
复合数据类型,英文词频统计
作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表:
1 #增 2 #append往列表里追加,放在最后 3 ls2=["helllo",[1,3],["hello"],3.14,"哈哈哈"] 4 ls2.append("append_1") 5 print(ls2) 6 ls2.append(["111",111]) 7 print(ls2) 8 9 #extend可以将另一个集合中的元素逐一添加到列表中 10 ls2=["helllo",[1,3],["hello"],3.14] 11 ls1=[123,456,"aaa",["bbb",789]] 12 ls2.extend(ls1) 13 print(ls2) 14 ls2.extend("aaaa") 15 print(ls2) 16 17 #insert 在指定位置index前插入元素数据项 18 ls2=["helllo",[1,3],["hello"],3.14,"哈哈哈"] 19 ls1=[1,3,"222"] 20 ls2.insert(1,"myinsert") 21 print(ls2) 22 ls2.insert(1,ls1) 23 print(ls2) 24 25 #删 26 #del根据角标去索引删除元素数据 27 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈",3.14,3.14,3.14] 28 del ls2[0] 29 print(ls2) 30 31 #pop无参数的话删除最后一个,有参数index的话,按角标删除,跟del功能相似 32 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈",3.14,3.14,3.14] 33 ls2.pop(0) 34 print(ls2) 35 ls2.pop() 36 print(ls2) 37 38 #remove根据元素的值进行删除,比较常用 39 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈",2.5,3,3.14,2.5,3] 40 ls1=["hello",123] 41 ls2.remove(3) 42 print(ls2) 43 44 #改 45 #修改列表中值,直接用赋值=即可 46 ls2=["helllo",[1,3],["hello"],3.14,"哈哈哈"] 47 ls2[0]="你好" 48 print(ls2) 49 50 #查 51 #判断某个元素是否在列表中,但是不返回具体位置,有为true,无为false. 52 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈"] 53 if "hello" in ls2: 54 print ("hello在ls2中") 55 else : 56 print("没找到") 57 58 #用index函数,如果存在返回角标 59 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈",3.14,3.14] 60 print(ls2.index(3.14)) 61 #print(ls2.index("3.14")) 62 63 #使用count()统计函数,也可以查询是否存在,但是无法返回角标位置 64 ls2=["hello",[1,3],["hello"],3.14,"哈哈哈",3.14,3.14,3.14] 65 print(ls2.count(3.14)) 66 print(ls2.count("aaaa")) 67 68 #遍历 69 #for循环语句遍历列表的值 70 ls1 =["hello",1,3,"你好",3.14,'true'] 71 num=1 72 for i in ls1: 73 print("列表的第%d的值:"%(num),i) 74 num +=1 75 76 #使用while语句遍历列表的值 77 ls1 =["hello",1,3,"你好",3.14,'true'] 78 i=0 79 while i<len(ls1): 80 print("打印ls1的第%d个值:"%(i+1),ls1[i]) 81 i += 1
元组(不能增删改,只能查找):
num = ("x", "y", "z") print('查询:\n原有的字母元素为:{}'.format(num)) print('num(0):查询到下标为1元素的值是:{}\n'.format(num[0]))
字典:
# 创建字典 textDict = {'JOJO':'60','GIOGIO':'100'} print(textDict) # 增 textDict['DIO']='120' print(textDict) # 改 textDict['JOJO']='90' print(textDict) # 删 del textDict['JOJO'] print(textDict) # 查 print(textDict['GIOGIO']) # 遍历 for s in textDict: print( "%s : %s"%(s,textDict[s]))
集合:
#增 s = set(['baidu','taobao','tianmao']) s.add('google') print(s) #删 s = set(['baidu','tianmao','taobao']) s.remove('taobao') print(s) #改 s = set(['baidu','tianmao',taobao']) s = list(s) s[0] = 'google' s = set(s) print(s) #遍历 s = set(['baidu','tianmao','taobao']) s.clear() print(s) s = set(['baidu','tianmao','taobao']) for bl in s: print(bl)
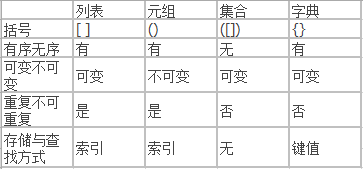
2.总结列表,元组,字典,集合的联系与区别。
3.词频统计
①下载一长篇小说,存成utf-8编码的文本文件 file
②通过文件读取字符串 str
③对文本进行预处理
④分解提取单词 list
⑤单词计数字典 set , dict
⑥按词频排序 list.sort(key=lambda),turple
⑦排除语法型词汇,代词、冠词、连词等无语义词
⑧自定义停用词表
或用stops.txt
输出TOP(20)
⑨可视化:词云
代码如下:
# -*- coding=utf-8 -*- exclude={'a','the','and','i','you','in','but','not','with','by','its','for','of','an','to','is','was','that','he','this','are','it','be','as','at','on','if','has','have','so','or'} #定义数组# #读取Harry Potter.txt文件中的英文内容# def gettxt(): sep=".,:;?!-_'" txt=open('Were You Ever a Child.txt','r',encoding='UTF-8').read().lower() for ch in sep : txt=txt.replace(ch,' ') return txt #分解提取单词# bigList=gettxt().split() print(bigList); print('big:',bigList.count('big')) bigSet=set(bigList) #过滤单词,包括一些冠词和连词等# bigSet=bigSet-exclude print(bigSet) #单词计数# bigDict={} for word in bigSet: bigDict[word]=bigList.count(word) print(bigDict) print(bigDict.items()) word=list(bigDict.items()) #按词频排序# word.sort(key=lambda x:x[1],reverse=True) print(word) #输出频率较高的词语top20# for i in range(20): print(word[i])
将生成的结果保存成csv文件:
import pandas as pd
pd.DataFrame(data=word).to_csv('Harry Potter.csv',encoding='utf-8')
运行结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号