
Transect-SQL 语言 函数学习
一、聚合函数
解释: 对一组值执行计算,并返回单个值。
1、APPROX_COUNT_DISTINCT()
功能:返回组中唯一非空值的近似数,比count(distinct)效率高,特别适合大数据,统计某一列有多少个不一样的值,另外有错误概率。
演示例子:
代码:
select APPROX_COUNT_DISTINCT(age) from student;
-- 返回结果 3
-- 统计age列不重复的值有多少个
2、AVG()
功能:返回平均数
用上面的表来查年龄的平均值,代码如下:
select avg(age) from student;
-- 返回平均值 15
3、CHECKSUM_AGG()
功能:返回组中各值的校验和,可以检验表中的更改。
用上面的例子,先检验,之后更改一“李二蛋”的年龄,再校验,对比一下:
select CHECKSUM_AGG(CAST(age as int)) from student;
-- 返回 9
update student set age='20' where name='李二蛋';
select CHECKSUM_AGG(CAST(age as int)) from student;
-- 返回 29,说明表被改过?就这点用处?
4、COUNT(),COUNT_BIG()
功能:都返回元组数量,还可以加distinct关键字,COUNT()返回int类型,COUNT_BIG()返回 bigint类型。
代码:
select count(*) from student;
-- 返回 4。说明有四行
-- 还可以搭配distinct 关键字 ,把某一列不重复计数,比如
-- select count(distinct(列名)) .....
-- ALL 和 distinct都是可选参数,默认是ALL
-- 我还可以多个聚合函数同时使用,比如统计所有行的同时,再统计平均年龄
select count(*),avg(age) from student;
-- 返回 4,15 (前面是4行,后面是平均年龄15)
5、GROUPING(),WITH ROLLUP,GROUPING_ID()
功能:GROUPING() 用来返回每个分组是否为rollup结果,是为1,否则为0,可以先看下WITH ROLLUP 功能
用下面这个student1表(学号,姓名,年级,性别,年龄):
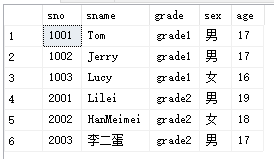
先按分组统计不同年级不同年龄的学生的个数:
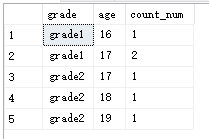
select grade,age,count(*) from student1 group by grade,age
结果:
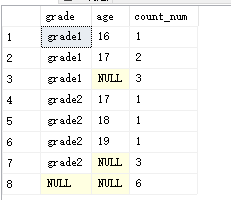
如果加上 WITH ROLLUP 看下结果:
select grade,age,count(*) from student1 group by grade,age with rollup
结果:grade 分组下面多了一个NULL,grade1,grade2 后面的age下面 分别多了NULL,count_num值是按分组的聚合值。
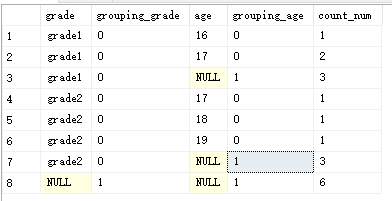
为了方便看出那条记录是 rollup 记录,可以使用GROUPING() :
select grade,GROUPING(grade) as grouping_grade ,age ,GROUPING(age) as grouping_age,count(*) as count_num
from student1
group by grade,age with rollup
结果:
6、MAX(),MIN(),SUM()
功能:求最大值,最小值,求和
select max(age) from student1
-- 返回 19
7、STDEV(), STDEVP(),VAR(),VARP()
功能:标准差 STDEV(),VAR() 方差
返回年龄标准差:
select stdev(age) from student1
-- 返回 1.03279555898864
二、转换函数
1、CAST(表达式 as 类型)
功能:把前面的表达式转换成后面的类型
例子:
declare @myval decimal(5,2)
set @myval = 193.24
select cast(cast(@myval as varbinary(20)) as decimal(10,5));
-- 返回 193.24000
2、CONVERT(类型,表达式)
功能:把后面的表达式转换成前面的类型
例子:
declare @myval decimal(5,2)
set @myval = 193.24
select convert(decimal(10,5),convert(varbinary(20),@myval))
-- 返回 193.24000,与上面的结果一致
3、PARSE(字符串 as 数字类型或日期时间类型)
功能:parse()函数仅仅应用于字符串转为日期时间 或 数字类型 numeric ,其他转换可以用cast 和convert
例子:
SELECT PARSE('Monday, 13 December 2010' AS datetime2 USING 'en-US') AS Result;
-- 返回 2010-12-13 00:00:00.0000000
-- 对被转换的字符串格式要求比较高 ,少个空格都不行
4、TRY_CAST(),TRY_CONVERT(),TRY_PARSE()
功能:如果转换成功返回成功的值,否则返回null
例子:
select
case when try_cast('test' as float) is null
then 'cast failed'
else 'cast succeeded'
end as result;
-- 返回 cast failed,其他函数类似
三、排名
1、RANK(),DENSE_RANK()
功能:排名,被排的列,相等的话,就是并列排名,rank()排名的数值可能不连续,dense_rank()排名数值连续(比如2个并列第一,第三个位置的排名就是第二)。
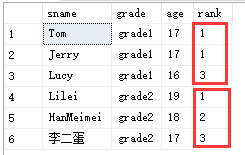
例子:用student1表来排序每个年级 同学年龄的由大到小的排名

代码:
select a.sname,a.grade,a.age,rank() over (partition by a.grade order by a.age desc) as rank
from student1 a
-- 如果对所有同学年龄排名可以这样写
-- select a.sname ,a.age,rank() over (order by age desc) as rank_age from student1 a
结果:
dense_rank 例子:
select t.sname,t.age,DENSE_RANK() over(order by t.age desc) as rank_age
from student1 t
-- 最后一名不是6 而是4
结果:

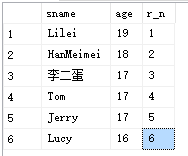
2、ROW_NUMBER()
功能:和rank()类似
例子:
select t.sname,t.age,ROW_NUMBER() over (order by age desc) as r_n
from student1 t
-- 结果是列出来了行号
结果:
例子:
-- 如果分区统计 行号呢?
select t.sname,t.grade ,t.age,ROW_NUMBER() over (partition by t.grade order by age desc) as r_n
from student1 t
结果:

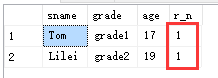
例子:
--如果想把分区统计的 第一行取出来呢?
select * from
(select t.sname,t.grade ,t.age,
ROW_NUMBER() over (partition by t.grade order by age desc) as r_n
from student1 t
) s
where s.r_n='1'
-- 结果是把行号为1的记录取了出来,这样会对并列第一的,不公平!
结果:
四、字符串
1、ASCII() 2、CHAR() 3、NCHAR() ,4、UNICODE()
直接看例子:
select ASCII('A') as A
-- 返回 65
select CHAR(65) as c
-- 返回 A
select CHAR(256) as c
-- 返回 NULL ,char 的范围是 0~255
select NCHAR(65) as nc
-- 返回 A
select NCHAR(65536) as nc
-- 返回 NULL ,NCHAR 范围是 0-~65535
select UNICODE(char(64)) as u
-- 返回 64 ,不知道有啥用
2、UPPER(),LOWER()
功能:大写,小写
例子:
select UPPER('hello') as upper_str
-- 返回 HELLO
select LOWER('HELLO') as lower_str
-- 返回 hello
3、TRIM(),LTRIM(),RTRIM()
功能:trim(),删除字符串两侧的空格,还可以删除指定字符和空格,其他两个是删除左侧和右侧空格
例子:
select trim(' hello,world! ') as trim_str
-- 返回 hello,world!,默认删除两端空格
select trim('.,! ' from ' hello,world! ') as trim_str
-- 返回 hello,world (感叹号没有了,还有from前面的引号内最后一个字符是空格
4、CONCAT() ,CONCAT_WS()
功能:字符串的拼接,concat_ws()函数还可以,指定拼接的字符。
例子:
select CONCAT('hello ','world!') as result
-- 返回 hello world!
select CONCAT_WS(',','hello','world!') as result
-- 返回 hello,world! (这样就很方便生成csv格式的数据,csv以逗号隔开)
5、CHARINDEX(),LEN(),PATINDEX()
功能:charindex()或者指定字符或字符串,在整个串的位置;LEN() 获取字符串长度。
例子:
select CHARINDEX('w','hello,world')
-- 返回 7
select LEN('hello,world')
-- 返回 11
6、SOUNDEX(),DIFFERENCE()
功能:soundex()根据字符串读音,返回由4个字符组成的字符串,difference(),返回2个字符串读音的差异。
例子:
select SOUNDEX('son'),SOUNDEX('sun')
-- 返回 S260 S600
select DIFFERENCE('son','sun')
-- 返回 3
select DIFFERENCE('hello','world')
-- 返回 0 (难道,数字越小 差异越大?)
7、FORMAT()
功能:格式化
例子:
declare @d date = getdate();
select FORMAT(@d,'dd/MM/yyyy','en-us') as 'date',FORMAT(13245678,'##-##-####') as result;
-- 返回 14/07/2022 13-24-5678
8、LEFT(),RIGHT(),SUBSTRING()
功能:LEFT()从左边取指定长度字符串,RIGHT()从右边取指定长度字符串,substring()取指定位置指定长度的字符串
例子:
select LEFT('hello',2) as result
-- 返回 he
select right('hello',2) as result
-- 返回 lo
select SUBSTRING('hello,world!',2,3)
-- 返回 ell
9、REVERSE()转置
例子:
select REVERSE('hello') as result
-- 返回 olleh
10、REPLACE(),REPLICATE(),TRANSLATE()
功能:替换和补全
例子:
select REPLACE('hello,world','o','a') as result;
-- 返回 hella,warld
select TRANSLATE('hello,world','ol','ab') as result
-- 返回 hebba,warbd(把o换成a,把l换成b)
declare @strno varchar(6) = '786'
select REPLICATE('0',6-LEN(@strno))+@strno
-- 返回 000786

 浙公网安备 33010602011771号
浙公网安备 33010602011771号