

第三次作业
| github地址 | https://github.com/shenyaxin/WordCount.git |
| 结对伙伴作业地址 |
一.结对过程
1.结对过程
在知道要完成结对编程这个作业的时候,已经和现在的结对伙伴组好了队,我们根据代码要求,分工合作了这个任务。分工大概是按照能力大小来分的,现在看来,在我们所预期的时间内,几乎刚刚好完成这个作业。
在第一步中,我完成了统计单词和字符的模块,她完成了统计行数的模块,我们互相审查了对方的代码,修正了一些小细节并合并了代码,封装由我的伙伴完成。在第三部功能新增中,我们各完成了其中的一般。
这是我们在一起讨论时候的照片:

这是预期的花费时间:
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
30 |
|
· stimate |
· 估计这个任务需要多少时间 |
400 |
500 |
|
Development |
开发 |
200 |
300 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
100 |
150 |
|
· Design Spec |
· 生成设计文档 |
30 |
30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
30 |
|
· Design |
· 具体设计 |
40 |
40 |
|
· Coding |
· 具体编码 |
200 |
200 |
|
· Code Review |
· 代码复审 |
30 |
30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
30 |
30 |
|
Reporting |
报告 |
60 |
60 |
|
· Test Report |
· 测试报告 |
30 |
30 |
|
· Size Measurement |
· 计算工作量 |
10 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 |
10 |
|
|
合计 |
1230 |
1480 |
二.编写代码
2.1代码要求
输入文件名以命令行参数传入。统计input.txt中的以下几个指标
(1)统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
(2)统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000 输出的单词统一为小写格式
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
(3)统计文件的有效行数:任何包含非空白字符的行,都需要统计。
2.2设计思路
拿到题目后,首先想到将统计要求分类,分为字符,单词和行数的统计,我和我的伙伴分好任务后,(我的任务为单词和字符),首先想到字符可以用字符串的形式来统计,但是单词几乎没有思路,在网上查找后,发现单词和字符都可以用正则表达式来统计,在粗略的了解了正则表达式后,决定用正则表达式来统计。
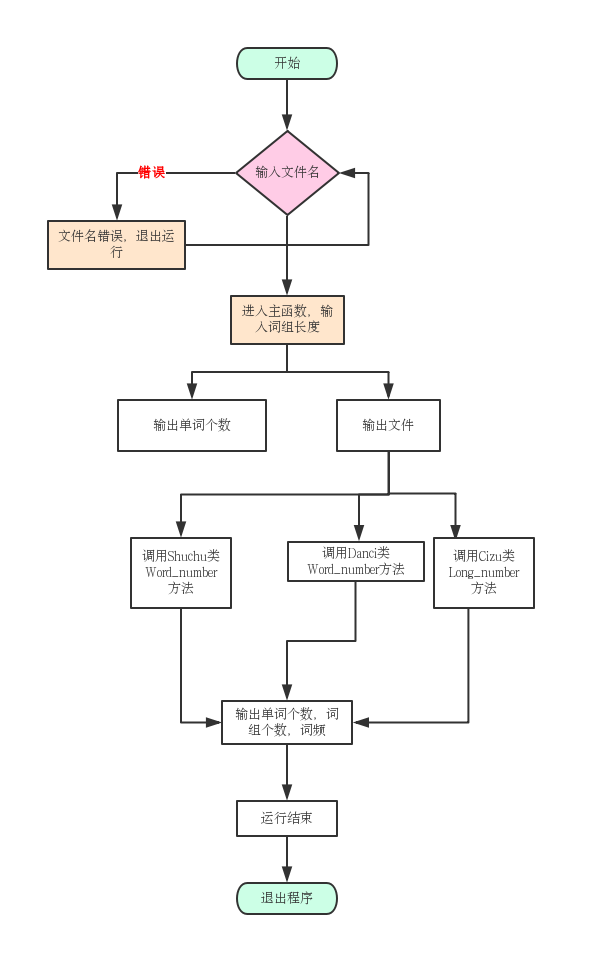
2.3设计过程
首先在主函数中设定输入文件名,然后传参到各个函数中,我们确定只有一个类,设定三个函数,将统计单词量与输出单词合并为一个函数,所以三个函数分别实现单词,字符,和行数。主要采用的是正则表达式来实现的单词和字符统计。这三个类各自编写好后,合并两人代码实现封装时再细化函数功能。
2.4流程图
三.关键代码
1.统计词组
StreamReader reader = new StreamReader(File_name, Encoding.Default); String path = null; string si = null; while ((path = reader.ReadLine()) != null) { si += (path + "\n"); } string[] words = Regex.Split(si, @"\W+"); foreach (string word in words) { if (ss.ContainsKey(word)) { ss[word]++; num++; } else { ss[word] = 1; num++; } }
2.字典类
Dictionary<string, int> ss = new Dictionary<string, int>(); string[] Word1 = new string[num]; int[] Word1_n = new int[num]; int i = 0; foreach (KeyValuePair<string, int> entry in ss)//统计单词总量 { Word1[i] = entry.Key; Word1_n[i] = entry.Value; i++; }
3.正则表达式
num = Regex.Matches(str, @"\d").Count; num = num + Regex.Matches(str, @"\s").Count; num = num + Regex.Matches(str, @"\w").Count; Console.WriteLine("字符数为:" + num);
四.测试过程
4.1代码互审
在代码互审过程中,首先发现在判断字符个数时出现了遗漏,没有将空格等也算入字符计算。其次是在文件名的输入,以及扩展新功能时与新功能链接使用的问题上,从一开始简单的输入文件名到我们加入了循环。行数判断后来才加入循环,使空白行不算入行数。
4.2建立单元测试

4.3 统计字符数类测试

4.4统计单词与词频类测试

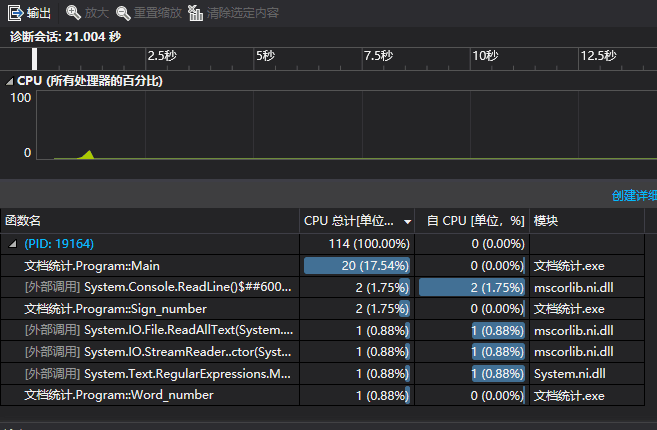
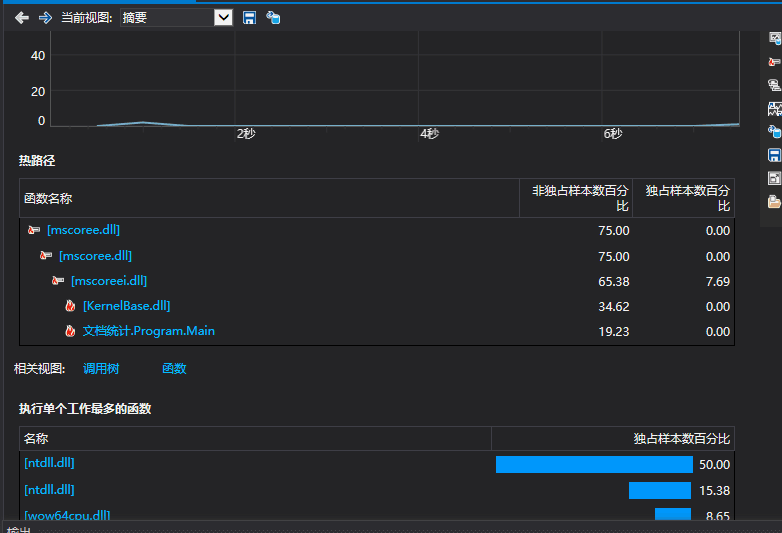
4.5效能分析
不是很懂效能分析怎么变成这样的,但是我弄了很多遍都还是这样的,还有很多要学习的,推测占用最多的是含循环的那个函数。但循环已经优化了,所以不多讨论了。
五.代码规范链接
https://blog.csdn.net/qq_31606375/article/details/77783328
六.总结
结对编程在分工好了的时候,相较于单人编程来说较省时间,但是当其中一人遇到瓶颈时,两个人的进度都会卡住,但是总体来说,还是感受到了1+1>2的效果,收货了很多,在讨论中也学到了不少东西,对于以后和团队的沟通交流肯定是有很大进步的。另外一个收货就是字典类和正则表达式的学习。对于正则表达式,参考了这个博客,写的很详细,帮助很大:https://blog.csdn.net/saccharine/article/details/53032062.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号