二叉树顺序结构和链式结构的相互转换
设计思路
顺序存储结构和链式存储结构的联系
链式存储结构的根节点的序号与其左右孩子的序号,在顺序存储结构中,存在这样的关系: (注:根节点序号从零开始算,若从一开始算无需+1)
\[左孩子的序号=根节点序号*2+1
\]
\[右孩子的序号=左孩子+1=根节点序号*2+2
\]
伪代码
根据顺序存储结构和链式存储结构之间序号的关系,设想如下伪代码:
/*顺序转链式*/
BiTree Order_to_Chain(SqBtree T, int i)
{
if (T[i] == '#')
{
return 空;
}
新建二叉树的结点BT;
BT->data = T[i];
递归遍历左子树;
递归遍历右子树;
return BT;
}
/*链式转顺序*/
void Chain_to_Order(BiTree T,int i) //T为链式存储结构的二叉树
{
if (树不空)
{
BT[i]=T->data; //BT是为存储顺序存储结构的二叉树定义的字符串
递归遍历左子树;
递归遍历右子树;
}
else(如果该节点为空)
{
顺序树存入‘#’字符。
}
}
重要代码实现
顺序转链式
/*顺序存储结构转链式*/
BiTree Order_to_Chain(SqBtree T, int i)
{
BiTree BT;
if (T[i] == '#')
{
return NULL;
}
BT = new TNode;
BT->data = T[i];
BT->lchild = Order_to_Chain(T, 2 * i+1);
BT->rchild = Order_to_Chain(T, 2 * i + 2);
return BT;
}
链式转顺序
/*链式存储结构转顺序*/
void Chain_to_Order(BiTree T,SqBtree &BT,int i)
{
if (T)
{
BT[i] = T->data;
Chain_to_Order(T->lchild, BT, 2 * i + 1);
Chain_to_Order(T->rchild, BT, 2 * i + 2);
}
else
{
BT[i] = '#';
}
}
代码运行结果及分析
对于这棵二叉树:
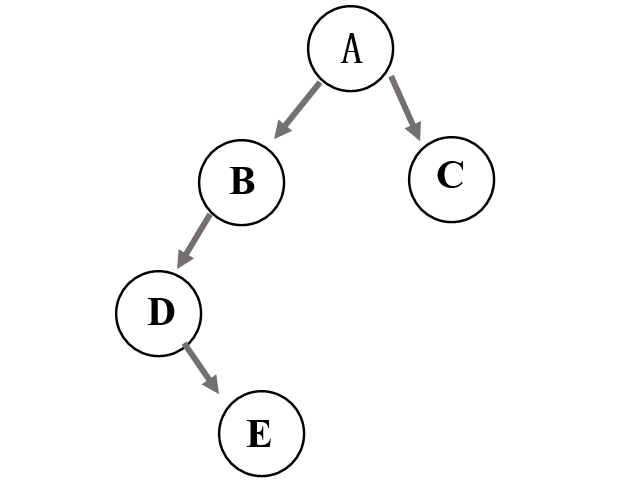
它的前序遍历结果为ABDEC,中序遍历结果为DEBAC,它的后序遍历结果为EDBCA,它的顺序存储结构为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| A | B | C | D | # | # | # | # | E |
其实顺序存储结构最后一位结点E,它的左孩子和右孩子都为空,但也是需要申请存储空间的,但因为他后面无带数据的根节点,我们可以在代码上加入一个判断,当下标超出数组长度时,则均返回null。
进行代码测试:
1、顺序转链式,输入字符串“ABCD####E”
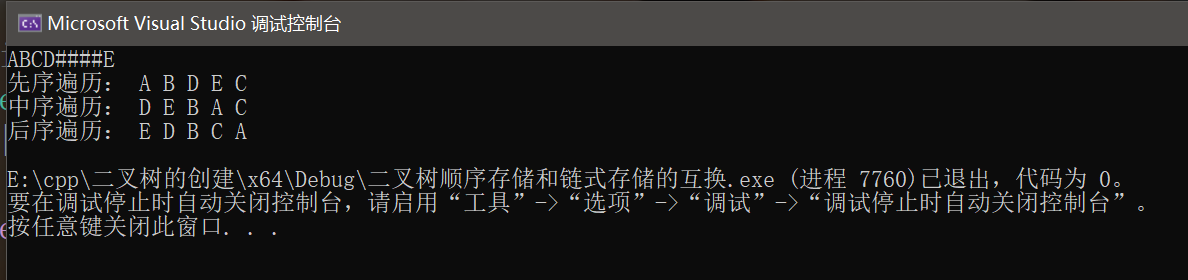
运行结果正确。
2、链式转顺序,输入一串字符”ABD#E###C##“,前序创建树

运行结果正确
全部代码展示
#include<iostream>
#include<string>
using namespace std;
char BT[100]; //定义全局变量,存储顺序存储结构的二叉树
typedef char Elemtype;
typedef string SqBtree;
typedef struct TNode {
Elemtype data;
TNode* lchild, * rchild;
}TNode,*BiTree;
/*先序遍历创建树*/
int N = 0;
BiTree CreateTree(string s) {
if (s[N] == '#') {
N++;
return NULL;
}
BiTree root;
root = new TNode;
root->data = s[N];
N++;
root->lchild = CreateTree(s);
root->rchild = CreateTree(s);
return root;
}
/*顺序存储结构转链式*/
BiTree Order_to_Chain(SqBtree T, int i,int len)
{
if (i >= len) return NULL;
BiTree BT;
if (T[i] == '#')
{
return NULL;
}
BT = new TNode;
BT->data = T[i];
BT->lchild = Order_to_Chain(T, 2 * i+1,len);
BT->rchild = Order_to_Chain(T, 2 * i + 2,len);
return BT;
}
/*链式存储结构转顺序*/
void Chain_to_Order(BiTree T,int i)
{
if (T)
{
BT[i] = T->data;
Chain_to_Order(T->lchild, 2 * i + 1);
Chain_to_Order(T->rchild, 2 * i + 2);
}
else
{
BT[i] = '#';
}
}
/*前序遍历*/
void PreOrder(BiTree b)
{
if (b != NULL)
{
cout << b->data
<< ' ';
PreOrder(b->lchild);
PreOrder(b->rchild);
}
else return;
}
/*中序遍历*/
void InOrder(BiTree b)
{
if (b != NULL)
{
InOrder(b->lchild);
cout << b->data
<< ' ';
InOrder(b->rchild);
}
else return;
}
/*后序遍历*/
void PostOrder(BiTree b)
{
if (b != NULL)
{
PostOrder(b->lchild);
PostOrder(b->rchild);
cout << b->data
<< ' ';
}
else return;
}
/*遍历输出二叉链树*/
void printTree1(BiTree T)
{
if (T == NULL)
cout << "树为空";
else
{
cout << "先序遍历: ";
PreOrder(T);
cout << endl;
cout << "中序遍历: ";
InOrder(T);
cout << endl;
cout << "后序遍历: ";
PostOrder(T);
cout << endl;
}
}
/*输出顺序树*/
void printTree2(char BT[])
{
int i;
cout << "该树的顺序存储结构为: ";
for (i = 0; BT[i] != '0'; i++) {
cout << BT[i];
}
}
int main() {
SqBtree s;
BiTree T;
{
/*顺序转链序输入
cin >> s;
int len = s.size();
T = Order_to_Chain(s, 0,len);
printTree1(T);
*/
}
{
/* 链式转顺序
cin >> s;
T = CreateTree(s);
memset(BT, '0', sizeof(BT)); //将BT字符串一键初始化为0
Chain_to_Order(T,0);
printTree2(BT);
*/
}
return 0;
}
总结
整个代码设计都是围绕递归来写的,一开始没有初始化字符串BT的时候,运行总是出现string subscript out of range的错误,这是越界了,然后把string改为一个具有上限的char 【maxsize】的话,就无法确定输出字符的个数,因此引入了memset一键初始化,这样就既保证了不会越界,也能控制输出。
代码中有实现递归遍历输出,递归遍历分为先序遍历、中序遍历和后序遍历三种。
先序遍历:访问根节点;先序遍历左子树;先序遍历右子树;
中序遍历:中序遍历左子树;访问根节点;中序遍历右子树;(中序序列的根节点的左边是左子树的结点,右边是右子树的结点)
后序遍历:后序遍历左子树;后序遍历右子树;访问根节点;(后序序列的最后一个结点是根节点)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号