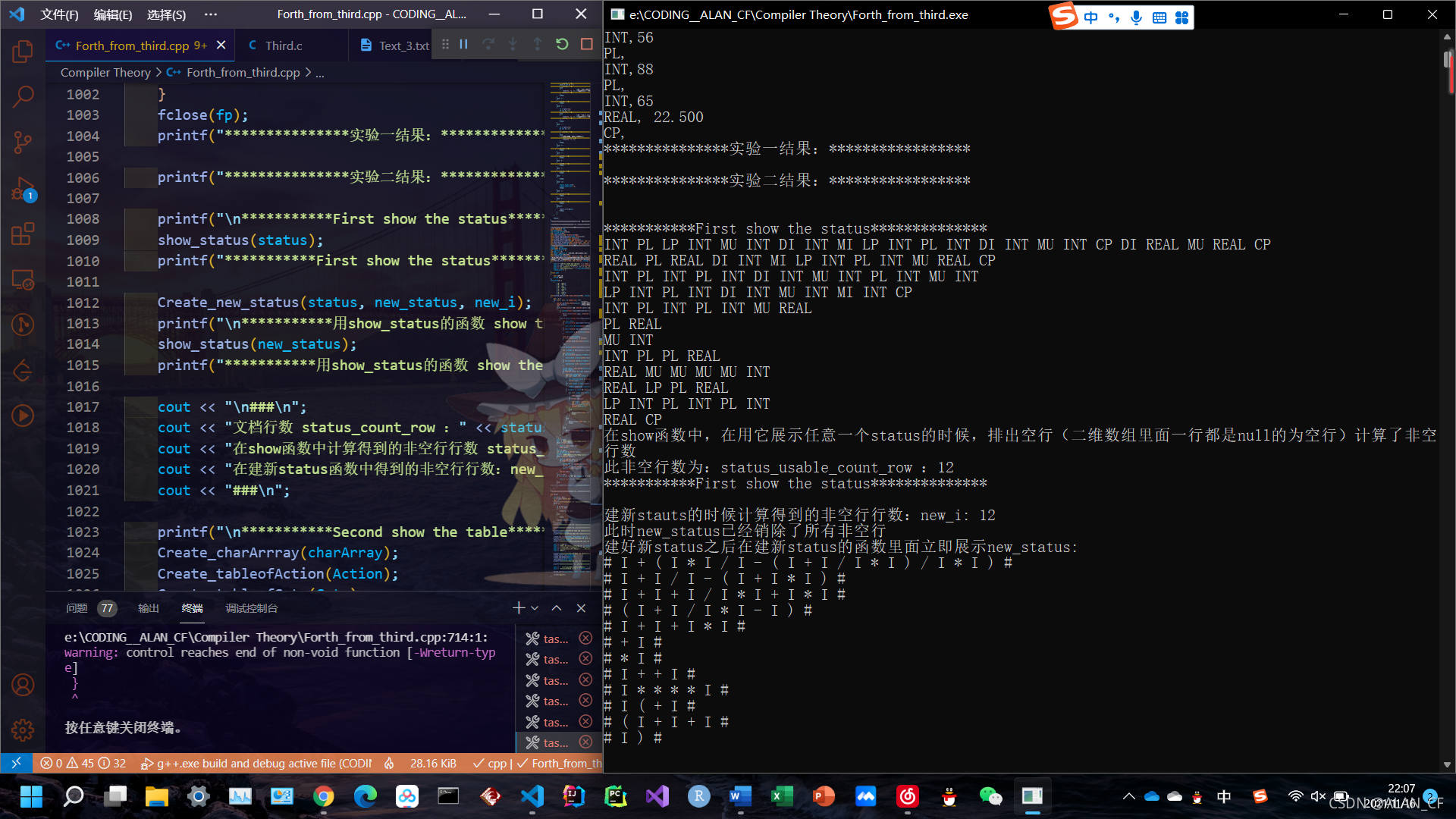
***************实验二结果:*****************
***********First show the status**************
INT PL LP INT MU INT DI INT MI LP INT PL INT DI INT MU INT CP DI REAL MU REAL CP
REAL PL REAL DI INT MI LP INT PL INT MU REAL CP
INT PL INT PL INT DI INT MU INT PL INT MU INT
LP INT PL INT DI INT MU INT MI INT CP
INT PL INT PL INT MU REAL
PL REAL
MU INT
INT PL PL REAL
REAL MU MU MU MU INT
REAL LP PL REAL
LP INT PL INT PL INT
REAL CP
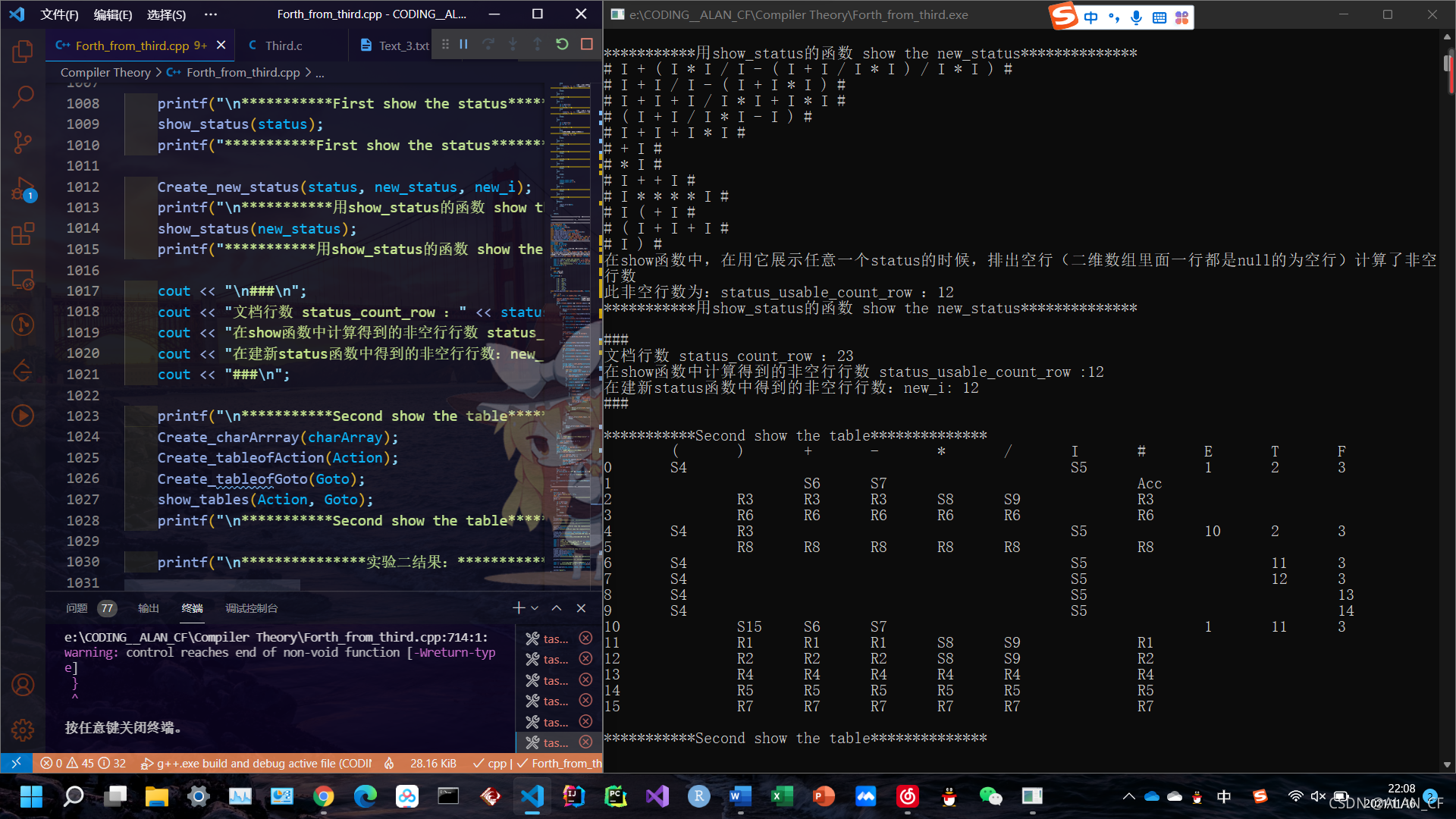
在show函数中,在用它展示任意一个status的时候,排出空行(二维数组里面一行都是null的为空行)计算了非空行数
此非空行数为:status_usable_count_row :12
***********First show the status**************
建新stauts的时候计算得到的非空行行数:new_i: 12
此时new_status已经销除了所有非空行
建好新status之后在建新status的函数里面立即展示new_status:
# I + ( I * I / I - ( I + I / I * I ) / I * I ) #
# I + I / I - ( I + I * I ) #
# I + I + I / I * I + I * I #
# ( I + I / I * I - I ) #
# I + I + I * I #
# + I #
# * I #
# I + + I #
# I * * * * I #
# I ( + I #
# ( I + I + I #
# I ) #
***********用show_status的函数 show the new_status**************
# I + ( I * I / I - ( I + I / I * I ) / I * I ) #
# I + I / I - ( I + I * I ) #
# I + I + I / I * I + I * I #
# ( I + I / I * I - I ) #
# I + I + I * I #
# + I #
# * I #
# I + + I #
# I * * * * I #
# I ( + I #
# ( I + I + I #
# I ) #
在show函数中,在用它展示任意一个status的时候,排出空行(二维数组里面一行都是null的为空行)计算了非空行数
此非空行数为:status_usable_count_row :12
***********用show_status的函数 show the new_status**************
###
文档行数 status_count_row :23
在show函数中计算得到的非空行行数 status_usable_count_row :12
在建新status函数中得到的非空行行数:new_i: 12
###
***********Second show the table**************
( ) + - * / I # E T F
0 S4 S5 1 2 3
1 S6 S7 Acc
2 R3 R3 R3 S8 S9 R3
3 R6 R6 R6 R6 R6 R6
4 S4 R3 S5 10 2 3
5 R8 R8 R8 R8 R8 R8
6 S4 S5 11 3
7 S4 S5 12 3
8 S4 S5 13
9 S4 S5 14
10 S15 S6 S7 1 11 3
11 R1 R1 R1 S8 S9 R1
12 R2 R2 R2 S8 S9 R2
13 R4 R4 R4 R4 R4 R4
14 R5 R5 R5 R5 R5 R5
15 R7 R7 R7 R7 R7 R7
***********Second show the table**************
***************实验二结果:*****************
检验string类的at(index)函数的效果
Action[0][0]的第0位: S
Action[0][0]的第1位: 4
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
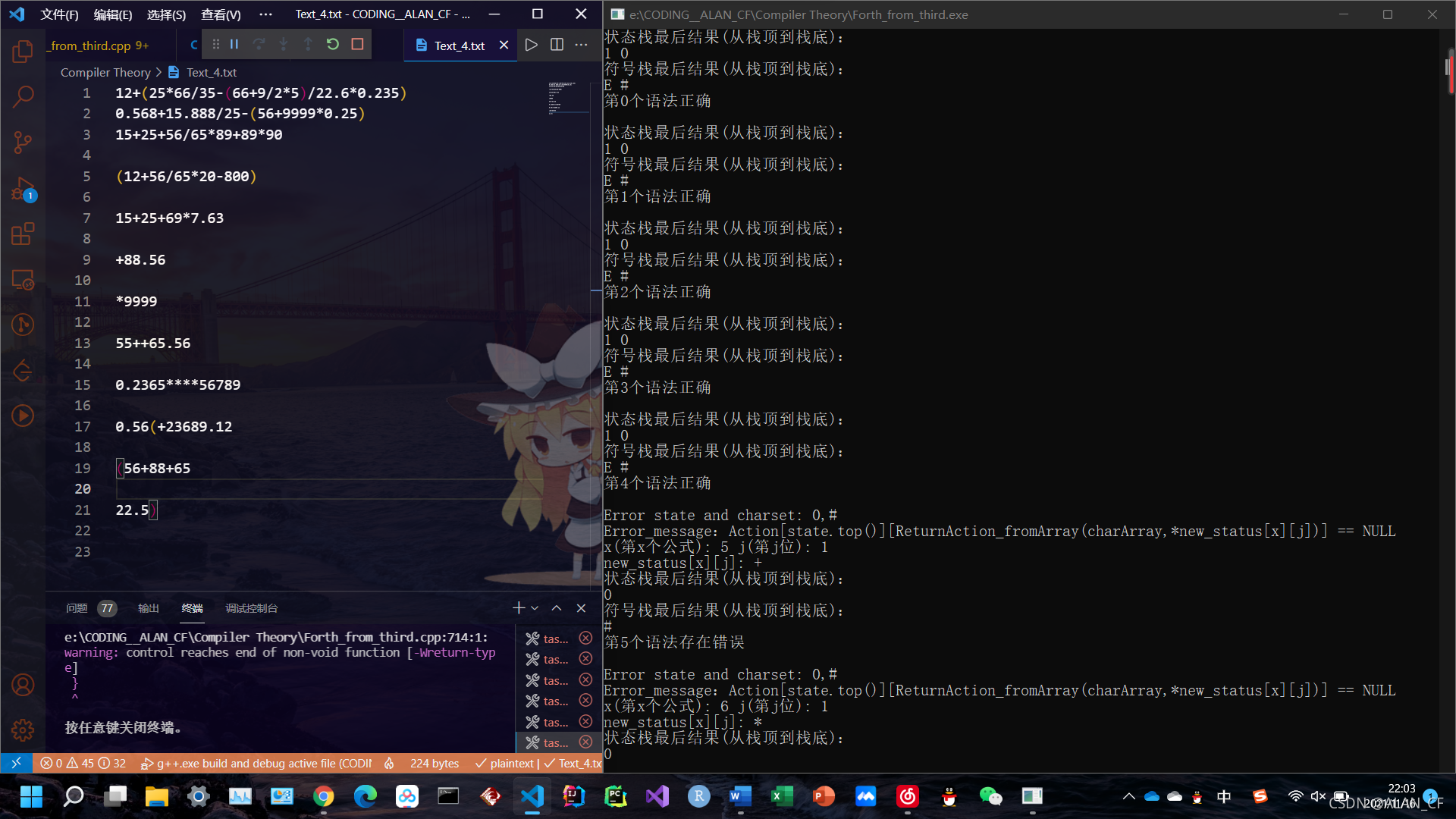
第0个语法正确
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
第1个语法正确
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
第2个语法正确
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
第3个语法正确
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
第4个语法正确
Error state and charset: 0,#
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 5 j(第j位): 1
new_status[x][j]: +
状态栈最后结果(从栈顶到栈底):
0
符号栈最后结果(从栈顶到栈底):
#
第5个语法存在错误
Error state and charset: 0,#
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 6 j(第j位): 1
new_status[x][j]: *
状态栈最后结果(从栈顶到栈底):
0
符号栈最后结果(从栈顶到栈底):
#
第6个语法存在错误
Error state and charset: 6,+
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 7 j(第j位): 3
new_status[x][j]: +
状态栈最后结果(从栈顶到栈底):
6 1 0
符号栈最后结果(从栈顶到栈底):
+ E #
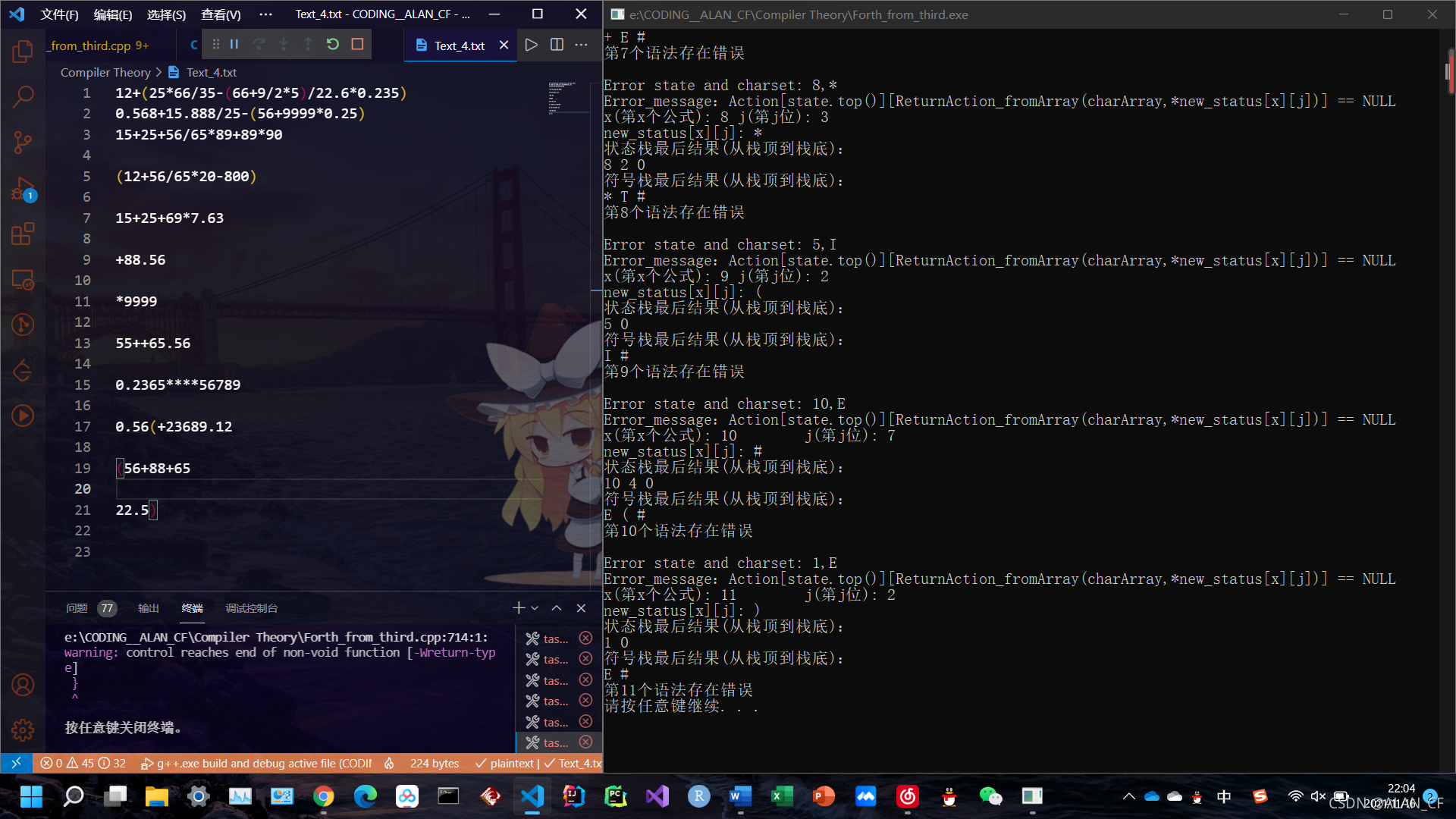
第7个语法存在错误
Error state and charset: 8,*
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 8 j(第j位): 3
new_status[x][j]: *
状态栈最后结果(从栈顶到栈底):
8 2 0
符号栈最后结果(从栈顶到栈底):
* T #
第8个语法存在错误
Error state and charset: 5,I
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 9 j(第j位): 2
new_status[x][j]: (
状态栈最后结果(从栈顶到栈底):
5 0
符号栈最后结果(从栈顶到栈底):
I #
第9个语法存在错误
Error state and charset: 10,E
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 10 j(第j位): 7
new_status[x][j]: #
状态栈最后结果(从栈顶到栈底):
10 4 0
符号栈最后结果(从栈顶到栈底):
E ( #
第10个语法存在错误
Error state and charset: 1,E
Error_message:Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL
x(第x个公式): 11 j(第j位): 2
new_status[x][j]: )
状态栈最后结果(从栈顶到栈底):
1 0
符号栈最后结果(从栈顶到栈底):
E #
第11个语法存在错误
请按任意键继续. . .
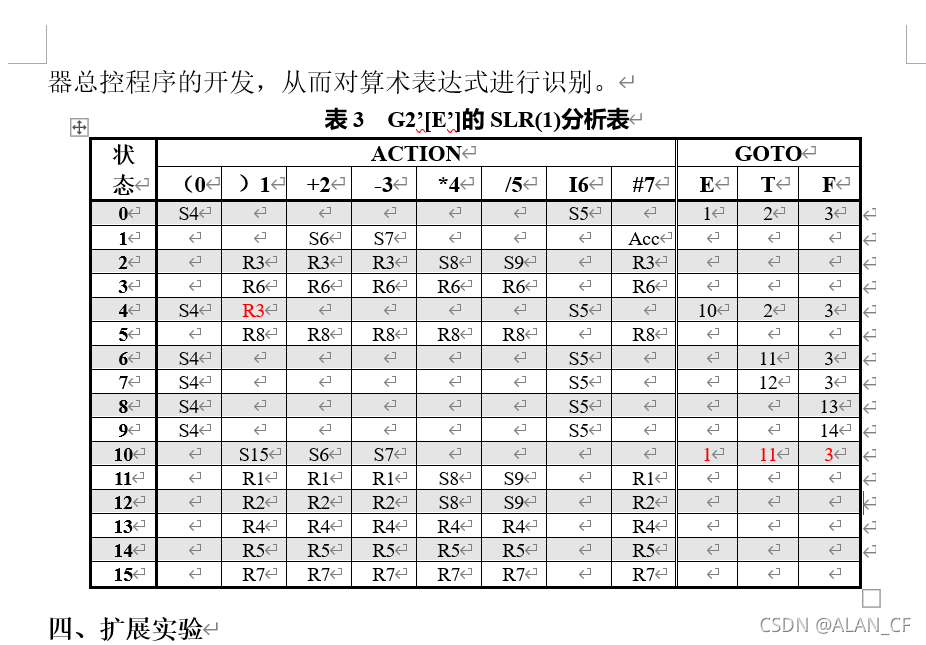
(4)SLR(1)分析器的开发
首先,对于分析对象,即算术表达式的文法G2[E],引入一个新的开始符号E’,得到G2[E]的拓广文法G2’[E’]:
0. E’→E
- E→E+T
- E→E-T
- E→T
- T→T*F
- T→T/F
- T→F
- F→(E)
- F→i
求出文法中各个非终结符号的FOLLOW集如下:
Follow(E)={#,),+,-}
Follow(T)={#,),+,-,,/}
Follow(F)={#,),+,-,,/}
然后,根据文法G2’[E’]构造识别其全部活前缀的DFA,以便据此构造如表3所示的SLR(1)分析表,并设计好存放分析表的数据结构。
最后,可参考教材P149程序4-6,设置状态栈、符号栈等,编写移进、归约、接受及报错等模块,实现SLR(1)分析表的驱动程序,即完成LR分析器总控程序的开发,从而对算术表达式进行识别。
感觉是不是指导书的表有问题(解决不了(E)–> F),我改动了这个SLR表(红字)
代码暂时先这样,继续找bug
#include <iostream>
#include <cstring>
#include <math.h>
#include <stdlib.h>
#include <string>
#include <stack>
#define ID 7 /*标识符*/
#define INT 8 /*整型常数*/
#define REAL 9 /*实型常数*/
#define LT 10 /*<*/
#define LE 11 /*<=*/
#define EQ 12 /*=*/
#define NE 13 /*<>*/
#define GT 14 /*>*/
#define GE 15 /*>=*/
#define IS 16 /*:=*/
#define PL 17 /*+*/
#define MI 18 /*-*/
#define MU 19 /***/
#define DI 20 /*/*/
#define LP 21 /*(*/
#define CP 22 /*)*/
/****************************判断实数**************************************/
#define DIGIT 1
#define POINT 2
#define OTHER 3
#define POWER 4
#define PLUS 5
#define MINUS 6
#define UCON 7
/*Suppose the class number of unsigned constant is 7
假设无符号常量的类数为7*/
#define ClassOther 200
#define EndState -1
int w, n, p, e, d;
int Class;
/*Used to indicate class of the word
用来表示单词的类别*/
int ICON;
float FCON;
static int CurrentState;
/***********保存所有的状态在一个二维字符串数组里(文件有几行,状态有几行)(为实验二做准备)*************/
char *status[50][100];
int status_count_row = 0;
int status_count_col = 0;
int status_usable_count_row = 0;
/**********保存所有的状态在一个二维字符串数组里(文件有几行,状态有几行)(为实验二做准备)**************/
/*Used to present current state, the initial value:0
用于表示当前状态,初始值:0*/
int GetChar(void);
int EXCUTE(int, int);
int HandleOtherWord(void)
{
return ClassOther;
}
int HandleError(void)
{
printf("Error!\n");
return 0;
}
int GetChar(FILE *fp)
{
int c;
c = fgetc(fp);
if (isdigit(c))
{
d = c - '0';
return DIGIT;
}
if (c == '.')
return POINT;
if (c == 'E' || c == 'e')
return POWER;
if (c == '+')
return PLUS;
if (c == '-')
return MINUS;
return OTHER;
}
int EXCUTE(int state, int symbol)
{
switch (state)
{
case 0:
switch (symbol)
{
case DIGIT:
n = 0;
p = 0;
e = 1;
w = d;
CurrentState = 1;
Class = UCON;
break;
case POINT:
w = 0;
n = 0;
p = 0;
e = 1;
CurrentState = 3;
Class = UCON;
break;
default:
HandleOtherWord();
Class = ClassOther;
CurrentState = EndState;
}
break;
case 1:
switch (symbol)
{
case DIGIT:
w = w * 10 + d;
break; //CurrentState=1
case POINT:
CurrentState = 2;
break;
case POWER:
CurrentState = 4;
break;
default:
ICON = w;
CurrentState = EndState;
}
break;
case 2:
switch (symbol)
{
case DIGIT:
n++;
w = w * 10 + d;
break;
case POWER:
CurrentState = 4;
break;
default:
FCON = w * pow(10, e * p - n);
CurrentState = EndState;
}
break;
case 3:
switch (symbol)
{
case DIGIT:
n++;
w = w * 10 + d;
CurrentState = 2;
break;
default:
HandleError();
CurrentState = EndState;
}
break;
case 4:
switch (symbol)
{
case DIGIT:
p = p * 10 + d;
CurrentState = 6;
break;
case MINUS:
e = -1;
CurrentState = 5;
break;
case PLUS:
CurrentState = 5;
break;
default:
HandleError();
CurrentState = EndState;
}
break;
case 5:
switch (symbol)
{
case DIGIT:
p = p * 10 + d;
CurrentState = 6;
break;
default:
HandleError();
CurrentState = EndState;
}
break;
case 6:
switch (symbol)
{
case DIGIT:
p = p * 10 + d;
break;
default:
FCON = w * pow(10, e * p - n);
CurrentState = EndState;
}
break;
}
return CurrentState;
}
int LEX(FILE *fp)
{
int ch;
CurrentState = 0;
while (CurrentState != EndState)
{
ch = GetChar(fp);
EXCUTE(CurrentState, ch);
}
fseek(fp, -1, 1);
/*printf("\nw: %d n: %d p: %d e: %d d: %d", w, n, p, e, d);*/
/*printf("\n ICON: %.3f, FCON: %.3f CLASS: %d\n\n", ICON, FCON, Class);*/
printf("REAL, %.3f\n", FCON);
status[status_count_row][status_count_col] = "REAL";
status_count_col++;
}
/***********************************判断实数***********************************/
/************************************判断是否是保留字********************************/
/* 建立保留字表 */
#define MAX_KEY_NUMBER 20 /*关键字的数量*/
#define KEY_WORD_END "waiting for your expanding" /*关键字结束标记*/
char *KeyWordTable[MAX_KEY_NUMBER] = {"begin", "end", "if", "then", "else", "switch", "case", KEY_WORD_END};
/* 查保留字表,判断是否为关键字
不是关键字,返回0,是关键字,返回n+1, n为关键字数组中所找到的相同的关键字的索引位置*/
int lookup(char *token)
{
int n = 0;
while (strcmp(KeyWordTable[n], KEY_WORD_END)) /*如果比较到最后一位,也就是KEY_WORD_END,也就是已经确定都没有相同的,返回0*/
{
/*strcmp比较两串是否相同,若相同返回0*/
/*相等:strcmp函数返回0,加上!后为:TRUE 进入if内部执行语句;
不相等: strcmp返回其他正数或负数,这些返回值都等价于:TRUE ,加上!后,都为:FALSE 不进入if内部语句*/
if (!strcmp(KeyWordTable[n], token))
{
return n + 1; /*根据单词分类码表I,设置正确的关键字类别码,并返回此类别码的值*/
break;
}
n++;
}
return 0; /*单词不是关键字,而是标识符*/
}
/************************************判断是否是保留字***************************************/
/**********************************非实数的所有显示与报错*********************************************/
void report_error(char *s)
{
printf("Having Error:%s\n", s);
status[status_count_row][status_count_col] = "Having Error in word";
status_count_col++;
}
void out(int x, char *s)
{
switch (x)
{
case 7:
{
printf("%s,%s\n", "ID", s);
status[status_count_row][status_count_col] = "ID";
status_count_col++;
break;
}
case 8:
{
printf("%s,%s\n", "INT", s);
status[status_count_row][status_count_col] = "INT";
status_count_col++;
break;
}
case 10:
{
printf("%s,%s\n", "LT", s);
status[status_count_row][status_count_col] = "LT";
status_count_col++;
break;
}
case 11:
{
printf("%s,%s\n", "LE", s);
status[status_count_row][status_count_col] = "LE";
status_count_col++;
break;
}
case 12:
{
printf("%s,%s\n", "EQ", s);
status[status_count_row][status_count_col] = "EQ";
status_count_col++;
break;
}
case 13:
{
printf("%s,%s\n", "NE", s);
status[status_count_row][status_count_col] = "NE";
status_count_col++;
break;
}
case 14:
{
printf("%s,%s\n", "GT", s);
status[status_count_row][status_count_col] = "GT";
status_count_col++;
break;
}
case 15:
{
printf("%s,%s\n", "GE", s);
status[status_count_row][status_count_col] = "GE";
status_count_col++;
break;
}
case 16:
{
printf("%s,%s\n", "IS", s);
status[status_count_row][status_count_col] = "IS";
status_count_col++;
break;
}
case 17:
{
printf("%s,%s\n", "PL", s);
status[status_count_row][status_count_col] = "PL";
status_count_col++;
break;
}
case 18:
{
printf("%s,%s\n", "MI", s);
status[status_count_row][status_count_col] = "MI";
status_count_col++;
break;
}
case 19:
{
printf("%s,%s\n", "MU", s);
status[status_count_row][status_count_col] = "MU";
status_count_col++;
break;
}
case 20:
{
printf("%s,%s\n", "DI", s);
status[status_count_row][status_count_col] = "DI";
status_count_col++;
break;
}
case 21:
{
printf("%s,%s\n", "LP", s);
status[status_count_row][status_count_col] = "LP";
status_count_col++;
break;
}
case 22:
{
printf("%s,%s\n", "CP", s);
status[status_count_row][status_count_col] = "CP";
status_count_col++;
break;
}
default:
{
printf("%s,%s\n", KeyWordTable[x], s);
status[status_count_row][status_count_col] = KeyWordTable[x];
status_count_col++;
break;
}
}
}
/**********************************非实数的所有显示与报错*********************************************/
/**********************************扫描一次*********************************************/
void scanner_example(FILE *fp)
{
char TOKEN[20] = {};
char ch;
int i = 0;
int c = 0;
ch = fgetc(fp); /*取出一个字符*/
/*首字符为字母,字母数字混杂*/
if (isalpha(ch)) /*是否是字母*/
{
TOKEN[0] = ch;
ch = fgetc(fp); /*取出下一个字符*/
i = 1;
while (isalnum(ch)) /*是否是字母或者数字*/
{
TOKEN[i] = ch;
i++;
ch = fgetc(fp); /*取出一个字符*/
}
/*跳出循环之后,fp指针指向的字符,不再是数字或者字母*/
fseek(fp, -1, 1); /*fp指针从当前位置往前挪一位*/
c = lookup(TOKEN); /*判断是否是关键字,不是的话返回0*/
if (c == 0)
out(ID, TOKEN);
else
out(c - 1, " "); /*因为lookup函数返回值为n+1*/
}
/*首字符是数字,整型数字*/
else if (isdigit(ch)) /*是否是数字*/
{
TOKEN[0] = ch;
ch = fgetc(fp); /*取出第二个字符*/
i = 1;
while (isdigit(ch)) /*后面取出的字符都依然是数字*/
{
TOKEN[i] = ch;
i++;
ch = fgetc(fp);
}
/*跳出循环之后,fp指针指向的字符,不再是数字*/
if (ch != 'E' && ch != 'e' && ch != '.')
{
fseek(fp, -1, 1); /*fp指针从当前位置往前挪一位*/
out(INT, TOKEN);
}
else /*考虑实型常数*/
{
fseek(fp, -(i + 1), 1);
LEX(fp);
}
}
else
{
switch (ch)
{
case '<':
{
ch = fgetc(fp);
if (ch == '=')
out(LE, " ");
else if (ch == '>')
out(NE, " ");
else
{ /*下一位不是=或者> :当做只有< */
fseek(fp, -1, 1); /*fp指针从当前位置往前挪一位*/
out(LT, " ");
}
break;
}
case '=':
{
out(EQ, " ");
break;
}
case '>':
{
ch = fgetc(fp);
if (ch == '=')
out(GE, " ");
else
{ /*下一位不是= :当做只有> */
fseek(fp, -1, 1); /*fp指针从当前位置往前挪一位*/
out(GT, " ");
}
break;
}
case ':':
{
ch = fgetc(fp);
if (ch == '=')
{
out(IS, " ");
}
else
{ /*冒号后面跟着的不是等号的话*/
report_error(":");
fseek(fp, -1, 1);
}
break;
}
case '+':
{
out(PL, " ");
break;
}
case '-':
{
out(MI, " ");
break;
}
case '*':
{
out(MU, " ");
break;
}
case '/':
{
out(DI, " ");
break;
}
case ' ':
{
break;
}
case '\n':
{
status_count_row++;
status_count_col = 0;
break;
}
case '(':
{
out(LP, " ");
break;
}
case ')':
{
out(CP, " ");
break;
}
default:
{
report_error(&ch);
break;
}
}
}
return;
}
/**********************************扫描一次*********************************************/
/*****************************实验二***************************************************/
/****************************建表*********************/
using namespace std;
int Goto[16][3] = {0};
std::string Action[16][8];
char charArray[50];
void show_status(char *status[][100])
{
int j = 0;
for (int i = 0; i <= status_count_row; i++)
{
while (status[i][j] != nullptr)
{
cout << status[i][j] << " ";
j++;
}
if (j != 0)
{
cout << endl;
j = 0;
if (status[i][0] != "#")
{
status_usable_count_row++;
/*计算非空行行数*/
}
}
}
cout << "在show函数中,在用它展示任意一个status的时候,排出空行(二维数组里面一行都是null的为空行)计算了非空行数" << endl;
cout << "此非空行数为:status_usable_count_row :" << status_usable_count_row << endl;
}
void Create_tableofAction(string Action[][8])
{
Action[0][0] = "S4";
Action[0][6] = "S5";
Action[1][2] = "S6";
Action[1][3] = "S7";
Action[1][7] = "Acc";
Action[2][1] = "R3";
Action[2][2] = "R3";
Action[2][3] = "R3";
Action[2][4] = "S8";
Action[2][5] = "S9";
Action[2][7] = "R3";
Action[3][1] = "R6";
Action[3][2] = "R6";
Action[3][3] = "R6";
Action[3][4] = "R6";
Action[3][5] = "R6";
Action[3][7] = "R6";
Action[4][0] = "S4";
Action[4][1] = "R3";
Action[4][6] = "S5";
Action[5][1] = "R8";
Action[5][2] = "R8";
Action[5][3] = "R8";
Action[5][4] = "R8";
Action[5][5] = "R8";
Action[5][7] = "R8";
Action[6][0] = "S4";
Action[6][6] = "S5";
Action[7][0] = "S4";
Action[7][6] = "S5";
Action[8][0] = "S4";
Action[8][6] = "S5";
Action[9][0] = "S4";
Action[9][6] = "S5";
Action[10][1] = "S15";
Action[10][2] = "S6";
Action[10][3] = "S7";
Action[11][1] = "R1";
Action[11][2] = "R1";
Action[11][3] = "R1";
Action[11][4] = "S8";
Action[11][5] = "S9";
Action[11][7] = "R1";
Action[12][1] = "R2";
Action[12][2] = "R2";
Action[12][3] = "R2";
Action[12][4] = "S8";
Action[12][5] = "S9";
Action[12][7] = "R2";
Action[13][1] = "R4";
Action[13][2] = "R4";
Action[13][3] = "R4";
Action[13][4] = "R4";
Action[13][5] = "R4";
Action[13][7] = "R4";
Action[14][1] = "R5";
Action[14][2] = "R5";
Action[14][3] = "R5";
Action[14][4] = "R5";
Action[14][5] = "R5";
Action[14][7] = "R5";
Action[15][1] = "R7";
Action[15][2] = "R7";
Action[15][3] = "R7";
Action[15][4] = "R7";
Action[15][5] = "R7";
Action[15][7] = "R7";
}
void Create_tableofGoto(int Goto[][3])
{
Goto[0][0] = 1;
Goto[0][1] = 2;
Goto[0][2] = 3;
Goto[4][0] = 10;
Goto[4][1] = 2;
Goto[4][2] = 3;
Goto[6][1] = 11;
Goto[6][2] = 3;
Goto[7][1] = 12;
Goto[7][2] = 3;
Goto[8][2] = 13;
Goto[9][2] = 14;
Goto[10][2] = 3;
Goto[10][1] = 11;
Goto[10][0] = 1;
}
void Create_charArrray(char charArray[])
{
charArray[0] = '(';
charArray[1] = ')';
charArray[2] = '+';
charArray[3] = '-';
charArray[4] = '*';
charArray[5] = '/';
charArray[6] = 'I';
charArray[7] = '#';
charArray[8] = 'E';
charArray[9] = 'T';
charArray[10] = 'F';
}
int ReturnAction_fromArray(char charArray[], char ch)
{
for (int i = 0; i <= 7; i++)
{
if (ch == charArray[i])
{
return i;
}
}
}
int ReturnGoto_fromArray(char charArray[], char ch)
{
for (int i = 8; i < 11; i++)
{
if (ch == charArray[i])
{
return i;
}
}
}
void show_tables(string Action[][8], int Goto[][3])
{
cout << "\t";
for (int i = 0; i < 11; i++)
{
cout << charArray[i] << '\t';
}
cout << endl;
for (int i = 0; i < 16; i++)
{
cout << i << "\t";
for (int j = 0; j < 8; j++)
{
cout << Action[i][j] << "\t";
}
for (int j = 0; j < 3; j++)
{
if (Goto[i][j] != 0)
{
cout << Goto[i][j] << "\t";
}
else
{
cout << "\t";
}
}
cout << endl;
}
}
/****************************建表*********************/
stack<int> state;
stack<char *> charset;
int status_error = 0;
int new_i_x = 0;
int *new_i = &new_i_x; /*有用的行数==usable_row*/
char *new_status[50][100];
void Create_new_status(char *status[][100], char *new_status[][100], int *new_i)
{
int j = 0;
for (int i = 0; i <= status_count_row; i++)
{
if (status[i][0] != nullptr)
{
new_status[*new_i][0] = "#";
while (status[i][j] != nullptr)
{
if (status[i][j] == "REAL" || status[i][j] == "INT")
{
new_status[*new_i][j + 1] = "I";
}
else
{
if (status[i][j] == "PL")
{
new_status[*new_i][j + 1] = "+";
}
else
{
if (status[i][j] == "MI")
{
new_status[*new_i][j + 1] = "-";
}
else
{
if (status[i][j] == "MU")
{
new_status[*new_i][j + 1] = "*";
}
else
{
if (status[i][j] == "DI")
{
new_status[*new_i][j + 1] = "/";
}
else
{
if (status[i][j] == "LP")
{
new_status[*new_i][j + 1] = "(";
}
else
{
new_status[*new_i][j + 1] = ")";
}
}
}
}
}
}
j++;
}
new_status[*new_i][j + 1] = "#";
(*new_i)++;
}
j = 0;
}
/*有用的行数:new_i*/
cout << "建新stauts的时候计算得到的非空行行数:new_i: " << *new_i << endl;
cout << "此时new_status已经销除了所有非空行" << endl;
cout << "建好新status之后在建新status的函数里面立即展示new_status:" << endl;
for (int i = 0; i < *new_i; i++)
{
while (new_status[i][j] != nullptr)
{
cout << new_status[i][j] << " ";
j++;
}
j = 0;
cout << endl;
}
}
/*R1-8:右部文法用string字符串存储,左部文法用char单个字符存储、右部文法字符串长度int
从符号栈中取出字符组成临时string字符串与右部文法的string字符串比较*/
void Return_error(int state, char charset, string Error_message, int x, int j)
{
cout << "\nError state and charset: " << state << "," << charset;
cout << endl<< "Error_message:" << Error_message << endl;
cout << "x(第x个公式): " << x << '\t' << "j(第j位): " << j << endl;
cout << "new_status[x][j]: " << new_status[x][j];
status_error = 1;
}
struct Left
{
char Left_ch;
string Right;
};
Left wenfa[8] =
{
{'E', "E+T"},
{'E', "E-T"},
{'E', "T"},
{'T', "T*F"},
{'T', "T/F"},
{'T', "F"},
{'F', "(E)"},
{'F', "I"}};
void Second_operate(char *new_status[][100], stack<int> state, stack<char *> charset, int usable_row, Left left_wenfa[])
{
int j = 0;
for (int x = 0; x < usable_row; x++)
{ /*每个非空行的文法判断*/
charset.push(new_status[x][j]); /*符号栈压入#*/
state.push(j); /*状态栈压入0*/
j++;
while (!state.empty() && !charset.empty() && Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])] != "Acc")
{
if (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])] == "")
{
Return_error(state.top(), *charset.top(), "Action[state.top()][ReturnAction_fromArray(charArray,*new_status[x][j])] == NULL", x, j);
break;
}
else if (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].at(0) == 'S')
{
int next_state;
if (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].length() == 2)
{
next_state = Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].at(1) - '0';
}
if (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].length() == 3)
{
next_state = 10 * (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].at(1) - '0') + (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].at(2) - '0');
}
state.push(next_state);
if (new_status[x][j] != nullptr)
{
charset.push(new_status[x][j]);
}
j++;
}
else if (Action[state.top()][ReturnAction_fromArray(charArray, *new_status[x][j])].at(0) == 'R')
{
int i_fromNew = ReturnAction_fromArray(charArray, *(new_status[x][j]));
int instruction;
if (Action[state.top()][i_fromNew].length() == 2)
{
instruction = Action[state.top()][i_fromNew].at(1) - '0';
}
if (Action[state.top()][i_fromNew].length() == 3)
{
instruction = 10 * (Action[state.top()][i_fromNew].at(1) - '0') + (Action[state.top()][i_fromNew].at(2) - '0');
}
string right = left_wenfa[instruction - 1].Right;
string compare;
if (charset.size() >= right.length())
{
char *fan_compare[3];
for (int length = 0; length < right.length(); length++)
{
fan_compare[length] = charset.top();
charset.pop();
}
for (int length = right.length() - 1; length >= 0; length--)
{
compare.append(fan_compare[length]);
}
if (compare == right && state.size() >= right.length())
{
for (int length = 0; length < right.length(); length++)
{
state.pop();
}
if (!state.empty())
{
char *leftx = &left_wenfa[instruction - 1].Left_ch;
int i_leftx = ReturnGoto_fromArray(charArray, *leftx) - 8;
state.push(Goto[state.top()][i_leftx]);
charset.push(leftx);
}
else
{
Return_error(state.top(), *charset.top(), "state.empty()", x, j);
break;
}
}
else
{
Return_error(state.top(), *charset.top(), "!(compare == right && state.size() >= right.length())", x, j);
break;
}
}
else
{
Return_error(state.top(), *charset.top(), "!(charset.size() >= right.length())", x, j);
break;
}
}
}
j = 0;
cout << endl;
cout << "状态栈最后结果(从栈顶到栈底):" << endl;
while (!state.empty())
{
cout << state.top() << " ";
state.pop();
}
cout << endl;
int length_end = charset.size();
string string_end;
cout << "符号栈最后结果(从栈顶到栈底):" << endl;
while (!charset.empty())
{
cout << charset.top() << " ";
if (charset.size() == 2)
{
string_end.append(charset.top());
charset.pop();
string_end.append(charset.top());
cout << charset.top() << " ";
}
charset.pop();
}
cout << endl;
if (string_end == "E#" && length_end == 2 && status_error == 0)
{
cout << "第" << x << "个语法正确\n";
}
else
{
cout << "第" << x << "个语法存在错误\n";
}
}
}
/*****************************实验二***************************************************/
int main()
{
FILE *fp = NULL;
fp = fopen("Text_4.txt", "r");
char ch;
printf("***************实验一结果:*****************\n");
while (1)
{
ch = fgetc(fp);
if (ch != EOF)
{
fseek(fp, -1, 1);
}
else
{
break;
}
scanner_example(fp);
}
fclose(fp);
printf("***************实验一结果:*****************\n\n");
printf("***************实验二结果:*****************\n\n");
printf("\n***********First show the status**************\n");
show_status(status);
printf("***********First show the status**************\n\n");
Create_new_status(status, new_status, new_i);
printf("\n***********用show_status的函数 show the new_status**************\n");
show_status(new_status);
printf("***********用show_status的函数 show the new_status**************\n");
cout << "\n###\n";
cout << "文档行数 status_count_row :" << status_count_row + 1 << endl;
cout << "在show函数中计算得到的非空行行数 status_usable_count_row :" << status_usable_count_row << endl;
cout << "在建新status函数中得到的非空行行数:new_i: " << *new_i << endl;
cout << "###\n";
printf("\n***********Second show the table**************\n");
Create_charArrray(charArray);
Create_tableofAction(Action);
Create_tableofGoto(Goto);
show_tables(Action, Goto);
printf("\n***********Second show the table**************\n");
printf("\n***************实验二结果:*****************\n");
cout << "检验string类的at(index)函数的效果" << endl;
cout << "Action[0][0]的第0位: " << Action[0][0].at(0) << " \nAction[0][0]的第1位: " << Action[0][0].at(1) << endl;
Second_operate(new_status, state, charset, status_usable_count_row, wenfa);
system("pause");
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号