

爬虫基础与安装
使用requests库模拟浏览器的,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib)
注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的requests请求
爬虫介绍:
爬虫本质
模拟浏览器发送请求(requests,selenium)->下载网页代码->只提取有用的数据(bs4,xpath,re)->存放于数据库或
文件中(文件,excel,mysql,redis,mongodb)
发送请求:请求地址(浏览器调试,抓包工具),请求头(难),请求体(难),请求方法
拿到响应:拿到响应体(json格式,xml格式,html格式(bs4,xpath),加密的未知格式(需要解密))
入库:Mongodb(json格式数据)
性能高一些(多线程,多进程,协程),只针对与python语言的cpython解释器(GIL:同一时刻只能由一个线程在执行)
-io密集型:用线程
-计算密集型:用进程
scrapy框架处理了性能
安装
1.安装requests模块
pip install requests
也可以换源安装
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple

示例:
1.找到你想爬取的网页:检查------再次刷新网页 -------找到user-agent(客户端的类型)

header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}
res=requests.get('https://www.kelagirls.com/albums-page-2.html')
print(res.text)
执行后这里可以看到图片地址

基本请求
把图片地址和headers=header写上
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}
res=requests.get('https://www.kelagirls.com/albums-page-2.html')
res1=requests.get('https://www.kelagirls.com/albums-page-2.html/static/images/kelanvs.png',headers=header)
print(res.text)
import requests #发送get请求 #res是python的对象,对象里,响应头,响应体。。。 header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'} # res=requests.get('https://www.duitang.com/category/?cat=avatar') res1=requests.get('https://c-ssl.dtstatic.com/uploads/blog/202206/26/20220626195023_f1e25.thumb.400_0.jpeg',headers=header) # print(res.text) print(res1.content) #那二进制的内容

如果显示有防盗链,就把referer复制带上(客户从哪一个页面跳过来的,也就是上一个链接是什么)
一班用来做图片防盗链
2.请求地址中携带数据(推荐第二种)
第一种
from urllib.parse import urlencode #自己导入模块来编码
#from urllib.parse import unquote 解码
#print(unquote(%E7%BE%8E%E5%A5%B3)) 解码过来就是美女两个字
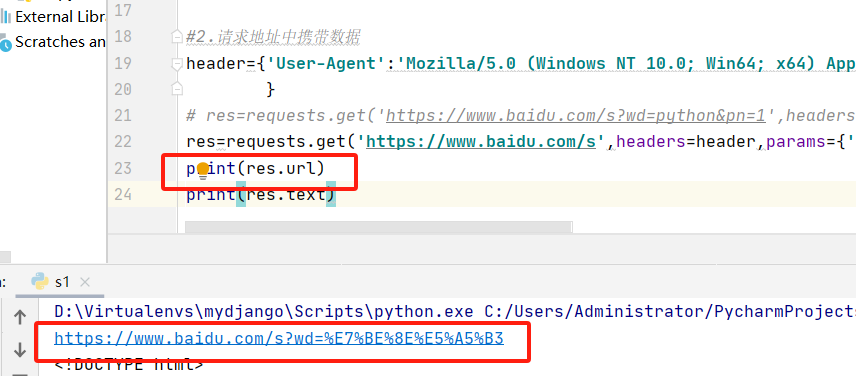
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', } res=requests.get('https://www.baidu.com/s?wd=python&pn=1',headers=header) print(res.url)#打印转码之后的url print(res.text)
第二种
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
}
res=requests.get('https://www.baidu.com/s',headers=header,params={'wd':'美女'}) #params会把括号中的转到s拼上以?wd=美女的形式,顺便转了个码
print(res.url)
print(res.text)
3.请求带cookie(两种方式) 推荐第二种
# 方式一:在header中放 header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', 'cookie':'key=sfccdcdc;key=hvhsvhsv h;key=ghvhvhb'} #这里我们测试下来,多个cookie会取最右侧的key的value值 res=requests.get('https://www.baidu.com/s?wd=美女',headers=header)
print(res.text)
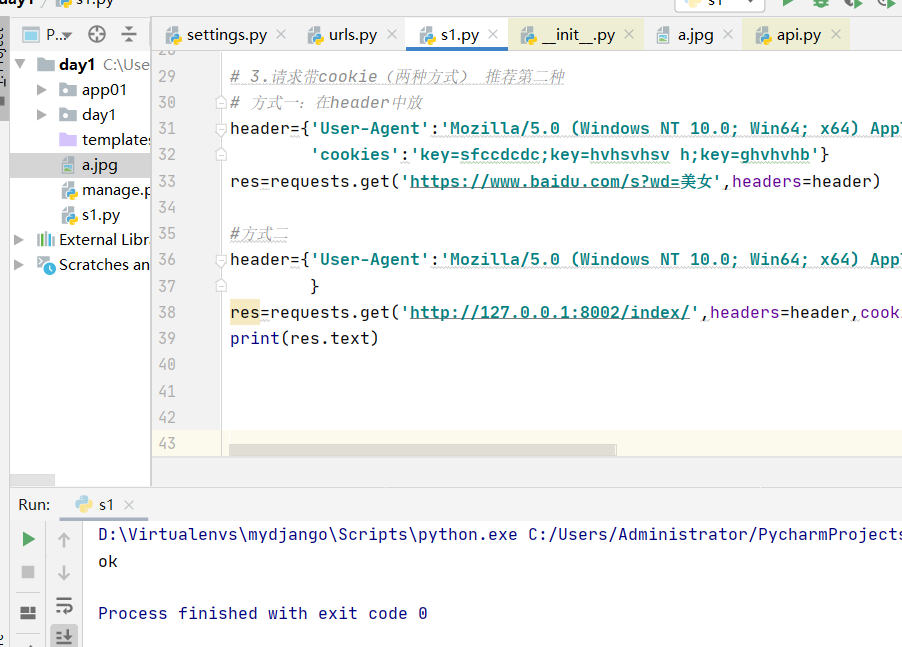
#方式二 header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36' } res=requests.get('http://127.0.0.1:8002/index/',headers=header,cookies={'key':'sfccdcdc'}) #这里的网址是我们重开一个项目当做服务器,运行后的网址 print(res.text)
新项目假服务器:
from django.shortcuts import render,HttpResponse # Create your views here. def index(request): print(request.COOKIES) return HttpResponse('ok')

4.发送post请求,携带数据 urlencoded和jso格式,是提交到data中去,就是从data中取出
res=requests.post('http://127.0.0.1:8002/index/',data={'name':'zz'}) print(res.text) # json # res1=requests.post('http://127.0.0.1:8002/index/',json={'age':2}) # print((res1.text))
新项目假服务器:
from django.shortcuts import render,HttpResponse # Create your views here. def index(request): # print(request.COOKIES) print(request.body) return HttpResponse('ok')
这里的格式是urlencoded

5.自动携带cookie
# session=requests.session() # res=session.post('http://127.0.0.1:8002/index/')#假设这个请求登录了 # res1=session.post('http://127.0.0.1:8002/order/')#现在不需要手动带cookie,session会帮咱处理
6. response对象
respone=requests.post('http://127.0.0.1:8000/index/',data={'name':'lqz'})print(respone.text) # 响应的文本print(respone.content) # 响应体的二进制print(respone.status_code) # 响应状态码print(respone.headers) # 响应头print(respone.cookies) # cookieprint(respone.cookies.get_dict()) # 把cookie转成字典print(respone.cookies.items()) # key和valueprint(respone.url) # 请求的urlprint(respone.history) #[]放重定向之前的地址print(respone.encoding) # 响应的编码方式 respone.iter_content() # 图片,视频,大文件,一点一点循环取出来for line in respone.iter_content(): f.write(line)
7 编码问题
res=requests.get('http://www.autohome.com/news') # # 一旦打印出来出现乱码问题 # # 方式一 # # res.encoding='gb2312' # # 方式二res.encoding=res.apparent_encodingprint(res.text)
8.解析json
import json respone=requests.post('http://127.0.0.1:8000/index/',data={'name':'lqz'}) #print(type(respone.text)) # 响应的文本 #print(json.loads(respone.text))print(respone.json()) # 相当于上面那句话print(type(respone.json())) # 相当于上面那句话
9 高级用法之ssl(补充知识)
# import requests # respone=requests.get('https://www.12306.cn') #不验证证书,报警告,返回200 # print(respone.status_code) # 使用证书,需要手动携带 # import requests # respone=requests.get('https://www.12306.cn', # cert=('/path/server.crt', # '/path/key')) # print(respone.status_code)
10 高级用法:使用代理
# respone=requests.get('http://127.0.0.1:8000/index/',proxies={'http':'代理的地址和端口号',}) # 代理,免费代理,收费代理花钱买 # 代理池:列表放了一堆代理ip,每次随机取一个,再发请求就不会封ip了 # 高匿和透明代理?如果使用高匿代理,后端无论如何拿不到你的ip,使用透明,后端能够拿到你的ip # 后端如何拿到透明代理的ip, 后端:X-Forwarded-For # respone=requests.get('https://www.baidu.com/',proxies={'http':'27.46.20.226:8888',}) # print(respone.text)
11 超时设置
# import requests # respone=requests.get('https://www.baidu.com', # timeout=0.0001)
12 认证设置(基本不使用了 见不到了)
# import requests # r=requests.get('xxx',auth=('user','password')) # print(r.status_code)
13 异常处理
# import requests # from requests.exceptions import * #可以查看requests.exceptions获取异常类型 # # try: # r=requests.get('http://www.baidu.com',timeout=0.00001) # # except ReadTimeout: # # print('===:') # except Exception as e: # print(e)
14 上传文件
# res=requests.post('http://127.0.0.1:8000/index/',files={'myfile':open('a.jpg','rb')}) # print(res.text)
案例:
爬取li视频:
#https://www.pearvideo.com/ # 爬取梨视频 import requests import re res=requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0') # print(res.text) re_video='<a href="(.*?)" class="vervideo-lilink actplay">' video_urls=re.findall(re_video,res.text) # https://www.pearvideo.com/ # print(video_urls) for video in video_urls: url='https://www.pearvideo.com/'+video print(url) # 向视频详情发送get请求 res_video=requests.get(url) # print(res_video.text) # break re_video_mp4='hdUrl="",sdUrl="",ldUrl="",srcUrl="(.*?)",vdoUrl=srcUrl,skinRes' video_url=re.findall(re_video_mp4,res_video.text)[0] print(video_url) video_name=video_url.rsplit('/',1)[-1] print(video_name) res_video_content=requests.get(video_url) with open(video_name,'wb') as f: for line in res_video_content.iter_content(): f.write(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号