
chapter1 :Pandas DataFrame 基础知识
2021.6.22
一、加载数据集
#read_csv 函数加载csv文件(head取前5条)
import pandas
df = pandas.read_csv('students.csv')
print(df.head())
cust_no name age
0 1001 tom 25
1 1002 lilei 24
2 1003 hanmeimei 22
#用内置函数type读取read_csv返回的类型是不是DataFrame
print(type(df))
<class 'pandas.core.frame.DataFrame'>
#获取行数和列数(3行3列),返回的是个元组,shape是个属性,不是方法
print(df.shape)
(3, 3)
#获取列名columns
print(df.columns)
Index(['cust_no', 'name', 'age'], dtype='object')
#获取每列的类型,每列的类型都应该一致,age是int64整型,name是object类型,如果某列有空值怎么办?
print(df.dtypes)
cust_no int64
name object
age int64
dtype: object
#获取更多的信息
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cust_no 3 non-null int64
1 name 3 non-null object
2 age 3 non-null int64
dtypes: int64(2), object(1)
memory usage: 200.0+ bytes
None
#pandas 和 python类型的对比
#object 对应 string :最常用数据类型
#int64 对应 int :整型
#float64 对应float :浮点型
#datetime64 对应datetime :日期时间
二、查看列、行和单元格
#获取name列(放入中括号)
df_name = df['name']
print(df_name)
0 tom
1 lilei
2 hanmeimei
Name: name, dtype: object
#取name和age列(中括号括起来多个列名)
name_age_df = df[['name','age']]
print(name_age_df)
name age
0 tom 25
1 lilei 24
2 hanmeimei 22
#获取行子集(loc 和 iloc)
#获取第一行
print(df.loc[0])#也是用中括号
cust_no 1001
name tom
age 25
Name: 0, dtype: object
#获取第三行
print(df.loc[2])
cust_no 1003
name hanmeimei
age 22
Name: 2, dtype: object
#获取最后一行
pring(df.loc[-1])#报错了,因为默认行号中都是从0开始的正整数,没有负数
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-16-9d42ef399860> in <module>
1 #获取最后一行
----> 2 pring(df.loc[-1])
NameError: name 'pring' is not defined
#但是可以获取最后一行的索引,然后取最后一行
last_row_num = df.shape[0]-1 #取形状的第一个值再减去1
print(df.loc[last_row_num])
cust_no 1003
name hanmeimei
age 22
Name: 2, dtype: object
#也可以用tail方式返回最后一行,这种现实方式和loc的方式不一致
print(df.tail(n=1))
cust_no name age
2 1003 hanmeimei 22
#对比一下2种方式返回的对象的类型,loc返回的是个series(竖着显示的是series),tail返回的还是一个dataframe(横着显示的是dataframe)
print(type(df.loc[last_row_num]))
print(type(df.tail(n=1)))
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
#还可以选取多行(也是2个中括号)
print(df.loc[[0,2]])
cust_no name age
0 1001 tom 25
2 1003 hanmeimei 22
#iloc跟loc相似,但是iloc可以用-1来取最后一行(loc=location?)
print(df.iloc[-1])
cust_no 1003
name hanmeimei
age 22
Name: 2, dtype: object
#loc和iloc还可以取多行多列(混用),取第1,3行的name和age列,loc的中括号中有2个中括号用逗号隔开,分别代表取的行和列
print(df.loc[[0,2],['name','age']])
name age
0 tom 25
2 hanmeimei 22
#python的切片法,冒号(:)。如果只用一个冒号,代表取所有数据,下面例子取所有行
print(df.loc[:,['name','age']])
name age
0 tom 25
1 lilei 24
2 hanmeimei 22
#以上不能用iloc,iloc只能用整数来取子集(就是某几行,某几列),loc的列只能用名字,不能用编号
print(df.iloc[:,[0,-1]]) #这里取第一列和最后一列的所有行
cust_no age
0 1001 25
1 1002 24
2 1003 22
#还可以通过python内置range函数取子集
my_range=list(range(1,3)) #顾首不顾尾
print(my_range)
print(df.iloc[:,my_range])
[1, 2]
name age
0 tom 25
1 lilei 24
2 hanmeimei 22
#range还有步长,另外range是个生成器
print(list(range(0,6,2))) #其中2是一次走2步
[0, 2, 4]
20210623
#读取一个学生成绩表
df_course = pandas.read_csv('data/course.csv')
print(df_course)
sno sname age course score
0 1001 Tom 25 英语 87
1 1001 Tom 25 数学 98
2 1001 Tom 25 语文 76
3 1002 Jerry 22 英语 91
4 1002 Jerry 22 数学 89
5 1002 Jerry 22 语文 86
6 1003 Lucy 21 语文 100
7 1003 Lucy 21 英语 87
8 1003 Lucy 21 数学 80
使用切片语法获取列的子集
#range函数可用于创建生成器并转换成一个列表,但切片的冒号语法仅仅在做切片的时候才有意义,本身没有内在含义
small_range = list(range(3)) #获取一个0-2的整数列表
subset = df_course.iloc[:,small_range] #冒号是行的索引(代表取所有),iloc用数字当列索引,loc用列名当列的索引
print(subset.head()) #head只取前5行
sno sname age
0 1001 Tom 25
1 1001 Tom 25
2 1001 Tom 25
3 1002 Jerry 22
4 1002 Jerry 22
#切片法获取前三列
subset = df_course.iloc[:,:3]
print(subset.head())
sno sname age
0 1001 Tom 25
1 1001 Tom 25
2 1001 Tom 25
3 1002 Jerry 22
4 1002 Jerry 22
#获取第3,4,5列
subset = df_course.iloc[:,2:5] #冒号前后 顾首不顾尾
print(subset.head())
age course score
0 25 英语 87
1 25 数学 98
2 25 语文 76
3 22 英语 91
4 22 数学 89
#取1,3,5列
subset = df_course.iloc[:,0:5:2]
print(subset.head())
sno age score
0 1001 25 87
1 1001 25 98
2 1001 25 76
3 1002 22 91
4 1002 22 89
#也可以省略冒号左右的一些数字,比如0::2
subset = df_course.iloc[:,0::2] #从0列开始到最后,每隔1列取一列,相当于取第1,3,5...列
print(subset.head())
sno age score
0 1001 25 87
1 1001 25 98
2 1001 25 76
3 1002 22 91
4 1002 22 89
取特定行的列
#用loc取
subset = df_course.loc[2,'sname'] #取第三行的sname列
print(subset)
Tom
#用iloc取
subset = df_course.iloc[2,1] #取第三行的sname列,与loc的区别,iloc的i就是index,只能用数字
print(subset)
Tom
#还可以获取多行多列
subset = df_course.iloc[[1,3,4],[1,3,4]] #取第2,4,5行的第2,4,5列
print(subset)
sname course score
1 Tom 数学 98
3 Jerry 英语 91
4 Jerry 数学 89
#尽量使用列名来取值(用loc,不容易错,如果列多了,还要计算一下这个列的索引是多少)
subset = df_course.loc[[1,3,4],['sname','course','score']]
print(subset)
sname course score
1 Tom 数学 98
3 Jerry 英语 91
4 Jerry 数学 89
分组和聚合
#计算每个人的平均分,聚合的步骤相当于“分组-计算-组合”的过程,用groupby函数
print(df_course.groupby('sname')['score'].mean()) #其中groupby函数参数是sname,要分组的列,然后根据列选出分数score列并计算平均数mean
sname
Jerry 88.666667
Lucy 89.000000
Tom 87.000000
Name: score, dtype: float64
print(df_course.groupby('course')) #这里只是单纯的返回了内存位置
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001D067504370>
#求所有分数的平均数
print(df_course['score'].mean())
88.22222222222223
#还可以按2个列分组,比如按姓名sname,科目course分组
df_course_groupby = df_course.groupby(['sname','course'])['score'].mean()
print(df_course_groupby)
sname course
Jerry 数学 89
英语 91
语文 86
Lucy 数学 80
英语 87
语文 100
Tom 数学 98
英语 87
语文 76
Name: score, dtype: int64
#还可以对上面的这个dataframe平铺一下(reset_index()),又回到原来的列表了,平铺是分组聚合的相反的过程
print(df_course_groupby.reset_index())
sname course score
0 Jerry 数学 89
1 Jerry 英语 91
2 Jerry 语文 86
3 Lucy 数学 80
4 Lucy 英语 87
5 Lucy 语文 100
6 Tom 数学 98
7 Tom 英语 87
8 Tom 语文 76
#还可以对分组的数据计数nunique(不重复计数)
print(df_course.groupby('sname')['course'].nunique()) #对按照姓名分组,选出来的科目course进行不重复计数,当然都是3,表里记录了每个人三门课的成绩
sname
Jerry 3
Lucy 3
Tom 3
Name: course, dtype: int64
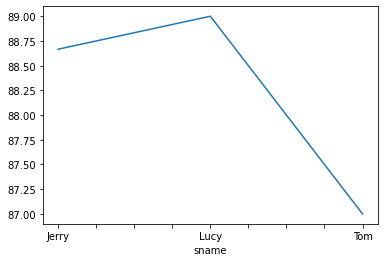
基本绘图
#拿以上df_course举个没有太大意义的例子,主要看功能
df_course.groupby('sname')['score'].mean().plot() #计算了每个人的平均分,然后按照平均分做了一个走势图
<AxesSubplot:xlabel='sname'>
chapter2:Pandas 数据结构
一、创建数据
创建Series
#Series是一维容器,类似于Python中的List,Numpy中的ndarray,但是Series中所有值的类型必须相同
import pandas as pd
s = pd.Series(['Tom',98])
print(s) #这里在Series中传入了2个值,一个是字符串Tom,一个是数字98,最后dtype是object类型
0 Tom
1 98
dtype: object
s=pd.Series([89,90,75])
print(s) #这里传入3个数值,得到dtype是int64
0 89
1 90
2 75
dtype: int64
#左侧0,1,2.。。都是索引,还可以指定索引的值,比如:
s = pd.Series(['Tom',98],index=['name','score'])
print(s) #左侧的索引变成了name 和 score 等有实际意义的内容了
name Tom
score 98
dtype: object
20210624
创建DataFrame
#DataFrame相当于Series组成的字典,
students = pd.DataFrame({ #字典就要带大括号了,键值对以冒号隔开,值是个列表用中括号
'name':['Tom','Jerry','Linda'],
'age':[19,20,18],
'born':['2003-02-03','2002-02-02','2001-01-01']
})
print(students)
name age born
0 Tom 19 2003-02-03
1 Jerry 20 2002-02-02
2 Linda 18 2001-01-01
#可以指定列的顺序
students = pd.DataFrame(
data={
'name':['Tom','Jerry','Linda'],
'age':[19,20,18],
'born':['2003-02-03','2002-02-02','2001-01-01']},
columns=['born','age','name'] #这里可以调整一下列的顺序,把名字移到最后了
)
print(students)
born age name
0 2003-02-03 19 Tom
1 2002-02-02 20 Jerry
2 2001-01-01 18 Linda
#还可以把name当做列索引
students = pd.DataFrame(
data={
'age':[19,20,18],
'born':['2003-02-03','2002-02-02','2001-01-01']},
columns=['born','age'],
index=['Tom','Jerry','Linda'] #用index做行的索引
)
print(students)
born age
Tom 2003-02-03 19
Jerry 2002-02-02 20
Linda 2001-01-01 18
Series对象
#取出一行看看类型
first_row = students.loc['Tom']
print(type(first_row)) #结果看到这是一个Series对象
<class 'pandas.core.series.Series'>
print(first_row) #输出的第一列,是索引index(其实是原表的列头),第二列是值values,Series对象有index和values等属性
born 2003-02-03
age 19
Name: Tom, dtype: object
print(first_row.index) #输出Series的索引
print(first_row.keys()) #keys()函数和index属性效果一样
print(first_row.values) #输出values的值
Index(['born', 'age'], dtype='object')
Index(['born', 'age'], dtype='object')
['2003-02-03' 19]
#属性后面跟方括号[],方法后面跟圆括号()
print(first_row.index[1])
print(first_row.keys()[1])
age
age
#Series的一些属性:loc iloc ix dtype dtypes T shape size values
print(first_row.shape) #数据的维数
(2,)
#刚才讲的loc获取一行代表一个Series,现在看看获取一列是什么
ages = students['age']
print(type(ages)) #从结果看,也是一个Series,Series是Pandas的一个数据结构
print(ages)
<class 'pandas.core.series.Series'>
Tom 19
Jerry 20
Linda 18
Name: age, dtype: int64
类似于ndarray的Series
#Series与numpy.ndarray相似,很多方法通用,Series也称“向量”
print(ages.mean())
print(ages.min())
print(ages.max())
print(ages.std()) #Series还有常用的方法,append(追加),drop_duplicates(去重),equals(判断2个Series是否相等),std(标准差),
#mean(算术平均数),transpose(返回转置),to_frame(转成DataFrame),sort_values(排序),isin(逐个判断每个值是否在参数的列表中)
19.0
18
20
1.0
print(ages.hist()) #绘制直方图
AxesSubplot(0.125,0.125;0.775x0.755)

print(ages.isin([20,10,19,17]))#逐个判断ages中的values是否在isin的参数列表中
Tom True
Jerry True
Linda False
Name: age, dtype: bool
print(ages.describe()) #获取基本描述,里面有count mean std min max 等等
count 3.0
mean 19.0
std 1.0
min 18.0
25% 18.5
50% 19.0
75% 19.5
max 20.0
Name: age, dtype: float64
#获取年龄大于18的学生的年龄
print(ages[ages>18]) #这里把ages与18比较当做条件,然后放在中括号中取子集
Tom 19
Jerry 20
Name: age, dtype: int64
print(ages>ages.mean())#逐个比较value与平均值mean的结果,返回的还是一个Series,这是以前没见过的方式,相当于不用for循环就可以实现对每个元素处理
Tom False
Jerry True
Linda False
Name: age, dtype: bool
操作自动对齐 和 向量化(广播)
print(ages+ages) #可以两个相加,其实是相同的位置,各个元素相加,这说明这个数据结构Series是向量化的数据结构
Tom 38
Jerry 40
Linda 36
Name: age, dtype: int64
#还可以加一个常数或者一个乘以一个常数
print(ages*3)
Tom 57
Jerry 60
Linda 54
Name: age, dtype: int64
print(pandas.Series([1,2,3,4,5])+pandas.Series([2,2,2])) #得到的结果有的是NaN(not a number),只有前三个逐个相加了
0 3.0
1 4.0
2 5.0
3 NaN
4 NaN
dtype: float64
#创建一个分数的Series
scores = pandas.Series([61,75,98,77,20,80])
print(scores)
0 61
1 75
2 98
3 77
4 20
5 80
dtype: int64
rev_scores= scores.sort_index(ascending=False) #ascending = False ,倒叙排列
print(rev_scores)
5 80
4 20
3 77
2 98
1 75
0 61
dtype: int64
print(rev_scores+scores) #得到的结果,是自动按照索引的顺序一一对应并相加的
0 122
1 150
2 196
3 154
4 40
5 160
dtype: int64
20210625
DataFrame对象
#DataFrame是最常见的Pandas数据结构,Series的很多特征同样适用DataFrame
#以df_course为例,取各科分数大于90的学生的各科分数
print(df_course[df_course['score']>90])
sno sname age course score
1 1001 Tom 25 数学 98
3 1002 Jerry 22 英语 91
6 1003 Lucy 21 语文 100
#利用布尔向量bool,[True,True,False....]相当于bool向量,里面是9个值,正好对应df_course的9行,这里只有第三个是False,相当于除了第三行,其他都取
print(df_course.loc[[True,True,False,True,True,True,True,True,True]])
sno sname age course score
0 1001 Tom 25 英语 87
1 1001 Tom 25 数学 98
3 1002 Jerry 22 英语 91
4 1002 Jerry 22 数学 89
5 1002 Jerry 22 语文 86
6 1003 Lucy 21 语文 100
7 1003 Lucy 21 英语 87
8 1003 Lucy 21 数学 80
#看一下DataFrame与标量的运算
print(df_course*2) #结果中数值会乘以2,字符串再拼接一个相同的字符串,这是向量化的体现,但是加法像是会报错,
sno sname age course score
0 2002 TomTom 50 英语英语 174
1 2002 TomTom 50 数学数学 196
2 2002 TomTom 50 语文语文 152
3 2004 JerryJerry 44 英语英语 182
4 2004 JerryJerry 44 数学数学 178
5 2004 JerryJerry 44 语文语文 172
6 2006 LucyLucy 42 语文语文 200
7 2006 LucyLucy 42 英语英语 174
8 2006 LucyLucy 42 数学数学 160
DataFrame 获取子集的总结
#df[column_name] 获取单列
#df[[column1,column2,...]] 获取多列
#df.loc[row_label] 根据标签名获取单行
#df.loc[[label1,label2,....] 根据标签名获取多行
#df.iloc[row_number] 根据行索引获取单行
#df.iloc[[number1,number2,....]] 根据行索引获取多行
#df[[bool,bool,bool,....]] 根据bool值获取行,但是列表中bool数量应该与df的行数一致
#df[start:stop:step] 根据切片法获取行
#用切片法获取前4行
print(df_course[:4])
sno sname age course score
0 1001 Tom 25 英语 87
1 1001 Tom 25 数学 98
2 1001 Tom 25 语文 76
3 1002 Jerry 22 英语 91
之前的都是查,现在要增删改
#可以为df_course增加一个科目考试日期,比如都是2021年6月25日考试的(2021-06-25)
df_date = pandas.Series(['2021-06-25']*9)
print(df_date)
0 2021-06-25
1 2021-06-25
2 2021-06-25
3 2021-06-25
4 2021-06-25
5 2021-06-25
6 2021-06-25
7 2021-06-25
8 2021-06-25
dtype: object
#添加日期列,就像获取日期列一样,直接赋值,赋的是一个Series
print(type(df_date))
df_course['date'] = df_date
print(df_course.head())
<class 'pandas.core.series.Series'>
sno sname age course score date
0 1001 Tom 25 英语 87 2021-06-25
1 1001 Tom 25 数学 98 2021-06-25
2 1001 Tom 25 语文 76 2021-06-25
3 1002 Jerry 22 英语 91 2021-06-25
4 1002 Jerry 22 数学 89 2021-06-25
#添加行试试,用append,目前总共9行,添加第10行,用索引9
df2 = pandas.DataFrame(data={'sno':[1004],'sname':['Lily'],'age':[24],'course':['语文'],'score':[100],'date':['2021-06-25']},\
columns=['sno','sname','age','course','score','date'],index=[9]) #此处用了索引9
print(df2)
print('-------------------------')
df_course = df_course.append(df2,ignore_index=False) #用append加1行
print(df_course) #追加了一行之后,每列的格式有变化,分数score和年龄age应该是整数才对
sno sname age course score date
9 1004 Lily 24 语文 100 2021-06-25
-------------------------
sno sname age course score date
0 1001.0 Tom 25.0 英语 87.0 2021-06-25
1 1001.0 Tom 25.0 数学 89.0 2021-06-25
2 1001.0 Tom 25.0 语文 87.0 2021-06-25
3 1002.0 Jerry 22.0 英语 98.0 2021-06-25
4 1002.0 Jerry 22.0 数学 76.0 2021-06-25
5 1002.0 Jerry 22.0 语文 86.0 2021-06-25
6 1003.0 Lucy 21.0 语文 100.0 2021-06-25
7 1003.0 Lucy 21.0 英语 80.0 2021-06-25
8 1003.0 Lucy 21.0 数学 91.0 2021-06-25
9 1004 Lily 24.0 语文 100.0 2021-06-25
#修改某列的类型为整型
df_course['sno']=df_course['sno'].astype('int64')
df_course['age']=df_course['age'].astype('int64')
df_course['score']=df_course['score'].astype('int64')
print(df_course)
sno sname age course score date
0 1001 Tom 25 英语 80 2021-06-25
1 1001 Tom 25 数学 98 2021-06-25
2 1001 Tom 25 语文 87 2021-06-25
3 1002 Jerry 22 英语 91 2021-06-25
4 1002 Jerry 22 数学 86 2021-06-25
5 1002 Jerry 22 语文 100 2021-06-25
6 1003 Lucy 21 语文 100 2021-06-25
7 1003 Lucy 21 英语 76 2021-06-25
8 1003 Lucy 21 数学 87 2021-06-25
9 1004 Lily 24 语文 89 2021-06-25
#还可以更改现有列,比如把分数score随机化处理
import random
random.seed(42) #先设置种子
random.shuffle(df_course['score']) #再用shuffle函数打乱df_course的score列
print(df_course) #分数打乱了
sno sname age course score date
0 1001 Tom 25 英语 76 2021-06-25
1 1001 Tom 25 数学 91 2021-06-25
2 1001 Tom 25 语文 87 2021-06-25
3 1002 Jerry 22 英语 87 2021-06-25
4 1002 Jerry 22 数学 100 2021-06-25
5 1002 Jerry 22 语文 100 2021-06-25
6 1003 Lucy 21 语文 89 2021-06-25
7 1003 Lucy 21 英语 86 2021-06-25
8 1003 Lucy 21 数学 80 2021-06-25
9 1004 Lily 24 语文 98 2021-06-25
d:\ProgramData\Anaconda3\lib\random.py:307: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
x[i], x[j] = x[j], x[i]
#查看现在所有列的类型
print(df_course.dtypes)
sno int64
sname object
age int64
course object
score int64
date object
dtype: object
删除行、列
#用drop删除列,找到列名,指定axis=1
df_course_drop_column = df_course.drop(['date'],axis=1)
print(df_course_drop_column)
sno sname age course score
0 1001 Tom 25 英语 76
1 1001 Tom 25 数学 91
2 1001 Tom 25 语文 87
3 1002 Jerry 22 英语 87
4 1002 Jerry 22 数学 100
5 1002 Jerry 22 语文 100
6 1003 Lucy 21 语文 89
7 1003 Lucy 21 英语 86
8 1003 Lucy 21 数学 80
9 1004 Lily 24 语文 98
#删除行,找到索引,删除
df_course_drop_row = df_course.drop([9])
print(df_course_drop_row)
sno sname age course score date
0 1001 Tom 25 英语 76 2021-06-25
1 1001 Tom 25 数学 91 2021-06-25
2 1001 Tom 25 语文 87 2021-06-25
3 1002 Jerry 22 英语 87 2021-06-25
4 1002 Jerry 22 数学 100 2021-06-25
5 1002 Jerry 22 语文 100 2021-06-25
6 1003 Lucy 21 语文 89 2021-06-25
7 1003 Lucy 21 英语 86 2021-06-25
8 1003 Lucy 21 数学 80 2021-06-25
导出和导入
#取df_course的一列,导出pickle文件,pickle文件是二进制格式,文本方式打开是乱码,可以保存python程序产生的中间值,节省磁盘存储空间
df_course_sname = df_course['sname']
df_course_sname.to_pickle('df_course_sname.pickle')
#读取pickle文件
df_read_pickle = pandas.read_pickle('df_course_sname.pickle')
print(type(df_read_pickle)) #读取的还是Series类型
print(df_read_pickle)
<class 'pandas.core.series.Series'>
0 Tom
1 Tom
2 Tom
3 Jerry
4 Jerry
5 Jerry
6 Lucy
7 Lucy
8 Lucy
9 Lily
Name: sname, dtype: object
20210629
Chapter3: 绘图入门
seaborn库的使用
#取出Anscombe数据集看看(网上找的,可以自行把以下结果黏贴成csv文件)
import pandas as pd
anscombe = pd.read_csv('anscombe.csv',sep='\t')
print(anscombe)
dataset x y
0 I 10.0 8.04
1 I 8.0 6.95
2 I 13.0 7.58
3 I 9.0 8.81
4 I 11.0 8.33
5 I 14.0 9.96
6 I 6.0 7.24
7 I 4.0 4.26
8 I 12.0 10.84
9 I 7.0 4.82
10 I 5.0 5.68
11 II 10.0 9.14
12 II 8.0 8.14
13 II 13.0 8.74
14 II 9.0 8.77
15 II 11.0 9.26
16 II 14.0 8.10
17 II 6.0 6.13
18 II 4.0 3.10
19 II 12.0 9.13
20 II 7.0 7.26
21 II 5.0 4.74
22 III 10.0 7.46
23 III 8.0 6.77
24 III 13.0 12.74
25 III 9.0 7.11
26 III 11.0 7.81
27 III 14.0 8.84
28 III 6.0 6.08
29 III 4.0 5.39
30 III 12.0 8.15
31 III 7.0 6.42
32 III 5.0 5.73
33 IV 8.0 6.58
34 IV 8.0 5.76
35 IV 8.0 7.71
36 IV 8.0 8.84
37 IV 8.0 8.47
38 IV 8.0 7.04
39 IV 8.0 5.25
40 IV 19.0 12.50
41 IV 8.0 5.56
42 IV 8.0 7.91
43 IV 8.0 6.89
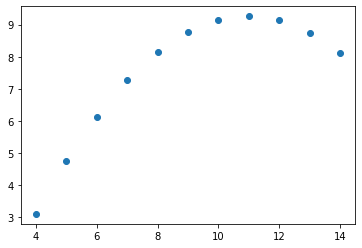
#用matplotlib.pyplot把Anscombe数据集画图
import matplotlib.pyplot as plt
dataset_1 = anscombe[anscombe['dataset']=='I']#把数据集中dataset列值为I的子集选出来
print(plt.plot(dataset_1['x'],dataset_1['y']))
[<matplotlib.lines.Line2D object at 0x000002370C8C5AF0>]

#默认情况下plot是划线,也可以画圆点,传递一个o参数
print(plt.plot(dataset_1['x'],dataset_1['y'],'o'))
[<matplotlib.lines.Line2D object at 0x000002370C9312B0>]

#再尝试个II的点图
dataset_2 = anscombe[anscombe['dataset']=='II']
print(plt.plot(dataset_2['x'],dataset_2['y'],'o'))
[<matplotlib.lines.Line2D object at 0x000002370C98A9A0>]
#还可以把四种类型的dataset放在一个图中
#创建一个画布
fig=plt.figure()
#创建第一个子图
axes1 = fig.add_subplot(2,2,1) #2行2列,从左到右,从上到下第1个位置
#创建第二三四
axes2 = fig.add_subplot(2,2,2)
axes3 = fig.add_subplot(2,2,3)
axes4 = fig.add_subplot(2,2,4)
print(fig)#打印一下,啥都没有

#获取剩下的2个子集
dataset_3 = anscombe[anscombe['dataset']=='III']
dataset_4 = anscombe[anscombe['dataset']=='IV']
#然后把4个子集数据对应到4个axes中
axes1.plot(dataset_1['x'],dataset_1['y'],'o')
axes2.plot(dataset_2['x'],dataset_2['y'],'o')
axes3.plot(dataset_3['x'],dataset_3['y'],'o')
axes4.plot(dataset_4['x'],dataset_4['y'],'o')
fig
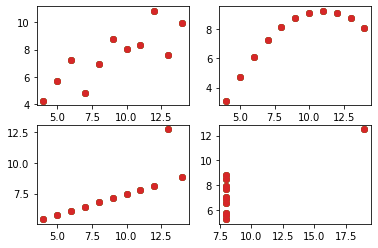
#向各个子图添加小标题
axes1.set_title("dataset_1")
axes2.set_title("dataset_2")
axes3.set_title("dataset_3")
axes4.set_title("dataset_4")
#添加大标题
fig.suptitle("Anscombe Data")
#使用紧凑布局
fig.tight_layout()
fig

20210705
使用matplotlib绘制统计图
#加载seaborn中的tips数据集,这里下载好的
import pandas as pd
tips = pd.read_csv('brightch-seaborn-data-master/seaborn-data/tips.csv')
print(tips.head()) #total_bill 账单总额,tip小费,sex性别,smoker是否吸烟,day星期,time早中晚餐,size人数
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
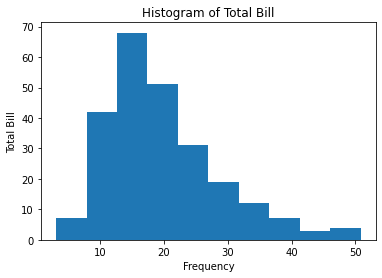
#绘制直方图,这是一个单变量图(Histogram),显示账单在各个区间的频率
import matplotlib.pyplot as plt
fig = plt.figure()
axes1 = fig.add_subplot(1,1,1)
axes1.hist(tips['total_bill'],bins=10) #在直方图中加载数据,第一个参数,是x轴
axes1.set_title('Histogram of Total Bill') #设置标题
axes1.set_xlabel('Frequency') #设置x轴
axes1.set_ylabel('Total Bill') #设置y轴
print(fig)
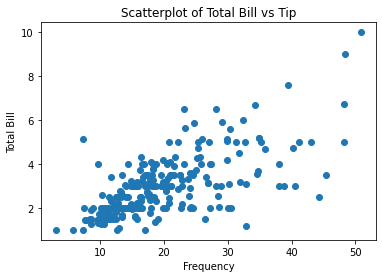
#散点图scatter,双变量图,显示小费和账单的关系
scatter_plot = plt.figure() #画布
axes2 = scatter_plot.add_subplot(1,1,1) #设置画布
axes2.scatter(tips['total_bill'],tips['tip']) #在散点图中加数据,第一个参数是x轴,第二个参数是y轴
axes2.set_title('Scatterplot of Total Bill vs Tip') #设置标题
axes2.set_xlabel('Frequency') #设置x轴
axes2.set_ylabel('Total Bill') #设置y轴
print(scatter_plot)
#箱线图
boxplot = plt.figure()
axes3 = boxplot.add_subplot(1,1,1)
axes3.boxplot(
[tips[tips['sex']=='Female']['tip'],tips[tips['sex']=='Male']['tip']],
labels=['Female','Male']
)
axes3.set_title('Boxplot of Tip by Sex') #设置标题
axes3.set_xlabel('Sex') #设置x轴
axes3.set_ylabel('Tip') #设置y轴
print(boxplot)

#基于性别,创建一个带颜色的“账单小费散点图” (仅供娱乐)
def recode_sex(sex):
if sex=='Female':return 0
else:return 1
tips['sex_color']=tips['sex'].apply(recode_sex) #这里用到apply函数,apply 函数的参数是一个函数名称recode_sex,这个函数参数由调用者tips['sex']传入
scatter_plot2 = plt.figure()
axes4 = scatter_plot2.add_subplot(1,1,1)
axes4.scatter(x=tips['total_bill'],y=tips['tip'],s=tips['size']*10,c=tips['sex_color'],alpha=0.5)
axes4.set_title('scatter plot of Total Bill vs Tip Colored by Sex and Sized by size') #设置标题
axes4.set_xlabel('Total Bill') #设置x轴
axes4.set_ylabel('Tip') #设置y轴
print(scatter_plot2)

用seaborn绘制图
#matplotlib是核心绘图工具,seaborn是基于matplotlib创建的,更简洁,美观
#直方图
import seaborn as sns
hist,ax = plt.subplots() #使用matplotlib 创建画布,
ax = sns.distplot(tips['total_bill']) #使用seaborn的函数distplot画图
ax.set_title('Total Bill Histogram with Density Plot')
print(ax)
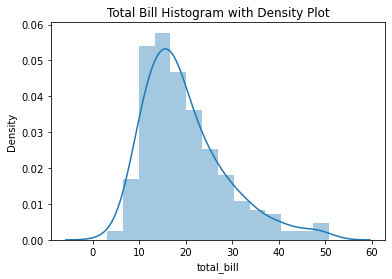
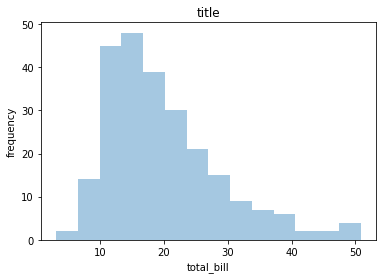
#上面的曲线是密度图,可以通过参数设置把它取消
hist1,ax1 = plt.subplots()
ax1 = sns.distplot(tips['total_bill'],kde=False) #kde这里把密度图取消
ax1.set_title('title')
ax1.set_xlabel('total_bill')
ax1.set_ylabel('frequency')
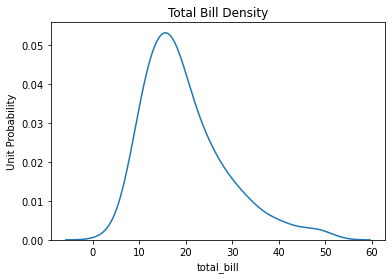
print(ax1)
#密度图,是展示单变量分布的另一种方法,曲线下面的面积是1
den,ax2 = plt.subplots()
ax2 = sns.distplot(tips['total_bill'],hist=False)
ax2.set_title('Total Bill Density')
ax2.set_xlabel('total_bill')
ax2.set_ylabel('Unit Probability')
print(ax2)
#只要密度图,也可以直接用seaborn库的kdeplot函数
den1,ax3=plt.subplots()
ax3 = sns.kdeplot(tips['total_bill']) #kdeplot函数
print(ax3)

#频数图
hist_den_rug,ax4 = plt.subplots()
ax3 = sns.distplot(tips['total_bill'],rug =True)
print(ax3)
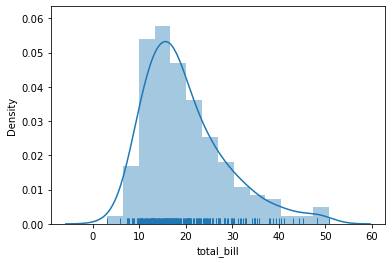
#计数图
count,ax5 = plt.subplots()
ax5 = sns.countplot('day',data=tips) #按照day(星期列)统计,星期六Sat吃饭的次数最多
print(ax5)
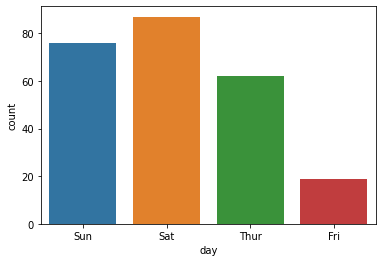
#seaborn画散点图,用regplot
scatter,ax6 = plt.subplots()
ax6 = sns.regplot(x='total_bill',y='tip',data = tips)
print(ax6) #这里还包含了一个条拟合回归线,
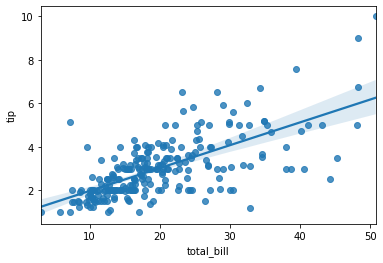
#如果不想显示拟合回归线,可以设置fit_reg=False
scatter,ax7 = plt.subplots()
ax7=sns.regplot(x='total_bill' ,y = 'tip',data=tips,fit_reg=False)
print(ax7)

#lmplot函数和regplot类似,区别是前者不创建轴域
ax8 = sns.lmplot(x='total_bill',y='tip',data=tips)
plt.show()

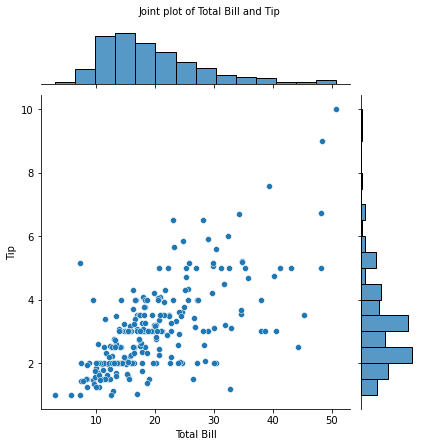
#还可用jointplot函数在每个轴上创建包含单个变量的直方图
joint = sns.jointplot(x='total_bill',y='tip',data=tips)
joint.set_axis_labels(xlabel='Total Bill',ylabel='Tip')
joint.fig.suptitle('Joint plot of Total Bill and Tip',fontsize=10,y=1.03)
print(joint)
#蜂巢图
#点太多了不直观,可以用蜂巢图来代替,蜂巢图类似直方图,只是把点放在一个个六边形的图形中来统计频率
hexbin = sns.jointplot(x='total_bill',y='tip',data=tips,kind='hex')
hexbin.set_axis_labels(xlabel='total bill',ylabel='tip')
hexbin.fig.suptitle('Hexbin joint plot of Total Bill and Tip',fontsize=10,y=1.03)
print(hexbin)
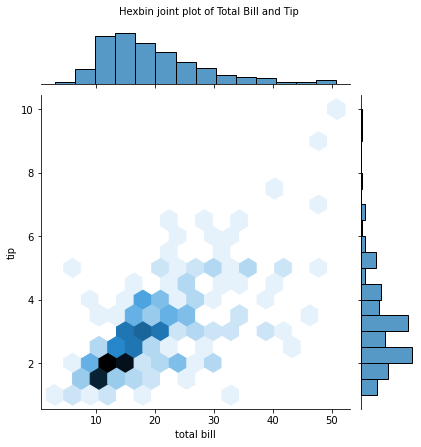
#2D密度图
kde,ax9 = plt.subplots()
ax9 = sns.kdeplot(data=tips['total_bill'],data2=tips['tip'],shade=True)
print(ax9)

#用jointplot再轴域画单变量图
kde_joint = sns.jointplot(x='total_bill',y='tip',data=tips,kind='kde',shade=True)
print(kde_joint)
<seaborn.axisgrid.JointGrid object at 0x0000029A386A0700>
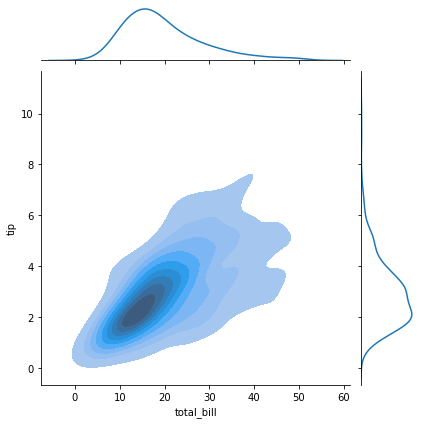

 浙公网安备 33010602011771号
浙公网安备 33010602011771号