
第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | <计科23级12班> |
|---|---|
| 这个作业的要求在哪里 | <个人项目> |
| 这个作业的目标 | <个人完成论文查重算法的设计与实现,结合 GitHub 进行项目管理与提交,使用 PSP 表跟踪用时,并对程序开展性能分析优化与单元测试> |
1.GitHub 链接:
https://github.com/Echooooe/Echooooe/tree/main/3223004210
2.PSP 表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 30 | 25 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| · Design | · 具体设计 | 90 | 100 |
| · Coding | · 具体编码 | 180 | 210 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 160 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 20 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 35 |
| · 合计 | 670 | 855 |
3. 计算模块接口的设计与实现过程
目录结构:
3223004210/
├─ main.py # 命令行入口:读取原文/疑似文本,调用相似度函数,写入结果
├─ requirements.txt # 运行依赖
├─ requirements-dev.txt # 开发/测试/质量工具依赖(引用 requirements.txt)
├─ pytest.ini # pytest 配置
├─ .coveragerc # coverage 配置
├─ .pylintrc # Pylint 配置
├─ pyproject.toml # Ruff/Black/isort 统一配置
├─ .gitignore # 项目级忽略(报告产物、缓存、.vs 等)
├─ data/
│ ├─ orig.txt # 示例:原文
│ ├─ org_0.8_add.txt # 示例:疑似文本
│ ├─ org_0.8_del.txt # 示例:疑似文本
│ ├─ org_0.8_dis_1.txt # 示例:疑似文本
│ ├─ org_0.8_dis_10.txt # 示例:疑似文本
│ ├─ org_0.8_dis_15.txt # 示例:疑似文本
│ └─ ans.txt # 示例:输出结果
├─ src/
│ ├─ __init__.py
│ ├─ io_utils.py # 读/写文本、路径/编码处理
│ ├─ text_norm.py # 文本清洗/规范化(大小写、空白、标点等)
│ └─ sim.py # 相似度核心算法(n-gram 切片、集合/签名运算等)
├─ tests/ #单元测试
│ ├─ test_io_utils.py
│ ├─ test_text_norm.py
│ ├─ test_sim.py
│ └─ test_main.py
├─ reports/
│ ├─ tests/
│ │ └─ coverage_branch_*.png #分支覆盖率截图
│ └─ perf/ # 性能分析
│ ├─ before/ # 优化前
│ │ ├─ baseline_top.txt # cProfile Top(累计耗时)文本
│ │ └─ VS-baseline.png # VS 性能分析器截图(CPU/热路径)
│ └─ after/ # 优化后
│ ├─ optimized_top.txt
│ └─ VS-optimized.png
└─ bench/
└─ sample_profile.py # 性能剖析脚本
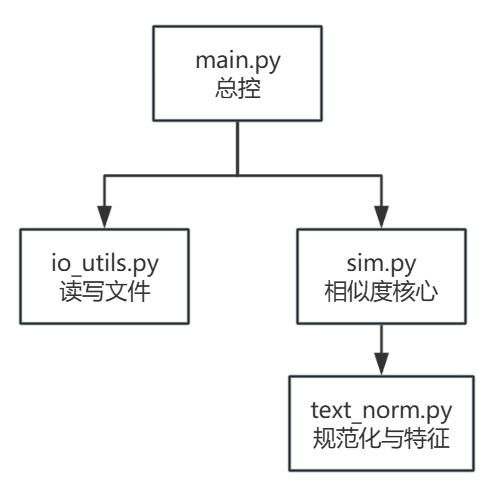
3.1 模块组织与关系
main.py # CLI/总控:解析参数 [-n N] 与 3 个路径参数;调用 src;
src/
├─ io_utils.py # I/O:读取/写入 UTF-8 文本
├─ text_norm.py # 规范化与特征:normalize / char_ngrams / counts
└─ sim.py # 相似度核心:_dot / _norm / _jaccard_chars / similarity_ratio
-
main.py(总控/CLI)
解析python main.py <org> <org_add> <ans> [-n N];调用io_utils.read_text_file读入、sim.similarity_ratio计算、io_utils.write_text_file -
io_utils.py
read_text_file(path) -> str、write_text_file(path, content) -> None -
text_norm.py
normalize(s) -> str:大小写统一、空白规整、按需清理标点;
char_ngrams(s, n) -> list[str]:生成字符 n-gram(默认 2);
counts(ngrams) -> dict[str,int]:n-gram 计数字典 -
sim.py
_dot(dict, dict) -> int:频次向量点积;_norm(dict) -> float:L2 范数;
_jaccard_chars(a: str, b: str) -> float:字符集合 Jaccard;
similarity_ratio(orig, copy, n=2) -> float:主接口,规范化 → n-gram;若任一侧无 n-gram 则退化为 Jaccard,否则以计数字典计算余弦相似度并返回[0,1]模块关系图:
3.2 输入输出方式
-
命令行输入
python main.py <orig_path> <copy_path> <ans_path> [-n N]-n/--ngram:扩展功能,n-gram 窗口(默认 2);非法取值(如<1)视为输入错误,stderr 提示并退出码 2;这里的[-n N]可选,若不输入参数,则默认使用2-gram。
-
输出:
<ans_path>写入一行相似度,四舍五入两位小数 -
退出码:
0正常;2已知异常
运行环境见 GitHub仓库 README 文件
3.3 关键算法与独到之处
3.3.1 算法:基于字符 n-gram 的向量空间模型(VSM)+ 余弦相似度,对极短文本退化为字符集合 Jaccard。
3.3.2 核心思想:
-
把文本先做规范化(大小写/空白/标点统一):
A = normalize(orig),B = normalize(copy) -
把连续的 n 个字符当作一个“片段”(n-gram):
toksA = char_ngrams(A,n),toksB = ...,如 n=2 时"今天是星期天"→今天、天是、是星、星期、期天。 -
统计每个片段出现的频次,得到两段文本各自的稀疏向量:
cA = counts(toksA),cB = counts(toksB) -
用余弦相似度比较两个向量的“夹角”:
\(cos(\theta)=\frac{\sum_i cA_i\cdot cB_i}{\sqrt{\sum_i cA_i^2}\cdot \sqrt{\sum_i cB_i^2}}\)
越接近,说明片段分布越相似;
若任一文本没有 n-gram(太短),则退化用Jaccard比较字符集合的交并比例:
\(\text{Jaccard} = \frac{|\,\text{set}(A)\cap \text{set}(B)\,|}{|\,\text{set}(A)\cup \text{set}(B)\,|}\)
3.3.3 设计亮点:
- 规范化:去 BOM、压缩空白,避免格式差异影响结果;
- 短文本退化:当文本过短无 n-gram 时,自动切换为字符集合 Jaccard,保证鲁棒性;
- 稀疏向量点积优化:只遍历较小的字典,减少哈希查找次数,提高常数效率;
- 边界定义清晰:
- 两者都空 → 1.0
- 一边空 → 0.0
- 分母为 0 → 防御性返回 0.0
- 模块解耦:I/O 与计算分离,计算过程可单独测试与扩展;
- 可调 n:允许用 -n/--ngram 调参以控制敏感度(n 越小越敏感,n 越大越严格)。
核心算法流程图:
3.4 复杂度
设输入长度为 L:
- 规范化
O(L);n-gram 生成O(L);词频统计O(L); - 余弦/交并集计算
O(|A|+|B|);总体 时间复杂度 ~ O(L),空间 ~ O(L)
4. 计算模块接口部分的性能改进
4.1 优化前问题:
- VS 性能分析器:
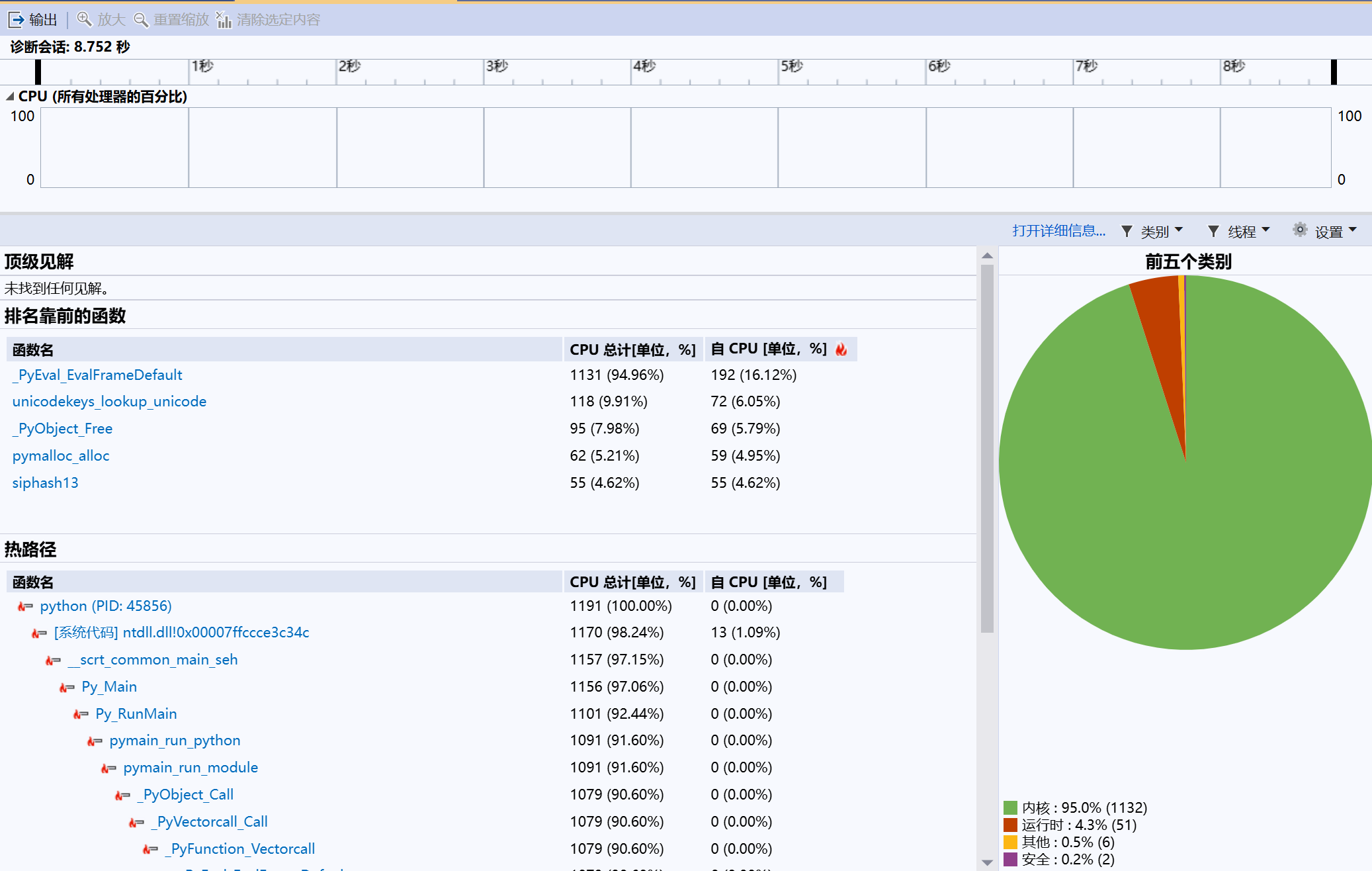
- cProfile(前15个热点函数)
reports/perf/baseline_top.txt:

-
总调用:1,835,052
-
总耗时:1.850 s
-
主要消耗函数:
counts1.204 s、char_ngrams0.488 s、normalize0.080 s -
热点集中在纯 Python 循环与字典累加:
text_norm.counts与char_ngrams占用最多 CPU;dict.get被调用 1,803,943 次。
4.2 改进思路与做法
- 计数用 C 实现
counts改为collections.Counter(底层_collections._count_elements为 C 执行),替代纯 Pythondict += 1循环。 - 重复输入缓存
对normalize(text)、char_ngrams(text, n)增加@lru_cache(maxsize=4096):多次对相同文本重复计算时直接复用结果。 - 点积微优化
_dot内将b.get绑定为局部b_get = b.get,减少属性查找开销。
4.3 优化后效果
- VS 性能分析器:

- cProfile(前15个热点函数)
reports/perf/optimized_top.txt(节选):

-
总调用:35,126
-
总耗时:0.246 s
-
主要消耗函数:
_collections._count_elements0.193 s、counts0.199 s -
速度提升:1.850 s → 0.246 s(≈ 7.5×)
-
函数调用数:1,835,052 → 35,126(≈ 52× )
5. 计算模块部分单元测试展示
5.1 测试用例设计(24 条)
| ID | 目标函数 | 覆盖点 / 测试目的 |
|---|---|---|
| TEXTNORM_R001_001 | normalize |
去 BOM、压缩空白 |
| TEXTNORM_R001_002 | normalize |
保留必要标点,不误删 |
| TEXTNORM_R001_003 | char_ngrams |
正常 2-gram |
| TEXTNORM_R001_004 | char_ngrams |
短文本 < n 返回空 |
| TEXTNORM_R001_005 | char_ngrams |
非法参数 n<=0 抛错 |
| TEXTNORM_R001_006 | counts |
计数字典正确 |
| SIM_R002_001 | similarity_ratio |
两空 → 1.0 |
| SIM_R002_002 | similarity_ratio |
一空 → 0.0 |
| SIM_R002_003 | similarity_ratio |
退化:无 n-gram 用 Jaccard |
| SIM_R002_004 | similarity_ratio |
自反性:同文本 = 1.0 |
| SIM_R002_005 | similarity_ratio |
无重叠 n-gram → 0.0 |
| SIM_R002_006 | similarity_ratio |
近义改写比分高于无关句 |
| SIM_R002_007 | _jaccard_chars(白盒) |
空∩空 → 1.0(边界) |
| SIM_R002_008 | _jaccard_chars(白盒) |
一空一非空 → 0.0 |
| IO_R003_001 | read_text_file/write_text_file |
写入后可回读;必要时创建父目录 |
| IO_R003_002 | read_text_file |
不存在文件 → FileNotFoundError |
| IO_R003_003 | read_text_file |
非法 UTF-8 字节 → UnicodeDecodeError |
| MAIN_R004_001 | CLI | 三参数端到端:一行两位小数+换行;退出码 0 |
| MAIN_R004_002 | CLI | 参量不足:打印 USAGE + 退出码 1 |
| MAIN_R004_003 | CLI | 输入文件缺失:stderr + 退出码 2 |
| MAIN_R004_004 | CLI | 扩展:-n 3 合法 → 正常 |
| MAIN_R004_005 | CLI | 扩展:-n 非法(n<=0/非整数)→ USAGE + 退出码 *1* |
| MAIN_R004_006 | CLI | 输出路径是目录:IsADirectoryError → 退出码 2 |
| MAIN_R004_007 | CLI | -n 非整数(如 "x")→ USAGE + 退出码 1 |
5.2 部分单元测试展示
_jaccard_chars边界极值
def test_SIM_R002_007_jaccard_both_empty_internal():
assert _jaccard_chars("", "") == 1.0
def test_SIM_R002_008_jaccard_one_empty_internal():
assert _jaccard_chars("A", "") == 0.0
assert _jaccard_chars("", "A") == 0.0
- 覆盖点:
_jaccard_chars的两个极端分支(空∩空=1;一空=0)。 - 数据思路:用最小字符串触发极端输入,验证定义语义并避免进入后续 n-gram 路径
similarity_ratio退化路径(无 n-gram ->Jaccard)
def test_SIM_R002_003_fallback_to_jaccard_when_no_ngram():
s = similarity_ratio("ab", "ac", n=4) # len("ab") < 4
assert 0.0 <= s <= 1.0
- 覆盖点:当任一侧没有 n-gram时,走 字符集合 Jaccard的退化分支。
- 数据思路:把
n设得比文本还大("ab","ac",n=4),确保 n-gram 为空,从而只比较字符集合。
similarity_ratio语义合理性对比(改写 > 无关)
def test_SIM_R002_006_paraphrase_higher_than_unrelated():
a = "机器学习是人工智能的重要分支。"
b = "人工智能的重要分支之一是机器学习。"
c = "今天天气晴朗,适合跑步。"
assert similarity_ratio(a, b) > similarity_ratio(a, c)
- 覆盖点:主路径下的相对排序合理性检查
- 数据思路:
a/b为改写句,a/c为主题无关;期望改写比分高于无关。
5.3 测试结果与覆盖率截图
测试全部通过:
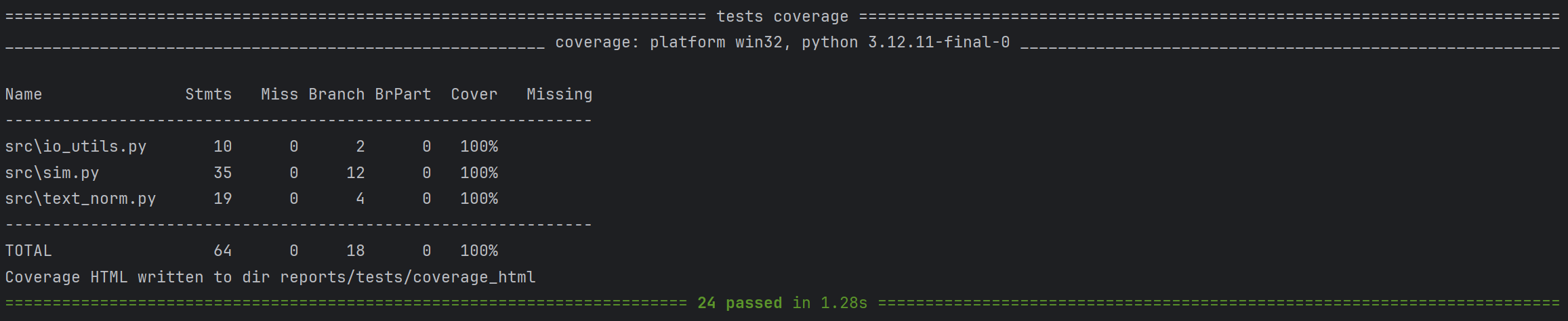
分支覆盖率100%:

6. 计算模块部分异常处理说明
异常分类、处理策略与单测样例:
A. 参数错误
-
设计目标:命令行参数不合法时快速失败,不进入计算和文件读写
-
覆盖场景:参数不足、
-n非法值、-n非整数。 -
代表用例:
# 参数不足 → Usage + returncode 1 def test_MAIN_R004_002_invalid_args_exit_code(): proc = subprocess.run([sys.executable, "main.py"], capture_output=True, text=True) assert proc.returncode == 1 assert "Usage:" in (proc.stdout + proc.stderr)
B. 文件不存在
-
设计目标:输入路径错误时给出明确错误,不崩溃
-
代表用例:
def test_MAIN_R004_003_missing_input_files_returncode_2(): proc = subprocess.run( [sys.executable, "main.py", "no_a.txt", "no_b.txt", "ans.txt"], capture_output=True, text=True, ) assert proc.returncode == 2 assert proc.stderr.strip() != ""
C. 路径非法/不可写
-
设计目标:输出路径不是文件、无写权限等情况要被捕获
-
代表用例:
def test_MAIN_R004_006_write_path_is_directory(tmp_path): """ 输出路径指向目录:write_text_file 内部调用 Path.write_text 抛 IsADirectoryError, main 捕获后应返回码 2,并在 stderr 打印错误信息。 """ import subprocess import sys o = tmp_path / "o.txt" c = tmp_path / "c.txt" out_dir = tmp_path / "ans_dir" o.write_text("A", encoding="utf-8") c.write_text("B", encoding="utf-8") out_dir.mkdir() # 故意把“输出文件”设为一个目录 proc = subprocess.run( [sys.executable, "main.py", str(o), str(c), str(out_dir)], capture_output=True, text=True ) assert proc.returncode == 2 assert proc.stderr.strip() != "" # 有错误信息
D. 编码异常的容错策略(忽略非法字节)
-
设计目标:遇到少量非 UTF-8 字节时,忽略非法字节以提升鲁棒性,而不是直接失败
-
代表用例:
def test_IO_R003_003_read_ignores_invalid_utf8(tmp_path): p = tmp_path / "bad.txt" p.write_bytes(b"\xff\xfehello") assert "hello" in read_text_file(str(p)) # 非法字节被忽略
7. 评价与改进方向
7.1 总体评价
- 功能:按要求完成,命令行三参 + 可选
-n,输出两位小数; - 正确性:单元测试覆盖关键分支(早返回/退化/主路径/异常),分支覆盖率 100%(见截图);
- 性能:
Counter + LRU优化后,样例耗时约 1.85s → 0.25s,明显加速;内存约 11 MB,达标; - 质量:Pylint 10/10,Ruff/Black/isort 全通过。
7.2 改进方向
- 更大文本:把 n-gram 改成流式生成,进一步降内存;
- 可读性:在 README 里加 阈值示例(相似度 ≥0.8 视为重复)和几条真实样例;
- 语义更稳:加入同义词/常见替换的小表(如“星期/周”),减少表面改写带来的分数波动。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号