


1.介绍
不足:由于以往的对于re-id的研究使用了两个或两个以上的输入图像,计算复杂度很高;17年一个deep zero-padding性能不行
创新:基于将输入数据全部输入一个one-stream网络,和deep zero-padding改变数据输入形式类似,作者提出了三种数据输入形式:IPVT-1, IPVT-2, and IIPVT。最后设计实验测试这三种结构在不同数据集的性能。
结果:在图片经过MSR处理(通过实验对比OSTU方法性能结果后得出),
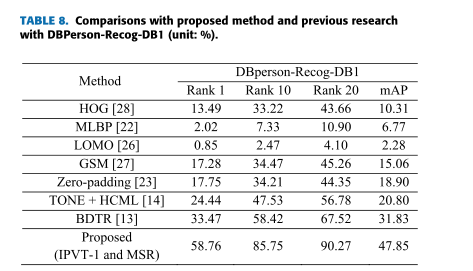
1.IPVT-1在相机视角变化小数据集,如Person-Recog-DB1,效果较好;
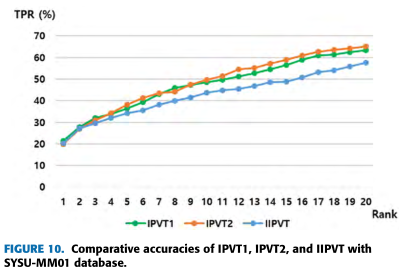
2.在相机视角变化大数据集,如SYSU-MM01:IPVT-1在rank1是最佳性能,IPVT-2在rank10和20以及mAP的性能最好

2.思想
2.1 数据输入
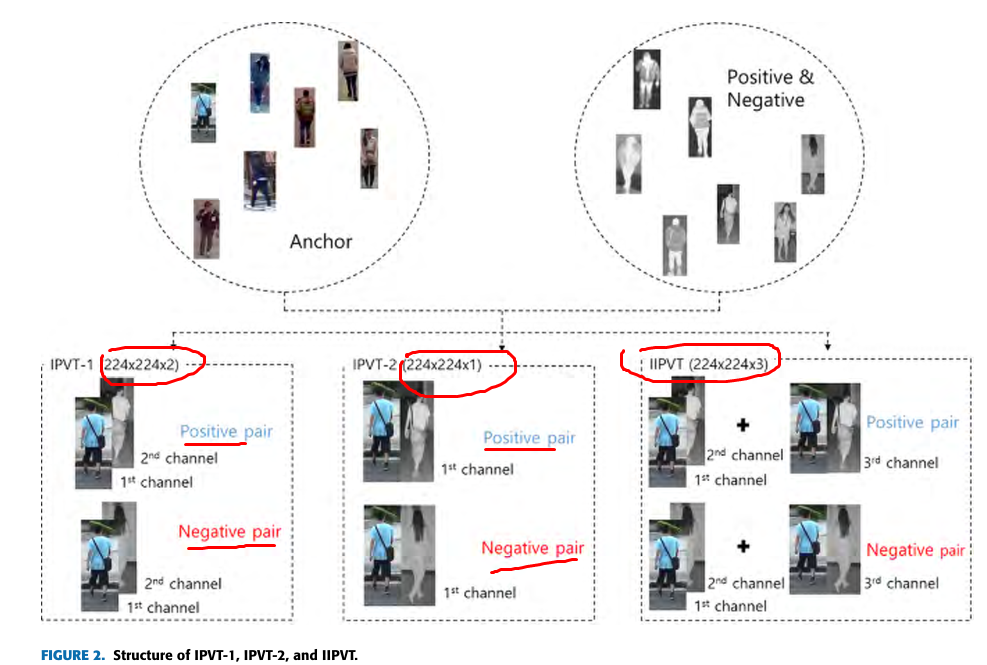
为了改变输入形式,作者提出了三种数据输入形式:IPVT-1, IPVT-2, and IIPVT。由于rgb有颜色,轮廓信息,而ir只有轮廓信息,为了使特征一致,作者先将rgb转换为灰度图。
IPVT-1:这种方式是将化为灰度图的rgb(一维)和ir(一维)叠加放入两个通道,组成一个inter-chanel(通道间)对,类似于[[rgb],[ir]]两维数据
IPVT-2:这种方式是将化为灰度图的rgb(一维)和ir(一维)追加放入一个通道,组成一个intra-chanel(通道内)对,类似于[rgb,ir]一维数据
IIPVT:而它是把IPVT-1和IPVT-2叠加起来,组成一个三维数据,包含了IPVT-1和IPVT-2的全部数据,类似于[[[rgb]],[[ir]],[[rgb,ir]]]]
最后将图片数据以一个正例,负例的方式组合。如图:
2.2 整体网络
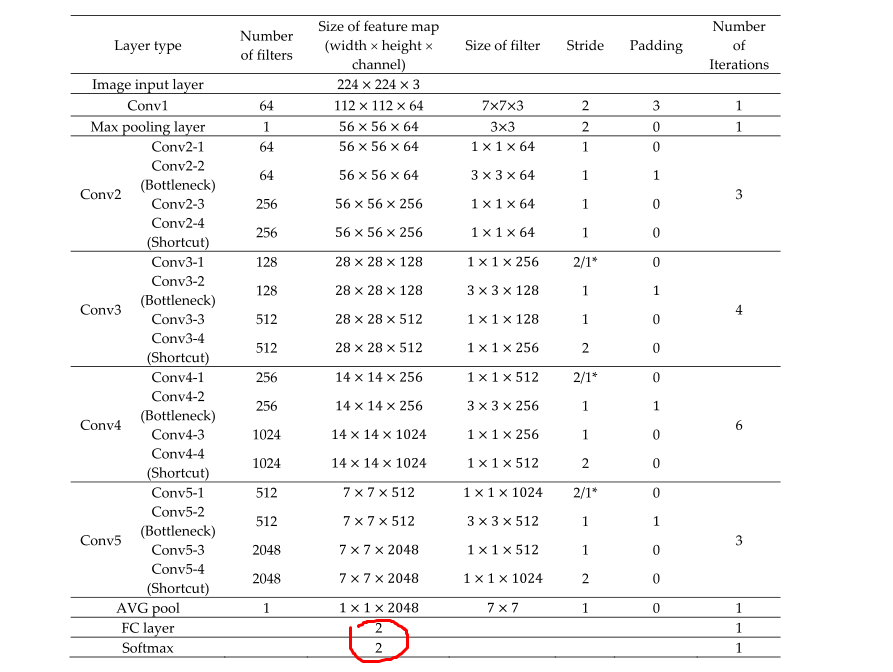
之后再把2.1的数据(IPVT-1或IPVT-2或IIPVT)输入resnet网络

这个resnet是经过修改的,最后的fc的输出由原来的1000改成了2,最后经过一个softmax层输出相似性和差异性的概率。
resnet参数如下:

2.3 结果

2.4 为什么可以分类
作者是这么说的,
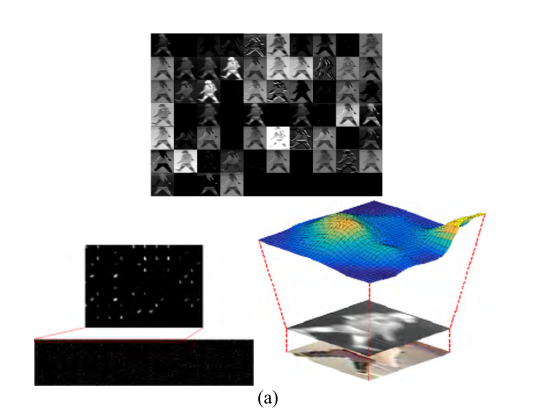
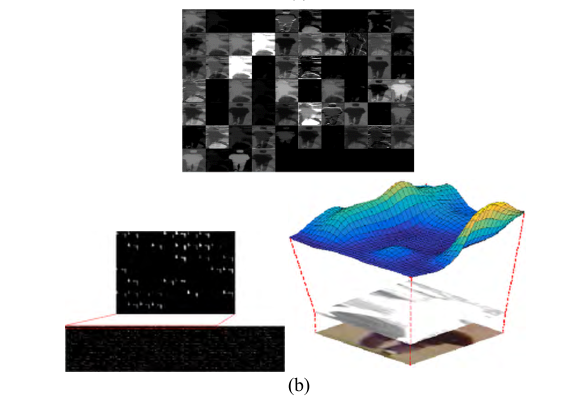
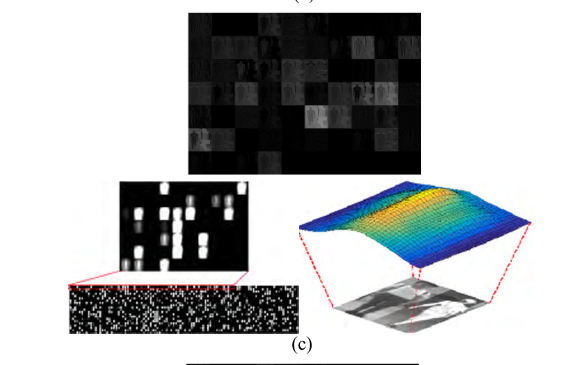


通过使用(a)、(b)DBPeer-Recog-DB1和(c)、(d) SYSU-MM01数据库进行测试获得的特征图示例。(a)和(c)来自正对,而(b)和(d)来自负对。在(a)-(d)中,上部图像显示从第一个卷积层获得的特征图(表2的Conv1),而左下部图像显示从最后一个卷积层获得的特征图(表2的AVG池之前)。在(a)-(d)中,右下图像分别基于左下图像的平均特征地图值显示3D特征地图图像。
如图13(a)–(d)的右下方图像所示,在负对的情况下,与正对的情况相比,特征图中的值的变化相对较大。(额。。没看出来,难道是看特征图的平缓程度?哪位大佬解释一下)由此可见,正负对是可以分类的。
也就是说,从图13中,证实了本研究中提出的基于图像对的深度CNN方法可以有效地用于人ReID。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号