Python 函数
一、函数定义:
概念:
- 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段
- 函数能提高应用的模块性,提高代码的重复利用率。之前我们已经很多次用到了Python的内建函数print(),内建函数有很多,当然也可以自己创建函数,称为自定义函数。
函数定义语法规则:
def 函数名(参数列表):
函数体
一个简单的例子:
# 比较大小,返回最大值
def max(a,b):
if a>b:
return a # return 是函数返回关键字
else:
return b # 比较大小,遇到非a即b的语句,可以用三元运算符,一句搞定:return a if a>b else b
print(max(4,5)) # 5 (函数max有2个参数a和b)
函数的返回值可以有很多:
# 刚才看到了return关键字,是函数用来返回值的
def fun():
a,b,c,d = [1,2,3,4]
return (a,b,c,d)
fun() # (1,2,3,4) ,结果是个元组
二、函数的参数
参数分类:
- 形参:就是函数定义的位置,括号内的参数,比如上面例子def max(a,b):,这里的a,b就是形参。
- 实参:就是在调用函数的时候,括号内传递的值,比如max(4,5),这里4和5 都是实参。
位置参数
- 从左至右,实参和形参一一对应。
- 既然是位置参数,那么参数的位置很重要,调用的时候传实参,位置弄错了,结果就错了,第一个形参代表的是姓名name,你传一个年龄21肯定不行。
def record(name,age,sex):
print('Your name is {},age is {},sex is {}'.format(name,age,sex))
record('lyq',21,'男') # Your name is lyq,age is 21,sex is 男,(参数按顺序对应)
关键字参数
- 如果一个函数形参太多,调用函数的时候(也就是传实参的时候),做到一一对应就很难,因为记住每个形参的位置有点难,虽然有的时候参数的位置比名字更重要,尽管参数的名字相对好记忆。那么可以用关键字参数,在传实参的时候,给实参加上形参的名字,这样,传参的时候形参会自动去匹配。
- 关键字参数中,参数位置不重要,但是参数名字很重要。
- 是位置参数,还是关键字参数,调用的时候才知道
# 还用上面record函数例子,我们直接调用:
record(age=21,sex='男',name='lyq') #返回结果一样。哪怕传入的参数打乱了也能精准匹配到函数的形参。这里的参数都是关键字参数,括号内都用带有形参的等式作为参数。看来是位置参数,还是关键字参数,是靠函数调用的时候(实参)来体现的。
# 还可以这样调用
record('lyq',21,sex='男')
# Your name is lyq,age is 21,sex is 男
# 这样看来,前两个name和age是位置参数,最后一个sex是关键字参数,所以,哪些是位置参数,哪些是关键字参数还要看调用的时候。而且前两个参数顺序不能乱。
# 如果这样调用
record(sex='男','lyq',21) # 报错,说关键字参数(sex),应该在位置参数(name和age)后面。
默认值参数:
def record(name,age,sex='男'): # 在定义函数的时候,给了sex一个默认值
print('Your name is {},age is {},sex is {}'.format(name,age,sex))
record('lyq',21) # Your name is lyq,age is 21,sex is 男(可以不给sex传参)
record('Lucy',20,'女') # Your name is Lucy,age is 20,sex is 女(也可以传参)
# 如果这样调用呢?
record(age=21,name = 'lyq') # 不报错
record(age=21,'lyq') # 报错,提示关键字参数应该在位置参数后面。
record('lyq',sex='男',age=21) # 这样也没问题,看来,传参的时候,带等号的参数,要放在没有等号的参数的后面
# 如果形参中都带默认值
def record(name='lyq',age=21,sex='男'):
print('Your name is {},age is {},sex is {}' (name,age,sex))
record() # Your name is lyq,age is 21,sex is 男 (可以不写任何参数)
record('lyq',22) # Your name is lyq,age is 22,sex is 男(可以写一部分)
record('Lucy',20,'女') # Your name is Lucy,age is 20,sex is 女
三、参数的魔法-动态参数
说明:
- 有时候我们输入的参数可能很多,有时候可能不确定,那么就要用到星号*
动态接收位置参数(*args):
# 做一个累加器(把一系列的数字累加)
def my_sum(*args):
sum = 0
for n in args: # 这里是args ,不能写 *args
sum+=n
return sum
my_sum(1,2,3,4) # 10
my_sum(1,2,3,4,5) # 15
my_sum(1,2,3,4,'a') # 报错,int 和str不能相加
可以看看这个args是什么类型:
def my_sum(*args): # 为什么要写成args?也可以写成别的参数名称,只不过大家都这么写
print(type(args))
my_sum() # <class 'tuple'> (原来是个元组,刚才函数返回值,return多个值得时候,结果也是个元组)
动态接收关键字参数(**kwargs):
def record(**kwargs):
print(kwargs)
print(type(kwargs))
record (name='lyq',age=21)
# {'name': 'lyq', 'age': 21} (kwargs是个字典哦)
# <class 'dict'> (看下类型是dict)
星号*的聚合作用
所以说星号*,在这里的作用是,把函数调用时传入的一个个的实参,聚合在一起给到args或者kwargs
星号*的打散作用
比如我传入的参数有可能是个列表或者元组,可以用*进行打散以后,挨个传入形参:
name = 'lyq'
l1 = [1,2,3]
tu1 = ('red','yellow','blue')
def func(*args):
print(args)
func(*name,*l1,*tu1) # ('l', 'y', 'q', 1, 2, 3, 'red', 'yellow', 'blue')
# (在调用的时候,这里的星号*起到了打散的作用,把lyq字符串打散成单个字符,然后一起传入到函数的形参,结果又被星号*聚合到了args,形成了一个元组)
# 好像在调用的时候,星号*是打散的作用,在定义函数的时候,星号*是聚合作用,姑且先这么认为
dic1 = {'name':'lyq','age':21}
dic2 = {'sex':'男','hobby':'swimming'}
def func(**kwargs):
print(kwargs)
func(**dic1,**dic2) # {'name': 'lyq', 'age': 21, 'sex': '男', 'hobby': 'swimming'} (字典的打散,用2个*)
星号*可以处理剩下的元素
a,b = (1,2)
print(a) # 1
print(b) # 2
a,*b = (1,2,3,4,5)
print(a) # 1
print(b) # [2, 3, 4, 5] (这里是元组的拆包,b把剩余的都接收了(豹子头:一个怎么够,我要十个。。),形成了一个列表,有意思,星号*的聚合作用)
*rest,a,b = range(5)
print(rest) # [0,1,2] (先给a和b安排好,然后rest把前面的都接收了,因缺思厅)
print(a) # 3
print(b) # 4
形参的顺序:
到目前为止,学了形参的4种形式:位置参数,默认值参数,**kwargs(关键字参数),*args(多个位置参数),那么这四种参数位置怎么排呢?
# 比如:
def func(*args,a,b,sex='男'): #这样肯定不行,*args已经把所有位置参数都接收了,后面的a,b拿不到了
print(args)
print(a)
print(b)
func(1,2,3,4,5) # 直接报错:TypeError: func() missing 2 required keyword-only arguments: 'a' and 'b'
#(说是缺了2个仅限关键字参数,就是a和b啦。这就是第五种参数,仅限关键字参数,它是出现在*rags后面的位置参数)
# 那么应该如何排序呢?
# 应该是:位置参数,*args,默认值参数**kwargs
def func(a,b,*args,sex='男',**kwargs):
print('a=',a)
print('b=',b)
print('args=',args)
print('sex=',sex)
print('kwargs=',kwargs)
func(1,2,3,4,5,name='lyq',age=21)
# a= 1
# b= 2
# args= (3, 4, 5) # a,b,args这三个就会把前面所有的位置参数都处理完
# sex= 男
# kwargs= {'name': 'lyq', 'age': 21}
加上“仅限关键字keyword-only”参数,应该怎样排序?
# 应该这样排序:位置参数,*args,默认参数,仅限关键字参数,**kwargs(我感觉默认参数和仅限关键字参数可以互换,但是谁没事设计函数的时候,写那么多类型的参数啊,sb,越少越好)
# 下面一个完整的例子:
def func(a,b,*args,c,sex='男',**kwargs): # 这里的参数c就是仅限关键字参数
print('a=',a)
print('b=',b)
print('args=',args)
print('c=',c)
print('sex=',sex)
print('kwargs=',kwargs)
func(1,2,3,4,5) # 报错,c仅限关键字参数没有指定
func(1,2,3,4,5,c=6)
# a= 1
# b= 2
# args= (3, 4, 5) # args是个元组
# c= 6
# sex= 男
# kwargs= {}
func(1,2,[3,4,5],c=6,sex='女')
# a= 1
# b= 2
# args= ([3, 4, 5],)
# c= 6
# sex= 女
# kwargs= {}
func(1,2,[3,4,5],name='lyq',c=6,sex='女')
# a= 1
# b= 2
# args= ([3, 4, 5],)
# c= 6
# sex= 女
# kwargs= {'name': 'lyq'} (name='lyq'写在仅限关键字参数c的前面也可以被kwargs识别)
func(1,2,c=6) # (就是a,b,c这些都要传参进去)
# a= 1
# b= 2
# args= ()
# c= 6
# sex= 男
# kwargs= {}
func(*[1, 2, 3, 4],**{'name':'lyq','c':12,'sex':'男'})
# a= 1
# b= 2
# args= (3, 4)
# c= 12
# sex= 男
# kwargs= {'name': 'lyq'}
四、作用域
先看一个例子:
x = 1
def my_func():
x = 2
print(x)
my_func() # 2
print(x) # 1
# 函数体内,x被赋值2,然后调用函数my_func(),打印的x是2,外层直接打印x却是1。
# 这里函数内的x和外面的x不是同一个,外面语句print(x)是不能访问my_func()函数内部的变量的。他们的作用域不同。我们用id()函数查看一下两个变量的地址就知道了。
x=1
def my_id():
x=2
print(id(x))
my_id() # 3130774323440
print(id(x)) # 3130774323472
# 两个变量的地址不一样,我们也看到了,函数体内外的变量,可以同名,都叫x,其实函数里的形参,也是函数内部的变量
全局作用域和局部作用域:
- 刚才函数体my_id()外部的x是,全局变量,它属于全局作用域
- 内部的x是局部变量,它属于局部作用域
- 如果局部作用域中有变量与全局作用域同名,那么在局部作用域中操作这个变量是局部变量,跟全局变量无关,
- 当解释器加载程序的时候,遇到全局变量就开辟内存空间,遇到函数里的局部变量,并不是马上开辟内存空间,而是当调用函数的时候开辟内存空间。有一个时间差的
用globals(),locals()查看全局和局部作用域中的变量(字典的形式)
x =1
def func():
y = 1
print(globals())
print(locals())
func():
print(globals())
print(locals())
结果:
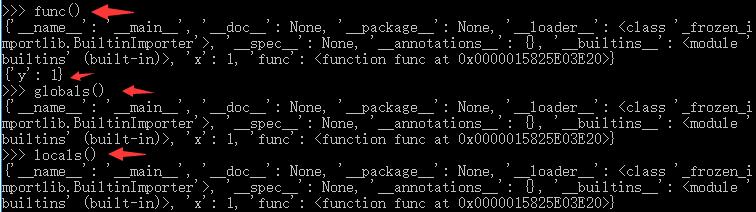
# 可以看到只有函数内调用的locals() 返回的值是{'y':1},别的调用globals()和locals()返回的结果都一样。也就是说函数内的变量只有y
# 外层的全局变量中有个 __name__ ,name的前后是2个下划线,这是一个内置属性,用来标识模块是不是独立运行,模块module中会有介绍。有人说:每个py文件在最下面写一句“if __name__ == '__main__':pass”,你的程序就高大上了许多。这句代码的意思就是,如果你独立运行这个py文件,这个if语句就执行,否则不执行。很适合做单个py文件(模块)的测试,就是你每写好一个模块,就在下面做一些测试。
global关键字
这个global和globals()函数还不一样
# 如何在函数内部访问全局变量呢?
# 试试函数内部不定义与外部同名的变量,直接用外部变量行不行?
x = 1
def func():
print(x)
print(id(x))
func()
# 1
# 1750153232624
print(x) # 1
print(id(x)) # 1750153232624
# 变量地址相同,可见,函数内部在不出现同名变量的情况下可以直接访问外部的全局变量
# 既然可以访问x,看能不能改
x = 1
def func():
x+=1
print(x)
func()
# UnboundLocalError: local variable 'x' referenced before assignment
# 直接报错,说局部变量在赋值前不能引用
# 是不是可以这样理解:函数内部,可以读外部全局变量的值,但是如果要改,它就认为这是个局部变量,跟外面的同名没关系了,你要改或者计算,就要遵循“先赋值,后计算”的原则。
# 用上global试试
x = 1
def func():
x = 2
global x # 用global的时候没有用括号,之前的删除列表的时候也用到了一个类似的关键字,del
print(x)
print(id(x))
# SyntaxError: name 'x' is assigned to before global declaration
# 还没有调用的时候就报错了,x在声明global的时候,被赋值了,不允许
# 调整下位置
x = 1
def func():
global x
x = 2
print(x)
print(id(x))
func()
# 2
# 1750153232656
print(x) # 2
print(id(x)) # 1750153232656
# 全局变量x的值变了,是在函数体内改变的,就是说,要想在函数内对全局变量改变
# 如果外部没有x变量,但在函数内部用global声明了一个x ,外部也可以调用的
def func():
global x
x = 2
print(x)
func() # 2
print(x) # 2
# 都可以返回x的值,这种写法是不是有点脑残呢?全局变量就写在全局嘛,干嘛写在局部作用域
五、内置函数
python官网内置函数文档链接: https://docs.python.org/3/library/functions.html?highlight=built

其中有很多已经接触过:
print(),list(),dict(),zip(),str(),int(),id(),bool(),float(),format(),input(),tuple(),type(),globals(),locals()
再来看看其他的:
# help()
print(help(list.append))
# >>> help(list.append)
# Help on method_descriptor:
# append(self, object, /)
# Append object to the end of the list.
# 返回了关于list列表的append方法的定义
# eval()
eval('1+1') # 2
eval('1+2*3-4/5*(6/8)') # 6.4
x = 5
eval('x**2') # 25
eval('print(100)') # 里面还可以是个print() 语句
# exec()
s = '''
for i in [1,2,3]:print(i)
'''
exec(s)
# 1
# 2
# 3
# exec()执行一系列语句,eval()执行一个语句。如果这样执行,eval(s),会报语法错误。
# compile()
str = 'for i in range(5):print(i)'
a = compile(str,'',mode = 'exec')
exec(a)
# 0
# 1
# 2
# 3
# 4
# 关键字参数 mode 不能等于 eval,要不然提示语法错误,eval只能执行一个语句,这里系统把 for i in range(5):print(i) 拆分了。
# range()
a = range(5)
type(a) # <class 'range'> (是个range类型)
# 一般用在for循环中,range类型是个可迭代类型
for i in range(5):print(i)
# 循环打印i
# range函数语法:range(stop)或range(start,stop[,step])
# 还可以把range直接转换成list列表类型
print(list(range(0,10,2)))
# [0,2,4,6,8]
# 开始0,结束10,步长2
# bin(),oct(),hex(),int()
# 二进制,八进制,十六进制
print(bin(10),type(bin(10))) # 0b1010 <class 'str'> (bin()结果是个字符串)
print(oct(10),type(oct(10))) # 0o12 <class 'str'>
print(hex(10),type(hex(10))) # 0xa <class 'str'>
# int(str,16)可以把十六进制转成十进制,同样可以处理八进制和二进制
print(int('0xa',16)) # 10
print(int('0o12',8)) # 10
print(int('0b1010',2)) # 10
# ord(),chr()
# ord():输入字符找到对应的Unicode字符编码(int类型,十进制),chr():输入编码找到字符
print(ord('a')) # 97
print(ord('中')) # 20013
print(chr(97)) # a
print(chr(20013)) # 中
# 练习:1、求‘中’字的Unicode编码的十六进制形式
# 2、求Unicode编码‘0x4e2d’对应的汉字
# 3、输出Unicode编码中‘一’后面的八个汉字
# callable()
# 检查对象是否可调用
x = 1
def func():pass
callable(func) # True
callable(print) # True
callable(x) # False
# divmod(),round(),pow(),abs()
# 除法求商求余,保留小数,求幂,求绝对值
print(divmod(8,3)) # (2,2) (得到一个元组,商是2,余数是2)
print(pow(3,2)) # 9
print(round(1/3,4)) # 0.3333 (round第一个参数是除法公式,第二个是保留位数)
print(abs(-1)) # 1
# repr()
# 返回一个对象的字符串string形式
a = repr(100)
type(a) # <class 'str'>
# all(),any()
# all():可迭代对象中,全都是True结果才是True
# any():可迭代对象中,有一个True结果就是True
print(all([1,2,True,'中国']) # True
print(all([1,2,'lyq',''])) # False (这里有一个空字符串)
print(any([1,2,'lyq',''])) # True
# reversed()
# 序列翻转
l1 = reversed('中国')
print(l1) # 结果是一个地址,是一个迭代对象
print(list(l1)) # ['国', '中'] (把字符串转置了,还拆分了)
l2 = reversed([1,2,[3,4,5]]) # [[3, 4, 5], 2, 1] (列表内的列表[3,4,5]并没有转置)
# zip()
# 拉链函数,可以好多个列表同时拉在一起,长度取决于最短的哪个列表
l1 = [1,2,3]
l2 = ['a','b','c','d']
l3 = ('11','12','13','14','15')
for i in zip(l1,l2,l3):print(i)
# (1, 'a', '11')
# (2, 'b', '12')
# (3, 'c', '13')
# 结果只有3个,因为l1列表最短,按最短的算。
# sorted()
# 语法:sorted(iterable,key=None,reverse=False)
# iterable : 可迭代对象
# key :排序规则函数
# reverse : 转置(key和reverse参数必须是关键字参数,就是用等式的方式传参,如:key = func1,reverse=True)
l1 = [1,3,7,5,9]
print(sorted(l1)) # [1,3,5,7,9]
print(sorted(l1,reverse = True)) # [9,7,5,3,1]
dict1 = {1:'a',3:'c',2:'b'}
print(sorted(dict1)) # [1, 2, 3] (只是把字典的键key排序了一下)
l2 = ['Lucy','lyq','Damon']
def func(s):return len(s)
print(sorted(l2,key = func)) # ['lyq', 'Lucy', 'Damon']
# 这里用key=函数的名称func的方式,实际上是把可迭代对象的所有元素都传入到这个函数,并且函数只能有一个参数,然后返回一个值,用这个值进行排序,然后再把可迭代对象排序
# 也可以用lambda 匿名函数(没有函数名的函数)
print(sorted(l2,key = lambda s:len(s)))
# ['lyq', 'Lucy', 'Damon']
# 再来一个例子,按照每个人的年龄排序:
l3 = [{'id':1,'name':'lyq','age':21},
{'id':2,'name':'Lucy','age':18},
{'id':3,'name':'Damon','age':20},]
print(sorted(l3,key = lambda d :d['age']))
# [{'id': 2, 'name': 'Lucy', 'age': 18}, {'id': 3, 'name': 'Damon', 'age': 20}, {'id': 1, 'name': 'lyq', 'age': 21}]
# filter()
# 语法:filter(function, iterable)
# function:是筛选函数,把iterable元素传入function,然后为True的留下,False的删掉
l3 = [{'id':1,'name':'lyq','age':21},
{'id':2,'name':'Lucy','age':18},
{'id':3,'name':'Damon','age':20},]
print(filter(lambda a:a['age']>20,l3))
# 结果是个地址,并没有把 {'id':1,'name':'lyq','age':21} 打印出来,其实filter()得到的是filter类型对象,是可迭代的,可以用list()显示转换。
# map()
# 语法:map(function,iterable),映射,对可迭代对象中每个元素按照function 进行映射,得到一个新的
l1 = [1,2,3,4]
def func(i):return i**2 # 求平方
print(map(func,l1)) # 也只是一个地址,我们看看是什么类型
m = map(func,l1)
type(m) # 结果是map类型,也是可迭代类型,可以用next()函数对可迭代对象进行迭代显示内部元素
next(m) # 1
next(m) # 4
next(m) # 9
next(m) # 16
next(m) # 报错,已经迭代完了
六、函数名的应用
我们先看看函数名是什么:
def func():pass
print(func) # <function func at 0x000001F630713490> (是个地址)
type(func) # <class 'function'> (是个函数类型)
a = 1
type(a) # <class 'int'>
print(a) # 1 ,为啥int类型的变量a在打印的时候就直接输出值呢?它也是有地址的
id(a) # 2156875350256
可以把函数名赋值给变量a:
a = func
print(a) # <function func at 0x000001F630713490>
# a也变成地址了,a和func都指向这个地址,这么说func也是个变量咯
func = 2
type(func) # <class 'int'>
print(func) # 2 (现在a是个函数名了,func却成了一个int类型的变量)
# 用之前学的callable()内置函数看看
callable(a) # True ,a可以调用,它现在是个函数名
callable(func) # False ,func不可以调用,它是int类型
函数名也可以放到容器中,比如list列表:
def func1():print('func1')
def func2():print('func2')
def func3():print('func3')
def func4():print('func4')
l1 = [func1,func2,func3,func4]
for i in l1:i()
# func1
# func2
# func3
# func4
# 这里的for循环中,相当于把i依次等于func1,func2。。。,然后再调用i函数。
函数名可以当做函数的参数
# 之前的sorted()函数就已经尝试过了,比如:sorted(l1,key = func)
def func1():print('func1')
def func2(f):
print('func2')
f()
func2(func1) # 这里调用func2函数的时候,把func1当参数传进去了,也可以这样写:func2(f=func1) ,就是关键字参数了,相当于做了如下操作,f=func1,参数f也是个函数了,就可以执行了f()
# func2
# func1
函数名还可以作为返回值:
def func1():print('func1')
def func2(f):
print('func2')
return f
result = func2(func1)
result()
# func2 ,这个结果是在等式result = func2(func1)的时候打印了。
# func1
七、匿名函数 (lambda)
概念:
# 顾名思义,就是没有名字的函数,也叫一句话函数。
语法:
函数名 = lambda 形参列表:返回值
# 不是说没有函数名么?之前在函数名的应用中说 可以把函数名赋值给某个变量,比如:a=func,这里的a就是函数名,它和func有同样的地址。所以函数名也是变量。
# lambda 是定义匿名函数的关键字。
# lambda后面是形参列表,用逗号,隔开
# 匿名函数只能写一行
写一个加法匿名函数:
calc = lambda a,b:a+b
print(calc(4,5)) # 9
练习:
# 1、写一个匿名函数,接收一个可切片数据类型,返回第一个和最后一个元素
# 2、写一个匿名函数,接收2个int类型,返回较大的值。
func = lambda a,b:a if a>b else b
func(4,6) # 6
八、迭代器(iterator)
先看看可迭代对象iterable:
- 汉语词典:迭代,更替的意思
- 百度百科:迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
- python官网解释:An object capable of returning its members one at a time.(一个有能力一次返回一个值的对象,主要针对的是有序列的比如list,str,tuple),凡是对象内部有__iter__方法的对象,都是可迭代对象,但并不一定是迭代器。
- 迭代器取值规则:一次取一个,按顺序取,适用于数据量大的时候,不能像列表,字典那样直观的看到所有内容的时候,可以迭代。
查看对象内部方法dir():
l1 = [1,2,3,4]
print(dir(l1)) # 可以看到很多内部方法(前后加上2个下划线),包括__iter__ ,说明list列表是可迭代对象
# 之前sorted语法规则:sorted(iterable,key=None,reverse=False)就可以用来排序列表list,说明列表是一个iterable
#嫌dir()太多,可以用in关键字
print('__iter__' in dir(l1)) # True

迭代器(iterator):python中把对象同时含有'iter'和'next'方法的对象叫迭代器
# 看看之前我们学的那么多数据类型中,是不是有迭代器
s1 = 'lyq'
l1 = [1,2,3]
dict1 = {1:'lyq',2:'Tom'}
tu1 = ('a','b','c')
set1 = {1.22,4.23,2.0}
print('__iter__' in dir(s1)) # True
print('__iter__' in dir(l1)) # True
print('__iter__' in dir(dict1)) # True
print('__iter__' in dir(tu1)) # True
print('__iter__' in dir(set1)) # True
print('__next__' in dir(s1)) # False
print('__next__' in dir(l1)) # False
print('__next__' in dir(dict1)) # False
print('__next__' in dir(tu1)) # False
print('__next__' in dir(set1)) # False
# 全都不是迭代器,但是他们都是可迭代对象。
看看map()行不行:
l1 = [1,2,3,4]
m = map(lambda s:s**2,l1)
print('__next__' in dir(m)) # True
print('__iter__' in dir(m)) # True
# 都是True,说明m是个迭代器。上面内置函数里已经说了map可以用next()逐个输出里面的数据
可迭代对象怎么转化成迭代器?
l1 = [1,2,3,4,5]
iter1 = l1.__iter__()
print(next(iter1)) # 1
print(next(iter1)) # 2
print(next(iter1)) # 3
print(next(iter1)) # 4
print(next(iter1)) # 5
# 逐个输出迭代器的元素,用的是同一句代码:next(iter1),迭代器中有多少个元素就next多少次
九、生成器(generator) yield
先看一个函数:
def func():return 100
result = func()
print(result) # 100
将函数中的return 换成 yield:
def func():yield 100
result = func()
print(result) # <generator object func at 0x000001F6304E66C0>
# 结果是个地址,generator object(生成器对象)
# 用next()试一下
print(next(result)) # 100
# 结果返回了100,看来result是个生成器,也就是带有yield返回值的函数func()成了一个生成器函数。
生成器的本质是个迭代器,所以可以用next()方法取值。而且生成器函数中可以有多个yield:
def func():
yield 100
yield 200
result = func()
print(next(result)) # 100
print(next(result)) # 200
print(next(result)) # 异常
# 如果这样行么?
print(next(func())) # 100
print(next(func())) # 100
# 不行,每次都相当于对生成器 func()执行第一次next()
yield from :
def func():
l1 = ['lyq','Lucy','Tom']
yield l1
g = func()
print(next(g)) # ['lyq', 'Lucy', 'Tom']
# 直接输出列表,用yield from 试试
def func():
l1 = ['lyq','Lucy','Tom']
yield from l1
g = func()
print(next(g)) # 'lyq'
print(next(g)) # 'Lucy'
print(next(g)) # 'Tom'
# 结果是逐个输出了列表中的内容
十、函数的嵌套
先看一个例子:
def func1():
print(1)
def func2():
print(2)
print(3)
func2()
print(4)
func1()
# 打印顺序是: 1,3,2,4
# 之前看到列表可以嵌套,字典可以嵌套,函数定义的时候也可以嵌套,具体什么时候执行函数体,要看什么时候调用
如果func2相用到func1的变量或者说资源该怎么处理?
x = 1
def func1():
x = 2
def func2():
print(x)
func2()
func1() # 2
# 返回的是func1()函数内的x变量,不是全局的x
十一、闭包
先用函数实现一个功能:
# 股票交易中,每买一笔股票(比如说茅台),就记录一下当时成交价(最新价),在持仓列表中会立刻计算出历史成交均价。
# 第一天买一笔,每股成交价1900元,成交均价 1900/1=1900
# 第二天买一笔,每股成交价2100元,成交均价 (1900+2100)/2 = 2000
# 第二天买一笔,每股成交价2300元,成交均价(1900+2100+2300)/3 = 2100
# .................
# 写一个函数,记录下每次成交价,并计算当时的成交均价
prices = []
def jiaoyi(price):
prices.append(price)
print(sum(prices)/len(prices))
jiaoyi(1900) # 1900.0
jiaoyi(2100) # 2000.0
jiaoyi(2300) # 2100.0
但是有一个问题,列表prices在全局作用域,jiaoyi()可以调用,别的函数当然也可以调用,每次成交价是不能随便修改的,所以说这个形式不安全,可以考虑把prices列表放在函数中,不是总说局部作用域更安全么
def jiaoyi(price):
prices = []
prices.append(price)
print(sum(prices)/len(prices))
jiaoyi(1900) # 1900
jiaoyi(2100) # 2100
jiaoyi(2300) # 2300
但是结果又不是我们想要的,成交均价计算的不对,因为prices放到函数内,函数调用一次,里面资源就全消失了,无法连续记录,现在我们想要的是,这个列表(变量)又安全,又能长期存在,就用到闭包的概念了,在函数里面再定义一个内部函数,内部函数对外部函数的变量进行引用计算,外部函数最后返回内部函数名(内部函数地址),给一个变量用外部函数赋值,变量=外部函数,那么这个变量其实就是一个内部函数,只要这个变量不消失,内部函数就不消失,那么外部函数更不能消失了。因为外部函数失效,内部所有资源都要失效。
def jiaoyi():
prices = []
def inner(price):
prices.append(price)
print(sum(prices)/len(prices))
return inner
func = jiaoyi()
func(1900) # 1900
func(2100) # 2000
func(2300) # 2100
# 完美,这就是闭包了。
# 这里的prices就是func函数的自由变量。
# 我们可以用__code__.co_freevars查看一个函数是否有自由变量,从而判断是不是闭包函数
print(func.__code__.freevars) # ('prices',)
# 从打印结果可以看出prices就是这个函数的自由变量
十二、装饰器
闭包的一个应用就是装饰器。
- 开放封闭原则:软件一旦开发好,针对里面的函数就不好随便修改,因为,可能很多地方都调用了这个函数,从调用的角度,函数是开放的,谁都可以调用,从安全的角度是封闭的,一旦修改,很多调用的都会报错。
- 但是可以扩展,这就是装饰器的功能,在一个功能或者函数的基础上,扩展一个新的功能(或者函数),原来的函数功能不会变。
举一个开发过程中的例子,测试一段代码运行时间:
import time
print(time.time) # 1661240843.8702693
# 这里引用 time模块(module,后续会学到),显示的是从1970年1月1日0时0分0秒 到现在的秒数
版本1:
import time
def func():time.sleep(3) # 为了方便模拟程序运行,定义一个睡3秒的函数
def calc_time():
start_time = time.time()
func()
end_time = time.time()
print(end_time-start_time)
calc_time() # 3.0000274181365967
# 但是这里只计算了func()函数的执行时间,如果要计算其他函数呢?可以把函数名当参数传进去。
版本2:
import time
def func1():time.sleep(2)
def func2():time.sleep(3)
def func3():time.sleep(4)
def calc_time(func):
start_time = time.time()
func()
end_time = time.time()
print(end_time-start_time)
calc_time(func1) # 2.000335931777954
calc_time(func2) # 3.0000085830688477
# 感觉还是不方便,这里calc_time函数并不是对func1,func2,func3 扩展,两者毫无关系,只是想测func1这些函数的执行时间才运行一下calc_time函数,考虑到有很多函数有可能每次运行都要记录一下时间,或者有些函数每次运行都要写日志log到日志文件,那就要用到闭包。
版本3(基本成型):
import time
def func1():time.sleep(2)
def func2():time.sleep(3)
def func3():time.sleep(4)
def calc_time(func):
def inner():
start_time = time.time()
func()
end_time = time.time()
print(end_time-start_time)
return inner
f1 = calc_time(func1)
f1() # 2.0003490447998047
# 这样f1()执行,相当于func1()执行,f1随便调用,每次调用都会计算一次func1()执行的时间。
# 虽然每次运行f1,都能额外计算func1的时间,不过,还是不方便,我已经定义一次func1了,居然还要再定义一个f1?
# 其实python 已经给了我们装饰器的解决方案,装饰器函数也就是这里的calc_time函数,应该写在最前面,然后在每个想被装饰的函数上面加一句代码 @calc_time 就可以了。
版本4(近乎完美):
import time
def calc_time(func):
def inner():
start_time = time.time()
func()
end_time = time.time()
print(end_time-start_time)
return inner
@calc_time
def func1():time.sleep(2)
@calc_time
def func2():time.sleep(3)
@calc_time
def func2():time.sleep(4)
func1()
func1()
func2()....
# 随便调用每个被装饰的函数的运行,都会走一遍calc_time这个装饰函数。
# 一个函数应该可以被多个装饰器装饰吧?
# 蛋是:如果被装饰的函数带有返回值呢?那么装饰器函数中也要体现返回值
版本5(被装饰函数返回值):
import time
def calc_time(func):
def inner():
start_time = time.time()
ret= func() # 这里做一下改变,之前是func()
end_time = time.time()
print(end_time-start_time)
return ret #返回
return inner
@calc_time
def func1():
time.sleep(2)
return 1 # 带返回值
func1()
# 2.0003511905670166
# 1
# 结果中不但打印了装饰器函数中的内容,还打印了被装饰的返回值
# 被装饰的函数带参数怎么办?参数也要传到装饰器函数中的哦
版本6(被装饰的函数带参数):
import time
def calc_time(func):
def inner(name): # 这里加上name参数
start_time = time.time()
ret= func(name)
end_time = time.time()
print(end_time-start_time)
return ret
return inner
@calc_time
def func1(name):
time.sleep(2)
return name
func1('lyq')
# 2.0003457069396973
# 'lyq'
# 如果参数很多,不确定,什么类型都有怎么办?
版本7(完美版本):
import time
def calc_time(func):
def inner(*args,**kwargs): # 这里加上name参数
start_time = time.time()
ret= func(*args,**kwargs)
end_time = time.time()
print(end_time-start_time)
return ret
return inner
@calc_time
def func1(name):
time.sleep(2)
return name
@calc_time
def func2(name,age):
print('Your name is {}, age is {}'.format(name,age))
func2('lyq',21)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号